首页
关于
Search
1
同步本地Markdown至Typecho站点
160 阅读
2
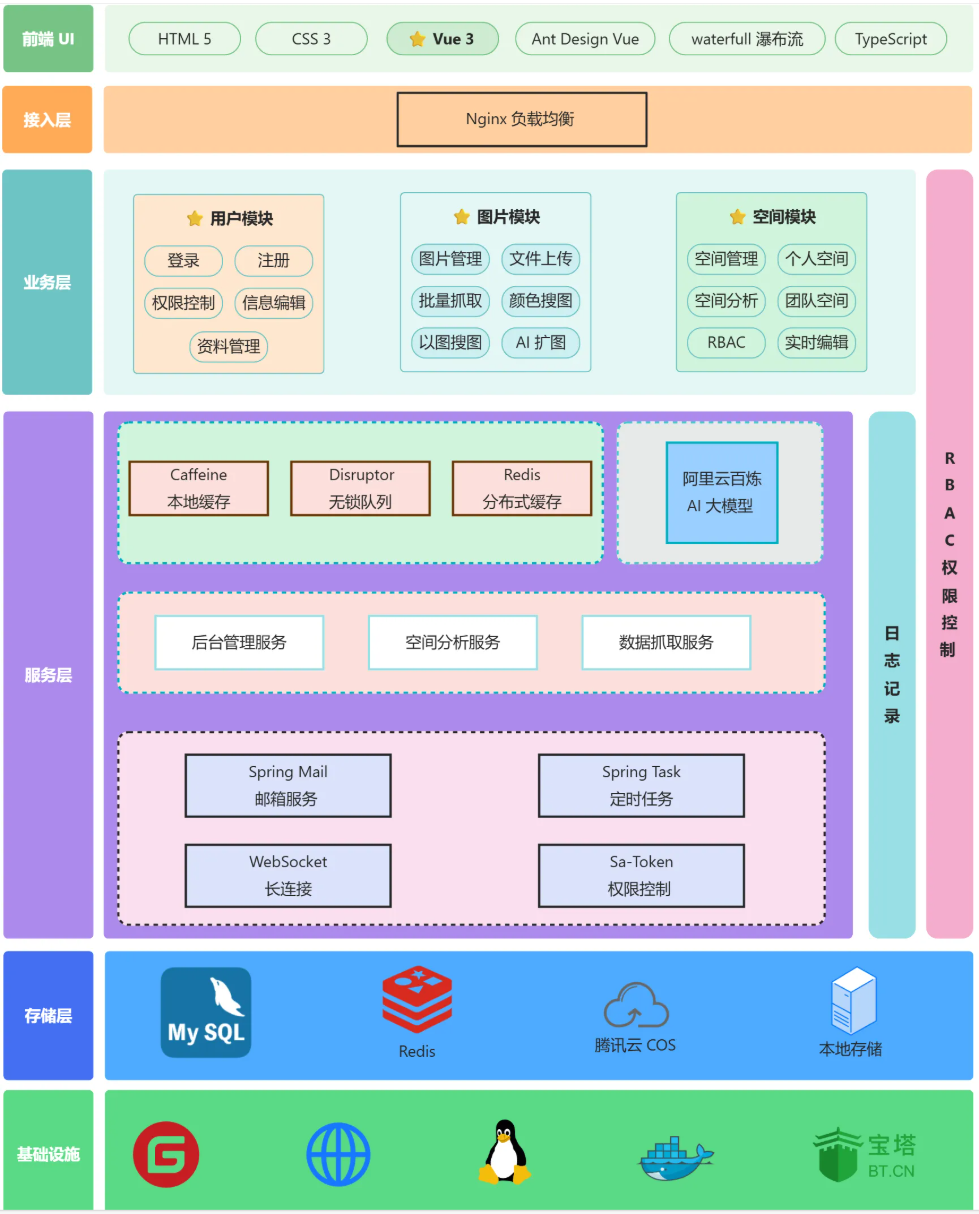
微服务
51 阅读
3
动态图神经网络
48 阅读
4
苍穹外卖
47 阅读
5
JavaWeb——后端
42 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
推荐文章
推荐
拼团设计模式
项目
1年前
0
16
0
推荐
拼团交易系统
项目
1年前
0
48
1
推荐
Smile云图库
项目
1年前
0
69
0
热门文章
160 ℃
同步本地Markdown至Typecho站点
项目
1年前
0
160
0
51 ℃
微服务
后端学习
1年前
0
51
0
48 ℃
动态图神经网络
论文
1年前
0
48
0
最新发布
2026-05-08
Mac快捷键与技巧
Mac 快捷键与使用技巧 修饰键速查 符号 键名 角色 ⌘ Command 系统级快捷键(最常用) ⌥ Option 辅助/扩展功能、特殊字符输入 ⌃ Control 终端里的主力、模拟右键 ⇧ Shift 扩展选择、反向操作 记忆诀窍:在终端里用 Control(跟 Linux 习惯一致),其他地方用 Command。 一、系统级 快捷键 作用 ⌘ + Space 聚焦搜索(Spotlight),秒开应用/算数/查汇率 ⌘ + Tab 切换应用 ⌘ + ` 同一应用内切换窗口(Tab 上方那个键) ⌘ + W 关闭当前窗口/标签页 ⌘ + Q 完全退出应用 ⌘ + H 隐藏当前应用 ⌘ + M 最小化窗口 ⌘ + , 打开偏好设置(几乎所有应用通用) ⌘ + ⌥ + Esc 强制退出应用 ⌘ + ⇧ + 3 全屏截图 ⌘ + ⇧ + 4 区域截图(按空格后可截窗口) ⌘ + ⇧ + 5 截图工具栏(含录屏) 二、文本编辑(macOS 全系统通用) 这些是 Emacs 风格的快捷键,任何文本框都能用,包括浏览器地址栏、IDE、微信。 快捷键 作用 ⌃ + A 跳到行首 ⌃ + E 跳到行尾 ⌃ + K 删除光标到行尾 ⌃ + U 删除整行 ⌃ + W 向前删除一个词 ⌃ + H 删除光标前一个字符 ⌃ + D 删除光标后一个字符 ⌃ + F / B 前进/后退一个字符 ⌃ + N / P 下一行/上一行 ⌥ + ←/→ 按单词跳转 ⌥ + Delete 删除前一个单词 ⌘ + ←/→ 跳到行首/行尾 ⌘ + ↑/↓ 跳到文档开头/结尾 ⇧ + 方向键 选中文本(配合上面任意跳转即可精确选中) 重点记住:⌃A/E 行首行尾、⌥←/→ 按词跳、⌘←/→ 行首行尾。 三、Finder(文件管理器) 快捷键 作用 ⌘ + N 新 Finder 窗口 ⌘ + ⇧ + G 前往文件夹(输入路径) ⌘ + ⇧ + H 前往用户主目录 ⌘ + ⇧ + . 显示/隐藏隐藏文件 ⌘ + Delete 删除文件到废纸篓 ⌘ + I 查看文件信息 ⌘ + ⌥ + Space 在当前目录打开终端(需先在 Finder 偏好设置里加) 空格 快速预览文件(Quick Look) 回车 重命名文件(不是打开!) 技巧:把常用文件夹拖到 Finder 侧边栏,从终端 open . 用 Finder 打开当前目录。 四、终端 快捷键 作用 ⌃ + A / E 行首 / 行尾 ⌃ + K / U 删到行尾 / 删整行 ⌃ + W 删前一个词 ⌃ + C 终止当前命令 ⌃ + D 退出 shell(或发送 EOF) ⌃ + R 反向搜索历史命令 ⌃ + L 清屏(等同于 clear) ⌥ + 点击 光标快速定位 ⌘ + D 分屏(iTerm2 和系统终端都支持) ⌘ + T 新建标签页 ⌘ + 数字 切换标签页 ⌘ + Enter 全屏终端 五、浏览器(Safari / Chrome / Edge 通用) 快捷键 作用 ⌘ + T 新建标签页 ⌘ + W 关闭当前标签页 ⌘ + ⇧ + T 恢复刚关闭的标签页 ⌘ + 数字 切换到第 N 个标签页 ⌘ + 9 切换到最后一个标签页 ⌘ + L 聚焦地址栏 ⌘ + R 刷新 ⌘ + ⇧ + R 强制刷新(清除缓存) ⌘ + ←/→ 前进/后退 ⌘ + D 添加书签 ⌘ + ⌥ + ←/→ 切换标签页 六、截图(macOS 自带) 快捷键 作用 ⌘ + ⇧ + 3 全屏截图 ⌘ + ⇧ + 4 区域截图 ⌘ + ⇧ + 4 再按空格 截取单个窗口(带阴影) ⌘ + ⇧ + 5 截图工具栏(可录屏) ⌘ + ⇧ + 6 截 Touch Bar(如有) 截图时按住 ⌥ 取消吸附边缘 截图时按住 ⇧ 锁定水平/垂直方向 截图默认保存到桌面。改路径:⌘ + ⇧ + 5 → 选项 → 存储位置。 七、窗口管理 macOS 窗口管理偏弱,推荐装 Rectangle(免费开源),也可以记原生能力: 快捷键 作用 ⌘ + ⌃ + F 全屏/退出全屏 长按窗口左上角绿色按钮 分屏(选择左右位置) ⌘ + ~ 同应用窗口间切换 八、开发相关技巧 访达里直接到终端:在 Finder 中右键文件夹 → 服务 → 新建位于文件夹位置的终端窗口(如没有去系统设置 → 键盘 → 快捷键 → 服务里开启) 终端里直接到访达:open . 用 Finder 打开当前目录,open 文件名 用默认应用打开 复制文件路径:Finder 中右键文件,按住 ⌥ 键,"拷贝"会变成"拷贝路径名" 粘贴纯文本:⌘ + ⇧ + ⌥ + V(去掉格式) 重命名:选中文档按回车即可重命名(新手常误以为要右键) Spotlight 直接算数:⌘ + Space 后输入 3.14*2,省掉计算器 Spotlight 查单词:⌘ + Space 后输入英文单词,直接出词典定义 三指拖移:系统设置 → 辅助功能 → 指针控制 → 触控板选项 → 开启三指拖移(拖窗口不用按住点击) 轻点点击:系统设置 → 触控板 → 轻点来点按(省力,不用按下去) Hot Corners(触发角):系统设置 → 桌面与程序坞 → 触发角 → 把鼠标甩到屏幕四角触发操作(比如锁屏、显示桌面) 九、Command / Control / Option 怎么区分 场景 主力键 说明 复制粘贴等日常操作 ⌘ Command macOS 的操作键,等价于 Windows 的 Ctrl 终端(Terminal / iTerm2) ⌃ Control 和 Linux 一致,⌘ 在终端里是标签页/窗口操作 特殊字符输入 ⌥ Option 比如 ⌥ + 2 = ™,⌥ + G = © 右键菜单 ⌃ Control + 点击 单指点按触控板等于右键 隐藏/显示文件 ⌘ ⇧ . 在 Finder 和打开文件对话框中都有效 Emacs 风格文本跳转 ⌃ Control ⌃A/E/K 在任何文本框都通用 一句话:GUI 里 ⌘ 是王者,终端里 ⌃ 是王者,⌥ 是补刀。 十、终端小贴士(给 Java 程序员) # 回到上级目录 cd - # sudo 用 Touch ID(不用输密码) sudo sed -i '' '2s/^/auth sufficient pam_tid.so\n/' /etc/pam.d/sudo # 管道到剪贴板 cat somefile | pbcopy # 剪贴板输出 pbpaste # 查看本机 IP ipconfig getifaddr en0 # 查看端口占用 lsof -i :8080 # 递归查找文件内容(比 find + grep 更好用) grep -r "某个注解" --include="*.java" . 刚开始不用全记,先记住 ⌘Space、⌘Tab、⌃A/E、⌥←/→ 这几个使用频率最高的,其他用到再查就行。
杂项
zy123
5天前
0
2
0
2026-04-29
claude_code_快速上手
Claude Code 快速上手指南 是什么 Claude Code 是 Anthropic 官方的命令行 AI 编程助手。直接在终端里和它对话,让它帮你写代码、改 bug、重构、查代码库。 # 安装 & 启动 npm install -g @anthropic-ai/claude-code claude 基本用法 直接输入自然语言就行,比如: > 帮我看看这个项目的目录结构 > 修复 utils.py 里的那个 bug > 给 login 接口加参数校验 它有权限控制,执行危险操作(删文件、推送代码)前会问你确认。 常用斜杠命令 命令以 / 开头,随时可输入: 命令 作用 /help 查看所有可用命令 /status 查看版本、模型、登录状态 /clear 清空对话,重新开始 /compact 压缩对话上下文,释放空间(对话太长时用) /cost 查看本次会话花了多少钱 /model 切换模型(Opus / Sonnet / Haiku) /init 在当前项目生成 CLAUDE.md 配置文件 /memory 编辑 CLAUDE.md,给项目添加持久记忆 /config 设置主题、输出格式等偏好 /permissions 管理工具权限规则 /diff 查看当前未提交的改动 /review 审查 PR /doctor 诊断安装是否正常 /resume 恢复之前的对话 快捷键 快捷键 作用 Esc 中断当前生成 Ctrl+C 取消当前输入 Ctrl+D 退出 Claude Code Tab 自动补全 ↑ / ↓ 浏览历史输入 Shift+Tab 切换权限模式 Ctrl+G 用外部编辑器写 prompt(写长需求时好用) Skills(技能) Skills 是可扩展的自定义命令,本质上是放在特定目录下的 SKILL.md 文件。Claude Code 自带了一些内置 skill(如 /review、/simplify),你也可以安装社区或自己写。 查看 & 使用 /skills — 列出当前所有可用 skills 直接输入 /<skill名称> 即可调用,比如 /review 某些 skill 会根据对话上下文自动触发,无需手动输入 安装 Skills 的三种方式 方式一:GitHub 下载,手动粘贴 从 GitHub 上把 skill 文件夹下载下来,直接复制到 skills 目录即可: # 全局安装(所有项目可用) cp -r 下载的skill文件夹 ~/.claude/skills/ # 项目级安装(仅当前项目,可 Git 提交共享给团队) cp -r 下载的skill文件夹 .claude/skills/ 方式二:npx skills 命令行安装(社区生态) 社区维护的命令行工具,一条命令搞定安装和管理: # 安装社区 skill npx skills add vercel/frontend-design # 从 GitHub 仓库中安装特定 skill npx skills add anthropics/skills --skill document-skills # 静默安装(跳过交互确认) npx skills add <仓库> --skill <名称> -g -y # 管理已安装的 skills npx skills list # 查看已安装 npx skills update # 更新 npx skills remove <名> # 删除 -g 表示安装到全局(所有项目可用),不加则仅当前项目。安装时会提示选择 AI 工具(选中 Claude Code 即可)。 技能市场:skills.sh — 5 万+ 可复用技能 方式三:自己手写 每个 skill 就是一个文件夹,核心是里面的 SKILL.md 文件: ~/.claude/skills/my-skill/ ├── SKILL.md # 必需:技能定义 ├── scripts/ # 可选:辅助脚本 └── resources/ # 可选:资源文件 SKILL.md 格式示例: --- name: my-skill description: 一句话描述,用于 Claude 自动匹配触发 --- ## 使用步骤 1. 第一步做什么 2. 第二步做什么 写好放到 ~/.claude/skills/(全局)或 .claude/skills/(仅当前项目),重启 Claude Code 即可使用。 注意事项 项目级 > 全局级:同名 skill,项目级优先 Skills 是"教模型怎么做事"(行为规范),MCP 是"给模型工具"(能力供给),两者不同但互补 从非可信来源安装前,建议看一眼 SKILL.md 内容,确认没有恶意指令 几个核心概念(一句话版) CLAUDE.md — 项目级配置文件,告诉 Claude 这个项目的约定和规则,类似 .cursorrules Memory — 自动记忆你的偏好和项目上下文,下次对话也能用 Hooks — 在特定事件(工具调用前后)自动执行的脚本 MCP Servers — 连接外部工具(数据库、API 等)的协议,扩展 Claude 的能力 settings.json — 权限、环境变量等底层配置 新手建议 不知道问什么就 /help,上面列了所有命令 对话太长时 /compact,不然会变慢变贵 项目根目录跑一下 /init,生成 CLAUDE.md 后 Claude 会更懂你的项目 写长需求用 Ctrl+G,打开编辑器慢慢写比在终端里敲舒服 大胆用自然语言描述,不需要写得很精确,它理解能力很强 @文件名 可以在 prompt 里直接引用文件,比如 @src/main.py 帮我重构这个文件
杂项
zy123
4月29日
0
5
0
2026-04-29
agent-browser - AI 专用浏览器自动化工具
title: agent-browser - AI 专用浏览器自动化工具 date: 2026-01-24 tags: 技术学习 浏览器自动化 Vercel Rust AI工具 Agent status: learning source: 归档/Clippings/完爆 Playwright?Vercel 开源 agent-browser,Context 节省 93%.md github: https://github.com/vercel-labs/agent-browser author: Chris Tate (Vercel Labs) agent-browser - AI 专用浏览器自动化工具 Vercel Labs 开源的浏览器自动化 CLI,专为 AI Agent 设计。核心思路是返回可访问性树(Accessibility Tree) 代替完整 HTML,大幅降低 Token 消耗。 核心优势 节省 93% Context:相比 Playwright MCP 语义化交互:返回可访问性树而非 HTML,AI 更好理解 Ref 引用系统:自动为元素打标签(@e1、@e2),AI 可直接引用 Rust CLI + Node 守护进程:首次启动 ~2s,后续命令 <100ms 核心工作流 # 1. 打开网页 agent-browser open example.com # 2. 获取 Snapshot(可访问性树 + 引用) agent-browser snapshot -i # - heading "Welcome" [ref=e1] # - button "Sign In" [ref=e4] # 3. 用 Ref 操作(不需要 CSS 选择器) agent-browser fill @e2 "user@example.com" agent-browser click @e4 安装 npm install -g agent-browser agent-browser install # 下载 Chromium 与 Claude Code 集成 已安装到 ~/.claude/skills/agent-browser/,Claude 会自动在需要的场景加载。也可手动调用使用。 对比 特性 agent-browser Playwright MCP 输出 可访问性树(~7% Tokens) 完整 HTML(100%) 选择器 Ref + 语义 + CSS CSS/Text/XPath 性能 Rust CLI + Node 守护进程 纯 Node AI 友好度 ⭐⭐⭐⭐⭐ ⭐⭐⭐ 原理 传统方式:返回完整 HTML(几千行)→ AI 自行解析 DOM agent-browser:返回可访问性树 → "这里有个按钮叫 Submit" AI 不需要在装饰性 HTML 中找关键信息,语义化输出让 Context 更聚焦。 场景 AI Agent 控制浏览器 表单自动填写 / 数据抓取 / 自动化测试 Electron 桌面应用自动化(VS Code、Slack 等) 学习总结 核心理念:不给 AI 看代码,给 AI 看"语义"。93% 的 Context 节省来自这个思路转变。 适用:AI Agent 场景强烈推荐;传统自动化测试 Playwright 生态更成熟,按需选择。 相关资源 GitHub:https://github.com/vercel-labs/agent-browser 本地 Skill 位置:~/.claude/skills/agent-browser/
杂项
zy123
4月29日
0
4
0
2026-04-29
planning-with-files - 复刻 Manus 上下文工程的开源插件
title: planning-with-files - 复刻 Manus 上下文工程的开源插件 date: 2026-02-02 tags: 技术学习 Agent Claude-Code 上下文工程 Manus 开源项目 status: learning source: 归档/Clippings/暴涨11.7k Star!复刻Manus上下文工程的开源Skills,Claude code等多个平台即插即用.md github: https://github.com/OthmanAdi/planning-with-files planning-with-files - 复刻 Manus 上下文工程的开源插件 开源插件,复刻了 Manus 的上下文工程方法论——用磁盘文件代替上下文窗口做"工作记忆",解决 AI 智能体失忆、迷航、重复犯错三大痛点。GitHub 11.7k+ Stars。 核心思想 任何重要信息都应写入磁盘,而非依赖易失且有限的上下文窗口。 LLM 上下文窗口 = 内存(易失、有限) 磁盘文件 = 硬盘(持久、无限) 三文件架构 文件 作用 更新时机 task_plan.md 阶段划分、进度状态、错误记录 每个阶段完成后 findings.md 调研结果、关键发现 查看/搜索/浏览操作后 progress.md 会话日志、测试结果 整个过程中持续记录 六大原则 先计划后执行:复杂任务必须先有 task_plan.md 及时写入发现:每 2 次查看/搜索/浏览后,立即写入 findings.md 决策前回顾目标:关键决策前重新读取 task_plan.md 阶段完成必更新:标记完成状态、记录错误和修改的文件 记录所有错误:持久化错误日志,避免重复踩坑 绝不重复失败:同一操作失败后换方案,记录尝试历史 安装 已通过 ~/.claude/skills/planning-with-files/ 安装。包含中文 SKILL.md、辅助脚本和模板文件。 也可在 Claude Code 内通过命令安装: /plugin marketplace add OthmanAdi/planning-with-files /plugin install planning-with-files@planning-with-files 使用场景 多步骤任务(3 步以上) 研究型任务(信息收集、分析、整理) 涉及大量工具调用的复杂工作流 研究或开发,需要断点续做的场景 学习总结 Manus 的方法论本质是用工程约束弥补模型缺陷——不追求让 AI 更聪明,而是让它更可靠地执行流程。三个文件看似简单,但 hooks 机制在每次工具调用前后自动读/写计划文件,形成了"读→做→写→审"的执行闭环,这是真正有效的关键。 参考资源 GitHub:https://github.com/OthmanAdi/planning-with-files 本地 Skill 位置:~/.claude/skills/planning-with-files/
杂项
zy123
4月29日
0
6
0
2026-04-11
PCA降维
PCA 1. 核心目的 以少胜多:用最少的维度(特征),保留原始数据中最重要的信息。 2. 核心假设(PCA 的世界观) 方差 = 信息:PCA 认为,数据变化越大(方差越大)的方向,包含的信息越多;反之,如果数据在某个方向上一动不动,那个方向就是无用的(或噪声)。 数据挤在一起 = 没有信息:如果全班同学的数学成绩都是 90 分(数据不分散),那“数学成绩”这个特征就没法用来区分好学生和差学生,它就是无用的。 数据分散 = 信息丰富:如果成绩从 30 分到 100 分都有(数据很分散),这个特征就非常有价值。 线性关系:PCA 假设数据的主要特征是可以通过线性的坐标旋转找到的。 3. 运作逻辑(三步走) 换视角(坐标变换):不再沿用原来的 x, y, z 轴,而是重新建立一套坐标系。 找主次(最大方差): 第一主成分 (PC1):找到数据拉得最长、波动最大的方向。 第二主成分 (PC2):在与 PC1 垂直(正交)的方向中,找波动最大的。 (以此类推,保证新特征之间互不干扰/无相关性) 做减法(投影截断):保留排在前面的几个主成分(比如前 2 个),把后面那些波动很小的主成分直接丢弃。 示例 学生 数学 (x) 物理 (y) 特点 A 2 3 学渣 B 3 4 也是学渣 C 5 5 普通人 D 8 7 学霸 E 9 8 超级学霸 第一步:中心化 (移到原点) PCA 不喜欢处理偏离原点的数据。我们算出平均分(数学 5.4,物理 5.4),然后把所有人的分数减去平均分。 目的:让数据的中心变成 $(0,0)$,方便旋转坐标轴。 效果:C 同学变成了 $( -0.4, -0.4)$,接近原点。 学生 新数学 (x′) 新物理 (y′) 含义解读 A -3.4 -2.4 比平均分低很多 (都在第三象限) B -2.4 -1.4 比平均分低一些 C -0.4 -0.4 非常接近原点 (0,0),代表普通人 D 2.6 1.6 比平均分高一些 E 3.6 2.6 比平均分高很多 (都在第一象限) 第二步:找主成分 (寻找新坐标轴) 现在把这 5 个点画在图上。你会发现这些点并不是乱跑的,而是沿着一条斜线(左下到右上)排列。 因为数学和物理在这个例子里同等重要,且变化幅度相似,PCA 算出的方向向量大约是: 数学的权重 ($w_1$):0.71 物理的权重 ($w_2$):0.71 注:这两个数在数学上叫“特征向量”,且 $0.71^2 + 0.71^2 \approx 1$(单位向量)。 PCA 会自动找到两条新的坐标轴: PC1(第一主成分):沿着数据分布最长的那条斜线。 $$PC1得分 = (\text{中心化数学} \times 0.71) + (\text{中心化物理} \times 0.71)$$ 含义:这代表了“理科综合能力”。(分数高的一起高,低的描述一起低)。 方差:数据在这个方向上拉得很开(方差大),保留了 95% 的信息。 PC2(第二主成分):垂直于 PC1 的方向。 含义:这代表了“偏科程度”(比如数学比物理好多少)。 方差:数据在这个方向上波动很小(大家数学物理差值都不大),只占 5% 的信息。 第三步:投影与降维 (做减法) 现在我们决定从 2 维降到 1 维。 因为 PC1 包含了 95% 的信息,而 PC2 只有 5%(可能是因为那天考试状态的小波动),我们决定保留 PC1,扔掉 PC2。 我们将所有点垂直投影到 PC1 这条线上。 第四步:得到新数据(1维) 现在的学生数据不再是 $(x, y)$ 两个数了,而是一个新的数值 $z$(他们在 PC1 轴上的坐标)。 学生 中心化数学 (x′) 中心化物理 (y′) 计算过程 (投影) 新数值 (z) 状态 A -3.4 -2.4 $(-3.4 \times 0.71) + (-2.4 \times 0.71)$ -4.12 低 B -2.4 -1.4 $(-2.4 \times 0.71) + (-1.4 \times 0.71)$ -2.70 低 C -0.4 -0.4 $(-0.4 \times 0.71) + (-0.4 \times 0.71)$ -0.57 中 D +2.6 +1.6 $(+2.6 \times 0.71) + (+1.6 \times 0.71)$ +2.98 高 E +3.6 +2.6 $(+3.6 \times 0.71) + (+2.6 \times 0.71)$ +4.40 极高 **为什么可以这样?**只要两个特征之间有很强的关系,PCA 就可以把它们合并成一个维度。
科研
zy123
4月11日
0
5
0
1
2
...
13
下一页