首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
41 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
推荐文章
推荐
拼团设计模式
项目
1年前
0
12
0
推荐
拼团交易系统
项目
1年前
0
41
1
推荐
Smile云图库
项目
1年前
0
60
0
热门文章
146 ℃
同步本地Markdown至Typecho站点
项目
1年前
0
146
0
47 ℃
微服务
后端学习
1年前
0
47
0
43 ℃
苍穹外卖
项目
1年前
0
43
0
最新发布
2025-07-30
mermaid画图
mermaid画图 graph TD A[多智能体随机网络结构分析] --> B[多智能体协同学习与推理] A --> A1["谱参数实时估算"] A1 --> A11["卡尔曼滤波"] A1 --> A12["矩阵扰动理论"] A1 --> A13["输出:谱参数"] A --> A2["网络拓扑重构"] A2 --> A21["低秩分解重构"] A2 --> A22["聚类量化"] A2 --> A23["输出:邻接矩阵、特征矩阵"] graph TD B[多智能体协同学习与推理] B --> B1["联邦学习、强化学习"] B1 --> B11["谱驱动学习率调整"] B1 --> B12["自适应节点选择策略"] B --> B2["动态图神经网络"] B2 --> B21["动态图卷积设计"] B2 --> B22["一致性推理"] graph TD %% 颜色和样式定义 classDef startEnd fill:#e6ffe6,stroke:#333,stroke-width:2px classDef operation fill:#fff,stroke:#000,stroke-width:1px classDef decision fill:#ffcccc,stroke:#000,stroke-width:1px classDef update fill:#ccffcc,stroke:#000,stroke-width:1px %% 节点定义(严格按图片顺序) A([开始]):::startEnd B[交易信息\n外部订单号]:::operation C{判断是否为锁单订单}:::decision D[查询拼团组队信息]:::operation E[更新订单详情\n状态为交易完成]:::update F[更新拼团组队进度]:::update G{拼团组队完结\n目标量判断}:::decision H[写入回调任务表]:::operation I([结束]):::startEnd %% 流程连接(完全还原图片走向) A --> B B --> C C -->|是| D D --> E E --> F F --> G G -->|是| H H --> I C -->|否| I G -->|否| I %% 保持原图连接线样式 linkStyle 0,1,2,3,4,5,6,7,8 stroke-width:1px graph TD A[用户发起退单请求] --> B{检查拼团状态} B -->|拼团未完成| C1[场景1:拼团中退单] C1 --> D1{是否已支付?} D1 -->|未支付| E1[取消订单] E1 --> F1[更新订单状态为2] F1 --> G1[通知拼团失败] G1 --> H1[退单完成] D1 -->|已支付| I1[发起退款] I1 --> F1 B -->|拼团已完成| C2[场景2:完成后退单] C2 --> D2{是否超时限?} D2 -->|未超时| E2[发起退款] E2 --> F2[更新订单状态] F2 --> H1 D2 -->|超时| G2[退单失败] style A fill:#f9f,stroke:#333 style B fill:#66f,stroke:#333 style C1 fill:#fbb,stroke:#f66 style C2 fill:#9f9,stroke:#090 flowchart LR %% ===================== 左侧:模板模式块 ===================== subgraph Template["设计模式 - 模板"] direction TB SM["StrategyMapper 策略映射器"] SH["StrategyHandler 策略处理器"] ASR["AbstractStrategyRouter<T, D, R> 策略路由抽象类"] SM -->|实现| ASR SH -->|实现| ASR end %% ===================== 右侧:策略工厂与支持类 ===================== DASFactory["DefaultActivityStrategyFactory 默认的拼团活动策略工厂"] AGMS["AbstractGroupBuyMarketSupport 功能服务支撑类"] DASFactory --> AGMS AGMS -->|继承| ASR %% ===================== 业务节点链路 ===================== Root["RootNode 根节点"] Switch["SwitchRoot 开关节点"] Market["MarketNode 营销节点"] End["EndNode 结尾节点"] Other["其他节点"] AGMS --> Root Root --> Switch Switch --> Market Market --> End Switch -.-> Other Other --> End %% ===================== 样式(可选) ===================== classDef green fill:#DFF4E3,stroke:#3B7A57,stroke-width:1px; classDef red fill:#E74C3C,color:#fff,stroke:#B03A2E; classDef purple fill:#7E60A2,color:#fff,stroke:#4B3B6B; classDef blue fill:#3DA9F5,color:#fff,stroke:#1B6AA5; class SM,SH,Root,Switch,Market,End,Other green; class DASFactory red; class AGMS purple; class ASR blue; style Template stroke-dasharray: 5 5; sequenceDiagram participant A as 启动时 participant B as BeanPostProcessor participant C as 管理后台 participant D as Redis Pub/Sub participant E as RTopic listener participant F as Bean 字段热更新 A->>B: 扫描 @DCCValue 标注的字段 B->>B: 写入默认值 / 读取 Redis B->>B: 注入字段值 B->>B: 缓存 key→Bean 映射 A->>A: Bean 初始化完成 C->>D: publish("myKey,newVal") D->>E: 订阅频道 "dcc_update" E->>E: 收到消息,更新 Redis E->>E: 从 Map 找到 Bean E->>E: 反射注入新值到字段 E->>F: Bean 字段热更新完成 sequenceDiagram participant A as 后台/系统 participant B as Redis Pub/Sub participant C as DCC监听器 participant D as Redis数据库 participant E as 反射更新字段 participant F as Bean实例 A->>B: 发布消息 ("cutRange:50") B->>D: 将消息 "cutRange:50" 写入 Redis B->>C: 触发订阅者接收消息 C->>D: 更新 Redis 中的 "cutRange" 配置值 C->>F: 根据映射找到对应的 Bean C->>E: 通过反射更新 Bean 中的字段 E->>C: 更新成功,字段值被同步 C->>A: 配置变更更新完成 flowchart LR A[请求进入链头 Head] --> B[节点1: 日志LogLink] B -->|继续| C[节点2: 权限AuthLink] B -->|直接返回/终止| R1[返回结果] C -->|通过→继续| D[节点3: 审批ApproveLink] C -->|不通过→终止| R2[返回失败结果] D --> R3[返回成功结果] classDef node fill:#eef,stroke:#669; classDef ret fill:#efe,stroke:#393; class A,B,C,D node; class R1,R2,R3 ret; flowchart LR subgraph mall["小型支付商城"] style mall fill:#ffffff,stroke:#333,stroke-width:2 A[AliPayController<br/>发起退单申请]:::blue C[订单状态扭转<br/>退单中]:::grey E[RefundSuccessTopicListener<br/>接收MQ消息<br/>执行退款和订单状态变更]:::green end subgraph pdd["拼团系统"] style pdd fill:#ffffff,stroke:#333,stroke-width:2 B[MarketTradeController<br/>接收退单申请]:::yellow D[TradeRefundOrderService<br/>退单策略处理]:::red F[TradeRepository<br/>发送MQ消息]:::purple G([MQ消息队列<br/>退单成功消息]):::orange H[RefundSuccessTopicListener<br/>接收MQ消息<br/>恢复库存]:::green end A -- "1. 发起退单请求" --> B B -- "2. 处理退单" --> D D -- "3. 发送MQ消息" --> F F -- "4. 发布消息 (异步+本地消息表补偿)" --> G F -- "5. 返回结果" --> C G -- "6. 消费消息 (恢复库存)" --> H G -. "7. 消费消息 (执行退款)" .-> E classDef blue fill:#dbe9ff,stroke:#6fa1ff,stroke-width:1; classDef grey fill:#e5e5e5,stroke:#9e9e9e,stroke-width:1; classDef green fill:#d6f2d6,stroke:#76b076,stroke-width:1; classDef yellow fill:#fef3cd,stroke:#f5c700,stroke-width:1; classDef red fill:#f8d7da,stroke:#e55353,stroke-width:1; classDef purple fill:#e4dbf9,stroke:#9370db,stroke-width:1; classDef orange fill:#ffecca,stroke:#ffa500,stroke-width:1; sequenceDiagram participant Client as 前端 participant WS as WebSocket 服务器 participant Auth as 权限校验 participant Dispatcher as 消息分发器 participant Handler as 消息处理器 Client->>WS: 请求建立 WebSocket 连接 WS->>Auth: 校验用户权限 Auth-->>WS: 校验通过,保存用户和图片信息 WS-->>Client: 连接成功 Client->>WS: 发送消息(包含消息类型) WS->>Dispatcher: 根据消息类型分发 Dispatcher->>Handler: 执行对应的消息处理逻辑 Handler-->>Dispatcher: 返回处理结果 Dispatcher-->>WS: 返回处理结果 WS-->>Client: 返回处理结果给客户端 Client->>WS: 断开连接 WS-->>Client: 删除 WebSocket 会话,释放资源 sequenceDiagram participant Client as Client(浏览器) participant WS as WebSocket Endpoint participant Producer as PictureEditEventProducer participant RB as RingBuffer participant Worker as PictureEditEventWorkHandler participant Handler as PictureEditHandler Client->>WS: 发送 PictureEditRequestMessage WS->>Producer: publishEvent(msg, session, user, pictureId) Producer->>RB: next() 获取序号,写入事件字段 Producer->>RB: publish(sequence) 发布 RB-->>Worker: 回调 onEvent(event) Worker->>Worker: 解析 type -> PictureEditMessageTypeEnum alt ENTER_EDIT Worker->>Handler: handleEnterEditMessage(...) else EXIT_EDIT Worker->>Handler: handleExitEditMessage(...) else EDIT_ACTION Worker->>Handler: handleEditActionMessage(...) else 其他/异常 Worker->>WS: sendMessage(ERROR 响应) end Worker-->>Client: 业务处理后的响应(通过 WS) sequenceDiagram participant Client as WebSocket Client participant IO as WebSocket I/O线程 participant Biz as 业务逻辑(耗时) Client->>IO: 收到消息事件(onMessage) IO->>Biz: 执行业务逻辑(耗时3s) Biz-->>IO: 返回结果 IO->>Client: 发送响应 Note over IO: I/O线程被业务阻塞3s 不能处理其他连接的消息 sequenceDiagram participant Client as WebSocket Client participant IO as WebSocket I/O线程 participant Disruptor as RingBuffer队列 participant Worker as Disruptor消费者线程 participant Biz as 业务逻辑(耗时) Client->>IO: 收到消息事件(onMessage) IO->>Disruptor: 发布事件(快速) Disruptor-->>IO: 立即返回 IO->>Client: (继续处理其他连接消息) Worker->>Biz: 异步执行业务逻辑(耗时3s) Biz-->>Worker: 返回结果 Worker->>Client: 通过WebSocket发送响应 flowchart TD A[客户端发起WebSocket连接] --> B[HTTP握手阶段] B --> C[WsHandshakeInterceptor.beforeHandshake] C -->|校验失败| D[拒绝握手 连接关闭] C -->|校验成功| E[建立WebSocket连接] E --> F[PictureEditHandler] F --> G[处理WebSocket消息 收发数据] flowchart TD A([接收请求]) --> B{查询本地缓存 Caffeine} B -- 命中 --> C[返回本地缓存数据] C --> End1(((结束))) B -- 未命中 --> D{查询分布式缓存 Redis} D -- 命中 --> E[更新本地缓存] E --> F[返回 Redis 缓存数据] F --> End2(((结束))) D -- 未命中 --> G[查询数据库] G --> H[更新本地缓存和 Redis 缓存] H --> I[返回数据库数据] I --> End3(((结束))) classDiagram class ImageSearchApiFacade { +searchImage(localImagePath) } class GetImagePageUrlApi { +getImagePageUrl(localImagePath) } class GetImageFirstUrlApi { +getImageFirstUrl(imagePageUrl) } class GetImageListApi { +getImageList(imageFirstUrl) } ImageSearchApiFacade --> GetImagePageUrlApi : Calls ImageSearchApiFacade --> GetImageFirstUrlApi : Calls ImageSearchApiFacade --> GetImageListApi : Calls erDiagram 用户 { BIGINT 用户ID VARCHAR 用户名 } 角色 { BIGINT 角色ID VARCHAR 角色名称 VARCHAR 描述 } 权限 { BIGINT 权限ID VARCHAR 权限名称 VARCHAR 描述 } 用户 }o--o{ 角色 : 拥有 角色 }o--o{ 权限 : 赋予 classDiagram class Collection { <<interface>> +add() +remove() +clear() +size() } class Set { <<interface>> } class List { <<interface>> } class Queue { <<interface>> } class Map { <<interface>> } class HashSet { <<class>> } class TreeSet { <<class>> } class ArrayList { <<class>> } class LinkedList { <<class>> } class PriorityQueue { <<class>> } class HashMap { <<class>> } class TreeMap { <<class>> } Collection <|-- Set Collection <|-- List Collection <|-- Queue Set <|-- HashSet Set <|-- TreeSet List <|-- ArrayList List <|-- LinkedList Queue <|-- LinkedList Queue <|-- PriorityQueue Map <|-- HashMap Map <|-- TreeMap sequenceDiagram participant U as 用户 participant O as 下单服务 participant P as 拼团/优惠服务 participant R as 风控/库存校验 U ->> O: 请求锁单(userId, goodsId, activityId, teamId) activate O %% Step 1 幂等查询 O ->> P: 幂等查询(out_trade_no 是否已有锁单) P -->> O: 存在则直接返回该条记录 %% Step 2 拼团人数校验 O ->> P: 校验拼团人数(再次拉取,避免前端滞后) P -->> O: 校验结果 %% Step 3 优惠试算 O ->> P: 优惠试算(activityId, goodsId) P -->> O: 返回拼团优惠价格 %% Step 4 人群限定 O ->> R: 校验是否在目标人群范围 R -->> O: 校验结果(非目标人群直接拒绝) %% Step 5 锁单责任链 O ->> P: 活动有效性校验 O ->> P: 用户参与次数校验 O ->> R: 剩余库存校验 O -->> U: 返回锁单结果(成功/失败) deactivate O flowchart TD A[initialize @PostConstruct] --> B[fetchAllPictureTableNames] B -->|查询 SpaceService| C[组装所有表名 picture + picture_xxx] C --> D[updateShardingTableNodes] D --> E[getContextManager] E --> F[获取 ShardingSphereRuleMetaData] F --> G[更新 ShardingRuleConfiguration.actual-data-nodes] G --> H[alterRuleConfiguration + reloadDatabase] subgraph 动态建表 I[createSpacePictureTable] --> J{space 是否旗舰团队?} J -- 否 --> K[不建表] J -- 是 --> L[SqlRunner 创建新表 picture_xxx] L --> D end flowchart TD %% 定义节点 Publisher[Publisher<br/>消息发布者] Exchange[fanout Exchange<br/>扇形交换机] Queue1[Queue1] Queue2[Queue2] Queue3[Queue3] Consumer1[Consumer1] Consumer2[Consumer2] Consumer3[Consumer3] Msg[msg] %% 消息流向 Publisher -->|发布消息| Exchange Exchange -->|广播消息| Queue1 Exchange -->|广播消息| Queue2 Exchange -->|广播消息| Queue3 Queue1 -->|投递消息| Consumer1 Queue2 -->|投递消息| Consumer2 Queue3 -->|投递消息| Consumer3 %% 确认回执 Consumer1 -->|ack<br/>成功处理,删除消息| Queue1 Consumer2 -->|nack<br/>处理失败,重新投递| Queue2 Consumer3 -->|reject<br/>处理失败并拒绝,删除消息| Queue3 %% 样式定义 classDef publisher fill:#e1f5fe,stroke:#01579b; classDef exchange fill:#d1c4e9,stroke:#4527a0; classDef queue fill:#f8bbd0,stroke:#880e4f; classDef consumer fill:#c8e6c9,stroke:#1b5e20; class Publisher publisher; class Exchange exchange; class Queue1,Queue2,Queue3 queue; class Consumer1,Consumer2,Consumer3 consumer; flowchart TD subgraph 运营 A1[配置拼团] end subgraph 用户 B1[查看商品] end subgraph 用户A/B C1[参与拼团] end %% 运营流程 A1 --> A2[拼团折扣] A2 --> A3[团长优惠] A3 --> A4[人群标签] %% 用户查看拼团 B1 --> B2[查看拼团] B2 --> B3[优惠试算] B3 --> B4[展示拼团] %% 用户参与拼团 C1 --> D1[商品支付 / 折扣支付] D1 --> D2[展示拼团 + 分享] D1 --> D3[拼团系统] D3 --> D4[记录拼团/多人拼团] D4 --> D5[团购回调/回调地址] D3 --> D6[拼团超时/拼团失败] D6 --> D7[发起退单] D7 --> D8[团购回调/回调地址] %% 拼团后逻辑 D1 --> E1[拼团订单 暂不发货] E1 --> E2[免拼下单 直接成单] E2 --> E3[拼团完成 商品发货] D6 --> F1[拼团失败 商品退单] E1 --> E4[直接购买 放弃拼团] E4 --> F1 E3 -->|成功| End1([结束]) F1 -->|失败| End2([结束]) flowchart TD A[Throwable] --> B[Error] A --> C[Exception] B --> D[虚拟机错误<br>VirtualMachineError] B --> E[内存溢出错误<br>OutOfMemoryError] B --> F[栈溢出错误<br>StackOverflowError] C --> G[IOException] C --> H[RuntimeException] C --> I[检查异常<br>Checked Exception<br>(除RuntimeException外的Exception)] G --> J[FileNotFoundException] G --> K[EOFException] H --> L[空指针异常<br>NullPointerException] H --> M[数组越界异常<br>ArrayIndexOutOfBoundsException] H --> N[类型转换异常<br>ClassCastException] H --> O[算术异常<br>ArithmeticException] flowchart TD A[请求进入方法] --> B{@DCCValue("rateLimiterSwitch:open") == "close"?} B -- 是 --> Z[直接放行<br>不执行限流逻辑] --> END[方法正常返回] B -- 否 --> C[@RateLimiterAccessInterceptor 拦截方法] C --> D[解析注解参数<br>获取限流维度 key] D --> E[反射提取方法参数中的字段值<br>如 userId] E --> F[生成 Redis Key<br>rl:limiter:userId] F --> G{是否在黑名单中?} G -- 是 --> H[调用 fallbackMethod<br>执行降级逻辑] --> END G -- 否 --> I[通过 RRateLimiter 尝试获取令牌] I -- 成功获取令牌 --> J[执行目标方法] --> END I -- 未获取令牌 --> K[记录拒绝次数<br>RAtomicLong 自增] K --> L{拒绝次数 > blacklistCount?} L -- 是 --> M[加入黑名单<br>设置 Key: rl:bl:userId<br>过期24小时] --> N[调用 fallbackMethod] L -- 否 --> N[调用 fallbackMethod] N --> END[降级逻辑返回结果]
杂项
zy123
1年前
0
9
0
2025-07-05
Mybatis&-Plus
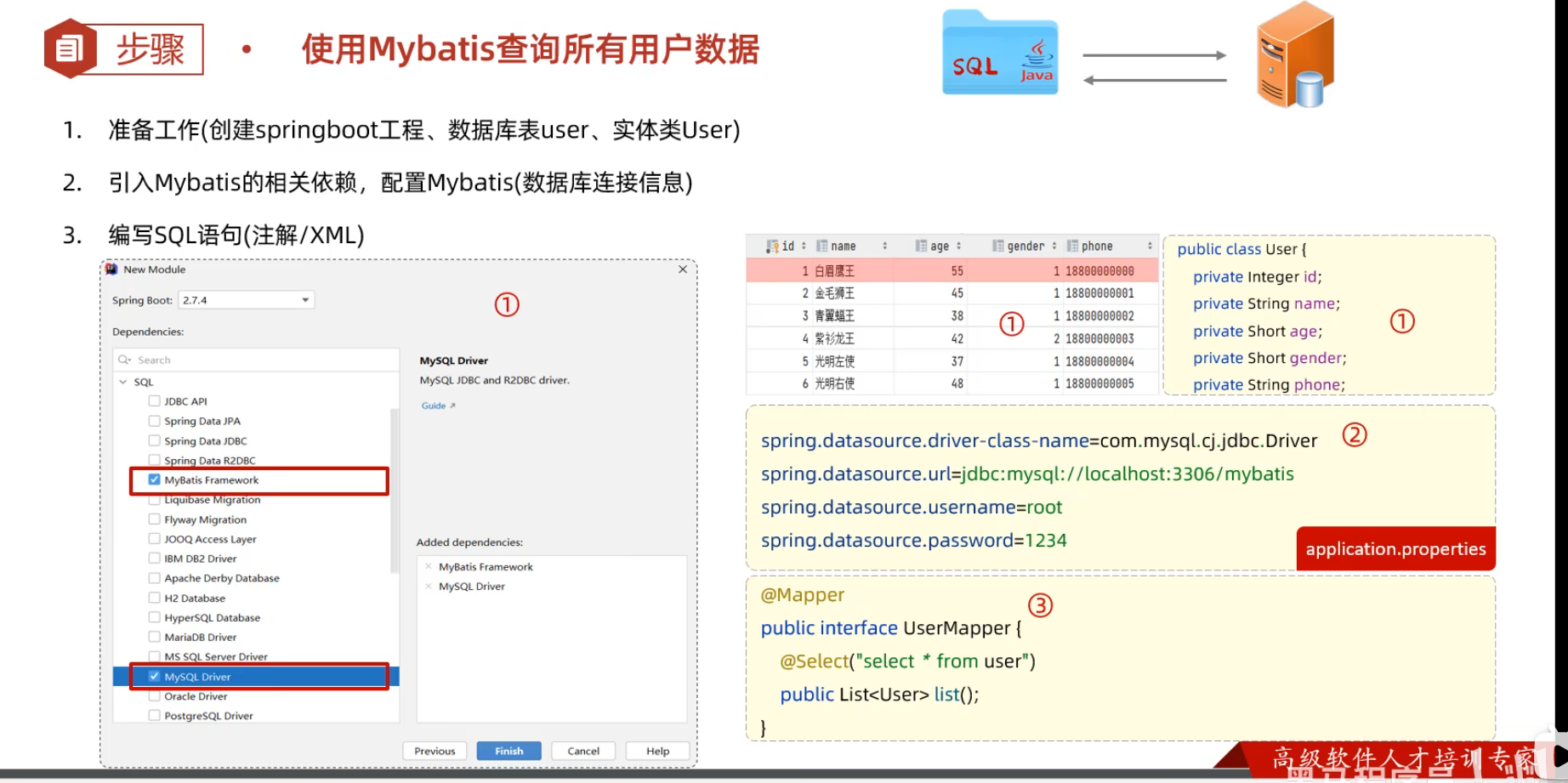
Mybatis 快速创建 创建springboot工程(Spring Initializr),并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User 在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。 #驱动类名称 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #数据库连接的url spring.datasource.url=jdbc:mysql://localhost:3306/mybatis #连接数据库的用户名 spring.datasource.username=root #连接数据库的密码 spring.datasource.password=1234 在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper @Mapper注解:表示是mybatis中的Mapper接口 -程序运行时:框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理 @Select注解:代表的就是select查询,用于书写select查询语句 @Mapper public interface UserMapper { //查询所有用户数据 @Select("select * from user") public List<User> list(); } 数据库连接池 数据库连接池是一个容器,负责管理和分配数据库连接(Connection)。 在程序启动时,连接池会创建一定数量的数据库连接。 客户端在执行 SQL 时,从连接池获取连接对象,执行完 SQL 后,将连接归还给连接池,以供其他客户端复用。 如果连接对象长时间空闲且超过预设的最大空闲时间,连接池会自动释放该连接。 优势:避免频繁创建和销毁连接,提高数据库访问效率。 Druid(德鲁伊) Druid连接池是阿里巴巴开源的数据库连接池项目 功能强大,性能优秀,是Java语言最好的数据库连接池之一 把默认的 Hikari 数据库连接池切换为 Druid 数据库连接池: 在pom.xml文件中引入依赖 <dependency> <!-- Druid连接池依赖 --> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency> 在application.properties中引入数据库连接配置 spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.druid.username=root spring.datasource.druid.password=123456 SQL注入问题$和# SQL注入:由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。 在Mybatis中提供的参数占位符有两种:${...} 、#{...} #{...} 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值 使用时机:参数传递,都使用#{…} ${...} 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题 使用时机:如果对表名、列表进行动态设置时使用 <select id="selectFromDynamicTable" resultType="User"> SELECT * FROM ${tableName} WHERE id = #{id} </select> userMapper.selectFromDynamicTable("user_2025", 1); 驼峰命名法 在 Java 项目中,数据库表字段名一般使用 下划线命名法(snake_case),而 Java 中的变量名使用 驼峰命名法(camelCase)。 小驼峰命名(lowerCamelCase): 第一个单词的首字母小写,后续单词的首字母大写。 例子:firstName, userName, myVariable 大驼峰命名(UpperCamelCase): 每个单词的首字母都大写,通常用于类名或类型名。 例子:MyClass, EmployeeData, OrderDetails 表中查询的数据封装到实体类中 实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。 解决方法: 起别名 结果映射 开启驼峰命名 属性名和表中字段名保持一致 开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射 驼峰命名规则: abc_xyz => abcXyz 表中字段名:abc_xyz 类中属性名:abcXyz 增删改 增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void! 作用于单个字段 @Mapper public interface EmpMapper { //SQL语句中的id值不能写成固定数值,需要变为动态的数值 //解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句 /** * 根据id删除数据 * @param id 用户id */ @Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值 public void delete(Integer id); } 上图参数值分离,有效防止SQL注入 作用于多个字段 @Mapper public interface EmpMapper { //会自动将生成的主键值,赋值给emp对象的id属性 @Options(useGeneratedKeys = true,keyProperty = "id") @Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})") public void insert(Emp emp); } 在 @Insert 注解中使用 #{} 来引用 Emp 对象的属性,MyBatis 会自动从 Emp 对象中提取相应的字段并绑定到 SQL 语句中的占位符。 @Options(useGeneratedKeys = true, keyProperty = "id") 这行配置表示,插入时自动生成的主键会赋值给 Emp 对象的 id 属性。 // 调用 mapper 执行插入操作 empMapper.insert(emp); // 现在 emp 对象的 id 属性会被自动设置为数据库生成的主键值 System.out.println("Generated ID: " + emp.getId()); 查 查询案例: 姓名:要求支持模糊匹配 性别:要求精确匹配 入职时间:要求进行范围查询 根据最后修改时间进行降序排序 重点在于模糊查询时where name like '%#{name}%' 会报错。 为什么? where name like '%#{name}%' MyBatis 会先解析 #{name},并用 ? 替换: where name like '%?%' 于是 SQL 就变成了一个 非法语法,数据库执行时会报错。 解决方案: 使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%') CONCAT() 如果其中任何一个参数为 NULL,CONCAT() 返回 NULL,Like NULL会导致查询不到任何结果! NULL和''是完全不同的 当 #{name} = '张三' → 结果是 '%张三%',能正常匹配。 当 #{name} = ''(空字符串) → 结果是 '%%',等价于 %,会匹配所有字符串。 当 #{name} = NULL → 结果是 NULL,SQL 变成: @Mapper public interface EmpMapper { @Select("select * from emp " + "where name like concat('%',#{name},'%') " + "and gender = #{gender} " + "and entrydate between #{begin} and #{end} " + "order by update_time desc") public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end); } 为了避免无意义查询,如果name == null或name=='' 就不要拼接like 条件,后面动态SQL会做优化。 XML配置文件规范 使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。 在Mybatis中使用XML映射文件方式开发,需要符合一定的规范: XML映射文件的namespace属性为Mapper接口全限定名一致 XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。 XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(非必须) <select>标签:就是用于编写select查询语句的。 resultType属性,指的是查询返回的单条记录所封装的类型(查询必须)。 parameterType属性(可选,MyBatis 会根据接口方法的入参类型(比如 Dish 或 DishPageQueryDTO)自动推断),POJO作为入参,需要使用全类名或是type‑aliases‑package: com.sky.entity 下注册的别名。 <insert id="insert" useGeneratedKeys="true" keyProperty="id"> <select id="pageQuery" resultType="com.sky.vo.DishVO"> <select id="list" resultType="com.sky.entity.Dish" parameterType="com.sky.entity.Dish"> 实现过程: resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件 配置Mapper文件 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="edu.whut.mapper.EmpMapper"> <!-- SQL 查询语句写在这里 --> </mapper> namespace 属性指定了 Mapper 接口的全限定名(即包名 + 类名)。 编写查询语句 <select id="findByName" parameterType="String" resultType="edu.whut.pojo.Emp"> SELECT id, name, gender, entrydate, update_time FROM emp WHERE name = #{name} </select> id="list":指定查询方法的名称,应该与 Mapper 接口中的方法名称一致。 resultType="edu.whut.pojo.Emp":resultType 只在 查询操作 中需要指定。指定查询结果映射的对象类型,这里是 Emp 类。 推荐的完整配置 mybatis: #mapper配置文件 mapper-locations: classpath:mapper/*.xml type-aliases-package: com.sky.entity configuration: #开启驼峰命名 map-underscore-to-camel-case: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl type-aliases-package: com.sky.entity把 com.sky.entity 包下的所有类都当作别名注册,XML 里就可以直接写 <resultType="Dish"> 而不用写全限定名。可以多添加几个包,用逗号隔开。 log-impl:org.apache.ibatis.logging.stdout.StdOutImpl只建议开发环境使用:在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果 map-underscore-to-camel-case: true 如果都是简单字段,开启之后XML 中不用写 <resultMap>: <resultMap id="dataMap" type="edu.whut.infrastructure.dao.po.PayOrder"> <id column="id" property="id"/> <result column="user_id" property="userId"/> <result column="product_id" property="productId"/> <result column="product_name" property="productName"/> </resultMap> 动态SQL SQL-if,where <if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。 <if test="条件表达式"> 要拼接的sql语句 </if> <where>只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,加了总比不加好 <select id="list" resultType="com.itheima.pojo.Emp"> select * from emp <where> <!-- if做为where标签的子元素 --> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> order by update_time desc </select> 不加判空条件时 如果 name == null,大多数数据库里 CONCAT('%', NULL, '%') 会返回 NULL,于是条件变成了 WHERE name LIKE NULL ,不会匹配任何行。 如果 name == ""(空串),CONCAT('%','', '%') 得到 "%%",name LIKE '%%' 对所有非null name 都成立,相当于“不过滤”这段条件,不影响结果,因此可以不判断空串。 加了判空 <if> 之后 <where> <if test="name != null and name != ''"> AND name LIKE CONCAT('%', #{name}, '%') </if> <!-- 其它条件类似 --> </where> 当 name 为 null 或 "" 时,这段 <if> 块不会被拼到最终的 SQL 里,等价于忽略了 name 这个过滤条件。 SQL-foreach Mapper 接口 @Mapper public interface EmpMapper { //批量删除 public void deleteByIds(@Param("ids") List<Integer> ids); } XML 映射文件 <foreach> 标签用于遍历集合,常用于动态生成 SQL 语句中的 IN 子句、批量插入、批量更新等操作。 <foreach collection="集合参数名" item="当前遍历项" index="当前索引(可选)" separator="每次遍历间的分隔符" open="遍历开始前拼接的片段" close="遍历结束后拼接的片段"> #{item} </foreach> open="(":这个属性表示,在生成的 SQL 语句开始时添加一个 左括号 (。 close=")":这个属性表示,在生成的 SQL 语句结束时添加一个 右括号 )。 例:批量删除实现 <delete id="deleteByIds"> DELETE FROM emp WHERE id IN <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete> int deleteByIds(@Param("ids") List<Long> ids); #{id} 代表集合里的一个元素。item 里定义的是什么,就要在 #{} 里用相同的名字。 这里一定要加 @Param("ids"),这样 MyBatis 才知道这个集合对应 XML 里的 collection="ids"。 实现效果类似:DELETE FROM emp WHERE id IN (1, 2, 3); Mybatis-Plus MyBatis-Plus 的使命就是——在保留 MyBatis 灵活性的同时,大幅减少模板化、重复的代码编写,让增删改查、分页等常见场景“开箱即用”,以更少的配置、更少的样板文件、更高的开发效率,帮助团队快速交付高质量的数据库访问层。 快速开始 1.引入依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.3.1</version> </dependency> <!-- <dependency>--> <!-- <groupId>org.mybatis.spring.boot</groupId>--> <!-- <artifactId>mybatis-spring-boot-starter</artifactId>--> <!-- <version>2.3.1</version>--> <!-- </dependency>--> 由于这个starter包含对mybatis的自动装配,因此完全可以替换掉Mybatis的starter。 2.定义mapper 为了简化单表CRUD,MybatisPlus提供了一个基础的BaseMapper接口,其中已经实现了单表的CRUD(增删查改): 仅需让自定义的UserMapper接口,继承BaseMapper接口: public interface UserMapper extends BaseMapper<User> { } 测试: @SpringBootTest class UserMapperTest { @Autowired private UserMapper userMapper; @Test void testInsert() { User user = new User(); user.setId(5L); user.setUsername("Lucy"); user.setPassword("123"); user.setPhone("18688990011"); user.setBalance(200); user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}"); user.setCreateTime(LocalDateTime.now()); user.setUpdateTime(LocalDateTime.now()); userMapper.insert(user); } @Test void testSelectById() { User user = userMapper.selectById(5L); System.out.println("user = " + user); } @Test void testSelectByIds() { List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L, 5L)); users.forEach(System.out::println); } @Test void testUpdateById() { User user = new User(); user.setId(5L); user.setBalance(20000); userMapper.updateById(user); } @Test void testDelete() { userMapper.deleteById(5L); } } 3.常见注解 MybatisPlus如何知道我们要查询的是哪张表?表中有哪些字段呢? 约定大于配置 泛型中的User就是与数据库对应的PO. MybatisPlus就是根据PO实体的信息来推断出表的信息,从而生成SQL的。默认情况下: MybatisPlus会把PO实体的类名驼峰转下划线作为表名 UserRecord->user_record MybatisPlus会把PO实体的所有变量名驼峰转下划线作为表的字段名,并根据变量类型推断字段类型 MybatisPlus会把名为id的字段作为主键 但很多情况下,默认的实现与实际场景不符,因此MybatisPlus提供了一些注解便于我们声明表信息。 @TableName 描述:表名注解,标识实体类对应的表 @TableId 描述:主键注解,标识实体类中的主键字段 TableId注解支持两个属性: 属性 类型 必须指定 默认值 描述 value String 否 "" 主键字段名 type Enum 否 IdType.NONE 指定主键类型 @TableName("user_detail") public class User { @TableId(value="id_dd",type=IdType.AUTO) private Long id; private String name; } 这个例子会,映射到数据库中的user_detail表,主键为id_dd,并且插入时采用数据库自增;能自动回写主键,相当于开启useGeneratedKeys=true,执行完 insert(user) 后,user.getId() 就会是数据库分配的主键值,否则默认获得null,但不影响数据表中的内容。 type=dType.ASSIGN_ID 表示用雪花算法生成密码,更加复杂,而不是简单的AUTO自增。它也能自动回写主键。 @TableField 普通字段注解 一般情况下我们并不需要给字段添加@TableField注解,一些特殊情况除外: 成员变量名与数据库字段名不一致 成员变量是以isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。 public class User { private Long id; private String name; private Boolean isActive; // 按 JavaBean 习惯,这里用 isActive,数据表是is_acitive,但MybatisPlus会识别为active } 成员变量名与数据库一致,但是与数据库的**关键字(如order)**冲突。 public class Order { private Long id; private Integer order; // 名字和 SQL 关键字冲突 } 默认MP会生成:SELECT id, order FROM order; 导致报错 一些字段不希望被映射到数据表中,不希望进行增删查改 解决办法: @TableField("is_active") private Boolean isActive; @TableField("`order`") //添加转义字符 private Integer order; @TableField(exist=false) //exist默认是true, private String address; 4.常用配置 大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如: 实体类的别名扫描包 全局id类型 要改也就改这两个即可 mybatis-plus: type-aliases-package: edu.whut.mp.domain.po global-config: db-config: id-type: auto # 全局id类型为自增长 作用:1.把edu.whut.mp.domain.po 包下的所有 PO 类注册为 MyBatis 的 Type Alias。这样在你的 Mapper XML 里就可以直接写 <resultType="User">(或 <parameterType="User">)而不用写全限定类名 edu.whut.mp.domain.po.User 2.无需在每个 @TableId 上都写 type = IdType.AUTO,统一由全局配置管。 核心功能 前面的例子都是根据主键id更新、修改、查询,无法支持复杂条件where。 条件构造器Wrapper 除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持更加复杂的where条件。 Wrapper就是条件构造的抽象类,其下有很多默认实现,继承关系如图: QueryWrapper 在AbstractWrapper的基础上拓展了一个select方法,允许指定查询字段,无论是修改、删除、查询,都可以使用QueryWrapper来构建查询条件。 select方法只需用于 查询 时指定所需的列,完整查询不需要,用于update和delete不需要。 QueryWrapper 里对 like、eq、ge 等方法都做了重载 QueryWrapper<User> qw = new QueryWrapper<>(); qw.like("name", name); //两参版本,第一个参数对应数据库中的列名,如果对应不上,就会报错!!! qw.like(StrUtil.isNotBlank(name), "name", name); //三参,多一个boolean condition 参数 **例1:**查询出名字中带o的,存款大于等于1000元的人的id,username,info,balance: /** * SELECT id,username,info,balance * FROM user * WHERE username LIKE ? AND balance >=? */ @Test void testQueryWrapper(){ QueryWrapper<User> wrapper =new QueryWrapper<User>() .select("id","username","info","balance") .like("username","o") .ge("balance",1000); //查询 List<User> users=userMapper.selectList(wrapper); users.forEach(System.out::println); } UpdateWrapper 基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。 例1: 例如:更新id为1,2,4的用户的余额,扣200,对应的SQL应该是: UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4) @Test void testUpdateWrapper() { List<Long> ids = List.of(1L, 2L, 4L); // 1.生成SQL UpdateWrapper<User> wrapper = new UpdateWrapper<User>() .setSql("balance = balance - 200") // SET balance = balance - 200 .in("id", ids); // WHERE id in (1, 2, 4) // 2.更新,注意第一个参数可以给null,告诉 MP:不要从实体里取任何字段值 // 而是基于UpdateWrapper中的setSQL来更新 userMapper.update(null, wrapper); } 例2: // 用 UpdateWrapper 拼 WHERE + SET UpdateWrapper<User> wrapper = new UpdateWrapper<User>() // WHERE status = 'ACTIVE' .eq("status", "ACTIVE") // SET balance = 2000, name = 'Alice' .set("balance", 2000) .set("name", "Alice"); // 把 entity 参数传 null,MyBatis-Plus 会只用 wrapper 里的 set/where userMapper.update(null, wrapper); LambdaQueryWrapper(推荐) 是QueryWrapper和UpdateWrapper的上位选择!!! 传统的 QueryWrapper/UpdateWrapper 需要把数据库字段名写成字符串常量,既容易拼写出错,也无法在编译期校验。MyBatis-Plus 引入了两种基于 Lambda 的 Wrapper —— LambdaQueryWrapper 和 LambdaUpdateWrapper —— 通过传入实体类的 getter 方法引用,框架会自动解析并映射到对应的列,实现了类型安全和更高的可维护性。 // ——— 传统 QueryWrapper ——— public User findByUsername(String username) { QueryWrapper<User> qw = new QueryWrapper<>(); // 硬编码列名,拼写错了编译不过不了,会在运行时抛数据库异常 qw.eq("user_name", username); return userMapper.selectOne(qw); } // ——— LambdaQueryWrapper ——— public User findByUsername(String username) { // 内部已注入实体 Class 和元数据,方法引用自动解析列名 LambdaQueryWrapper<User> qw = Wrappers.lambdaQuery(User.class) .eq(User::getUserName, username); return userMapper.selectOne(qw); } 自定义sql 即自己编写Wrapper查询条件,再结合Mapper.xml编写SQL **例1:**以 UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4) 为例: 1)先在业务层利用wrapper创建条件,传递参数 @Test void testCustomWrapper() { // 1.准备自定义查询条件 List<Long> ids = List.of(1L, 2L, 4L); QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids); // 2.调用mapper的自定义方法,直接传递Wrapper userMapper.deductBalanceByIds(200, wrapper); } 2)自定义mapper层把wrapper和其他业务参数传进去,自定义sql语句书写sql的前半部分,后面拼接。 public interface UserMapper extends BaseMapper<User> { /** * 注意:更新要用 @Update * - #{money} 会被替换为方法第一个参数 200 * - ${ew.customSqlSegment} 会展开 wrapper 里的 WHERE 子句 */ @Update("UPDATE user " + "SET balance = balance - #{money} " + "${ew.customSqlSegment}") void deductBalanceByIds(@Param("money") int money, @Param("ew") QueryWrapper<User> wrapper); } @Param("ew")就是给这个方法参数在 MyBatis 的 SQL 映射里起一个别名—— ew , Mapper 的注解或 XML 里,MyBatis 想要拿到这个参数,就用它的 @Param 名称——也就是 ew: @Param("ew")中ew是 MP 约定的别名! ${ew.customSqlSegment} 可以自动拼接传入的条件语句 **例2:**查询出所有收货地址在北京的并且用户id在1、2、4之中的用户 普通mybatis: <select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User"> SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id WHERE u.id <foreach collection="ids" separator="," item="id" open="IN (" close=")"> #{id} </foreach> AND a.city = #{city} </select> mp方法: @Test void testCustomJoinWrapper() { // 1.准备自定义查询条件 QueryWrapper<User> wrapper = new QueryWrapper<User>() .in("u.id", List.of(1L, 2L, 4L)) .eq("a.city", "北京"); // 2.调用mapper的自定义方法 List<User> users = userMapper.queryUserByWrapper(wrapper); } @Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}") List<User> queryUserByWrapper(@Param("ew")QueryWrapper<User> wrapper); Service层的常用方法 查询: selectById:根据主键 ID 查询单条记录。 selectBatchIds:根据主键 ID集合 批量查询记录。 selectOne:根据指定条件查询单条记录。 @Service public class UserService { @Autowired private UserMapper userMapper; public User findByUsername(String username) { // 查询 ID 为 1, 2, 3 的用户 List<Long> ids = Arrays.asList(1L, 2L, 3L); List<User> users = userMapper.selectBatchIds(ids); --------------分割线------------- QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("username", username); return userMapper.selectOne(queryWrapper); } } selectList:根据指定条件查询多条记录。 QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.ge("age", 18); List<User> users = userMapper.selectList(queryWrapper); 插入: insert:插入一条记录。 User user = new User(); user.setUsername("alice"); user.setAge(20); int rows = userMapper.insert(user); 更新 updateById:根据主键 ID 更新记录。 User user = new User(); user.setId(1L); user.setAge(25); int rows = userMapper.updateById(user); update:根据指定条件更新记录。 UpdateWrapper<User> updateWrapper = new UpdateWrapper<>(); updateWrapper.eq("username", "alice"); User user = new User(); user.setAge(30); int rows = userMapper.update(user, updateWrapper); 删除操作 类似query deleteById:根据主键 ID 删除记录。 deleteBatchIds:根据主键 ID集合 批量删除记录。 delete:根据指定条件删除记录。 QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("username", "alice"); int rows = userMapper.delete(queryWrapper); IService 基本使用 由于Service中经常需要定义与业务有关的自定义方法,因此我们不能直接使用IService,而是自定义Service接口,然后继承IService以拓展方法。同时,让自定义的Service实现类继承ServiceImpl,这样就不用自己实现IService中的接口了。 首先,定义IUserService,继承IService: public interface IUserService extends IService<User> { // 拓展自定义方法 } 然后,编写UserServiceImpl类,继承ServiceImpl(通用实现类),实现UserService: @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { } Controller层中写: @RestController @RequestMapping("/users") @Slf4j @Api(tags = "用户管理接口") public class UserController { @Autowired private IUserService userService; @PostMapping @ApiOperation("新增用户接口") public void saveUser(@RequestBody UserFormDTO userFormDTO){ User user=new User(); BeanUtils.copyProperties(userFormDTO, user); userService.save(user); } @DeleteMapping("{id}") @ApiOperation("删除用户接口") public void deleteUserById(@PathVariable Long id){ userService.removeById(id); } @GetMapping("{id}") @ApiOperation("根据id查询接口") public UserVO queryUserById(@PathVariable Long id){ User user=userService.getById(id); UserVO userVO=new UserVO(); BeanUtils.copyProperties(user,userVO); return userVO; } @PutMapping("/{id}/deduction/{money}") @ApiOperation("根据id扣减余额") public void updateBalance(@PathVariable Long id,@PathVariable Long money){ userService.deductBalance(id,money); } } service层: @Service public class IUserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { @Autowired private UserMapper userMapper; @Override public void deductBalance(Long id, Long money) { //1.查询用户 User user=getById(id); if(user==null || user.getStatus()==2){ throw new RuntimeException("用户状态异常!"); } //2.查验余额 if(user.getBalance()<money){ throw new RuntimeException("用户余额不足!"); } //3.扣除余额 update User set balance=balance-money where id=id userMapper.deductBalance(id,money); } } mapper层: @Mapper public interface UserMapper extends BaseMapper<User> { @Update("update user set balance=balance-#{money} where id=#{id}") void deductBalance(Long id, Long money); } 总结:如果是简单查询,如用id来查询、删除,可以直接在Controller层用Iservice方法,否则自定义业务层Service实现具体任务。 Service层的lambdaQuery IService中还提供了Lambda功能来简化我们的复杂查询及更新功能。 相当于「条件构造」和「执行方法」写在一起 this.lambdaQuery() = LambdaQueryWrapper + 内置的执行方法(如 .list()、.one()) // 返回 LambdaQueryChainWrapper,可以直接执行查询 List<User> users = userService.lambdaQuery() .eq(User::getUsername, "john") .eq(User::getStatus, 1) .list(); // 直接获取结果 或者先构建条件,后面再动态查询: // 只构建条件,不执行查询 LambdaQueryWrapper<User> wrapper = userService.lambdaQuery() .eq(User::getUsername, "john") .eq(User::getStatus, 1); // 后续可能添加更多条件 if (someCondition) { wrapper.like(User::getEmail, "example"); } // 在需要的时候才执行查询 List<User> users = userService.list(wrapper); 而Mapper 层的 lambdaQuery,只构造条件,不负责执行。法一: // 创建 LambdaQueryWrapper 对象 LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>() .eq(User::getUsername, "john") .eq(User::getStatus, 1); // 执行查询 List<User> users = userMapper.selectList(wrapper); 法二:Wrappers.lambdaQuery() // 方式1:使用 Wrappers.lambdaQuery() LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery(User.class) .eq(User::getUsername, "john") .eq(User::getStatus, 1); 特性 lambdaQuery() lambdaUpdate() 主要用途 构造查询条件,执行 SELECT 操作 构造更新条件,执行 UPDATE(或逻辑删除)操作 支持的方法 .eq(), .like(), .gt(), .orderBy(), .select() 等 .eq(), .lt(), .set(), .setSql() 等 执行方法 .list(), .one(), .page() 等 .update(), .remove()(逻辑删除 **案例一:**实现一个根据复杂条件查询用户的接口,查询条件如下: name:用户名关键字,可以为空 status:用户状态,可以为空 minBalance:最小余额,可以为空 maxBalance:最大余额,可以为空 @GetMapping("/list") @ApiOperation("根据id集合查询用户") public List<UserVO> queryUsers(UserQuery query){ // 1.组织条件 String username = query.getName(); Integer status = query.getStatus(); Integer minBalance = query.getMinBalance(); Integer maxBalance = query.getMaxBalance(); // 2.查询用户 List<User> users = userService.lambdaQuery() .like(username != null, User::getUsername, username) .eq(status != null, User::getStatus, status) .ge(minBalance != null, User::getBalance, minBalance) .le(maxBalance != null, User::getBalance, maxBalance) .list(); // 3.处理vo return BeanUtil.copyToList(users, UserVO.class); } .eq(status != null, User::getStatus, status),使用User::getStatus方法引用并不直接把'Status'插入到 SQL,而是在运行时会被 MyBatis-Plus 解析成实体属性 Status”对应的数据库列是 status。推荐!!! 可以发现lambdaQuery方法中除了可以构建条件,还需要在链式编程的最后添加一个list(),这是在告诉MP我们的调用结果需要是一个list集合。这里不仅可以用list(),可选的方法有: .one():最多1个结果 .list():返回集合结果 .count():返回计数结果 MybatisPlus会根据链式编程的最后一个方法来判断最终的返回结果。 这里不够规范,业务写在controller层中了。 **案例二:**改造根据id修改用户余额的接口,如果扣减后余额为0,则将用户status修改为冻结状态(2) @Override @Transactional public void deductBalance(Long id, Integer money) { // 1.查询用户 User user = getById(id); // 2.校验用户状态 if (user == null || user.getStatus() == 2) { throw new RuntimeException("用户状态异常!"); } // 3.校验余额是否充足 if (user.getBalance() < money) { throw new RuntimeException("用户余额不足!"); } // 4.扣减余额 update tb_user set balance = balance - ? int remainBalance = user.getBalance() - money; lambdaUpdate() //在service层中!!!相当于this.lambdaUpdate() .set(User::getBalance, remainBalance) // 更新余额 .set(remainBalance == 0, User::getStatus, 2) // 动态判断,是否更新status .eq(User::getId, id) .eq(User::getBalance, user.getBalance()) // 乐观锁 .update(); } 批量新增 每 batchSize 条记录作为一个 JDBC batch 提交一次(1000 条就一次) @Test void testSaveBatch() { // 准备10万条数据 List<User> list = new ArrayList<>(1000); long b = System.currentTimeMillis(); for (int i = 1; i <= 100000; i++) { list.add(buildUser(i)); // 每1000条批量插入一次 if (i % 1000 == 0) { userService.saveBatch(list); list.clear(); } } long e = System.currentTimeMillis(); System.out.println("耗时:" + (e - b)); } 之所以把 100 000 条记录分成每 1 000 条一批来插,是为了兼顾 性能、内存 和 数据库/JDBC 限制。 JDBC 或数据库参数限制 很多数据库(MySQL、Oracle 等)对单条 SQL 里 VALUES 列表的长度有上限,一次性插入几十万行可能导致 SQL 过长、参数个数过多,被驱动或数据库拒绝。 即使驱动不直接报错,也可能因为网络包(packet)过大而失败。 内存占用和 GC 压力 JDBC 在执行 batch 时,会把所有要执行的 SQL 和参数暂存在客户端内存里。如果一次性缓存 100 000 条记录的参数(可能是几 MB 甚至十几 MB),容易触发 OOM 或者频繁 GC。 事务日志和回滚压力 一次性插入大量数据,数据库需要在事务日志里记录相应条目,回滚时也要一次性回滚所有操作,性能开销巨大。分批能让每次写入都较为“轻量”,回滚范围也更小。 但是这样拆分插入,本质上还是逐条插入,效率很低 <!-- 低效:逐条插入 --> <insert id="insertBatch"> <foreach collection="list" item="item"> INSERT INTO user (username, email, age) VALUES (#{item.username}, #{item.email}, #{item.age}); </foreach> </insert> 实际执行的SQL: INSERT INTO user (username, email, age) VALUES ('user1', 'user1@test.com', 20); INSERT INTO user (username, email, age) VALUES ('user2', 'user2@test.com', 21); INSERT INTO user (username, email, age) VALUES ('user3', 'user3@test.com', 22); -- ... 总共1000条独立的INSERT语句 而如果想要得到最佳性能,最好是将VALUES 多行: <!-- 高效:VALUES多行插入 --> <insert id="insertBatch"> INSERT INTO user (username, email, age) VALUES <foreach collection="list" item="item" separator=","> (#{item.username}, #{item.email}, #{item.age}) </foreach> </insert> INSERT INTO user (username, email, age) VALUES ('user1', 'user1@test.com', 20), ('user2', 'user2@test.com', 21), ('user3', 'user3@test.com', 22), 需要修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true: url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true 或者直接自定义批量SQL,不用mabatis-plus框架。 MQ分页 快速入门 1)引入依赖 <!-- 数据库操作:https://mp.baomidou.com/ --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.9</version> </dependency> <!-- MyBatis Plus 分页插件 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-jsqlparser-4.9</artifactId> </dependency> 2)定义通用分页查询条件实体 @Data @ApiModel(description = "分页查询实体") public class PageQuery { @ApiModelProperty("页码") private Long pageNo; @ApiModelProperty("页码") private Long pageSize; @ApiModelProperty("排序字段") private String sortBy; @ApiModelProperty("是否升序") private Boolean isAsc; } 3)新建一个 UserQuery 类,让它继承自你已有的 PageQuery @Data @ApiModel(description = "用户分页查询实体") public class UserQuery extends PageQuery { @ApiModelProperty("用户名(模糊查询)") private String name; } 4)Service里使用 @Service public class UserService extends ServiceImpl<UserMapper, User> { /** * 用户分页查询(带用户名模糊 + 动态排序) * * @param query 包含 pageNo、pageSize、sortBy、isAsc、name 等字段 */ public Page<User> pageByQuery(UserQuery query) { // 1. 构造 Page 对象 Page<User> page = new Page<>( query.getPageNo(), query.getPageSize() ); // 2. 构造查询条件 LambdaQueryWrapper<User> qw = Wrappers.<User>lambdaQuery() // 当 name 非空时,加上 user_name LIKE '%name%' .like(StrUtil.isNotBlank(query.getName()), User::getUserName, query.getName()); // 3. 动态排序 if (StrUtil.isNotBlank(query.getSortBy())) { String column = StrUtil.toUnderlineCase(query.getSortBy()); boolean asc = Boolean.TRUE.equals(query.getIsAsc()); qw.last("ORDER BY " + column + (asc ? " ASC" : " DESC")); } // 4. 执行分页查询 return this.page(page, qw); } }
后端学习
zy123
1年前
0
14
0
2025-07-05
matlab
matlab笔记 命令行窗口 clc:清屏(命令行窗口) clear all:把命名的变量删掉,不是命令行窗口 命名规则: 变量命名以字母开头,不可以下划线,变量是区分字母大小写的 脚本 %% xxx 注释(百分号+一个空格) % xxx 也是注释 s='a' '"aaaa",字符串 abs(s) 字符s的ascii码,为97 char(97), 输出'a' numtostr(65) ans='65',数字转字符串 length(str),字符串的长度 矩阵 A=[1 2 3 ;4 5 6 ;7 8 9] 分号换行 B=A‘ ,矩阵转置 C=A(:) ,将矩阵拉成一列,按列存储,第一列拼接第二列拼接第三列 D=inv(A) 求逆矩阵 E=zeros(10,5,3) 生成10行5列3维0矩阵 元胞数组 A=cell(1,6),生成1行6列的小格子,每个小格子可以存放各种数据 eye(3),生成3x3的单位阵 A{2}=eye(3),matlab数组从1开始,不是0
科研
zy123
1年前
0
10
0
2025-06-27
DDD领域驱动设计
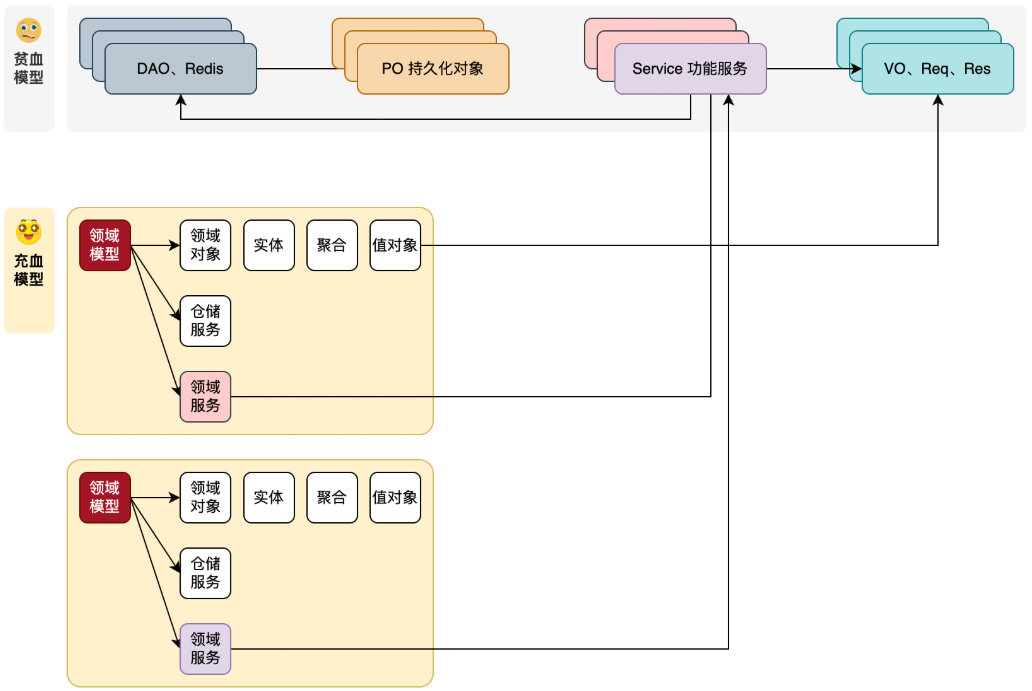
DDD领域驱动设计 什么是 DDD? DDD(领域驱动设计,Domain-Driven Design)是一种软件设计方法论,它为软件工程设计提供了一套完整的指导思想与实践手段。通过领域、界限上下文、实体、值对象、聚合、工厂、仓储等概念,DDD 帮助我们合理划分工程模型,从而在前期投入更多思考,规划出可持续迭代和演进的系统架构。 在工程实践中,DDD 通常分为两个层面的设计: 1. 战略设计 战略设计关注复杂业务的宏观拆分。通过限界上下文和子域划分,将系统分治为独立模块或服务。拆分是否合理取决于上线效率:若每次改动牵涉多个服务,即是失败的“微服务单体”。更实用的方式是:以少数中等规模的核心应用为主体,构建周边服务生态,既保持灵活性,又避免过度拆分。 2. 战术设计 战术设计关注如何在代码层面表达业务概念。它强调通过面向对象建模,将业务逻辑封装进领域模型,并以实体、值对象、聚合和领域服务来承载业务行为,确保代码贴合业务语义。 传统的 MVC 三层架构往往只是 Service 层加数据模型的简单组合,容易导致 Service 类臃肿、逻辑复杂,甚至出现“贫血模型”问题——数据与行为分离,增加了维护难度。DDD 的战术设计通过丰富的领域模型来规避这一问题,使系统结构更清晰、业务逻辑更可维护。 为什么要用DDD? 先说说传统Spring MVC: Spring MVC 传统上多采用 分层架构(Controller-Service-DAO)。 对于 简单业务 或 原型开发,这种方式足够清晰,开发成本低,上手快。 说说Spring MVC的不足: 在 复杂业务场景(核心逻辑复杂、规则频繁变化的系统)中,传统分层模式会暴露出明显问题: 1)业务逻辑分散: 大量 if-else、规则判断和外部调用混杂在 Service 中。 代码难以维护,稍有业务变更,就需要在已有方法里继续堆条件分支。 @Service public class OrderService { @Autowired private OrderRepository orderRepository; @Autowired private PaymentGateway paymentGateway; public void payOrder(Long orderId, String payMethod) { Order order = orderRepository.findById(orderId); // 校验订单 if (order == null) { throw new IllegalArgumentException("订单不存在"); } if (!order.getStatus().equals("UNPAID")) { throw new IllegalStateException("订单状态不允许支付"); } // 校验金额 if (order.getAmount().compareTo(BigDecimal.ZERO) <= 0) { throw new IllegalStateException("订单金额异常"); } // 支付逻辑 boolean success = paymentGateway.pay(order.getId(), order.getAmount(), payMethod); if (!success) { throw new RuntimeException("支付失败"); } // 修改状态 order.setStatus("PAID"); orderRepository.save(order); } } 一个 Service 同时承担校验、业务逻辑、状态修改、持久化和外部调用,演变成“上帝类”。 2)贫血模型:Entity/POJO 只存数据,业务逻辑全堆在 Service,对象与业务语义严重脱节,比如Order 类里找不到 pay(),只能在 OrderService 找到 payOrder()。 3)随着需求增长,Service 越来越庞大,修改风险高、测试困难。 引出DDD的价值 1)业务逻辑回归领域模型(充血模型) 通过 实体、值对象、聚合、领域服务 等概念,把业务规则放回领域模型中,实现高内聚: public class Order { private Long id; private BigDecimal amount; private String status; // 领域方法:支付 public void pay(PaymentGateway paymentGateway, String payMethod) { validateBeforePay(); boolean success = paymentGateway.pay(this.id, this.amount, payMethod); if (!success) { throw new RuntimeException("支付失败"); } this.status = "PAID"; } private void validateBeforePay() { if (!"UNPAID".equals(this.status)) { throw new IllegalStateException("订单状态不允许支付"); } if (amount.compareTo(BigDecimal.ZERO) <= 0) { throw new IllegalStateException("订单金额异常"); } } } @Service public class OrderAppService { @Autowired private OrderRepository orderRepository; @Autowired private PaymentGateway paymentGateway; public void payOrder(Long orderId, String payMethod) { Order order = orderRepository.findById(orderId); order.pay(paymentGateway, payMethod); // 业务逻辑放在 Order 里 orderRepository.save(order); } } 扩展更容易:如果要加优惠券逻辑,只需要在 Order 里扩展,而不是在 Service 里继续堆 if-else。 2)统一语言(Ubiquitous Language) DDD 强调与业务专家使用一致的术语建模,保证沟通顺畅: 传统写法: Controller: OrderController.create() Service: OrderService.saveOrder() DAO: OrderRepository.insert() 业务专家说:“下单” 。开发说:“调用 create() 接口,service.saveOrder(),repository.insert()。” DDD 写法: 团队必须先和业务专家一起挖掘、定义业务概念。 然后这些词汇会 直接落到模型、聚合、实体、方法名 上。 Customer.placeOrder() (客户下单) Order.markAsPendingPayment() (订单标记为待支付) OrderRepository.save(order) (仓储保存订单) 业务专家说:“下单 → 待支付” 。开发说:“placeOrder() → markAsPendingPayment()。” 3)技术解耦与可演进性 1)领域层不依赖技术实现,领域模型只关心业务,不关心底层是 MySQL、Redis、ES 还是文件。 所有外部依赖都通过 接口 定义,比如 OrderRepository。具体的存储实现交给 适配器,在基础设施层完成。 2)遵循依赖倒置原则,领域层依赖抽象接口,而不是依赖具体实现,当技术实现需要调整(如 MySQL → Redis),只需要改适配器。领域模型的变更只来自业务规则的变化,而不是技术变更。 **面试官可能追问:**你只是把service层中的逻辑移动到了实体类中,将臃肿的代码逻辑转移到了别处? 回答: 表面上看,DDD 确实是把 Service 里的逻辑挪到了实体,但本质不是搬家,而是职责重构。 在贫血模型里,实体只是数据容器,业务规则分散在不同 Service 里,导致代码臃肿、逻辑重复。 在充血模型里,规则和实体强绑定,代码语义更贴近业务: 规则归属清晰:订单的支付校验、发货校验都收拢在 Order 聚合里,不会分散在多个 Service。 统一语言:order.pay() 就等于业务里的“订单支付”,减少沟通成本。 复杂度可控:领域服务负责编排,聚合/实体承载业务逻辑,基础设施负责实现,避免出现‘上帝 Service’。 更易维护扩展:新增优惠券逻辑只需在 Order 内扩展,而不是在庞大的 Service 里继续加 if-else。 所以 DDD 的意义在于让领域模型成为业务的表达中心,而不仅仅是逻辑搬家。 如何理解聚合根? 我把聚合理解为一组强相关的实体和值对象,它们必须作为一个整体来保证业务一致性。聚合根是这组对象对外唯一的入口。所有修改必须通过聚合根来进行,它负责维护不变式,并定义事务边界;仓储也以聚合根为单位。跨聚合我们通过 ID 引用与领域事件实现最终一致,避免大事务。例如在订单域,Order 是聚合根,OrderLine、Address 在聚合内;总价计算、状态流转等不变式在一次事务里由 Order 保证;库存属于另一个聚合,通过“订单已提交”事件去扣减库存。这样既保证一致性,又降低耦合、便于扩展。 DDD概念理论 充血模型 vs 贫血模型 定义 贫血模型:对象仅包含数据属性和简单的 getter/setter,业务逻辑由外部服务处理。 充血模型:对象既包含数据,也封装相关业务逻辑,符合面向对象设计原则。 特点 贫血模型 充血模型 封装性 数据和逻辑分离 数据和逻辑封装在同一对象内 职责分离 服务类负责业务逻辑,对象负责数据 对象同时负责数据和自身的业务逻辑 适用场景 简单的增删改查、DTO 传输对象 复杂的领域逻辑和业务建模 优点 简单易用,职责清晰 高内聚,符合面向对象设计思想 缺点 服务层臃肿,领域模型弱化 复杂度增加,不适合简单场景 面向对象原则 违反封装原则 符合封装原则 贫血模型: // 1. “贫血”的订单实体 (Entity) // 它只是一个数据袋子,没有行为,只有getter/setter public class Order { private Long id; private String status; private BigDecimal amount; // ... 一堆getter和setter方法 } // 2. “贫血”的商品实体 (Entity) public class Product { private Long id; private String name; private Integer stock; // 库存 // ... 一堆getter和setter方法 } // 3. 庞大的“服务层” (Service) 包含所有业务逻辑 @Service public class OrderService { @Autowired private ProductRepository productRepository; public void decreaseStock(Long productId, Integer quantity) { // 步骤1: 查询商品 Product product = productRepository.findById(productId); // 步骤2: 检查库存(业务规则) if (product.getStock() < quantity) { throw new RuntimeException("库存不足"); } // 步骤3: 计算并设置新库存(业务逻辑) Integer newStock = product.getStock() - quantity; product.setStock(newStock); // 对象的状态由外部服务来修改 // 步骤4: 保存回数据库 productRepository.save(product); } } 问题:所有业务逻辑(检查库存、计算新库存)都放在了 OrderService这个外部服务里。Product对象本身只是个“傻傻的”数据载体,它对自己的业务规则(如“库存不能为负”)一无所知,谁都可以随意setStock,非常容易出错。这就是 “贫血模型”。 充血模型: // 1. “充血”的商品实体 (Entity/Aggregate Root) // 它不仅有数据,更有行为(方法),它对自己的业务规则负责 public class Product { private Long id; private String name; private Integer stock; // 库存 // 核心业务行为:减少库存 // 这个方法是直接写在这个实体对象内部的! public void decreaseStock(Integer quantity) { // 守护业务规则:库存不能减少为负数 if (this.stock < quantity) { throw new DomainException("商品库存不足,无法减少"); } // 业务逻辑:修改自身状态 this.stock -= quantity; } // 其他行为,如增加库存... public void increaseStock(Integer quantity) { this.stock += quantity; } } // 2. 变得很“薄”的服务层 (Service/Application Service) // 它的职责不再是处理业务逻辑,而是协调事务、调用仓库、发布事件等 @Service public class OrderApplicationService { @Autowired private ProductRepository productRepository; public void decreaseStock(Long productId, Integer quantity) { // 步骤1: 获取领域对象(聚合根) Product product = productRepository.findById(productId); // 步骤2: 调用领域对象自身的业务方法! product.decreaseStock(quantity); // 逻辑在Product内部 // 步骤3: 保存这个发生了变化的对象 productRepository.save(product); } } 这样的方式可以在使用一个对象时,就顺便拿到这个对象的提供的一系列业务方法,所有使用对象的逻辑方法,都不需要自己再次处理同类逻辑。 但不要只是把充血模型,仅限于一个类的设计和一个类内的方法设计。充血还可以是整个包结构**(领域模型)**,一个包下包括了用于实现此包 Service 服务所需的各类零部件(模型、仓储、工厂),也可以被看做充血模型。 同时我们还会再一个同类的类下,提供对应的内部类,如用户实名,包括了通信类、实名卡、银行卡、四要素等。它们都被写进到一个用户类下的内部子类,这样在代码编写中也会清晰的看到子类的所属信息,更容易理解代码逻辑,也便于维护迭代。 我的实体类本身还是偏贫血模型,主要负责承载数据和基本的不变式校验。**但在领域层里,我会把仓储、领域服务和实体组合在一起,所有业务逻辑都在领域模型中闭环实现,不会散落到外层,这样整体上就是充血思想。**实体保证自身一致性,复杂逻辑交给领域服务来实现。 限界上下文 限界上下文是指一个明确的边界,规定了某个子领域的业务模型和语言,确保在该上下文内的术语、规则、模型不与其他上下文混淆。是一个 业务设计概念。 表达 语义环境 实际含义 "我吃得很饱,现在不能动了" 日常用餐 字面意思:吃到肚子很满 "我吃得很饱,今天的演讲让人充实" 知识分享 比喻:得到了很大满足 限界上下文的作用 定义业务边界:类似于语义环境,为通用语言划定范围 消除歧义:确保团队对领域对象、事件的认知一致 领域转换:同一对象在不同上下文有不同名称(goods在电商称"商品",运输称"货物") 模型隔离:防止不同业务领域的模型相互干扰 在代码工程里,每个上下文拥有独立包结构 领域模型 指特定业务领域内,业务规则、策略以及业务流程的抽象和封装。在设计手段上,通过风暴模型拆分领域模块,形成界限上下文。最大的区别在于把原有的众多 Service + 数据模型的方式,拆分为独立的有边界的领域模块。每个领域内创建自身所属的;领域对象(实体、聚合、值对象)、仓储服务(DAO 操作)、工厂、端口适配器Port(调用外部接口的手段)等。 在原本的 Service + 贫血的数据模型开发指导下,Service 串联调用每一个功能模块。这些基础设施(对象、方法、接口)是被相互调用的。这也是因为贫血模型并没有面向对象的设计,所有的需求开发只有详细设计。 换到充血模型下,现在我们以一个领域功能为聚合,拆分一个领域内所需的 Service 为领域服务,VO、Req、Res 重新设计为领域对象,DAO、Redis 等持久化操作为仓储等。举例:一套账户服务中的,授信认证、开户、提额降额等,每一个都是一个独立的领域,在每个独立的领域内,创建自身领域所需的各项信息。 领域模型还有一个特点,它自身只关注业务功能实现,不与外部任何接口和服务直连。如:不会直接调用 DAO 操作库,也不会调用缓存操作 Redis,更不会直接引入 RPC 连接其他微服务。而是通过仓库Repository和端口适配器port,定义调用外部数据的含有出入参对象的接口标准,让基础设施层做具体的调用实现——通过这样的方式让领域只关心业务实现,同时做好防腐。(依赖倒置) 领域服务 一组无状态的业务操作,封装那些“不属于任何单个实体/聚合”的领域逻辑。 职责 执行跨聚合、跨实体的业务场景—— 处理一个订单支付时,可能需要处理与 订单、账户、支付信息 等多个实体的交互。 在这种情况下,领域服务负责协调这些实体之间的交互。 协调仓储接口、调用多个聚合根的方法,但本身不持有长期状态。 领域服务自己不持有数据状态,它的职责是调度和协调。它通过调用聚合根(或实体)的方法来完成业务操作。它也不会涉及持久化(数据存储),这些通常是通过仓储层来管理的。 典型示例 订单支付功能: 涉及订单、用户账户、支付信息等多个实体,适合放在领域服务中实现 订单(Order):包含订单的详细信息。 账户(Account):用户的账户信息,包括余额。 支付信息(PaymentDetails):支付的具体信息,例如支付方式、金额等。 @Service public class PaymentService { @Transactional public void processPayment(Order order, PaymentDetails paymentDetails, Account account) { // 调用领域对象的行为 account.pay(paymentDetails.getAmount()); //负责余额检查与扣款 order.markAsPaid(); //负责支付状态变更 paymentDetails.recordPayment(order); // 保存这些聚合(Repository 层操作) orderRepository.save(order); accountRepository.save(account); paymentRepository.save(paymentDetails); } } 领域对象 实体 实体是基于持久化层数据和领域服务功能目标设计的领域对象。与持久化的 PO(持久化对象)不同,PO 只是原子类对象,缺乏业务语义,而实体对象不仅具备业务语义,还具有唯一标识。实体对象与领域服务方法紧密结合,跟随其生命周期进行操作。 例如,用户的 PO 对象可能包括用户开户信息、授信信息和额度信息等多个方面,而订单则可能涉及多个实体,例如商品下单时的购物车实体。实体通常作为领域服务方法的入参对象。 在代码中,实体通常表现为具有唯一标识的业务对象,标识属性(如 ID)是其核心特征。例如: 订单实体:通过订单 ID 唯一标识 用户实体:通过用户 ID 唯一标识 核心特征: 实体的属性随着时间变化而变化。 唯一标识(ID)保持不变,确保实体的唯一性。 实体对象通常在代码中以实体类的形式存在,并且通常采用 充血模型 实现,即将与该实体相关的业务逻辑和行为写入实体类中,而不仅仅是存储数据。 **作用:**实体类的作用是用来建模领域中的“唯一业务对象”,它通过 ID 保证唯一性,随着生命周期发生状态变化,并将与自身相关的业务逻辑和行为封装在内部,是领域建模的核心元素。 值对象 值对象是没有唯一标识的业务对象,具有以下特征: 创建后不可修改(immutable) 只能通过整体替换来更新 通常用于描述实体的属性和特征 在开发值对象的时候,通常不会提供 setter 方法,而是提供构造函数或者 Builder 方法来实例化对象。这个对象通常不会独立作为方法的入参对象,但做可以独立作为出参对象使用。 作用: 表达领域概念:用值对象建模能让代码更贴近业务,比如用枚举类XXStatus代替1、2、3。 保证一致性与正确性:值对象可以在内部封装校验逻辑,比如金额不能为负数。 可复用:多个实体都可以组合使用相同的值对象。 用于:枚举类、VO返回对象 聚合与聚合根 ”高内聚、低耦合“,代码中直观的感受就是仓储层中,传入的如果是聚合根,意味着要对不同的表进行处理,因此对应方法上一般要加@Transactional-------拼团中的锁单、退单都是如此!!! 锁单:同时操作拼团表和拼团明细表;退单:拼团表+拼团明细表+消息通知表。 在领域驱动设计(DDD)中,聚合是一组紧密关联的 **实体 **和 值对象的组合,这些对象在业务上共同协作,形成一个统一的一致性与事务边界。 聚合根 是聚合的唯一入口,负责对外提供操作接口,并维护聚合内部的一致性和业务规则。 1. 聚合(逻辑边界) 聚合内的所有变更必须在同一事务中完成,要么全部成功,要么全部失败,确保内部业务不变式始终成立。例:订单的总金额必须等于所有订单项金额之和。 一次事务只允许跨越一个聚合,避免分布式事务的复杂性。 外部代码不得直接修改聚合内除聚合根之外的对象,所有操作都必须通过聚合根进行。例:外部不能直接改 OrderItem 数量,而是调用 Order.changeItemQuantity()。 示例: 一个订单聚合可能包含: 订单实体(聚合根):Order,全局唯一 ID,提供操作方法;包含订单总金额 totalAmount。 订单明细实体:OrderItem,描述商品项(数量、单价)。 收货地址值对象:ShippingAddress,不可变,存储地址信息。 2. 聚合根(物理入口) 唯一入口:对外唯一的访问点Order,聚合内的所有修改必须经由聚合根发起。 全局标识:聚合根是一个拥有全局唯一 ID 的实体。 规则守护者:负责封装聚合内部的业务逻辑、数据校验及不变式维护。 跨聚合交互:与其他聚合交互时,只传递 ID 或使用领域服务,不直接持有对方实体的引用,避免跨边界耦合。 3.代码示例(订单聚合) // 聚合根:订单 public class Order { private final String orderId; private List<OrderItem> items; private ShippingAddress address; private double totalAmount; // 总金额作为不变式 public Order(String orderId, ShippingAddress shippingAddress) { this.orderId = orderId; this.address = shippingAddress; this.items = new ArrayList<>(); this.totalAmount = 0.0; } // 添加商品 public void addItem(String productId, int quantity, double price) { OrderItem item = new OrderItem(productId, quantity, price); items.add(item); recalculateTotalAmount(); } // 修改订单项数量(外部必须通过聚合根调用) public void changeItemQuantity(String productId, int newQuantity) { for (OrderItem item : items) { if (item.getProductId().equals(productId)) { item.changeQuantity(newQuantity); // 修改子实体 recalculateTotalAmount(); // 重新计算总金额 return; } } throw new IllegalArgumentException("未找到商品:" + productId); } // 聚合内规则:每次修改都要维护不变式 private void recalculateTotalAmount() { this.totalAmount = items.stream() .mapToDouble(OrderItem::totalPrice) .sum(); } public double getTotalAmount() { return totalAmount; } } 比如订单聚合根,有自己唯一orderid,以及totalamount总金额,订单明细实体,地址值对象; 每次添加新的商品+数量,就自动调用一次更新总金额;保证事务的一致性。 仓储服务 特征 封装持久化操作:Repository负责封装所有与数据源交互的操作,如创建、读取、更新和删除(CRUD)操作。这样,领域层的代码就可以避免直接处理数据库或其他存储机制的复杂性。 抽象接口:Repository定义了一个与持久化机制无关的接口,这使得领域层的代码可以在不同的持久化机制之间切换,而不需要修改业务逻辑。 职责分离 领域层 只定义 Repository 接口,关注“需要做哪些数据操作”(增删改查、复杂查询),不关心具体实现。 基础设施层 实现这些接口(ORM、JDBC、Redis、ES、RPC、HTTP、MQ 推送等),封装所有外部资源的访问细节。 仓储解耦的手段使用了依赖倒置的设计。 示例: 只定义接口,由基础设施层来实现。 public interface IActivityRepository { GroupBuyActivityDiscountVO queryGroupBuyActivityDiscountVO(String source, String channel); SkuVO querySkuByGoodsId(String goodsId); } 使用:在应用程序中使用依赖注入(DI)来将具体的Repository实现注入到需要它们的领域服务或应用服务中。 聚合和领域服务和仓储服务的比较 有状态(Stateful): 一个订单(Order)聚合,它可能会记录订单的状态,比如“未支付”或“已支付”,以及订单项(OrderItem)的列表。在处理订单时,这些状态会发生变化(例如,当订单支付时,它的状态从“未支付”变为“已支付”)。 无状态: 一个计算价格的服务(PricingService)是无状态的,它接收输入(例如商品数量、商品价格等),然后计算并返回结果。它不会记住上一次计算的结果,每次计算都是独立的。 特性 聚合(Aggregate) 领域服务(Domain Service) 仓储(Repository) 本质 相关实体和值对象的组合,以“聚合根”为唯一访问入口 无状态的业务逻辑单元,封装跨实体 / 跨聚合规则 抽象的数据访问接口,隐藏底层存储细节,为聚合提供持久化能力 状态 有状态——内部维护数据与不变式 无状态——仅暴露行为 无业务状态;实现层可能有缓存,但对外看作无状态 职责 1. 内部一致性2. 定义事务边界3. 提供领域行为(order.pay() 等) 1. 承载跨实体规则2. 协调多个聚合完成业务动作 1. 加载 / 保存聚合根2. 把 PO ↔️ Entity 映射3. 屏蔽 SQL/ORM/缓存等技术细节 边界 聚合边界:内部操作要么全部成功要么全部失败 无一致性边界,仅调用聚合或仓储 持久化边界:一次操作针对一个聚合;不负责业务事务(由应用层控制) 典型用法 Order.addItem(),Order.cancel() PricingService.calculate(...),InventoryService.reserveStock(...) orderRepository.findById(id),orderRepository.save(order) **自己总结:**领域服务纯编排流程并注入仓储服务; 仓储服务只写接口,规定一个具体的'动作'; 然后基础设施层中子类实现该仓储接口,并注入若干Dao,一个'动作'可能调用多个Dao来实现; Dao直接与数据库打交道,实现增删查改。 API层 提供给其他服务直接依赖、并通过 RPC 调用本服务的契约。 这个 api 模块会被单独打成一个 Jar 包,其他服务只需要 依赖这个 jar,就能拿到: 1.请求 DTO 2.服务接口(通常供 RPC/Dubbo、HTTP 控制器或内部模块调用) 3.统一响应包装 response 基础设施层 1.持久化实现(Repository 实现类) 在领域层你只定义了 仓储接口(Repository Interface),比如 OrderRepository。 在基础设施层才写具体实现,比如用 JPA、MyBatis、Hibernate、JDBC 去操作数据库。 2.外部系统适配 对接第三方服务、消息队列例如:支付服务调用的 HttpClient 实现;拼团通过http请求小型支付商城的xx接口,或发rabbitmq。 3.基础设施组件封装 通用的技术性工具代码,不涉及业务逻辑,比如DCC动态配置中心,邮件的调用,AOP切面类动态限流 4.事件与消息机制 提供消息队列的具体实现,配置与发送。 Trriger触发器层 触发器层主要负责 “接收外部输入,触发应用/领域逻辑” 1.HTTP 接口(Controller) 2.消息监听(Listener / Consumer) 3.定时任务(Job / Scheduler) 比如超时退款、拼团组队成功通知等。 4.RPC 接口(Dubbo、gRPC、Thrift 等) 作为服务提供方,暴露给其他系统调用的接口。 Types通用类型层 目录 作用 示例 annotations 自定义注解及其拦截器。 DCCValue、RateLimiterAccessInterceptor:比如做参数校验、限流、配置注入等。 common 全局常量、通用工具类。 Constants:放系统级别的常量、公共配置Key等。 design.framework 设计模式或通用策略框架的封装。tree、link 子包像是策略路由、责任链等可复用的实现。 AbstractStrategyRouter、StrategyHandler:策略路由器抽象,供业务模块按需继承。 enums 系统级枚举。和业务场景相关但通用的状态、返回码等。 ActivityStatusEnumVO、GroupBuyOrderStatusEnumVO、ResponseCode 等。 event 基础事件类型,领域事件的通用父类。 BaseEvent:其他模块可继承实现自定义事件。 exception 自定义异常体系。 AppException:统一异常封装,便于全局处理。 DDD架构设计 四层架构 用户接口层interface:处理用户交互和展示 应用层application:协调领域对象完成业务用例 领域层domain:包含核心业务逻辑和领域模型 基础设施层infrastructure:提供技术实现支持 如何从MVC架构映射到DDD架构? 六边形架构 领域模型设计 方式1;DDD 领域科目类型分包,类型之下写每个业务逻辑。 **方式2;**业务领域分包,每个业务领域之下有自己所需的 DDD 领域科目。(拼团营销系统是方式2)
后端学习
zy123
1年前
0
22
0
2025-06-20
拼团交易系统
拼团交易系统 部署 本地环境:Maven3.8.4 SpringBoot: 2.7.12 jdk:1.8 目录结构: 本地启动-1 docker-compose: version: '3.8' services: # 1. 前端 group-buy-market-front: image: nginx:alpine container_name: group-buy-market-front restart: unless-stopped ports: - '18091:80' volumes: - ./nginx/html:/usr/share/nginx/html - ./nginx/conf/nginx.conf:/etc/nginx/nginx.conf:ro privileged: true networks: - group-buy-network # 4. Java 后端 group-buying-sys: build: context: ../../.. # 从 docs/tag/v2.0 回到项目根 dockerfile: group-buying-sys-app/Dockerfile image: smile/group-buying-sys:latest container_name: group-buying-sys restart: unless-stopped depends_on: mysql: condition: service_healthy redis: condition: service_healthy ports: - '8091:8091' environment: - TZ=Asia/Shanghai - SPRING_PROFILES_ACTIVE=prod volumes: - ./log:/data/log logging: driver: json-file options: max-size: '10m' max-file: '3' networks: - group-buy-network mysql: image: mysql:8.0 container_name: group-buy-mysql hostname: mysql command: --default-authentication-plugin=mysql_native_password restart: unless-stopped environment: TZ: Asia/Shanghai MYSQL_ROOT_PASSWORD: 123456 ports: - "13306:3306" volumes: - ./mysql/my.cnf:/etc/mysql/conf.d/mysql.cnf:ro - ./mysql/sql:/docker-entrypoint-initdb.d healthcheck: test: [ "CMD", "mysqladmin" ,"ping", "-h", "localhost" ] interval: 5s timeout: 10s retries: 10 start_period: 15s networks: - group-buy-network # Redis redis: image: redis:6.2 restart: unless-stopped container_name: group-buy-redis hostname: redis privileged: true ports: - 16379:6379 volumes: - ./redis/redis.conf:/usr/local/etc/redis/redis.conf command: redis-server /usr/local/etc/redis/redis.conf networks: - group-buy-network healthcheck: test: [ "CMD", "redis-cli", "ping" ] interval: 10s timeout: 5s retries: 3 # rabbitmq # 账密 admin/admin # rabbitmq-plugins enable rabbitmq_management rabbitmq: image: rabbitmq:3.8-management container_name: group-buy-rabbitmq hostname: rabbitmq restart: unless-stopped ports: - "5672:5672" - "15672:15672" environment: RABBITMQ_DEFAULT_USER: admin RABBITMQ_DEFAULT_PASS: admin command: rabbitmq-server volumes: - ./rabbitmq/enabled_plugins:/etc/rabbitmq/enabled_plugins - ./rabbitmq/mq-data:/var/lib/rabbitmq networks: - group-buy-network nacos: image: nacos/nacos-server:v2.1.0 container_name: group-buy-nacos-server hostname: nacos restart: unless-stopped env_file: - ./nacos/custom.env ports: - "8848:8848" - "9848:9848" - "9849:9849" depends_on: - mysql networks: - group-buy-network volumes: - ./nacos/init.d:/docker-entrypoint-init.d networks: group-buy-network: external: true 本地启动,首先需要把docker中的mysql、redis、rabbitmq基本环境启动起来即可,其中nacos、group-buy-market-front(拼团前端)、group-buying-sys(拼团后端)都不用启。 然后项目代码改几个配置: 1)application配置文件切换到dev模式 spring: profiles: active: dev 2)application-dev中的dubbo相关配置注释掉 #dubbo: # application: # name: group-buy-market-service # 换成各自服务名 # registry: # address: nacos://localhost:8848 # 远程环境写内网地址 # # username/password 如果 Nacos 开了鉴权 # protocol: # name: dubbo # port: 20880 # 生产者开放端口;消费者可不写 # consumer: # timeout: 3000 # 毫秒 # check: false # 忽略启动时服务是否可用 3)把启动类上的@EnableDubbo注释掉 @SpringBootApplication @Configurable @EnableScheduling //@EnableDubbo(scanBasePackages = "edu.whut.trigger") public class Application { public static void main(String[] args){ SpringApplication.run(Application.class); } } 这样就不用配置 nacos 和小型支付商城 pay-mall 了,但是也无法使用前端界面联调,只能APIFOX、POSTMAN进行接口测试。 本地启动-2 要想前端联调,由于本服务是微服务项目,请求都由小型支付商城pay-mall发出,所以在本地启动-1的基础上,需要docker部署nacos、pay-mall、前端、frp内网穿透(可选),并且把项目代码中和dubbo相关的配置都启用,再运行后端。 其中前端需要修改一下nginx.conf中的: # 上游后端定义 upstream gbm_backend { # server group-buying-sys:8091; #线上部署 server host.docker.internal:8091; # 本地调试 } upstream pay_backend { # server pay-mall:8092; server host.docker.internal:8092; } 线上部署 docker-compose文件中的所有环境+前后端都用docker部署,其中后端单独写个dockerfile文件。 项目代码中将模式改为prod,dubbo配置全部启用,nginx.conf配置为线上部署。 dockerfile: # —— 第一阶段:Maven 构建 —— FROM maven:3.8.7-eclipse-temurin-17-alpine AS builder WORKDIR /workspace # 把项目级 settings.xml 复制到容器里 COPY .mvn/settings.xml /root/.m2/settings.xml # 1. 先只拷贝父 POM 及各模块的 pom.xml,加速依赖下载 COPY pom.xml ./pom.xml COPY group-buying-sys-api/pom.xml ./group-buying-sys-api/pom.xml COPY group-buying-sys-domain/pom.xml ./group-buying-sys-domain/pom.xml COPY group-buying-sys-infrastructure/pom.xml ./group-buying-sys-infrastructure/pom.xml COPY group-buying-sys-trigger/pom.xml ./group-buying-sys-trigger/pom.xml COPY group-buying-sys-types/pom.xml ./group-buying-sys-types/pom.xml COPY group-buying-sys-app/pom.xml ./group-buying-sys-app/pom.xml # 离线下载所有依赖 RUN mvn dependency:go-offline -B # 2. 拷贝所有源码 COPY . . # 3. 只打包 main 应用模块(连带编译它依赖的模块),跳过测试,加速构建 RUN mvn \ -f pom.xml clean package \ -pl group-buying-sys-app -am \ -DskipTests -B # —— 第二阶段:运行时镜像 —— FROM openjdk:17-jdk-slim LABEL maintainer="smile" # 可选:设置时区 ENV TZ=Asia/Shanghai RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone # 把构建产物拷过来 COPY --from=builder \ /workspace/group-buying-sys-app/target/group-buying-sys-app.jar \ app.jar # 暴露端口,按需改 EXPOSE 8091 ENTRYPOINT ["java", "-jar", "app.jar"] 修改项目后部署的影响: 前端服务 (group-buy-market-front) 代码位置:通过卷挂载 (./nginx/html:/usr/share/nginx/html)。 修改影响 如果修改的是 ./nginx/html 下的前端代码(如 HTML/JS/CSS),无需重建,Nginx 会直接读取更新后的文件。 如果修改的是 Nginx 配置 (./nginx/conf/nginx.conf),需重启容器生效: docker compose restart group-buy-market-front Java 后端服务 (group-buying-sys) 代码位置:通过镜像构建(build 指定了 Dockerfile 路径)。 修改影响 如果修改了 Java 代码或依赖(如 pom.xml),必须重建镜像: docker compose up -d --build group-buying-sys 其他服务(MySQL/Redis/RabbitMQ/Nacos) 代码位置:均使用官方镜像,无业务代码。 修改影响 修改配置文件(如 ./redis/redis.conf)需重启容器: docker compose restart redis 无需 --build(除非你自定义了它们的镜像)。 压测 .服务器资源:2核心4GB 验证锁单接口:防超卖 Jmeter测试,一秒发1000次请求下: 可以发现,只有一开始的少部分的并发请求进入抢占库存,抢占失败会返回'拼团组队失败,缓存库存不足',后面'交易锁单拦截-xx'都是在第一层就被拦下了,即下单前的人数/库存校验。 如果仅要求“防超卖”,已经可以确保在资源有限时也不超卖。 但是在2核 4GB,服务只能稳定支撑 ≈240 QPS,平均响应 2 秒 测试查询拼团配置接口: ≈320 QPS 系统备忘录 本系统涉及微信和支付宝的回调。 1.微信扫码登录,*https://mp.weixin.qq.com/debug/cgi-bin/sandboxinfo?action=showinfo&t=sandbox/index*平台上配置了扫描通知地址,如果是本地测试,需要打开frp内网穿透,然后填的地址是frp建立通道的服务器端的ip:端口 2.支付宝,用户付款成功回调,也是同理,本地测试就要开frp。注意frp中的通道,默认是本地端口=远程端口,但是如果在服务器上部署了一套,那么远程的端口就会与frp的端口冲突!!!导致本地测试的时候失效。 锁单结算大致流程: 用户锁单-》支付宝付款-》成功后return_url设置了用户支付完毕后跳转回哪个地址是给前端用户看的; alipay_notify_url设置了支付成功后alipay调用你的后端哪个接口。 这里有小商城和拼团系统,notify_url指拼团系统中拼团达到指定人数后,通知小商城的HTTP地址,但是如果notify_type为MQ,则 notify_url为空,并且notify_mq非空,指明是拼团成功通知还是用户退单通知(topic.team_refund)。 如果不参与拼团,则小商城的支付回调会直接修改订单为deal_done,然后发一个'支付成功'消息,进入下一环节:发货。 若参与拼团,则RPC调用拼团系统中的'拼团交易结算'接口,增加拼团完成量、更新订单状态。 若拼团达到人数,发送拼团成功通知,小商场将订单中相应拼团的 status 都设置为deal_done,然后小商场发一个'支付成功'消息,进入下一环节:发货。 此处为粗略总结,详细的和退单流程见下文。 踩坑 Lua脚本问题(后面也没采用这种方式) long max = target + recovery; String lua = "local v = redis.call('INCR', KEYS[1])+1; " + "if tonumber(v) > tonumber(ARGV[1]) then " + " redis.call('DECR', KEYS[1]); " + " return 0; " + "end " + "return v;"; Long occupy = redisService.eval( lua, RScript.ReturnType.INTEGER, Collections.singletonList(teamOccupiedStockKey), max); 报错: org.redisson.client.RedisException: ERR Error running script (call to f_xxxx): @user_script:1: user_script:1: attempt to compare nil with number. 问题:max的值根本传不到 ARGV[1] 原因:因为我配置了一个全局默认的序列号器: config.setCodec(JsonJacksonCodec.INSTANCE); //用 Jackson 进行序列化 Lua脚本期望:原始字符串或数字参数 因此,需要对这块单独配置序列化器StringCodec(): redissonClient.getScript(new org.redisson.client.codec.StringCodec()).eval(xxx,xx....) 系统设计 在 DDD 中有一套共识的工程两阶段设计手段,包括;战略设计、战术设计。 战略设计:战略设计的核心是通过业务边界划分和上下文隔离,将复杂的业务系统拆分为多个高内聚、低耦合的限界上下文,并明确它们之间的交互方式(如通过领域事件、API、消息队列等)。 战术设计:战术设计关注如何在限界上下文内部,使用领域模型来表达业务逻辑,避免传统的贫血模型(Anemic Model)导致的复杂、难以维护的代码。 用例图 用例图(use case diagram)是用户与系统交互的最简表示形式,展现了用户和与他相关的用例之间的关系。它不仅反映了不同角色(如用户、运营)在系统中的职责边界和任务范围,还以可视化的方式呈现了系统提供的核心功能和服务,如同一份构建系统的战略蓝图。 四色建模图 MVC的困局:面向过程的“大通铺” 传统MVC开发是面向过程的,像一个大通铺,大家挤在一起。 为每个功能流程(A、B、C流程)编写代码,导致功能代码四处复制、杂乱交织,难以管理和复用。 DDD的解法:面向领域的“精装公寓” DDD通过领域建模,将系统划分为不同的领域(如活动域、人群标签配置域、交易域)。 这就像为每个家庭分配独立的公寓和房间,让代码各归其位,结构清晰,易于维护。 1.建模方法 建模的起点:从用户行为出发 DDD建模始于用户,分析其行为命令如何触发系统动作。 用例图是完美的起点,它直观展示了用户与系统的所有交互,帮助我们识别出所有关键行为。 统一的语言:协作的基石 建模过程需要产品、研发、测试等所有角色基于统一语言(如“拼团”、“成团”)进行协作。 四色建模/风暴模型是DDD的标准方法,旨在让所有参与者能共同理解和构建业务模型。 此图为事件风暴法指导图,通过寻找领域事件,发起事件命令,完成领域事件的过程,完成 DDD 工程建模。 蓝色 - 决策命令,是用户发起的行为动作,如;发起拼团Command、支付订单Command,是流程的起点。 黄色 - 领域事件,在领域内已经发生的、有业务意义的事实。如支付已成功Event、拼团已成功Event。,是流程的终点。 红色 - 业务流程,连接决策命令和领域事件的处理逻辑或业务规则。它接收命令,执行业务操作,并产生事件,如拼团成团策略(判断人数是否已满)、支付处理流程。 粉色 - 外部系统,流程中需要调用的第三方服务或系统,如支付宝支付、微信登录。 绿色 - 只读模型,做一些读取数据的动作,没有写库的操作,如拼团活动展示。 棕色 - 领域对象,承载业务数据和行为的核心对象,是命令操作的直接目标,包括实体、值对象、聚合根,如用户地址(值对象)。 综上,左下角的示意图。是一个用户,通过一个策略命令,使用领域对象,通过业务流程,完成2个领域事件,调用1次外部接口个过程。我们在整个 DDD 建模过程中,就是在寻找这些节点。 流程解析: 1.起点:用户意图(User),用户想要做一件事,比如“发起拼团”或“支付订单”。 2.动作:决策命令(Command),用户的意图被封装为一个具体的 Command(命令),通常包含执行该命令所需的所有数据。 3.核心:领域对象,命令不会凭空执行,它 必须作用于 一个具体的 领域对象(通常是聚合根 Aggregate)。这个对象是业务的核心载体,拥有数据和行为。 4.执行:业务流程,领域对象根据自身的业务规则来处理接收到的命令。这个过程会修改对象自身的状态(如减少库存),并封装了最核心的业务逻辑。 5.结果:领域事件,业务执行成功后,会产生一个或多个领域事件。 6.扩展:调用外部系统,产生的领域事件可能会触发后续动作,其中之一就是调用外部系统。这是系统与外界协作的方式。 7.展示:读模型,负责提供数据查询功能。它通常通过监听领域事件来更新自己的数据视图,确保用户能看到最新的状态 2.寻找领域事件 寻找领域事件的过程,就是寻找系统中流程节点的结果态。什么结束了、什么完成了、什么终止。这个过程就是一堆人头脑风暴的过程,避免错失流程节点。 比如:发起拼团完成、支付完成、参与拼团完成、拼团目标达成、回调通知完成... 3.划分领域 在确定了领域事件以后,接下来要做的就是通过决策命令串联领域事件,并填充上所需要的领域对象。 首先,通过用户的行为动作,也就是决策命令,串联到对应的领域事件上。并对复杂的流程提供出红色的业务流程。 之后,为决策命令添加领域对象,每一个领域在整个流程中都起到了至关重要的作用。 有了识别出来的领域角色的流程,就可以非常容易的划分出领域边界了。 观察串联好的流程和聚集的领域对象,功能紧密相关、数据频繁交互的一组对象和事件自然形成一个领域。 例如: 所有与成团逻辑相关的命令、事件、实体(如拼团锁单、拼团结算)、策略(如成团校验策略)可以划归为 拼团域。 所有与活动相关的,比如活动配置信息、商品试算优惠价格,都可以划分为活动域。 4.简易流程图 首先,站在运营的角度,要为这次拼团配置对应的拼团活动。那么就会涉及到;给哪个渠道的什么商品ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商品所提供的规则信息,包括:折扣、起止时间、人数等。还要拿到折扣的一个试算金额。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格。 那么,拼团活动表,为什么会把折扣拆分出来呢。因为这里的折扣可能有多种迭代到一个拼团上。比如,给一个商品添加了直减10元的优惠,又对符合的人群id的用户,额外打9折,这样就有了2个折扣迭代。所以拆分出来会更好维护。这是对常变的元素和稳定的元素进行设计的思考。 另外,为了支持拼团库表,需要先根据业务规则把符合条件的用户 ID 写入 Bitmap,并为这批用户打上可配置的人群标签。创建拼团活动时,只需关联对应标签,即可让活动自动面向这部分用户生效,实现精准运营和差异化折扣。 之后,站在用户的角度,是参与拼团。首次发起一个拼团或者参与已存在的拼团进行数据的记录,达成拼团约定拼团人数后,开始进行通知。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。 系统表设计 group_buy_activity(拼团活动) 字段名 说明 id 自增 activity_id 活动ID activity_name 活动名称 discount_id 折扣ID group_type 成团方式(0自动成团、1达成目标成团) take_limit_count 拼团次数限制 target 拼团目标 valid_time 拼团时长(分钟) status 活动状态(0创建、1生效、2过期、3废弃) start_time 活动开始时间 end_time 活动结束时间 tag_id 人群标签规则标识 tag_scope 人群标签规则范围(多选;1可见限制、2参与限制) create_time 创建时间 update_time 更新时间 group_buy_discount(折扣配置) 字段名 说明 id 自增ID discount_id 折扣ID discount_name 折扣标题 discount_desc 折扣描述 discount_type 折扣类型(0:base、1:tag) market_plan 营销优惠计划(ZJ:直减、MJ:满减、ZK:折扣、N元购) market_expr 营销优惠表达式 tag_id 人群标签(特定优惠限定) create_time 创建时间 update_time 更新时间 group_buy_order(拼团订单表) 字段名 说明 id 自增ID team_id 拼单组队ID activity_id 活动ID source 渠道 channel 来源 original_price 原始价格 deduction_price 折扣金额 pay_price 支付价格 target_count 目标数量 complete_count 完成数量 lock_count 锁单数量 status 状态(0拼单中、1完成、2失败、3完成-含退单) valid_start_time 拼团开始时间 valid_end_time 拼团结束时间 notify_type 回调类型(HTTP、MQ) notify_url 回调地址(HTTP 回调不可为空) create_time 创建时间 update_time 更新时间 group_buy_order_list(拼团订单明细表) 字段名 说明 id 自增ID user_id 用户ID team_id 拼单组队ID order_id 订单ID activity_id 活动ID start_time 锁单时间 end_time 最晚锁单时间 valid_end_time 拼团结束时间 goods_id 商品ID source 渠道 channel 来源 original_price 原始价格 deduction_price 折扣金额 pay_price 支付金额 status 状态(0初始锁定、1消费完成、2用户退单) out_trade_no 外部交易单号(幂等) create_time 创建时间 update_time 更新时间 biz_id 业务唯一ID out_trade_time 外部交易时间 notify_task(回调任务) 字段名 说明 id 自增ID activity_id 活动ID team_id 拼单组队ID notify_category 回调种类(trade_unpaid2refund) notify_type 回调类型(HTTP、MQ) notify_mq 回调消息 notify_url 回调接口 notify_count 回调次数 notify_status 回调状态(0初始、1完成、2重试、3失败) parameter_json 参数对象 uuid 唯一标识 create_time 创建时间 update_time 更新时间 crowd_tags(人群标签) 字段名 说明 id 自增ID tag_id 人群ID tag_name 人群名称 tag_desc 人群描述 statistics 人群标签统计量 create_time 创建时间 update_time 更新时间 crowd_tags_detail(人群标签明细) 字段名 说明 id 自增ID tag_id 人群ID user_id 用户ID create_time 创建时间 update_time 更新时间 crowd_tags_job(人群标签任务) 字段名 说明 id 自增ID tag_id 标签ID batch_id 批次ID tag_type 标签类型(参与量、消费金额) tag_rule 标签规则(限定类型 N次) stat_start_time 统计数据开始时间 stat_end_time 统计数据结束时间 status 状态(0初始、1计划、2重置、3完成) create_time 创建时间 update_time 更新时间 sc_sku_activity(渠道商品活动配置关联表) 字段名 说明 id 自增ID source 渠道 channel 来源 activity_id 活动ID goods_id 商品ID create_time 创建时间 update_time 更新时间 sku(商品信息) 字段名 说明 id 自增ID source 渠道 channel 来源 goods_id 商品ID goods_name 商品名称 original_price 商品价格 create_time 创建时间 update_time 更新时间 DDD架构设计 MVC架构: DDD架构: 价格试算与人群标签 活动是否允许用户参与,拼团的判断逻辑有两重,具体条件如下: 活动是否设置了 tag_scope tag_scope 用于限制活动参与的范围。若活动未设置 tag_scope,则默认认为没有任何限制,所有用户均可参与拼团;若配置了 tag_scope,则需要根据该配置进一步判断用户是否符合参与条件。 用户是否在指定的人群标签 tag_id 范围内 tag_id 指定了本次活动的参与人群,只有拥有该标签的人群才能参与活动(具体逻辑就是每个tagid的位图里存了很多userid,只有这些userid才能参与)。如果活动未配置 tag_id,则默认所有用户都可参与拼团。 需要注意的是,在本项目的实现中,虽然活动配置了 tag_id,但由于位图(bitmap)未进行配置,实际上也是默认所有用户均可参与拼团。 ps:这里只校验用户是否有参与活动的资格!!! 后续还有锁单的校验,注意区分,锁单是基于这里的资格判断之后的,再去此时活动是否仍有效、用户参与拼团次数是否已达上限... 价格试算流程 使用了规则树的设计模式,详情请见 拼图设计模式 IndexGroupBuyMarketService │ │ indexMarketTrial() ▼ DefaultActivityStrategyFactory │ (return rootNode) ▼ RootNode.apply() │ doApply() (执行) │ router() (路由到下一node) ▼ SwitchNode.apply() │ ... ▼ MarketNode.apply() ... (可能还有其他节点) ▼ EndNode.apply() → 组装结果并返回 TrialBalanceEntity ▲ └────────── 最终一路向上 return IndexGroupBuyMarketService 是领域服务,整个价格试算的入口 DefaultActivityStrategyFactory 帮你拿到 根节点,真正的“工厂”工作(多线程预处理、分支路由)都在各 Node 里完成。 DynamicContext 是一次性创建的共享上下文:谁需要谁就往里放 优惠策略配置 目前项目中是单策略模式,即满减、直减、折扣 这些优惠 N选一 ;未来可能需要支持 多种优惠组合(例如“满减 + 优惠券 + 折扣”),因此需要一种 可扩展的优惠计算策略体系。 1.组合策略(静态组合) 最简单的实现方式是为每种优惠组合定义一个组合类,例如“满减 + 优惠券”: @Service("MJ_COUPON") public class MJCouponCalculateService extends AbstractDiscountCalculateService { @Resource private MJCalculateService mjCalculateService; @Resource private CouponCalculateService couponCalculateService; @Override public BigDecimal doCalculate(BigDecimal originalPrice, GroupBuyActivityDiscountVO.GroupBuyDiscount groupBuyDiscount) { // 先满减 BigDecimal afterMJ = mjCalculateService.doCalculate(originalPrice, groupBuyDiscount); // 再用优惠券 return couponCalculateService.doCalculate(afterMJ, groupBuyDiscount); } } 问题:但是如果以后有更多组合(比如“满减+直减+优惠券”),会出现类爆炸,扩展性差。 2.动态策略组合(推荐方案) 通过配置文件或数据库指定策略执行顺序,例如:["MJ", "COUPON", "DISCOUNT"] 编写通用组合类,根据配置顺序依次执行各策略: public class CompositeDiscountService extends AbstractDiscountCalculateService { private final List<IDiscountCalculateService> strategies; @Override public BigDecimal doCalculate(BigDecimal originalPrice, GroupBuyActivityDiscountVO.GroupBuyDiscount discount) { BigDecimal price = originalPrice; for (IDiscountCalculateService s : strategies) { price = s.calculate("userId", price, discount); } return price; } } 这种设计支持任意顺序与动态扩展,避免硬编码。 策略执行逻辑配置方式 (1)固定优先级(非动态计算) 由运营或产品预先定义策略执行顺序,例如:例如强制规定 满减 → 直减 → 折扣,避免计算所有排列组合。 优点:性能高,规则可控。适用场景:优惠策略较少或业务方明确要求顺序。 (2)动态计算最优解 系统自动枚举可叠加的优惠组合,有限枚举 + 剪枝优化,仅对允许叠加的策略枚举顺序,并通过规则提前排除无效组合(如互斥优惠)。 优点:灵活性高,用户获利最大化。 假设总价 300元,可用优惠三选二: 满 200减 50. 满 300打 8折. 直减 20元 顺序 计算过程 结果 满减 → 折扣 (300-50)*0.8 200 满减 → 直减 (300-50)-20 230 折扣 → 满减 (300*0.8)-50 190 ← 最优 折扣 → 直减 (300*0.8)-20 220 直减 → 满减 (300-20) -50 230 直减 → 折扣 (300-20)*0.8 224 (3)分层优惠 总价 │ ├─ 第一阶段:全局优惠(如全场8折) │ ├─ 第二阶段:品类优惠(如家电满1000减100) │ └─ 第三阶段:单品优惠(如A商品直降50) 人群标签 在规则树的TagNode节点中,需要判断当前请求用户是否在位图中(目标人群)。 人群标签采集 步骤 目的 说明 1. 记录日志 标明本次批次任务的开始 方便后续排查、链路追踪 2. 读取批次配置 拿到该批次统计范围、规则、时间窗等 若返回 null 通常代表批次号错误或已被清理 3. 采集候选用户 从业务数仓/模型结果里拉取符合条件的用户 ID 列表 真实场景中会:• 调 REST / RPC 拿画像• 或扫离线结果表• 或读 Kafka 流 4. 双写标签明细 将每个用户与标签的关系永久化 & 提供实时校验能力 方法内部两件事:• 插入 crowd_tags_detail 表• 在 Redis BitMap 中把该用户对应位设为 1(幂等处理冲突) 5. 更新统计量 维护标签当前命中人数,用于运营看板 这里简单按“新增条数”累加,也可改为重新 count(*) 全量回填 6. 结束 方法返回 void 如果过程抛异常,调度系统可重试/报警 一句话总结 这是一个被定时器或消息触发的离线批量打标签任务: 拉取任务规则 → (离线)筛出符合条件的用户 → 写库 + 写 Redis 位图 → 更新命中人数。 之后业务系统就能用位图做到毫秒级 isUserInTag(userId, tagId) 判断,实现精准运营投放。 Bitmap(位图) 概念 Bitmap 又称 Bitset,是一种用位(bit)来表示状态的数据结构。 它把一个大的“布尔数组”压缩到最小空间:每个元素只占 1 位,要么 0(False)、要么 1(True)。 为什么用 Bitmap? 超高空间效率:1000 万个用户,只需要约 10 MB(1000 万 / 8)。 超快操作:检查某个索引位是否为 1、计数所有“1”的个数(BITCOUNT)、找出第一个“1”的位置(BITPOS)等,都是 O(1) 或者极快的位运算。 存储方式 bitmap.set(123) 的含义就是把 第 123 位 (bit) 标记为 1。 在底层实现上,Bitmap 通常用一段连续的二进制数组(比如 int[] 或 byte[])来存储: 如果用 int 数组存储:每个 int 占 32 bit(在 Java/C++ 等语言里)。 第 123 个 bit 属于第 123 / 32 = 3 个整型元素(下标从 0 开始)。 在这个元素里具体是哪一位呢?就是 123 % 32 = 27 这位。 所以实际上是 array[3] 的第 27 个 bit 被置 1。 如果用 byte 数组存储:每个 byte 占 8 bit。 第 123 个 bit 属于第 123 / 8 = 15 个字节。 在这个字节里具体位置是 123 % 8 = 3。 所以是 array[15] 的第 3 位被置 1。 Bitmap人群标签思路 法一: 把 userid 用 MD5 映射到了一个固定的整数区间 [0, Integer.MAX_VALUE),即约 21 亿个可能的位置。 MD5(UUID) → 128 位哈希值=>转成正整数=>对 Integer.MAX_VALUE(≈2.1×10⁹)取模=>结果就是 bitmap 下标 index。 ≈ 256 MB 的位图 default int getIndexFromUserId(String userId) { try { MessageDigest md = MessageDigest.getInstance("MD5"); byte[] hashBytes = md.digest(userId.getBytes(StandardCharsets.UTF_8)); // 将哈希字节数组转换为正整数 BigInteger bigInt = new BigInteger(1, hashBytes); // 取模以确保索引在合理范围内 return bigInt.mod(BigInteger.valueOf(Integer.MAX_VALUE)).intValue(); } catch (NoSuchAlgorithmException e) { throw new RuntimeException("MD5 algorithm not found", e); } } MD5有128位,只能BigInteger来接收。 这个方法会出现假阳性(非目标用户被误判为在)。减轻办法: 布隆过滤器 核心思想:用 多个哈希函数 来降低冲突,不消除碰撞本质。 具体做法: 对 userId 用 k 个不同的 hash 函数(可以是 MD5 的不同切片、或 MurmurHash 等)。 得到 k 个位置,把这些位置的 bit 全部设为 1。 判断存在性时,只要这 k 个位置都为 1,就认为“可能存在”;只要有一个为 0,就一定不存在。 这样虽然依然有假阳性(可能存在其实不存在),但概率大大降低。 判断是否是否存在,如果任意一个bit=0 =》一定不存在;如果所有bit=1=》可能存在。 法二: 如果用户是 UUID,我不会直接拿 UUID 取模进 bitmap,因为那样一定会有哈希冲突。想做到精确集合、零误判,我会先在系统中维护一份稳定的 UUID 到稠密整型 ID 的映射表。 每个 UUID 在首次出现时分配一个连续的整型 ID,比如从 0 开始自增,这样我们就把原本稀疏的 128 位空间压缩成 0 到 N-1 的稠密索引。之后,bitmap 的第 ID 位就代表该用户是否在目标人群。 **查询流程也很简单:**先通过映射表把 UUID 转成 ID,然后直接在 bitmap 上判断对应那一位是否为 1。这样整个体系是 O(1) 的查写效率,完全无冲突,而且空间极省——一千万人也就一两兆。 映射表这层大概两三百兆,可以放在 Redis 或 RocksDB 里,全局复用。 追问:那我直接在redis中用set存储目标用户的uuid不可以吗?为什么还要先通过映射表,再查bitmap? 答:映射表只是一个全局、长期复用的索引层。它的空间开销固定、规模稳定。我们后面的人群 bitmap 可能有上千份,对应着不同的目标人群分类!!!,但它们都共用这一份映射表。一次投入,多次使用。 人群标签过滤 白名单。 无 tagId(没配标签)→ 不限人群,全部放行(visible=true, enable=true)。 有 tagId 且位图存在 → 位图里的人可以参加(白名单)。 有 tagId 但位图不存在 → 现在的实现是默认全放行(把“未配置位图”当作“不限制”),因为真实场景中由外部系统统计用户行为 => 将符合条件的用户放入位图中,这里暂时没有模拟。 动态降级与人群切量 downgradeSwitch —— 降级开关 作用:在出现异常或高压场景时,主动关闭部分功能,保证核心流程可用。 值为 0(默认):功能正常,系统按照全量逻辑执行。 值为 1:开启降级,比如: 关闭一些非核心功能(如推荐、统计、日志落库)。 使用兜底方案(如直接返回默认值、提示“稍后再试”)。 cutRange —— 人群切量开关 作用:做灰度发布或分流测试,让不同用户群体验不同的功能版本。 默认值为 100:表示 100% 用户都可用,即全量发布。 如果设置为 30:就表示 只有 30% 的用户能进入新功能,其他 70% 用户还是老逻辑。 计算逻辑:对用户 ID 做哈希,取模 100,落在 [0, cutRange] 范围内的用户通过。 public boolean isCutRange(String userId) { // 计算哈希码的绝对值 int hashCode = Math.abs(userId.hashCode()); // 获取最后两位 int lastTwoDigits = hashCode % 100; // 判断是否在切量范围内 // 在范围内,可以继续参加活动 if (lastTwoDigits <= Integer.parseInt(cutRange)) { return true; } return false; } 不要直接对用户 ID 取模,因为可能是String类型的。 拼团交易锁单 下单到支付中间有一个流程,即锁单,比如淘宝京东中,在这个环节(限定时间内)选择使用优惠券、京豆等,可以得到优惠价,再进行支付;拼团场景同理,先加入拼团,进行锁单,然后优惠试算,最后才付款。 锁单流程: 1.幂等查询,如果已有一模一样的锁单,直接返回该条记录;(见下文防止重复下单 ) 2.拼团人数校验(前端显示有滞后性,在调用锁单接口的时候还要重新拉取一下) 3.优惠试算,查看拼团活动配置信息(优惠价、目标人群、活动有效期、最大参与次数...)。 4.人群限定,非目标人群不允许参与活动。 5.锁单责任链 活动有效性 用户参与次数 剩余库存校验(见下文 防超卖 ) 拼团结算 结算规则过滤:SC渠道拦截、外部交易单号交易、结算时间校验(now小于拼团结束时间) 对接商城和拼团系统 下单总体流程 查询商品并初始化订单 查询商品信息,构建订单,填入 total_amount,此时订单状态为 PAY_CREATE。 判断订单类型 普通下单:直接进入预支付流程。 拼团下单/开团:远程调用拼团系统,执行锁单逻辑(活动校验、库存校验、优惠计算等)。 生成预支付订单 根据订单类型决定支付金额: 普通单:按商品原价。 拼团单:按优惠后价格。 创建支付单,填入 pay_amount、pay_url 等信息,订单状态置为 PAY_WAIT。 等待支付回调 用户扫码/支付成功后,支付平台回调商城接口,更新订单状态。 超时未支付订单由调度任务关闭。 具体业务步骤 1. 用户下单 如果用户已存在未支付订单: 且有支付链接(pay_url) → 直接返回支付链接。 没有支付链接 → 进入支付单创建流程。 否则,进入新订单创建。 2. 创建订单 查询商品信息并保存新订单(状态 PAY_CREATE)。 若为拼团单(marketType == GROUP_BUY_MARKET),调用拼团系统执行 营销锁单 校验活动有效性 校验用户参与次数 校验剩余库存 优惠试算 记录拼团锁单结果(订单号、折扣金额等) 普通订单跳过营销锁单。 3. 创建预支付单 拼团单:根据优惠结果生成预支付订单。 普通单:直接用原价生成预支付订单。 更新订单状态为 PAY_WAIT,返回支付链接。 支付完成与组队结算 1.支付回调 更新订单状态 触发“支付结算并发货”流程 2.组队结算判断 调用拼团营销系统组队结算接口,更新当前拼团完成人数 判断该拼团是否已完成: 是: 调用营销结算 HTTP 接口 结算完成 N 个用户组成的队伍 发送“组队完成回调通知” 否:直接结束流程 3.后续发货 当收到拼团完成(complete_count==target_count)的回调消息时,小型商城执行后续交易结算及发货逻辑(目前是模拟触发的)。 注意 alipay_notify_url 作用:支付宝在用户支付成功后,向该地址发起服务器端回调(需公网可访问,或通过内网穿透映射到本地)。 调用流程:支付宝 → pay-mall 用途:pay-mall 接收到支付成功通知后,可以调用拼团组队结算接口。 与之相关的两个地址: return_url:用户付款后网页自动跳转的地址(通常是返回商城首页),属于前端页面跳转,与业务结算无关。 gateway_url:支付宝提供的商户收款页面地址(用户发起付款时访问)。 group-buy-market_notify_url http://127.0.0.1:8092/api/v1/alipay/group_buy_notify 注意!HTTP调用下才使用,MQ这个字段失效! 作用:由 pay-mall 商城设置,作为拼团平台的回调地址。 调用流程:拼团平台(group-buy-market) → pay-mall 触发条件:某个 teamId 的拼团人数达到目标值,拼团成功。 用途:通知 pay-mall 对该 teamId 下所有成员执行后续操作,例如发货。 本地对接 在 group-buying-sys 项目中,对 group-buying-api 模块执行 mvn clean install(或在 IDE 中运行 install)。这会将该模块的 jar 安装到本地 Maven 仓库(~/.m2/repository)。然后在 pay-mall 项目的 pom.xml 中添加依赖,使用相同的 groupId、artifactId 和 version 即可引用该模块,如下所示: <dependency> <groupId>edu.whut</groupId> <artifactId>group-buying-api</artifactId> <version>1.0.0-SNAPSHOT</version> </dependency> 发包 仅适用于本地,共用一个本地Maven仓库,一旦换台电脑或者在云服务器上部署,无法就这样引入,因此可以进行发包。这里使用阿里云效发包https://packages.aliyun.com/ 1)点击制品仓库->生产库 2)下载settings-aliyun.xml文件并保存至本地的Maven的conf文件夹中。 3) 配置项目的Maven仓库为阿里云提供的这个,而不是自己的本地仓库。 4)发包,打开Idea中的Maven,双击deploy 5)验证 6)使用 将公共镜像仓库的settings文件和阿里云效的settings文件合并,可以同时拉取公有依赖和私有包。 逆向工程:退单 逆向的流程,要分析用户是在哪个流程节点下进行退单行为。包括3个场景; 已锁单、未支付:redis恢复量+1,mysql中锁单量-1 已锁单、已支付,但拼团未成团:redis恢复量+1,mysql中锁单量、完成量-1,退款 已锁单、已支付,且拼团已成团:redis恢复量无需+1,因为成团之后不开放给别人;mysql中锁单量、完成量-1,退款,拼团设置为'已完成含退单'状态,但拼团中所有人都退单,更新为失败! 核心流程说明 阶段一:退单操作流程 客户主动提交退单请求 通过责任链模式处理:数据加载Node(查询订单) → 重复检查Node(防止重复退单) → 策略执行Node 策略选择 根据订单状态和拼团状态选择对应退单策略(三种之一) 执行退单 更新数据库操作(锁单量、完成量、拼团状态、订单状态...) 消息通知 + 任务补偿 发送MQ退单消息通知(未支付退单、已支付未成团...三种消息 notify_category) 将消息写入notify_task表,定时任务扫描未成功处理的消息,以做补偿兜底。 阶段二:库存恢复流程 消息监听 MQ监听器接收退单成功消息 服务调用 调用恢复库存服务 策略选择 根据退单类型选择对应策略(已成团的无需恢复了,反正新用户也无法再参与该拼团) 库存恢复 执行Redis库存恢复操作(带分布式锁保护) 设计模式应用 责任链模式 TradeRefundRuleFilterFactory 构建的过滤链: DataNodeFilter → UniqueRefundNodeFilter → RefundOrderNodeFilter 策略模式 策略接口:RefundOrderStrategy 实现策略: Unpaid2RefundStrategy(未付款退单的流程) Paid2RefundStrategy(已付款退单) PaidTeam2RefundStrategy(已成团退单) 工厂模式 TradeRefundRuleFilterFactory 负责组装责任链 模板方法模式 AbstractRefundOrderStrategy 提供: 公共方法封装 (发送退单MQ消息、库存恢复redis) 依赖注入支持 退单触发入口 1)用户主动退单 2)定时任务,定时任务扫描锁单但未结算的订单,若支付时间超过设定值,对这笔订单执行退单操作。 注意:小型支付商城中的订单可能有些是普通订单,有些是拼团订单。 对于普通订单,无需调用拼团系统中的退单接口,自己本地退单,对于CREATE或PAY_WAIT状态的订单,直接修改订单状态为CLOSED;对于PAY_SUCCESS(个人支付完成)、DEAL_DONE,额外调用支付宝退款。 对于拼团订单,RPC调用拼团系统的退单接口,调用成功后设置订单为WAIT_REFUND,然后由MQ消息回调调用支付宝退款。 定时任务+MQ消息通知 定时任务 拼团营销系统: 1.MQ消息补偿,每天零点执行一次(暂定) //每天零点执行一次 @Scheduled(cron = "0 0 0 * * ?") public void exec() { // 为什么加锁?分布式应用N台机器部署互备(一个应用实例挂了,还有另外可用的),任务调度会有N个同时执行,那么这里需要增加抢占机制,谁抢占到谁就执行。完毕后,下一轮继续抢占。 // 获取锁句柄,并未真正获取锁 RLock lock = redissonClient.getLock("group_buy_market_notify_job_exec"); try { //尝试获取锁 waitTime = 3:如果当前锁已经被别人持有,调用线程最多等待 3 秒去重试获取; // leaseTime = 0:不设过期时间,看门狗机制 boolean isLocked = lock.tryLock(3, 0, TimeUnit.SECONDS); if (!isLocked) return; Map<String, Integer> result = tradeTaskService.execNotifyJob(); log.info("定时任务,回调通知完成 result:{}", JSON.toJSONString(result)); } catch (Exception e) { log.error("定时任务,回调通知失败", e); } finally { if (lock.isLocked() && lock.isHeldByCurrentThread()) { lock.unlock(); } } } 2.超时未支付订单扫描,每隔5分钟执行一次;主要就是营销锁单了,但是15分之内还没付款,自动调用退单逻辑,释放锁单量,然后发退单的MQ消息。 小型支付商城: 1.支付宝回调补偿,未支付订单扫描,每隔10秒调用一次支付宝的接口,查询某未支付的订单到底付了没有,如果付了,则更新订单状态。主要是为了防止用户付了钱,但是由于网络波动,导致支付宝调用系统的回调接口失败,做的一次补偿动作。 2.超时订单扫描,每3分钟执行一次,对于超过15分钟仍未付款的订单,将其关闭。 待优化:将定时轮询查询改为在每个用户下单时发一个延迟消息的事件触发方式。 特性 定时轮询查询 延迟消息(事件触发) 优胜方 实时性 差(取决于轮询间隔,如1分钟) 高(理论上精确到秒) 延迟消息 数据库压力 巨大(高频扫描全表) 极小(只查单条记录) 延迟消息 可靠性 高(逻辑简单,不易丢单) 中(依赖MQ的可靠性) 定时轮询 扩展性 差(订单量越大,性能越差) 好(天然分布式,随订单量线性扩展) 延迟消息 复杂度 低(实现简单) 中(需引入和维护MQ) 定时轮询 资源利用率 低(大量无效查询) 高(按需触发,无浪费) 延迟消息 MQ消息 有三种MQ消息: 1.退单消息 2.拼团组队成功消息 3.订单支付成功消息 退单消息:拼团系统发送,拼团订单。拼团系统发送,小型商城和拼团系统都接收,各自执行退单流程。 组队成功消息:拼团系统发送,拼团订单。拼团系统发送,小型商城和拼团系统都接收,小型商城更新订单状态;拼团系统仅仅是简单的打印一下'通知成功'消息。 订单支付成功消息:小型商城发送,普通订单则用户支付后的回调就发送;拼团订单则是先接到'组队成功消息'之后 再发MQ。小型商城接收,更新订单状态为模拟发货。 这里主要起到解耦的作用,将发货这个过程解耦。 不仅在相关接口完成的时候自动发送MQ消息,同时有兜底,将MQ消息持久化进Mysql,设置定时任务来扫描表,对暂未处理(处理失败)的MQ消息重新投递。 字段名 类型 允许为空 默认值 约束 / 备注 id int UNSIGNED NO AUTO_INCREMENT 自增ID,主键 activity_id bigint NO 活动ID team_id varchar(8) NO 拼单组队ID notify_category varchar(64) YES NULL 回调种类 notify_type varchar(8) NO 'HTTP' 回调类型(HTTP、MQ) notify_mq varchar(32) YES NULL 回调消息 notify_url varchar(128) YES NULL 回调接口 notify_count int NO 回调次数 notify_status tinyint(1) NO 回调状态【0 初始、1 完成、2 重试、3 失败】 parameter_json varchar(256) NO 参数对象(JSON 字符串) uuid varchar(128) NO 唯一标识 create_time datetime NO CURRENT_TIMESTAMP 创建时间 update_time datetime NO CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 更新时间 如何确保MQ消息持久化成功? // 4. 更新数据库,拼团交易结算,若达到拼团人数,返回notifyTaskEntity发送回调通知,否则返回null不做处理 NotifyTaskEntity notifyTaskEntity =repository.settlementMarketPayOrder(groupBuyTeamSettlementAggregate); // 5. 组队回调处理 - 处理失败也会有定时任务补偿,通过这样的方式,可以减轻任务调度,提高时效性 if (null != notifyTaskEntity) { threadPoolExecutor.execute(() -> { Map<String, Integer> notifyResultMap = null; try { notifyResultMap = tradeTaskService.execNotifyJob(notifyTaskEntity); log.info("回调通知拼团完结 result:{}", JSON.toJSONString(notifyResultMap)); } catch (Exception e) { log.error("回调通知拼团完结失败 result:{}", JSON.toJSONString(notifyResultMap), e); throw new AppException(e.getMessage()); } }); } 在拼团支付成功后的结算过程中(repository.settlementMarketPayOrder),所有数据库操作(更新状态、更新拼团人数、持久化拼团成功消息)都被包含在一个事务内。通过 @Transactional 注解保证了事务的一致性,确保了操作的原子性。 如果任何步骤失败,事务会回滚,数据保持一致。 repository.settlementMarketPayOrder 执行失败的话,后面也不会发送MQ消息了。 如果操作是幂等的,并且失败是由于 暂时性故障(如数据库连接失败、网络问题等),那么可以引入 重试机制 来增加系统的容错性。 如何衡量消息是否成功发送? private Map<String, Integer> execNotifyJob(List<NotifyTaskEntity> notifyTaskEntityList) throws Exception { //successCount:成功回调的任务数量 int successCount = 0, errorCount = 0, retryCount = 0; for (NotifyTaskEntity notifyTask : notifyTaskEntityList) { // HTTP模式下回调小商城中的groupBuyNotify接口 success 成功,error 失败 String response = port.groupBuyNotify(notifyTask); // 更新状态判断&变更数据库表回调任务状态 if (NotifyTaskHTTPEnumVO.SUCCESS.getCode().equals(response)) { int updateCount = repository.updateNotifyTaskStatusSuccess(notifyTask); if (1 == updateCount) { successCount += 1; } } else if (NotifyTaskHTTPEnumVO.ERROR.getCode().equals(response)) { if (notifyTask.getNotifyCount() < 5) { // 失败但可以重试 → 标记为 RETRY,等待下一次收集 “待处理的通知任务列表” if (repository.updateNotifyTaskStatusRetry(notifyTask) == 1) { retryCount++; } } else { // 已达最大重试次数 → 标记为 ERROR(不再重试) if (repository.updateNotifyTaskStatusError(notifyTask) == 1) { errorCount++; } } } } 目前逻辑比较简单,只能确保消息发送出去了,如果为了提高安全性,还需要: 1.发送方确认机制(ConfirmCallback、returnCallback) 2.消费方确认机制,比如把auto ACK改为manul ACK,配置无状态重试/有状态重试(需要对消息做幂等性处理),超过最大重试次数的消息进入死信队列中,等待人工审查。 3.消费方成功收到消息并将消息表中的对应消息的status设置为'已完成',而不是发送者来写。 收获 实体对象 实体是指具有唯一标识的业务对象。 在 DDD 分层里,Domain Entity ≠ 数据库 PO。 在 edu.whut.domain.*.model.entity 包下放的是纯粹的业务对象,它们只表达业务语义(团队 ID、活动时间、优惠金额……),对「数据持久化细节」保持无感知。因此它们看起来“字段不全”是正常的: 它们不会带 @TableName / @TableId 等 MyBatis-Plus 注解; 也不会出现数据库的技术字段(id、create_time、update_time、status 等); 只保留聚合根真正需要的业务属性与行为。 @Data @Builder @AllArgsConstructor @NoArgsConstructor public class PayActivityEntity { /** 拼单组队ID */ private String teamId; /** 活动ID */ private Long activityId; /** 活动名称 */ private String activityName; /** 拼团开始时间 */ private Date startTime; /** 拼团结束时间 */ private Date endTime; /** 目标数量 */ private Integer targetCount; } 这个也是实体对象,因为多个字段的组合: teamId 和 activityId 能唯一标识这个实体。 多线程异步调用 如果某任务比较耗时(如加载大量数据),可以考虑开多线程异步调用。 创建线程池 ThreadPoolExecutor executor = new ThreadPoolExecutor( corePoolSize, // 核心线程数,常驻 maxPoolSize, // 最大线程数 keepAliveTime, // 空闲线程存活时间 TimeUnit.SECONDS, // 时间单位 new LinkedBlockingQueue<>(100), // 有界任务队列 Executors.defaultThreadFactory(), // 线程工厂,默认命名 pool-1-thread-x new ThreadPoolExecutor.AbortPolicy() // 拒绝策略,队列满时抛异常 ); 注意:生产环境建议使用有界队列,避免内存溢出;拒绝策略可选 CallerRunsPolicy 等实现背压。 提交任务 在 ThreadPoolExecutor 中,你可以用 两种方式提交任务: execute(Runnable):提交不需要返回值的任务。 submit(Runnable):也可以传 Runnable,但会返回一个 Future<?>,future.get() 得到 null,常用于等待任务完成或捕获异常。 submit(Callable):提交需要返回值的任务,返回 Future。 // 1) Runnable + execute:无返回值,无法感知异常 executor.execute(() -> { try { System.out.println(Thread.currentThread().getName()); } catch (Exception e) { e.printStackTrace(); } }); // 2) Runnable + submit:返回 Future,可用来等待或捕获异常 Future<?> f1 = executor.submit(() -> { System.out.println("Runnable 任务"); // int x = 1 / 0; // 如果抛异常,在 f1.get() 时感知 }); f1.get(); // 返回 null;若任务抛异常,这里会抛 ExecutionException // 3) Callable + submit:有返回值,可抛异常 Future<String> f2 = executor.submit(() -> { TimeUnit.MILLISECONDS.sleep(200); return "任务完成"; }); System.out.println(f2.get()); // 拿到返回值;若任务抛异常,这里会抛 ExecutionException executor是ThreadPoolExecutor 实例,调用 execute/submit 后,线程池会把任务放入队列,并自动选择线程执行,执行完后线程复用,不会频繁创建销毁。 什么是 Future? 当你用 submit() 提交任务时,线程池会立即返回一个 Future 对象,表示“任务的未来结果”。 你可以通过这个 Future: 获取任务的执行结果 判断任务是否完成 取消任务 获取任务抛出的异常 V get() // 阻塞,直到任务执行完成,返回结果或抛异常 V get(long timeout, TimeUnit unit) // 阻塞指定时间,超时抛 TimeoutException boolean cancel(boolean mayInterruptIfRunning) // 取消任务 boolean isDone() // 判断任务是否完成 什么是FutureTask 同时实现了 Runnable 和 Future 两个接口。它既是一个 任务(能被线程或线程池执行),又是一个 Future(能拿到异步结果)。 FutureTask = Runnable + Future import java.util.concurrent.*; public class FutureTaskDemo2 { public static void main(String[] args) throws Exception { ExecutorService executor = Executors.newFixedThreadPool(2); Callable<String> task = () -> { Thread.sleep(1000); return "Hello from FutureTask"; }; FutureTask<String> futureTask = new FutureTask<>(task); // 线程池执行 FutureTask executor.execute(futureTask); // 获取结果 String result = futureTask.get(); System.out.println("结果: " + result); executor.shutdown(); } } 相当于直接拿futureTask.get()获得结果,而不是: Future<Integer> f = executor.submit(callable); Integer result = f.get(); 动态配置(热更新) BeanPostProcessor 是 Spring 提供的一个扩展接口,用来在 Spring 容器实例化 Bean(并完成依赖注入)之后,但 在调用 Bean 的初始化方法之前或之后,对 Bean 进行额外的加工处理。 Spring 容器启动时会扫描并实例化所有实现了 BeanPostProcessor 接口的 Bean,然后在Bean 初始化阶段前后依次调用它们的 postProcessBeforeInitialization 和 postProcessAfterInitialization 方法。 postProcessAfterInitialization返回你修改之后的bean实例。 **原理:**利用 Redis 的发布/订阅(Pub/Sub)机制,在程序运行时动态推送配置变更通知,订阅者接收到消息后更新相应的 Bean 字段。通过 反射(Reflection API) 可以 动态修改运行中的对象实例的字段值。 实现步骤 注解标记 用 @DCCValue("key:default") 标注需要动态注入的字段,指定 Redis Key 和默认值。 // 标记要动态注入的字段 @Retention(RUNTIME) @Target(FIELD) public @interface DCCValue { String value(); // "key:default" } // 业务使用示例 @Service public class MyFeature { @DCCValue("myFlag:0") //标注字段,默认值为0 private String myFlag; public boolean enabled() { return "1".equals(myFlag); } } 启动时注入 代码位置:app/config 实现 BeanPostProcessor,覆写postProcessAfterInitialization方法,在每个 Spring Bean 初始化后自动执行: 扫描标注了 @DCCValue 的字段; 拼接完整 Redis Key,若 Redis 中没有配置,则写入默认值(即@DCCValue注解上的值); 通过反射将配置值注入到 Bean 的字段; 将配置与 Bean 映射关系存入本地HashMap,以便后续热更新。 @Override public Object postProcessAfterInitialization(Object bean, String name) { private final Map<String, Object> dccObjGroup = new HashMap<>(); Class<?> cls = AopUtils.isAopProxy(bean) ? AopUtils.getTargetClass(bean) : bean.getClass(); for (Field f : cls.getDeclaredFields()) { DCCValue dccValue = f.getAnnotation(DCCValue.class); if (dccValue != null) { String[] parts = dccValue.value().split(":"); String key = PREFIX + parts[0]; // Redis 中存储的 Key String defaultValue = parts[1]; // 默认值 RBucket<String> bucket = redis.getBucket(key); String value = bucket.isExists() ? bucket.get() : defaultValue; bucket.trySet(defaultValue); // 若 Redis 中无配置,则写入默认值 injectField(bean, f, value); // 通过反射注入值 dccObjGroup.put(key, bean); // 缓存配置与 Bean 映射关系 } } return bean; // 返回初始化后的 Bean } 运行时热更新 订阅一个 Redis Topic(频道),比如 "dcc_update"; 外部通过发布接口 PUBLISH dcc_update "key,newValue" 发送更新消息; private final RTopic dccTopic; @GetMapping("/dcc/update") public void update(@RequestParam String key, @RequestParam String value) { // 发布配置更新消息到 Redis 主题,格式为 "configKey,newValue" String message = key + "," + value; dccTopic.publish(message); // 通过 dccTopic 发布更新消息 log.info("配置更新发布成功 - key: {}, value: {}", key, value); } 订阅者收到后: 更新 Redis 中的配置; 从映射里取出对应 Bean,使用反射更新字段。 // 发布/订阅配置热更新 @Bean("dccTopic") public RTopic dccTopic(RedissonClient redis) { RTopic dccTopic = redis.getTopic("dcc_update"); dccTopic.addListener(String.class, (channel, msg) -> { String[] parts = msg.split(","); // msg 约定格式:"configKey,newValue" String key = PREFIX + parts[0]; // 拼接 Redis Key String newValue = parts[1]; // 新的配置值 RBucket<String> bucket = redis.getBucket(key); if (!bucket.isExists()) { return; // 如果不是我们关心的配置,跳过 } bucket.set(newValue); // 更新 Redis 中的配置 Object bean = beans.get(key); // 从内存中取出 Bean 实例 if (bean != null) { injectField(bean, parts[0], newValue); // 通过反射更新 Bean 字段 } }); return dccTopic; // 返回 Redis Topic 实例 } 在 Redis 的发布/订阅模型中,RTopic dccTopic = redis.getTopic("dcc_update"); 这行代码指定了 dccTopic 订阅的主题(也可以理解为一个消息通道)。不同的类可以通过依赖注入来使用这个 RTopic 实例。一些类可以调用 dccTopic.publish(message) 向该通道发送消息;而另一些类则可以通过 dccTopic.addListener() 来订阅该主题,从而接收消息并进行相应的处理。 面试官:为什么选择Redis Pub/Sub,不用rabbitmq? 两者都能实现这个需求,但 Redis 更轻量。在多实例部署时,每个实例都能收到广播并通过反射完成热更新;如果某个实例宕机重启,它会直接从 Redis 中拉取最新配置,而不依赖历史广播。 确实,Redis Pub/Sub 没有消息确认等可靠性机制;如果换成 RabbitMQ,配置交换机为广播模式,各实例使用匿名队列,同样可以接收消息并完成更新,而且还能提供更强的可靠性保证。不过在本项目中,动态配置中心在初期就基于 Redis 实现了,RabbitMQ 是在后期做交易领域时才引入的组件。考虑到场景对可靠性要求不高,同时也为了保持架构的简单性,所以没有替换为 RabbitMQ。 热更新数据流转过程 1.广播消息(PUBLISH):配置变更会通过 PUBLISH 命令广播到 Redis 中的某个主题。 2.Redis Sub(订阅):订阅该主题的客户端收到消息后,进行处理。 3.更新 Redis 和 Bean 字段: 更新 Redis 中的配置(保持一致性)。 更新 Bean 实例的对应字段(通过反射,确保配置的实时性)。 重要说明 RedissonClient( Redis)的作用: 1.消息广播(通过 Topic) 2.redis中的配置与bean中的字段配置一致,有一定容错 / 恢复能力,如果某个节点启动时错过了消息,它可以在初始化时直接从 Redis 读到最新配置。 HashMap的作用: 在广播监听阶段,快速获取要操作的bean实例,进行反射。 OkHttpClient+Retrofit 小型支付商城中,需要调用外部的支付宝、微信登录相关接口,使用了OkHttp + Retrofit。 1.引入依赖 <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>4.12.0</version> </dependency> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>retrofit</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>converter-jackson</artifactId> <version>2.11.0</version> </dependency> 2.配置 OkHttpClient @Configuration public class OkHttpClientConfig { @Bean public OkHttpClient okHttpClient() { return new OkHttpClient.Builder() .connectTimeout(Duration.ofSeconds(10)) .readTimeout(Duration.ofSeconds(30)) .writeTimeout(Duration.ofSeconds(30)) .retryOnConnectionFailure(true) // TODO: 可以统一加日志拦截器、鉴权拦截器 .build(); } } 单例复用:Spring 管理 Bean,整个应用只创建一次。 集中配置:超时、拦截器、SSL 等只在这里写一份,避免代码里到处 new。 3.配置Retrofit @Configuration public class RetrofitConfig { private static final String BASE_URL = "https://api.example.com/"; @Bean public Retrofit retrofit(OkHttpClient okHttpClient) { return new Retrofit.Builder() .baseUrl(BASE_URL) .client(okHttpClient) // 🔑 复用统一的 OkHttpClient .addConverterFactory(JacksonConverterFactory.create()) .build(); } @Bean public ApiService apiService(Retrofit retrofit) { return retrofit.create(ApiService.class); } } 4.定义 API 接口(Retrofit 风格) public interface ApiService { @GET("users/{id}") Call<User> getUser(@Path("id") String id); @POST("orders") Call<OrderResponse> createOrder(@Body OrderRequest request); } 5.在 Service 中调用 @Slf4j @Service @RequiredArgsConstructor public class UserService { private final ApiService apiService; // 同步请求 public User getUserById(String id) { try { Response<User> resp = apiService.getUser(id).execute(); if (resp.isSuccessful()) { return resp.body(); } throw new RuntimeException("请求失败,HTTP " + resp.code()); } catch (Exception e) { log.error("获取用户信息失败", e); throw new RuntimeException(e); } } // 异步请求 public void getUserAsync(String id) { apiService.getUser(id).enqueue(new Callback<User>() { @Override public void onResponse(Call<User> call, Response<User> response) { log.info("异步回调结果: {}", response.body()); } @Override public void onFailure(Call<User> call, Throwable t) { log.error("异步请求失败", t); } }); } } Retrofit 在运行时会生成这个接口的实现类,帮你完成: 拼 URL(把 {id} 换成具体值) 发起 GET 请求 拿到响应的 JSON 并自动反序列化成 User 对象 OkHttp 提供底层能力:连接池、超时、拦截器、HTTP/2 等,适合做全局单例配置。 特点/场景 Retrofit RPC(如 gRPC、Dubbo 等) 主要用途 封装 HTTP API 调用,集成第三方服务 微服务之间的内部通信 协议层 基于 HTTP/HTTPS(REST 风格) 基于 TCP/HTTP2,自定义协议或 Protobuf 数据序列化 JSON(默认) Protobuf / Thrift / Avro(更高效) 典型应用场景 第三方 REST API、外部服务调用 微服务架构、跨语言调用、内部高性能通信 调用方式 支持同步/异步,声明式接口 支持同步/异步、流式调用,多语言 SDK 性能特点 依赖 HTTP/JSON,序列化开销较大 高吞吐量、低延迟,序列化高效 易用性 简单,代码少,学习成本低 需要服务框架支持,学习/配置成本较高 支付宝下单沙箱 https://open.alipay.com/develop/sandbox/app 读取本地配置文件。 @Data @Component @ConfigurationProperties(prefix = "alipay", ignoreInvalidFields = true) public class AliPayConfigProperties { // 「沙箱环境」应用ID - 您的APPID,收款账号既是你的APPID对应支付宝账号。获取地址;https://open.alipay.com/develop/sandbox/app private String appId; // 「沙箱环境」商户私钥,你的PKCS8格式RSA2私钥 private String merchantPrivateKey; // 「沙箱环境」支付宝公钥 private String alipayPublicKey; // 「沙箱环境」服务器异步通知页面路径 private String notifyUrl; // 「沙箱环境」页面跳转同步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问 private String returnUrl; // 「沙箱环境」 private String gatewayUrl; // 签名方式 private String signType = "RSA2"; // 字符编码格式 private String charset = "utf-8"; // 传输格式 private String format = "json"; } 创建alipay客户端。 @Configuration public class AliPayConfig { @Bean("alipayClient") public AlipayClient alipayClient(AliPayConfigProperties properties) { return new DefaultAlipayClient(properties.getGatewayUrl(), properties.getAppId(), properties.getMerchantPrivateKey(), properties.getFormat(), properties.getCharset(), properties.getAlipayPublicKey(), properties.getSignType()); } } 公众号扫码登录流程 https://mp.weixin.qq.com/debug/cgi-bin/sandboxinfo?action=showinfo&t=sandbox/index 微信开发者平台。 微信登录时,需要调用微信提供的接口做验证,使用Retrofit 场景:用微信的能力来替你的网站做“扫码登录”或“社交登录”,代替自己写一整套帐号/密码体系。后台只需要基于 openid 做一次性关联(比如把某个微信号和你系统的用户记录挂钩),后续再次扫码就当作同一用户; 1.前端请求二维码凭证 用户点击“扫码登录”,前端向后端发 GET /api/v1/login/weixin_qrcode_ticket。 后端获取 access_token 1.先尝试从本地缓存(如 Guava Cache)读取 access_token; 2.若无或已过期,则请求微信接口: GET https://api.weixin.qq.com/cgi-bin/token ?grant_type=client_credential &appid={你的 AppID} &secret={你的 AppSecret} 微信返回 { "access_token":"ACCESS_TOKEN_VALUE", "expires_in":7200 },后端缓存这个值(有效期约 2 小时)。 后端利用 access_token 创建二维码 ticket,返给前端。(每次调用微信会返回不同的ticket) 2.前端展示二维码 前端根据 ticket 生成二维码链接:https://mp.weixin.qq.com/cgi-bin/showqrcode?ticket={ticket} 3.微信回调后端 用户确认扫描后,微信服务器向你预先配置的回调 URL(如 POST /api/v1/weixin/portal/receive)推送包含 ticket 和 openid 的消息。 后端:将 ticket → openid 存入缓存(openidToken.put(ticket, openid));调用 sendLoginTemplate(openid) 给用户推送“登录成功”模板消息(手机公众号上推送,非网页) 4.前端获知登录结果 轮询方式:生成二维码后,前端每隔几秒向后端 check_login 接口发送 ticket来验证登录状态,后端查缓存来判断 ticket 对应用户是否成功登录。 推送方式:前端通过 WebSocket/SSE 建立长连接,后端回调处理完成后直接往该连接推送登录成功及 JWT。 浏览器指纹获取登录ticket 在扫码登录流程的基础上改进!!! 目的:把「这张二维码/ticket」严格绑在发起请求的那台浏览器上,防止别的设备或会话拿到同一个 ticket 就能登录。 1.生成指纹 前端在用户打开「扫码登录页」时,先用 JS/浏览器 API(比如 User-Agent、屏幕分辨率、插件列表、Canvas 指纹等)算出一个唯一的浏览器指纹 fp。 2.获取 ticket 时携带指纹 前端发起请求: GET /api/v1/login/weixin_qrcode_ticket_scene?sceneStr=<fp> 后端执行: String ticket = loginPort.createQrCodeTicket(sceneStr); sceneTicketCache.put(sceneStr, ticket); // 把 fp→ticket 映射进缓存 3.扫码后轮询校验 前端轮询:传入 ticket 和 sceneStr 指纹 GET /api/v1/login/check_login_scene?ticket=<ticket>&sceneStr=<fp> 后端逻辑(简化): // 1) 验证拿到的 sceneStr(fp) 对应的 ticket 是否一致 String cachedTicket = sceneTicketCache.getIfPresent(sceneStr); if (!ticket.equals(cachedTicket)) { // fp 不匹配,拒绝 return NO_LOGIN; } // 2) 再看 ticket→openid 有没有被写入(扫码并回调后,saveLoginState 会写入) String openid = ticketOpenidCache.getIfPresent(ticket); if (openid != null) { // 同一浏览器,且已扫码确认,返回 openid(或 JWT) return SUCCESS(openid); } return NO_LOGIN; 4.回调时保存登录状态 当用户扫描二维码,微信会回调你预定的接口地址,拿到 ticket、openid 后,调用: ticketOpenidCache.put(ticket, openid); // 保存 ticket→openid 注意 ticketOpenidCache 和 sceneTicketCache 一般是一个Cache Bean,这里只是为了更清晰。 安全性提升 防止“票据劫持”:别人就算截获了这个 ticket,想拿去自己那台机器上轮询也不行,因为指纹对不上。 防止多人共用:多个人在不同设备上同时扫同一个码,只有最先发起获取 ticket 的那台浏览器能完成登录。 独占锁和无锁化场景(防超卖) 目标: 保证 库存数量的正确性 —— 不能出现“明明只有 10 件商品,却卖出去 11 件”的情况。 典型问题场景: 秒杀/拼团/抢购,高并发请求瞬间打到库存。 多个并发事务都认为“库存足够”,于是都扣减成功。 独占锁 适用场景 定时任务互备 多机部署时,确保每天只有一台机器在某个时间点执行同一份任务(如数据清理、报表生成、邮件推送等)。 @Scheduled(cron = "0 0 0 * * ?") public void exec() { // 获取锁句柄,并未真正获取锁 RLock lock = redissonClient.getLock("group_buy_market_notify_job_exec"); try { //尝试获取锁 waitTime = 3:如果当前锁已经被别人持有,调用线程最多等待 3 秒去重试获取;leaseTime = 0:不设过期时间,看门狗机制 boolean isLocked = lock.tryLock(3, 0, TimeUnit.SECONDS); if (!isLocked) return; Map<String, Integer> result = tradeSettlementOrderService.execSettlementNotifyJob(); log.info("定时任务,回调通知拼团完结任务 result:{}", JSON.toJSONString(result)); } catch (Exception e) { log.error("定时任务,回调通知拼团完结任务失败", e); } finally { if (lock.isLocked() && lock.isHeldByCurrentThread()) { lock.unlock(); } } } 无锁化并发控制(法一) 目标:在万级并发下保证 不超卖、可退单补量、团长也算库存,且不引入 JVM 级互斥锁。 角色 Redis Key 含义 变化方式 计数器 teamOccupiedStockKey 已占用名额(仅团员) INCR 退单补量 recoveryTeamStockKey 退回名额(累加) 退单环节 INCRBY 配额上限 target 团长 + 团员 的最大名额 配置 1. Lua 原子脚本 -- KEYS[1] = teamOccupiedStockKey -- ARGV[1] = target(含团长) -- ARGV[2] = recoveryCount local limit = tonumber(ARGV[1]) + tonumber(ARGV[2]) local v = redis.call('INCR', KEYS[1]) + 1 -- +1 把团长补进去 if v > limit then redis.call('DECR', KEYS[1]) -- 回滚 return 0 -- 告诉调用方名额已满 else return v -- 抢到的序号(含团长) end 原子性:INCR → 判断 → DECR 全在一条脚本里,Redis 单线程保证不会被并发打断。 +1 偏移:计数器只统计团员,每次 +1 把团长补进去,对比对象与 target 同维度。(redis中的teamOccupiedStockKey的值比真实锁单量少1,是正常的,因为redis中只存了团员的锁单,团长是在代码逻辑中手动+1的) 退单补量:limit = target + recoveryCount,退单线程把名额写回 recoveryTeamStockKey 后,下一次抢单自然放量。 无锁化并发控制(法二) @Override public boolean occupyTeamStock(String teamOccupiedStockKey, String recoveryTeamStockKey, Integer target, Integer validTime) { // 获取失败恢复量 Long recoveryCount = redisService.getAtomicLong(recoveryTeamStockKey); recoveryCount = null == recoveryCount ? 0 : recoveryCount; // 1. incr 得到值,与总量和恢复量做对比。恢复量为系统失败时候记录的量。 // 2. 从有组队量开始,相当于已经有了一个占用量,所以要 +1,因为团长开团的时候teamid为null,但事实上锁单已经有一单了。 long occupy = redisService.incr(teamOccupiedStockKey) + 1; //取teamOccupiedStockKey的值,先自增,再返回;类似++i if (occupy > target + recoveryCount) { repository.recoveryTeamStock(recoveryTeamStockKey); return false; } // 1. 给每个产生的值加锁为兜底设计,虽然incr操作是原子的,基本不会产生一样的值。但在实际生产中,遇到过集群的运维配置问题,以及业务运营配置数据问题,导致incr得到的值相同。 // 2. validTime + 60分钟,是一个延后时间的设计,让数据保留时间稍微长一些,便于排查问题。 String lockKey = teamOccupiedStockKey + Constants.UNDERLINE + occupy; Boolean lock = redisService.setNx(lockKey, validTime + 60, TimeUnit.MINUTES); if (!lock) { log.info("组队库存加锁失败 {}", lockKey); } return lock; } 这里teamOccupiedStockKey 和recoveryTeamStockKey 都是只增不减的,如果抢占失败的,直接对recoveryTeamStockKey+1。 recoveryTeamStockKey 还有通过参与拼团的人退单来+1 为什么对teamOccupiedStockKey-1 必须要用Lua脚本? long occupy = redisService.incr(teamOccupiedStockKey); if (occupy > target + recoveryCount) { redisService.decr(teamOccupiedStockKey); // 回滚 return false; } 如果直接JAVA代码中写两个逻辑,风险在: INCR 和 DECR 是两条独立命令。 在 INCR 和 DECR 之间的时间窗口里,其他请求可能已经拿到 INCR 的结果。 多个失败请求并发执行,会出现“多次 DECR 把计数扣过头”的问题,导致库存虚减甚至超卖。 本项目采用第二种方法!!! 极端兜底锁 String lockKey = teamOccupiedStockKey + Constants.UNDERLINE + occupy; Boolean lock = redisService.setNx(lockKey, validTime + 60, TimeUnit.MINUTES); if (!lock) { log.info("组队库存加锁失败 {}", lockKey); } 解决极小概率 相同序号并发撞号 的问题( TTL 比业务 validTime 多留 60 min,方便排查。 订单关闭/失效时记得删除对应 lockKey(目的是设置了过期时间为拼团有效期+60分钟),防止 Redis 小键堆积。 怎样的情况可能导致并发撞号? t1:客户端发起 INCR,Redis 内存里变成 101,返回 101(内存里修改完成就返回,不等落盘); t1+Δ:Redis 还没把这条写刷到磁盘(AOF 还在缓冲里 / OS 还没 fsync); t2:Redis 故障崩溃 → 只剩下落盘的旧状态(100); t3:重启后加载旧数据,从 100 再开始递增 → 101(和之前用过的号重复)。 持久化粒度取决于 appendfsync 配置: always:每次写都 fsync → 最安全,最慢。 everysec(默认):每秒 fsync → 可能丢 1 秒内的数据。 no:完全交给操作系统 → 性能好,但可能丢几十秒。 本项目有三层防护: 页面/接口层校验 前端进入拼团展示页时,先查询当前拼团信息(展示“还差 X 人”)。 用户下单时调用“锁单接口”,若此时名额已满,接口直接返回“拼团组队完结”。 这一层主要是减少无效请求,但无法彻底防止并发穿透。 后端并发控制层(Redis 无锁化) Redis 原子计数:通过 INCR 原子操作,确保同一时刻的请求不会并发写入同一计数值。 补偿计数:通过 recoveryTeamStockKey 自动回收名额,防止异常锁单占用。 兜底锁(SETNX):防止极端情况下(如 Redis AOF 数据丢失后重启)出现“号段重复”。 Redis 层负责 高并发抢占的并发正确性与性能优化,让大部分请求在内存层快速失败返回。 最终防线:数据库层库存约束 Redis 只作为并发控制与削峰层,真正防止超卖的约束仍在数据库: INSERT ... WHERE lock_count < target; 面试问题:如果Redis宕机了,里面的锁单量、恢复量岂不是清零了?是否导致超卖? 答:不会导致超卖。 1.配置AOF Redis 会把每一条写命令以日志形式追加到 appendonly.aof 文件。 宕机重启时,Redis 会回放 AOF 文件里的命令,恢复到宕机前的状态。 appendfsync=always → 每次写都刷盘,几乎不丢数据,但性能略低。。 2.哨兵+主从集群 Redis 主从集群可实现自动故障切换,保证服务高可用。 虽然主从切换瞬间可能出现短暂数据不一致(最终一致性),但在同步完成后数据会恢复一致。 3.数据库层兜底约束 “Redis 掉了不会导致超卖,因为它只是瞬时控制层,最终库存是由数据库和恢复机制兜底的。” INSERT ... WHERE lock_count < target; 生活例子理解 假设你有一个限量商品,每个商品有一个唯一的编号,假设这些商品编号为 1、2、3、4、5(总共 5 个)。这些商品被分配给用户,每个用户会抢一个编号。每个用户成功抢到一个商品后,系统会在库存中占用一个编号。 抢购过程: 有 5 个商品编号(1-5),这些编号是库存量。 每个用户请求一个商品编号,系统会给用户分配一个编号(这个过程就像是自增占用量的过程)。 如果用户请求的编号超过了现有库存的最大编号(5),则说明没有商品可以分配给该用户,用户抢购失败。 如果有多个用户抢同一个编号(例如都想抢到编号 1 的商品),系统通过“分布式锁”来保证只有一个用户能成功抢到编号 1,其他用户则失败。 缓存Supplier<T> Supplier<T> 是 Java 8 提供的一个函数式接口 @FunctionalInterface public interface Supplier<T> { /** * 返回一个 T 类型的结果,参数为空 */ T get(); } 任何“无参返回一个 T 类型对象”的代码片段(方法引用或 lambda)都可以当成 Supplier<T> 来用。 作用 1.延迟执行 把“取数据库数据”这类开销大的操作,包装成 Supplier<T> 传进去;只有真正需要时(缓存未命中),才触发执行。 // 缓存未命中时,才调用 supplier.get() 执行数据库查询 T dbResult = dataFetcher.get(); 2.解耦逻辑 缓存组件不关心数据如何获取,只负责缓存策略;调用方通过 Supplier提供数据获取逻辑。 public <T> T getFromCacheOrDb(String key, Supplier<T> dataFetcher) { ... } 3.重用性高 同一个缓存-回源模板方法可以服务于任何返回 T 的场景,既可以查 User,也可以查 Order、List<Product>…… // 查询用户 User user = getFromCacheOrDb("user:123", () -> userDao.findById(123)); // 查询订单列表 List<Order> orders = getFromCacheOrDb("orders:456", () -> orderDao.listByUserId(456)); dataFetcher.get() → userDao.findById(123) 分布式限流(AOP + Redisson 实现)+黑名单 核心思路 动态开关管理 使用 @DCCValue("rateLimiterSwitch:open") 从配置中心动态注入全局开关,支持热更新。 当开关为 "close" 时,直接放行所有请求,切面不再执行限流逻辑。 AOP 切面拦截 通过自定义注解 @RateLimiterAccessInterceptor 标记需要限流的方法。 注解参数 key 用于指定限流维度(如 userId 表示按用户限流,all 表示全局限流)。 切面在运行时解析这个字段的值,动态生成 Redis 限流器 Key,例如: //添加拦截注解 @RateLimiterAccessInterceptor(key = "userId", permitsPerSecond = 5, fallbackMethod = "fallback") public void order(String userId) {...} 请求1: userId=U12345 → Redis Key: rl:limiter:U12345 请求2: userId=U67890 → Redis Key: rl:limiter:U67890 反射的应用: 获取限流维度 Key(如 userId) 切面会从方法参数对象中反射查找 userId字段: private String extractField(Object obj, String name) { Field field = getFieldByName(obj, name); field.setAccessible(true); Object v = field.get(obj); return v != null ? v.toString() : null; } 调用降级方法 当请求被限流或进入黑名单时,切面会通过反射执行注解里指定的 fallbackMethod: Method method = jp.getTarget().getClass() .getMethod(fallbackMethod, ms.getParameterTypes()); return method.invoke(jp.getTarget(), jp.getArgs()); 限流与黑名单 使用 RRateLimiter 实现分布式令牌桶,每秒放入 permitsPerSecond 个令牌。 取不到令牌时: 如果配置了 blacklistCount,用 RAtomicLong 记录该 Key 的拒绝次数; 拒绝次数超限后,将 Key 加入黑名单 24 小时。(rl:bl:keyAttr 中存放着24小时内该用户超限次数,如果大于blacklistCount,则黑名单启动拦截;而不是指某个rl:bl:keyAttr 存在就拦截,还是要比较次数的!) 命中黑名单或限流时,调用注解里的 fallbackMethod 执行降级逻辑。 注意这里有两个key: rl:bl:keyAttr ,设置了24小时的过期时间,里面存着24小时内xx用户超限的次数。 rl:limiter:keyAttr 未设置过期时间(xx用户随时来,随时限流) 令牌桶算法(Token Bucket) 工作原理:按固定速率往桶里放“令牌”(tokens),例如每秒放 N 个。每次请求到达时,必须先从桶中“取一个令牌”,才能通过;如果取不到,则拒绝或降级。 特点:支持流量平滑释放和突发流量吸纳,桶最多能存储 M 个令牌。 方法调用 ↓ AOP 切面拦截(匹配 @RateLimiterAccessInterceptor) ↓ 检查全局限流开关(@DCCValue 注入) ↓ 解析注解里的 key → 获取对应参数值(如 userId) ↓ 黑名单检查(RAtomicLong) ↓ 分布式令牌桶限流(RRateLimiter.tryAcquire) ↓ ├─ 成功 → 执行目标方法 └─ 失败 → 累加拒绝计数 & 调用 fallbackMethod 对比维度 本地限流 分布式限流 实现复杂度 低:直接用 Guava RateLimiter,几行代码即可接入 中高:依赖 Redis/Redisson,需要注入客户端并管理限流器 性能开销 极低:全程内存操作,纳秒级延迟 中等:每次获取令牌需网络往返,存在 RTT 延迟 限流范围 单实例:仅对当前 JVM 有效,多实例互不影响 全局:多实例共享同一套令牌桶,合计速率可控 状态持久化 & 容错 无:服务重启后状态丢失;实例宕机只影响自身 有:Redis 存储限流器与黑名单,可持久化;需保证 Redis 可用性 目前本项目采用 分布式限流,使用 Redisson 实现跨实例令牌桶,确保全局限流控制。 防止重复下单 目标: 确保同一用户在同一业务维度(如一个拼团活动、一个商品、一次支付流程)下,无论请求多少次,都只生成一条有效订单。 典型问题场景: 用户在页面疯狂点击“立即购买”; 网络延迟导致重复提交; 用户恶意构造多条请求。 一、整体思路 核心目标:实现幂等性(Idempotency) 对于同一个操作的重复请求,系统只执行一次,结果一致、返回同一订单号。 层级 方案 作用 前端 按钮禁用 / loading 状态 阻止多次点击 服务端 幂等 Key + 唯一索引 数据层防重 可选 Redis 分布式锁 并发控制(防止短时间内重复插入) 二、实现幂等性 1)生成幂等 Key 前端生成:调用 /api/idempotency-key,由后端生成唯一 ID(UUID / 雪花算法); 外部系统传入:使用外部交易号(如 out_trade_no)作为幂等 key。 原则:幂等 Key 必须唯一且可复用(同一业务场景同一 key,重复请求仍返回同一结果)。 请求下单接口 /create_order 时,前端需携带该 Key。 2)数据库唯一约束(核心防重机制) 给幂等 Key 添加唯一索引 ALTER TABLE orders ADD UNIQUE KEY uniq_idempotent (idempotency_key); 3)数据库原子插入(推荐写法) INSERT INTO orders (user_id, idempotency_key, ...) VALUES (:uid, :key, ...) ON DUPLICATE KEY UPDATE id = LAST_INSERT_ID(id); SELECT LAST_INSERT_ID() AS order_id; 客户端连接 Session #1 ────────────────────────────────────────────── SQL1: INSERT INTO orders (...) VALUES (...) ON DUPLICATE KEY UPDATE id = LAST_INSERT_ID(id); MySQL 内部执行: ┌─检测唯一键冲突───────────────┐ │ 若无冲突 → 插入 → 设置 last_insert_id = 新id │ │ 若冲突 → 更新 → 设置 last_insert_id = 原id │ └──────────────────────────┘ SQL2: SELECT LAST_INSERT_ID() AS order_id; → 返回上一步中设置的 last_insert_id(无论是插入的还是更新的) MySQL 内部保证原子性: 要么插入,要么更新 → 不存在竞态条件。 4)Redis 分布式锁(可选层) 针对高并发下同一 Key 的同时提交,可使用 Redis 锁: String lockKey = "order:submit:" + idempotencyKey; if (tryLock(lockKey, 5s)) { // 查是否已存在 // 不存在则创建订单 } else { return "重复请求"; } 锁仅控制短期并发,幂等仍由数据库唯一索引兜底。 三、为什么不建议“先查后插”或"先插后查" -- 1. 尝试插入 INSERT INTO orders (user_id, idempotency_key, ...) VALUES (:uid, :key, ...); -- 2. 如果影响行数 == 0,则说明冲突了(存在了) -- 3. 再去查询 SELECT id FROM orders WHERE idempotency_key = :key; 在并发下存在竞态: 顺序 线程 A 线程 B 1 插入成功 插入冲突失败 2 – 立即查询时可能读到别的线程刚写入的数据 → 数据不一致、逻辑混乱。 ✅ 推荐:使用 ON DUPLICATE KEY 让 MySQL 原子处理。 企业做法:幂等 Key + 状态表 维护一个专门的幂等控制表(order_request) 记录「请求级别」的信息,主要用来判断:这个幂等 key(一次下单操作)是不是已经被处理过。 CREATE TABLE idempotent_record ( id BIGINT AUTO_INCREMENT PRIMARY KEY, biz_type VARCHAR(32), -- 业务类型: order/pay/refund/notify idempotency_key VARCHAR(64) UNIQUE, biz_id BIGINT, -- 对应业务主键 status ENUM('PROCESSING','SUCCESS','FAILED'), error_msg VARCHAR(255), created_at DATETIME ); 可以把这张幂等表理解成一个「防火墙」或「中间登记簿」: 每一个请求先“登记”; 若登记成功,说明是第一次进入 → 允许创建订单; 若登记失败(重复 key) → 直接查记录返回原订单。 为什么要单独维护这张表? 原因 说明 ✅ 控制层和业务层解耦 幂等控制独立,不污染订单表结构 ✅ 通用性强 同一个机制可复用在「支付、退款、回调」等接口 RPC微服务调用 RPC(Remote Procedure Call,远程过程调用) 就像调用本地方法一样调用远程服务的方法。 框架(Dubbo、gRPC、Thrift 等)会帮你处理 动态代理、序列化、网络通信、连接管理、负载均衡 等细节。 开发者只需要写接口 + 实现类,调用方直接调用接口,RPC 框架在背后“悄悄”完成远程调用。 实现步骤 1.父Pom统一版本 <!-- 统一锁版本,避免不同模块写不同小版本 --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-bom</artifactId> <version>3.3.5</version> <type>pom</type> <scope>import</scope> </dependency> 2.pay-mall-infrustruct(Consumer)group-buying-sys-trigger (Provider)引入依赖 <dependencies> <!-- Dubbo 核心 + Spring Boot 自动装配 --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> </dependency> <!-- Nacos 注册中心扩展 --> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-registry-nacos</artifactId> </dependency> </dependencies> 3.部署nacos(详见微服务笔记) 4.配置注册(消费者、生产者都要配) dubbo: application: name: group-buy-market-service # 换成各自服务名 registry: address: nacos://localhost:8848 # 远程环境写内网地址 # username/password 如果 Nacos 开了鉴权 protocol: name: dubbo port: 20880 # 生产者开放端口;消费者可不写 consumer: timeout: 3000 # 毫秒 check: false # 忽略启动时服务是否可用 5.开启 Dubbo 注解扫描 在消费者、生产者的主启动类上加,设置正确的包名,让 @DubboService 和 @DubboReference 被 Spring+Dubbo 识别和处理 @SpringBootApplication @EnableDubbo(scanBasePackages = "edu.whut") public class Application { … } 6.在Dubbo RPC调用中,DTO对象需要在网络中进行传输,因此它们必须实现 java.io.Serializable 接口: /** * 用户信息请求对象 */ @Data public class UserRequestDTO implements Serializable { // 实现 Serializable private static final long serialVersionUID = 1L; // 添加 serialVersionUID,用于版本控制 // 用户ID private String userId; // 用户名 private String userName; // 邮箱 private String email; } 7.定义服务接口: 服务接口定义了服务提供者能够提供的功能以及服务消费者能够调用的方法。这个接口必须是公共的,并且通常放置在一个独立的 api模块中。供服务提供者和消费者共同依赖。 /** * 用户服务接口 */ public interface IUserService { /** * 根据用户ID获取用户信息 * @param requestDTO 用户请求对象 * @return 用户响应对象 */ UserResponseDTO getUserInfo(UserRequestDTO requestDTO); /** * 创建新用户 * @param requestDTO 用户请求对象 * @return 操作结果 */ String createUser(UserRequestDTO requestDTO); } 8.服务提供者 (Provider) 实现并暴露服务 在服务提供者应用中,实现上述定义的服务接口,并使用 @DubboService 注解将其暴露为Dubbo服务。可以放在trigger/rec包下。 /** * 用户服务实现类 */ @DubboService(version = "1.0.0", group = "user-service") // 关键注解:暴露Dubbo服务 @Service // 也可以同时是Spring的Service public class UserServiceImpl implements IUserService { @Override public UserResponseDTO getUserInfo(UserRequestDTO requestDTO) { System.out.println("收到获取用户信息的请求: " + requestDTO.getUserId()); // 模拟业务逻辑 UserResponseDTO response = new UserResponseDTO(); response.setUserId(requestDTO.getUserId()); response.setUserName("TestUser_" + requestDTO.getUserId()); response.setEmail("test_" + requestDTO.getUserId() + "@example.com"); return response; } @Override public String createUser(UserRequestDTO requestDTO) { System.out.println("收到创建用户的请求: " + requestDTO.getUserName()); // 模拟业务逻辑 return "User " + requestDTO.getUserName() + " created successfully."; } } 9.服务消费者 (Consumer) 引用远程服务 在服务消费者应用中,通过 @DubboReference 注解引用远程Dubbo服务。Dubbo 会自动通过注册中心查找并注入对应的服务代理。 /** * 用户API控制器 */ @RestController public class UserController { @DubboReference(version = "1.0.0", group = "user-service") // 关键注解:引用Dubbo服务 private IUserService userService; @GetMapping("/user/info") public UserResponseDTO getUserInfo(@RequestParam String userId) { UserRequestDTO request = new UserRequestDTO(); request.setUserId(userId); return userService.getUserInfo(request); } @GetMapping("/user/create") public String createUser(@RequestParam String userName, @RequestParam String email) { UserRequestDTO request = new UserRequestDTO(); request.setUserName(userName); request.setEmail(email); return userService.createUser(request); } } RPC:同步调用、强一致、快速响应,比如pay-mall调用拼团系统的拼团交易锁单 、营销结算、营销拼团退单 HTTP:本系统调用微信支付这种第三方接口。 MQ:异步解耦、削峰填谷、最终一致性,比如退单消息,pay-mall调用营销拼团退单接口后,将订单设置为'待退单状态',然后拼团系统退单完成后发送'退单完成'消息,pay-mall接收继续做最终的退单处理。 怎么确保这个微服务调用的可靠性? 如果小型支付商城调用拼团失败,有两种情况: 1.网络异常、超时,dubbo框架会抛一个异常,可以特别处理,对其进行重试,设置最大重试次数,以及指数退避算法;这里要求锁单做幂等校验! 2.业务异常,不重试,可能是因为用户参与次数已达上限、活动过期之类的。 日志系统 输出流向一览 输出到3个地方:控制台、本地文件、ELK日志(服务器上内存不足无法部署!) 日志级别 控制台 本地文件(异步) Logstash (TCP) TRACE/DEBUG — — — INFO ✔ log_info.log ✔ WARN ✔ log_info.log``log_error.log ✔ ERROR/FATAL ✔ log_info.log``log_error.log ✔ 注意:实际写文件时,都是通过 ASYNC_FILE_INFO/ERROR 两个异步 Appender 执行,以免日志写盘阻塞业务线程。 ELK日志系统 本地文件每台机器都会在自己 /data/log/... 目录下滚动输出自己的日志,互相之间不会合并。 如果你希望跨多台服务器统一管理,就需要把日志推到中央端——ELK日志系统 ELK=Elasticsearch(存储&检索)+ Logstash(采集&处理)+ Kibana(可视化) docker-compose.yml: version: '3' services: elasticsearch: image: elasticsearch:7.17.28 ports: ['9201:9200','9300:9300'] environment: - discovery.type=single-node - ES_JAVA_OPTS=-Xms512m -Xmx512m volumes: - ./data:/usr/share/elasticsearch/data logstash: image: logstash:7.17.28 ports: ['4560:4560','9600:9600'] volumes: - ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf environment: - LS_JAVA_OPTS=-Xms1g -Xmx1g kibana: image: kibana:7.17.28 ports: ['5601:5601'] environment: - elasticsearch.hosts=http://elasticsearch:9200 networks: default: driver: bridge kibana配置: # # ** THIS IS AN AUTO-GENERATED FILE ** # # Default Kibana configuration for docker target server.host: "0" server.shutdownTimeout: "5s" elasticsearch.hosts: [ "http://elasticsearch:9200" ] # 记得修改ip monitoring.ui.container.elasticsearch.enabled: true i18n.locale: "zh-CN" logstash配置: input { tcp { mode => "server" host => "0.0.0.0" port => 4560 codec => json_lines type => "info" } } filter {} output { elasticsearch { action => "index" hosts => "es:9200" index => "group-buy-market-log-%{+YYYY.MM.dd}" } } 自己的项目: <!-- 上报日志;ELK --> <springProperty name="LOG_STASH_HOST" scope="context" source="logstash.host" defaultValue="127.0.0.1"/> <!--输出到logstash的appender--> <appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <!--可以访问的logstash日志收集端口--> <destination>${LOG_STASH_HOST}:4560</destination> <encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>7.3</version> </dependency> 使用 检查索引:curl http://localhost:9201/_cat/indices?v3 打开 Kibana:浏览器访问 http://localhost:5601,新建 索引模式(如 app-log-*),即可在 Discover/Visualize 中查看与分析日志。
项目
zy123
1年前
0
41
1
上一页
1
2
3
4
...
12
下一页