首页
关于
Search
1
图神经网络
11 阅读
2
微服务
10 阅读
3
微信小程序
10 阅读
4
欢迎使用 Typecho
9 阅读
5
数学基础
8 阅读
默认分类
科研
自学
登录
找到
24
篇与
科研
相关的结果
- 第 4 页
2025-03-21
PID控制器
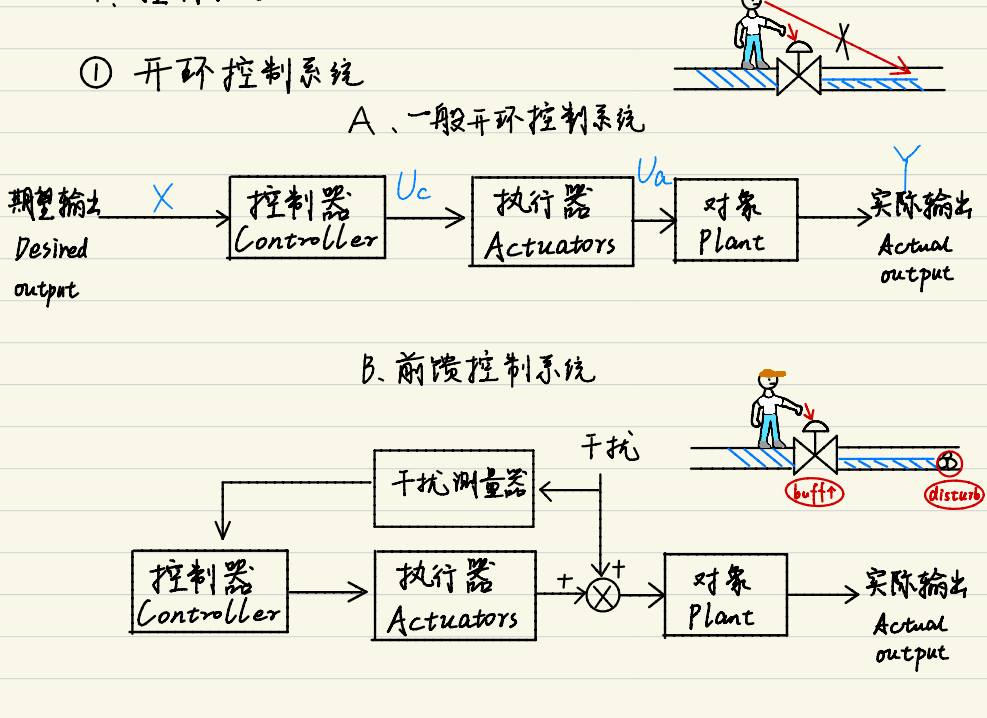
PID控制器 PID控制器是一种常用的反馈控制系统,广泛应用于工业控制系统和各种控制系统中,用来持续调整一个过程的控制输入,以减小系统当前位置和期望位置之间的误差。PID代表比例(Proportional)、积分(Integral)、微分(Derivative)。 控制系统概述 开环控制系统 前馈控制系统尝试预先计算扰动对系统的影响,并在扰动影响系统输出之前调整输入以抵消它。 闭环控制系统 控制器接收误差信号。该系统通过反馈回路来自动调节其输出 复合控制系统 连续与离散信号 从连续信号到离散信号的转换过程涉及以下步骤: 采样:在连续信号上每隔一定时间间隔取一个值。 量化:将每个采样值映射到最接近的量化级上。 积分可以通过求和来近似,微分可以通过相邻样本之间的差分来近似。 PID公式 控制系统中的传感器会连续监测被控制对象的状态(例如,温度、压力、位置等),而PID控制器通过在固定的采样间隔收集输入信号,将其转换为离散信号,计算控制动作,然后输出到控制对象。离散PID控制的优势在于其灵活性和适应性,它可以轻松地与软件算法集成。 直观例子 **仅使用比例(P)控制无法消除稳态误差。**稳态误差是指当系统达到平衡状态时,控制系统的实际输出与期望输出之间的差异。 原因:当系统接近其期望点时,误差减小,进而控制器输出也减小。如果控制器输出减小到无法克服系统内部阻力(如摩擦力)或外部扰动的程度时,系统就无法进一步接近设定点,从而留下稳态误差。 为了解决稳态误差问题,通常会在P控制基础上加入积分(I)控制。积分控制能够累积误差,即使是很小的误差,也会随时间积累,最终产生足够的控制作用以调整系统输出,直到误差为零。 微分控制在PID控制器中的作用主要是提高系统的瞬态响应和稳定性。 $$ {k}_{d}({e}_{i}-{e}_{i-1}) $$ 它通过对误差信号的变化率(即误差的微分)进行响应,来预测系统未来的行为。如果误差在快速变化,微分项会产生一个相对较大的控制作用来尝试减缓这种变化。 相关控制知识 当系统启动时或者遇到大的扰动,会产生大的初始误差。若系统调整缓慢,积分项会在达到目标状态之前累积很大的值。这可导致控制器输出超出了实际的执行器(比如电机、阀门等)可以处理的范围。当这种情况发生时,即使误差减少,由于积分项累积的值太大,控制器的输出可能仍然处于饱和状态。 积分限幅 积分限幅可防止积分项超过预设的上限和下限。 $$ {I}_{clamped}(t)=clamp({I}_{updated(t)},{I}_{max},{I}_{min}) $$ 积分分离 当误差超过某个预定阈值时,禁用积分作用,仅使用比例(P)和微分(D)控制来快速减小误差,避免因积分作用导致的控制器输出过度响应。 if (abs(error) > threshold) { // 积分作用被分离,即暂时禁用积分作用 integral = 0; } else { // 正常积分累积 integral += error * dt; } PID控制器: def update(self, current_value): error = self.set_point - current_value # 实现积分分离逻辑 if abs(error) < self.error_threshold: self.integral += error * self.dt # 应用积分限幅 self.integral = max(min(self.integral, self.integral_limit), -self.integral_limit) else: # 误差过大时重置积分累积 self.integral = 0 derivative = (error - self.prev_error) / self.dt # PID 输出 output = self.Kp * error + self.Ki * self.integral + self.Kd * derivative self.prev_error = error return output
科研
zy123
3月21日
0
2
0
2025-03-21
传统图机器学习
传统图机器学习和特征工程 节点层面的特征工程 目的:描述网络中节点的结构和位置 eg:输入某个节点的D维向量,输出该节点是某类的概率。 节点度 (Node Degree) 定义: 节点度是指一个节点直接连接到其他节点的边数。 无向图中: 节点的度即为与其相邻的节点数。 有向图中: 通常区分为入度(有多少条边指向该节点)和出度(从该节点发出的边的数量)。 意义: 节点度直观反映了节点在网络中的直接连接能力。度高的节点通常在信息传播或资源分配中具有较大作用。 例如,在社交网络中,一个拥有大量好友的用户(高节点度)可能被视为“热门”或者“活跃”的社交人物。 节点中心性 (Node Centrality) 定义: 节点中心性是一类衡量节点在整个网络中“重要性”或“影响力”的指标。其核心思想是,不仅要看节点的直接连接数,还要看它在网络中的位置和在信息流动中的角色。 常见的指标: 介数中心性 (Betweenness Centrality): 衡量节点位于其他节点间最短路径上的频率,反映其作为“桥梁”的作用。 接近中心性 (Closeness Centrality): 衡量节点到网络中其他节点平均距离的倒数,距离越近中心性越高。 特征向量中心性 (Eigenvector Centrality): 除了考虑连接数量外,还考虑邻居节点的“重要性”,连接到重要节点会提升自身的中心性。 举例: 假设有 3 个节点,记为 $1, 2, 3$,它们构成了一条链: $$ 1 \; \leftrightarrow \; 2 \; \leftrightarrow \; 3 $$ 即只有边 $(1,2)$ 和 $(2,3)$,没有直接连接 $(1,3)$。 令邻接矩阵 $A$ 为: $$ A \;=\; \begin{pmatrix} 0 & 1 & 0\\ 1 & 0 & 1\\ 0 & 1 & 0 \end{pmatrix}. $$ 介数中心性(必经之地): $$ \displaystyle c_v \;=\; \sum_{s \neq t}\; \frac{\sigma_{st}(v)}{\sigma_{st}}, $$ 其中 $\sigma_{st}$ 表示从节点 $s$ 到节点 $t$ 的所有最短路径数; $\sigma_{st}(v)$ 表示这些最短路径当中经过节点 $v$ 的条数; 求和一般只考虑 $s \neq t$ 且 $s \neq v \neq t$ 的情形,避免把端点本身算作中间节点。 换言之,节点 $v$ 的介数中心性就是它作为“中间节点”出现在多少对 $(s,t)$ 的最短路径上。 对 3 个节点 ${1,2,3}$,不同的 $(s,t)$ 有: $(s,t)=(1,2)$:最短路径为 $(1,2)$。 路径上节点:1 → 2 中间节点:无 (1、2 是端点) $(s,t)=(1,3)$:最短路径为 $(1,2,3)$。 路径上节点:1 → 2 → 3 中间节点:2 $(s,t)=(2,3)$:最短路径为 $(2,3)$。 路径上节点:2 → 3 中间节点:无 (2、3 是端点) 节点 1 只会出现在路径 (1,2) 或 (1,3) 的端点位置;(2,3) 的最短路径不包含 1。 端点不计作中间节点,所以 $\sigma_{st}(1) = 0$ 对所有 $s\neq t\neq 1$。 因此 $$ c_1 = 0. $$ 节点 2 在 (1,3) 的最短路径 (1,2,3) 中,2 是中间节点。此时 $\sigma_{1,3}(2) = 1$; (1,2) 路径 (1,2) 中 2 是端点,(2,3) 路径 (2,3) 中 2 也是端点,因此不计入中间节点。 所以 $$ c_2 = \underbrace{\frac{\sigma_{1,3}(2)}{\sigma_{1,3}}}_{=1/1=1} ;=; 1. $$ 接近中心性(去哪儿都近): $$ c_v \;=\; \frac{1}{\sum_{u \neq v} d(u,v)}, $$ 其中 $d(u,v)$ 表示节点 $u$ 与节点 $v$ 的最短路径距离。 节点1: 与节点 2 的距离:$d(1,2)=1$。 与节点 3 的距离:$d(1,3)=2$(路径 1→2→3)。 距离和:$;1 + 2 = 3.$ 接近中心性:$; c_1 = \tfrac{1}{3} \approx 0.333.$ 其他两节点同理。 特征向量中心性 特征向量中心性要求我们求解 $$ A\,\mathbf = \lambda\,\mathbf , $$ 并选取对应**最大特征值** $\lambda$ 的特征向量 $\mathbf $ 来代表每个节点的中心性。 记 $\mathbf = (x_1,,x_2,,x_3)^T$ 这里 $x_1$ 是节点 1 的中心性值,$x_2$ 是节点 2 的中心性值,$x_3$ 是节点 3 的中心性值 方程 $A,\mathbf = \lambda,\mathbf $ 具体展开 $$ \begin{pmatrix} 0 & 1 & 0\ 1 & 0 & 1\ 0 & 1 & 0 \end{pmatrix} \begin{pmatrix} x_1\ x_2\ x_3 \end{pmatrix} ;=; \lambda \begin{pmatrix} x_1\ x_2\ x_3 \end{pmatrix}. $$ 这意味着: $$ \begin{cases} 1.; x_2 = \lambda, x_1, \ 2.; x_1 + x_3 = \lambda, x_2, \ 3.; x_2 = \lambda, x_3. \end{cases} $$ 求解最大特征值 $\lambda$ 及对应的 $\mathbf $ 通过特征多项式可知本矩阵的最大特征值为 $\sqrt{2}$。 最终(若需单位化)可以将向量归一化为 $$ \mathbf = \frac{1}{2},\begin{pmatrix} 1 \ \sqrt{2} \ 1 \end{pmatrix}. $$ 解释 节点 2 的得分最高($\tfrac{\sqrt{2}}{2}\approx 0.707$),因为它连接了节点 1 和 3,两边的贡献都能“传递”到它。 节点 1 和 3 的得分相同且略低($\tfrac{1}{2}=0.5$),因为它们都只与节点 2 相连。 聚类系数 (Clustering Coefficient) 定义: 聚类系数描述一个节点的邻居之间彼此相连的紧密程度。 对于某个节点,其局部聚类系数计算为: $$ C = \frac{2 \times \text{实际邻居间的边数}}{k \times (k-1)} $$ 其中 $k$ 为该节点的度数。 意义: 高聚类系数: 表示节点的邻居往往彼此熟识,形成紧密的小团体。 低聚类系数: 则说明邻居之间联系较少,节点更多处于桥梁位置,可能连接不同的社群。 在很多网络中,聚类系数能揭示局部社区结构和节点的协同效应。 Graphlets 定义: Graphlets 是指网络中规模较小(通常由3至5个节点构成)的非同构子图。 通过统计一个节点参与的各种 graphlet 模式的数量,我们可以构造出该节点的 Graphlet Degree Vector (GDV)。 意义: Graphlets 能捕捉节点在局部网络结构中的精细模式,比单纯的度数或聚类系数提供更丰富的信息。 在很多应用中(如生物网络分析或社交网络挖掘),通过分析节点参与的 graphlet 模式,可以更好地理解节点的功能和在整个网络中的角色。 Graphlets 被视为网络的“结构指纹”,有助于区分功能不同的节点。 连接层面的特征工程 目的:通过已知连接补全未知连接 eg: AB之间有连接,BC之间有连接,那么AC之间是否可能有连接呢? 法一:直接提取连接的特征,把连接变成D维向量(推荐)。 法二:把连接两端节点的D维向量拼接,即上一讲的节点特征拼接(不推荐,损失了连接本身的结构信息。) Distance-based Feature 核心思路: 用两个节点之间的最短路径长度(或加权距离等)作为边的特征,衡量节点对的“接近”程度。 Local Neighborhood Overlap 核心思路: 度量两个节点在其“一阶邻居”层面共享多少共同邻居,或者它们的邻居集合相似度如何。 Common Neighbors $$ \text{CN}(u,v) ;=; \bigl|,N(u),\cap,N(v)\bigr|, $$ 其中 $N(u)$ 是节点 $u$ 的邻居集合,$\cap$ 表示交集。数值越大,表示两节点在局部网络中有更多共同邻居。 Jaccard Coefficient $$ \text{Jaccard}(u,v) ;=; \frac{\bigl|,N(u),\cap,N(v)\bigr|}{\bigl|,N(u),\cup,N(v)\bigr|}. $$ 反映了两个节点邻居集合的交并比,越大则两者邻居越相似。 Adamic-Adar $$ \text{AA}(u,v) ;=; \sum_{w ,\in, N(u),\cap,N(v)} \frac{1}{\log,\bigl|N(w)\bigr|}. $$ 共同邻居数目较多、且这些邻居本身度数越小,贡献越大。常用于社交网络链接预测。(直观理解:如果AB都认识C,且C是个社牛,那么AB之间的友谊就不一定好) Global Neighborhood Overlap 核心思路: 不只看“一阶邻居”,还考虑更大范围(如 2 步、3 步乃至更多跳数)上的共同可达节点,或更广泛的结构相似度。 Katz 指标:累加节点间所有长度的路径并衰减; Random Walk:基于随机游走来度量节点对的全局可达性; Graph Embedding:DeepWalk、node2vec等,都可将多跳结构信息编码到向量表示里,再用向量相似度当作边特征。 真实情况如何编码边的特征? 在一个 边的特征工程 任务中,可以将 Distance-based Feature、Local Neighborhood Overlap 和 Global Neighborhood Overlap 等特征组合起来,形成一个完整的特征向量。 例如:对于每条边 $ (u,v) $,我们提取以下 6 种特征: 最短路径长度 $ d(u,v) $ (Distance-based Feature) 共同邻居数 $ CN(u,v) $ (Local Neighborhood Overlap) Jaccard 系数 $ Jaccard(u,v) $ (Local Neighborhood Overlap) Adamic-Adar 指标 $ AA(u,v) $ (Local Neighborhood Overlap) Katz 指数 $ Katz(u,v) $ (Global Neighborhood Overlap) Random Walk 访问概率 $ RW(u,v) $ (Global Neighborhood Overlap) 对于图中某条边 $ (A, B) $,它的特征向量可能是: $$ \mathbf{f}(A, B) = \big[ 2, 5, 0.42, 0.83, 0.31, 0.45 \big] $$ 图层面的特征工程 目的:网络相似度、图分类(已知分子结构判断是否有xx特性) 当我们要对整张图进行分类或比较(如图分类、图相似度计算等),需要将图转化为可比较的向量或特征。最朴素的想法是: Bag-of-Node-Degrees:统计每个节点的度,然后构建一个“度分布”或“度直方图”。 例如,对图 $G$,我们计算 $\phi(G) = [,\text{count of deg}=1,\ \text{count of deg}=2,\ \dots,]$。 缺点:只关注了节点度,无法区分很多结构不同、但度分布相同的图。 为解决这个不足,人们提出了更精细的“Bag-of-*”方法,把节点周围的更丰富结构(子图、子树、图形)纳入统计,从而形成更有判别力的特征。 Graphlet Kernel Graphlets:指小规模(如 3 节点、4 节点、5 节点)的非同构子图。 做法:枚举或随机采样网络中的所有小型子图(graphlets),并根据其类型计数出现频率。 比如在 4 节点层面,有 6 种不同的非同构结构,就统计每种结构出现多少次。 得到的特征:一个“graphlet type”直方图,即 $\phi(G) = \big[\text{count}(\text{graphlet}_1), \dots, \text{count}(\text{graphlet}_k)\big]$。 优点:比单纯节点度更能捕捉网络的局部模式。 缺点:当图很大时,遍历或采样 graphlet 代价较高;仅依赖小子图也可能忽略更大范围结构。 Weisfeiler–Lehman Kernel Weisfeiler–Lehman (WL) 核是一种基于迭代标签传播的方法,用于图同构测试和图相似度计算。 核心思路: 初始标签:给每个节点一个初始标签(可能是节点的类型或颜色)。 迭代更新:在每一步迭代中,将节点自身标签与其邻居标签拼接后做哈希,得到新的标签。 记录“标签多重集”:每次迭代会产生新的节点标签集合,可视为“节点子树结构”的某种编码。 Bag-of-Labels / Bag-of-Subtrees: 在每一轮迭代后,统计各类标签出现次数,累加到特征向量中。 相当于对节点子树或“局部邻域结构”做词袋统计。 优点:在保留更多结构信息的同时,计算复杂度相对可控。 缺点:仍然可能有一定的“同构测试”盲区;对于非常复杂的图,标签碰撞可能出现。 例子: 假设我们有一个简单的无向图,包含 4 个节点和 4 条边,结构如下: 1 — 2 — 3 | 4 1. 初始化标签 首先,给每个节点一个初始标签。假设我们直接用节点的度数作为初始标签: 初始标签如下: 节点 1: 1 节点 2: 3 节点 3: 1 节点 4: 1 2. 第一次迭代 在第一次迭代中,每个节点的标签会更新为其自身标签和邻居标签的拼接,然后通过哈希函数生成新的标签。 节点 1: 邻居是节点 2,标签为 3。 拼接后的标签为 (1, 3)。 假设哈希结果为 A。 节点 2: 邻居是节点 1、3、4,标签分别为 1、1、1。 拼接后的标签为 (3, 1, 1, 1)。 假设哈希结果为 B。 节点 3: 邻居是节点 2,标签为 3。 拼接后的标签为 (1, 3)。 假设哈希结果为 A。 节点 4: 邻居是节点 2,标签为 3。 拼接后的标签为 (1, 3)。 假设哈希结果为 A。 第一次迭代后的标签如下: 节点 1: A 节点 2: B 节点 3: A 节点 4: A 3. 第二次迭代 节点 1: 邻居是节点 2,标签为 B。 拼接后的标签为 (A, B)。 假设哈希结果为 C。 节点 2: 邻居是节点 1、3、4,标签分别为 A、A、A。 拼接后的标签为 (B, A, A, A)。 假设哈希结果为 D。 节点 3: 邻居是节点 2,标签为 B。 拼接后的标签为 (A, B)。 假设哈希结果为 C。 节点 4: 邻居是节点 2,标签为 B。 拼接后的标签为 (A, B)。 假设哈希结果为 C。 第二次迭代后的标签如下: 节点 1: C 节点 2: D 节点 3: C 节点 4: C 4. 停止条件 通常,WL Kernel 会进行多次迭代,直到节点的标签不再变化(即收敛)。在这个例子中,假设我们只进行两次迭代。 5.统计标签的多重集 在每次迭代后,统计图中所有节点的标签分布(即“标签多重集”),并将其作为图的特征。 初始标签多重集: 标签 1 出现 3 次(节点 1、3、4)。 标签 3 出现 1 次(节点 2)。 第一次迭代后的标签多重集: 标签 A 出现 3 次(节点 1、3、4)。 标签 B 出现 1 次(节点 2)。 第二次迭代后的标签多重集: 标签 C 出现 3 次(节点 1、3、4)。 标签 D 出现 1 次(节点 2)。 $$ \phi(G) = [\text{count}(1), \text{count}(3), \text{count}(A), \text{count}(B), \text{count}(C), \text{count}(D)]. \\ \phi(G) = [3, 1, 3, 1, 3, 1]. $$ 直观理解 初始标签:只关注节点的度数。 第一次迭代:关注节点的度数及其邻居的度数。 第二次迭代:关注节点的度数、邻居的度数,以及邻居的邻居的度数。 随着迭代的进行,WL Kernel 能够捕捉到越来越复杂的局部结构信息。
科研
zy123
3月21日
0
4
0
2025-03-21
颜佳佳论文
颜佳佳论文 多智能体随机网络结构的实时精确估算 多智能体随机网络特征值滤波建模 1. 状态转移模型 系统的特征值向量 $\lambda_k$(状态向量)随时间演化的动态方程为: $$ \lambda_k = \lambda_{k-1} + w_{k-1} $$ 参数说明: $\lambda_k \in \mathbb{R}^{r \times 1}$:$k$ 时刻的特征值向量,$r$ 为特征值个数。 $w_{k-1} \sim \mathcal{N}(0, {Q})$:过程噪声,均值为零,协方差矩阵为对角阵 $\mathbf{Q} \in \mathbb{R}^{r \times r}$(因特征值独立)。 简化假设: 状态转移矩阵 $\mathbf{A}$ 和控制输入矩阵 $\mathbf{B}$ 为单位阵或零(无外部控制输入),故模型简化为随机游走形式。 2. 测量模型 观测到的特征值向量 $z_k$ 为: $$ z_k = \lambda_k + v_k $$ 参数说明: $z_k \in \mathbb{R}^{r \times 1}$:观测向量,维度与状态向量相同。 $v_k \sim \mathcal{N}(0, \mathbf{R})$:测量噪声,协方差 $\mathbf{R} \in \mathbb{R}^{r \times r}$ 为对角阵(噪声独立)。 简化假设: 测量矩阵 $\mathbf{H}$ 为单位阵,即观测直接反映状态。 3. 噪声协方差矩阵的设定 $\mathbf{Q}$ 和 $\mathbf{R}$ 为对角矩阵,对角元素由特征值方差确定: $$ \mathbf{Q} = \text{diag}(2\sigma_1^2, 2\sigma_2^2, \dots, 2\sigma_r^2), \quad \mathbf{R} = \text{diag}(\sigma_1^2, \sigma_2^2, \dots, \sigma_r^2) $$ 其中 $\sigma_i^2$ 为第 $i$ 个特征值的初始方差(由引理3-1推导)。 网络重构分析 滤波误差 原始全矩阵 $$ A = X \Lambda X^T = X_r \Lambda_r X_{r}^T + \underbrace{X_{-r} \Lambda_{-r} X_{-r}^T}_{\text{被截掉的尾部}} $$ 截断重构(真实) $$ A_k = X_r \Lambda_r X_{r}^T $$ 滤波后重构 $$ \hat{A}r = X_r (\Lambda_r + \Delta \Lambda_r) X{r}^T $$ 卡尔曼滤波误差矩阵(定义为两者之差): $$ E_{KF} = \hat{A}r - A_r = X_r \Delta \Lambda_r X{r}^T. $$ 要量化这个误差,常用矩阵的 Frobenius 范数: $$ e_{KF} = \| E_{KF} \|_F = \| X_r \Delta \Lambda_r X_r^T \|_F. $$ 由于 $X_K$ 是正交子矩阵(假设特征向量正交归一),有 $$ e_{KF} = \|\Delta \Lambda_K\|_F = \sqrt{\sum_{i=1}^r (\delta \lambda_i)^2}. $$ 全局误差度量 对估计矩阵 $\hat{A}k$ 的所有元素 ${\hat{a}{ij}}$ 进行 $K$-means 聚类,得到中心 ${c_k}_{k=1}^K$。 簇内平均偏差: $$ \text{mean}_k = \frac{1}{|\mathcal{S}k|} \sum{(i,j)\in\mathcal{S}k} |\hat{a}{ij} - c_k| $$ 全局允许误差: $$ \delta_{\max} = \frac{1}{K} \sum_{k=1}^K \text{mean}_k $$ 最终约束条件: $$ \boxed{ \underbrace{e_{KF}}_{\text{滤波误差}} \;+\; \underbrace{\epsilon}_{\text{重构算法误差}} \;\le\; \underbrace{\delta_{\max}}_{\text{聚类量化容限}} } $$ $$ {\epsilon}\;\le\; {\delta_{\max}} -e_{KF} $$ 网络结构优化 直接SNMF分解(无优化) 输入矩阵:原始动态网络邻接矩阵 $A$(可能稠密或高秩) 处理流程: 直接对称非负矩阵分解:$A \approx UU^T$ 通过迭代调整$U$和旋转矩阵$Q$逼近目标 存在问题: 高秩矩阵需要保留更多特征值($\kappa$较大) 非稀疏矩阵计算效率低 先优化再SNMF(论文方法) 优化阶段(ADMM): 目标函数:$\min_{A_{\text{opt}}} (1-\alpha)|A_{\text{opt}}|* + \alpha|A{\text{opt}}|_1$ 输出优化矩阵$A_{\text{opt}}$ SNMF阶段: 输入变为优化后的$A_{\text{opt}}$ 保持相同分解流程但效率更高 网络优化中的邻接矩阵重构问题建模与优化 可行解集合定义(公式4-4) $$ \Omega = \left\{ A \middle| A^T = A,\, A \odot P = A_{\text{pre}} \odot P,\, A \odot A_{\max}' = 0 \right\} $$ $A^T = A$:确保邻接矩阵对称 $A \odot P = A_{\text{pre}} \odot P$:掩码矩阵$P$ ,原来已有的连接不变,只让优化原本没有连接的地方。($\odot$为Hadamard积) $A \odot A_{\max}' = 0$:功率约束矩阵$\ A_{\max}'$ 禁止在原本无连接的节点间新增边 限制矩阵$A_{\max}'$的定义(公式4-5) $$ A'_{\max, ij} = \begin{cases} 0, & \text{若 } A_{\max, ij} \ne 0 \\ 1, & \text{若 } A_{\max, ij} = 0 \end{cases} $$ $A_{\max, ij}$表示在最大发射功率下哪些节点对之间能连通(非零表示可连通,零表示即便满功率也连不通) $A_{\max}'$在“连不通”的位置上是1,其他位置是0。通过$A_{\max}'$标记禁止修改的零元素位置 对于所有满足 $A'{\max,ij}=1$ 的位置(即物理不可连通的节点对),必须有 $A{ij}=0$,即始终保持断开 原始优化目标(公式4-6) $$ \min_{A} \, (1-\alpha)\, \text{rank}(A) + \alpha \|A\|_0 $$ $\|A\|_0$ 表示矩阵 $A$ 中非零元素的个数 目标:平衡低秩性($\text{rank}(A)$)与稀疏性($|A|_0$) 问题:非凸、不可导,难以直接优化 凸松弛后的目标(公式4-7) $$ \min_{A} \, (1-\alpha)\, \|A\|_* + \alpha \|A\|_1 $$ 核范数$|A|_*$:奇异值之和,替代$\text{rank}(A)$ L1范数$|A|_1$:元素绝对值和,替代$|A|_0$ 性质:凸优化问题,存在全局最优解 求解方法 传统方法: 可转化为**半定规划(SDP)**问题,使用内点法等求解器。但缺点是计算效率低,尤其当矩阵规模大(如多智能体网络节点数 $n$ 很大)时不可行。 改进方法: 采用ADMM(交替方向乘子法)结合投影和对偶上升的方法,适用于动态网络(矩阵频繁变化的情况)。 ADMM核心算法 变量定义与作用 输入变量: $A_{pre}$:初始邻接矩阵(优化前的网络拓扑)。 $P$:对称的0-1矩阵,用于标记 $A_{pre}$ 中非零元素的位置(保持已有边不变)。 $A'{max}$:功率最大时的邻接矩阵的补集($A'{maxij} = 1$ 表示 $A_{maxij} = 0$,即不允许新增边)。 $\alpha$:权衡稀疏性($L_1$ 范数)和低秩性(核范数)的系数。 iters:ADMM迭代次数。 算法步骤详解 (S.1) 更新原始变量 $A$(对应ADMM的$x$步) 代码行4-17:通过内层循环(投影和对偶上升)更新 $A$。 行4-11: 通过内层循环(行8-11)迭代更新 $R$,本质是梯度投影法: $temp_R^{k+1} = M - X^k \odot A_{\text{pre}}$(计算残差)。 $X^{k+1} = X^k + \beta(A_{\text{pre}} \odot temp_R^{k+1})$(梯度上升步,$\beta$ 为步长)。 本质:通过迭代强制 $A$ 在 $P$ 标记的位置与 $A_{pre}$ 一致。 行13-17:将 $A$ 投影到 $A \odot A'_{\text{max}} = 0$ 的集合。 类似地,通过内层循环(行14-17)更新 $Y$: $temp_A^{k+1} = D_2 - Y^k \odot A'_{\text{max}}$(残差计算)。 $Y^{k+1} = Y^k + \gamma(A'_{\text{max}} \odot temp_A^{k+1})$(对偶变量更新)。 (S.2) 更新辅助变量 $Z_1, Z_2$(对应ADMM的$z$步) 通过阈值操作分离目标函数的两部分: 行18-19:分别对核范数和 $L_1$ 范数进行阈值操作: $Z_1^{t+1} = T_r(A^{t+1} + U_1^t)$: $T_r(\cdot)$ 是奇异值阈值算子(核范数投影),对$A + U1$ 做SVD分解,保留前 $r$ 个奇异值。作用:把自己变成低秩矩阵=》强制 $A$ 低秩。 $Z_2^{t+1} = S_{\alpha}(A^{t+1} + U_2^t)$: $S_{\alpha}(\cdot)$ 是软阈值算子($L_1$ 范数投影),将小于 $\alpha$ 的元素置零。把自己变成稀疏矩阵=》促进 $A$ 的稀疏性。 (S.3) 更新 拉格朗日乘子$U_1, U_2$(对应ADMM的对偶上升) 行20-21:通过残差 $(A - Z)$ 调整拉格朗日乘子 $U_1, U_2$: $U_1^{t+1} = U_1^t + A^{t+1} - Z_1^{t+1}$(核范数约束的乘子更新)。 $U_2^{t+1} = U_2^t + A^{t+1} - Z_2^{t+1}$($L_1$ 范数约束的乘子更新)。 作用:惩罚 $A$ 与辅助变量 $Z1, Z2$ 的偏差(迫使$A$更贴近$Z$),推动收敛。 网络结构控制 核心目标:将优化后的低秩稀疏矩阵 $A$ 转化为实际网络参数(如功率、带宽),并维持动态网络的连通性和稳定性。 具体实现: 通过PID控制调整发射/接收功率,使实际链路带宽匹配矩阵 $A$ 的优化值。 结合CSMA/CA协议处理多节点竞争,确保稀疏网络下的高效通信。 优化模型(4.2节) ↓ 生成目标带宽矩阵A 香农公式 → 计算目标Pr → 自由空间公式 → 计算目标Pt ↓ PID控制发射机(AGC电压) → 实际Pt ≈ 目标Pt ↓ PID控制接收机(AAGC/DAGC) → 实际Pr ≈ 目标Pr ↓ 实际带宽 ≈ Aij (闭环反馈) 发射机: 功能:将数据转换为无线信号并通过天线发射。 关键参数:发射功率($P_t$)、天线增益($G_t$)、工作频率(决定波长$\lambda$)。 控制目标:通过调整AGC电压,动态调节发射功率,以匹配优化后的带宽需求(矩阵$A$中的$A_{ij}$)。 接收机: 功能:接收无线信号并转换为可处理的数据。 关键参数:接收功率($P_r$)、噪声($N_0$)、天线增益($G_r$)。 控制目标:通过AAGC/DAGC增益调整,确保接收信号强度适合解调,维持链路稳定性。 具体步骤 步骤1:生成目标带宽矩阵 $A$(4.2节优化模型) 数学建模: 通过凸松弛优化问题(公式4-7)得到低秩稀疏矩阵 $A$: $$ \min_A (1-\alpha) |A|_* + \alpha |A|_1 \quad \text{s.t.} \quad A \in \Omega $$ 约束集 $\Omega$ 确保矩阵对称性、保留原有链路($A \odot P = A_{\text{pre}} \odot P$)、禁止不可达链路($A \odot A'_{\max} = 0$)。 物理意义: 非零元素 $A_{ij}$ 直接表示 目标信道带宽 $C_{ij}$(单位:bps),即: $$ A_{ij} = C_{ij} = W \log_2\left(1 + \frac{P_r}{N_0 W}\right) \quad \text{(香农公式4-10)} $$ 步骤2:从带宽 $A_{ij}$ 反推功率参数 接收功率 $P_r$ 计算: 根据香农公式解耦: $$ P_r = (2^{A_{ij}/W} - 1) N_0 W $$ 输入:噪声 $N_0$、带宽 $W$、目标带宽 $A_{ij}$。 发射功率 $P_t$ 计算: 通过自由空间公式(4-11): $$ P_t = \frac{P_r L (4\pi d)^2}{G_t G_r \lambda^2} $$ 输入:距离 $d$、天线增益 $G_t, G_r$、波长 $\lambda$、损耗 $L$。 逻辑分支: 若 $A_{ij} \neq A_{\text{pre}ij}$(需调整链路): 计算 $P_r$ 和 $P_t$; 若 $A_{ij} = 0$(无连接): 直接设 $P_r = P_t = 0$。 步骤3:发射机功率调整(图4-2a) 定义目标:$P_t$(来自步骤2)。 测量实际:通过传感器获取当前发射功率 $P_{t,\text{actual}}$。 计算偏差:$e(t) = P_t - P_{t,\text{actual}}$。 PID调节:通过AGC电压改变发射功率,逼近 $P_t$。 步骤4:接收机功率调整(图4-2b) 定义目标:$P_r$(来自步骤2)。 测量实际:检测空口信号功率 $P_{r,\text{actual}}$。 计算偏差:$e(t) = P_r - P_{r,\text{actual}}$。 PID调节: 调整AAGC(模拟增益)和DAGC(数字增益),持续监测直至 $|e(t)| < \epsilon$。 基于谱聚类的无人机网络充电 (1) 谱聚类分组Spectral_Clustering(表5.1) 目标:将无人机和充电站划分为 $K$ 个簇,使充电站位于簇中心。 步骤: 输入:带权邻接矩阵 $A$(权值=无人机间距离)、节点数 $N$、充电站数 $K$。 拉普拉斯矩阵: $$L = D - A, \quad D_{ii} = \sum_j A_{ij}$$ 归一化: $$L_{norm} = D^{-\frac{1}{2}}LD^{\frac{1}{2}}$$ 谱分解:求 $L_{norm}$ 前 $K$ 小特征值对应的特征向量矩阵 $V \in \mathbb{R}^{N \times K}$。 聚类:对 $V$ 的行向量进行 k-means 聚类,得到标签 $\text{labels}$。 输出:每个无人机/充电站的簇编号 $\text{labels}$。 (2) 无人机选择充电站(表5-2) 目标:电量低的无人机前往对应簇中心的充电站。 步骤: 周期性运行(间隔 $\Delta t$): 通过 Push_Sum 协议获取所有无人机位置 Positions。 计算距离矩阵 $A$。 动态聚类:调用 Spectral_Clustering(A) 更新簇标签。 充电触发:若电量 $E < P_{th}$,向簇中心请求坐标 $\text{CS_point}$ 并前往。 关键公式: $$A_{ij} = \| \text{Position}_i - \text{Position}_j \|_2$$ (3) 充电站跟踪算法(表5-3) 目标:充电站动态调整位置至簇中心。 步骤: 周期性运行(间隔 $\Delta t$): 同无人机算法获取 $A$ 和 labels。 定位簇中心: 充电站根据编号匹配簇标签。 计算簇内无人机位置均值: $$\text{CS_point} = \frac{1}{|C_k|} \sum_{i \in C_k} \text{Position}_i$$ 其中 $C_k$ 为第 $k$ 簇的节点集合。 移动至新中心并广播位置。 (4) 算法改进 替换通信协议:用第3章的卡尔曼滤波 替代 Push_Sum,获取特征值、特征向量重构全局矩阵 $A$,减少消息传递。 基于T-GAT的无人机群流量预测 TCN 流量矩阵 $X \in \mathbb{R}^{N \times T}$,其中: $N$:无人机节点数量(例如10架无人机)。 $T$:时间步数量。 每个元素 $X_{i,t}$ 表示第 $i$ 个节点在时间 $t$ 的总流量(如发送/接收的数据包数量或带宽占用)。 流量矩阵的形状 假设有3架无人机,记录5个时间步的流量数据,矩阵如下: $$ X = \begin{bmatrix} 100 & 150 & 200 & 180 & 220 \\[6pt] 50 & 75 & 100 & 90 & 110 \\[6pt] 80 & 120 & 160 & 140 & 170 \end{bmatrix} $$ 行 ($N=3$):每行代表一架无人机的历史流量序列(例如第1行表示无人机1的流量变化:100 → 150 → 200 → 180 → 220)。 列 ($T=5$):每列代表所有无人机在同一时间步的流量状态(例如第1列表示在时间 $t_1$ 时,三架无人机的流量分别为:[100, 50, 80])。 TCN处理流量矩阵: 卷积操作 TCN 的每个卷积核会滑动扫描所有通道(即所有无人机)的时序数据。 例如,一个大小为 3 的卷积核会同时分析每架无人机连续 3 个时间步的流量(例如从 $t_1$ 到 $t_3$),以提取局部时序模式。 输出时序特征 经过多层扩张卷积和残差连接后,TCN 会输出一个高阶特征矩阵 $H_T^l$,其形状与输入类似(例如 (1, 3, 5)),但每个时间步的值已包含了: 趋势信息:流量上升或下降的长期规律。 TCN的卷积核仅在单个通道内滑动,计算时仅依赖该节点自身的历史时间步。节点间的交互是通过后续的**图注意力网络(GAT)**实现的。 与 GAT 的衔接 TCN 输出的特征矩阵 $H_T^l$ 会传递给 GAT 进行进一步处理。 时间步对齐:通常取最后一个时间步的特征(例如 H_T^l[:, :, -1])作为当前节点特征。 空间聚合:GAT 根据邻接矩阵计算无人机间的注意力权重,例如考虑“无人机2的当前流量可能受到无人机1过去3分钟流量变化的影响”。 LSTM+GAT训练过程说明(RWP网络节点移动预测) 先LSTM后GAT侧重点在时序特征的提取;先GAT后LSTM侧重点在空间特征的提取。 1. 数据构造 输入数据: 节点轨迹数据: 每个节点在1000个时间单位内的二维坐标 $(x, y)$,形状为 $[N, 1000, 2]$($N$个节点,1000个时间步,2维特征)。 动态邻接矩阵序列: 每个时间步的节点连接关系(基于距离阈值或其他规则生成),得到1000个邻接矩阵 $[A_1, A_2, \dots, A_{1000}]$,每个 $A_t$ 的形状为 $[2, \text{num_edges}_t]$(稀疏表示)。 滑动窗口处理: 窗口大小:12(用前12个时间步预测第13个时间步)。 滑动步长:1(每次滑动1个时间步,生成更多训练样本)。 生成样本数量: 总时间步1000,窗口大小12 → 可生成 $1000 - 12 = 988$ 个样本。 样本格式: 输入序列 $X^{(i)}$:形状 $[N, 12, 2]$($N$个节点,12个时间步,2维坐标)。 目标输出 $Y^{(i)}$:形状 $[N, 2]$(第13个时间步所有节点的坐标)。 动态邻接矩阵:每个样本对应12个邻接矩阵 $[A^{(i)}_1, A^{(i)}2, \dots, A^{(i)}{12}]$(每个 $A^{(i)}_t$ 形状 $[2, \text{num_edges}_t]$)。 2. 训练过程 模型结构: LSTM层: 输入:$[N, 12, 2]$($N$个节点的12步历史轨迹)。 输出:每个节点的时序特征 $[N, 12, H]$($H$为LSTM隐藏层维度)。 关键点:LSTM独立处理每个节点的时序,节点间无交互。 GAT层: 输入:取LSTM最后一个时间步的输出 $[N, H]$(即每个节点的最终时序特征)。 动态图输入:使用第12个时间步的邻接矩阵 $A^{(i)}_{12}$(形状 $[2, \text{num_edges}]$)。 输出:通过图注意力聚合邻居信息,得到空间增强的特征 $[N, H']$($H'$为GAT输出维度)。 预测层: 全连接层将 $[N, H']$ 映射到 $[N, 2]$,预测下一时刻的坐标。 训练步骤: 前向传播: 输入 $[N, 12, 2]$ → LSTM → $[N, 12, H]$ → 取最后时间步 $[N, H]$ → GAT → $[N, H']$ → 预测 $[N, 2]$。 损失计算: 均方误差(MSE)损失:比较预测坐标 $[N, 2]$ 和真实坐标 $[N, 2]$。 反向传播: 梯度从预测层回传到GAT和LSTM,更新所有参数。 3. 数据维度变化总结 步骤 数据形状 说明 原始输入 $[N, 1000, 2]$ $N$个节点,1000个时间步的$(x,y)$坐标。 滑动窗口样本 $[N, 12, 2]$ 每个样本包含12个历史时间步。 LSTM输入 $[N, 12, 2]$ 输入LSTM的节点独立时序数据。 LSTM输出 $[N, 12, H]$ $H$为LSTM隐藏层维度。 GAT输入(最后时间步) $[N, H]$ 提取每个节点的最终时序特征。 GAT输出 $[N, H']$ $H'$为GAT输出维度,含邻居聚合信息。 预测输出 $[N, 2]$ 下一时刻的$(x,y)$坐标预测。 4. 关键注意事项 动态图的处理: 每个滑动窗口样本需匹配对应时间步的邻接矩阵(如第 $i$ 到 $i+11$ 步的 $[A^{(i)}1, \dots, A^{(i)}{12}]$),但GAT仅使用最后一步 $A^{(i)}_{12}$。 若图结构变化缓慢,可简化为所有窗口共享 $A^{(i)}_{12}$。 数据划分: 按时间划分训练/验证集(如前800个窗口训练,后188个验证),避免未来信息泄露。 颜佳佳论文问题: 卡尔曼滤波预测了流量矩阵,但是又要TCN-GAT预测了流量矩阵,是否可以将TCN-GAT预测流量矩阵作为卡尔曼滤波的观测值。
科研
zy123
3月21日
0
4
0
2025-03-21
机器学习
机器学习与深度学习 机器学习 监督学习 监督学习(Supervised Learning) 定义:所有训练数据都具有明确的标签,模型通过这些标签进行学习。 特点:模型训练相对直接,性能受限于标注数据的质量和数量。 示例:传统的分类问题,如手写数字识别、垃圾邮件检测等。 无监督学习(Unsupervised Learning) 定义:训练数据完全没有标签,模型需要自己去发现数据中的模式或结构。 特点:常用于聚类、降维、关联规则挖掘等任务,难以直接用于分类任务。 示例:聚类算法(如K-means)和主成分分析(PCA)。 半监督学习(Semi‑supervised Learning) 定义:介于监督学习和无监督学习之间,使用少量带标签的数据和大量未标签的数据共同训练模型,以在标注数据稀缺时提升分类性能。 特点:结合标签信息与数据分布结构,通过利用未标签数据的内在聚类或流形结构降低对标注数据的依赖,从而提高模型泛化能力并降低标注成本;通常依赖平滑假设和聚类假设等前提。 示例:在猫狗图像分类任务中,先使用少量已标记的猫狗图片训练初始模型,再用该模型为大量未标记图片生成“伪标签”,将这些伪标签数据与原有标记数据合并重新训练,从而获得比仅使用有标签数据更高的分类准确率。 在半监督学习中,为了避免将错误的模型预测“伪标签”纳入训练,必须对每个未标注样本的预测结果进行可信度评估,只保留高置信度、准确率更高的伪标签作为新增训练数据。 深度学习 前向传播 Mini Batch梯度下降 Batch Size(批大小) 定义 Batch Size 指在深度学习模型训练过程中,每次迭代送入网络进行前向传播和反向传播的样本数量。 特点 Batch Size 决定了梯度更新的频率和稳定性;较大的 Batch Size 能更好地利用 GPU 并行计算、减少迭代次数、加快训练速度,但会显著增加显存占用且可能降低模型泛化能力;较小的 Batch Size 则带来更大的梯度噪声,有助于跳出局部最优、提高泛化性能,但训练过程更不稳定且耗时更长。 示例:在 PyTorch 中,使用 DataLoader(dataset, batch_size=32, shuffle=True) 表示每次迭代从数据集中抽取 32 个样本进行训练。一个batch的所有样本会被打包成一个张量,一次性并行送入网络进行计算 将完整训练集分割成若干大小相同的小批量(mini‑batch),每次迭代仅使用一个 mini‑batch 来计算梯度并更新模型参数,结合了批量梯度下降(Batch GD)和随机梯度下降(SGD)的优势。 当 batch_size=1 时退化为随机梯度下降;当 batch_size=m(训练集总样本数)时退化为批量梯度下降。 通常选择 2 的幂(如32、64、128、256)以匹配 GPU/CPU 内存布局并提升运算效率。 算法流程 将训练数据随机打乱并按 batch_size 划分成多个 mini‑batch。 对每个 mini‑batch 执行: 前向传播计算输出。 计算 mini‑batch 上的平均损失。 反向传播计算梯度。 按公式更新参数: $$ \theta \leftarrow \theta - \eta \frac{1}{|\text{batch}|}\sum_{i\in \text{batch}} \nabla_\theta \mathcal{L}(x_i,y_i) $$ 遍历所有 mini‑batch 即完成一个 epoch,可重复多轮直到收敛。 Softmax 公式 假设有一个输入向量 $$ z = [z_1, z_2, \dots, z_K], $$ 则 softmax 函数的输出为: $$ \sigma(z)_i = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}, $$ 其中 $i = 1, 2, \dots, K$。 分子:对每个 $z_i$ 取自然指数 $e^{z_i}$,目的是将原始的实数扩展到正数范围。 分母:对所有 $e^{z_j}$ 求和,从而实现归一化,使得所有输出概率和为 1。 交叉熵损失 假设有三个类别,真实标签为第二类,因此用 one-hot 编码表示为: $$ y = [0,\; 1,\; 0]. $$ 假设模型经过 softmax 后输出的预测概率为: $$ \hat{y} = [0.2,\; 0.7,\; 0.1]. $$ 交叉熵损失函数的定义为: $$ L = -\sum_{i=1}^{3} y_i \log \hat{y}_i. $$ 将 $y$ 和 $\hat{y}$ 的对应元素代入公式中: $$ L = -(0 \cdot \log 0.2 + 1 \cdot \log 0.7 + 0 \cdot \log 0.1) = -\log 0.7. $$ 计算 $-\log 0.7$(以自然对数为例): $$ -\log 0.7 \approx -(-0.3567) \approx 0.3567. $$ 因此,这个样本的交叉熵损失大约为 0.3567。 残差连接 假设一个神经网络层(或一组层)的输入为 $x$,传统的设计会期望该层直接学习一个映射 $F(x)$。而采用残差连接的设计,则将输出定义为: $$ \text{Output} = F(x) + x. $$ 这里: $F(x)$ 表示经过几层变换(比如卷积、激活等)后所学到的“残差”部分, $x$ 则是直接通过捷径传递过来的输入。 为什么使用残差连接 缓解梯度消失问题 在深层网络中,梯度往往会在反向传播过程中逐层衰减,而残差连接为梯度提供了一条捷径,使得梯度可以直接从后面的层传递到前面的层,从而使得网络更容易训练。 简化学习任务 网络不必学习从零开始构造一个完整的映射,而只需要学习输入与目标之间的残差。这样可以使得学习任务变得更简单,更易收敛。 提高网络性能 在很多实际应用中(例如图像识别中的 ResNet),引入残差连接的网络能训练得更深,并在多个任务上取得更好的效果。
科研
zy123
3月21日
0
3
0
2025-03-21
图神经网络
图神经网络 图表示学习的本质是把节点映射成低维连续稠密的向量。这些向量通常被称为 嵌入(Embedding),它们能够捕捉节点在图中的结构信息和属性信息,从而用于下游任务(如节点分类、链接预测、图分类等)。 低维:将高维的原始数据(如邻接矩阵或节点特征)压缩为低维向量,减少计算和存储开销。 连续:将离散的节点或图结构映射为连续的向量空间,便于数学运算和捕捉相似性。 稠密:将稀疏的原始数据转换为稠密的向量,每个维度都包含有意义的信息。 对图数据进行深度学习的“朴素做法” 把图的邻接矩阵和节点特征“直接拼接”成固定维度的输入,然后将其送入一个深度神经网络(全连接层)进行学习。 这种做法面临重大问题,导致其并不可行: $O(|V|^2)$ 参数量 ,参数量庞大 无法适应不同大小的图 ,需要固定输入维度 对节点顺序敏感 ,节点编号顺序一变,输入就完全变样,但其实图的拓扑并没变(仅节点编号/排列方式不同)。 A —— B | | D —— C 矩阵 1(顺序 $[A,B,C,D]$): $$ M_1 = \begin{pmatrix} 0 & 1 & 0 & 1\ 1 & 0 & 1 & 0\ 0 & 1 & 0 & 1\ 1 & 0 & 1 & 0 \end{pmatrix}. $$ 矩阵 2(顺序 $[C,A,D,B]$): $$ M_2 = \begin{pmatrix} 0 & 0 & 1 & 1 \ 0 & 0 & 1 & 1 \ 1 & 1 & 0 & 0 \ 1 & 1 & 0 & 0 \end{pmatrix}. $$ 两个矩阵完全不同,但它们对应的图是相同的(只不过节点的顺序改了)。 计算图 在图神经网络里,通常每个节点$v$ 都有一个局部计算图,用来表示该节点在聚合信息时所需的所有邻居(及邻居的邻居……)的依赖关系。 直观理解 以节点 $v$ 为根; 1-hop 邻居在第一层,2-hop 邻居在第二层…… 逐层展开直到一定深度(例如 k 层)。 这样形成一棵“邻域树”或“展开图”,其中每个节点都需要从其子节点(邻居)获取特征进行聚合。 例子 在图神经网络中,每一层的计算通常包括以下步骤: 聚合(Aggregation):将邻居节点的特征聚合起来(如求和、均值、最大值等)。 变换(Transformation):将聚合后的特征通过一个神经网络(如 MLP)进行非线性变换。 A | B / \ C D 假设每个节点的特征是一个二维向量: 节点 $ A $ 的特征:$ h_A = [1.0, 0.5] $ 节点 $ B $ 的特征:$ h_B = [0.8, 1.2] $ 节点 $ C $ 的特征:$ h_C = [0.3, 0.7] $ 节点 $ D $ 的特征:$ h_D = [1.5, 0.9] $ 第 1 层更新:$A^{(0)} \to A^{(1)}$ 节点 $A$ 的 1-hop 邻居:只有 $B$。 聚合(示例:自+邻居取平均): $$ z_A^{(1)} = \frac{A^{(0)} + B^{(0)}}{2} = \frac{[1.0,,0.5] + [0.8,,1.2]}{2} = \frac{[1.8,,1.7]}{2} = [0.9,,0.85]. $$ MLP 变换:用一个MLP映射 $z_A^{(1)}$ 到 2 维输出: $$ A^{(1)} ;=; \mathrm{MLP_1}\bigl(z_A^{(1)}\bigr). $$ (数值略,可想象 $\mathrm{MLP}([0.9,0.85]) \approx [1.0,0.6]$ 之类。) 结果:$A^{(1)}$ 包含了 A 的初始特征 + B 的初始特征信息。 第 2 层更新:$A^{(1)} \to A^{(2)}$ 为了让 A 获得 2-hop 范围($C, D$)的信息,需要先让 $B$ 在第 1 层就吸收了 $C, D$ 的特征,从而 $B^{(1)}$ 蕴含 $C, D$ 信息。然后 A 在第 2 层再从 $B^{(1)}$ 聚合。 节点 B 在第 1 层(简要说明) 邻居:${A,C,D}$ 聚合:$z_B^{(1)} = \frac{B^{(0)} + A^{(0)} + C^{(0)} + D^{(0)}}{4} = \frac{[0.8,,1.2] + [1.0,,0.5] + [0.3,,0.7] + [1.5,,0.9]}{4} = \frac{[3.6,,3.3]}{4} = [0.9,,0.825].$ MLP 变换:$B^{(1)} = \mathrm{MLP}\bigl(z_B^{(1)}\bigr)$。 此时 $B^{(1)}$ 已经包含了 $C, D$ 的信息。 节点 $A$ 的第 2 层聚合 邻居:$B$,但此时要用 $B^{(1)}$(它已吸收 C、D) 聚合: $$ z_A^{(2)} = A^{(1)} + B^{(1)}. $$ MLP 变换: $$ A^{(2)} = \mathrm{MLP_2}\bigl(z_A^{(2)}\bigr). $$ 结果:$A^{(2)}$ 就包含了 2-hop 范围的信息,因为 $B^{(1)}$ 中有 $C, D$ 的贡献。 GNN 的层数就是节点聚合邻居信息的迭代次数(也是计算图的层数)。 同一层里,所有节点共享一组参数(同一个 MLP 或全连接神经网络) 矩阵运算 符号波浪号用于表示经过自环增强的矩阵。 $\tilde D^{-1},\tilde A,\tilde D^{-1}H$ $H'=\tilde D^{-1},\tilde A,H$ A | B / \ C D 1.构造矩阵 含自环邻接矩阵 $\tilde A=A+I$ $$ \tilde A = \begin{bmatrix} 1 & 1 & 0 & 0\\ 1 & 1 & 1 & 1\\ 0 & 1 & 1 & 0\\ 0 & 1 & 0 & 1 \end{bmatrix} $$ 度矩阵 $\tilde D$(对角=自身+邻居数量) $$ \tilde D = \mathrm{diag}(2,\,4,\,2,\,2) $$ 特征矩阵 $H$(每行为一个节点的特征向量) $$ H = \begin{bmatrix} 1.0 & 0.5\\ 0.8 & 1.2\\ 0.3 & 0.7\\ 1.5 & 0.9 \end{bmatrix} $$ **2.计算** 求和: $\tilde A,H$ $$ \tilde A H = \begin{bmatrix} 1.8 & 1.7\\ 3.6 & 3.3\\ 1.1 & 1.9\\ 2.3 & 2.1 \end{bmatrix} $$ 平均: $\tilde D^{-1}(\tilde A H)$ $$ \tilde D^{-1}\tilde A H = \begin{bmatrix} 0.90 & 0.85\\ 0.90 & 0.825\\ 0.55 & 0.95\\ 1.15 & 1.05 \end{bmatrix} $$ GCN 在 GCN 里,归一化(normalization)的核心目的就是 平衡不同节点在信息传播(message‑passing)中的影响力,避免「高连通度节点(high‑degree nodes)」主导了所有邻居的特征聚合。 $H' = \tilde D^{-1},\tilde A,\tilde D^{-1}H$ 对节点 $i$ 来说: $$ H'_i = \frac1{d_i}\sum_{j\in \mathcal N(i)}\frac1{d_j}\,H_j $$ 先用源节点 $j$ 的度 $d_j$ 缩小它的特征贡献,再用目标节点 $i$ 的度 $d_i$ 归一化总和。 GCN中实际的公式: $$ H^{(l+1)} = \sigma\Big(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}H^{(l)}W^{(l)}\Big) $$ 其中: $H^{(l)}$ 是第 $l$ 层的输入特征(对第 $0$ 层来说就是节点的初始特征), $W^{(l)}$ 是第 $l$ 层的可训练权重矩阵,相当于一个简单的线性变换(类似于 MLP 中的全连接层), $\sigma(\cdot)$ 是非线性激活函数(例如 ReLU), $\tilde{A}$ 是包含自连接的邻接矩阵, $\tilde{D}$ 是 $\tilde{A}$ 的度矩阵。 $\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}$的优势 1.对称归一化:$\tilde D^{-\frac{1}{2}},\tilde A,\tilde D^{-\frac{1}{2}}$ 是一个对称矩阵,这意味着信息在节点之间的传播是双向一致的。这种对称性特别适合无向图,因为无向图的邻接矩阵 $\tilde A$ 本身就是对称的。 2.适度抑制高连通度节点:对称平方根归一化通过 $\tilde D^{-\frac{1}{2}}$ 对源节点和目标节点同时进行归一化,能够适度抑制高连通度节点的特征贡献,而不会过度削弱其影响力。 3.谱半径控制:对称平方根归一化后的传播矩阵 $\tilde D^{-\frac{1}{2}},\tilde A,\tilde D^{-\frac{1}{2}}$ 的谱半径(最大特征值)被控制在 $[0, 1]$ 范围内,这有助于保证模型的数值稳定性。 4.归一化拉普拉斯矩阵:对称平方根归一化的传播矩阵 $\tilde D^{-\frac{1}{2}},\tilde A,\tilde D^{-\frac{1}{2}}$ 与归一化拉普拉斯矩阵 $L = I - \tilde D^{-\frac{1}{2}},\tilde A,\tilde D^{-\frac{1}{2}}$ 有直接联系。归一化拉普拉斯矩阵在图信号处理中具有重要的理论意义,能够更好地描述图的频谱特性。 GraphSAGE优化 $$ h_v^{(k+1)} = \sigma \Big( \mathbf{W}_{\text{self}}^{(k)} \cdot h_v^{(k)} \;+\; \mathbf{W}_{\text{neigh}}^{(k)} \cdot \mathrm{MEAN}_{u\in N(v)}\bigl(h_u^{(k)}\bigr) \Big), $$ GAT 以下例子只汇聚了一阶邻居信息! 图注意力网络(GAT)中最核心的运算:图注意力层。它的基本思想是: 线性变换:先对每个节点的特征 $\mathbf{h}_i$ 乘上一个可学习的权重矩阵 $W$,得到变换后的特征 $W \mathbf{h}_i$。 自注意力机制:通过一个可学习的函数 $a$,对节点 $i$ 和其邻居节点 $j$ 的特征进行计算,得到注意力系数 $e_{ij}$。这里会对邻居进行遮蔽(masked attention),即只计算图中有边连接的节点对。 归一化:将注意力系数 $e_{ij}$ 通过 softmax 进行归一化,得到 $\alpha_{ij}$,表示节点 $j$ 对节点 $i$ 的重要性权重。 聚合:最后利用注意力系数加权邻居节点的特征向量,并经过激活函数得到新的节点表示 $\mathbf{h}_i'$。 多头注意力:为增强表示能力,可并行地执行多个独立的注意力头(multi-head attention),再将它们的结果进行拼接(或在最后一层进行平均),从而得到最终的节点表示。 输入: 节点特征矩阵(Node Features) 形状:[num_nodes, num_features] 每个节点的初始特征向量,例如社交网络中用户的属性或分子图中原子的特征。 图的边结构(Edge Index) 形状:**[2, num_edges](稀疏邻接表格式)**或稠密邻接矩阵 [num_nodes, num_nodes](最好是将邻接矩阵转为邻接表) 定义图中节点的连接关系(有向/无向边)。 预训练的GAT模型参数 包括注意力层的权重矩阵、注意力机制参数等(通过model.load_state_dict()加载) 线性变换(特征投影) 目的:将原始特征映射到更高维/更有表达力的空间。 操作:对每个节点的特征向量 $\mathbf{h}_i$ 左乘可学习权重矩阵 $W$(维度为 $d' \times d$,$d$ 是输入特征维度,$d'$ 是输出维度): $$ \mathbf{z}_i = W \mathbf{h}_i, \quad \mathbf{z}_j = W \mathbf{h}_j $$ 自注意力系数计算(关键步骤) 目标:计算节点 $i$ 和邻居 $j$ 之间的未归一化注意力得分 $e_{ij}$。 实现方式: 步骤1:将两个节点的投影特征 $\mathbf{z}_i$ 和 $\mathbf{z}_j$ 拼接($|$),得到一个联合表示。 步骤2:通过一个可学习的参数向量 $\mathbf{a}$(维度 $2d'$)和激活函数(如LeakyReLU)计算得分: $$ e_{ij} = \text{LeakyReLU}\Bigl(\mathbf{a}^\top [\mathbf{z}_i | \mathbf{z}_j]\Bigr) $$ 直观理解:$\mathbf{a}$ 像一个"问题",询问两个节点的联合特征有多匹配。 公式拆分: 拼接:$[\mathbf{z}_i | \mathbf{z}_j]$(长度 $2d'$) 点积:$\mathbf{a}^\top [\mathbf{z}_i | \mathbf{z}_j]$(标量) 非线性激活:LeakyReLU(引入稀疏性,避免负值被完全抑制) 归一化注意力权重 目的:让注意力系数在邻居间具有可比性(总和为1)。 方法:对 $e_{ij}$ 应用 softmax,仅对节点 $i$ 的邻居 $\mathcal{N}i$ 归一化: $$ \alpha{ij} = \text{softmax}j(e{ij}) = \frac{\exp(e_{ij})}{\sum_{k \in \mathcal{N}i} \exp(e{ik})} $$ 关键点:分母只包含节点 $i$ 的直接邻居(包括自己,如果图含自环)。 注意力系数计算示例(带数值模拟) 假设: 输入特征 $\mathbf{h}_i = [1.0, 2.0]$, $\mathbf{h}_j = [0.5, 1.5]$(维度 $d=2$) 权重矩阵 $W = \begin{bmatrix}0.1 & 0.2 \ 0.3 & 0.4\end{bmatrix}$($d'=2$) 参数向量 $\mathbf{a} = [0.5, -0.1, 0.3, 0.2]$(长度 $2d'=4$) 计算步骤: 线性变换: $$ \mathbf{z}_i = W \mathbf{h}_i = [0.1 \times 1.0 + 0.2 \times 2.0,\ 0.3 \times 1.0 + 0.4 \times 2.0] = [0.5, 1.1] $$ $$ \mathbf{z}_j = W \mathbf{h}_j = [0.1 \times 0.5 + 0.2 \times 1.5,\ 0.3 \times 0.5 + 0.4 \times 1.5] = [0.35, 0.75] $$ 拼接特征: $$ [\mathbf{z}_i | \mathbf{z}_j] = [0.5, 1.1, 0.35, 0.75]\ [\mathbf{z}_i | \mathbf{z}_i] = [0.5, 1.1, 0.5, 1.1] $$ 计算未归一化得分: $$ e_{ij} = \text{LeakyReLU}(0.5 \times 0.5 + (-0.1) \times 1.1 + 0.3 \times 0.35 + 0.2 \times 0.75) = \text{LeakyReLU}(0.25 - 0.11 + 0.105 + 0.15) = \text{LeakyReLU}(0.395) = 0.395 $$ $$ e_{ii} = \text{LeakyReLU}(0.5 \times 0.5 + (-0.1) \times 1.1 + 0.3 \times 0.5 + 0.2 \times 1.1)=0.51 $$ (假设LeakyReLU斜率为0.2,正输入不变) 归一化(假设邻居只有 $j$ 和自身 $i$): $$ \alpha_{ij} = \frac{\exp(0.395)}{\exp(0.395) + \exp(0.51)}\approx 0.529 $$ 特征聚合 单头注意力聚合(得到新的节点特征) $$ \mathbf{h}_i' = \sigma\Bigl(\sum_{j \in \mathcal{N}_i} \alpha_{ij} \,W \mathbf{h}_j\Bigr)=\sigma\left(\sum_{j \in \mathcal{N}_i} \alpha_{ij} \mathbf{z}_j\right) $$ 对$i$ 的邻居节点加权求和,再经过非线性激活函数得到新的特征表示 多头注意力(隐藏层时拼接) 每个头都有自己的一组可学习参数,并独立计算注意力系数和输出特征。以捕捉邻居节点的多种不同关系或特征。 如果有 $K$ 个独立的注意力头,每个头输出 $\mathbf{h}_i'^{(k)}$,则拼接后的输出为: $$ \begin{align*} \mathbf{h}_i' = \Bigg\Vert_{\substack{k=1 \\ ~}}^{K} \mathbf{h}_i^{(k)} \end{align*} $$ 其中,$\big\Vert$ 表示向量拼接操作,$\alpha_{ij}^{(k)}$、$W^{(k)}$ 分别为第 $k$ 个注意力头对应的注意力系数和线性变换。 例假如: $$ \mathbf{h}_i'^{(1)} = \sigma\left(\begin{bmatrix} 0.6 \\ 0.4 \end{bmatrix}\right) = \begin{bmatrix} 0.6 \\ 0.4 \end{bmatrix}. \\ \mathbf{h}_i'^{(2)} = \sigma\left(\begin{bmatrix} 0.6 \\ 1.4 \end{bmatrix}\right) = \begin{bmatrix} 0.6 \\ 1.4 \end{bmatrix}. $$ 将两个头的输出在特征维度上进行拼接,得到最终节点 $i$ 的新特征表示: $$ \mathbf{h}_i' = \mathbf{h}_i'^{(1)} \,\Vert\, \mathbf{h}_i'^{(2)} = \begin{bmatrix} 0.6 \\ 0.4 \end{bmatrix} \,\Vert\, \begin{bmatrix} 0.6 \\ 1.4 \end{bmatrix} = \begin{bmatrix} 0.6 \\ 0.4 \\ 0.6 \\ 1.4 \end{bmatrix}. $$ 意义:不同注意力头可以学习到节点之间不同类型的依赖关系。例如: 一个头可能关注局部邻居(如一阶邻居的拓扑结构), 另一个头可能关注全局特征相似性(如节点特征的余弦相似性)。 多头注意力(输出层时平均) 在最终的输出层(例如分类层)通常会将多个头的结果做平均,而不是拼接: $$ \begin{align*} \mathbf{h}_i' = \sigma\left(\frac{1}{K}\sum_{k=1}^K \mathbf{h}_i^{(k)}\right) \end{align*} $$ 多头注意力比喻:盲人摸象 + 团队合作 场景: 大象 = 图中的目标节点及其邻居(待分析的复杂结构) 盲人 = 多个注意力头(每个头独立"观察") 团队指挥 = 损失函数(指导所有盲人协作) 1. 初始摸象(前向传播) 盲人A(头1): 摸到腿(关注局部结构邻居),心想:"柱子!这动物像房子。"(生成表示 $\mathbf{h}_i^{(1)}$) 初始偏好:腿的粗细、纹理(权重 $W^{(1)}$ 和 $\mathbf{a}^{(1)}$ 的初始化倾向) 盲人B(头2): 摸到鼻子(关注特征相似的邻居),心想:"软管!这动物能喷水。"(生成表示 $\mathbf{h}_i^{(2)}$) 初始偏好:鼻子的长度、灵活性(权重 $W^{(2)}$ 和 $\mathbf{a}^{(2)}$ 不同) 盲人C(头3): 摸到尾巴(关注远距离邻居),心想:"绳子!这动物有附件。"(生成表示 $\mathbf{h}_i^{(3)}$) 2. 团队汇报(多头聚合) 综合报告: 将三人的描述拼接:"柱子+软管+绳子"($\mathbf{h}_i' = \text{concat}(\mathbf{h}_i^{(1)}, \mathbf{h}_i^{(2)}, \mathbf{h}_i^{(3)})$) 指挥者(分类器)猜测:"这可能是大象。"(预测结果 $\hat{y}_i$) 3. 指挥者反馈(损失函数) 真实答案:是大象(标签 $y_i$) 损失计算: 当前综合报告遗漏了"大耳朵"(交叉熵损失 $\mathcal{L}$ 较高) 指挥者说:"接近答案,但还缺关键特征!"(反向传播梯度) 4. 盲人调整(梯度更新) 盲人A(头1): 听到反馈:"需要更多特征,但你的柱子描述还行。" 调整:更精确测量腿的直径和硬度(更新 $W^{(1)}$),而非改摸鼻子 结果:下次报告"粗柱子上有横向褶皱"(更接近象腿的真实特征) 盲人B(头2): 听到反馈:"软管描述不够独特。" 调整:更仔细感受鼻子的褶皱和肌肉运动(更新 $W^{(2)}$) 结果:下次报告"可弯曲的软管,表面有环形纹路" 盲人C(头3): 听到反馈:"绳子太模糊。" 调整:注意尾巴的末端毛发(更新 $W^{(3)}$) 结果:下次报告"短绳末端有硬毛刷" 5. 最终协作 新一轮综合报告:"褶皱粗柱 + 环形软管 + 带毛刷短绳" → 指挥者确认:"是大象!"(损失 $\mathcal{L}$ 降低) 直推式学习与归纳式学习 直推式学习(Transductive Learning) 模型直接在固定的训练图上学习节点的表示或标签,结果只能应用于这张图中的节点,无法直接推广到新的、未见过的节点或图。 例如:DeepWalk ,它通过对固定图的随机游走生成节点序列来学习节点嵌入,因此只能得到训练图中已有节点的表示,一旦遇到新节点,需要重新训练或进行特殊处理。 注意:GCN是直推式的,因为它依赖于整个图的归一化邻接矩阵进行卷积操作,需要在固定图上训练。 归纳式学习(Inductive Learning) 模型学习的是一个映射函数或规则,可以将这种规则推广到未见过的新节点或新图上。这种方法能够处理动态变化的图结构或新的数据。 例如: 图神经网络的变体(GAT)都是归纳式的,因为它们在聚合邻居信息时学习一个共享的函数,该函数能够应用于任意新节点。 局部计算:GAT 的注意力机制仅在每个节点的局部邻域内计算,不依赖于全局图结构。 参数共享:模型中每一层的参数(如 $W$ 和注意力参数 $\mathbf{a}$)是共享的,可以直接应用于新的、未见过的图。 泛化到新节点:在许多推荐系统中,如果有新用户加入(新节点),我们需要给他们做个性化推荐,这就要求系统能够在不重新训练整个模型的情况下,为新用户生成表示(Embedding),并且完成推荐预测。 泛化到新图: 分子图预测。我们会用一批训练分子(每个分子是一张图)来训练一个 GNN 模型,让它学会如何根据图结构与原子特征来预测分子的某些性质(如毒性、溶解度、活性等)。训练完成后,让它在新的分子上做预测。 总结:直推式要求图的邻接矩阵不能变化,归纳式要求现有的邻接关系尽量不变化,支持少量节点新加入,直接复用已有W和a聚合特征。 GNN的优点: 参数共享 浅层嵌入(如Deepwalk)为每个节点单独学习一个向量,参数量随节点数线性增长。 GNN 使用统一的消息传递/聚合函数,所有节点共享同一套模型参数,大幅减少参数量。 归纳式学习 浅层方法通常无法直接处理训练时未见过的新节点。 GNN 能通过邻居特征和结构来生成新节点的表示,实现对新节点/新图的泛化。 利用节点特征 浅层方法多半只基于连接关系(图结构)。 GNN 可以直接整合节点的属性(文本、图像特征等),生成更具语义信息的嵌入。 更强的表达能力 GNN 通过多层聚合邻居信息,可学习到更丰富的高阶结构和特征交互,往往在多种任务上表现更优。
科研
zy123
3月21日
0
11
0
上一页
1
...
3
4
5
下一页