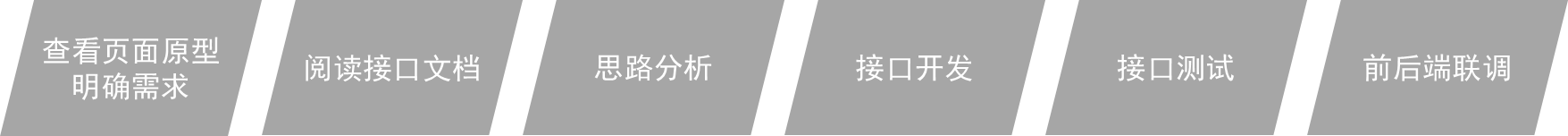首页
关于
Search
1
图神经网络
8 阅读
2
数学基础
7 阅读
3
欢迎使用 Typecho
6 阅读
4
线性代数
4 阅读
5
linux服务器
3 阅读
默认分类
科研
自学
登录
找到
24
篇与
自学
相关的结果
- 第 2 页
2025-03-21
linux服务器
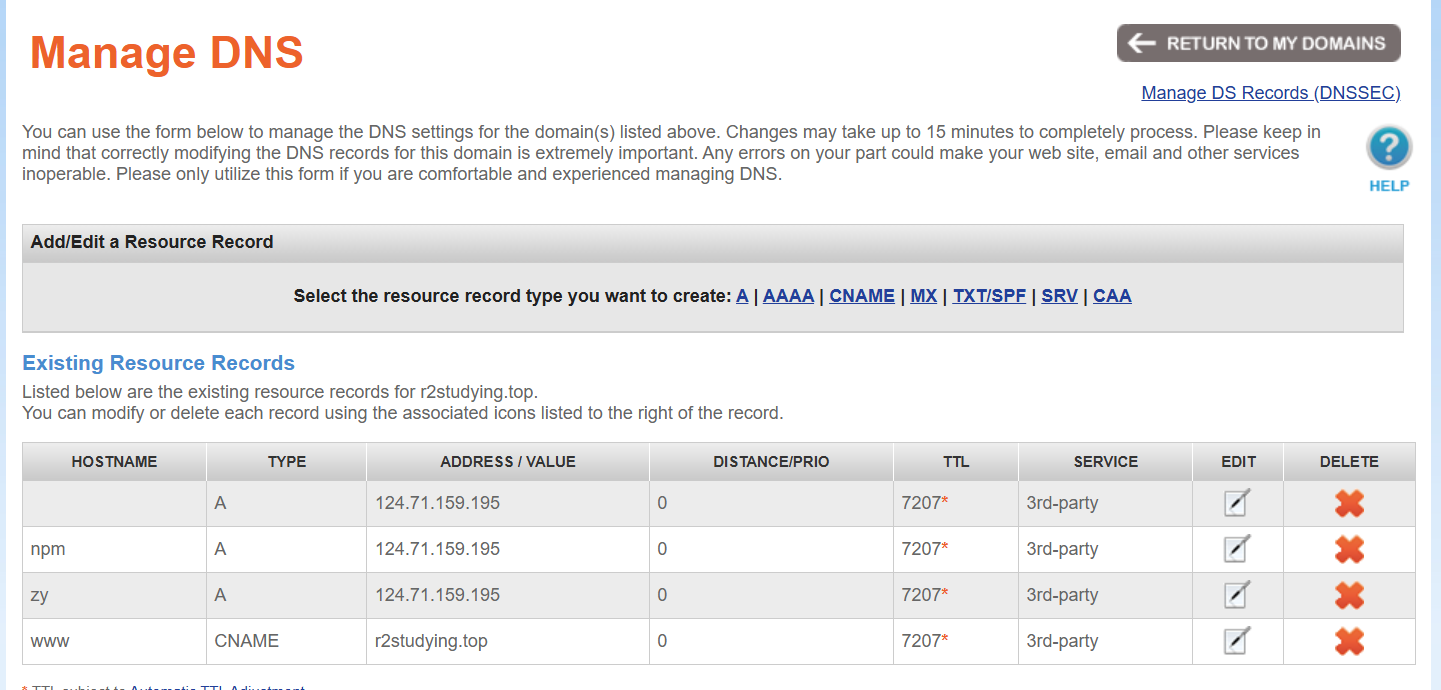
llinux服务器(以debian为例) 预先准备 域名购买与解析 购买:Low-Cost Domain Names & Hosting from $0.99 | NameSilo 教程:【服务器、域名购买】Namesilo优惠码和域名解析教程(附带服务器购买推荐和注意事项) | 爱玩实验室 DNS解析:可能需等待几分钟生效 买的域名的r2studying.top 这里的HOSTNAME相当于二级域名,如npm.r2studying.top 现改为CloudFlare来做DNS解析,不用namesilo,它有两种模式: Proxied(橙色云朵):当你将某个 DNS 记录设置为 Proxied 时,Cloudflare 会作为反向代理服务器处理该域名的 HTTP/HTTPS 流量。这样做有几个效果: 隐藏真实 IP:用户访问时看到的是 Cloudflare 的 Anycast IP,而不是你服务器的真实 IP,从而提高安全性。 提供 CDN 加速:Cloudflare 会缓存静态资源,并通过全球节点加速内容传输,提升网站响应速度。 附加安全防护:包括 DDoS 防护和 Web 应用防火墙等功能。 DNS Only(灰色云朵):如果你设置为 DNS Only,Cloudflare 只负责 DNS 解析,不会对流量进行代理或处理。也就是说,用户访问时会直接获取并连接到你服务器的真实 IP。 安全组设置 登录云服务器的控制台设置 入站规则 入站规则(Inbound Rules)是指防火墙中用来控制外部流量进入服务器的规则。通过这些规则,你可以指定允许或拒绝哪些类型的网络流量(例如特定协议、端口号、IP地址等)进入你的服务器。 类型 协议端口 源地址 描述 IPv4 TCP : 22 0.0.0.0/0 允许外部访问安全组内实例的SSH(22)端口,用于远程登录Linux实例。 IPv4 TCP : 3389 0.0.0.0/0 允许外部访问安全组内实例的RDP(3389)端口,用于远程登录Windows实例。 IPv4 TCP : 80 0.0.0.0/0 允许外部访问安全组内实例的HTTP(80)端口,用于通过HTTP协议访问网站。 IPv4 TCP : 443 0.0.0.0/0 允许外部访问安全组内实例的HTTPS(443)端口,用于通过HTTPS协议访问网站。 IPv4 TCP : 20-21 0.0.0.0/0 允许通过FTP上传和下载文件。 IPv4 ICMP: 全部 0.0.0.0/0 允许外部使用ping命令验证安全组内实例的网络连通性。 出站规则 出站规则(Outbound Rules)则是指控制服务器向外部发送流量的规则。你可以通过出站规则来限制服务器发出的数据包,比如限制服务器访问某些外部服务或 IP 地址。 凡是服务正常启动但是浏览器上无法访问的,都首先想想防火墙端口是否打开!!! 常用的命令 cat 用于查看文本文件的内容 head 查看前n行 head -n 100 文件名 touch 新建文本文件,如touch /home/hello.py 将在home 文件夹下新建hello.py ls 列出所有文件,但默认只是显示出最基础的文件和文件夹,如果需要更详细的信息,则使用ls -la,这将列出包括隐藏文件在内的所有文件和文件夹,并且给出对应的权限、大小和日期等信息。 zy123@hcss-ecs-588d:~$ ls -la total 44 drwxr-xr-x 6 zy123 zy123 4096 Feb 26 08:53 . drwxr-xr-x 3 root root 4096 Feb 24 16:33 .. -rw------- 1 zy123 zy123 6317 Feb 25 19:41 .bash_history -rw-r--r-- 1 zy123 zy123 220 Feb 24 16:33 .bash_logout -rw-r--r-- 1 zy123 zy123 3526 Feb 24 16:33 .bashrc drwx------ 3 zy123 zy123 4096 Feb 24 16:35 .config drwxr-xr-x 3 zy123 zy123 4096 Feb 24 16:36 .local -rw-r--r-- 1 zy123 zy123 807 Feb 24 16:33 .profile drwxr-xr-x 5 zy123 zy123 4096 Feb 26 08:53 zbparse drwxr-xr-x 3 root root 4096 Feb 26 08:54 zbparse_output 权限与文件类型(第一列): 第一个字符表示文件类型: “d”表示目录(directory) “-”表示普通文件(regular file) “l”表示符号链接(symbolic link) 后续的9个字符分为3组,每组三个字符,分别代表所有者、所属组和其他用户的权限(读、写、执行)。 硬链接数(第二列): 表示指向该文件的硬链接数量。对于目录来说,这个数字通常会大于1,因为“.”和“..”也算在内。 所有者(第三列): 显示该文件或目录的拥有者用户名。 所属组(第四列): 显示该文件或目录所属的用户组。 文件大小(第五列): 以字节为单位显示文件的大小。对于目录,通常显示的是目录文件占用的磁盘空间(一般为4096字节)。 最后修改日期和时间(第六列): 显示文件最后一次修改的日期和时间(可能包含月、日和具体时间或年份)。 文件名或目录名(第七列): 显示文件或目录的名称。 cd 进入指定文件夹,如cd /home 将进入home目录。返回上层目录的命令是cd ..,返回刚才操作的目录的命令是cd - mkdir 新建文件夹,如mkdir /home/Python 将在home 文件夹下新建一个Python 文件夹。 mv 移动文件和文件夹,也可以用来修改名称,如: mv /home/hello.py /home/helloworld.py 将上文的hello.py重命名为helloworld.py, mv /home/helloworld.py /home/Python/helloworld.py 将helloworld.py 由home文件夹移动到了次级的Python文件夹。 mv /home/hello.py . 将/home/hello.py 移动到当前目录下 cp 复制文件 cp /home/Python/hellowrold.py /home/Python/HelloWorld.py 将helloworld.py复制为HelloWolrd.py。注意:Linux系统严格区分大小写,helloworld.py和HelloWolrd.py是两个文件。 rm 删除,即江湖传说中rm -rf ,r为递归,可以删除文件夹中的文件,f为强制删除。rm /home/Python/helloworld.py 可以删除刚才的helloworld.py 文件,而想删除包括Python 在内的所有文件,则是rm -rf /home/Python 。 du -h 查看当前文件夹下,各文件、文件夹的大小,h是让文件自动使用K/M/G显示而不是只有K。“disk usage”(磁盘使用情况) grep 是用于在文件或标准输入中搜索符合条件的行的命令。 grep "pattern" filename #pattern可以是一个正则表达式 -i忽略大小写 -n显示行号 awk 是一个功能强大的文本处理工具,它可以对文本文件进行分列处理、模式匹配和报告生成。它的语法类似一种简单的脚本语言。 awk 'pattern { action }' filename pattern:用于匹配文本的条件(可以省略,默认对所有行生效)。 action:在匹配的行上执行的操作。 $0:代表整行内容。 $1, $2, ...:代表各个字段(默认分隔符是空白字符,可以通过 -F 参数指定其他分隔符)。 awk '{print $1, $3}' filename #印指定列 管道 | 是将一个命令的输出直接传递给另一个命令作为输入的一种机制。 示例:将 grep 与 awk 联合使用:假设有一个日志文件 access.log,需要先用 grep 过滤出包含 "ERROR" 的行,再用 awk 提取时间字段: 127.0.0.1 27/Feb/2025:10:30:25 "GET /index.html HTTP/1.1" 200 1024 192.168.1.1 27/Feb/2025:10:31:45 "POST /login HTTP/1.1" 302 512 10.0.0.5 27/Feb/2025:10:32:10 "GET /error_page HTTP/1.1" 500 2048 ERROR grep 'ERROR' access.log | awk '{print $2}' 输出:27/Feb/2025:10:32:10 lsof"List Open Files"显示系统中当前打开的文件。 -i会显示所有正在使用网络连接的进程 lsof -i :80 #查看 80 端口上的进程,或者判断80端口是否被占用! usermode 修改用户账户信息的命令 sudo usermod -aG docker zy123 #-aG一起用,添加zy123到group组 chmod 命令用于修改文件或目录的权限 数字方式:数字方式使用三个(或四个)数字来表示所有者、组用户和其他用户的权限。每个数字代表读 (4)、写 (2)、执行 (1) 权限的和。 chmod 644 filename #所有者:读 + 写 = 6 组用户:读 = 4 其他用户:读 = 4 符号方式 chmod [用户类别][操作符][权限] filename 用户类别: u:所有者(user) g:组用户(group) o:其他用户(others) a:所有用户(all),等同于 u+g+o 操作符: +:增加权限 -:去掉权限 =:直接设置权限 权限: r:读权限 w:写权限 x:执行权限 chmod u+x filename #为所有者增加执行权限 文本编辑器 nano:Debian 11自带了简便易用的nano文本编辑器 nano /etc/apt/sources.list #打开sources.list文件 Ctrl+O:保存修改 ->弹出询问-> Y则保存,N则不保存,ctrl+c 取消操作。 Ctrl+X:退出 vim 普通模式(Normal Mode): 打开 Vim 后默认进入普通模式。在该模式下,可以执行移动光标、删除、复制、粘贴等命令。 光标移动: 0:跳到当前行行首 $:跳到当前行行尾 gg: 将光标移到文件开头 文本操作: dd:删除(剪切)整行 yy:复制(拷贝)整行 p:在光标后粘贴(把剪切或复制的内容贴上) u:撤销上一步操作 Ctrl + r:重做上一步撤销的操作 插入模式(Insert Mode): 在普通模式下按 i、I、a、A 等键可进入插入模式,此时可以像普通编辑器那样输入文本。 按 ESC 键退出插入模式,返回普通模式。 可视模式(Visual Mode): 用于选中一段文本,自动进入可视模式。选中文本后可以进行复制、剪切等操作。 在可视模式下选中后按 d 删除 按 y 复制选中区域 命令行模式(Command-Line Mode): 在普通模式下,输入 : 进入命令行模式,可以执行保存、退出、查找等命令。 :w:保存当前文件 :q:退出 Vim(如果有未保存的修改会警告) :wq 或 :x:保存文件并退出 :q!:不保存强制退出 :set number:显示行号 :set paste:适用于代码或格式敏感的文本,确保粘贴操作不会破坏原有的布局和缩进。 :%d: 删除全文 抓包 sudo tcpdump -nn -i any port 1000 //查看请求端口1000的源 IP 地址 SSH 生成密钥 ssh-keygen -t rsa -b 4096 -C "your_email@example.com" 默认会在当前用户的主目录下的 ~/.ssh/ 文件夹中生成两个文件: 私钥(id_rsa):必须保存在本地,切勿泄露或放到服务器上。它是用来证明你身份的重要凭证。 公钥(id_rsa.pub):需要复制到目标服务器上,通常放入服务器用户主目录下的 ~/.ssh/authorized_keys 文件中,用于验证连接时与私钥匹配。 根据我的理解: 1.服务器从github上通过ssh拉取代码时,需要把服务器的公钥放在github上,因为拉代码时,github需要认证服务器的身份,就要用服务器给它提供的公钥加密。 2.通过windows上的finalshell连接linux服务器时,需要在windows环境下生成一对密钥,私钥用于ssh登录的时候输入,公钥放在linux服务器的~/.ssh/authorized_keys文件中。因为ssh登录的时候服务器需要验证你的身份,需要用你提供给它的公钥加密。 除此之外,还需要给文件和相关文件夹合适的权限: chmod 600 authorized_keys chmod 700 ~/.ssh 文件系统 在 Linux 系统中,整个文件系统从根目录 / 开始,下面简单介绍一些主要目录及其存放的文件类型: /bin 存放系统启动和运行时必需的用户二进制可执行文件,如常用的 shell 命令(例如 ls、cp、mv 等)。 /boot 包含启动加载器(如 GRUB)的配置文件和内核映像(kernel image),这些文件用于系统启动过程。 /dev 包含设备文件,这些文件代表系统中的各种硬件设备(例如硬盘、终端、USB 设备等),以及一些伪设备。 /etc 存放系统范围内的配置文件,例如网络配置、用户账户信息、服务配置等。这些文件通常由管理员维护。 /home 为普通用户提供的家目录,每个用户在这里有一个独立的子目录,存放个人文件和配置。 /lib 和 /lib64 存放系统和应用程序所需的共享库文件,这些库支持 /bin、/sbin 及其他程序的运行。 /media 通常用于挂载移动介质,如光盘、U 盘或其他可移动存储设备。 /mnt 提供一个临时挂载点,一般供系统管理员在需要手动挂载文件系统时使用。 /opt 用于安装附加的应用程序软件包,通常是第三方提供的独立软件,不与系统核心软件混合。 /proc 这是一个虚拟文件系统,提供内核和进程信息,例如系统资源使用情况、硬件信息、内核参数等。这里的文件不占用实际磁盘空间。 /root 系统管理员(root 用户)的家目录,与普通用户的 /home 分开存放。 /run 存储系统启动后运行时产生的临时数据,比如 PID 文件、锁文件等,系统重启后会清空该目录。 /sbin 存放系统管理和维护所需的二进制文件(系统级命令),例如网络配置、磁盘管理工具等,这些通常只由 root 用户使用。 /srv 用于存放由系统提供的服务数据,如 FTP、HTTP 服务的数据目录等。 /tmp 用于存放临时文件,许多应用程序在运行时会将临时数据写入这里,系统重启后通常会清空该目录。 /usr 存放大量用户应用程序和共享资源,其子目录包括: /usr/bin:大部分用户命令和应用程序。 /usr/sbin:非基本系统维护工具,主要供系统管理员使用。 /usr/lib:程序库文件。 /usr/share:共享数据,如文档、图标、配置样本等。 /var 存放经常变化的数据,如日志文件、缓存、邮件、打印队列和临时应用数据等。 Bash #!/bin/bash # 定义变量,注意等号两边不能有空格 name="World" # 如果脚本传入了参数,则使用第一个参数覆盖默认值 if [ $# -ge 1 ]; then # $# 表示传入脚本的参数个数 name=$1 # $1 表示第一个参数。 fi # 输出问候语 echo "Hello, $name!" #变量引用时要用 $ 符号,如 $name。 # 循环示例:遍历1到5的数字 for i in {1..5}; do echo "当前数字:$i" done # 定义一个函数,函数名为greet greet() { echo "函数内问候: Hello, $1!" } # 调用函数,并传入变量name作为参数 greet $name 如何运行? 赋予可执行权限 chmod +x hello_world.sh 执行 ./hello_world.sh 或者 ./hello_world.sh Alice #传参 在 Linux 系统中,默认情况下当前目录(.)并不包含在 PATH 环境变量中。这意味着,如果你在终端中直接输入脚本名(例如 hello_world.sh),系统不会在当前目录下查找这个脚本,而是只在 PATH 中指定的目录中查找可执行程序。使用 ./hello_world.sh 表示“在当前目录下执行 hello_world.sh”,从而告诉系统正确的路径。 如何设置定时任务? sudo crontab -e #在里面添加: 10 0 * * * /path/toyour/xx.sh #让gpt写 反向代理神器——Nginx Proxy Manager 【Docker系列】一个反向代理神器——Nginx Proxy Manager-我不是咕咕鸽 概念 正向代理是代理客户端的行为,即代理服务器代表客户端向目标服务器发出请求。客户端将自己的请求先发送给代理服务器,由代理服务器转发给真正的目标服务器,然后再将返回结果传递给客户端。 特点: 保护访问者(客户端)的信息:目标服务器只会看到代理服务器的请求,无法直接获知真正发起请求的客户端是谁。 应用场景:当客户端出于隐私、访问控制或跨越网络限制的目的,需要隐藏自己的真实IP或身份时,会使用正向代理。 反向代理是代理服务器代表目标服务器接收客户端请求,并将请求转发给内部的真实服务器,然后将结果返回给客户端。客户端只与代理服务器通信,而不知道背后实际处理请求的服务器。 特点: 保护服务器端的信息:客户端看不到真正的服务器细节,只知道代理服务器。这样可以隐藏真实服务器的 IP 和其他内部结构信息,从而增强安全性和负载均衡等功能。 应用场景:在大型网站或应用中,为了防止恶意攻击或实现负载均衡,通常会在真实服务器前部署一个反向代理服务器。 docker 部署 version: '3' services: app: image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: - '80:80' # 保持默认即可,不建议修改左侧的80 - '81:81' # 冒号左边可以改成自己服务器未被占用的端口 - '443:443' # 保持默认即可,不建议修改左侧的443 volumes: - ./data:/data # 冒号左边可以改路径,现在是表示把数据存放在在当前文件夹下的 data 文件夹中 - ./letsencrypt:/etc/letsencrypt # 冒号左边可以改路径,现在是表示把数据存放在在当前文件夹下的 letsencrypt 文件夹中 NPM后台管理网站运行在81号端口,NPM服务本身监听80(http)和443(https)端口 工作原理 用户访问网站(80/443端口) 当用户访问 https://blog.test.com 时,请求到达服务器的443端口。 Nginx根据域名匹配代理规则(由NPM配置),将请求转发到后端服务(如 192.168.1.100:8080)。 管理员访问后台(81端口) 管理员通过 http://服务器IP:81 访问NPM管理界面,配置代理规则。 配置完成后,NPM会自动生成Nginx配置文件并重启Nginx服务,使新规则生效。 两种方法实现SSL安全连接 1. 开启橙云+Cloudflare Origin CA:网站SSL证书自动续期又又又失败了?试试CloudFlare的免费证书,15年有效期!-我不是咕咕鸽 cloudflare解析DNS,开启橙云 Cloudflare Full (strict)模式(灵活模式下无需以下步骤) 在 Nginx Proxy Manager(NPM)添加 Cloudflare Origin CA 配置 Proxy Host 使其使用 选择刚刚添加的 Cloudflare Origin CA 证书 选择 Force SSL(强制 HTTPS) 启用 HTTP/2 支持 Cloudflare Origin CA作用:实现cloudflare与源服务器之间的流量加密 2.通配符SSL证书:【Docker系列】反向代理神器NginxProxyManager——通配符SSL证书申请-我不是咕咕鸽 更推荐第二种!!!目前正在使用,但是3个月续签一次证书! 浏览器 → (HTTPS) → NPM → (HTTP 或 HTTPS) → Gitea 这就是反向代理常见的工作流程。 默认经常是 NPM 做 SSL 终止(内网用 HTTP 转发给 Gitea)。如果你想内外全程加密,就要让 NPM -> Gitea 这段也走 HTTPS,并在 Gitea 上正确配置证书。 正向代理(用于拉取镜像) 下载Clash客户端:Release Clash-Premium · DustinWin/proxy-tools 或者Index of /Linux/centOS/ 我是windows上下载clashpremium-release-linux-amd64.tar.gz 然后FTP上传到linux服务器上。 下载配置文件config.yaml:每个人独一无二的 wget -O /home/zy123/VPN/config.yaml "https://illo1.no-mad-world.club/link/2zXAEzExPjAi6xij?clash=3" 类似这样: port: 7890 socks-port: 7891 allow-lan: false mode: Rule //Global log-level: info external-controller: 0.0.0.0:9090 unified-delay: true hosts: time.facebook.com: 17.253.84.125 time.android.com: 17.253.84.125 dns: enable: true use-hosts: true nameserver: - 119.29.29.29 - 223.5.5.5 - 223.6.6.6 - tcp://223.5.5.5 - tcp://223.6.6.6 - tls://dns.google:853 - tls://8.8.8.8:853 - tls://8.8.4.4:853 - tls://dns.alidns.com - tls://223.5.5.5 - tls://223.6.6.6 - tls://dot.pub - tls://1.12.12.12 - tls://120.53.53.53 - https://dns.google/dns-query - https://8.8.8.8/dns-query - https://8.8.4.4/dns-query - https://dns.alidns.com/dns-query - https://223.5.5.5/dns-query - https://223.6.6.6/dns-query - https://doh.pub/dns-query - https://1.12.12.12/dns-query - https://120.53.53.53/dns-query default-nameserver: - 119.29.29.29 - 223.5.5.5 - 223.6.6.6 - tcp://119.29.29.29 - tcp://223.5.5.5 - tcp://223.6.6.6 proxies: - {name: 🇭🇰 香港Y01, server: qvhh1-g03.hk01-ae5.entry.v50307shvkaa.art, port: 19273, type: ss, cipher: aes-256-gcm, password: 6e4124c4-456e-36a3-b144-c0e1a618d04c, udp: true} 注意,魔戒vpn给的是一个订阅地址!!!还需要解码 简便方法:windows上将订阅链接导入,自动解析成yaml配置文件,然后直接把该文件传到服务器上! 启动Clash ./CrashCore -d . & //后台启动 为Clash创建服务 1.创建 systemd 服务文件 sudo vim /etc/systemd/system/clash.service 2.在文件中添加以下内容: [Unit] Description=Clash Proxy Service After=network.target [Service] ExecStart=/home/zy123/VPN/CrashCore -d /home/zy123/VPN WorkingDirectory=/home/zy123/VPN Restart=always User=zy123 Group=zy123 [Install] WantedBy=multi-user.target 这段配置将 Clash 配置为: 在网络服务启动后运行。 在启动时自动进入后台,执行 CrashCore 服务。 如果服务意外停止,它将自动重启。 以 zy123 用户身份运行 Clash。 启动服务: sudo systemctl start clash 停止服务: sudo systemctl stop clash 查看服务状态: sudo systemctl status clash 配置YACD YACD 是一个基于 Clash 的 Web 管理面板,用于管理您的 Clash 配置、查看流量和节点信息等。 直接用现成的:https://yacd.haishan.me/ 服务器上部署:目前是npm手动构建安装启动的。 下载yacd git clone https://github.com/haishanh/yacd.git 安装npm 构建yacd cd ~/VPN/yacd pnpm install pnpm build 启动yacd nohup pnpm serve --host 0.0.0.0 & //如果不是0.0.0.0 不能在windows上打开 停止进程 ps aux | grep pnpm kill xxx 通过http://124.71.159.195:4173/ 访问yacd控制面板。手动添加crash服务所在的ip:端口。 如果连不上:yacd和crash都是http协议就行了。 使用代理:curl -x http://127.0.0.1:7890 https://www.google.com File Browser 文件分享 https://github.com/filebrowser/filebrowser Docker 部署 File Browser 文件管理系统_filebrowser docker-CSDN博客 1.创建数据目录 mkdir -p /data/filebrowser/{srv,config,db} 2.目录授权 chmod -R 777 /data/filebrowser/ 3.编辑 docker-compose.yaml 文件 version: '3' services: filebrowser: image: filebrowser/filebrowser:s6 container_name: filebrowser restart: always ports: - "2000:80" # 将容器的80端口映射到宿主机2000端口 volumes: - /data/filebrowser/srv:/srv #保存用户上传的文件 - /data/filebrowser/config:/config # 配置文件存储路径 - /data/filebrowser/db:/database #数据库存储路径 调用API实现文件上传与下载 登录: # 登录 → 获取 JWT token(原始字符串) curl -X POST "yourdomain/api/login" \ -H "Content-Type: application/json" \ -d '{ "username": "admin", "password": "123456" }' 响应: "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9…" //jwt令牌 上传: # 先把 token 保存到环境变量(假设你已经执行过 /api/login 并拿到了 JWT) export TOKEN="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9…" # 定义要上传的本地文件和目标名称 FILE_PATH="/path/to/local/photo.jpg" OBJECT_NAME="photo.jpg" # 对远程路径做 URL 编码(保留斜杠) REMOTE_PATH="store/${OBJECT_NAME}" ENCODED_PATH=$(printf "%s" "${REMOTE_PATH}" \ | jq -sRr @uri \ | sed 's/%2F/\//g') # 发起上传请求(raw body 模式) curl -v -X POST "https://yourdomain/api/resources/${ENCODED_PATH}?override=true" \ -H "X-Auth: ${TOKEN}" \ -H "Content-Type: image/jpeg" \ # 根据文件后缀改成 image/png 等 --data-binary "@${FILE_PATH}" 获取分享链接url: # 假设已经执行过 /api/login 并把 JWT 保存在环境变量 TOKEN # 同样复用之前算好的 ENCODED_PATH 和 REMOTE_PATH # 调用分享接口(注意:POST,body 为空 JSON "{}") curl -s -X POST "https://yourdomain/api/share/${ENCODED_PATH}" \ -H "X-Auth: ${TOKEN}" \ -H "Cookie: auth=${TOKEN}" \ -H "Content-Type: text/plain;charset=UTF-8" \ -d '{}' \ | jq -r '.hash' \ | xargs -I{} printf "https://yourdomain/api/public/dl/%s/%s\n" {} "${REMOTE_PATH}" Gitea Gitea Docker 安装与使用详解:轻量级自托管 Git 服务教程-CSDN博客 version: "3" services: gitea: image: gitea/gitea:latest container_name: gitea environment: - USER_UID=1000 - USER_GID=1000 restart: always ports: - "3000:3000" # 将宿主机的3000端口映射到容器的3000端口 volumes: - /data/gitea:/data # 持久化存储Gitea数据(包括仓库、配置、日志等) EasyImage 【好玩儿的Docker项目】10分钟搭建一个简单图床——Easyimage-我不是咕咕鸽 github地址:icret/EasyImages2.0: 简单图床 - 一款功能强大无数据库的图床 2.0版 sudo -i # 切换到root用户 apt update -y # 升级packages apt install wget curl sudo vim git # Debian系统比较干净,安装常用的软件 version: '3.3' services: easyimage: image: ddsderek/easyimage:latest container_name: easyimage ports: - '1000:80' environment: - TZ=Asia/Shanghai - PUID=1000 - PGID=1000 volumes: - '/root/data/docker_data/easyimage/config:/app/web/config' - '/root/data/docker_data/easyimage/i:/app/web/i' restart: unless-stopped 网页打开显示bug: cd /data/easyimage/config/config.php 这里添加上https 网站域名 图片域名设置可以改变图片的url:IP或域名 picgo安装: Releases · Molunerfinn/PicGo 1.右下角小窗打开 2.插件设置,搜索web-uploader 1.1.1 (自定义web图床) 旧版有搜索不出来的情况!建议直接安装最新版! 3.配置如下,API地址从easyimage-设置-API设置中获取 typora设置 左上角文件-偏好设置-图像-插入图片时{ 上传图片-picgo服务器-填写picgo安装路径 } ps:还可以选择上传到./assets,每个md文件独立 或者上传到指定路径如/image,多个md文件共享 py脚本1:将所有md文件中的图片路径改为本地,统一保存到本地output文件夹中 py脚本2:将每个md文件及其所需图片单独保存,保存到本地,但每个md文件有自己独立的assets文件夹 py脚本3:将本地图片上传到easyimage图床并将链接返回替换md文件中的本地路径 Typecho 【好玩儿的Docker项目】10分钟搭建一个Typecho博客|太破口!念念不忘,必有回响!-我不是咕咕鸽 typecho:https://github.com/typecho/typecho/ 注意:nginx一定要对typecho目录有操作权限! sudo chmod 755 -R ./typecho services: nginx: image: nginx ports: - "4000:80" # 左边可以改成任意没使用的端口 restart: always environment: - TZ=Asia/Shanghai volumes: - ./typecho:/var/www/html - ./nginx:/etc/nginx/conf.d - ./logs:/var/log/nginx depends_on: - php networks: - web php: build: php restart: always expose: - "9000" # 不暴露公网,故没有写9000:9000 volumes: - ./typecho:/var/www/html environment: - TZ=Asia/Shanghai depends_on: - mysql networks: - web pyapp: build: ./markdown_operation # Dockerfile所在的目录 restart: "no" networks: - web env_file: - .env depends_on: - mysql mysql: image: mysql:5.7 restart: always environment: - TZ=Asia/Shanghai expose: - "3306" # 不暴露公网,故没有写3306:3306 volumes: - ./mysql/data:/var/lib/mysql - ./mysql/logs:/var/log/mysql - ./mysql/conf:/etc/mysql/conf.d env_file: - mysql.env networks: - web networks: web: 卸载: sudo -i # 切换到root cd /root/data/docker_data/typecho # 进入docker-compose所在的文件夹 docker-compose down # 停止容器,此时不会删除映射到本地的数据 cd ~ rm -rf /root/data/docker_data/typecho # 完全删除映射到本地的数据 主题 Joe主题:https://github.com/HaoOuBa/Joe Joe再续前缘主题 - 搭建本站同款网站 - 易航博客 自定义文章详情页的上方信息(如更新日期/文章字数第): /typecho/usr/themes/Joe/functions.php中定义art_count,统计字数(粗略)。 原始 Markdown → [1] 删除代码块/行内代码/图片/链接标记/标题列表标记/强调符号 → [2] strip_tags() + html_entity_decode() → [3] 正则保留 “文字+数字+标点”,去除其它 → 结果用 mb_strlen() 得到最终字数 typecho/usr/themes/Joe/module/single/batten.php <?php if (!defined('__TYPECHO_ROOT_DIR__')) { http_response_code(404); exit; } ?> <h1 class="joe_detail__title"><?php $this->title() ?></h1> <div class="joe_detail__count"> <div class="joe_detail__count-information"> <a href="<?php $this->author->permalink(); ?>"> <img width="38" height="38" class="avatar lazyload" src="<?php joe\getAvatarLazyload(); ?>" data-src="<?php joe\getAvatarByMail($this->author->mail) ?>" alt="<?php $this->author(); ?>" /> </a> <div class="meta ml10"> <div class="author"> <a class="link" href="<?php $this->author->permalink(); ?>" title="<?php $this->author(); ?>"><?php $this->author(); ?></a> </div> <div class="item"> <span class="text"> <?php echo $this->date('Y-m-d'); ?> / <?php $this->commentsNum('%d'); ?> 评论 / <?php echo joe\getAgree($this); ?> 点赞 / <?php echo joe\getViews($this); ?> 阅读 / <?php echo art_count($this->cid); ?> 字 </span> </div> </div> </div> </div> <div class="relative" style="padding-right: 40px;"> <i class="line-form-line"></i> <!-- 新增最近修改日期显示 --> <div style="font-size: 1.0em; position: absolute; right: 20px; top: 50%; transform: translateY(-50%);"> 最后更新于 <?php echo date('m-d', $this->modified); ?> </div> <div class="flex ac single-metabox abs-right"> <div class="post-metas"> <!-- 原图标及其他冗余信息已删除 --> </div> <div class="clearfix ml6"> <!-- 编辑文章/页面链接已删除 --> </div> </div> </div> 修改代码块背景色: typecho/usr/themes/Joe/assets/css/joe.global.css .joe_detail__article code:not([class]) { border-radius: var(--radius-inner, 4px); /* 可以设置一个默认值 */ background: #f5f5f5; /* 稍微偏灰的背景色 */ color: #000000; /* 黑色字体 */ padding: 2px 6px; /* 内边距可以适当增大 */ font-family: "SFMono-Regular", Consolas, "Liberation Mono", Menlo, Courier, monospace; word-break: break-word; font-weight: normal; -webkit-text-size-adjust: 100%; -webkit-font-smoothing: antialiased; white-space: pre-wrap; /* 保持代码换行 */ font-size: 0.875em; margin-inline-start: 0.25em; margin-inline-end: 0.25em; } 大坑: 会显示为勾选框,无法正常进行latex公式解析,因为typecho/usr/themes/Joe/public/short.php中设置了短代码替换,在文章输出前对 $content 中的特定标记或短代码进行搜索和替换,从而实现一系列自定义功能。现已全部注释。 typecho/usr/themes/Joe/assets/js/joe.single.js原版: 显示弹窗,点叉后消失 { document.querySelector('.joe_detail__article').addEventListener('copy', () => { autolog.log(`本文版权属于 ${Joe.options.title} 转载请标明出处!`, 'warn', false); }); } 显示5秒后消失: document.querySelector('.joe_detail__article').addEventListener('copy', () => { // 显示 autolog 消息 autolog.log(`本文版权属于 ${Joe.options.title} 转载请标明出处!`, 'warn', false); // 5 秒后删除该消息 setTimeout(() => { const warnElem = document.querySelector('.autolog-warn'); if (warnElem) { warnElem.remove(); // 或者使用 warnElem.style.display = 'none'; } }, 5000); }); markdown编辑与解析 确保代码块```后面紧跟着语言,如```java,否则无法正确显示。 markdown编辑器插件:https://xiamp.net/archives/aaeditor-is-another-typecho-editor-plugin.html '开启公式解析!' markdown解析器插件:mrgeneralgoo/typecho-markdown: A markdown parse plugin for typecho. 关闭公式解析,仅开启代码解析! slug为页面缩略名,在新增文章时可以传入,默认是index数字。 qBittorrent 【好玩的Docker项目】10分钟搭建你专属的下载神器——qbittorrent-我不是咕咕鸽 docker pull linuxserver/qbittorrent cd ~ mkdir /root/data/docker_data/qBittorrent #创建qbitorrent数据文件夹 cd /root/data/docker_data/qBittorrent mkdir config downloads #创建配置文件目录与下载目录 nano docker-compose.yml #创建并编辑文件 services: qbittorrent: image: linuxserver/qbittorrent container_name: qbittorrent environment: - PUID=1000 - PGID=1000 - TZ=Asia/Shanghai # 你的时区 - UMASK_SET=022 - WEBUI_PORT=8081 # 将此处修改成你欲使用的 WEB 管理平台端口 volumes: - ./config:/config # 绝对路径请修改为自己的config文件夹 - ./downloads:/downloads # 绝对路径请修改为自己的downloads文件夹 ports: # 要使用的映射下载端口与内部下载端口,可保持默认,安装完成后在管理页面仍然可以改成其他端口。 - 6881:6881 - 6881:6881/udp # 此处WEB UI 目标端口与内部端口务必保证相同,见问题1 - 8081:8081 restart: unless-stopped
自学
zy123
3月21日
0
3
0
2025-03-21
git基本操作
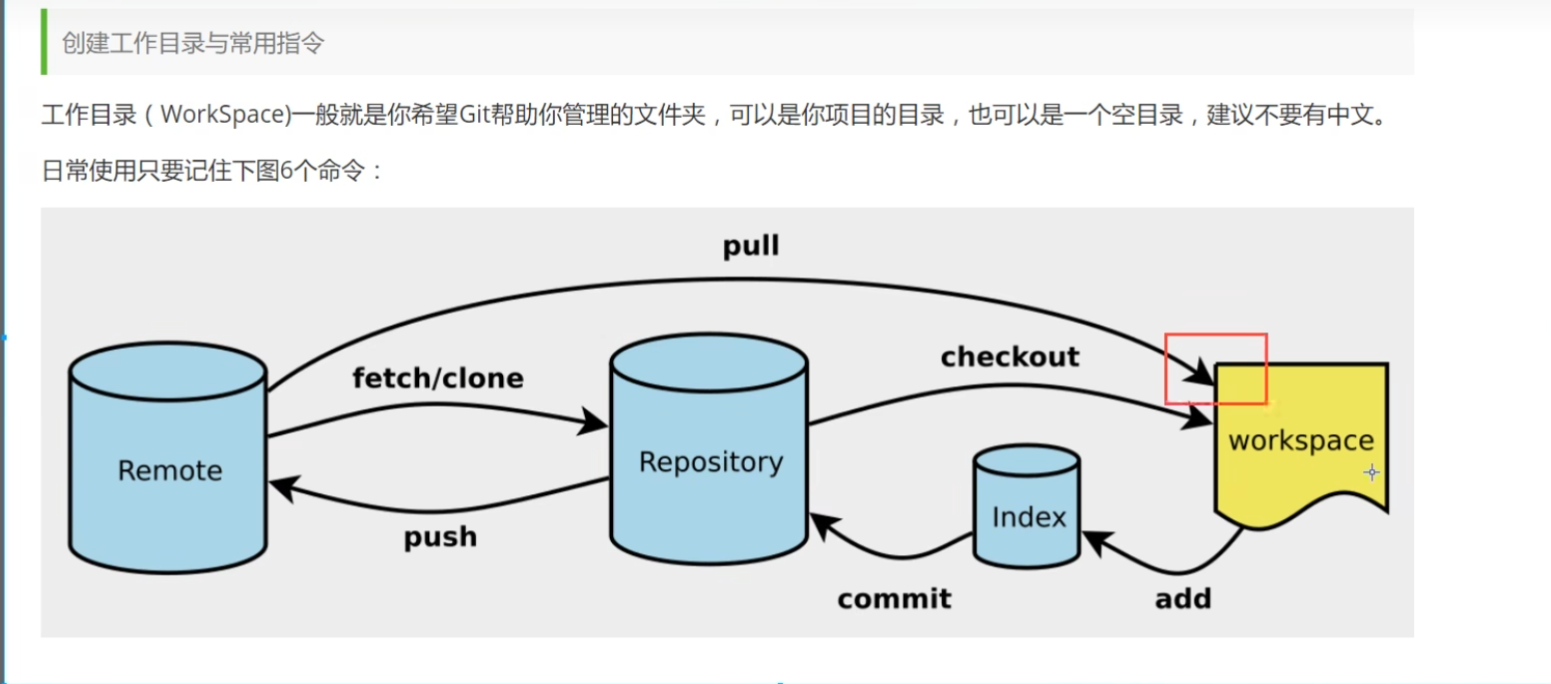
Git linux上安装Git sudo apt update sudo apt install git Git Bash:与linux风格接近,使用最多,推荐 Git CMD:windows风格 Git GUI:图形界面,不推荐 查看配置 git config -l :查看所有配置 git config --global --list 查看用户配置的 git config --system --list :系统配置的 核心原理 index是暂存区 respository 是本地代码仓库,保存着本地的各个版本代码 remote是远程仓库,通常是github/gitee码云 如何克隆别人已有的项目 获取项目地址http 打开本地文件系统,选择你需要保存项目的位置并打开cmd git clone xxx,这个过程可能需要验证身份,输入用户名密码 如何将本地仓库与远程仓库连接?从零开始 法1: 首先在Github上新建一个代码仓库,拷贝地址 eg:https://github.com/zhangww-web/JianShu.git 在你本地文件夹下鼠标右键git bash here git init 新建本地仓库,生成.git隐藏文件,点进去有head文件。 git remote add origin url,可以绑定远程仓库 继续输入git pull origin master(若你远程仓库为空,不需要这一步) git add .(.表示所有的,注意这个‘点’)—将本地文件提交至暂存区 git commit -m '提交信息' git push origin master 法2: 第2种方法比较简单,直接用把远程仓库拉到本地,然后再把自己本地的项目拷贝到仓库中去。然后push到远程仓库上去即可。要求远程仓库为新建的空仓库!!! 在空文件夹中git bash here(不用init!) 首先git clone https://github.com/zhangww-web/JianShu.git 然后复制自己项目的所有文件到刚刚克隆下来的仓库中 git push -u origin master 法3:在android studio中集成 配置Git 关联自己的github 对于任何安卓项目,前两步都是通用的!!! 这里的Remote填远程仓库地址,eg: https://github.com/zhangww-web/JianShu.git IDEA 方法类似,先init本地仓库, 点击顶部菜单栏的 Git -> Manage Remotes。 如果Share project on github一直失败,可以这样: 前面步骤不变,现在去github上新建一个空白仓库,获得一个remote url,然后本地仓库提交到该空白仓库,即可建立链接。 迁移代码仓库 法一(推荐):访问令牌(Access Token)获取:点击右上角头像,选择“Settings”(设置)。 在左侧菜单中找到“Developer settings”(开发者设置),然后点击“Personal access tokens”(个人访问令牌)。点击“Generate new token”(生成新令牌),按照需要选择相应的权限(通常建议勾选 repo、read:org 等,根据你的实际需求)。生成后将令牌复制下来,填入 Gitea 的迁移界面中。 直接推完整git信息,推荐 法二: 本地有完整的代码已经git提交记录,不想丢失,推送到新的远程仓库: 在本地文件夹下git bash here git remote add origin <新仓库地址> git push -u origin --all 注意:只会将你本地仓库已经 checkout 出来的所有分支(即本地存在的分支)推送到新远程仓库中。 Git 常用命令 提交代码 git add--> git commit --> git push git add . 提交所有文件到暂存区,此时git status显示changes to be commited git commit -m "describe描述性内容" 提交到本地仓库 分支操作 git banch -a 可以查看所有分支 git branch dev 可以新建dev分支 git checkout dev 可以切换到dev分支 git branch -d dev 删除dev分支 git branch -m dev cs :将dev分支修改名称为cs分支 push失败问题 首先,科学上网一定能打开github的官网,但是idea中仍然无法push 此时查看你的代理服务器的端口,发现是7890 然后打开git bash,输入以下代码: 使用http代理 git config --global http.proxy http://127.0.0.1:7890 git config --global https.proxy https://127.0.0.1:7890 使用socks5代理 git config --global http.proxy socks5://127.0.0.1:7890 git config --global https.proxy socks5://127.0.0.1:7890 取消代理 git config --global --unset http.proxy git config --global --unset https.proxy 或者使用国产的gitee或者自己服务器上搭建gitea进行代码托管!!! 拉取代码与解决冲突 git pull 命令用于从远程仓库拉取(fetch)并合并(merge)最新的更改到本地仓库。它实际上执行了两个操作: git fetch: 这个操作会从远程仓库下载最新的更改到本地仓库,但不会自动合并到当前分支。它将远程仓库的更改存储在本地仓库中,使你能够查看它们,但不会更改你当前工作目录中的文件。 git merge: 这个操作将远程仓库的更改合并到当前分支。如果有冲突,你需要解决冲突后再次提交合并的结果 情况1:本地修改代码未提交,拉取代码的时候就会报错: 错误:您对下列文件的本地修改将被合并操作覆盖: docker-compose.yaml 请在合并前提交或贮藏您的修改。 正在终止 暂存未提交的更改(git stash) 如果还不想提交本地修改,可以将更改暂存起来: git stash git pull git stash pop git stash 会将当前工作区的改动保存到一个栈中,拉取完成后通过 git stash pop 恢复修改。如果恢复过程中出现冲突,同样需要手动解决。 舍弃本地修改 如果确定不需要这些修改,可以放弃它们: git reset --hard git pull 但是推荐先提交本地的代码!!! git add . git commit -m "描述本次修改的提交信息" git pull 情况2:权限校验问题 一般可以保持git网页端账号的登录状态,再pull,会有弹窗出来输入git的用户名和密码,成功后即可拉取。 情况3 合并冲突,以pycharm为例 1.触发冲突解决界面 当你执行 git pull 后如果出现冲突,PyCharm 会在右下角或版本控制工具窗口中提醒有冲突文件。你可以点击提示信息或在版本控制面板中找到冲突文件。 2.启动合并工具 双击冲突文件后,PyCharm 会自动打开三方合并工具。界面通常分为三部分: 左侧:本地修改(当前分支的更改) 右侧:远程修改(要合并进来的更改) 中间:合并结果(你需要编辑的区域) 3.手动选择并合并代码 在合并工具中,你可以逐个查看冲突部分: 点击左侧或右侧的按钮来选择保留哪部分内容。 如果需要,你也可以手动编辑中间的合并结果区域,直接输入合适的代码。 合并工具通常会有跳转到下一个冲突的按钮,方便你逐个解决。 4.保存合并结果并标记解决 合并完成后,点击工具窗口上的“Apply”或“Accept Merge”按钮,保存你的修改。此时,冲突文件会标记为已解决。 5.提交合并后的更改 返回主界面后,你可以在版本控制面板中看到已解决的文件。检查确认无误后,通过 VCS 菜单或直接点击工具栏中的提交按钮,将合并结果提交到仓库。 其他Git相关 SSH公私钥 公私钥生成 在linux中,使用账号密码链接github报错如下: remote: Support for password authentication was removed on August 13, 2021. remote: Please see https://docs.github.com/get-started/getting-started-with-git/about-remote-repositories#cloning-with-https-urls for information on currently recommended modes of authentication. 致命错误:'https://github.com/zhangww-web/reptile.git/' 鉴权失败 原因是linux不支持账号密码链接!! 配置ssh,可以在git push的时候直接推送,github会通过ssh来验证你的身份。 如何在linux中配置私钥? 生成 SSH 密钥: 如果你还没有 SSH 密钥,可以使用以下命令生成: ssh-keygen -t rsa -b 4096 -C "your_email@example.com" 按照提示保存密钥文件。 添加 SSH 密钥到 GitHub: 复制生成的公钥内容(通常在 ~/.ssh/id_rsa.pub 文件中)。 登录到 GitHub。 进入 SSH and GPG keys 页面。 点击 "New SSH key" 按钮,粘贴公钥内容并保存。 使用 SSH URL 克隆仓库: git clone git@github.com:zhangww-web/reptile.git SSH 连接 GitHub 并触发身份验证,流程如下: GitHub 发送一个随机挑战(Challenge) GitHub 服务器会向你的 Linux 服务器发送一个随机字符串,并用 你的公钥 进行加密。 你的 Linux 服务器用私钥解密 你的 SSH 客户端(ssh 命令或 git)会自动使用本地的 私钥(id_rsa) 进行解密。如果解密成功,证明你拥有匹配的私钥。 返回解密后的数据 你的客户端将解密后的数据返回给 GitHub。 GitHub 验证解密结果 GitHub 服务器检查解密结果是否匹配它最初发送的随机挑战。如果匹配,则认证成功。 身份验证逻辑:GitHub 发送加密数据 → 你的私钥解密 → 返回结果 → GitHub 确认一致性 → 认证成功。 如果避免每次git pull都要验证身份? git config --global credential.helper store //将凭据保存到磁盘上(明文存储): .gitignore(忽略某些文件) 如果不小心commit了如何撤销? 例:如果在添加.gitignore文件前不小心提交了.idea文件夹,到项目根目录,git bash here git rm -r --cached -f .idea git commit -m "Remove .idea from tracking" 在.gitignore文件进行添加 为什么.gitignore文件不放在.git文件夹中? 用途不同:.git文件夹由Git自动创建,用于存储Git的内部数据,包括所有提交记录、配置和对象等。用户一般不需要手动修改这个文件夹里的内容。而.gitignore文件是用户创建和维护的,用于定义哪些文件和目录应被Git忽略。 便于版本控制:.gitignore文件放在项目的根目录中,可以和项目代码一起被版本控制,这样其他协作开发者也能看到和使用相同的忽略规则。如果把.gitignore放在.git文件夹中,它就不会被版本控制系统追踪到。 撤销Git版本控制 直接把项目文件夹中的.git文件夹删除即可(开启查看隐藏文件夹可看到) 若idea/pycharm报错: COVID-19-Detector is registered as a Git root, but no Git repositories were found there. 添加协作者 协作者权限 如果不使用组织的话,你也可以单独为每个仓库添加协作者。这样做的话,公钥仍然应该添加到你的个人设置中,但是你可以在每个仓库的设置中单独管理协作者访问权限。 设置步骤包括: 打开你想要添加协作者的仓库。 导航到仓库设置中的“Manage access”(管理访问)或“Collaborators”(协作者)部分。 添加协作者的GitHub用户名,并设置他们的访问级别。
自学
zy123
3月21日
0
1
0
2025-03-21
JavaWeb——后端
JavaWeb——后端 Java版本解决方案 单个Java文件运行: Edit Configurations 针对单个运行配置:每个 Java 运行配置(如主类、测试类等)可以独立设置其运行环境(如 JRE 版本、程序参数、环境变量等)。 不影响全局项目:修改某个运行配置的环境不会影响其他运行配置或项目的全局设置。 如何调整全局项目的环境 打开 File -> Project Structure -> Project。 在 Project SDK 中选择全局的 JDK 版本(如 JDK 17)。 在 Project language level 中设置全局的语言级别(如 17)。 Java Compiler File -> Settings -> Build, Execution, Deployment -> Compiler -> Java Compiler Maven Runner File -> Settings -> Build, Execution, Deployment -> Build Tools -> Maven -> Runner 三者之间的关系 全局项目环境 是基准,决定项目的默认 JDK 和语言级别。 Java Compiler 控制编译行为,可以覆盖全局的 Project language level。 Maven Runner 控制 Maven 命令的运行环境,可以覆盖全局的 Project SDK。 Maven 项目: 确保 pom.xml 中的 <maven.compiler.source> 和 <maven.compiler.target> 与 Project SDK 和 Java Compiler 的配置一致。 确保 Maven Runner 中的 JRE 与 Project SDK 一致。 如果还是不行,pom文件右键点击maven->reload project HTTP协议 响应状态码 状态码分类 说明 1xx 响应中 --- 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 2xx 成功 --- 表示请求已经被成功接收,处理已完成 3xx 重定向 --- 重定向到其它地方,让客户端再发起一个请求以完成整个处理 4xx 客户端错误 --- 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 5xx 服务器端错误 --- 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 状态码 英文描述 解释 200 OK 客户端请求成功,即处理成功,这是我们最想看到的状态码 302 Found 指示所请求的资源已移动到由Location响应头给定的 URL,浏览器会自动重新访问到这个页面 304 Not Modified 告诉客户端,你请求的资源至上次取得后,服务端并未更改,你直接用你本地缓存吧。隐式重定向 400 Bad Request 客户端请求有语法错误,不能被服务器所理解 403 Forbidden 服务器收到请求,但是拒绝提供服务,比如:没有权限访问相关资源 404 Not Found 请求资源不存在,一般是URL输入有误,或者网站资源被删除了 405 Method Not Allowed 请求方式有误,比如应该用GET请求方式的资源,用了POST 429 Too Many Requests 指示用户在给定时间内发送了太多请求(“限速”),配合 Retry-After(多长时间后可以请求)响应头一起使用 500 Internal Server Error 服务器发生不可预期的错误。服务器出异常了,赶紧看日志去吧 503 Service Unavailable 服务器尚未准备好处理请求,服务器刚刚启动,还未初始化好 开发规范 REST风格 在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。 什么是REST风格呢? REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。 传统URL风格如下: http://localhost:8080/user/getById?id=1 GET:查询id为1的用户 http://localhost:8080/user/saveUser POST:新增用户 http://localhost:8080/user/updateUser PUT:修改用户 http://localhost:8080/user/deleteUser?id=1 DELETE:删除id为1的用户 我们看到,原始的传统URL,定义比较复杂,而且将资源的访问行为对外暴露出来了。 基于REST风格URL如下: http://localhost:8080/users/1 GET:查询id为1的用户 http://localhost:8080/users POST:新增用户 http://localhost:8080/users PUT:修改用户 http://localhost:8080/users/1 DELETE:删除id为1的用户 其中总结起来,就一句话:通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。 REST风格后端代码: @RestController @RequestMapping("/depts") //定义当前控制器的请求前缀 public class DeptController { // GET: 查询资源 @GetMapping("/{id}") public Dept getDept(@PathVariable Long id) { ... } // POST: 新增资源 @PostMapping public void createDept(@RequestBody Dept dept) { ... } // PUT: 更新资源 @PutMapping public void updateDept(@RequestBody Dept dept) { ... } // DELETE: 删除资源 @DeleteMapping("/{id}") public void deleteDept(@PathVariable Long id) { ... } } GET:查询,用 URL 传参,不能带 body。 POST:创建/提交,可以用 body 传数据(JSON、表单)。 PUT:更新,可以用 body 。 DELETE:删除,一般无 body,只要 -X DELETE。 开发流程 查看页面原型明确需求 根据页面原型和需求,进行表结构设计、编写接口文档(已提供) 阅读接口文档 思路分析 功能接口开发 就是开发后台的业务功能,一个业务功能,我们称为一个接口(Controller 中一个完整的处理请求的方法) 功能接口测试 功能开发完毕后,先通过Postman进行功能接口测试,测试通过后,再和前端进行联调测试 前后端联调测试 和前端开发人员开发好的前端工程一起测试 SpringBoot Servlet 容器 是用于管理和运行 Web 应用的环境,它负责加载、实例化和管理 Servlet 组件,处理 HTTP 请求并将请求分发给对应的 Servlet。常见的 Servlet 容器包括 Tomcat、Jetty、Undertow 等。 SpringBoot的WEB默认内嵌了tomcat服务器,非常方便!!! 浏览器与 Tomcat 之间通过 HTTP 协议进行通信,而 Tomcat 则充当了中间的桥梁,将请求路由到你的 Java 代码,并最终将处理结果返回给浏览器。 查看springboot版本:查看pom文件 <parent> <artifactId>spring-boot-starter-parent</artifactId> <groupId>org.springframework.boot</groupId> <version>2.7.3</version> </parent> 版本为2.7.3 快速启动 新建spring initializr project 删除以下文件 新建HelloController类 package edu.whut.controller; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class HelloController { @RequestMapping("/hello") public String hello(){ System.out.println("hello"); return "hello"; } } 然后启动服务器,main程序 package edu.whut; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class SprintbootQuickstartApplication { public static void main(String[] args) { SpringApplication.run(SprintbootQuickstartApplication.class, args); } } 然后浏览器访问 localhost:8080/hello。 SpringBoot请求 简单参数 在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。 @RestController public class RequestController { // http://localhost:8080/simpleParam?name=Tom&age=10 // 第1个请求参数: name=Tom 参数名:name,参数值:Tom // 第2个请求参数: age=10 参数名:age , 参数值:10 //springboot方式 @RequestMapping("/simpleParam") public String simpleParam(String name , Integer age ){//形参名和请求参数名保持一致 System.out.println(name+" : "+age); return "OK"; } } 如果方法形参名称与请求参数名称不一致,controller方法中的形参还能接收到请求参数值吗? 解决方案:可以使用Spring提供的@RequestParam注解完成映射 在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。代码如下: @RestController public class RequestController { // http://localhost:8080/simpleParam?name=Tom&age=20 // 请求参数名:name //springboot方式 @RequestMapping("/simpleParam") public String simpleParam(@RequestParam("name") String username , Integer age ){ System.out.println(username+" : "+age); return "OK"; } } 实体参数 复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下: User类中有一个Address类型的属性(Address是一个实体类) 复杂实体对象的封装,需要遵守如下规则: 请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。 注意:这里User前面不能加@RequestBody是因为请求方式是 Query 或 路径 参数;如果是JSON请求体(Body)就必须加。 @RequestMapping("/complexpojo") public String complexpojo(User user){ System.out.println(user); return "OK"; } @Data @NoArgsConstructor @AllArgsConstructor public class User { private String name; private Integer age; private Address address; } @Data @NoArgsConstructor @AllArgsConstructor public class Address { private String province; private String city; } 数组参数 数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数 @RestController public class RequestController { //数组集合参数 @RequestMapping("/arrayParam") public String arrayParam(String[] hobby){ System.out.println(Arrays.toString(hobby)); return "OK"; } } 路径参数 请求的URL中传递的参数 称为路径参数。例如: http://localhost:8080/user/1 http://localhost:880/user/1/0 注意,路径参数使用大括号 {} 定义 @RestController public class RequestController { //路径参数 @RequestMapping("/path/{id}/{name}") public String pathParam2(@PathVariable Integer id, @PathVariable String name){ System.out.println(id+ " : " +name); return "OK"; } } 在路由定义里用 {id} 只是一个占位符,实际请求时 不要 带大括号 JSON格式参数 { "backtime": [ "与中标人签订合同后 5日内", "投标截止时间前撤回投标文件并书面通知招标人的,2日内", "开标现场投标文件被拒收,开标结束后,2日内" ], "employees": [ { "firstName": "John", "lastName": "Doe" }, { "firstName": "Anna", "lastName": "Smith" }, { "firstName": "Peter", "lastName": "Jones" } ] } JSON 格式的核心特征 接口文档中的请求参数中是 'Body' 发送数据 数据为键值对:数据存储在键值对中,键和值用冒号分隔。在你的示例中,每个对象有两个键值对,如 "firstName": "John"。 使用大括号表示对象:JSON 使用大括号 {} 包围对象,对象可以包含多个键值对。 使用方括号表示数组:JSON 使用方括号 [] 表示数组,数组中可以包含多个值,包括数字、字符串、对象等。在该示例中:"employees" 是一个对象数组,数组中的每个元素都是一个对象。 Postman如何发送JSON格式数据: 服务端Controller方法如何接收JSON格式数据: 传递json格式的参数,在Controller中会使用实体类进行封装。 封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。 @Data @NoArgsConstructor @AllArgsConstructor public class DataDTO { private List<String> backtime; private List<Employee> employees; } @Data @NoArgsConstructor @AllArgsConstructor public class Employee { private String firstName; private String lastName; } @RestController public class DataController { @PostMapping("/data") public String receiveData(@RequestBody DataDTO data) { System.out.println("Backtime: " + data.getBacktime()); System.out.println("Employees: " + data.getEmployees()); return "OK"; } } JSON格式工具包 用于高效地进行 JSON 与 Java 对象之间的序列化和反序列化操作。 引入依赖: <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.76</version> </dependency> 使用: import com.alibaba.fastjson.JSON; public class FastJsonDemo { public static void main(String[] args) { // 创建一个对象 User user = new User("Alice", 30); // 对象转 JSON 字符串 String jsonString = JSON.toJSONString(user); System.out.println("JSON String: " + jsonString); // JSON 字符串转对象 User parsedUser = JSON.parseObject(jsonString, User.class); System.out.println("Parsed User: " + parsedUser); } } // JSON String: {"age":30,"name":"Alice"} // Parsed User: User(name=Alice, age=30) SpringBoot响应 @ResponseBody注解: 位置:书写在Controller方法上或类上 作用:将方法返回值直接响应给浏览器 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器 @RestController = @Controller + @ResponseBody 统一响应结果: 下图返回值分别是字符串、对象、集合。 定义统一返回结果类 响应状态码:当前请求是成功,还是失败 状态码信息:给页面的提示信息 返回的数据:给前端响应的数据(字符串、对象、集合) 定义在一个实体类Result来包含以上信息。代码如下: @Data @NoArgsConstructor @AllArgsConstructor public class Result { private Integer code;//响应码,1 代表成功; 0 代表失败 private String msg; //响应信息 描述字符串 private Object data; //返回的数据 //增删改 成功响应 public static Result success(){ return new Result(1,"success",null); } //查询 成功响应 public static Result success(Object data){ return new Result(1,"success",data); } //失败响应 public static Result error(String msg){ return new Result(0,msg,null); } } Spring分层架构 三层架构 Controller层接收请求,调用Service层;Service层先调用Dao层获取数据,然后实现自己的业务逻辑处理部分,最后返回给Controller层;Controller层再响应数据。可理解为递归的过程。 传统模式:对象的创建、管理和依赖关系都由程序员手动编写代码完成,程序内部控制对象的生命周期。 例如: public class A { private B b; public A() { b = new B(); // A 自己创建并管理 B 的实例 } } 假设有类 A 依赖类 B,在传统方式中,类 A 可能在构造方法或方法内部直接调用 new B() 来创建 B 的实例。 如果 B 的创建方式发生变化,A 也需要修改代码。这就导致了耦合度较高。 软件设计原则:高内聚低耦合。 高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。 低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。 IOC&DI 分层解耦 外部容器(例如 Spring 容器)是一个负责管理对象创建、配置和生命周期的软件系统。 它扫描项目中的类,根据预先配置或注解,将这些类实例化为 Bean。 它维护各个 Bean 之间的依赖关系,并在创建 Bean 时把它们所需的依赖“注入”进去。 依赖注入(DI):类 A 不再自己创建 B,而是声明自己需要一个 B,容器在创建 A 时会自动将 B 的实例提供给 A。 public class A { private B b; // 通过构造器注入依赖 public A(B b) { this.b = b; } } Bean 对象:在 Spring 中,被容器管理的对象称为 Bean。通过注解(如 @Component, @Service, @Repository, @Controller),可以将一个普通的 Java 类声明为 Bean,容器会负责它的创建、初始化以及生命周期管理。 任务:完成Controller层、Service层、Dao层的代码解耦 思路: 删除Controller层、Service层中new对象的代码 Service层及Dao层的实现类,交给IOC容器管理 为Controller及Service注入运行时依赖的对象 Controller程序中注入依赖的Service层对象 Service程序中注入依赖的Dao层对象 第1步:删除Controller层、Service层中new对象的代码 第2步:Service层及Dao层的实现类,交给IOC容器管理 使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理 第3步:为Controller及Service注入运行时依赖的对象 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象 **如果我有多个实现类,eg:EmpServiceA、EmpServiceB,我该如何切换呢?**两种方法 只需在需要使用的实现类上加@Component,注释掉不需要用到的类上的@Component。可以把@Component想象成装入盒子,@Autowired想象成拿出来,因此只需改变放入的物品,而不需改变拿出来的这个动作。 // 只启用 EmpServiceA,其他实现类的 @Component 注解被注释或移除 @Component public class EmpServiceA implements EmpService { // 实现细节... } // EmpServiceB 没有被 Spring 管理 // @Component // public class EmpServiceB implements EmpService { ... } 在@Component上面加上@Primary,表明该类优先生效 // 默认使用 EmpServiceB,其他实现类也在容器中,但未标记为 Primary @Component public class EmpServiceA implements EmpService { // 实现细节... } @Component @Primary // 默认优先注入 public class EmpServiceB implements EmpService { // 实现细节... } Component衍生注解 注解 说明 位置 @Controller @Component的衍生注解 标注在控制器类上Controller @Service @Component的衍生注解 标注在业务类上Service @Repository @Component的衍生注解 标注在数据访问类上(由于与mybatis整合,用的少)DAO @Component 声明bean的基础注解 不属于以上三类时,用此注解 注:@Mapper 注解本身并不是 Spring 框架提供的,是用于 MyBatis 数据层的接口标识,但效果类似。 SpringBoot原理 容器启动 在 Spring 框架中,“容器启动”指的是 ApplicationContext 初始化过程,主要包括配置解析、加载 Bean 定义、实例化和初始化 Bean 以及完成依赖注入。具体来说,容器启动的时机包括以下几个关键点: 当你启动一个 Spring 应用时,无论是通过直接运行一个包含 main 方法的类,还是部署到一个 Servlet 容器中,Spring 的应用上下文都会被创建和初始化。这个过程包括: 读取配置:加载配置文件或注解中指定的信息,确定哪些组件由 Spring 管理。 注册 Bean 定义:将所有扫描到的 Bean 定义注册到容器中。 实例化 Bean:根据 Bean 定义创建实例。默认情况下,所有单例 Bean在启动时被创建(除非配置为懒加载)。 依赖注入:解析 Bean 之间的依赖关系,并自动注入相应的依赖。 配置文件 配置优先级 在SpringBoot项目当中,常见的属性配置方式有5种, 3种配置文件,加上2种外部属性的配置(Java系统属性、命令行参数)。优先级(从低到高): application.yaml(忽略) application.yml application.properties java系统属性(-Dxxx=xxx) 命令行参数(--xxx=xxx) 在 Spring Boot 项目中,通常使用的是 application.yml 或 application.properties 文件,这些文件通常放在项目的 src/main/resources 目录下。 如果项目已经打包上线了,这个时候我们又如何来设置Java系统属性和命令行参数呢? java -Dserver.port=9000 -jar XXXXX.jar --server.port=10010 在这个例子中,由于命令行参数的优先级高于 Java 系统属性,最终生效的 server.port 是 10010。 properties 位置:src/main/resources/application.properties 将配置信息写在application.properties,用注解@Value获取配置文件中的数据 @Value("${aliyun.oss.endpoint}") yml配置文件(推荐!!!) 位置:src/main/resources/application.yml 了解下yml配置文件的基本语法: 大小写敏感 数据前边必须有空格,作为分隔符 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格) 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可 #表示注释,从这个字符一直到行尾,都会被解析器忽略 对象/map集合 user: name: zhangsan detail: age: 18 password: "123456" 数组/List/Set集合 hobby: - java - game - sport //获取示例 @Value("${hobby}") private List<String> hobby; 以上获取配置文件中的属性值,需要通过@Value注解,有时过于繁琐!!! @ConfigurationProperties 是用来将外部配置(如 application.properties / application.yml)映射到一个 POJO 上的。 在 Spring Boot 中,根据 驼峰命名转换规则,自动将 YAML 配置文件中的 键名(例如 user-token-name user_token_name)映射到 Java 类中的属性(例如 userTokenName)。 @Data @Component @ConfigurationProperties(prefix = "aliyun.oss") public class AliOssProperties { private String endpoint; private String accessKeyId; private String accessKeySecret; private String bucketName; } Spring提供的简化方式套路: 需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致 比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法 ==》@Data 需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象 ==>@Component 在实体类上添加@ConfigurationProperties注解,并通过perfix属性来指定配置参数项的前缀 (可选)引入依赖pom.xml (自动生成配置元数据,让 IDE 能识别并补全你在 application.properties/yml 中的自定义配置项,提高开发体验) <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> </dependency> Bean 的获取和管理 获取Bean 1.自动装配(@Autowired) @Service public class MyService { @Autowired private MyRepository myRepository; // 自动注入 MyRepository Bean } 2.手动获取(ApplicationContext) @Autowired 自动将 Spring 创建的 ApplicationContext 注入到 applicationContext 字段中, 再通过 applicationContext.getBean(...) 拿到其他 Bean Spring 会默认采用类名并将首字母小写作为 Bean 的名称。例如,类名为 DeptController 的组件默认名称就是 deptController。 @RunWith(SpringRunner.class) @SpringBootTest public class SpringbootWebConfig2ApplicationTests { @Autowired private ApplicationContext applicationContext; // IoC 容器 @Test public void testGetBean() { // 根据 Bean 名称获取 DeptController bean = (DeptController) applicationContext.getBean("deptController"); System.out.println(bean); } } 默认情况下,Spring 在容器启动时会创建所有单例 Bean(饿汉模式);使用 @Lazy 注解则可实现延迟加载(懒汉模式) bean的作用域 作用域 说明 singleton 容器内同名称的bean只有一个实例(单例)(默认) prototype 每次使用该bean时会创建新的实例(非单例) 在设计单例类时,通常要求它们是无状态的,不仅要确保成员变量不可变,还需要确保成员方法不会对共享的、可变的状态进行不受控制的修改,从而实现整体的线程安全。 @Service public class CalculationService { // 不可变的成员变量 private final double factor = 2.0; // 成员方法仅依赖方法参数和不可变成员变量 public double multiply(double value) { return value * factor; } } 更改作用域方法: 在bean类上加注解@Scope("prototype")(或其他作用域标识)即可。 第三方 Bean配置 如果要管理的bean对象来自于第三方(不是自定义的),是无法用@Component 及衍生注解声明bean的,就需要用到**@Bean**注解。 如果需要定义第三方Bean时, 通常会单独定义一个配置类 @Configuration // 配置类 public class CommonConfig { // 定义第三方 Bean,并交给 IoC 容器管理 @Bean // 返回值默认作为 Bean,Bean 名称默认为方法名 public SAXReader reader(DeptService deptService) { System.out.println(deptService); return new SAXReader(); } } 在应用启动时,Spring 会调用配置类中标注 @Bean 的方法,将方法返回值注册为容器中的 Bean 对象。 默认情况下,该 Bean 的名称就是该方法的名字。本例 Bean 名称默认就是 "reader"。 使用: @Service public class XmlProcessingService { // 按类型注入 @Autowired private SAXReader reader; //方法的名字!! public void parse(String xmlPath) throws DocumentException { Document doc = reader.read(new File(xmlPath)); // ... 处理 Document ... } } SpirngBoot原理 如果我们直接基于Spring框架进行项目的开发,会比较繁琐。SpringBoot框架之所以使用起来更简单更快捷,是因为SpringBoot框架底层提供了两个非常重要的功能:一个是起步依赖,一个是自动配置。 起步依赖 Spring Boot 只需要引入一个起步依赖(例如 springboot-starter-web)就能满足项目开发需求。这是因为: Maven 依赖传递: 起步依赖内部已经包含了开发所需的常见依赖(如 JSON 解析、Web、WebMVC、Tomcat 等),无需开发者手动引入其它依赖。 结论: 起步依赖的核心原理就是 Maven 的依赖传递机制。 自动配置 Spring Boot 会自动扫描启动类所在包及其子包中的所有带有组件注解(如 @Component, @Service, @Repository, @Controller, @Mapper 等)的类并加载到IOC容器中。 自动配置原理源码入口就是@SpringBootApplication注解,在这个注解中封装了3个注解,分别是: @SpringBootConfiguration 声明当前类是一个配置类,等价于 @Configuration又与之区分 @ComponentScan 进行组件扫描。如果你的项目有server pojo common模块,启动类在com.your.package.server下,那么只会默认扫描com.your.package及其子包。 @ComponentScan({"com.your.package.server", "com.your.package.common"})可以显示指定扫描的包路径。 @EnableAutoConfiguration(自动配置核心注解,下节详解) 自动配置的效果: 在IOC容器中除了我们自己定义的bean以外,还有很多配置类,这些配置类都是SpringBoot在启动的时候加载进来的配置类。这些配置类加载进来之后,它也会生成很多的bean对象。 当我们想要使用这些配置类中生成的bean对象时,可以使用@Autowired就自动注入了。 如何让第三方bean以及配置类生效? 如果配置类(如 CommonConfig)不在 Spring Boot 启动类的扫描路径内(即不在启动类所在包或其子包下): 1.@ComponentScan添加包扫描路径,适合批量导入(繁琐、性能低) 2.通过 @Import 手动导入该配置类。适合精确导入,如: com └── example └── SpringBootApplication.java // 启动类 src └── com └── config └── CommonConfig.java // 配置类 借助 @Import 注解,我们可以将外部的普通类、配置类或实现了 ImportSelector 的类显式导入到 Spring 容器中。 也就是这些类会加载到IOC容器中。 1.使用@Import导入普通类: 如果某个普通类(如 TokenParser)没有 @Component 注解标识,也可以通过 @Import 导入它,使其成为 Spring 管理的 Bean。 // TokenParser 类没有 @Component 注解 public class TokenParser { public void parse(){ System.out.println("TokenParser ... parse ..."); } } 在启动类上使用 @Import 导入: @Import(TokenParser.class) //导入的类会被Spring加载到IOC容器中 @SpringBootApplication public class SpringbootWebConfig2Application { public static void main(String[] args) { SpringApplication.run(SpringbootWebConfig2Application.class, args); } } 2.使用@Import导入配置类: 配置类中可以定义多个 Bean,通过 @Configuration 和 @Bean 注解实现集中管理。 @Configuration public class HeaderConfig { @Bean public HeaderParser headerParser(){ return new HeaderParser(); } @Bean public HeaderGenerator headerGenerator(){ return new HeaderGenerator(); } } 启动类导入配置类: @Import(HeaderConfig.class) //导入配置类 @SpringBootApplication public class SpringbootWebConfig2Application { public static void main(String[] args) { SpringApplication.run(SpringbootWebConfig2Application.class, args); } } 3.使用第三方依赖@EnableXxxx 注解 如果第三方依赖没有提供自动配置支持, 常见方案是第三方依赖提供一个 @EnableXxxx 注解,这个注解内部封装了 @Import,通过它可以一次性导入多个配置或 Bean。 @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) @Import(MyImportSelector.class)//指定要导入哪些bean对象或配置类 public @interface EnableHeaderConfig { } 在应用启动类上添加第三方依赖提供的 @EnableHeaderConfig 注解,即可导入相关的配置和 Bean。 @EnableHeaderConfig //使用第三方依赖提供的Enable开头的注解 @SpringBootApplication public class SpringbootWebConfig2Application { public static void main(String[] args) { SpringApplication.run(SpringbootWebConfig2Application.class, args); } } 推荐第三种方式! @EnableAutoConfiguration 导入自动配置类 通过元注解 @Import(AutoConfigurationImportSelector.class),在启动时读取所有 JAR 包中 META‑INF/spring.factories 下 EnableAutoConfiguration 对应的自动配置类列表。 将这些配置类当作 @Configuration 导入到 Spring 容器中。 按条件注册 Bean 自动配置类内部使用多种条件注解(如 @ConditionalOnClass、@ConditionalOnMissingBean、@ConditionalOnProperty 等)。 Spring Boot 会检查当前类路径、配置属性和已有 Bean,仅在满足所有条件时,才执行对应的 @Bean 方法,将组件注入 IOC 容器。 @ComponentScan 用于发现和加载应用自身的组件; @EnableAutoConfiguration 则负责加载 Spring Boot 提供的“开箱即用”配置。如: DataSourceAutoConfiguration 检测到常见的 JDBC 驱动(如 HikariCP、Tomcat JDBC)和配置属性(spring.datasource.*)时,自动创建并配置 DataSource。、 WebMvcAutoConfiguration自动配置 Spring MVC 的核心组件,并启用默认的静态资源映射、消息转换器(Jackson JSON)等。但遇到用户自定义的 MVC 支持配置(如继承 WebMvcConfigurationSupport )时会“失效”(Back Off)因为其内部有个注解:@ConditionalOnMissingBean(WebMvcConfigurationSupport.class),一旦容器内有xx类型注解,默认配置自动失效。 常见的注解!! @RequestMapping("/jsonParam"):可以用于控制器级别,也可以用于方法级别。 用于方法:HTTP 请求路径为 /jsonParam 的请求将调用该方法。 @RequestMapping("/jsonParam") public String jsonParam(@RequestBody User user){ System.out.println(user); return "OK"; } 用于控制器: 所有方法的映射路径都会以这个前缀开始。 @RestController @RequestMapping("/depts") public class DeptController { @GetMapping("/{id}") public Dept getDept(@PathVariable Long id) { // 实现获取部门逻辑 } @PostMapping public void createDept(@RequestBody Dept dept) { // 实现新增部门逻辑 } } @RequestBody:这是一个方法参数级别的注解,用于告诉Spring框架将请求体的内容解析为指定的Java对象。 @RestController:这是一个类级别的注解,它告诉Spring框架这个类是一个控制器(Controller),并且处理HTTP请求并返回响应数据。与 @Controller 注解相比,@RestController 注解还会自动将控制器方法返回的数据转换为 JSON 格式,并写入到HTTP响应中,得益于@ResponseBody 。 @RestController = @Controller + @ResponseBody @PathVariable 注解用于将路径参数 {id} 的值绑定到方法的参数 id 上。当请求的路径是 "/path/123" 时,@PathVariable 会将路径中的 "123" 值绑定到方法的参数 id 上。 public String pathParam(@PathVariable Integer id) { System.out.println(id); return "OK"; } //参数名与路径名不同 @GetMapping("/{id}") public ResponseEntity<User> getUserById(@PathVariable("id") Long userId) { } @RequestParam,如果方法的参数名与请求参数名不同,需要在 @RequestParam 注解中指定请求参数的名字。 类似@PathVariable,可以指定参数名称。 @RequestMapping("/example") public String exampleMethod(@RequestParam String name, @RequestParam("age") int userAge) { // 在方法内部使用获取到的参数值进行处理 System.out.println("Name: " + name); System.out.println("Age: " + userAge); return "OK"; } 还可以设置默认值 @RequestMapping("/greet") public String greet(@RequestParam(defaultValue = "Guest") String name) { return "Hello, " + name; } 如果既改请求参数名字,又要设置默认值 @RequestMapping("/greet") public String greet(@RequestParam(value = "age", defaultValue = "25") int userAge) { return "Age: " + userAge; } 控制反转与依赖注入: @Component、@Service、@Repository 用于标识 bean 并让容器管理它们,从而实现 IoC。 @Autowired、@Configuration、@Bean 用于实现 DI,通过容器自动装配或配置 bean 的依赖。 数据库相关。 @Mapper注解:表示是mybatis中的Mapper接口,程序运行时,框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理 @Select注解:代表的就是select查询,用于书写select查询语句 @SpringBootTest:它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如自动装配、依赖注入、配置加载等。 lombok的相关注解。非常实用的工具库。 在pom.xml文件中引入依赖 <!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> 在实体类上添加以下注解(加粗为常用) 注解 作用 @Getter/@Setter 为所有的属性提供get/set方法 @ToString 会给类自动生成易阅读的 toString 方法 @EqualsAndHashCode 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 @Data 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) @NoArgsConstructor 为实体类生成无参的构造器方法 @AllArgsConstructor 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 @Slf4j 可以log.info("输出日志信息"); //equals 方法用于比较两个对象的内容是否相同 Address addr1 = new Address("SomeProvince", "SomeCity"); Address addr2 = new Address("SomeProvince", "SomeCity"); System.out.println(addr1.equals(addr2)); // 输出 true log: log.info("应用启动成功"); Long empId = 12L; log.info("当前员工id:{}", empId); //带占位符,推荐! log.info("当前员工id:" + empId); //不错,但不推荐 log.info("当前员工id:", empId); //错误的! @Test,Junit测试单元,可在测试类中定义测试函数,一次性执行所有@Test注解下的函数,不用写main方法 @Override,当一个方法在子类中覆盖(重写)了父类中的同名方法时,为了确保正确性,可以使用 @Override 注解来标记这个方法,这样编译器就能够帮助检查是否正确地重写了父类的方法。 @DateTimeFormat将日期转化为指定的格式。Spring会尝试将接收到的字符串参数转换为控制器方法参数的相应类型。 @RestController public class DateController { // 例如:请求 URL 为 /search?begin=2025-03-28 @GetMapping("/search") public String search(@RequestParam("begin") @DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin) { // 此时 begin 已经是 LocalDate 类型,可以直接使用 return "接收到的日期是: " + begin; } } @RestControllerAdvice= @ControllerAdvice + @ResponseBody。加上这个注解就代表我们定义了一个全局异常处理器,而且处理异常的方法返回值会转换为json后再响应给前端 @RestControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(Exception.class) @ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR) public String handleException(Exception ex) { // 返回错误提示或错误详情 return "系统发生异常:" + ex.getMessage(); } } @Configuration和@Bean配合使用,可以对第三方bean进行集中的配置管理,依赖注入!!@Bean用于方法上。加了@Configuration,当Spring Boot应用启动时,它会执行一系列的自动配置步骤。 @ComponentScan指定了Spring应该在哪些包下搜索带有@Component、@Service、@Repository、@Controller等注解的类,以便将这些类自动注册为Spring容器管理的Bean.@SpringBootApplication它是一个便利的注解,组合了@Configuration、@EnableAutoConfiguration和@ComponentScan注解。 登录校验 会话技术 会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。比如:1、2、3这三个请求都是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web服务器关了,那么所有的会话就都结束了。 会话跟踪技术有三种: Cookie(客户端会话跟踪技术) Session(服务端会话跟踪技术) 令牌技术 Cookie 原理:会话数据存储在客户端浏览器中,通过浏览器自动管理。 优点:HTTP协议中支持的技术(像Set-Cookie 响应头的解析以及 Cookie 请求头数据的携带,都是浏览器自动进行的,是无需我们手动操作的) 缺点: 移动端APP(Android、IOS)中无法使用Cookie 不安全,用户可以自己禁用Cookie Cookie不能跨域传递 Session 原理:服务端存储会话数据(如内存、Redis),客户端只保存会话 ID。 Session 底层是基于Cookie实现的会话跟踪,因此Cookie的缺点他也有。 优点:Session是存储在服务端的,安全。会话数据存在客户端有篡改的风险。 缺点: 在分布式服务器集群环境下,Session 无法自动共享 如果客户端禁用 Cookie,Session 会失效。 需要在服务器端存储会话信息,可能带来性能压力,尤其是在高并发环境下。 流程解析 1.当用户登录时,客户端(浏览器)向服务器发送请求(如用户名和密码)。 服务器验证用户身份,如果身份验证成功,服务器会生成一个 唯一标识符(例如 userId 或 authToken),并将其存储在 Cookie 中。服务器会通过 Set-Cookie HTTP 响应头将这个信息发送到浏览器:如: Set-Cookie: userId=12345; Path=/; HttpOnly; Secure; Max-Age=3600; userId=12345 是服务器返回的标识符。 Path=/ 表示此 Cookie 对整个网站有效。 HttpOnly 限制客户端 JavaScript 访问该 Cookie,提高安全性。 Secure 指示该 Cookie 仅通过 HTTPS 协议传输。 Max-Age=3600 设置 Cookie 的有效期为一小时。 2.浏览器存储 Cookie: 浏览器收到 Set-Cookie 响应头后,会自动将 userId 存储在客户端的 Cookie 中。 userId 会在 本地存储,并在浏览器的后续请求中自动携带。 3.后续请求发送 Cookie 当浏览器再次向服务器发送请求时,它会自动在 HTTP 请求头中附带之前存储的 Cookie。 4.服务器识别用户 服务器通过读取请求中的 Cookie,获取 userId(或其他标识符),然后可以从数据库或缓存中获取对应的用户信息。 令牌(推荐) 优点: 支持PC端、移动端 解决集群环境下的认证问题 减轻服务器的存储压力(无需在服务器端存储) 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验) 跨域问题 跨域问题指的是在浏览器中,一个网页试图去访问另一个域下的资源时,浏览器出于安全考虑,默认会阻止这种操作。这是浏览器的同源策略(Same-Origin Policy)导致的行为。 同源策略(Same-Origin Policy) 同源策略是浏览器的一种安全机制,它要求: 协议(如 http、https) 域名/IP(如 example.com) 端口(如 80 或 443) 这三者必须完全相同,才能被视为同源。 举例: http://192.168.150.200/login.html ----------> https://192.168.150.200/login [协议不同,跨域] http://192.168.150.200/login.html ----------> http://192.168.150.100/login [IP不同,跨域] http://192.168.150.200/login.html ----------> http://192.168.150.200:8080/login [端口不同,跨域] http://192.168.150.200/login.html ----------> http://192.168.150.200/login [不跨域] 解决跨域问题的方法: CORS(Cross-Origin Resource Sharing)是解决跨域问题的标准机制。它允许服务器在响应头中加上特定的 CORS 头部信息,明确表示允许哪些外域访问其资源。 服务器端配置:服务器返回带有 Access-Control-Allow-Origin 头部的响应,告诉浏览器允许哪些域访问资源。 Access-Control-Allow-Origin: *(表示允许所有域访问) Access-Control-Allow-Origin: http://site1.com(表示只允许 http://site1.com 访问) 全局统一配置 import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.CorsRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; @Configuration public class WebCorsConfig implements WebMvcConfigurer { @Override public void addCorsMappings(CorsRegistry registry) { registry.addMapping("/api/**") // 匹配所有 /api/** 路径 .allowedOrigins("http://allowed-domain.com") // 允许的域名 .allowedMethods("GET","POST","PUT","DELETE","OPTIONS") .allowedHeaders("Content-Type","Authorization") .allowCredentials(true) // 是否允许携带 Cookie .maxAge(3600); // 预检请求缓存 1 小时 } } Nginx解决方案 统一域名入口: 前端和 API 均通过 Nginx 以相同的域名(例如 https://example.com)提供服务。前端发送 AJAX 请求时,目标也是该域名的地址,如 https://example.com/api,从而避免了跨域校验。 Nginx 作为中间代理: Nginx 将特定路径(例如 /api/)的请求转发到后端服务器。对浏览器来说,请求和响应均来自同一域名,代理过程对浏览器透明。 “黑匣子”处理: 浏览器只与 Nginx 交互,不关心 Nginx 内部如何转发请求。无论后端位置如何,浏览器都认为响应源自统一域名,从而解决跨域问题。 总结 普通的跨域请求依然会送达服务器,服务器并不主动拦截;它只是通过响应头声明哪些来源被允许访问,而真正的拦截与安全检查,则由浏览器根据同源策略来完成。 JWT令牌 特性 Session JWT(JSON Web Token) 存储方式 服务端存储会话数据(如内存、Redis) 客户端存储完整的令牌(通常在 Header 或 Cookie) 标识方式 客户端持有一个 Session ID 客户端持有一个自包含的 Token 状态管理 有状态(Stateful),服务器要维护会话 无状态(Stateless),服务器不存会话 生成和校验 引入依赖 <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9.1</version> </dependency> 生成令牌与解析令牌: public class JwtUtils { private static String signKey = "zy123"; private static Long expire = 43200000L; //单位毫秒 12小时 /** * 生成JWT令牌 * @param claims JWT第二部分负载 payload 中存储的内容 * @return */ public static String generateJwt(Map<String, Object> claims){ String jwt = Jwts.builder() .addClaims(claims) .signWith(SignatureAlgorithm.HS256, signKey) .setExpiration(new Date(System.currentTimeMillis() + expire)) .compact(); return jwt; } /** * 解析JWT令牌 * @param jwt JWT令牌 * @return JWT第二部分负载 payload 中存储的内容 */ public static Claims parseJWT(String jwt){ Claims claims = Jwts.parser() .setSigningKey(signKey) .parseClaimsJws(jwt) .getBody(); return claims; } } 令牌可以存储当前登录用户的信息:id、username等等,传入claims Object 类型能够容纳字符串、数字等各种对象。 Map<String, Object> claims = new HashMap<>(); claims.put("id", emp.getId()); // 假设 emp.getId() 返回一个数字(如 Long 类型) claims.put("name", e.getName()); // 假设 e.getName() 返回一个字符串 claims.put("username", e.getUsername()); // 假设 e.getUsername() 返回一个字符串 String jwt = JwtUtils.generateJwt(claims); 解析令牌: @Autowired private HttpServletRequest request; String jwt = request.getHeader("token"); Claims claims = JwtUtils.parseJWT(jwt); // 解析 JWT 令牌 // 获取存储的 id, name, username Long id = (Long) claims.get("id"); // 如果 "id" 是 Long 类型 String name = (String) claims.get("name"); String username = (String) claims.get("username"); JWT 登录认证流程 用户登录 用户发起登录请求,校验密码、登录成功后,生成 JWT 令牌,并将其返回给前端。 前端存储令牌 前端接收到 JWT 令牌,存储在浏览器中(通常存储在 LocalStorage 或 Cookie 中)。 // 登录成功后,存储 JWT 令牌到 LocalStorage const token = response.data.token; // 从响应中获取令牌 localStorage.setItem('token', token); // 存储到 LocalStorage // 在后续请求中获取令牌并附加到请求头 const storedToken = localStorage.getItem('token'); fetch("https://your-api.com/protected-endpoint", { method: "GET", headers: { "token": storedToken // 添加 token 到请求头 } }) .then(response => response.json()) .then(data => console.log(data)) .catch(error => console.log('Error:', error)); 请求带上令牌 后续的每次请求,前端将 JWT 令牌携带上。 服务端校验令牌 服务端接收到请求后,拦截请求并检查是否携带令牌。若没有令牌,拒绝访问;若令牌存在,校验令牌的有效性(包括有效期),若有效则放行,进行请求处理。 注意,使用APIFOX测试时,需要在headers中添加 {token:"jwt令牌..."}否则会无法通过拦截器。 拦截器(Interceptor) 在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。 快速入门 定义拦截器,实现HandlerInterceptor接口,并重写其所有方法 //自定义拦截器 @Component public class JwtTokenUserInterceptor implements HandlerInterceptor { //目标资源方法执行前执行。 返回true:放行 返回false:不放行 @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { System.out.println("preHandle .... "); return true; //true表示放行 } //目标资源方法执行后执行 @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { System.out.println("postHandle ... "); } //视图渲染完毕后执行,最后执行 @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { System.out.println("afterCompletion .... "); } } 注意: preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行 postHandle方法:目标资源方法执行后执行 afterCompletion方法:视图渲染完毕后执行,最后执行 注册配置拦截器,实现WebMvcConfigurer接口,并重写addInterceptors方法 @Configuration public class WebConfig implements WebMvcConfigurer { //自定义的拦截器对象 @Autowired private JwtTokenUserInterceptor jwtTokenUserInterceptor; @Override protected void addInterceptors(InterceptorRegistry registry) { log.info("开始注册自定义拦截器..."); registry.addInterceptor(jwtTokenUserInterceptor) .addPathPatterns("/user/**") .excludePathPatterns("/user/user/login") .excludePathPatterns("/user/shop/status"); } } WebMvcConfigurer接口: 拦截器配置 通过实现 addInterceptors 方法,可以添加自定义的拦截器,从而在请求进入处理之前或之后执行一些逻辑操作,如权限校验、日志记录等。 静态资源映射 通过 addResourceHandlers 方法,可以自定义静态资源(如 HTML、CSS、JavaScript)的映射路径,这对于使用前后端分离或者集成第三方文档工具(如 Swagger/Knife4j)非常有用。 消息转换器扩展 通过 extendMessageConverters 方法,可以在默认配置的基础上,追加自定义的 HTTP 消息转换器,如将 Java 对象转换为 JSON 格式。 跨域配置 使用 addCorsMappings 方法,可以灵活配置跨域资源共享(CORS)策略,方便前后端跨域请求。 拦截路径 addPathPatterns指定拦截路径; 调用excludePathPatterns("不拦截的路径")方法,指定哪些资源不需要拦截。 拦截路径 含义 举例 /* 一级路径 能匹配/depts,/emps,/login,不能匹配 /depts/1 /** 任意级路径 能匹配/depts,/depts/1,/depts/1/2 /depts/* /depts下的一级路径 能匹配/depts/1,不能匹配/depts/1/2,/depts /depts/** /depts下的任意级路径 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 登录校验 主要在preHandle中写逻辑 public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //判断当前拦截到的是Controller的方法还是其他资源 if (!(handler instanceof HandlerMethod)) { //当前拦截到的不是动态方法,直接放行 return true; } //1、从请求头中获取令牌 String token = request.getHeader(jwtProperties.getUserTokenName()); //2、校验令牌 try { log.info("jwt校验:{}", token); Claims claims = JwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token); Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString()); log.info("当前用户id:", userId); BaseContext.setCurrentId(userId); //3、通过,放行 return true; } catch (Exception ex) { //4、不通过,响应401状态码 response.setStatus(401); return false; } } 全局异常处理 **当前问题:**如果程序因不知名原因报错,响应回来的数据是一个JSON格式的数据,但这种JSON格式的数据不符合开发规范当中所提到的统一响应结果Result吗,导致前端不能解析出响应的JSON数据。 当我们没有做任何的异常处理时,我们三层架构处理异常的方案: Mapper接口在操作数据库的时候出错了,此时异常会往上抛(谁调用Mapper就抛给谁),会抛给service。 service 中也存在异常了,会抛给controller。 而在controller当中,我们也没有做任何的异常处理,所以最终异常会再往上抛。最终抛给框架之后,框架就会返回一个JSON格式的数据,里面封装的就是错误的信息,但是框架返回的JSON格式的数据并不符合我们的开发规范。 如何解决: 方案一:在所有Controller的所有方法中进行try…catch处理 缺点:代码臃肿(不推荐) 方案二:全局异常处理器 好处:简单、优雅(推荐) 全局异常处理 定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解**@RestControllerAdvice**,加上这个注解就代表我们定义了一个全局异常处理器。 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解**@ExceptionHandler**。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。 @RestControllerAdvice public class GlobalExceptionHandler { //处理 RuntimeException 异常 @ExceptionHandler(RuntimeException.class) public Result handleRuntimeException(RuntimeException e) { e.printStackTrace(); return Result.error("系统错误,请稍后再试"); } // 处理 NullPointerException 异常 @ExceptionHandler(NullPointerException.class) public Result handleNullPointerException(NullPointerException e) { e.printStackTrace(); return Result.error("空指针异常,请检查代码逻辑"); } //处理异常 @ExceptionHandler(Exception.class) //指定能够处理的异常类型,Exception.class捕获所有异常 public Result ex(Exception e){ e.printStackTrace();//打印堆栈中的异常信息 //捕获到异常之后,响应一个标准的Result return Result.error("对不起,操作失败,请联系管理员"); } } 模拟NullPointerException String str = null; // 调用 null 对象的方法会抛出 NullPointerException System.out.println(str.length()); // 这里会抛出 NullPointerException 模拟RuntimeException int res=10/0; 事务 问题分析: @Slf4j @Service public class DeptServiceImpl implements DeptService { @Autowired private DeptMapper deptMapper; @Autowired private EmpMapper empMapper; //根据部门id,删除部门信息及部门下的所有员工 @Override public void delete(Integer id){ //根据部门id删除部门信息 deptMapper.deleteById(id); //模拟:异常发生 int i = 1/0; //删除部门下的所有员工信息 empMapper.deleteByDeptId(id); } } 即使程序运行抛出了异常,部门依然删除了,但是部门下的员工却没有删除,造成了数据的不一致。 因此,需要事务来控制这组操作,让这组操作同时成功或同时失败。 Transactional注解 @Transactional作用:就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。一般会在**业务层(Service)**当中来控制事务。 @Transactional注解书写位置: 方法:当前方法交给spring进行事务管理 类:当前类中所有的方法都交由spring进行事务管理 接口:接口下所有的实现类当中所有的方法都交给spring 进行事务管理 @Transactional注解当中的两个常见的属性: 异常回滚的属性:rollbackFor 事务传播行为:propagation 默认情况下,只有出现RuntimeException(运行时异常)才会回滚事务。假如我们想让所有的异常都回滚,需要来配置@Transactional注解当中的rollbackFor属性,通过rollbackFor这个属性可以指定出现何种异常类型回滚事务。 @Transactional(rollbackFor=Exception.class) public void delete(Integer id){ //根据部门id删除部门信息 deptMapper.deleteById(id); //模拟:异常发生 int num = id/0; //删除部门下的所有员工信息 empMapper.deleteByDeptId(id); } 在@Transactional注解的后面指定一个属性propagation,通过 propagation 属性来指定事务的传播行为。 什么是事务的传播行为呢? 就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。A方法运行的时候,首先会开启一个事务,在A方法当中又调用了B方法, B方法自身也具有事务,那么B方法在运行的时候,到底是加入到A方法的事务当中来,还是B方法在运行的时候新建一个事务? 属性值 含义 REQUIRED 【默认值】有父事务则加入,父子有异常则一起回滚;无父事务则创建新事务 REQUIRES_NEW 需要新事务,无论有无,总是创建新事务 REQUIRED :大部分情况下都是用该传播行为即可。 REQUIRES_NEW :当我们不希望事务之间相互影响时,可以使用该传播行为。比如:下订单前需要记录日志,不论订单保存成功与否,都需要保证日志记录能够记录成功。 @Transactional(propagation = Propagation.REQUIRES_NEW) Spring事务日志开关 logging: level: org.springframework.jdbc.support.JdbcTransactionManager: debug 当你设置 debug 级别日志时,Spring 会打印出关于事务的详细信息,例如事务的开启、提交、回滚以及数据库操作。 总结 当 Service 层发生异常 时,Spring 会按照以下顺序处理: 事务的回滚:如果 Service 层抛出了一个异常(如 RuntimeException),并且这个方法是 @Transactional 注解标注的,Spring 会在方法抛出异常时 回滚事务。Spring 事务管理器会自动触发回滚操作。 异常传播到 Controller 层:如果异常在 Service 层处理后未被捕获,它会传播到 Controller 层(即调用 Service 方法的地方)。 全局异常处理器:当异常传播到 Controller 层时,全局异常处理器(@RestControllerAdvice 或 @ControllerAdvice)会捕获并处理该异常,返回给前端一个标准的错误响应。 AOP AOP(Aspect-Oriented Programming,面向切面编程)是一种编程思想,旨在将横切关注点(如日志、性能监控等)从核心业务逻辑中分离出来。简单来说,AOP 是通过对特定方法的增强(如统计方法执行耗时)来实现代码复用和关注点分离。 实现业务方法执行耗时统计的步骤 定义模板方法:将记录方法执行耗时的公共逻辑提取到模板方法中。 记录开始时间:在方法执行前记录开始时间。 执行原始业务方法:中间部分执行实际的业务方法。 记录结束时间:在方法执行后记录结束时间,计算并输出执行时间。 通过 AOP,我们可以在不修改原有业务代码的情况下,完成对方法执行耗时的统计。 快速入门 实现步骤: 导入依赖:在pom.xml中导入AOP的依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency> 编写AOP程序:针对于特定方法根据业务需要进行编程 @Component @Aspect //当前类为切面类 @Slf4j public class TimeAspect { ////第一个星号表示任意返回值,第二个星号表示类/接口,第三个星号表示所有方法。 @Around("execution(* edu.whut.zy123.service.*.*(..))") public Object recordTime(ProceedingJoinPoint pjp) throws Throwable { //记录方法执行开始时间 long begin = System.currentTimeMillis(); //执行原始方法 Object result = pjp.proceed(); //记录方法执行结束时间 long end = System.currentTimeMillis(); //计算方法执行耗时,pjp.getSignature()获得函数名 log.info(pjp.getSignature()+"执行耗时: {}毫秒",end-begin); return result; } } 我们通过AOP入门程序完成了业务方法执行耗时的统计,那其实AOP的功能远不止于此,常见的应用场景如下: 记录系统的操作日志 权限控制 事务管理:我们前面所讲解的Spring事务管理,底层其实也是通过AOP来实现的,只要添加@Transactional注解之后,AOP程序自动会在原始方法运行前先来开启事务,在原始方法运行完毕之后提交或回滚事务 核心概念 1. 连接点:JoinPoint,可以被AOP控制的方法,代表方法的执行位置 2. 通知:Advice,指对目标方法的“增强”操作 (体现为额外的代码) 3. 切入点:PointCut,是一个表达式,匹配连接点的条件,它指定了 在目标方法的哪些位置插入通知,比如在哪些方法调用之前、之后、或者哪些方法抛出异常时进行增强。 4. 切面:Aspect,通知与切入点的结合 5.目标对象:Target,被 AOP 代理的对象,通知会作用到目标对象的对应方法上。 示例: @Slf4j @Component @Aspect public class MyAspect { @Before("execution(* edu.whut.zy123.service.MyService.doSomething(..))") public void beforeMethod(JoinPoint joinPoint) { // 连接点:目标方法执行位置 System.out.println("Before method: " + joinPoint.getSignature().getName()); } } joinPoint 代表的是 doSomething() 方法执行的连接点。 beforeMethod() 方法就是一个前置通知 "execution(* com.example.service.MyService.doSomething(..))"是切入点 MyAspect是切面。 com.example.service.MyService 类的实例是目标对象 通知类型 @Around:环绕通知。此通知会在目标方法前后都执行。 @Before:前置通知。此通知在目标方法执行之前执行。 @After :后置通知。此通知在目标方法执行后执行,无论方法是否抛出异常。 @AfterReturning : 返回后通知。此通知在目标方法正常返回后执行,发生异常时不会执行。 @AfterThrowing : 异常后通知。此通知在目标方法抛出异常后执行。 在使用通知时的注意事项: @Around 通知必须调用 ProceedingJoinPoint.proceed() 才能执行目标方法,其他通知不需要。 @Around 通知的返回值必须是 Object 类型,用于接收原始方法的返回值。 通知执行顺序 默认情况下,不同切面类的通知执行顺序由类名的字母顺序决定。 可以通过 @Order 注解指定切面类的执行顺序,数字越小,优先级越高。 例如:@Order(1) 表示该切面类的通知优先执行。 @Aspect @Order(1) // 优先级1 @Component public class AspectOne { @Before("execution(* edu.whut.zy123.service.MyService.*(..))") public void beforeMethod() { System.out.println("AspectOne: Before method"); } } @Aspect @Order(2) // 优先级2 @Component public class AspectTwo { @Before("execution(* edu.whut.zy123.service.MyService.*(..))") public void beforeMethod() { System.out.println("AspectTwo: Before method"); } } 如果调用 MyService 中的某个方法,AspectOne切面类中的通知会先执行。 结论:目标方法前的通知方法,Order小的或者类名的字母顺序在前的先执行。 目标方法后的通知方法,Order小的或者类名的字母顺序在前的后执行。 相对于显式设置(Order)的通知,默认通知的优先级最低。 切入点表达式 作用:主要用来决定项目中的哪些方法需要加入通知 常见形式: execution(……):根据方法的签名来匹配 @annotation(……) :根据注解匹配 公共表示@Pointcut 使用 @Pointcut 注解可以将切点表达式提取到一个独立的方法中,提高代码复用性和可维护性。 @Aspect @Component public class LoggingAspect { // 定义一个切点,匹配com.example.service包下 UserService 类的所有方法 @Pointcut("execution(public * com.example.service.UserService.*(..))") public void userServiceMethods() { // 该方法仅用来作为切点标识,无需实现任何内容 } // 在目标方法执行前执行通知,引用上面的切点 @Before("userServiceMethods()") public void beforeUserServiceMethods() { System.out.println("【日志】即将执行 UserService 中的方法"); } } execution execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为: execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?) 其中带?的表示可以省略的部分 访问修饰符:可省略(比如: public、protected) 包名.类名.: 可省略,但不建议 throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常) 示例: //如果希望匹配 public void delete(Integer id) @Before("execution(void edu.whut.zy123.service.impl.DeptServiceImpl.delete(java.lang.Integer))") //如果希望匹配 public void delete(int id) @Before("execution(void edu.whut.zy123.service.impl.DeptServiceImpl.delete(int))") 在 Pointcut 表达式中,为了确保匹配准确,通常建议对非基本数据类型使用全限定名。这意味着,对于像 Integer 这样的类,最好写成 java.lang.Integer 可以使用通配符描述切入点 * :单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分 execution(* edu.*.service.*.update*(*)) 这里update后面的'星'即通配方法名的一部分,()中的'星'表示有且仅有一个任意参数 可以匹配: package edu.zju.service; public class UserService { public void updateUser(String username) { // 方法实现 } } .. :多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数 execution(* com.example.service.UserService.*(..)) annotation 那么如果我们要匹配多个无规则的方法,比如:list()和 delete()这两个方法。我们可以借助于另一种切入点表达式annotation来描述这一类的切入点,从而来简化切入点表达式的书写。 实现步骤: 新建anno包,在这个包下编写自定义注解 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; // 定义注解 @Retention(RetentionPolicy.RUNTIME) // 定义注解的生命周期 @Target(ElementType.METHOD) // 定义注解可以应用的Java元素类型 public @interface MyLog { // 定义注解的元素(属性) String description() default "This is a default description"; int value() default 0; } 在业务类要做为连接点的方法上添加自定义注解 @MyLog //自定义注解(表示:当前方法属于目标方法) public void delete(Integer id) { //1. 删除部门 deptMapper.delete(id); } AOP切面类上使用类似如下的切面表达式: @Before("@annotation(edu.whut.anno.MyLog)") 连接点JoinPoint 执行: ProceedingJoinPoint和 JoinPoint 都是调用 proceed() 就会执行被代理的方法 Object result = joinPoint.proceed(); 获取调用方法时传递的参数,即使只有一个参数,也以数组形式返回: Object[] args = joinPoint.getArgs(); getSignature(): 返回一个Signature类型的对象,这个对象包含了被拦截点的签名信息。在方法调用的上下文中,这包括了方法的名称、声明类型等信息。 方法名称:可以通过调用getName()方法获得。 声明类型:方法所在的类或接口的完全限定名,可以通过getDeclaringTypeName()方法获取。 返回类型(对于方法签名):可以通过将Signature对象转换为更具体的MethodSignature类型,并调用getReturnType()方法获取。 WEB开发总体图
自学
zy123
3月21日
0
1
0
2025-03-21
草稿
在 0/1 背包问题中,使用一维 DP 数组时必须逆序遍历背包容量,主要原因在于避免同一物品被重复计算。这与二维 DP 的实现方式有本质区别。下面通过公式和例子详细说明。 为什么一维 DP 必须逆序遍历? 状态定义 一维 DP 数组定义为: $$ dp[j] = \text{背包容量为 } j \text{ 时的最大价值} $$ 状态转移方程 对于物品 $i$(重量 $w_i$,价值 $v_i$): $$ dp[j] = \max(dp[j], dp[j-w_i] + v_i) \quad (j \geq w_i) $$ 关键问题 正序遍历会导致 $dp[j-w_i]$ 在更新 $dp[j]$ 时已被当前物品更新过,相当于重复使用该物品。 逆序遍历保证 $dp[j-w_i]$ 始终是**上一轮(未考虑当前物品)**的结果,符合 0/1 背包的“一次性”规则。 二维 DP 为何不需要逆序? 二维 DP 定义为: $$ dp[i][j] = \text{前 } i \text{ 个物品,容量 } j \text{ 时的最大价值} $$ 状态转移: $$ dp[i][j] = \max(dp[i-1][j], dp[i-1][j-w_i] + v_i) $$ - 由于直接依赖 **上一行 $dp[i-1][\cdot]$**,不存在状态覆盖问题,正序/逆序均可。 例子演示 假设物品 $w=2$, $v=3$,背包容量 $C=5$。 错误的正序遍历($j=2 \to 5$) $j=2$: $dp[2] = \max(0, dp[0]+3) = 3$ $\Rightarrow dp = [0, 0, 3, 0, 0, 0]$ $j=4$: $dp[4] = \max(0, dp[2]+3) = 6$ $\Rightarrow$ 错误:物品被重复使用两次! 正确的逆序遍历($j=5 \to 2$) $j=5$: $dp[5] = \max(0, dp[3]+3) = 0$ ($dp[3]$ 未更新) $j=2$: $dp[2] = \max(0, dp[0]+3) = 3$ $\Rightarrow dp = [0, 0, 3, 3, 3, 0]$ 正确:物品仅使用一次。 总结 维度 遍历顺序 原因 一维DP 逆序 防止 $dp[j-w_i]$ 被当前物品污染,确保每个物品只计算一次。 二维DP 任意顺序 状态分层存储($dp[i][j]$ 只依赖 $dp[i-1][\cdot]$),无覆盖风险。 核心思想:一维 DP 的空间优化需要逆序来保证状态的无后效性。
自学
zy123
3月21日
0
0
0
2025-03-21
Java笔记本
Java笔记本 IDEA基础操作 Intellij Ideav创建Java项目: 创建空项目 创建Java module 创建包 package edu.whut.xx 创建类,类名首字母必须大写! IDEA快捷键: Ctrl + Alt + L 格式化代码 Ctrl + / 注释/取消注释当前行 Ctrl + D 复制当前行或选中的代码块 Ctrl + Y 删除当前行 Ctrl + N 查找类 Ctrl+shift+F 在文件中查找代码 调试快捷键: 快捷键 功能 Shift + F9 调试当前程序 F8 单步执行(不进入方法) F7 单步执行(进入方法) Shift + F8 跳出当前方法 Alt + F9 运行到光标处 Ctrl + F2 停止调试 缩写 生成的代码 说明 psvm public static void main(String[] args) {} 生成 main 方法 sout System.out.println(); 打印到控制台 fori for (int i = 0; i < ; i++) {} 生成 for 循环 iter for (Type item : iterable) {} 生成增强 for 循环 new Test().var Test test = new Test(); 自动补全变量声明 从exsiting file中导入模块: 方法一:复制整个模块到项目文件夹,并导入模块的 *.iml 文件,这种方式保留了模块原有的配置信息。 方法二:新建一个模块,然后将原模块的 src 文件夹下的包复制过去,这种方式更灵活,可以手动调整模块设置。 删除模块: 模块右键,remove module,这只是把它从项目中移除,然后!!打开模块所在文件夹,物理删除,才是真正完全删除。 转义符的作用 防止字符被误解: 在字符串中,一些字符(如 " 和 \)有特殊的含义。例如,双引号用于标识字符串的开始和结束,反斜杠通常用于转义。所以当你希望在字符串中包含这些特殊字符时,你需要使用转义符来告诉解析器这些字符是字符串的一部分,而不是特殊符号。 例如,\" 表示在字符串中包含一个双引号字符,而不是字符串的结束标志。 "Hello \"World\"" => 结果是:Hello "World" (双引号被转义) "C:\\Program Files\\App" => 结果是:C:\Program Files\App(反斜杠被转义) 如果只是"C:\Program Files\App" 那么路径就会报错 表示非打印字符: 转义符可以用于表示一些不可见的或非打印的控制字符,如换行符(\n)、制表符(\t)等。这些字符无法直接通过键盘输入,所以使用转义符来表示它们。 Java基础语法 二进制:0b 八进制:0 十六进制:0x 在 System.out.println() 方法中,"ln" 代表 "line",表示换行。因此,println 实际上是 "print line" 的缩写。这个方法会在输出文本后自动换行. System.out.println("nihao "+1.3331); #Java 会自动将数值转换为字符串 一维数组创建: // 方式1:先声明,再指定长度(默认值为0、null等) int[] arr1 = new int[10]; // 创建一个长度为10的int数组 // 方式2:使用初始化列表直接创建数组 int[] arr2 = {1, 2, 3, 4, 5}; // 创建并初始化一个包含5个元素的int数组 String[] strs = {"eat", "tea", "tan", "ate", "nat", "bat"}; // 方式3:结合new关键字和初始化列表创建数组(常用于明确指定类型时) int[] arr3 = new int[]{1, 2, 3, 4, 5}; // 与方式2效果相同 字符串创建 String str = "Hello, World!"; //(1)直接赋值 String str = new String("Hello, World!"); //使用 new 关键字 char[] charArray = {'H', 'e', 'l', 'l', 'o'}; String str = new String(charArray); //通过字符数组创建 switch-case public class SwitchCaseExample { public static void main(String[] args) { // 定义一个 int 类型变量,作为 switch 的表达式 int day = 3; String dayName; // 根据 day 的值执行相应的分支 switch(day) { case 1: dayName = "Monday"; // 当 day 为 1 时 break; // 结束当前 case case 2: dayName = "Tuesday"; // 当 day 为 2 时 break; case 3: dayName = "Wednesday"; // 当 day 为 3 时 break; case 4: dayName = "Thursday"; // 当 day 为 4 时 break; case 5: dayName = "Friday"; // 当 day 为 5 时 break; case 6: dayName = "Saturday"; // 当 day 为 6 时 break; case 7: dayName = "Sunday"; // 当 day 为 7 时 break; default: // 如果 day 不在 1 到 7 之间 dayName = "Invalid day"; } // 输出最终结果 System.out.println("The day is: " + dayName); } } 强制类型转换 double sqrted=Math.sqrt(n); int soft_max=(int) sqrted; Math库常用方法 Math.pow(3, 2)); Math.sqrt(9)); Math.abs(a)); Math.max(a, b)); Math.min(a, b)); 枚举 public enum OperationType { /** * 更新操作 */ UPDATE, /** * 插入操作 */ INSERT } OperationType opType = OperationType.INSERT; // 声明并初始化 public void execute(OperationType type, Object entity) { switch (type) { case INSERT: insertEntity(entity); break; case UPDATE: updateEntity(entity); break; default: throw new IllegalArgumentException("Unsupported operation: " + type); } } // 定义枚举类型 public enum DayOfWeek { MONDAY("星期一", 1), TUESDAY("星期二", 2), WEDNESDAY("星期三", 3), THURSDAY("星期四", 4), FRIDAY("星期五", 5), SATURDAY("星期六", 6), SUNDAY("星期日", 7); // 枚举属性 private final String chineseName; private final int dayNumber; // 构造方法 DayOfWeek(String chineseName, int dayNumber) { this.chineseName = chineseName; this.dayNumber = dayNumber; } // 方法 public String getChineseName() { return chineseName; } public int getDayNumber() { return dayNumber; } } // 使用示例 public class Main { public static void main(String[] args) { DayOfWeek today = DayOfWeek.MONDAY; System.out.println(today.getChineseName()); // 输出: 星期一 System.out.println(today.getDayNumber()); // 输出: 1 } } Java传参方式 基本数据类型(Primitives) 传递方式:按值传递 每次传递的是变量的值的副本**,对该值的修改不会影响原变量**。例如:int、double、boolean 等类型。 引用类型(对象) 传递方式:对象引用的副本传递 传递的是对象引用的一个副本,指向同一块内存区域。因此,方法内部通过该引用修改对象的状态,会影响到原对象。如数组、集合、String、以及其他所有对象类型。 注意 StringBuilder s = new StringBuilder(); s.append("hello"); String res = s.toString(); // res = "hello" s.append(" world"); // s = "hello world" System.out.println(res); // 输出还是 "hello" 浅拷贝 拷贝对象本身,但内部成员(例如集合中的元素)只是复制引用,新旧对象的内部成员指向同一份内存。如果内部元素是不可变的(如 Integer、String 等),这种拷贝通常足够。如果元素是可变对象,修改其中一个对象可能会影响另一个。 List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); // 浅拷贝:新列表中的元素引用和原列表中的是同一份 List<Integer> shallowCopy = new ArrayList<>(list); 可变对象,浅拷贝修改对象会出错! List<Box> list = new ArrayList<>(); list.add(new Box(1)); list.add(new Box(2)); list.add(new Box(3)); List<Box> shallowCopy = new ArrayList<>(list); shallowCopy.get(0).value = 10; // 修改 shallowCopy 中第一个 Box 的 value System.out.println(list); // 输出: [10, 2, 3],因为同一 Box 对象被修改 System.out.println(shallowCopy); // 输出: [10, 2, 3] 深拷贝 不仅复制对象本身,还递归地复制其所有内部成员,从而生成一个完全独立的副本。即使内部元素是可变的,修改新对象也不会影响原始对象。 // 深拷贝 List<MyObject> 的例子 List<MyObject> originalList = new ArrayList<>(); originalList.add(new MyObject(10)); originalList.add(new MyObject(20)); List<MyObject> deepCopy = new ArrayList<>(); for (MyObject obj : originalList) { deepCopy.add(new MyObject(obj)); // 每个元素都创建一个新的对象 } 日期 在Java中: 代表年月日的类型是 LocalDate。LocalDate 类位于 java.time 包下,用于表示没有时区的日期,如年、月、日。 代表年月日时分秒的类型是 LocalDateTime。LocalDateTime 类也位于 java.time 包下,用于表示没有时区的日期和时间,包括年、月、日、时、分、秒。 LocalDateTime.now(),获取当前时间 访问修饰符 public(公共的): 使用public修饰的成员可以被任何其他类访问,无论这些类是否属于同一个包。 例如,如果一个类的成员被声明为public,那么其他类可以通过该类的对象直接访问该成员。 protected(受保护的): 使用protected修饰的成员可以被同一个包中的其他类访问,也可以被不同包中的子类访问。 与包访问级别相比,protected修饰符提供了更广泛的访问权限。 default (no modifier)(默认的,即包访问级别): 如果没有指定任何访问修饰符,则默认情况下成员具有包访问权限。 在同一个包中的其他类可以访问默认访问级别的成员,但是在不同包中的类不能访问。 private(私有的): 使用private修饰的成员只能在声明它们的类内部访问,其他任何类都不能访问这些成员。 这种访问级别提供了最高的封装性和安全性。 如果您在另一个类中实例化了包含私有成员的类,那么您无法直接访问该类的私有成员。但是,您可以通过公共方法来间接地访问和操作私有成员。 则每个实例都有自己的一份拷贝,只有当变量被声明为 static 时,变量才是类级别的,会被所有实例共享。 // 文件:com/example/PrivateExample.java package com.example; public class PrivateExample { private int privateVar = 30; // 公共方法,用于访问私有成员 public int getPrivateVar() { return privateVar; } } 修饰符不仅可以用来修饰成员变量和方法,也可以用来修饰类。顶级类只能使用 public 或默认(即不写任何修饰符,称为包访问权限)。内部类可以使用所有访问修饰符(public、protected、private 和默认),这使得你可以更灵活地控制嵌套类的访问范围。 public class OuterClass { // 内部类使用private,只能在OuterClass内部访问 private class InnerPrivateClass { // ... } // 内部类使用protected,同包以及其他包中的子类可以访问 protected class InnerProtectedClass { // ... } // 内部类使用默认访问权限,只在同包中可见 class InnerDefaultClass { // ... } // 内部类使用public,任何地方都可访问(但访问时需要通过OuterClass对象) public class InnerPublicClass { // ... } } 四种内部类 下面是四种内部类(成员内部类、局部内部类、静态内部类和匿名内部类)的示例代码,展示了如何用每一种方式来实现Runnable的run()方法并创建线程。 成员内部类 定义位置:成员内部类定义在外部类的成员位置。 访问权限:可以无限制地访问外部类的所有成员,包括私有成员。 实例化方式:需要先创建外部类的实例,然后才能创建内部类的实例。 修改限制:不能有静态字段和静态方法(除非声明为常量final static)。成员内部类属于外部类的一个实例,不能独立存在于类级别上。 用途:适用于内部类与外部类关系密切,需要频繁访问外部类成员的情况。 public class OuterClass { class InnerClass implements Runnable { // static int count = 0; // 编译错误 public static final int CONSTANT = 100; // 正确:可以定义常量 public void run() { System.out.println("成员内部类中的线程正在运行..."); } } public void startThread() { InnerClass inner = new InnerClass(); Thread thread = new Thread(inner); thread.start(); } public static void main(String[] args) { OuterClass outer = new OuterClass(); outer.startThread(); } } 局部内部类 定义位置:局部内部类定义在一个方法或任何块内(如:if语句、循环语句内)。 访问权限:只能访问所在方法的final或事实上的final(即不被后续修改的)局部变量和外部类的成员变量(同成员内部类)。 实例化方式:只能在定义它们的块中创建实例。 修改限制:同样不能有静态字段和方法。 用途:适用于只在方法或代码块中使用的类,有助于将实现细节隐藏在方法内部。 public class OuterClass { public void startThread() { class LocalInnerClass implements Runnable { public void run() { System.out.println("局部内部类中的线程正在运行..."); } } LocalInnerClass localInner = new LocalInnerClass(); Thread thread = new Thread(localInner); thread.start(); } public static void main(String[] args) { OuterClass outer = new OuterClass(); outer.startThread(); } } 静态内部类 定义位置:定义在外部类内部,但使用static修饰。 访问权限:只能直接访问外部类的静态成员,访问非静态成员需要通过外部类实例。 实例化方式:可以直接创建,不需要外部类的实例。 修改限制:可以有自己的静态成员。 用途:适合当内部类工作不依赖外部类实例时使用,常用于实现与外部类关系不那么密切的帮助类。 public class OuterClass { // 外部类的静态成员 private static int staticVar = 10; // 外部类的实例成员 private int instanceVar = 20; // 静态内部类 public static class StaticInnerClass { public void display() { // 可以直接访问外部类的静态成员 System.out.println("staticVar: " + staticVar); // 下面这行代码会报错,因为不能直接访问外部类的实例成员 // System.out.println("instanceVar: " + instanceVar); // 如果确实需要访问实例成员,可以通过创建外部类的对象来访问 OuterClass outer = new OuterClass(); System.out.println("通过外部类实例访问 instanceVar: " + outer.instanceVar); } } public static void main(String[] args) { // 直接创建静态内部类的实例,不需要外部类实例 OuterClass.StaticInnerClass inner = new OuterClass.StaticInnerClass(); inner.display(); } } 匿名内部类 使用匿名内部类实现抽象类相当于临时创建了一个未命名的子类,并且立即实例化了这个子类的对象。 定义位置:在需要使用它的地方立即定义和实例化。 访问权限:类似局部内部类,只能访问final或事实上的final局部变量。 实例化方式:在定义时就实例化,不能显式地命名构造器。 修改限制:不能有任何静态成员。 用途:适用于创建一次性使用的实例,通常用于接口或抽象类的实现。 //eg1 public class OuterClass { public static void main(String[] args) { Runnable runnable = new Runnable() { @Override public void run() { System.out.println("匿名内部类中的线程正在运行..."); } }; Thread thread = new Thread(runnable); thread.start(); } } //eg2 安卓开发中用过很多次! import javax.swing.*; import java.awt.event.*; public class GUIApp { public static void main(String[] args) { JFrame frame = new JFrame("Demo"); JButton button = new JButton("Click Me!"); // 匿名内部类用于事件监听 button.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { System.out.println("Button was clicked!"); } }); frame.add(button); frame.setSize(300, 200); frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); frame.setVisible(true); } } 创建ActionListener实例 new ActionListener() { public void actionPerformed(ActionEvent e) { System.out.println("Button was clicked!"); } } 这部分代码是匿名内部类的核心。这里发生的事情包括: new ActionListener():这表示创建了ActionListener接口的一个实现。由于ActionListener是一个接口,我们不能直接实例化它,而是需要提供该接口的一个具体实现。在这种情况下,我们通过创建一个匿名内部类来提供实现。 大括号 { ... }:在这对大括号内,我们定义了接口中需要实现的方法。对于ActionListener接口,必须实现actionPerformed(ActionEvent e)方法。 方法实现: public void actionPerformed(ActionEvent e):这是ActionListener接口要求实现的方法,用于响应事件。这里的方法定义了当事件发生时(例如,用户点击按钮)执行的操作。 System.out.println("Button was clicked!");:这是actionPerformed方法的具体实现,即当按钮被点击时,控制台将输出一条消息。 将匿名内部类添加为事件监听器 button.addActionListener(...); button.addActionListener(EventListener):这是JButton类的一个方法,用于添加事件监听器。这个方法的参数是ActionListener类型的对象,这里传入的正是我们刚刚创建的匿名内部类的实例。 Lambda表达式 Lambda表达式特别适用于只有单一抽象方法的接口(也即函数式接口)。lambda 表达式主要用于实现函数式接口。 @FunctionalInterface 注解:这是一个可选的注解,用于表示接口是一个函数式接口。虽然不是强制的,但它可以帮助编译器识别意图,并检查接口是否确实只有一个抽象方法。 public class LambdaExample { // 定义函数式接口,doSomething 有两个参数 @FunctionalInterface interface MyInterface { void doSomething(int a, int b); } public static void main(String[] args) { // 使用 Lambda 表达式实现接口方法 MyInterface obj = (a, b) -> { System.out.println("参数a: " + a + ", 参数b: " + b); }; obj.doSomething(5, 10); } } lambda表达式格式:(参数列表) -> { 代码块 } 或 (参数列表) ->表达式; 在上述Lambda表达式中,因为MyInterface接口的doSomething()方法不接受任何参数并且没有返回值,所以Lambda表达式的参数列表为空(()),后面跟的是执行的代码块。 以下是lambda表达式的重要特征: 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。 可选的参数圆括号:一个参数无需定义圆括号,但无参数或多个参数需要定义圆括号。 可选的大括号:如果主体只有一个语句,可以不使用大括号。 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,使用大括号需显示retrun;如果函数是void则不需要返回值。 // 定义一个函数式接口 interface Calculator { int add(int a, int b); } public class LambdaReturnExample { public static void main(String[] args) { // 例子1:单个表达式,不使用大括号和 return 关键字 Calculator calc1 = (a, b) -> a + b; System.out.println("calc1: " + calc1.add(5, 3)); // 输出:8 // 例子2:使用大括号,需要显式使用 return 关键字 Calculator calc2 = (a, b) -> { return a + b; }; System.out.println("calc2: " + calc2.add(5, 3)); // 输出:8 } } 示例1: list.forEach这个方法接受一个函数式接口作为参数。它只有一个抽象方法 accept(T t)因此,可以使用 lambda 表达式来实现。 import java.util.Arrays; import java.util.List; public class Main { public static void main(String[] args) { List<String> list = Arrays.asList("Apple", "Banana", "Cherry", "Date"); // 使用 Lambda 表达式迭代列表 list.forEach(item -> System.out.println(item)); } } 示例2: Collections.sort 方法用于对列表进行排序,它接受两个参数 第一个参数:要排序的列表(这里是一个 List<String>)。 第二个参数:一个实现了 Comparator 接口的比较器,用于指定排序规则。 如果返回负数,表示 a 应该排在 b 的前面; 如果返回正数,则 a 应该排在 b 的后面。 import java.util.Arrays; import java.util.Collections; import java.util.List; public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("John", "Jane", "Adam", "Dana"); // 使用Lambda表达式排序 Collections.sort(names, (String a, String b) -> a.compareTo(b)); // 输出排序结果 names.forEach(name -> System.out.println(name)); } } 静态成员变量的初始化 静态成员变量属于类级别,在类加载时完成初始化。初始化方式主要有两种: 1.静态初始化块(Static Initialization Block) public class MyClass { static int num1, num2; // 第一个静态代码块 static { num1 = 1; System.out.println("静态代码块1执行"); } // 主方法 public static void main(String[] args) { System.out.println("main方法执行"); } // 第二个静态代码块 static { num2 = 3; System.out.println("静态代码块2执行"); } } 输出: 静态代码块1执行 静态代码块2执行 main方法执行 说明: 类加载时依次执行所有静态代码块,然后执行 main 方法。 2.在声明时直接初始化 public class MyClass { // 直接在声明时初始化静态成员变量 public static int staticVariable = 42; } 静态成员变量的访问不需要创建 MyClass 的实例,可以直接通过类名访问: int value = MyClass.staticVariable; MyClass obj = new MyClass(); System.out.println("obj.num1 = " + obj.staticVariable); #通过示例访问也可以 静态方法 静态方法属于类级别,不依赖于任何具体实例 静态方法访问规则: 可以直接访问: 类中的其他静态成员变量。 类中的静态方法。 不能直接访问: 非静态成员变量。 非静态方法(必须通过对象实例访问)。 public class MyClass { private static int staticVar = 10; private int instanceVar = 20; // 静态方法:可以直接访问静态成员 public static void staticMethod() { System.out.println(staticVar); // 正确:访问静态成员变量 // System.out.println(instanceVar); // 错误:不能直接访问非静态成员变量 // 如需要访问非静态成员,必须先创建对象实例 MyClass obj = new MyClass(); System.out.println(obj.instanceVar); // 正确:通过对象实例访问非静态成员变量 } // 非静态方法:可以访问所有成员 public void instanceMethod() { System.out.println(staticVar); // 正确:访问静态成员变量 System.out.println(instanceVar); // 正确:访问非静态成员变量 } } 调用静态方法: MyClass.staticMethod(); // 通过类名直接调用静态方法 super关键字 super 关键字有两种主要的使用方法:访问父类的成员和调用父类的构造方法。 访问父类的成员 可以使用 super 关键字来引用父类的字段或方法。这在子类中存在同名的字段或方法时特别有用。 因为父类的成员变量和方法都是默认的访问修饰符,可以继承给子类,而子类也定义了同名的xxx,发生了变量隐藏(shadowing)。 class Parent { int num = 10; void display() { System.out.println("Parent class method"); } } class Child extends Parent { int num = 20; void display() { System.out.println("Child class method"); } void print() { System.out.println("Child class num: " + num); // 访问子类中的num System.out.println("Parent class num: " + super.num); // 使用super关键字访问父类中的num super.display(); // 调用父类中的display方法 } } public class Main { public static void main(String[] args) { Child obj = new Child(); obj.print(); } } 输出: Child class num: 20 Parent class num: 10 Parent class method 调用父类的构造方法 可以使用 super 关键字调用父类的构造方法。这通常在子类的构造方法中使用,用于显式地调用父类的构造方法。 class Parent { Parent() { System.out.println("Parent class constructor"); } } class Child extends Parent { Child() { super(); // 调用父类的构造方法 System.out.println("Child class constructor"); } } public class Main { public static void main(String[] args) { Child obj = new Child(); } } 输出: Parent class constructor Child class constructor final关键字 final 关键字,意思是最终的、不可修改的,最见不得变化 ,用来修饰类、方法和变量,具有以下特点: 修饰类:类不能继承,final 类中的所有成员方法都会被隐式的指定为 final 方法; 修饰变量:该变量为常量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能让其指向另一个对象。 修饰符方法:方法不能重写 变量修饰符的顺序 在Java中,变量的修饰符应该按照规定的顺序出现,通常是这样的: 访问修饰符:public、protected、private,或者不写(默认为包级访问)。 非访问修饰符:final、static、abstract、synchronized、volatile等。 数据类型:变量的数据类型,如int、String、class等。 变量名:变量的名称。 public static final int MAX_COUNT = 100; #定义常量 protected static volatile int counter; #定义成员变量 全限定名 全限定名(Fully Qualified Name,简称 FQN)指的是一个类或接口在 Java 中的完整名称,包括它所在的包名。例如: 对于类 Integer,其全限定名是 java.lang.Integer。 对于自定义的类 DeptServiceImpl,如果它位于包 edu.zju.zy123.service.impl 中,那么它的全限定名就是 edu.zju.zy123.service.impl.DeptServiceImpl。 使用全限定名可以消除歧义,确保指定的类型在整个项目中唯一无误。 使用场景: Spring AOP 的 Pointcut 表达式 MyBatis的XML映射文件的namespace属性 JAVA面向对象 JAVA三大特性 封装 封装指隐藏对象的状态信息(属性),不允许外部对象直接访问对象的内部信息(private实现)。但是可以提供一些可以被外界访问的方法(public)来操作属性。 继承 [修饰符] class 子类名 extends 父类名{ 类体部分 } //class C extends A, B // 错误:C 不能同时继承 A 和 B Java只支持单继承,不支持多继承。一个类只能有一个父类,不可以有多个父类。 Java支持多层继承(A → B → C )。 Java继承了父类非私有的成员变量和成员方法,但是请注意:子类是无法继承父类的构造方法的。 多态 指在面向对象编程中,同样的消息(方法调用)可以在不同的对象上触发不同的行为。 方法重写(Override):动态多态;子类从父类继承的某个实例方法无法满足子类的功能需要时,需要在子类中对该实例方法进行重新实现,这样的过程称为重写,也叫做覆写、覆盖。 要求: 必须存在继承关系(子类继承父类)。 子类重写的方法的访问修饰符不能比父类更严格(可以相同或更宽松)。 方法名、参数列表和返回值类型必须与父类中的方法完全相同(Java 5 以后支持协变返回类型,即允许返回子类型)。 向上转型(Upcasting):动态多态;子类对象可以赋值给父类引用,这样做可以隐藏对象的真实类型,只能调用父类中声明的方法。 class Animal { public void makeSound() { System.out.println("Animal makes sound"); } } class Dog extends Animal { @Override public void makeSound() { System.out.println("Dog barks"); } public void fetch() { System.out.println("Dog fetches the ball"); } } public class Test { public static void main(String[] args) { Animal animal = new Dog(); // 向上转型 animal.makeSound(); // 调用的是 Dog 重写的 makeSound() 方法 // animal.fetch(); // 编译错误:Animal 类型没有 fetch() 方法 } } 多态实现总结:继承 + 重写 + 父类引用指向子类对象 = 多态 方法重载(Overload):静态多态;在一个类中,可以定义多个同名方法,但参数列表不同。当调用这些方法时,会根据传递的参数类型或数量选择相应的方法。 与重写的区别: 重载发生在同一个类中,与继承无关; 重写发生在子类中,依赖继承关系,实现运行时多态。 class Calculator { int add(int a, int b) { return a + b; } double add(double a, double b) { return a + b; } 抽象类 定义 抽象类是包含至少一个抽象方法的类。抽象方法没有实现,只定义了方法的签名。 注意: 抽象类不能被实例化。 必须实现抽象方法 如果一个子类继承了抽象类,通常必须实现抽象类中的所有抽象方法,否则该子类也必须声明为抽象类。例如: abstract class Animal { // 抽象方法,没有方法体 public abstract void makeSound(); // 普通方法 public void sleep() { System.out.println("Sleeping..."); } } // 正确:子类实现了所有抽象方法 class Dog extends Animal { @Override public void makeSound() { System.out.println("Dog barks"); } } // 错误:如果不实现 makeSound() 方法,则 Dog 必须也声明为抽象类 如何使用抽象类 由于抽象类不能直接实例化,我们通常有两种方法来使用抽象类: 定义一个新的子类 创建一个子类继承抽象类并实现所有抽象方法,然后使用子类实例化对象: Animal animal = new Dog(); animal.makeSound(); // 输出:Dog barks 使用匿名内部类 使用匿名内部类实现抽象类相当于临时创建了一个未命名的子类,并且立即实例化了这个子类的对象。 Animal animal = new Animal() { @Override public void makeSound() { System.out.println("Anonymous animal sound"); } }; animal.makeSound(); // 输出:Anonymous animal sound 接口 接口(Interface): 定义了一组方法的规范,侧重于行为的约定。接口中的所有方法默认是抽象的(Java 8 之后可包含默认方法和静态方法),不包含成员变量(除了常量)。 抽象类(Abstract Class): 可以包含抽象方法和具体实现的方法,还可以拥有成员变量和构造方法,适用于需要部分通用实现的情况。 方法实现: 接口: Java 8 前:所有方法都是抽象方法,只包含方法声明。 Java 8 及以后:可包含默认方法(default methods)和静态方法。 抽象类: 可以同时包含抽象方法(不提供实现)和具体方法(提供实现)。 继承: 类实现接口时,使用关键字 implements。 类继承抽象类时,使用关键字 extends。 多继承: 类可以实现多个接口(多继承)。 类只能继承一个抽象类(单继承)。 // 定义接口 interface Flyable { void fly(); } interface Swimmable { void swim(); } // 实现多个接口的类 class Bird implements Flyable, Swimmable { // 实现接口中的方法 public void fly() { System.out.println("Bird is flying"); } public void swim() { System.out.println("Bird is swimming"); } } // 主类 public class Main { public static void main(String[] args) { // 创建实现多个接口的对象 Bird bird = new Bird(); // 调用实现的方法 bird.fly(); // 输出: Bird is flying bird.swim(); // 输出: Bird is swimming } } 容器 Collection 在 Java 中,Collection 是一个接口,它表示一组对象的集合。Collection 接口是 Java 集合框架中最基本的接口之一,定义了一些操作集合的通用方法,例如添加、删除、遍历等。 所有集合类(例如 List、Set、Queue 等)都直接或间接地继承自 Collection 接口。 boolean add(E e):将指定的元素添加到集合中(可选操作)。 boolean remove(Object o):从集合中移除指定的元素(可选操作)。 boolean contains(Object o):如果集合中包含指定的元素,则返回 true。 int size():返回集合中的元素个数。 void clear():移除集合中的所有元素。 boolean isEmpty():如果集合为空,则返回 true。 import java.util.ArrayList; import java.util.Collection; public class CollectionExample { public static void main(String[] args) { // 创建一个 Collection 对象,使用 ArrayList 作为实现类 Collection<String> fruits = new ArrayList<>(); // 添加元素到集合中 fruits.add("Apple"); fruits.add("Banana"); fruits.add("Cherry"); System.out.println("添加元素后集合大小: " + fruits.size()); // 输出集合大小 // 检查集合是否包含某个元素 System.out.println("集合中是否包含 'Banana': " + fruits.contains("Banana")); // 从集合中移除元素 fruits.remove("Banana"); System.out.println("移除 'Banana' 后集合大小: " + fruits.size()); // 清空集合 fruits.clear(); System.out.println("清空集合后,集合是否为空: " + fruits.isEmpty()); } } Iterator 在 Java 中,Iterator 是一个接口,遍历集合元素。Collection 接口中定义了 iterator() 方法,返回一个 Iterator 对象。 Iterator 接口中包含以下主要方法: hasNext():如果迭代器还有下一个元素,则返回 true,否则返回 false。 next():返回迭代器的下一个元素,并将迭代器移动到下一个位置。 remove():从迭代器当前位置删除元素。该方法是可选的,不是所有的迭代器都支持。 import java.util.ArrayList; import java.util.Iterator; public class Main { public static void main(String[] args) { // 创建一个 ArrayList 集合 ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); int size = list.size(); // 获取列表大小 System.out.println("Size of list: " + size); // 输出 3 // 获取集合的迭代器 Iterator<Integer> iterator = list.iterator(); // 使用迭代器遍历集合并输出元素 while (iterator.hasNext()) { Integer element = iterator.next(); System.out.println(element); } } } ArrayList ArrayList 是 List 接口的一种实现,而 List 接口又继承自 Collection 接口。包括 add()、remove()、contains() 等。 HashSet HashMap // 使用 entrySet() 方法获取 Map 中所有键值对的集合,并使用增强型 for 循环遍历键值对 System.out.println("Entries in the map:"); for (Map.Entry<String, Integer> entry : map.entrySet()) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println("Key: " + key + ", Value: " + value); } PriorityQueue 默认是小根堆,输出1,2,5,8 import java.util.PriorityQueue; public class Main { public static void main(String[] args) { // 创建一个 PriorityQueue 对象 PriorityQueue<Integer> pq = new PriorityQueue<>(); // 添加元素到队列 pq.offer(5); pq.offer(2); pq.offer(8); pq.offer(1); // 打印队列中的元素 System.out.println("Elements in the priority queue:"); while (!pq.isEmpty()) { System.out.println(pq.poll()); } } } offer() 方法用于将元素插入到队列中 poll() 方法用于移除并返回队列中的头部元素 peek() 方法用于返回队列中的头部元素但不移除它。 JAVA异常处理 public class ExceptionExample { // 方法声明中添加 throws 关键字,指定可能抛出的异常类型 public static void main(String[] args) throws SomeException, AnotherException { try { // 可能会抛出异常的代码块 if (someCondition) { throw new SomeException("Something went wrong"); } } catch (SomeException e) { // 处理 SomeException 异常 System.out.println("Caught SomeException: " + e.getMessage()); } catch (AnotherException e) { // 处理 AnotherException 异常 System.out.println("Caught AnotherException: " + e.getMessage()); } finally { // 不管是否发生异常,都会执行的代码块 System.out.println("End of try-catch block"); } } } // 自定义异常类,继承自 Exception 类 public class SomeException extends Exception { // 构造方法,用于设置异常信息 public SomeException(String message) { // 调用父类的构造方法,设置异常信息 super(message); } } 好用的方法 toString() **Arrays.toString()**转一维数组 **Arrays.deepToString()**转二维数组 这个方法是是用来将数组转换成String类型输出的,入参可以是long,float,double,int,boolean,byte,object 型的数组。 import java.util.Arrays; public class Main { public static void main(String[] args) { // 一维数组示例 int[] oneD = {1, 2, 3, 4, 5}; System.out.println("一维数组输出: " + Arrays.toString(oneD)); // 二维数组示例 int[][] twoD = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; // 使用 Arrays.deepToString() 输出二维数组 System.out.println("二维数组输出: " + Arrays.deepToString(twoD)); } } 自定义对象的toString() 方法 每个 Java 对象默认都有 toString() 方法(可以根据需要覆盖) 当直接打印一个没有重写 toString() 方法的对象时,其输出格式通常为: java.lang.Object@15db9742 当打印重写toString() 方法的对象时: class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{name='" + name + "', age=" + age + "}"; } } public class Main { public static void main(String[] args) { Person person = new Person("Alice", 30); System.out.println(person); //会自动调用对象的 toString() 方法 //Person{name='Alice', age=30} } } 类加载器和获取资源文件路径 在Java中,类加载器的主要作用是根据**类路径(Classpath)**加载类文件以及其他资源文件。 类路径是JVM在运行时用来查找类文件和资源文件的一组目录或JAR包。在许多项目(例如Maven或Gradle项目)中,src/main/resources目录下的内容在编译时会被复制到输出目录(如target/classes),src/main/java 下编译后的 class 文件也会放到这里。 src/ ├── main/ │ ├── java/ │ │ └── com/ │ │ └── example/ │ │ └── App.java │ └── resources/ │ ├── application.yml │ └── static/ │ └── logo.png └── test/ ├── java/ │ └── com/ │ └── example/ │ └── AppTest.java └── resources/ └── test-data.json 映射到 target/ 后: target/ ├── classes/ ← 主代码和资源的输出根目录 │ ├── com/ │ │ └── example/ │ │ └── App.class ← 编译自 src/main/java/com/example/App.java │ ├── application.yml ← 复制自 src/main/resources/application.yml │ └── static/ │ └── logo.png ← 复制自 src/main/resources/static/logo.png └── test-classes/ ← 测试代码和测试资源的输出根目录 ├── com/ │ └── example/ │ └── AppTest.class ← 编译自 src/test/java/com/example/AppTest.java └── test-data.json ← 复制自 src/test/resources/test-data.json // 获取 resources 根目录下的 emp.xml 文件路径 String empFileUrl = this.getClass().getClassLoader().getResource("emp.xml").getFile(); // 获取 resources/static 目录下的 tt.img 文件路径 URL resourceUrl = getClass().getClassLoader().getResource("static/tt.img"); String ttImgPath = resourceUrl != null ? resourceUrl.getFile() : null; this.getClass():获取当前对象(即调用该代码的对象)的 Class 对象。 .getClassLoader():获取该 Class 对象的类加载器(ClassLoader)。 .getResource("emp.xml"):从类路径中获取名为 "emp.xml" 的资源,并返回一个 URL 对象,该 URL 对象指向 "emp.xml" 文件的位置。 .getFile():从 URL 对象中获取文件路径部分,即获取 "emp.xml" 文件的绝对路径字符串。 **类路径(Classpath)**是 Java 虚拟机(JVM)用于查找类文件和其他资源文件的一组路径。 类加载器的主要作用之一就是从类路径中加载类文件和其他资源文件。 反射 反射技术,指的是加载类的字节码到内存,并以编程的方法解刨出类中的各个成分(成员变量、方法、构造器等)。 反射技术例子:IDEA通过反射技术就可以获取到类中有哪些方法,并且把方法的名称以提示框的形式显示出来,所以你能看到这些提示了。 1.获取类的字节码(Class对象):有三种方法 public class Test1Class{ public static void main(String[] args){ Class c1 = Student.class; System.out.println(c1.getName()); //获取全类名:edu.whut.pojo.Student System.out.println(c1.getSimpleName()); //获取简单类名: Student Class c2 = Class.forName("com.itheima.d2_reflect.Student"); //全类名 System.out.println(c1 == c2); //true Student s = new Student(); Class c3 = s.getClass(); System.out.println(c2 == c3); //true } } 2.获取类的构造器 定义类 public class Cat{ private String name; private int age; public Cat(){ } private Cat(String name, int age){ } } 获取构造器列表 public class TestConstructor { @Test public void testGetAllConstructors() { // 1. 获取类的 Class 对象 Class<?> c = Cat.class; // 2. 获取类的全部构造器(包括public、private等) Constructor<?>[] constructors = c.getDeclaredConstructors(); // 3. 遍历并打印构造器信息 for (Constructor<?> constructor : constructors) { System.out.println( constructor.getName() + " --> 参数个数:" + constructor.getParameterCount() ); } } } c.getDeclaredConstructors() 会返回所有声明的构造器(包含私有构造器),而 c.getConstructors() 只会返回公共构造器。 constructor.getParameterCount() 用于获取该构造器的参数个数。 获取某个构造器:指定参数类型! public class Test2Constructor(){ @Test public void testGetConstructor(){ //1、反射第一步:必须先得到这个类的Class对象 Class c = Cat.class; /2、获取private修饰的有两个参数的构造器,第一个参数String类型,第二个参数int类型 Constructor constructor = c.getDeclaredConstructor(String.class,int.class); constructor.setAccessible(true); //禁止检查访问权限,可以使用private构造函数 Cat cat=(Cat)constructor.newInstance("叮当猫",3); //初始化Cat对象 } } c.getDeclaredConstructor(String.class, int.class):根据参数列表获取特定的构造器。 如果构造器是private修饰的,先需要调用setAccessible(true) 表示禁止检查访问控制,然后再调用newInstance(实参列表) 就可以执行构造器,完成对象的初始化了。 3.获取类的成员变量 不管是设置值还是获取值,都需要: 拿到 Field 对象。 指定操作哪个对象的该字段。 对于私有字段,还需要调用 setAccessible(true) 来关闭访问检查。 4.获取类的成员方法 获取单个指定的成员方法:第一个参数填方法名、第二个参数填方法中的参数类型 执行:第一个参数传入一个对象,然后是若干方法参数(无参可不写)... 示例:Cat 类与测试类 public class Cat { private String name; public int age; public Cat() { this.name = "Tom"; this.age = 1; } public void meow() { System.out.println("Meow! My name is " + this.name); } private void purr() { System.out.println("Purr... I'm a happy cat!"); } } import org.junit.Test; import java.lang.reflect.Field; import java.lang.reflect.Method; public class FieldReflectionTest { @Test public void testFieldAccess() throws Exception { // 1. 获取 Cat 类的 Class 对象 Class<?> catClass = Cat.class; // 2. 创建 Cat 对象实例 Cat cat = new Cat(); // ---------------------- // A. 获取 public 字段 // ---------------------- Field ageField = catClass.getField("age"); // 只能获取public字段 System.out.println("初始 age = " + ageField.get(cat)); // 读取 age 的值 // 设置 age 的值 ageField.set(cat, 5); System.out.println("修改后 age = " + ageField.get(cat)); // ---------------------- // B. 获取 private 字段 // ---------------------- Field nameField = catClass.getDeclaredField("name"); // 获取私有字段 nameField.setAccessible(true); // 关闭权限检查 System.out.println("初始 name = " + nameField.get(cat)); // 设置 name 的值 nameField.set(cat, "Jerry"); System.out.println("修改后 name = " + nameField.get(cat)); } @Test public void testMethodAccess() throws Exception { // 1. 获取 Cat 类的 Class 对象 Class<?> catClass = Cat.class; // 2. 创建 Cat 对象实例 Cat cat = new Cat(); // ---------------------- // A. 获取并调用 public 方法 // ---------------------- // 获取名为 "meow"、无参数的方法 Method meowMethod = catClass.getMethod("meow"); // 调用该方法 meowMethod.invoke(cat); // ---------------------- // B. 获取并调用 private 方法 // ---------------------- // 获取名为 "purr"、无参数的私有方法 Method purrMethod = catClass.getDeclaredMethod("purr"); purrMethod.setAccessible(true); // 关闭权限检查 purrMethod.invoke(cat); } } 注解 在 Java 中,注解用于给程序元素(类、方法、字段等)添加元数据,这些元数据可被编译器、工具或运行时反射读取,以实现配置、检查、代码生成以及框架支持(如依赖注入、AOP 等)功能,而不直接影响代码的业务逻辑。 比如:Junit框架的@Test注解可以用在方法上,用来标记这个方法是测试方法,被@Test标记的方法能够被Junit框架执行。 再比如:@Override注解可以用在方法上,用来标记这个方法是重写方法,被@Override注解标记的方法能够被IDEA识别进行语法检查。 使用注解 定义注解 使用 @interface 定义注解 // 定义注解 @Retention(RetentionPolicy.RUNTIME) // 定义注解的生命周期 @Target(ElementType.METHOD) // 定义注解可以应用的Java元素类型 public @interface MyAnnotation { // 定义注解的元素(属性) String description() default "This is a default description"; int value() default 0; } 元注解 是修饰注解的注解。 @Retention(RetentionPolicy.RUNTIME) //指定注解的生命周期,即在运行时有效,可用于反射等用途。 @Target(ElementType.METHOD) //方法上的注解 @Target(ElementType.TYPE) //类上的注解(包含类、接口、枚举等类型) 简化使用:如果注解中只有一个属性需要设置,而且该属性名为 value,则在使用时可以省略属性名 @MyAnnotation(5) // 等同于 @MyAnnotation(value = 5) public void someMethod() { // 方法实现 } 当需要为注解的多个属性赋值时,传参必须指明属性名称: @MyAnnotation(value = 5, description = "Specific description") public void anotherMethod() { // 方法实现 } 如果所有属性都使用默认值,可以直接使用注解而不传入任何参数: @MyAnnotation public void anotherMethod() { // 方法实现 } 解析注解 public class MyClass { @MyAnnotation(value = "specific value") public void myMethod() { // 方法实现 } } import java.lang.reflect.Method; public class AnnotationReader { public static void main(String[] args) throws NoSuchMethodException { // 获取MyClass的Class对象 Class<MyClass> obj = MyClass.class; // 获取myMethod方法的Method对象 Method method = obj.getMethod("myMethod"); // 获取方法上的MyAnnotation注解实例 MyAnnotation annotation = method.getAnnotation(MyAnnotation.class); if (annotation != null) { // 输出注解的value值 System.out.println("注解的value: " + annotation.value()); } } } 快速检查某个注解是否存在于method 上 if (method.isAnnotationPresent(MyAnnotation.class)) { // 如果存在MyAnnotation注解,则执行相应逻辑 } 检查方法 method 上是否存在 MyAnnotation 注解。如果存在,就返回该注解的实例,否则返回 null MyAnnotation annotation = method.getAnnotation(MyAnnotation.class); Junit 单元测试 步骤 1.导入依赖 将 JUnit 框架的 jar 包添加到项目中(注意:IntelliJ IDEA 默认集成了 JUnit,无需手动导入)。 2.编写测试类 为待测业务方法创建对应的测试类。 测试类中定义测试方法,要求方法必须为 public 且返回类型为 void。 3.添加测试注解 在测试方法上添加 @Test 注解,确保 JUnit 能自动识别并执行该方法。 4.运行测试 在测试方法上右键选择“JUnit运行”。 测试通过显示绿色标志; 测试失败显示红色标志。 public class UserMapperTest { @Test public void testListUser() { UserMapper userMapper = new UserMapper(); List<User> list = userMapper.list(); Assert.assertNotNull("User list should not be null", list); list.forEach(System.out::println); } } 注意,如果需要使用依赖注入,需要在测试类上加@SpringBootTest注解 它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如自动装配、依赖注入、配置加载等 @RunWith(SpringRunner.class) @SpringBootTest public class UserMapperTest { @Autowired private UserMapper userMapper; @Test public void testListUser() { List<User> list = userMapper.list(); Assert.assertNotNull("User list should not be null", list); list.forEach(System.out::println); } } 写了@Test注解,那么该测试函数就可以直接运行!若一个测试类中写了多个测试方法,可以全部执行! 原理可能是: //自定义注解 @Retention(RetentionPolicy.RUNTIME) //指定注解在运行时可用,这样才能通过反射获取到该注解。 @Target(ElementType.METHOD) //指定注解可用于方法上。 public @interface MyTest { } public class AnnotationTest4 { @MyTest public void test() { System.out.println("===test4==="); } public static void main(String[] args) throws Exception { AnnotationTest4 a = new AnnotationTest4(); Class<?> c = AnnotationTest4.class; // 获取当前类中声明的所有方法 Method[] methods = c.getDeclaredMethods(); // 遍历方法,检查是否使用了 @MyTest 注解 for (Method method : methods) { if (method.isAnnotationPresent(MyTest.class)) { // 如果标注了 @MyTest,就通过反射调用该方法 method.invoke(a); } } } } 在Springboot中,如何快速生成单元测试? 选中类名,右键: 对象拷贝属性 public void save(EmployeeDTO employeeDTO) { Employee employee = new Employee(); //对象属性拷贝 BeanUtils.copyProperties(employeeDTO, employee); } employeeDTO的内容拷贝给employee StartOrStopDTO dto = new StartOrStopDTO(1, 100L); // 用 Builder 拷贝 id 和 status Employee employee = Employee.builder() .id(dto.getId()) .status(dto.getStatus()) .build();
自学
zy123
3月21日
0
0
0
上一页
1
2
3
...
5
下一页