首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
40 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
推荐文章
推荐
拼团设计模式
项目
1年前
0
12
0
推荐
拼团交易系统
项目
1年前
0
41
1
推荐
Smile云图库
项目
1年前
0
60
0
热门文章
146 ℃
同步本地Markdown至Typecho站点
项目
1年前
0
146
0
47 ℃
微服务
后端学习
1年前
0
47
0
43 ℃
苍穹外卖
项目
1年前
0
43
0
最新发布
2025-03-21
anaconda基础命令
Anaconda基础命令 cuda版本 12.3.1 驱动版本 546.26 打开anaconda prompt(普通命令行cmd也可以): 查看版本和环境 conda -V 查看版本 conda env list 查看已安装的环境 *代表当前环境 环境管理 conda create -n 新环境名字 python=3.7 (若只有python则下载最新版python) conda activate 新环境名字 可以切换环境 conda deactivate 退出环境到base conda remove -n 新环境名字 --all 删除创建的环境(先deactivate退出) 包管理 注:包管理操作前请先激活目标环境。 conda list 列出当前环境所安装的包 conda search numpy 可以查看numpy有哪些版本 conda install numpy 可以指定版本,默认最新版 pip install -r requirements.txt (使用 pip 安装依赖包列表) conda remove numpy 删除numpy以及所有依赖关系的包 查看激活的环境的python版本 python --version 结合 PyCharm 使用 conda 环境 在 conda 中创建好虚拟环境 如上文所示,使用 conda create -n 新环境名字 python=版本 创建。 在 PyCharm 中使用已有的 conda 环境 打开 PyCharm,进入 File > Settings > Project: YourProject > Python Interpreter 点击右侧的 Show All,可以看到 PyCharm 已经检测到的所有解释器。 若没有显示目标 conda 环境,可以点击右侧的加号(+)添加现有 conda 环境作为解释器。 这是添加conda镜像 conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/mysys2/ conda config --set show_channel_urls yes 这是添加Pypi镜像,适用于pip安装 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:https://mirrors.aliyun.com/pypi/simple/ 中国科技大学: https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:https://pypi.hustunique.com/ 山东理工大学:https://pypi.sdutlinux.org/ 豆瓣:https://pypi.douban.com/simple/ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 在conda中导出pip requirements.txt: pip freeze > requirements.txt Conda环境与Pycharm环境的大坑 如果你的pycharm中使用conda环境,那么你在pycharm的终端中所用的可能不是conda环境! 解决办法: shell path改为 cmd.exe 这样虚拟环境就默认设置为conda环境了 如果命令行cd到项目根目录,所用的也并不是conda环境!这里用的是conda的默认环境? 正确方法: 1.使用anaconda prompt打开 2.conda activate env 激活环境 3.cd到项目根目录 4.输入命令
杂项
zy123
1年前
0
6
0
2025-03-21
招标文件解析
产品官网:智标领航 - 招投标AI解决方案 产品后台:xxx 项目地址:xxx git clone地址:xxx 选择develop分支,develop-xx 后面的xx越近越新。 正式环境:xxx 测试环境:xxx 大解析:指从招标文件解析入口进去,upload.py 小解析:从投标文件生成入口进去,little_zbparse 和get_deviation,两个接口后端一起调 项目启动与维护: .env存放一些密钥(大模型、textin等),它是gitignore忽略了,因此在服务器上git pull项目的时候,这个文件不会更新(因为密钥比较重要),需要手动维护服务器相应位置的.env。 如何更新服务器上的版本: 步骤 进入项目文件夹 **注意:**需要确认.env是否存在在服务器,默认是隐藏的 输入cat .env 如果不存在,在项目文件夹下sudo vim .env 将密钥粘贴进去!!! git pull sudo docker-compose up --build -d 更新并重启 或者 sudo docker-compose build 先构建镜像 sudo docker-compose up -d 等空间时再重启 sudo docker-compose logs flask_app --since 1h 查看最近1h的日志(如果重启后报错也能查看,推荐重启后都运行一下这个) requirements.txt一般无需变动,除非代码中使用了新的库,也要手动在该文件中添加包名及对应的版本 docker基础知识 docker-compose: 本项目为单服务项目,只有flask_app(服务名) build context(context: .): 这是在构建镜像时提供给 Docker 的文件集,指明哪些文件可以被 Dockerfile 中的 COPY 或 ADD 指令使用。它是构建过程中的“资源包”。 对于多服务,build下就要针对不同的服务,指定所需的“资源包”和对应的Dockerfile dockerfile: COPY . .(在 Dockerfile 中): 这条指令会将构建上下文中的所有内容复制到镜像中的当前工作目录(这里是 /flask_project)。 docker exec -it zbparse-flask_app-1 sh 这个命令会直接进入到flask_project目录内部ls之后可以看到: Dockerfile README.md docker-compose.yml flask_app md_files requirements.txt 如果这个基础上再cd /会切换到这个容器的根目录,可以看到flask_project文件夹以及其他基础系统环境。如: bin boot dev etc flask_project home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var 数据卷挂载: volumes: -/home/Z/zbparse_output_dev:/flask_project/flask_app/static/output # 额外的数据卷挂载 本地路径:容器内路径 都从根目录找起。 完整的容器名 <项目名>-<服务名>-<序号> 项目名:默认是当前目录的名称(这里是 zbparse),或者你在启动 Docker Compose 时通过 -p 参数指定的项目名称。 服务名:在 docker-compose.yml 文件中定义的服务名称(这里是 flask_app)。 序号:如果同一个服务启动了多个容器,会有数字序号来区分(这里是 1)。 docker-compose exec flask_app sh docker exec -it zbparse-flask_app-1 sh 这两个是等价的,因为docker-compose 会自动找到对应的完整容器名并执行命令。 删除所有悬空镜像(无容器引用的 <none> 镜像) docker image prune 如何本地启动本项目: Pycharm启动 requirements.txt里的环境要配好 conda create -n zbparse python=3.8 conda activate zbparse pip install -r requirements.txt .env环境配好 (一般不需要在电脑环境变量中额外配置了,但是要在Pycharm中安装插件,使得项目在启动时能将env中的环境变量自动配置到系统环境变量中!!!) 点击下拉框,Edit configurations 设置run_serve.py为启动脚本 注意这里的working directory要设置到最外层文件夹,而不是flask_app!!! 命令行启动 1.编写ps1脚本 # 切换到指定目录 cd D:\PycharmProjects\zbparse # 激活 Conda 环境 conda activate zbparse # 检查是否存在 .env 文件 if (Test-Path .env) { # 读取 .env 文件并设置环境变量 Get-Content .env | ForEach-Object { if ($_ -match '^\s*([^=]+)=(.*)') { $name = $matches[1].Trim() $value = $matches[2].Trim() [System.Environment]::SetEnvironmentVariable($name, $value) } } } else { Write-Host ".env not find" } # 设置 PYTHONPATH 环境变量 $env:PYTHONPATH = "D:\flask_project" # 运行 Python 脚本 python flask_app\run_serve.py $env:PYTHONPATH = "D:\flask_project",告诉 Python 去 D:\flask_project 查找模块,这样就能让 Python 找到你的 flask_app 包。 2.确保conda已添加到系统环境变量 打开 Anaconda Prompt,然后输入 where conda 来查看 conda 的路径。 打开系统环境变量Path,添加一条:C:\ProgramData\anaconda3\condabin 或者 CMD 中 set PATH=%PATH%;新添加的路径 重启终端可以刷新环境变量 3.如果你尚未在 PowerShell 中初始化 conda,可以在 Anaconda Prompt 中运行: conda init powershell 4.进入到存放run.ps1文件的目录,在搜索栏中输入powershell 5.默认情况下,PowerShell 可能会阻止运行脚本。你可以调整执行策略: Set-ExecutionPolicy RemoteSigned -Scope CurrentUser 6.运行脚本 .\run.ps1 注意!!! Windows 控制台存在QuickEdit 模式,在 QuickEdit 模式下,当你在终端窗口中点击(尤其是拖动或选中内容)时,控制台会进入文本选择状态,从而暂停正在运行的程序!! 禁用 QuickEdit 模式 在 PowerShell 窗口标题栏上点击右键,选择“属性”。 在“选项”选项卡中,取消勾选“快速编辑模式”。 点击“确定”,重启 PowerShell 窗口后再试。 模拟用户请求 postman打post请求测试: http://127.0.0.1:5000/upload body: { "file_url":"xxxx", "zb_type":2 } file_url如何获取:OSS管理控制台 bid-assistance/test 里面找个文件的url,推荐'094定稿-湖北工业大学xxx' 注意这里的url地址有时效性,要经常重新获取新的url 清理服务器上的文件夹 1.编写shell文件,sudo vim clean_dir.sh 清理/home/Z/zbparse_output_dev下的output1这些二级目录下的c8d2140d-9e9a-4a49-9a30-b53ba565db56这种uuid的三级目录(只保留最近7天)。 #!/bin/bash # 需要清理的 output 目录路径 ROOT_DIR="/home/Z/zbparse_output_dev" # 检查目标目录是否存在 if [ ! -d "$ROOT_DIR" ]; then echo "目录 $ROOT_DIR 不存在!" exit 1 fi echo "开始清理 $ROOT_DIR 下超过 7 天的目录..." echo "以下目录将被删除:" # -mindepth 2 表示从第二层目录开始查找,防止删除 output 下的直接子目录(如 output1、output2) # -depth 采用深度优先遍历,确保先处理子目录再处理父目录 find "$ROOT_DIR" -mindepth 2 -depth -type d -mtime +7 -print -exec rm -rf {} \; echo "清理完成。" 2.添加权限。 sudo chmod +x ./clean_dir.sh 3.执行 sudo ./clean_dir.sh 以 root 用户的身份编辑 crontab 文件,从而设置或修改系统定时任务(cron jobs)。每天零点10分清理 sudo crontab -e 在里面添加: 10 0 * * * /home/Z/clean_dir.sh 目前测试服务器和正式服务器都写上了!无需变动 内存泄漏问题 问题定位 查看容器运行时占用的文件FD套接字FD等(排查内存泄漏,长期运行这三个值不会很大) [Z@iZbp13rxxvm0y7yz7l02hbZ zbparse]$ docker exec -it zbparse-flask_app-1 sh ls -l /proc/1/fd | awk ' BEGIN { file=0; socket=0; pipe=0; other=0 } { if(/socket:/) socket++ else if(/pipe:/) pipe++ else if(/\/|tmp/) file++ # 识别文件路径特征 else other++ } END { print "文件FD:", file print "套接字FD:", socket print "管道FD:", pipe print "其他FD:", other }' 可以发现文件FD很大,基本上发送一个请求文件FD就加一,且不会衰减: 经排查,@validate_and_setup_logger注解会为每次请求都创建一个logger,需要在@app.teardown_request中获取与本次请求有关的logger并释放。 def create_logger(app, subfolder): """ 创建一个唯一的 logger 和对应的输出文件夹。 参数: subfolder (str): 子文件夹名称,如 'output1', 'output2', 'output3' """ unique_id = str(uuid.uuid4()) g.unique_id = unique_id output_folder = os.path.join("flask_app", "static", "output", subfolder, unique_id) os.makedirs(output_folder, exist_ok=True) log_filename = "log.txt" log_path = os.path.join(output_folder, log_filename) logger = logging.getLogger(unique_id) if not logger.handlers: file_handler = logging.FileHandler(log_path) file_formatter = CSTFormatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') file_handler.setFormatter(file_formatter) logger.addHandler(file_handler) stream_handler = logging.StreamHandler() stream_handler.setFormatter(logging.Formatter('%(message)s')) logger.addHandler(stream_handler) logger.setLevel(logging.INFO) logger.propagate = False g.logger = logger g.output_folder = output_folder #输出文件夹路径 handler:每当 logger 生成一条日志信息时,这条信息会被传递给所有关联的 handler,由 handler 决定如何输出这条日志。例如,FileHandler 会把日志写入文件,而 StreamHandler 会将日志输出到控制台。 logger.setLevel(logging.INFO) :它设置了 logger 的日志级别阈值。Logger 只会处理大于或等于 INFO 级别的日志消息(例如 INFO、WARNING、ERROR、CRITICAL),而 DEBUG 级别的消息会被忽略。 解决这个文件句柄问题后内存泄漏仍未解决,考虑分模块排查。 本项目结构大致是**1.**预处理(文件读取切分) **2.**并发调用5个函数分别调用大模型获取结果。 因此排查思路: 先将预处理模块单独拎出来作为接口,上传文件测试。 文件一般几MB,首先会读到内存,再处理,必然会占用很多内存,且它是调用每个接口都会经历的环节(little_zbparse/upload等) 内存泄漏排查工具 pip install memory_profiler from memory_profiler import memory_usage import time @profile def my_function(): a = [i for i in range(100000)] time.sleep(1) # 模拟耗时操作 b = {i: i*i for i in range(100000)} time.sleep(1) return a, b # 监控函数“运行前”和“运行后”的内存快照 mem_before = memory_usage()[0] result=my_function() mem_after = memory_usage()[0] print(f"Memory before: {mem_before} MiB, Memory after: {mem_after} MiB") @profile注解加在函数上,可以逐行分析内存增减情况。 memory_usage()[0] 可以获取当前程序所占内存的快照 产生的数据都存到result变量-》内存中,这是正常的,因此my_function没有内存泄漏问题。 但是 @profile def extract_text_by_page(file_path): result = "" with open(file_path, 'rb') as file: reader =PdfReader(file) num_pages = len(reader.pages) # print(f"Total pages: {num_pages}") for page_num in range(num_pages): page = reader.pages[page_num] text = page.extract_text() return "" 可以发现尽管我返回"",内存仍然没有释放!因为就是读取pdf这块发生了内存泄漏! tracemalloc def extract_text_by_page(file_path): result = "" with open(file_path, 'rb') as file: reader =PdfReader(file) num_pages = len(reader.pages) # print(f"Total pages: {num_pages}") for page_num in range(num_pages): page = reader.pages[page_num] text = page.extract_text() return result # 开始跟踪内存分配 tracemalloc.start() # 捕捉函数调用前的内存快照 snapshot_before = tracemalloc.take_snapshot() # 调用函数 file_path=r'C:\Users\Administrator\Desktop\fsdownload\00550cfc-fd33-469e-8272-9215291b175c\ztbfile.pdf' result = extract_text_by_page(file_path) # 捕捉函数调用后的内存快照 snapshot_after = tracemalloc.take_snapshot() # 比较两个快照,获取内存分配差异信息 stats = snapshot_after.compare_to(snapshot_before, 'lineno') print("[ Top 10 内存变化 ]") for stat in stats[:10]: print(stat) # 停止内存分配跟踪 tracemalloc.stop() tracemalloc能更深入的分析,不仅是自己写的代码,调用的库函数产生的内存也能分析出来。在这个例子中就是PyPDF2中的各个函数占用了大部分内存。 综上,定位到问题,就是读取PDF,使用PyPDF2库的地方 如何解决: 首先尝试用with open打开文件,代替直接使用 reader =PdfReader(file_path) 能够确保文件正常关闭。但是没有效果。 考虑为每次请求开子进程处理,有效隔离内存泄漏导致的资源占用,这样子进程运行结束后会释放资源。 但是解析流程是流式/分段返回的,因此还需处理: _child_target 是一个“桥梁”: 它在子进程内调用 goods_bid_main(...) (你的生成器) 并把每一次 yield 得到的数据放进队列。 结束时放一个 None 表示没有更多数据。 run_in_subprocess 是主进程使用的接口,开启子进程: 它启动子进程并实时 get() 队列数据,然后 yield 给外界调用者。 当队列里读到 None,说明子进程运行完毕,就 break 循环并 p.join()。 main_func是真正执行的函数!!! def _child_target(main_func, queue, output_folder, file_path, file_type, unique_id): """ 子进程中调用 `main_func`(它是一个生成器函数), 将其 yield 出的数据逐条放进队列,最后放一个 None 表示结束。 """ try: for data in main_func(output_folder, file_path, file_type, unique_id): queue.put(data) except Exception as e: # 如果要把异常也传给父进程,以便父进程可感知 queue.put(json.dumps({'error': str(e)}, ensure_ascii=False)) finally: queue.put(None) def run_in_subprocess(main_func, output_folder, file_path, file_type, unique_id): """ 启动子进程调用 `main_func(...)`,并在父进程流式获取其输出(通过 Queue)。 子进程结束时,操作系统回收其内存;父进程则保持实时输出。 """ queue = multiprocessing.Queue() p = multiprocessing.Process( target=_child_target, args=(main_func, queue, output_folder, file_path, file_type, unique_id) ) p.start() while True: item = queue.get() # 阻塞等待子进程产出的数据 if item is None: break yield item p.join() 如果开子线程,线程共享同一进程的内存空间,所以如果发生内存泄漏,泄漏的内存会累积在整个进程中,影响所有线程。 开子进程的缺点:多进程通常消耗的系统资源(如内存、启动开销)比多线程要大,因为每个进程都需要独立的资源和上下文切换开销。 进程池 在判断上传的文件是否为招标文件时,需要快速准确地响应。因此既保证内存不泄漏,又保证速度的方案就是在项目启动时创建进程池。(因为创建进程需要耗时2到3秒!) 如果是Waitress服务器启动,这里的进程池是全局共享的;但如果Gunicorn启动,每个请求分配一个worker进程,进程池是在worker里面共享的!!! #创建app,启动时 def create_app(): # 创建全局日志记录器 app = Flask(__name__) app.process_pool = Pool(processes=10, maxtasksperchild=3) app.global_logger = create_logger_main('model_log') # 全局日志记录器 #调用时 pool = current_app.process_pool # 使用全局的进程池 def judge_zbfile_exec_sub(file_path): result = pool.apply( judge_zbfile_exec, # 你的实际执行函数 args=(file_path,) ) return result 但是存在一个问题:第一次发送请求执行时间较慢! 可以发现实际执行只需7.7s,但是接口实际耗时10.23秒,主要是因懒加载或按需初始化:有些模块或资源在子进程启动时并不会马上加载,而是在子进程首次真正执行任务时才进行初始化。 解决思路:提前热身(warm up)进程池 在应用启动后、还没正式接受请求之前,可以提交一个简单的“空任务”或非常小的任务给进程池,让子进程先完成相关的初始化。这种“预热”方式能在正式请求到来之前就完成大部分初始化,减少首次请求的延迟。 还可以快速验证服务是否正常启动 def warmup_request(): # 等待服务器完全启动,例如等待 1-2 秒 time.sleep(5) try: url = "http://127.0.0.1:5000/judge_zbfile" #url必须为永久地址,完成热启动,创建进程池 payload = {"file_url": "xxx"} # 根据实际情况设置 file_url headers = {"Content-Type": "application/json"} response = requests.post(url, json=payload, headers=headers) print(f"Warm-up 请求发送成功,状态码:{response.status_code}") except Exception as e: print(f"Warm-up 请求出错:{e}") threading.Thread(target=warmup_request, daemon=True).start() flask_app结构介绍 项目中做限制的地方 账号、服务器分流 服务器分流:目前linux服务器和windows服务器主要是硬件上的分流(文件切分需要消耗CPU资源),大模型基底还是调用阿里,共用的tpm qpm。 账号分流:qianwen_plus下的 api_keys = cycle([ os.getenv("DASHSCOPE_API_KEY"), # os.getenv("DASHSCOPE_API_KEY_BACKUP1"), # os.getenv("DASHSCOPE_API_KEY_BACKUP2") ]) api_keys_lock = threading.Lock() def get_next_api_key(): with api_keys_lock: return next(api_keys) api_key = get_next_api_key() 只需轮流使用不同的api_key即可。目前没有启用。 大模型的限制 general/llm下的doubao.py 和通义千问long_plus.py 目前是linux和windows各部署一套,因此项目中的qps是对半的,即calls=? 这是qianwen-long的限制(针对阿里qpm为1200,每秒就是20,又linux和windows服务器对半,就是10;TPM无上限) @sleep_and_retry @limits(calls=10, period=1) # 每秒最多调用10次 def rate_limiter(): pass # 这个函数本身不执行任何操作,只用于限流 这是qianwen-plus的限制(针对tpm为1000万,每个请求2万tokens,那么linux和windows总的qps为8时,8x60x2=960<1000。单个为4) 经过2.11号测试,calls=4时最高TPM为800,因此把目前稳定版把calls设为5 2.12,用turbo作为超限后的承载,目前把calls设为7 @sleep_and_retry @limits(calls=7, period=1) # 每秒最多调用7次 def qianwen_plus(user_query, need_extra=False): logger = logging.getLogger('model_log') # 通过日志名字获取记录器 qianwen_turbo的限制(TPM为500万,由于它是plus后的手段,稳妥一点,qps设为6,两个服务器分流即calls=3) @sleep_and_retry @limits(calls=3, period=1) # 500万tpm,每秒最多调用6次,两个服务器分流就是3次 (plus超限后的保底手段,稳妥一点) 重点!!后续阿里扩容之后成倍修改这块calls=? 如果不用linux和windows负载均衡,这里的calls也要乘2!! 接口的限制 start_up.py的def create_app()函数,限制了对每个接口同时100次请求。这里事实上不再限制了(因为100已经足够大了),默认限制做到大模型限制这块。 app.connection_limiters['upload'] = ConnectionLimiter(max_connections=100) app.connection_limiters['get_deviation'] = ConnectionLimiter(max_connections=100) app.connection_limiters['default'] = ConnectionLimiter(max_connections=100) app.connection_limiters['judge_zbfile'] = ConnectionLimiter(max_connections=100) ConnectionLimiter.py以及每个接口上的装饰器,如 @require_connection_limit(timeout=1800) def zbparse(): 这里限制了每个接口内部执行的时间,暂时设置到了30分钟!(不包括排队时间)超时就是解析失败 后端的限制: 目前后端发起招标请求,如果发送超过100(max_connections=100)个请求,我这边会排队后面的请求,这时后端的计时器会将这些请求也视作正在解析中,事实上它们还在排队等待中,这样会导致在极端情况下,新进的解析文件速度大于解析的速度,排队越来越长,后面的文件会因为等待时间过长而直接失败,而不是'解析失败'。 general 是公共函数存放的文件夹,llm下是各类大模型,读取文件下是docx pdf文件的读取以及文档清理clean_pdf,去页眉页脚页码 general下的llm下的清除file_id.py 需要每周运行至少一次,防止file_id数量超出(我这边对每次请求结束都有file_id记录并清理,向应该还没加) llm下的model_continue_query是'模型继续回答'脚本,应对超长文本模型一次无法输出完的情况,继续提问,拼接成完整的内容。 general下的file2markdown是textin 文件--》markdown general下的format_change是pdf-》docx 或doc/docx->pdf general下的merge_pdfs.py是拼接文件的:1.拼接招标公告+投标人须知 2.拼接评标细则章节+资格审查章节 general中比较重要的!!! 后处理: general下的post_processing,解析后的后处理部分,包括extract_info、 资格审查、技术偏离 商务偏离 所需提交的证明材料,都在这块生成。 post_processing中的inner_post_processing专门提取extracted_info post_processing中的process_functions_in_parallel提取 资格审查、技术偏离、 商务偏离、 所需提交的证明材料 大解析upload用了post_processing完整版, little_zbparse.py、小解析main.py用了inner_post_processing get_deviation.py、偏离表数据解析main.py用了process_functions_in_parallel 截取pdf: 截取pdf_main.py是顶级函数, 二级是截取pdf货物标版.py和截取pdf工程标版.py (非general下) 三级是截取pdf通用函数.py 如何判断截取位置是否正确?根据output文件夹中的切分情况(打开各个文件查看是否切分准确,目前的逻辑主要是按大章切分,即'招标公告'章节) 如果切分不准确,如何定位正则表达式? 首先判断当前是工程标解析还是货物标解析,即zb_type=1还是2 如果是2,那么是货物标解析,那么就是截取pdf_main.py调用截取pdf货物标版.py,如下图,selection=1代表截取'招标公告',那么如果招标公告没有切准,就在这块修改。这里可以发现get_notice是通用函数,即截取pdf通用函数.py中的get_notice函数,那么继续往内部跳转。 若开头没截准,就改begin_pattern,末尾没截准,就改end_pattern 另外:在截取pdf货物标版.py中,还有extract_pages_twice函数,即第一次没有切分到之后,会运行该函数,这边又有一套begin_pattern和end_pattern,即二次提取 如何测试? 输入pdf_path,和你要切分的序号,selection=1代表切公告,依次类推,可以看切出来的效果如何。 无效标和废标公共代码 获取无效标与废标项的主要执行代码。对docx文件进行预处理=》正则=》temp.txt=》大模型筛选 如果提的不全,可能是正则没涵盖到位,也可能是大模型提示词漏选了。 这里:如果段落中既被正则匹配,又被follow_up_keywords中的任意一个匹配,那么不会添加到temp中(即不会被大模型筛选),它会直接添加到最后的返回中! 投标人须知正文条款提取成json文件 将截取到的ztbfile_tobidders_notice_part2.pdf ,即须知正文,转为clause1.json 文件,便于后续提取开评定标流程、投标文件要求、重新招标、不再招标和终止招标 这块的主要逻辑就是匹配形如'一、总则'这样的大章节 然后匹配形如'1.1' '1.1.1'这样的序号,由于是按行读取pdf,一个序号后面的内容可能有好几行,因此遇到下一个序号(如'2.1')开头,之前的内容都视为上一个序号的。 old_version 都是废弃文件代码,未在正式、测试环境中使用的,不用管 routes 是接口以及主要实现部分,一一对应 get_deviation对应偏离表数据解析main,获得偏离表数据 judge_zbfile对应判断是否是招标文件 little_zbparse对应小解析main,负责解析extract_info test_zbparse是测试接口,无对应 upload对应工程标解析和货物标解析,即大解析 混淆澄清:小解析可以指代一个过程,即从'投标文件生成'这个入口进去的解析,后端会同时调用little_zbparse和get_deviation。这个过程称为'小解析'。 但是little_zbparse也叫小解析,命名如此因为最初只需返回这些数据(extract_info),后续才陆续返回商务、技术偏离... utils是接口这块的公共功能函数。其中validate_and_setup_logger函数对不同的接口请求对应到不同的output文件夹,如upload->output1。后续增加接口也可直接在这里写映射关系。 重点关注大解析:upload.py和货物标解析main.py static 存放解析的输出和提示词 其中output用gitignore了,git push不会推送这块内容。 各个文件夹(output1 output2..)对应不同的接口请求 test_case&testdir test_case是测试用例,是对一些函数的测试。好久没更新了 testdir是平时写代码的测试的地方 它们都不影响正式和测试环境的解析 工程标&货物标 是两个解析流程中不一样的地方(一样的都写在general中了) 主要是货物标额外解析了采购要求(提取采购需求main+技术参数要求提取+商务服务其他要求提取) 最后: ConnectionLimiter.py定义了接口超时时间->超时后断开与后端的连接 logger_setup.py 为每个请求创建单独的log,每个log对应一个log.txt start_up.py是启动脚本,run_serve也是启动脚本,是对start_up.py的简单封装,目前dockerfile定义的直接使用run_serve启动 持续关注 yield sse_format(tech_deviation_response) yield sse_format(tech_deviation_star_response) yield sse_format(zigefuhe_deviation_response) yield sse_format(shangwu_deviation_response) yield sse_format(shangwu_star_deviation_response) yield sse_format(proof_materials_response) 工程标解析目前仍没有解析采购要求这一块,因此后处理返回的只有'资格审查'和''证明材料"和"extracted_info",没有''商务偏离''及'商务带星偏离',也没有'技术偏离'和'技术带星偏离',而货物标解析是完全版。 其中''证明材料"和"extracted_info"是直接返给后端保存的 大解析中返回了技术评分,后端接收后不仅显示给前端,还会返给向,用于生成技术偏离表 小解析时,get_deviation.py其实也可以返回技术评分,但是没有返回,因为没人和我对接,暂时注释了。 4.商务评议和技术评议偏离表,即评分细则的偏离表,暂时没做,但是商务评分、技术评分无论大解析还是小解析都解析了,稍微对该数据处理一下返回给后端就行。 这个是解析得来的结果,适合给前端展示,但是要生成商务技术评议偏离表的话,需要再调一次大模型,对该数据进行重新归纳,以字符串列表为佳。再传给后端。(未做) 如何定位问题 查看static下的output文件夹 (upload大解析对应output1) docker-compose文件中规定了数据卷挂载的路径:- /home/Z/zbparse_output_dev:/flask_project/flask_app/static/output 也就是说static/output映射到了服务器的Z/zbparse_output_dev文件夹 根据时间查找哪个子文件夹(uuid作为子文件名) 查看是否有final_result.json文件,如果有,说明解析流程正常结束了,问题可能出在后端(a.后端接口请求超限30分钟 b.后处理存在解析数据的时候出错) 也可能出现在自身解析,可以查看子文件内的log.txt,查看日志。 若解析正常(有final_result)但解析不准,可以根据以下定位: a.查看子文件夹下的文件切分是否准确,例如:如果评标办法不准确,那么查看ztbfile_evaluation_methon,是否正确切到了评分细则。如果切到了,那就改general/商务技术评分提取里的提示词;否则修改截取pdf那块关于'评标办法'的正则表达式。 b.总之是先看切的准不准,再看提示词能否优化,都要定位到对应的代码中! 学习总结 Flask + Waitress : Flask 和 Waitress 是两个不同层级的工具,在 Python Web 开发中扮演互补角色。它们的协作关系可以概括为:Flask 负责构建 Web 应用逻辑,而 Waitress 作为生产级服务器承载 Flask 应用。 # Flask 开发服务器(仅用于开发) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000) # 使用 Waitress 启动(生产环境) from waitress import serve serve(app, host='0.0.0.0', port=8080) Waitress 的工作方式 作为 WSGI 服务器:Waitress 作为一个 WSGI 服务器,负责监听指定端口上的网络请求,并将请求传递给 WSGI 应用(如 Flask 应用)。 多线程处理:默认情况下,waitress 在单个进程内启用线程池。当请求到达时,waitress 会从线程池中分配一个线程来处理这个请求。由于 GIL 限制,同一时间只有一个线程在执行 Python 代码(只能使用一个核心,CPU利用率只能到100%)。 Flask 与 waitress 的协同工作 WSGI 接口:Flask 应用实现了 WSGI 接口。waitress 接收到请求后,会调用 Flask 应用对应的视图函数来处理请求,生成响应。 请求处理流程 请求进入 waitress waitress 分配一个线程并调用 Flask 应用 Flask 根据路由匹配并执行对应的处理函数 处理函数返回响应,waitress 将响应发送给客户端 Waitress 的典型使用场景 跨平台部署:尤其适合 Windows 环境(Gunicorn 等服务器不支持)。 简单配置:无需复杂设置即可获得比开发服务器(Flask自带)更强的性能。 中小型应用:对并发要求不极高的场景,Waitress 的轻量级特性优势明显。 Waitress的不足与处理 由于 waitress 是在单进程下工作,所有线程共享进程内存,如果业务逻辑简单且无复杂资源共享问题,这种方式是足够的。 引入子进程:如果需要每个请求实现内存隔离或者绕过 GIL 来利用多核 CPU,有时会在 Flask 视图函数内部启动子进程来处理实际任务。 直接采用多进程部署方案:使用 Gunicorn 的多 worker 模式 Gunicorn Gunicorn 的工作方式 预启动 Worker 进程。Gunicorn 启动时,会按照配置数量(例如 4 个 worker)创建多个 worker 进程。这些 worker 进程会一直运行,并监听同一个端口上的请求。不会针对每个请求单独创建新进程。 共享 socket:所有 worker 进程共享同一个监听 socket,当有请求到来时,操作系统会将请求分发给某个空闲的 worker。 推荐worker 数量 = (2 * CPU 核心数) + 1 如何启动: 要使用异步 worker,你需要: pip install gevent 启动 Gunicorn 时指定 worker 类型和数量,例如: gunicorn -k gevent -w 4 --max-requests 100 flask_app.start_up:create_app --bind 0.0.0.0:5000 使用 -k gevent(或者 -k eventlet)就可以使用异步 worker,单个 worker 能够处理多个 I/O 密集型请求。 使用--max-requests 100 。每个 worker 在处理完 100 个请求后会自动重启,从而释放可能累积的内存。 本项目的执行流程: 调用CPU进行PDF文件的读取与切分,CPU密集型,耗时半分钟 针对切分之后的不同部分,分别调用大模型,得到回答,IO密集型,耗时2分钟。 解决方案: 1.使用flask+waitress,waitress会为每个用户请求开新的线程处理,然后我的代码逻辑会在这个线程内开子进程来执行具体的代码,以绕过GIL限制,且正确释放内存资源。 **后续可以开一个共享的进程池代替为每个请求开子进程。以避免高并发下竞争多核导致的频繁CPU切换问题。 2.使用Gunicorn的异步worker,gunicorn为固定创建worker(进程),处理用户请求,一个异步 worker 可以同时处理多个用户请求,因为当一个请求在等待外部响应(例如调用大模型接口)时,worker 可以切换去处理其他请求。 全局解释器锁(GIL): Python(特别是 CPython 实现)中有一个叫做全局解释器锁(Global Interpreter Lock,简称 GIL)的机制,这个锁确保在任何时刻只有一个线程在执行 Python 字节码。 这意味着,即使你启动了多个线程,它们在执行 Python 代码时实际上是串行执行的,而不是并行利用多核 CPU。 在 Java 中,多线程通常能充分利用多核,因为 Java 的线程是真正的系统级线程,不存在类似 CPython 中的 GIL 限制。 影响: CPU密集型任务:由于 GIL 的存在,在 CPU 密集型任务中,多线程往往不能提高性能,因为同时只有一个线程在执行 Python 代码。 I/O密集型任务:如果任务主要等待 I/O(例如网络、磁盘读写),线程在等待时会释放 GIL,此时多线程可以提高程序的响应性和吞吐量。 NumPy能够在一定程度上绕过 Python 的 GIL 限制。许多 NumPy 的数值计算操作(如矩阵乘法、向量化运算等)是由高度优化的 C 或 Fortran 库(如 BLAS、LAPACK)实现的。这些库通常在执行计算密集型任务时会释放 GIL。C 扩展模块的方式将 C 代码嵌入到 Python 中,从而利用底层 C 库的高性能优势 进程与线程 1、进程是操作系统分配任务的基本单位,进程是python中正在运行的程序;当我们打开了1个浏览器时就是开始了一个浏览器进程; 线程是进程中执行任务的基本单元(执行指令集),一个进程中至少有一个线程、当只有一个线程时,称为主线程 2、线程的创建和销毁耗费资源少,进程的创建和销毁耗费资源多;线程很容易创建,进程不容易创建 3、线程的切换速度快,进程慢 4、一个进程中有多个线程时:线程之间可以进行通信;一个进程中有多个子进程时,进程与进程之间不可以相互通信,如果需要通信时,就必须通过一个中间代理实现,Queue、Pipe。 5、多进程可以利用多核cpu,多线程不可以利用多核cpu 6、一个新的线程很容易被创建,一个新的进程创建需要对父进程进行一次克隆 7、多进程的主要目的是充分使用CPU的多核机制,多线程的主要目的是充分利用某一个单核 ——————————————— 每个进程有自己的独立 GIL 多线程适用于 I/O 密集型任务 多进程适用于CPU密集型任务 因此,多进程用于充分利用多核,进程内开多线程以充分利用单核。 进程池 multiprocessing.Pool库:,通过 maxtasksperchild 指定每个子进程在退出前最多执行的任务数,这有助于防止某些任务中可能存在的内存泄漏问题 pool =Pool(processes=10, maxtasksperchild=3) concurrent.futures.ProcessPoolExecutor更高级、更统一,没有类似 maxtasksperchild 的参数,意味着进程在整个执行期内会一直存活,适合任务本身比较稳定的场景。 pool =ProcessPoolExecutor(max_workers=10) 最好创建的进程数等同于CPU核心数,如果大于,且每个进程都是CPU密集型(高负债一直用到CPU),那么进程之间会竞争CPU,导致上下文切换增加,反而会降低性质。 设置的工作进程数接近 CPU 核心数,以便每个进程能独占一个核运行。 进程、线程间通信 线程间通信: 线程之间可以直接共享全局变量、对象或数据结构,不需要额外的序列化过程,但这也带来了同步的复杂性(如竞态条件)。 import threading num=0 def work(): global num for i in range(1000000): num+=1 print('work',num) def work1(): global num for i in range(1000000): num+=1 print('work1',num) if __name__ == '__main__': t1=threading.Thread(target=work) t2=threading.Thread(target=work1) t1.start() t2.start() t1.join() t2.join() print('主线程执行结果',num) 运行结果: work 1551626 work1 1615783 主线程执行结果 1615783 这些数值都小于预期的 2000000,因为: 即使存在 GIL,num += 1 这样的操作实际上并不是原子的。GIL 确保同一时刻只有一个线程执行 Python 字节码,但在执行 num += 1 时,实际上会发生下面几步操作: 从内存中读取 num 的当前值 对读取到的值进行加 1 操作 将新的值写回到内存 由多个字节码组成!!! 因此会导致: 线程 A 读取到 num 的值 切换到线程 B,线程 B 也读取同样的 num 值并进行加 1,然后写回 当线程 A 恢复时,它依然基于之前读取的旧值进行加 1,最后写回,从而覆盖了线程 B 的更新 解决: from threading import Lock import threading num=0 def work(): global num for i in range(1000000): with lock: num+=1 print('work',num) def work1(): global num for i in range(1000000): with lock: num+=1 print('work1',num) if __name__ == '__main__': lock=Lock() t1=threading.Thread(target=work) t2=threading.Thread(target=work1) t1.start() t2.start() t1.join() t2.join() print('主线程执行结果',num) 进程间通信(IPC): 进程之间默认不共享内存,因此如果需要传递数据,就必须使用专门的通信机制。 在 Python 中,可以使用 multiprocessing.Queue、multiprocessing.Pipe、共享内存(如 multiprocessing.Value 和 multiprocessing.Array)等方式实现进程间通信。 from multiprocessing import Process, Queue def worker(process_id, q): # 每个进程将数据放入队列 q.put(f"data_from_process_{process_id}") print(f"Process {process_id} finished.") if __name__ == '__main__': q = Queue() processes = [] for i in range(5): p = Process(target=worker, args=(i, q)) processes.append(p) p.start() for p in processes: p.join() # 从队列中收集数据 results = [] while not q.empty(): results.append(q.get()) print("Collected data:", results) 当你在主进程中创建了一个 Queue 对象,然后将它作为参数传递给子进程时,子进程会获得一个能够与主进程通信的“句柄”。 子进程中的 q.put(...) 操作会将数据通过这个管道传送到主进程,而主进程可以通过 q.get() 来获取这些数据。 这种机制虽然看起来像是“共享”,但实际上是通过 IPC(进程间通信)实现的,而不是直接共享内存中的变量。 项目贡献 效果图
项目
zy123
1年前
0
15
0
2025-03-21
微服务
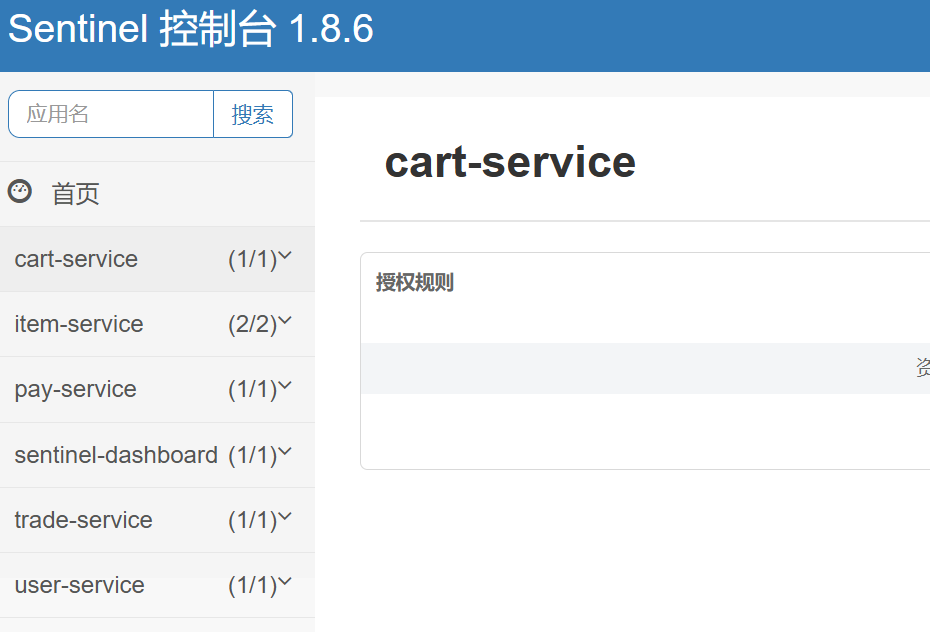
微服务 踩坑总结 Mybatis-PLUS 分页不生效,因为mybatis-plus自3.5.9起,默认不包含分页插件,需要自己引入。 <dependencyManagement> <dependencies> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-bom</artifactId> <version>3.5.9</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <!-- MyBatis Plus 分页插件 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-jsqlparser-4.9</artifactId> </dependency> config包下新建: @Configuration @MapperScan("edu.whut.smilepicturebackend.mapper") public class MybatisPlusConfig { /** * 拦截器配置 * * @return {@link MybatisPlusInterceptor} */ @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); // 分页插件 interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); return interceptor; } } 雪花算法表示精度问题 “雪花算法”(Snowflake)生成的 ID 本质上是一个 64 位的整数(Java等后端里通常对应 long ),而浏览器端的 JavaScript Number 类型只能安全地表示到 2^53−1 以内的整数,超出这个范围就会出现 “精度丢失”──即低位那几位数字可能会被四舍五入掉,导致 ID 读取或比对出错。因此,最佳实践是: 后端依然用 long(或等价的 64 位整数)存储和处理雪花 ID。 对外接口(REST/graphQL 等)返回时,将这类超出 JS 安全范围的整数序列化为字符串,比如: @Configuration public class JacksonConfig { private static final String DATE_FORMAT = "yyyy-MM-dd"; private static final String DATETIME_FORMAT = "yyyy-MM-dd HH:mm:ss"; private static final String TIME_FORMAT = "HH:mm:ss"; @Bean public Jackson2ObjectMapperBuilderCustomizer jacksonCustomizer() { return builder -> { // 将所有 long / Long 类型序列化成 String SimpleModule longToString = new SimpleModule(); longToString.addSerializer(Long.class, ToStringSerializer.instance); longToString.addSerializer(Long.TYPE, ToStringSerializer.instance); builder.modules(longToString); }; } } 包扫描问题(非常容易出错!) 以 Spring Boot 为例,框架默认会扫描启动类所在包及其子包中的组件(@Component/@Service/@Repository/@Configuration 等),将它们注册到 Spring 容器中。 问题:当你把某些业务组件、配置类或第三方模块放在了启动类的同级或平级包下(而非子包),却没有手动指定扫描路径,就会出现 “无法注入 Bean” 的情况。 // 启动类 @SpringBootApplication public class OrderServiceApplication { … } // 业务类位于 com.example.common 包 @Service public class PaymentClient { … } 如果项目结构是: com.example.orderservice ← 启动类 com.example.common ← 依赖组件 默认情况下 com.example.common 不会被扫描到,导致注入 PaymentClient 时抛出 NoSuchBeanDefinitionException。 解决方案: 1)显式指定扫描路径**: @SpringBootApplication @ComponentScan(basePackages = { "com.example.orderservice", "com.example.common" }) public class OrderServiceApplication { … } 2)使用 @Import 或者 Spring Cloud 的自动配置机制(如编写 spring.factories,让依赖模块自动装配)。 数据库连接池 为什么需要? 每次通过 JDBC 调用 DriverManager.getConnection(...),都要完成网络握手、权限验证、初始化会话等大量开销,通常耗时在几十到几百毫秒不等。连接池通过提前建立好 N 条物理连接并在应用各处循环复用,避免了反复的开销。 流程 数据库连接池在应用启动时预先创建一定数量的物理连接,并将它们保存在空闲队列中;当业务需要访问数据库时,直接从池中“借用”一个连接(无需新建),用完后调用 close() 即把它归还池中;池会根据空闲超时或最大寿命策略自动回收旧连接,并在借出或定期扫描时执行简单心跳(如 SELECT 1)来剔除失效连接,确保始终有可用、健康的连接供高并发场景下快速复用。 ┌─────────────────────────────────────────┐ │ 应用线程 A 调用 getConnection() │ │ ┌──────────┐ ┌─────────────┐ │ │ │ 空闲连接队列 │──取出──▶│ 物理连接 │───┐│ │ └──────────┘ └─────────────┘ ││ │ (代理包装) ││ │ 返回代理连接给业务代码 ││ └─────────────────────────────────────────┘ │ │ ┌─────────────────────────────────────────┐ │ │ 业务执行 SQL,最后调用 close() │ │ ┌───────────────┐ ┌────────────┐ │ │ │ 代理 Connection │──归还──▶│ 空闲连接队列 │◀─────┘ │ └───────────────┘ └────────────┘ └─────────────────────────────────────────┘ 当你从连接池里拿到一个底层已被远程关闭的连接时,HikariCP(以及大多数成熟连接池)会在“借出”前先做一次简易校验(默认为 Connection.isValid(),或你配置的 connection-test-query)。如果校验失败,连接池会自动将这条“死”连接销毁,并尝试从池里或新建一个新的物理连接来替换,再把新的健康连接返给业务;只有当新的连接也创建或校验失败到达池的最大重试次数时,才会抛出拿不到连接的超时异常。 遇到的问题 如果本地启动了 Java 应用和前端 Nginx,而 MySQL 部署在远程服务器上,Java 应用通过连接池与远程数据库建立的 TCP 连接在 5 分钟内若无任何 SQL 操作,就会因中间网络设备(如 NAT、负载均衡器、防火墙)超时断开,且应用层不会主动感知,导致后续 SQL 请求失败。 13:20:01:383 WARN 43640 --- [nio-8084-exec-4] com.zaxxer.hikari.pool.PoolBase : HikariPool-1 - Failed to validate connection com.mysql.cj.jdbc.ConnectionImpl@36e971ae (No operations allowed after connection closed.). Possibly consider using a shorter maxLifetime value. 13:20:01:384 ERROR 43640 --- [nio-8084-exec-4] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException: ### Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30048ms. 为了解决这个问题, 1.只需在 Spring Boot 配置中为 HikariCP 添加定期心跳,让连接池在真正断连前保持流量: spring: datasource: hikari: keepalive-time: 180000 # 3 分钟发送一次心跳(维持 TCP 活跃) 这样,HikariCP 会每隔 3 分钟自动对空闲连接执行轻量级的验证操作(如 Connection.isValid()),确保中间网络链路不会因长时间静默而被强制关闭。 2.如果JAVA应用和Mysql在同一服务器上(可互通),就不会有上述问题! Sentinel无数据 sentinel 控制台可以发现哪些微服务连接了,但是Dashboard 在尝试去拿各个微服务上报的规则(端点 /getRules)和指标(端点 /metric)时,一直连不上它们,因为JAVA微服务是在本地私网内部署的,Dashboard无法连接上。 Failed to fetch metric from http://192.168.0.107:8725/metric?… Failed to fetch metric from http://192.168.0.107:8721/metric?… HTTP request failed: http://192.168.0.107:8721/getRules?type=flow java.net.ConnectException: Operation timed out 解决办法: 1.将JAVA应用部署到服务器,但我的服务器内存不够 2.将Dashboard部署到本机docker中,和JAVA应用可互通。 Nacos迁移后的 No DataSource set 原本Nacos和Mysql都是部署到公网服务器,mysql容器对外暴露3307,因此Nacos的env文件中可以是: MYSQL_SERVICE_DB_NAME=124.xxx.xxx.xxx MYSQL_SERVICE_PORT=3307 填的mysql的公网ip,以及它暴露的端口3307,这是OK的 但是如果将它们部署在docker同一网络中,应该这样写: MYSQL_SERVICE_DB_NAME=mysql MYSQL_SERVICE_PORT=3306 mysql是服务名,不能写localhost(或 127.0.0.1),它永远只会指向「当前容器自己」!!! 注意,Nacos中的配置文件也要迁移过来,导入nacos配置列表中,并且修改JAVA项目中nacos的地址 Docker Compose问题 1)如果你把某个服务从 docker-compose.yml 里删掉,然后再执行: docker compose down 默认情况下 并不会 停止或删除那个已经“离开”了 Compose 配置的容器。 只能: docker compose down --remove-orphans #清理这些“孤儿”容器 或者手动清理: docker ps #列出容器 docker stop <container_id_or_name> docker rm <container_id_or_name> 2)端口占用问题 Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:5672 -> 0.0.0.0:0: listen tcp 0.0.0.0:5672: bind: An attempt was made to access a socket in a way forbidden by its access permissions. 先查看是否端口被占用: netstat -aon | findstr 5672 如果没有被占用,那么就是windows的bug,在CMD使用管理员权限重启NAT网络服务即可 net stop winnat net start winnat 3)ip地址问题 seata-server: image: seataio/seata-server:1.5.2 container_name: seata-server restart: unless-stopped depends_on: - mysql - nacos environment: # 指定 Seata 注册中心和配置中心地址 - SEATA_IP=192.168.10.218 # IDEA 可以访问到的宿主机 IP - SEATA_SERVICE_PORT=17099 - SEATA_CONFIG_TYPE=file # 可视情况再加:SEATA_NACOS_SERVER_ADDR=nacos:8848 networks: - hmall-net ports: - "17099:7099" # TC 服务端口 - "8099:8099" # 服务管理端口(Console) volumes: - ./seata:/seata-server/resources SEATA_IP配置的是宿主机IP,你的电脑换了IP,如从教室到寝室,那这里的IP也要跟着变:ipconfig查看宿主机ip 认识微服务 微服务架构,首先是服务化,就是将单体架构中的功能模块从单体应用中拆分出来,独立部署为多个服务。 SpringCloud 使用Spring Cloud 2021.0.x以及Spring Boot 2.7.x版本(需要对应)。 在父pom中的<dependencyManagement>锁定版本,使得后续你在子模块里引用 Spring Cloud 或 Spring Cloud Alibaba 的各个组件时,不需要再写 <version>,Maven 会统一采用你在父 POM 中指定的版本。 微服务拆分 微服务拆分时: 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖,或者依赖接口的稳定性要强。 一般微服务项目有两种不同的工程结构: 完全解耦:每一个微服务都创建为一个独立的工程,甚至可以使用不同的开发语言来开发,项目完全解耦。 优点:服务之间耦合度低 缺点:每个项目都有自己的独立仓库,管理起来比较麻烦 Maven聚合:整个项目为一个Project,然后每个微服务是其中的一个Module 优点:项目代码集中,管理和运维方便 缺点:服务之间耦合,编译时间较长 ,每个模块都要有:pom.xml application.yml controller service mapper pojo 启动类 IDEA配置小技巧 1.自动导包 2.配置service窗口,以显示多个微服务启动类 3.如何在idea中虚拟多服务负载均衡? More options->Add VM options -> -Dserver.port=xxxx 这边设置不同的端口号! 服务注册和发现 注册中心、服务提供者、服务消费者三者间关系如下: 流程如下: 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署) 调用者自己对实例列表负载均衡,挑选一个实例 调用者向该实例发起远程调用 当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢? 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求) 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表 当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表(防止服务调用者继续调用挂逼的服务) Nacos部署: 1.依赖mysql中的一个数据库 ,可由nacos.sql初始化 2.需要.env文件,配置和数据库的连接信息: PREFER_HOST_MODE=hostname MODE=standalone SPRING_DATASOURCE_PLATFORM=mysql MYSQL_SERVICE_HOST=124.71.159.*** MYSQL_SERVICE_DB_NAME=nacos MYSQL_SERVICE_PORT=3307 MYSQL_SERVICE_USER=root MYSQL_SERVICE_PASSWORD=******* MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai 3.docker部署: nacos: image: nacos/nacos-server:v2.1.0 container_name: nacos-server restart: unless-stopped env_file: - ./nacos/custom.env # 自定义环境变量文件 ports: - "8848:8848" # Nacos 控制台端口 - "9848:9848" # RPC 通信端口 (TCP 长连接/心跳) - "9849:9849" # gRPC 通信端口 networks: - hm-net depends_on: - mysql volumes: - ./nacos/init.d:/docker-entrypoint-init.d # 如果需要额外初始化脚本,可选 启动完成后,访问地址:http://ip:8848/nacos/ 初始账号密码都是nacos 服务注册 1.在item-service的pom.xml中添加依赖: <!--nacos 服务注册发现--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> 2.配置Nacos 在item-service的application.yml中添加nacos地址配置: spring: application: name: item-service #服务名 cloud: nacos: server-addr: 124.71.159.***:8848 # nacos地址 注意,服务注册默认连9848端口!云服务需要开启该端口! 配置里的item-service就是服务名! 多个实例注册 version: '3' services: item-service-1: image: item-service container_name: item-service-1 environment: - spring.application.name=item-service - nacos.server-addr=124.71.159.***:8848 ports: - "8081:8080" # 映射端口 8081 item-service-2: image: item-service container_name: item-service-2 environment: - spring.application.name=item-service - nacos.server-addr=124.71.159.***:8848 ports: - "8082:8080" # 映射端口 8082 item-service-1 和 item-service-2 都会向 Nacos 注册为名为 item-service 的服务实例,但它们是不同的容器实例,具有不同的端口和 instanceId。 这样就能实现多实例部署,可以负载均衡了。 服务发现 前两步同服务注册 3.通过 DiscoveryClient 发现服务实例列表,然后通过负载均衡算法,选择一个实例去调用 discoveryClient发现服务 + restTemplate远程调用 @Service public class CartServiceImpl { @Autowired private DiscoveryClient discoveryClient; // 注入 DiscoveryClient @Autowired private RestTemplate restTemplate; // 用于发 HTTP 请求 private void handleCartItems(List<CartVO> vos) { // 1. 获取商品 id 列表 Set<Long> itemIds = vos.stream() .map(CartVO::getItemId) .collect(Collectors.toSet()); // 2.1. 发现 item-service 服务的实例列表 List<ServiceInstance> instances = discoveryClient.getInstances("item-service"); // 2.2. 负载均衡:随机挑选一个实例 ServiceInstance instance = instances.get( RandomUtil.randomInt(instances.size()) ); // 2.3. 发送请求,查询商品详情 String url = instance.getUri().toString() + "/items?ids={ids}"; ResponseEntity<List<ItemDTO>> response = restTemplate.exchange( url, HttpMethod.GET, null, new ParameterizedTypeReference<List<ItemDTO>>() {}, String.join(",", itemIds) ); // 2.4. 处理结果 if (response.getStatusCode().is2xxSuccessful()) { List<ItemDTO> items = response.getBody(); // … 后续处理 … } else { throw new RuntimeException("查询商品失败: " + response.getStatusCode()); } } } OpenFeign 让远程调用像本地方法调用一样简单 快速入门 1.引入依赖 <!--openFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <!--负载均衡器--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> 2.启用OpenFeign 在服务调用者cart-service的CartApplication启动类上添加注解: @EnableFeignClients 3.编写OpenFeign客户端 在cart-service中,定义一个新的接口,编写Feign客户端: @FeignClient("item-service") public interface ItemClient { @GetMapping("/items") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); } queryItemByIds这个方法名可以随便取,但@GetMapping("/items") 和 @RequestParam("ids") 要跟 item-service 服务中实际暴露的接口路径和参数名保持一致(直接参考服务提供者的Controller层对应方法对应即可); 一个客户端对应一个服务,可以在ItemClient里面写多个方法。 4.使用 List<ItemDTO> items = itemClient.queryItemByIds(Arrays.asList(1L, 2L, 3L)); Feign 会帮你把 ids=[1,2,3] 序列化成一个 HTTP GET 请求,URL 形如: GET http://item-service/items?ids=1&ids=2&ids=3 连接池 Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括: HttpURLConnection:默认实现,不支持连接池 Apache HttpClient :支持连接池 OKHttp:支持连接池 这里用带有连接池的HttpClient 替换默认的 1.引入依赖 <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> </dependency> 2.开启连接池 feign: httpclient: enabled: true # 使用 Apache HttpClient(默认关闭) 重启服务,连接池就生效了。 最佳实践 如果拆分了交易微服务(trade-service),它也需要远程调用item-service中的根据id批量查询商品功能。这个需求与cart-service中是一样的。那么会再次定义ItemClient接口导致重复编程。 思路1:抽取到微服务之外的公共module,需要调用client就引用该module的坐标。 思路2:每个微服务自己抽取一个module,比如item-service,将需要共享的domain实体放在item-dto模块,需要供其他微服务调用的cilent放在item-api模块,自己维护自己的,然后其他微服务引入maven坐标直接使用。 大型项目思路2更清晰、更合理。但这里选择思路1,方便起见。 拆分之后重启报错:Parameter 0 of constructor in com.hmall.cart.service.impl.CartServiceImpl required a bean of type 'com.hmall.api.client.ItemClient' that could not be found. 是因为:Feign Client 没被扫描到,Spring Boot 默认只会在主应用类所在包及其子包里扫描 @FeignClient。 需要额外设置basePackages package com.hmall.cart; @MapperScan("com.hmall.cart.mapper") @EnableFeignClients(basePackages= "com.hmall.api.client") @SpringBootApplication public class CartApplication { public static void main(String[] args) { SpringApplication.run(CartApplication.class, args); } } 网关 在微服务拆分后的联调过程中,经常会遇到以下问题: 不同业务数据分布在各自微服务,需要维护多套地址和端口,调用繁琐且易错; 前端无法直接访问注册中心(如 Nacos),无法实时获取服务列表,导致接口切换不灵活。 此外,单体架构下只需完成一次登录与身份校验,所有业务模块即可共享用户信息;但在微服务架构中: 每个微服务是否都要重复实现登录校验和用户信息获取? 服务间调用时,如何安全、可靠地传递用户身份? 通过引入 API 网关,我们可以在统一入口处解决以上问题:它提供动态路由与负载均衡,前端只需调用一个地址;它与注册中心集成,实时路由调整;它还在网关层集中完成登录鉴权和用户信息透传,下游服务无需重复实现安全逻辑。 快速入门 网关本身也是一个独立的微服务,因此也需要创建一个模块开发功能。大概步骤如下: 创建网关微服务 引入 SpringCloudGateway 、NacosDiscovery依赖 编写启动类 配置网关路由 1.依赖引入: <!-- 网关 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!-- Nacos Discovery --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- 负载均衡 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> 2.配置网关路由 id:给这条路由起个唯一的标识,方便你在日志、监控里看是哪个规则。(最好和服务名一致) uri: lb://xxx:xxx 必须和服务注册时的名字一模一样(比如 Item-service 或全大写 ITEM-SERVICE,取决于你在微服务启动时 spring.application.name 配置) server: port: 8080 spring: application: name: gateway cloud: nacos: server-addr: 192.168.150.101:8848 gateway: routes: - id: item # 路由规则id,自定义,唯一 uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表 predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务 - Path=/items/**,/search/** # 支持多个路径模式,用逗号隔开 - id: cart uri: lb://cart-service predicates: - Path=/carts/** - id: user uri: lb://user-service predicates: - Path=/users/**,/addresses/** - id: trade uri: lb://trade-service predicates: - Path=/orders/** - id: pay uri: lb://pay-service predicates: - Path=/pay-orders/** predicates:路由断言,其实就是匹配条件 After 是某个时间点后的请求 - After=2037-01-20T17:42:47.789-07:00[America/Denver] Before 是某个时间点之前的请求 - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] Path 请求路径必须符合指定规则 - Path=/red/{segment},/blue/** 如果(predicates)符合这些规则,就把请求送到(uri)这里去。 Ant风格路径 用来灵活地匹配文件或请求路径: ?:匹配单个字符(除了 /)。 例如,/user/??/profile 能匹配 /user/ab/profile,但不能匹配 /user/a/profile 或 /user/abc/profile。 *:匹配任意数量的字符(零 个或 多个),但不跨越路径分隔符 /。 例如,/images/*.png 能匹配 /images/a.png、/images/logo.png,却不匹配 /images/icons/logo.png。 **:匹配任意层级的路径(可以跨越多个 /)。 例如,/static/** 能匹配 /static/、/static/css/style.css、/static/js/lib/foo.js,甚至 /static/a/b/c/d。 AntPathMatcher 是 Spring Framework 提供的一个工具类,用来对“Ant 风格”路径模式做匹配 @Component @ConfigurationProperties(prefix = "auth") public class AuthProperties { private List<String> excludePaths; // getter + setter } @Component public class AuthInterceptor implements HandlerInterceptor { private final AntPathMatcher pathMatcher = new AntPathMatcher(); private final List<String> exclude; public AuthInterceptor(AuthProperties props) { this.exclude = props.getExcludePaths(); } @Override public boolean preHandle(HttpServletRequest req, HttpServletResponse res, Object handler) { String path = req.getRequestURI(); // e.g. "/search/books/123" // 检查是否匹配任何一个“放行”模式 for (String pattern : exclude) { if (pathMatcher.match(pattern, path)) { return true; // 放行,不做 auth } } // 否则执行认证逻辑 // ... return false; } } 当然 predicates: - Path=/users/**,/addresses/** 这里不需要手写JAVA逻辑进行路径匹配,因为Gateway自动实现了。但是后面自定义Gateway过滤器的时候就需要AntPathMatcher了! 登录校验 我们需要实现一个网关过滤器,有两种可选: GatewayFilter:路由过滤器,作用范围比较灵活,可以是任意指定的路由Route. GlobalFilter:全局过滤器,作用范围是所有路由,不可配置。 网关需要实现两个功能: JWT 校验:网关会拦截请求,验证 JWT Token 的有效性。如果 Token 无效,返回 401 错误。如果 Token 有效,提取用户 ID,并将其作为请求头的一部分传递给微服务。 传递用户信息:网关将 user-info(用户 ID)传递给微服务。微服务的拦截器会从请求头中获取并保存用户信息到 ThreadLocal,后续代码可以方便地获取。 网关过滤器 - JWT 校验 + 用户信息传递 @Component @RequiredArgsConstructor public class AuthGlobalFilter implements GlobalFilter, Ordered { private final JwtTool jwtTool; private final AuthProperties authProperties; private final AntPathMatcher antPathMatcher = new AntPathMatcher(); @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { // 获取请求 ServerHttpRequest request = exchange.getRequest(); // 判断是否不需要拦截 if (isExclude(request.getPath().toString())) { return chain.filter(exchange); // 跳过不需要拦截的路径 } // 获取 Token String token = request.getHeaders().getFirst("authorization"); // 校验并解析 Token Long userId = null; try { userId = jwtTool.parseToken(token); // 校验 Token 并获取用户 ID } catch (UnauthorizedException e) { ServerHttpResponse response = exchange.getResponse(); response.setRawStatusCode(401); // Token 校验失败,返回 401 return response.setComplete(); } // 将用户信息添加到请求头 ServerWebExchange modifiedExchange = exchange.mutate() .request(builder -> builder.header("user-info", userId.toString())) .build(); // 放行请求,继续执行后续过滤器 return chain.filter(modifiedExchange); } private boolean isExclude(String path) { // 判断路径是否是需要排除的路径(不需要拦截) for (String pattern : authProperties.getExcludePaths()) { if (antPathMatcher.match(pattern, path)) { return true; } } return false; } @Override public int getOrder() { return 0; // 优先级,数字越小优先级越高 } } JWT 校验:通过 jwtTool.parseToken(token) 校验 Token 是否有效。如果有效,就提取用户 ID;如果无效,返回 401 Unauthorized 错误。 传递用户信息:将 user-info(用户 ID)添加到请求头中,然后放行请求。 isExclude 方法:检查当前请求路径是否匹配不需要拦截的路径(如登录、注册等)。 微服务拦截器 - 获取用户信息 为了统一处理微服务中的用户信息提取,我们将拦截器放在 common 模块中。拦截器的作用是从请求头中获取 user-info,并将其保存到 UserContext 中,供后续业务逻辑使用。具体的拦截和校验逻辑由 网关过滤器 处理,而拦截器的职责仅仅是将用户信息存入 ThreadLocal,避免每个微服务都实现相同的逻辑。 1.用户信息拦截器 public class UserInfoInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 1.获取请求头中的用户信息 String userInfo = request.getHeader("user-info"); // 2.判断是否为空 if (StrUtil.isNotBlank(userInfo)) { // 不为空,保存到ThreadLocal UserContext.setUser(Long.valueOf(userInfo)); } // 3.放行 return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { // 移除用户 UserContext.removeUser(); } } 2.配置拦截器 在 common 模块中,我们通过配置类 MvcConfig 来注册拦截器,使其在微服务应用中生效。该配置类实现了 WebMvcConfigurer 接口,并在 addInterceptors 方法中注册 UserInfoInterceptor。 @Configuration @ConditionalOnClass(DispatcherServlet.class) public class MvcConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new UserInfoInterceptor()); } } 3.解决包扫描问题 由于 common 模块与其他微服务模块(如 item、cart)是平级的,common 包无法被微服务自动扫描到。因此,我们需要通过以下方式确保微服务能够加载 common 模块中的拦截器配置。解决方法: 1.在每个微服务的启动类上添加包扫描 @SpringBootApplication( scanBasePackages = {"com.hmall.item", "com.hmall.common"} // 扫描 item 和 common 包 ) public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } 主包以及common包 2.通过 @Import 引入配置类 @SpringBootApplication @Import(com.hmall.common.config.MvcConfig.class) // 引入 common 模块中的拦截器配置 public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } 3.将 common 模块做成 Spring Boot 自动配置 1)在 common 模块的 src/main/resources/META-INF/spring.factories 文件中声明: org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.hmall.common.config.MvcConfig 2)在 common 模块里给 MvcConfig 加上 @Configuration @ConditionalOnClass(DispatcherServlet.class) //网关不生效 spring服务生效 public class MvcConfig { … } 3)这样,任何微服务只要依赖了 common 模块,MvcConfig 配置就会自动加载,拦截器会自动生效,无需修改微服务的 @SpringBootApplication 配置。 OpenFeign传递用户 前端发起的请求都会经过网关再到微服务,微服务可以轻松获取登录用户信息。但是,有些业务是比较复杂的,请求到达微服务后还需要调用其它多个微服务,微服务之间的调用无法传递用户信息,因为不在一个上下文(线程)中! 解决思路:让每一个由OpenFeign发起的请求自动携带登录用户信息。要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor public class DefaultFeignConfig { @Bean public RequestInterceptor userInfoRequestInterceptor(){ return new RequestInterceptor() { @Override public void apply(RequestTemplate template) { // 获取登录用户 Long userId = UserContext.getUser(); if(userId == null) { // 如果为空则直接跳过 return; } // 如果不为空则放入请求头中,传递给下游微服务 template.header("user-info", userId.toString()); } }; } } 同时,需要在服务调用者的启动类上添加: @EnableFeignClients( basePackages = "com.hmall.api.client", defaultConfiguration = DefaultFeignConfig.class ) @SpringBootApplication public class PayApplication { 这样 DefaultFeignConfig.class 会对于所有Client类生效 @FeignClient(value = "item-service", configuration = DefaultFeignConfig.class) public interface ItemClient { @GetMapping("/items") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); } 这种只对ItemClient生效! 整体流程图 配置管理 微服务共享的配置可以统一交给Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。 配置共享 在nacos控制台的配置管理中添加配置文件 数据库ip:通过${hm.db.host:192.168.150.101}配置了默认值为192.168.150.101,同时允许通过${hm.db.host}来覆盖默认值 配置读取流程: 微服务整合Nacos配置管理的步骤如下: 1)引入依赖: <!--nacos配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> 2)新建bootstrap.yaml 在cart-service中的resources目录新建一个bootstrap.yaml文件: 主要给nacos的信息 spring: application: name: cart-service # 服务名称 profiles: active: dev cloud: nacos: server-addr: 192.168.150.101 # nacos地址 config: file-extension: yaml # 文件后缀名 shared-configs: # 共享配置 - dataId: shared-jdbc.yaml # 共享mybatis配置 - dataId: shared-log.yaml # 共享日志配置 - dataId: shared-swagger.yaml # 共享日志配置 3)修改application.yaml server: port: 8082 feign: okhttp: enabled: true # 开启OKHttp连接池支持 hm: swagger: title: 购物车服务接口文档 package: com.hmall.cart.controller db: database: hm-cart 配置热更新 有很多的业务相关参数,将来可能会根据实际情况临时调整,如何不重启服务,直接更改配置文件生效呢? 示例:购物车中的商品上限数量需动态调整。 1)在nacos中添加配置 在nacos中添加一个配置文件,将购物车的上限数量添加到配置中: 文件的dataId格式: [服务名]-[spring.active.profile].[后缀名] 文件名称由三部分组成: 服务名:我们是购物车服务,所以是cart-service spring.active.profile:就是spring boot中的spring.active.profile,可以省略,则所有profile共享该配置(不管local还是dev还是prod) 后缀名:例如yaml 示例:cart-service.yaml hm: cart: maxAmount: 1 # 购物车商品数量上限 2)在微服务中配置 @Data @Component @ConfigurationProperties(prefix = "hm.cart") public class CartProperties { private Integer maxAmount; } 3)下次,只需改nacos中的配置文件 =》发布,即可实现热更新。 动态路由 1.监听Nacos的配置变更 NacosConfigManager可以获取ConfigService 配置信息 String configInfo = nacosConfigManager.getConfigService() 内容是带换行和缩进的 YAML 文本或者 JSON 格式(取决于你的配置文件格式): //多条路由 [ { "id": "user-service", "uri": "lb://USER-SERVICE", "predicates": [ "Path=/user/**" ], "filters": [ "StripPrefix=1" ] }, { "id": "order-service", "uri": "lb://ORDER-SERVICE", "predicates": [ "Path=/order/**" ], "filters": [ "StripPrefix=1", "AddRequestHeader=X-Order-Source,cloud" ] } ] 因为YAML格式解析不方便,故配置文件采用 JSON 格式保存、读取、解析! String getConfigAndSignListener( String dataId, // 配置文件id String group, // 配置组,走默认 long timeoutMs, // 读取配置的超时时间 Listener listener // 监听器 ) throws NacosException; getConfigAndSignListener既可以在第一次读配置文件又可以在后面进行监听 每当 Nacos 上该配置有变更,会触发其内部receiveConfigInfo(...) 方法 2.然后手动把最新的路由更新到路由表中。 RouteDefinitionWriter public interface RouteDefinitionWriter { /** * 更新路由到路由表,如果路由id重复,则会覆盖旧的路由 */ Mono<Void> save(Mono<RouteDefinition> route); /** * 根据路由id删除某个路由 */ Mono<Void> delete(Mono<String> routeId); } @Slf4j @Component @RequiredArgsConstructor public class DynamicRouteLoader { private final RouteDefinitionWriter writer; private final NacosConfigManager nacosConfigManager; // 路由配置文件的id和分组 private final String dataId = "gateway-routes.json"; private final String group = "DEFAULT_GROUP"; // 保存更新过的路由id private final Set<String> routeIds = new HashSet<>(); //order-service ... @PostConstruct public void initRouteConfigListener() throws NacosException { // 1.注册监听器并首次拉取配置 String configInfo = nacosConfigManager.getConfigService() .getConfigAndSignListener(dataId, group, 5000, new Listener() { @Override public Executor getExecutor() { return null; } @Override public void receiveConfigInfo(String configInfo) { updateConfigInfo(configInfo); } }); // 2.首次启动时,更新一次配置 updateConfigInfo(configInfo); } private void updateConfigInfo(String configInfo) { log.debug("监听到路由配置变更,{}", configInfo); // 1.反序列化 List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class); // 2.更新前先清空旧路由 // 2.1.清除旧路由 for (String routeId : routeIds) { writer.delete(Mono.just(routeId)).subscribe(); } routeIds.clear(); // 2.2.判断是否有新的路由要更新 if (CollUtils.isEmpty(routeDefinitions)) { // 无新路由配置,直接结束 return; } // 3.更新路由 routeDefinitions.forEach(routeDefinition -> { // 3.1.更新路由 writer.save(Mono.just(routeDefinition)).subscribe(); // 3.2.记录路由id,方便将来删除 routeIds.add(routeDefinition.getId()); }); } } 可以在项目启动时先更新一次路由,后续随着配置变更通知到监听器,完成路由更新。 服务保护 服务保护方案 1)请求限流 限制或控制接口访问的并发流量,避免服务因流量激增而出现故障。 2)线程隔离 为了避免某个接口故障或压力过大导致整个服务不可用,我们可以限定每个接口可以使用的资源范围,也就是将其“隔离”起来。 3)服务熔断 线程隔离虽然避免了雪崩问题,但故障服务(商品服务)依然会拖慢购物车服务(服务调用方)的接口响应速度。 所以,我们要做两件事情: 编写服务降级逻辑:就是服务调用失败后的处理逻辑,根据业务场景,可以抛出异常,也可以返回友好提示或默认数据。 异常统计和熔断:统计服务提供方的异常比例,当比例过高表明该接口会影响到其它服务,应该拒绝调用该接口,而是直接走降级逻辑。 无非就是停止无意义的等待,直接返回Fallback方案。 Sentinel 介绍和安装 Sentinel是阿里巴巴开源的一款服务保护框架,quick-start | Sentinel 特性 Sentinel (阿里巴巴) Hystrix (网飞) 线程隔离 信号量隔离 线程池隔离 / 信号量隔离 熔断策略 基于慢调用比例或异常比例 基于异常比率 限流 基于 QPS,支持流量整形 有限的支持 Fallback 支持 支持 控制台 开箱即用,可配置规则、查看秒级监控、机器发现等 不完善 配置方式 基于控制台,重启后失效 基于注解或配置文件,永久生效 安装: 1)下载jar包 https://github.com/alibaba/Sentinel/releases 2)将jar包放在任意非中文、不包含特殊字符的目录下,重命名为sentinel-dashboard.jar 然后运行如下命令启动控制台: java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar 3)访问http://localhost:8090页面,就可以看到sentinel的控制台了 账号和密码,默认都是:sentinel 微服务整合 1)引入依赖 <!--sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> 2)配置控制台 修改application.yaml文件(可以用共享配置nacos),添加如下: spring: cloud: sentinel: transport: dashboard: localhost:8090 我们的SpringMVC接口是按照Restful风格设计,因此购物车的查询、删除、修改等接口全部都是/carts路径。默认情况下Sentinel会把路径作为簇点资源的名称,无法区分路径相同但请求方式不同的接口。 可以在application.yml中添加下面的配置 然后,重启服务 spring: cloud: sentinel: transport: dashboard: localhost:8090 http-method-specify: true # 开启请求方式前缀 OpenFeign整合Sentinel 默认sentinel只会整合spring mvc中的接口。 修改cart-service模块的application.yml文件,可开启Feign的sentinel功能: feign: sentinel: enabled: true # 开启feign对sentinel的支持 调用的别的服务(/item-service)的接口也会显示在这。 限流: 直接在sentinel控制台->簇点链路->流控 里面设置QPS 线程隔离 阈值类型选 并发线程数 ,代表这个接口所能用的线程数。 Fallback 触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,采用FallbackFactory,可以对远程调用的异常做处理。 业务场景:购物车服务需要同时openFeign调用服务B和商品服务,现在对商务服务做了线程隔离,在高并发的时候,会疯狂抛异常,现在做个fallback让它返回默认值。 步骤一:在hm-api模块中给ItemClient定义降级处理类,实现FallbackFactory: public class ItemClientFallback implements FallbackFactory<ItemClient> { @Override public ItemClient create(Throwable cause) { return new ItemClient() { @Override public List<ItemDTO> queryItemByIds(Collection<Long> ids) { log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause); // 查询购物车允许失败,查询失败,返回空集合 return CollUtils.emptyList(); } @Override public void deductStock(List<OrderDetailDTO> items) { // 库存扣减业务需要触发事务回滚,查询失败,抛出异常 throw new BizIllegalException(cause); } }; } } 步骤二:在hm-api模块中的com.hmall.api.config.DefaultFeignConfig类中将ItemClientFallback注册为一个Bean: @Bean public ItemClientFallback itemClientFallback(){ return new ItemClientFallback(); } 步骤三:在hm-api模块中的ItemClient接口中使用ItemClientFallbackFactory: @FeignClient(value = "item-service",fallbackFactory = ItemClientFallback.class) public interface ItemClient { @GetMapping("/items") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); } 重启后,再次测试 熔断器 分布式事务 场景:订单服务依次调用了购物车服务和库存服务,它们各自操作不同的数据库。当清空购物车操作成功、库存扣减失败时,订单服务能捕获到异常,却无法通知已完成操作的购物车服务,导致数据不一致。虽然每个微服务内部都能保证本地事务的 ACID 特性,但跨服务调用缺乏全局协调,无法实现端到端的一致性。 Seeta 要解决这个问题,只需引入一个统一的事务协调者,负责跟每个分支通信,检测状态,并统一决定全局提交或回滚。 在 Seata 中,对应三大角色: TC(Transaction Coordinator)事务协调者 维护全局事务和各分支事务的状态,负责发起全局提交或回滚指令。 TM(Transaction Manager)事务管理器 定义并启动全局事务,最后根据应用调用决定调用提交或回滚。 RM(Resource Manager)资源管理器 嵌入到各微服务中,负责注册分支事务、上报执行结果,并在接到 TC 指令后执行本地提交或回滚。 其中,TM 和 RM 作为客户端依赖,直接集成到业务服务里;TC 则是一个独立部署的微服务,承担全局协调的职责。这样,无论有多少分支参与,都能保证“要么都成功、要么都回滚”的一致性。 部署TC服务 1)准备数据库表 seata-tc.sql 运行初始化脚本 2)准备配置文件 3)Docker部署 seeta-server: image: seataio/seata-server:1.5.2 container_name: seata-server restart: unless-stopped depends_on: - mysql - nacos environment: # 指定 Seata 注册中心和配置中心地址 - SEATA_IP=192.168.0.107 # IDEA 可以访问到的宿主机 IP - SEATA_SERVICE_PORT=17099 - SEATA_CONFIG_TYPE=file # 可视情况再加:SEATA_NACOS_SERVER_ADDR=nacos:8848 networks: - hmall-net ports: - "17099:7099" # TC 服务端口 - "8099:8099" # 服务管理端口(Console) volumes: - ./seata:/seata-server/resources 微服务集成Seata 1)引入依赖 <!--统一配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> <!--seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency> 2)在nacos上添加一个共享的seata配置,命名为shared-seata.yaml,你在bootstrap中引入该配置即可: seata: registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址 type: nacos # 注册中心类型 nacos nacos: server-addr: 192.168.0.107:8848 # 替换为自己的nacos地址 namespace: "" # namespace,默认为空 group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP application: seata-server # seata服务名称 username: nacos password: nacos tx-service-group: hmall # 事务组名称 service: vgroup-mapping: # 事务组与tc集群的映射关系 hmall: "default" 这段配置是告诉你的微服务如何去「找到并使用」Seata 的 TC(Transaction Coordinator)服务,以便在本地发起、提交或回滚分布式事务。 XA模式 XA模式的优点是什么? 事务的强一致性,满足ACID原则 常用数据库都支持,实现简单,并且没有代码侵入 XA模式的缺点是什么? 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差 依赖关系型数据库实现事务 实现方式 1)在Nacos中的共享shared-seata.yaml配置文件中设置: seata: data-source-proxy-mode: XA 2)利用@GlobalTransactional标记分布式事务的入口方法 @GlobalTransactional public Long createOrder(OrderFormDTO orderFormDTO) { ... } 3)子事务中方法前添加@Transactional ,方便回滚 AT模式 简述AT模式与XA模式最大的区别是什么? XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。 XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。 XA模式强一致;AT模式最终一致(存在短暂不一致) 实现方式: 1)为需要的微服务数据库中创建undo_log表 -- for AT mode you must to init this sql for you business database. the seata server not need it. CREATE TABLE IF NOT EXISTS `undo_log` ( `branch_id` BIGINT NOT NULL COMMENT 'branch transaction id', `xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id', `context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization', `rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info', `log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status', `log_created` DATETIME(6) NOT NULL COMMENT 'create datetime', `log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime', UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table'; 2)微服务的配置中设置(其实不设置,默认也是AT模式) seata: data-source-proxy-mode: AT
后端学习
zy123
1年前
0
47
0
2025-03-21
Java笔记本
Java笔记本 IDEA基础操作 Intellij Idea创建Java项目: 创建空项目 创建Java module 创建包 package edu.whut.xx 创建类,类名首字母必须大写! IDEA快捷键: Ctrl + L 格式化代码 Ctrl + / 注释/取消注释当前行 Ctrl + D 复制当前行或选中的代码块 Ctrl + N 查找类 shift+shift 在文件中查找代码 alt+ enter “意图操作” “快捷修复” 可以1:service接口类跳转到实现 2:补全函数的返回值 调试快捷键: 快捷键 功能 Shift + F9 调试当前程序 F8 单步执行(不进入方法) F7 单步执行(进入方法) Shift + F8 跳出当前方法 Alt + F9 运行到光标处 Ctrl + F2 停止调试 缩写 生成的代码 说明 psvm public static void main(String[] args) {} 生成 main 方法 sout System.out.println(); 打印到控制台 fori for (int i = 0; i < ; i++) {} 生成 for 循环 iter for (Type item : iterable) {} 生成增强 for 循环 new Test().var Test test = new Test(); 自动补全变量声明 从exsiting file中导入模块: 方法一:复制整个模块到项目文件夹,并导入模块的 *.iml 文件,这种方式保留了模块原有的配置信息。 方法二:新建一个模块,然后将原模块的 src 文件夹下的包复制过去,这种方式更灵活,可以手动调整模块设置。 删除模块: 模块右键,remove module,这只是把它从项目中移除,然后!!打开模块所在文件夹,物理删除,才是真正完全删除。 Java基础 二进制:0b 八进制:0 十六进制:0x 在 System.out.println() 方法中,"ln" 代表 "line",表示换行。因此,println 实际上是 "print line" 的缩写。这个方法会在输出文本后自动换行. System.out.println("nihao "+1.3331); #Java 会自动将数值转换为字符串 一维数组创建: // 方式1:先声明,再指定长度(默认值为0、null等) int[] arr1 = new int[10]; // 创建一个长度为10的int数组 // 方式2:使用初始化列表直接创建数组 int[] arr2 = {1, 2, 3, 4, 5}; // 创建并初始化一个包含5个元素的int数组 String[] strs = {"eat", "tea", "tan", "ate", "nat", "bat"}; // 方式3:结合new关键字和初始化列表创建数组(常用于明确指定类型时) int[] arr3 = new int[]{1, 2, 3, 4, 5}; // 与方式2效果相同 字符串创建 String str = "Hello, World!"; //(1)直接赋值 String str = new String("Hello, World!"); //使用 new 关键字 char[] charArray = {'H', 'e', 'l', 'l', 'o'}; String str = new String(charArray); //通过字符数组创建 switch-case public class SwitchCaseExample { public static void main(String[] args) { // 定义一个 int 类型变量,作为 switch 的表达式 int day = 3; String dayName; // 根据 day 的值执行相应的分支 switch(day) { case 1: dayName = "Monday"; // 当 day 为 1 时 break; // 结束当前 case case 2: dayName = "Tuesday"; // 当 day 为 2 时 break; case 3: dayName = "Wednesday"; // 当 day 为 3 时 break; case 4: dayName = "Thursday"; // 当 day 为 4 时 break; case 5: dayName = "Friday"; // 当 day 为 5 时 break; case 6: dayName = "Saturday"; // 当 day 为 6 时 break; case 7: dayName = "Sunday"; // 当 day 为 7 时 break; default: // 如果 day 不在 1 到 7 之间 dayName = "Invalid day"; } // 输出最终结果 System.out.println("The day is: " + dayName); } } 强制类型转换 double sqrted=Math.sqrt(n); int soft_max=(int) sqrted; Math库常用方法 Math.pow(3, 2)); Math.sqrt(9)); Math.abs(a)); Math.max(a, b)); Math.min(a, b)); 转义符的作用 防止字符被误解: 在字符串中,一些字符(如 " 和 \)有特殊的含义。例如,双引号用于标识字符串的开始和结束,反斜杠通常用于转义。所以当你希望在字符串中包含这些特殊字符时,你需要使用转义符来告诉解析器这些字符是字符串的一部分,而不是特殊符号。 例如,\" 表示在字符串中包含一个双引号字符,而不是字符串的结束标志。 "Hello \"World\"" => 结果是:Hello "World" (双引号被转义) "C:\\Program Files\\App" => 结果是:C:\Program Files\App(反斜杠被转义) 如果只是"C:\Program Files\App" 那么路径就会报错 表示非打印字符: 转义符可以用于表示一些不可见的或非打印的控制字符,如换行符(\n)、制表符(\t)等。这些字符无法直接通过键盘输入,所以使用转义符来表示它们。 枚举 //纯状态枚举 常见于 switch-case、简单条件判断。 public enum OperationType { /** * 更新操作 */ UPDATE, /** * 插入操作 */ INSERT } OperationType opType = OperationType.INSERT; // 声明并初始化 public void execute(OperationType type, Object entity) { switch (type) { case INSERT: insertEntity(entity); break; case UPDATE: updateEntity(entity); break; default: throw new IllegalArgumentException("Unsupported operation: " + type); } } // 携带数据的枚举, 适合“常量 + 不变数据”的场景,如 星期、货币、错误码等。 public enum DayOfWeek { //创建7个 DayOfWeek 类型的对象,分别传入构造参数chineseName和dayNumber,它们叫“枚举常量” MONDAY("星期一", 1), TUESDAY("星期二", 2), WEDNESDAY("星期三", 3), THURSDAY("星期四", 4), FRIDAY("星期五", 5), SATURDAY("星期六", 6), SUNDAY("星期日", 7); // 枚举属性 private final String chineseName; private final int dayNumber; // 构造方法 DayOfWeek(String chineseName, int dayNumber) { this.chineseName = chineseName; this.dayNumber = dayNumber; } // 方法 public String getChineseName() { return chineseName; } public int getDayNumber() { return dayNumber; } } // 使用示例 public class Main { public static void main(String[] args) { DayOfWeek today = DayOfWeek.MONDAY; System.out.println(today.getChineseName()); // 输出: 星期一 System.out.println(today.getDayNumber()); // 输出: 1 } } 枚举类的构造方法必须是 private的,默认就是private的,这意味着只能在枚举内部使用这个构造方法。 枚举类你只需要使用,而不用创建对象,类内部已经定义好了MONDAY、TUESDAY...对象。 Java传参方式 基本数据类型 传递方式:按值传递 每次传递的是变量的值的副本**,对该值的修改不会影响原变量**。例如:int、double、boolean 等类型。 引用类型(对象) 传递方式:对象引用的副本传递 传递的是对象引用的一个副本,指向同一块内存区域。因此,方法内部通过该引用修改对象的状态,会影响到原对象。如数组、集合、String、以及其他所有对象类型。 Integer 属于引用类型,变量 Integer a = 10;中的 a是一个引用,它指向堆中存储的 Integer对象。 注意 StringBuilder s = new StringBuilder(); s.append("hello"); String res = s.toString(); // res = "hello" s.append(" world"); // s = "hello world" System.out.println(res); // 输出还是 "hello" 浅拷贝深拷贝 不可变对象 一个对象一旦被创建并初始化,它的状态(其内部代表的数据)就再也无法被改变,如Integer、String。 不可变”在代码中的具体表现:所有修改操作都返回新对象 String s1 = "Hello"; String s2 = s1.concat(" World"); // 不是修改s1,而是创建新字符串 字符串常量池 String a = "1"; String b = "1"; 变量 a和变量 b会指向同一个内存中的 String对象。 原理:常量池中有,就直接返回其引用;没有,就创建一个放进去再返回。 存放位置: Java 7 之前:字符串常量池逻辑上属于方法区(Method Area) 的运行时常量池(Runtime Constant Pool) 的一部分。而方法区的具体实现是 永久代(PermGen)。 问题:永久代大小有限且难以调整,容易发生 OutOfMemoryError: PermGen space。 Java 7 开始:字符串常量池被从永久代移动到了 Java 堆(Heap) 中。 Java 8 及以后:永久代被彻底移除,取而代之的是元空间(Metaspace)(用于存类元信息、方法码等)。而字符串常量池依然留在堆中。 浅拷贝 拷贝对象本身,但内部成员(例如集合中的元素)只是复制引用,新旧对象的内部成员指向同一份内存。如果内部元素是不可变的(如 Integer、String 等),这种拷贝通常足够。如果元素是可变对象,修改其中一个对象可能会影响另一个。 回溯法用的就是浅拷贝,因为List<Integer> path; 中间的Integer是不可变对象。 List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); //new ArrayList<>(list)的底层行为: //1.新建一个空的 ArrayList实例。 //2.将原集合 list中的所有元素引用逐个复制到新集合中。 //3.返回这个新集合。 //4.新集合和原集合是两个完全独立的容器,只是内容(元素引用)相同。 List<Integer> shallowCopy = new ArrayList<>(list); 可变对象,浅拷贝修改对象会出错! List<Box> list = new ArrayList<>(); list.add(new Box(1)); list.add(new Box(2)); list.add(new Box(3)); List<Box> shallowCopy = new ArrayList<>(list); shallowCopy.get(0).value = 10; // 修改 shallowCopy 中第一个 Box 的 value System.out.println(list); // 输出: [10, 2, 3],因为同一 Box 对象被修改 System.out.println(shallowCopy); // 输出: [10, 2, 3] 深拷贝 不仅复制对象本身,还递归地复制其所有内部成员,从而生成一个完全独立的副本。即使内部元素是可变的,修改新对象也不会影响原始对象。 // 深拷贝 List<MyObject> 的例子 List<MyObject> originalList = new ArrayList<>(); originalList.add(new MyObject(10)); originalList.add(new MyObject(20)); List<MyObject> deepCopy = new ArrayList<>(); for (MyObject obj : originalList) { deepCopy.add(new MyObject(obj)); // 每个元素都创建一个新的对象 } 日期 在Java中: 代表年月日的类型是 LocalDate。LocalDate 类位于 java.time 包下,用于表示没有时区的日期,如年、月、日。 代表年月日时分秒的类型是 LocalDateTime。LocalDateTime 类也位于 java.time 包下,用于表示没有时区的日期和时间,包括年、月、日、时、分、秒。 LocalDateTime.now(),获取当前时间 静态成员变量与静态方法 一、静态成员变量 静态成员变量使用 static 修饰,属于类级别,而非对象,即所有对象共享同一份静态变量。 在类加载时完成初始化,且只执行一次。 可以通过类名直接访问,无需创建对象。 二、静态变量的初始化方式 1)静态代码块,用于对静态变量进行复杂初始化,在类第一次加载到 JVM 时执行一次。 public class MyClass { static int num1, num2; static { num1 = 1; System.out.println("静态代码块1执行"); } static { num2 = 3; System.out.println("静态代码块2执行"); } public static void main(String[] args) { System.out.println("main方法执行"); } } 输出: 静态代码块1执行 静态代码块2执行 main方法执行 类加载时按代码顺序依次执行所有静态代码块。 由于 main() 是静态方法,调用前类已被加载,因此静态代码块先执行。 示例 2:静态代码块 vs 构造方法 class Demo { static { System.out.println("静态代码块"); } Demo() { System.out.println("构造方法"); } } public class Test { public static void main(String[] args) { System.out.println("main开始"); Demo d1 = new Demo(); Demo d2 = new Demo(); } } 输出: main开始 静态代码块 构造方法 构造方法 说明:静态代码块仅在类首次加载时执行一次,构造方法在每次 new 对象时执行。 2)声明时直接初始化 public class MyClass { public static int staticVariable = 42; } 类加载时 staticVariable 直接被赋值为 42。 3)通过静态方法赋值(运行时) public class GlobalCounter { public static int currentCount; public static void initializeCounter(int startValue) { currentCount = startValue; } public static void incrementCounter() { currentCount++; } } public class Main { public static void main(String[] args) { GlobalCounter.initializeCounter(100); System.out.println(GlobalCounter.currentCount); // 输出 100 GlobalCounter.incrementCounter(); System.out.println(GlobalCounter.currentCount); // 输出 101 } } 只有 静态方法 才能在不创建对象的情况下访问或修改静态变量。 三、静态方法 用 static 修饰的方法,属于类本身,不依赖任何实例。 通过类名直接调用,无需创建对象。 public class MathUtils { public static int square(int n) { return n * n; } } int result = MathUtils.square(5); // 直接通过类名调用 四、访问静态成员变量 int value = MyClass.staticVariable; // ✅ 推荐 MyClass obj = new MyClass(); System.out.println(obj.staticVariable); // ✅ 可行,但不推荐 静态成员属于类,与对象无关;推荐使用类名访问。 变量修饰符final、static... 在Java中,变量的修饰符应该按照规定的顺序出现,通常是这样的: 访问修饰符:public、protected、private,或者不写(默认为包级访问)。 非访问修饰符:final、static、abstract、synchronized、volatile等。 数据类型:变量的数据类型,如 int、String、class 等。 变量名:变量的名称。 public static final int MAX_COUNT = 100; #定义常量 protected static volatile int counter; #定义成员变量 虽然final、static都是非访问修饰符,但是一般都是 static final ,不推荐反过来!!! final关键字 final 关键字,意思是最终的、不可修改的,最见不得变化 ,用来修饰类、方法和变量,具有以下特点: 修饰类:类不能继承,final 类中的所有成员方法都会被隐式的指定为 final 方法; 修饰变量:该变量为常量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能让其指向另一个对象。 修饰符方法:方法不能重写 全限定名 全限定名(Fully Qualified Name,简称 FQN)指的是一个类或接口在 Java 中的完整名称,包括它所在的包名。例如: 对于类 Integer,其全限定名是 java.lang.Integer。 对于自定义的类 DeptServiceImpl,如果它位于包 edu.zju.zy123.service.impl 中,那么它的全限定名就是 edu.zju.zy123.service.impl.DeptServiceImpl。 使用全限定名可以消除歧义,确保指定的类型在整个项目中唯一无误。 使用场景: Spring AOP 的 Pointcut 表达式 MyBatis的XML映射文件的namespace属性 synchronized 概念 它的核心在于选择一个对象作为“锁”(也称为“监视器”或“互斥量”)。 synchronized (lockObject) { // 需要同步的代码块(临界区) } lockObject:这是一个对象引用,它作为锁。任何Java对象都可以充当锁。 { ... }:大括号内的代码就是“临界区”。JVM保证同一时刻,只有一个线程可以持有 lockObject这把锁并执行临界区内的代码。其他试图进入的线程必须等待,直到当前线程释放锁。 常见使用形式 类型 写法 锁对象 用途 同步方法(实例) public synchronized void foo() this 保护实例变量 同步方法(静态) public static synchronized void foo() 类对象(ClassName.class) 保护静态变量 同步代码块 synchronized (obj) {...} 任意对象 灵活控制锁粒度 1)同步代码块: class Counter { private int count = 0; private final Object lock = new Object(); public void increment() { synchronized (lock) { count++; System.out.println(Thread.currentThread().getName() + " -> " + count); } } } public class Demo { public static void main(String[] args) { Counter counter = new Counter(); Runnable task = counter::increment; new Thread(task, "A").start(); new Thread(task, "B").start(); } } 2)同步方法 class Counter { private int count = 0; public synchronized void increment() { count++; System.out.println(Thread.currentThread().getName() + " -> " + count); } } public class Test { public static void main(String[] args) { Counter c = new Counter(); for (int i = 0; i < 5; i++) { new Thread(c::increment).start(); } } } synchronized 修饰实例方法时,锁的是当前对象(this)。 同一个对象的同步方法是互斥的。 同一个对象(p1),T1 和 T2 都调用 p1.print(),因为 synchronized 锁的是 p1,所以 T1 和 T2 必须一个执行完,另一个才能进入方法。 不同对象(p2),T3 和 T4 调用的是另一个对象 p2.print() 因此,T1、T2 顺序执行,T3、T4 也顺序执行,它们之间互不影响。 Lambda表达式 函数式接口:有且仅有一个抽象方法的接口。 @FunctionalInterface 注解:这是一个可选的注解,用于表示接口是一个函数式接口。虽然不是强制的,但它可以帮助编译器识别意图,并检查接口是否确实只有一个抽象方法。 这个时候可以用Lambda代替匿名内部类!!! public class LambdaExample { // 定义函数式接口,doSomething 有两个参数 @FunctionalInterface interface MyInterface { void doSomething(int a, int b); } public static void main(String[] args) { // 使用匿名内部类实现接口方法 MyInterface obj = new MyInterface() { @Override public void doSomething(int a, int b) { System.out.println("参数a: " + a + ", 参数b: " + b); } }; obj.doSomething(5, 10); } public static void main(String[] args) { // 使用 Lambda 表达式实现接口方法 MyInterface obj = (a, b) -> { System.out.println("参数a: " + a + ", 参数b: " + b); }; obj.doSomething(5, 10); } } lambda表达式格式:(参数列表) -> { 代码块 }或 (参数列表) ->表达式 如果上述MyInterface接口的doSomething()方法不接受任何参数并且没有返回值: // Lambda 表达式(无参数) MyInterface obj = () -> { System.out.println("doSomething 被调用,无参数!"); }; 以下是lambda表达式的重要特征: 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。 可选的参数圆括号():一个参数无需定义圆括号,但无参数或多个参数需要定义圆括号。 可选的大括号{}:如果主体只有一个语句,可以不使用大括号。 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,使用大括号需显示retrun;如果函数是void则不需要返回值。 // 定义一个函数式接口,只有一个抽象方法 interface Calculator { int add(int a, int b); } public class LambdaReturnExample { public static void main(String[] args) { // 例子1:单个表达式,不使用大括号和 return 关键字 Calculator calc1 = (a, b) -> a + b; System.out.println("calc1: " + calc1.add(5, 3)); // 输出:8 // 例子2:使用大括号,需要显式使用 return 关键字 Calculator calc2 = (a, b) -> { return a + b; }; System.out.println("calc2: " + calc2.add(5, 3)); // 输出:8 } } 示例1: list.forEach这个方法接受一个函数式接口作为参数。它只有一个抽象方法 accept(T t)因此,可以使用 lambda 表达式来实现。 @FunctionalInterface public interface Consumer<T> { void accept(T t); } public class Main { public static void main(String[] args) { List<String> list = Arrays.asList("Apple", "Banana", "Cherry", "Date"); // 使用 Lambda 表达式迭代列表,这段 lambda,就是在“实现” void accept(String item) 这个方法——把每个元素传给 accept,然后打印它。 list.forEach(item -> System.out.println(item)); } } 示例2:为什么可以使用 Lambda 表达式自定义排序? 因为**Comparator<T> 是一个函数式接口**,只有一个抽象方法 compare(T o1, T o2) @FunctionalInterface public interface Comparator<T> { int compare(T o1, T o2); // 唯一的抽象方法 // 其他方法(如 thenComparing、reversed)都是默认方法或静态方法,不影响函数式接口特性 } public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("John", "Jane", "Adam", "Dana"); // 使用Lambda表达式排序 Collections.sort(names, (a, b) -> a.compareTo(b)); // 输出排序结果 names.forEach(name -> System.out.println(name)); } } JAVA面向对象 public class Dog { // 成员变量 private String name; // 构造函数 public Dog(String name) { this.name = name; } // 一个函数:让狗狗“叫” public void bark() { System.out.println(name + " says: Woof! Woof!"); } // (可选)获取狗狗的名字 public String getName() { return name; } // 测试主方法 public static void main(String[] args) { Dog myDog = new Dog("Buddy"); myDog.bark(); // 输出:Buddy says: Woof! Woof! System.out.println("Name: " + myDog.getName()); } } 访问修饰符 public(公共的): 使用public修饰的成员可以被任何其他类访问,无论这些类是否属于同一个包。 例如,如果一个类的成员被声明为public,那么其他类可以通过该类的对象直接访问该成员。 protected(受保护的): 使用protected修饰的成员可以被同一个包中的其他类访问,也可以被不同包中的子类访问。 与包访问级别相比,protected修饰符提供了更广泛的访问权限。 default (no modifier)(默认的,即包访问级别): 如果没有指定任何访问修饰符,则默认情况下成员具有包访问权限。 在同一个包中的其他类可以访问默认访问级别的成员,但是在不同包中的类不能访问。 private(私有的): 使用private修饰的成员只能在声明它们的类内部访问,其他任何类(子类也不行!)都不能访问这些成员。 这种访问级别提供了最高的封装性和安全性。 如果您在另一个类中实例化了包含私有成员的类,那么您无法直接访问该类的私有成员。但是,您可以通过公共方法来间接地访问和操作私有成员。 public class PrivateExample { private int privateVar = 30; // 公共方法,用于访问私有成员 public int getPrivateVar() { return privateVar; } } 则每个实例都有自己的一份拷贝,只有当变量被声明为 static 时,变量才是类级别的,会被所有实例共享。 修饰符不仅可以用来修饰成员变量和方法,也可以用来修饰类。顶级类只能使用 public 或默认(即不写任何修饰符,称为包访问权限)。内部类可以使用所有访问修饰符(public、protected、private 和默认),这使得你可以更灵活地控制嵌套类的访问范围。 public class OuterClass { // 内部类使用private,只能在OuterClass内部访问 private class InnerPrivateClass { // ... } // 内部类使用protected,同包以及其他包中的子类可以访问 protected class InnerProtectedClass { // ... } // 内部类使用默认访问权限,只在同包中可见 class InnerDefaultClass { // ... } // 内部类使用public,任何地方都可访问(但访问时需要通过OuterClass对象) public class InnerPublicClass { // ... } } JAVA三大特性 封装 封装指隐藏对象的状态信息(属性),不允许外部对象直接访问对象的内部信息(private实现)。但是可以提供一些可以被外界访问的方法(public)来操作属性。 优点:隐藏内部实现细节,提升安全性。 继承 [修饰符] class 子类名 extends 父类名{ 类体部分 } //class C extends A, B // 错误:C 不能同时继承 A 和 B Java只支持单继承,不支持多继承。一个类只能有一个父类,不可以有多个父类。 Java支持多层继承(A → B → C )。 Java继承了父类非私有的成员变量和成员方法,但是请注意:子类是无法继承父类的构造方法的。 优点:实现代码复用,减少重复代码。子类可以在继承基础上扩展或修改功能。 多态 指在面向对象编程中,同样的消息(方法调用)可以在不同的对象上触发不同的行为。 方法重写(Override):动态多态;子类从父类继承的某个实例方法无法满足子类的功能需要时,需要在子类中对该实例方法进行重新实现,这样的过程称为重写,也叫做覆写、覆盖。 要求: 必须存在继承关系(子类继承父类)。 子类重写的方法的访问修饰符不能比父类更严格(可以相同或更宽松)。 方法名、参数列表和返回值类型必须与父类中的方法完全相同(Java 5 以后支持协变返回类型,即允许返回子类型)。 向上转型(Upcasting):动态多态;子类对象可以赋值给父类引用,这样做可以隐藏对象的真实类型,只能调用父类中声明的方法。 class Animal { public void makeSound() { System.out.println("Animal makes sound"); } } class Dog extends Animal { @Override public void makeSound() { System.out.println("Dog barks"); } public void fetch() { System.out.println("Dog fetches the ball"); } } public class Test { public static void main(String[] args) { Animal animal = new Dog(); // 向上转型 animal.makeSound(); // 调用的是 Dog 重写的 makeSound() 方法 // animal.fetch(); // 编译错误:Animal 类型没有 fetch() 方法 } } 多态实现总结:继承 + 重写 + 父类引用指向子类对象 = 多态 方法重载(Overload):静态多态;方法名相同但参数列表不同。当调用这些方法时,会根据传递的参数类型或数量选择相应的方法。 参数类型不同;参数数量不同:参数顺序不同;返回类型可以不同,但仅返回类型不同不构成重载 void print(int a) { ... } void print(String a) { ... } // 合法重载 void log(String msg) { ... } void log(String msg, int level) { ... } // 合法重载 void save(int id, String name) { ... } void save(String name, int id) { ... } // 合法重载 优点:提高代码的灵活性和可扩展性。通过统一接口调用不同实现,提高可替换性。 继承与super关键字 类加载与对象实例化顺序 class Parent { static { System.out.println("A"); } Parent() { System.out.println("B"); } } class Child extends Parent { static { System.out.println("C"); } Child() { System.out.println("D"); } } 加载类时: A // 父类静态块先执行 C // 再执行子类静态块 实例化子类对象时: B // 父类构造函数先执行 D // 再执行子类构造函数 记忆口诀:静态先父后子,构造先父后子。(析构则相反,先子后父) new Child()的时候-> 输出顺序为 ACBD Super关键字 super 用于在子类中访问父类的内容: 1)访问父类的成员 当子类与父类存在同名成员时,子类中的成员会**隐藏(shadow)**父类的同名成员。可用 super 显式访问父类版本。 2)调用父类的构造方法 创建子类对象时,一定会先调用父类构造函数。若父类没有无参构造函数,则子类必须显式调用父类构造函数,否则编译报错。使用 super(参数) 调用父类构造方法。 示例: class Parent { int num = 10; Parent(int num) { this.num = num; System.out.println("Parent constructor: num = " + num); } void display() { System.out.println("Parent method"); } } class Child extends Parent { int num = 20; Child(int num) { super(num); // 调用父类构造函数 System.out.println("Child constructor: num = " + num); } void print() { System.out.println("Child num: " + num); // 子类字段 System.out.println("Parent num: " + super.num); // 父类字段 super.display(); // 调用父类方法 } } public class Main { public static void main(String[] args) { Child obj = new Child(30); System.out.println("---- 调用 print() ----"); obj.print(); } } 运行结果: Parent constructor: num = 30 Child constructor: num = 30 ---- 调用 print() ---- Child num: 20 Parent num: 30 Parent method 注意:若父类定义了构造函数(无论是否有参),编译器不会再自动生成默认无参构造函数。 如果父类仅有有参构造函数,子类必须显式调用 super(...) 来选择合适的父类构造函数。 如果有有参+无参,那子类可以不显示调用super(...),系统会自动帮你调用父类的无参构造函数。 抽象类 用 abstract 修饰的类,不能被实例化。可以包含抽象方法(无方法体)和具体方法(有实现)。抽象类可以实现接口,也可以继续保持抽象。 注意:抽象类可以一个抽象方法都没有。 abstract class Animal { public abstract void makeSound(); // 抽象方法 public void sleep() { // 普通方法 System.out.println("Sleeping..."); } } class Dog extends Animal { @Override public void makeSound() { System.out.println("Dog barks"); } } 如何使用抽象类 由于抽象类不能直接实例化,我们通常有两种方法来使用抽象类: 通过子类继承并实现抽象方法: Animal animal = new Dog(); animal.makeSound(); // 输出:Dog barks 使用匿名内部类 Animal a = new Animal() { @Override public void makeSound() { System.out.println("Anonymous sound"); } }; 如何算作实现抽象方法 抽象类的子类必须实现全部抽象方法,否则该子类也必须声明为抽象类。 实现接口时,可选择性实现方法,未实现的交由子类完成。 接口 一组行为规范或契约。接口中的变量默认是 public static final 常量。方法默认是 public abstract(Java 8 之后可包含 default 和 static 方法)。 interface SmartDevice { String DEFAULT_BRAND = "Generic"; void turnOn(); // 抽象方法 default void updateFirmware() { System.out.println("Updating firmware..."); } static void checkConnection() { System.out.println("Checking network..."); } } class SmartLight implements SmartDevice { @Override public void turnOn() { System.out.println("Light is on"); } } 接口特性 支持 多继承(一个类可以实现多个接口)。 接口之间可以使用 extends 继承。 默认方法(default)可提供接口级的默认实现。 抽象类 vs 接口 特性 抽象类 接口 关键字 abstract + class interface 实例化 ❌ 不能 ❌ 不能 方法类型 抽象 + 具体 抽象(默认)、默认方法、静态方法 变量 普通成员变量 public static final 常量 继承 extends(单继承) implements(多实现) 关系 可实现接口 可被类实现、可继承接口 适用场景 表示**“是什么”**(共性与实现) 表示**“能做什么”**(行为约定) 四种内部类 1.成员内部类 定义位置:成员内部类定义在外部类的成员位置。 访问权限:可以无限制地访问外部类的所有成员,包括私有成员、静态成员变量。 实例化方式:需要先创建外部类的实例,然后才能创建内部类的实例。 修改限制:不能有静态字段和静态方法(除非声明为常量final static)。成员内部类属于外部类的一个实例,不能独立存在于类级别上。 用途:适用于内部类与外部类关系密切,需要频繁访问外部类成员的情况。 public class Outer { private static int staticVar = 10; // 外部类静态变量 private int instanceVar = 20; // 外部类实例变量 // 非静态内部类 class Inner { void print() { System.out.println("静态变量: " + staticVar); // 直接访问外部类静态变量 System.out.println("实例变量: " + instanceVar); // 直接访问外部类实例变量 } } public static void main(String[] args) { Outer outer = new Outer(); Outer.Inner inner = outer.new Inner(); // 创建内部类实例 inner.print(); } } 易错题: class A { static class B { void hello() { System.out.println("hello from static A.B"); } } } class C implements A.B { public void hello() { System.out.println("hello from C"); } } 会编译报错,A.B 是一个 非静态内部类(inner class),它隐式地依赖外部类 A 的实例。 2.静态内部类 没有静态类,但是有静态内部类! 定义位置:定义在外部类内部,但使用static修饰。 访问权限:只能直接访问外部类的静态成员,访问非静态成员需要通过外部类实例。 实例化方式:可以直接创建,不需要外部类的实例。 修改限制:可以有自己的静态成员。 用途:适合当内部类工作不依赖外部类实例时使用,常用于实现与外部类关系不那么密切的帮助类。 public class Solution { // 外部类的静态成员 private static String author = "AlgoMaster"; // 外部类的实例成员 private int solveCount = 0; // 静态内部类:二叉树节点 public static class TreeNode { int val; TreeNode left, right; TreeNode(int val) { this.val = val; } public void showInfo() { // ✅ 可以直接访问外部类的静态成员 System.out.println("Created by: " + author); // ❌ 不能直接访问外部类的实例成员 // System.out.println("solveCount: " + solveCount); } // 算法函数:递归求最大深度 public int maxDepth(TreeNode root) { solveCount++; // 访问实例成员 if (root == null) return 0; return 1 + Math.max(maxDepth(root.left), maxDepth(root.right)); } // 测试 public static void main(String[] args) { // ✅ 静态内部类可以脱离外部类实例独立创建 TreeNode root = new TreeNode(1); root.left = new TreeNode(2); root.right = new TreeNode(3); root.left.left = new TreeNode(4); // 展示静态内部类对外部类成员的访问特性 root.showInfo(); // 使用外部类实例来跑算法 Solution sol = new Solution(); System.out.println("Max Depth: " + sol.maxDepth(root)); // 输出 3 } } 如果把辅助类直接写成顶级类,可能导致包里出现一堆“小工具类”。 把它们作为静态内部类放到外部类里,可以让代码结构更紧凑,命名更直观。 例子:在算法题里定义 TreeNode、ListNode 常作为 Solution 的静态内部类。 3.局部内部类 定义位置:局部内部类定义在一个方法或任何块内(如:if语句、循环语句内)。 访问权限:只能访问所在方法的final或事实上的final(即不被后续修改的)局部变量和外部类的成员变量(同成员内部类)。 实例化方式:只能在定义它们的块中创建实例。 修改限制:同样不能有静态字段和方法。 用途:适用于只在方法或代码块中使用的类,有助于将实现细节隐藏在方法内部。 public class OuterClass { public void startThread() { class LocalInnerClass implements Runnable { @override public void run() { System.out.println("局部内部类中的线程正在运行..."); } } LocalInnerClass localInner = new LocalInnerClass(); Thread thread = new Thread(localInner); thread.start(); } public static void main(String[] args) { OuterClass outer = new OuterClass(); outer.startThread(); } } 4.匿名内部类 new 父类/接口() { // 实现或重写方法 @Override void method() { ... } } 在定义的同时直接实例化,而不需要显式地声明一个子类的名称。 用途:适用于创建一次性使用的实例,通常用于接口或抽象类的实现。但匿名内部类并不限于接口或抽象类,只要是非 final 的普通类,都有机会通过匿名内部类来“现场”创建一个它的子类实例。 abstract class Animal { public abstract void makeSound(); } public class Main { public static void main(String[] args) { // 匿名内部类:临时创建一个 Animal 的子类并实例化 Animal dog = new Animal() { // 注意这里的 new Animal() { ... } @Override public void makeSound() { System.out.println("汪汪汪!"); } }; dog.makeSound(); // 输出:汪汪汪! } } 如何理解?可以对比普通子类(显式定义),即显示定义了Dog来继承Animal // 抽象类或接口 abstract class Animal { public abstract void makeSound(); } // 显式定义一个具名的子类 class Dog extends Animal { @Override public void makeSound() { System.out.println("汪汪汪!"); } } public class Main { public static void main(String[] args) { // 实例化具名的子类 Animal dog = new Dog(); dog.makeSound(); // 输出:汪汪汪! } } 容器 Collection 在 Java 中,Collection 是一个接口,它表示一组对象的集合。Collection 接口是 Java 集合框架中最基本的接口之一,定义了一些操作集合的通用方法,例如添加、删除、遍历等。 所有集合类(例如 List、Set、Queue 等)都直接或间接地继承自 Collection 接口。 boolean add(E e):将指定的元素添加到集合中(可选操作)。 boolean remove(Object o):从集合中移除指定的元素(可选操作)。 boolean contains(Object o):如果集合中包含指定的元素,则返回 true。 int size():返回集合中的元素个数。 void clear():移除集合中的所有元素。 boolean isEmpty():如果集合为空,则返回 true。 public class CollectionExample { public static void main(String[] args) { // 创建一个 Collection 对象,使用 ArrayList 作为实现类 Collection<String> fruits = new ArrayList<>(); // 添加元素到集合中 fruits.add("Apple"); fruits.add("Banana"); fruits.add("Cherry"); System.out.println("添加元素后集合大小: " + fruits.size()); // 输出集合大小 // 检查集合是否包含某个元素 System.out.println("集合中是否包含 'Banana': " + fruits.contains("Banana")); // 从集合中移除元素 fruits.remove("Banana"); System.out.println("移除 'Banana' 后集合大小: " + fruits.size()); // 清空集合 fruits.clear(); System.out.println("清空集合后,集合是否为空: " + fruits.isEmpty()); } } Iterator 在 Java 中,Iterator 是一个接口,遍历集合元素。Collection 接口中定义了 iterator() 方法,返回一个 Iterator 对象。 Iterator 接口中包含以下主要方法: hasNext():如果迭代器还有下一个元素,则返回 true,否则返回 false。 next():返回迭代器的下一个元素,并将迭代器移动到下一个位置。 remove():从迭代器当前位置删除元素。该方法是可选的,不是所有的迭代器都支持。 import java.util.ArrayList; import java.util.Iterator; public class Main { public static void main(String[] args) { // 创建一个 ArrayList 集合 ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); int size = list.size(); // 获取列表大小 System.out.println("Size of list: " + size); // 输出 3 // 获取集合的迭代器 Iterator<Integer> iterator = list.iterator(); // 使用迭代器遍历集合并输出元素 while (iterator.hasNext()) { Integer element = iterator.next(); System.out.println(element); } } } ArrayList ArrayList 是 List 接口的一种实现,而 List 接口又继承自 Collection 接口。包括 add()、remove()、contains() 等。 HashSet HashMap // 使用 entrySet() 方法获取 Map 中所有键值对的集合,并使用增强型 for 循环遍历键值对 System.out.println("Entries in the map:"); for (Map.Entry<String, Integer> entry : map.entrySet()) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println("Key: " + key + ", Value: " + value); } PriorityQueue 默认是小根堆,输出1,2,5,8 import java.util.PriorityQueue; public class Main { public static void main(String[] args) { // 创建一个 PriorityQueue 对象 PriorityQueue<Integer> pq = new PriorityQueue<>(); // 添加元素到队列 pq.offer(5); pq.offer(2); pq.offer(8); pq.offer(1); // 打印队列中的元素 System.out.println("Elements in the priority queue:"); while (!pq.isEmpty()) { System.out.println(pq.poll()); } } } offer() 方法用于将元素插入到队列中 poll() 方法用于移除并返回队列中的头部元素 peek() 方法用于返回队列中的头部元素但不移除它。 JAVA异常处理 public class ExceptionExample { // 方法声明中添加 throws 关键字,指定可能抛出的异常类型 public static void main(String[] args) throws SomeException, AnotherException { try { // 可能会抛出异常的代码块 if (someCondition) { throw new SomeException("Something went wrong"); } } catch (SomeException e) { // 处理 SomeException 异常 System.out.println("Caught SomeException: " + e.getMessage()); } catch (AnotherException e) { // 处理 AnotherException 异常 System.out.println("Caught AnotherException: " + e.getMessage()); } finally { // 不管是否发生异常,都会执行的代码块 System.out.println("End of try-catch block"); } } } // 自定义异常类,继承自 Exception 类 public class SomeException extends Exception { // 构造方法,用于设置异常信息 public SomeException(String message) { // 调用父类的构造方法,设置异常信息 super(message); } } JAVA泛型 在类、接口或方法定义时,用类型参数来替代具体的类型,编译时检查类型安全,运行时通过类型擦除映射到原始类型。 <T>: 用于 定义泛型类型。 在 类、接口、方法 的定义中,<T> 是用来指定一个占位符,表示这个类或方法可以接受任何类型。 T 在这里是 类型参数,你可以在类、接口或方法内使用它来代替具体的类型。 public class Box<T> { // <T> 定义了一个泛型类,T 是类型参数 private T value; // 使用 T 来表示某种类型 public void set(T value) { // 使用 T 来表示参数类型 this.value = value; } public T get() { // 使用 T 来表示返回类型 return value; } } 定义一个泛型类 // 定义一个“盒子”类,可以装任何类型的对象 public class Box<T> { private T value; public Box() {} public Box(T value) { this.value = value; } public void set(T value) { this.value = value; } public T get() { return value; } } T 是类型参数(Type Parameter),可任意命名(常见还有 E、K、V 等)。 使用: public class Main { public static void main(String[] args) { // 创建一个只装 String 的盒子 Box<String> stringBox = new Box<>(); stringBox.set("Hello Generics"); String s = stringBox.get(); // 自动类型推断为 String System.out.println(s); // 创建一个只装 Integer 的盒子 Box<Integer> intBox = new Box<>(123); Integer i = intBox.get(); System.out.println(i); } } 定义一个泛型方法 有时候我们只想让某个方法支持多种类型,而不必为此写泛型类,就可以在方法前加上类型声明: public class Utils { //[修饰符] <T> 返回类型 方法名(参数列表) { … } // 泛型方法:打印任意类型的一维数组 public static <T> void printArray(T[] array) { for (T element : array) { System.out.println(element); } } } 方法签名中 <T> 表示这是一个泛型方法,注意这里不是指返回值!!!这个返回值是void!!! 调用时,编译器会根据传入实参自动推断 T。 使用 public class Main { public static void main(String[] args) { String[] names = {"Alice", "Bob", "Charlie"}; Utils.printArray(names); // 等价于 Utils.<String>printArray(names); Integer[] nums = {10, 20, 30}; Utils.printArray(nums); // 等价于 Utils.<Integer>printArray(nums); } } 好用的方法 toString() **Arrays.toString()**转一维数组 **Arrays.deepToString()**转二维数组 这个方法是是用来将数组转换成String类型输出的,入参可以是long,float,double,int,boolean,byte,object 型的数组。 import java.util.Arrays; public class Main { public static void main(String[] args) { // 一维数组示例 int[] oneD = {1, 2, 3, 4, 5}; System.out.println("一维数组输出: " + Arrays.toString(oneD)); // 二维数组示例 int[][] twoD = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; // 使用 Arrays.deepToString() 输出二维数组 System.out.println("二维数组输出: " + Arrays.deepToString(twoD)); } } 自定义对象的toString() 方法 每个 Java 对象默认都有 toString() 方法(可以根据需要覆盖) 当直接打印一个没有重写 toString() 方法的对象时,其输出格式通常为: java.lang.Object@15db9742 当打印重写toString() 方法的对象时: class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{name='" + name + "', age=" + age + "}"; } } public class Main { public static void main(String[] args) { Person person = new Person("Alice", 30); System.out.println(person); //会自动调用对象的 toString() 方法 //Person{name='Alice', age=30} } } 对象拷贝属性 public void save(EmployeeDTO employeeDTO) { Employee employee = new Employee(); //对象属性拷贝 BeanUtils.copyProperties(employeeDTO, employee,"id"); } employeeDTO的内容拷贝给employee,跳过字段为"id"的属性。 StartOrStopDTO dto = new StartOrStopDTO(1, 100L); // 用 Builder 拷贝 id 和 status Employee employee = Employee.builder() .id(dto.getId()) .status(dto.getStatus()) .build(); Java 8 Stream API SpaceUserRole role = SPACE_USER_AUTH_CONFIG.getRoles() .stream() // 1 .filter(r -> r.getKey().equals(spaceUserRole)) // 2 .findFirst() // 3 .orElse(null); // 4 stream() 把 List<SpaceUserRole> 转换成一个 Stream<SpaceUserRole>,Stream 是 Java 8 引入的对集合进行函数式操作的管道。 .filter(r -> r.getKey().equals(spaceUserRole)) filter 接受一个 Predicate<T>(这里是从每个 SpaceUserRole r 中调用 r.getKey().equals(...)),只保留“满足该条件”的元素,其余都丢弃。 .findFirst() 在过滤后的流中,取第一个元素,返回一个 Optional<SpaceUserRole>。即使流是空的,它也会返回一个空的 Optional,而不会抛异常。 .orElse(null) 从 Optional 中取值:如果存在就返回该值,不存在就返回 null。 等价于下面的老式写法(Java 7 及以前): SpaceUserRole role = null; for (SpaceUserRole r : SPACE_USER_AUTH_CONFIG.getRoles()) { if (r.getKey().equals(spaceUserRole)) { role = r; break; } } 类加载器和获取资源文件路径 在Java中,类加载器的主要作用是根据**类路径(Classpath)**加载类文件以及其他资源文件。 启动类加载器(Bootstrap ClassLoader):加载 Java 运行时环境的核心类库,包括 Java 的标准库和 JVM 必须的类,比如 java.lang.* 包中的类。 扩展类加载器:加载 Java 扩展目录中的类库,这些库通常是 ext 目录中的 JAR 文件(例如,$JAVA_HOME/jre/lib/ext/)。 系统类加载器:加载应用程序的类路径(classpath)下的类和资源文件,通常用于加载项目中的类和 JAR 包。 自定义类加载器:这个类加载器是由开发者自定义实现的,用于加载非标准的类或动态加载类。它是 Java 提供的类加载机制的扩展,允许你根据特定需求来自定义类加载的行为。 双亲委派机制的基本原理: 双亲委派机制的核心思想是:一个类加载器在加载类时,首先将请求委托给它的父类加载器,只有当父类加载器无法加载该类时,当前加载器才会自己去加载。 原因: 1.避免类的重复加载 2.保证核心类的安全性,如 java.lang.Object 类等是 Java 核心类库的一部分,必须由启动类加载器(Bootstrap ClassLoader)加载。 类路径是JVM在运行时用来查找类文件和资源文件的一组目录或JAR包。在许多项目(例如Maven或Gradle项目)中,src/main/resources目录下的内容在编译时会被复制到输出目录(如target/classes),src/main/java 下编译后的 class 文件也会放到这里。 src/ ├── main/ │ ├── java/ │ │ └── com/ │ │ └── example/ │ │ └── App.java │ └── resources/ │ ├── application.yml │ └── static/ │ └── logo.png └── test/ ├── java/ │ └── com/ │ └── example/ │ └── AppTest.java └── resources/ └── test-data.json 映射到 target/ 后: target/ ├── classes/ ← 主代码和资源的输出根目录 │ ├── com/ │ │ └── example/ │ │ └── App.class ← 编译自 src/main/java/com/example/App.java │ ├── application.yml ← 复制自 src/main/resources/application.yml │ └── static/ │ └── logo.png ← 复制自 src/main/resources/static/logo.png └── test-classes/ ← 测试代码和测试资源的输出根目录 ├── com/ │ └── example/ │ └── AppTest.class ← 编译自 src/test/java/com/example/AppTest.java └── test-data.json ← 复制自 src/test/resources/test-data.json // 获取 resources 根目录下的 emp.xml 文件路径 String empFileUrl = this.getClass().getClassLoader().getResource("emp.xml").getFile(); // 获取 resources/static 目录下的 tt.img 文件路径 URL resourceUrl = getClass().getClassLoader().getResource("static/tt.img"); String ttImgPath = resourceUrl != null ? resourceUrl.getFile() : null; this.getClass():获取当前对象(即调用该代码的对象)的 Class 对象。 .getClassLoader():获取该 Class 对象的类加载器(ClassLoader)。 .getResource("emp.xml"):从类路径中获取名为 "emp.xml" 的资源,并返回一个 URL 对象,该 URL 对象指向 "emp.xml" 文件的位置。 .getFile():从 URL 对象中获取文件路径部分,即获取 "emp.xml" 文件的绝对路径字符串。 **类路径(Classpath)**是 Java 虚拟机(JVM)用于查找类文件和其他资源文件的一组路径。 是的,类加载器的主要作用之一确实是从类路径中加载类文件(.class 文件)以及其他资源(如图片、配置文件等)。在 Java 项目启动时,类加载器不仅会加载类文件,还会把这些类文件转换为 Java 程序可以使用的 Class 对象,并将它们放入 运行时数据区,即 方法区(Method Area) 和 堆区(Heap)。 反射 反射技术的关键之一是能够在 运行时动态加载 类的字节码并将其转换为 Class 对象,并以编程的方法解刨出类中的各个成分(成员变量、方法、构造器等)。 .class 是静态的文件,加载到内存并解析后,就会创建一个对应的 java.lang.Class 实例即 Class对象,是动态的。 反射技术例子:IDEA通过反射技术就可以获取到类中有哪些方法,并且把方法的名称以提示框的形式显示出来,所以你能看到这些提示了。 获取类的字节码(Class对象) 有三种方法: public class Test1Class{ public static void main(String[] args){ Class c1 = Student.class; System.out.println(c1.getName()); //获取全类名:edu.whut.pojo.Student System.out.println(c1.getSimpleName()); //获取简单类名: Student Class c2 = Class.forName("edu.whut.pojo.Student"); //全类名 System.out.println(c1 == c2); //true Student s = new Student(); Class c3 = s.getClass(); System.out.println(c2 == c3); //true } } 类的 Class 对象(字节码对象)是类的模具,不会直接存放数据。 类的 实例对象obj是用 new 出来的,它代表着 实际的运行时对象,会在堆(Heap)里开辟内存,存放实例字段的数据。每次 new 一下,就会有一个独立的实例,它们共享同一个 Class,但各自的数据独立。 1.获取类的元信息 类名:getName()、getSimpleName()、getPackage() 父类和接口:getSuperclass()、getInterfaces() 修饰符:getModifiers()(配合 Modifier 工具类解析 public、private、abstract 等) 注解:getAnnotation() / getAnnotations() 获取类上的注解!!! 2.获取类的构造器 定义类 public class Cat{ private String name; private int age; public Cat(){} private Cat(String name, int age){ } } 获取构造器列表 public class TestConstructor { @Test public void testGetAllConstructors() { // 1. 获取类的 Class 对象 Class<?> c = Cat.class; // 2. 获取类的全部构造器(包括public、private等) Constructor<?>[] constructors = c.getDeclaredConstructors(); // 3. 遍历并打印构造器信息 for (Constructor<?> constructor : constructors) { System.out.println( constructor.getName() + " --> 参数个数:" + constructor.getParameterCount() ); } } } c.getDeclaredConstructors() 会返回所有声明的构造器(包含私有构造器),而 c.getConstructors() 只会返回公共构造器。 constructor.getParameterCount() 用于获取该构造器的参数个数。 获取某个构造器:指定参数类型! public class Test2Constructor(){ @Test public void testGetConstructor(){ //1、反射第一步:必须先得到这个类的Class对象 Class c = Cat.class; /2、获取private修饰的有两个参数的构造器,第一个参数String类型,第二个参数int类型 Constructor constructor = c.getDeclaredConstructor(String.class,int.class); constructor.setAccessible(true); //禁止检查访问权限,可以使用private构造函数 Cat cat=(Cat)constructor.newInstance("叮当猫",3); //初始化Cat对象 } } c.getDeclaredConstructor(String.class, int.class):根据参数列表获取特定的构造器。 如果构造器是private修饰的,先需要调用setAccessible(true) 表示禁止检查访问控制,然后再调用newInstance(实参列表) 就可以执行构造器,完成对象的初始化了。 Constructor 本身就是用来创建对象实例的,它的职责是生成实例,而不是操作某个已经存在的实例。 3.获取类的成员变量 获取类的成员变量 方法 说明 public Field[] getFields() 获取类的全部成员变量(只能获取 public 修饰的) public Field[] getDeclaredFields() 获取类的全部成员变量(只要存在就能拿到) public Field getField(String name) 获取类的某个成员变量(只能获取 public 修饰的) public Field getDeclaredField(String name) 获取类的某个成员变量(只要存在就能拿到) 设置与获取字段值 方法 说明 void set(Object obj, Object value) 设置字段值 Object get(Object obj) 获取字段值 public void setAccessible(boolean flag) 设置为 true,表示禁止检查访问控制(暴力反射) 不管是设置值还是获取值,都需要: 获取 Field 对象 —— 先通过 Class 对象拿到目标字段的 Field 实例。 指定目标实例 —— 操作字段时必须传入具体的对象实例,告诉 JVM 要修改或读取哪一个对象的该字段。 处理访问权限 —— 如果字段是私有的,需要调用 setAccessible(true) 来关闭 Java 的访问检查(俗称“暴力反射”)。 import java.lang.reflect.Field; public class ReflectionExample { // 示例类 public static class MyClass { public String publicField = "Public Field"; private String privateField = "Private Field"; } public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException { // 创建 MyClass 的实例 MyClass obj = new MyClass(); // 获取 MyClass 的 Class 对象 Class<?> clazz = obj.getClass(); // 获取 public 字段 Field publicField = clazz.getField("publicField"); System.out.println("Public Field: " + publicField.get(obj)); // 获取并输出 publicField 的值 // 获取 private 字段(使用 getDeclaredField) Field privateField = clazz.getDeclaredField("privateField"); // 设置私有字段为可访问(通过 setAccessible) privateField.setAccessible(true); System.out.println("Private Field: " + privateField.get(obj)); // 获取并输出 privateField 的值 // 修改 private 字段的值 privateField.set(obj, "New Private Value"); System.out.println("Updated Private Field: " + privateField.get(obj)); // 获取修改后的值 } } 4.获取类的成员方法 获取单个指定的成员方法:第一个参数填方法名、第二个参数填方法中的参数类型 执行:第一个参数传入一个对象实例,然后是若干方法参数(无参可不写)... 示例:Cat 类与测试类 public class Cat { private String name; public int age; public Cat() { this.name = "Tom"; this.age = 1; } public void meow() { System.out.println("Meow! My name is " + this.name); } private void purr() { System.out.println("Purr... I'm a happy cat!"); } } public class FieldReflectionTest { @Test public void testMethodAccess() throws Exception { // 1. 获取 Cat 类的 Class 对象 Class<?> catClass = Cat.class; // 2. 创建 Cat 对象实例 Cat cat = new Cat(); // ---------------------- // A. 获取并调用 public 方法 // ---------------------- // 获取名为 "meow"、无参数的方法 Method meowMethod = catClass.getMethod("meow"); // 调用该方法 meowMethod.invoke(cat); // ---------------------- // B. 获取并调用 private 方法 // ---------------------- // 获取名为 "purr"、无参数的私有方法 Method purrMethod = catClass.getDeclaredMethod("purr"); purrMethod.setAccessible(true); // 关闭权限检查 purrMethod.invoke(cat); } } 注解 在 Java 中,注解用于给程序元素(类、方法、字段等)添加元数据,这些元数据可被编译器、工具或运行时反射读取,以实现配置、检查、代码生成以及框架支持(如依赖注入、AOP 等)功能,而不直接影响代码的业务逻辑。 比如:Junit框架的 @Test 注解可以用在方法上,用来标记这个方法是测试方法,被@Test标记的方法能够被Junit框架执行。 再比如:@Override 注解可以用在方法上,用来标记这个方法是重写方法,被@Override注解标记的方法能够被IDEA识别进行语法检查。 使用注解 元注解 是修饰注解的注解。 @Retention(RetentionPolicy.SOURCE) //只在源码阶段保留,编译后 `.class` 文件中不会有这个注解信息。 @Retention(RetentionPolicy.RUNTIME) //指定注解的生命周期,即在运行时有效,可用于反射等用途。 @Target(ElementType.TYPE) //类上的注解(包含类、接口、枚举等类型) @Target(ElementType.METHOD) //方法上的注解 @Target(ElementType.FIELD) //字段上的注解 注意,若想在运行时通过反射读取,只能设置@Retention(RetentionPolicy.RUNTIME) 定义注解 使用 @interface 定义注解 // 定义注解 @Retention(RetentionPolicy.RUNTIME) // 生命周期:运行时保留,可反射获取 @Target(ElementType.METHOD) // 目标:作用于方法 public @interface MyAnnotation { String description() default "This is a default description"; int value() default 0; } 用法: // 1. 只传 value,可省略属性名 @MyAnnotation(5) public void someMethod() {} // 2. 多属性赋值必须指明名称 @MyAnnotation(value = 5, description = "Specific description") public void anotherMethod() {} // 3. 使用默认值 @MyAnnotation public void defaultMethod() {} 解析注解 在 Java 中,注解本质上是类的元数据,要在运行时获取注解信息,必须依赖反射 API 来读取。 下面示例展示了如何通过反射获取方法上的自定义注解 @MyAnnotation。 1.定义示例类与注解 // 自定义注解 @Retention(RetentionPolicy.RUNTIME) // 运行时保留,可反射获取 @Target(ElementType.METHOD) // 仅可作用于方法 public @interface MyAnnotation { String value(); } // 使用注解 public class MyClass { @MyAnnotation(value = "specific value") public void myMethod() { // 方法实现 } } 2.通过反射获取注解 import java.lang.reflect.Method; public class AnnotationReader { public static void main(String[] args) throws NoSuchMethodException { // 获取MyClass的Class对象 Class<MyClass> obj = MyClass.class; // 获取myMethod方法的Method对象 Method method = obj.getMethod("myMethod"); // 获取方法上的MyAnnotation注解实例 MyAnnotation annotation = method.getAnnotation(MyAnnotation.class); if (annotation != null) { // 输出注解的value值 System.out.println("注解的value: " + annotation.value()); } } } // 反射调用链: // Class → 通过类加载器获取类的运行时描述对象; // Method → 从 Class 对象中获取方法的反射对象; // getAnnotation() → 从方法反射对象中获取注解实例。 3.快速判断注解是否存在 if (method.isAnnotationPresent(MyAnnotation.class)) { // 如果存在MyAnnotation注解,则执行相应逻辑 } Junit 单元测试 步骤 1.导入依赖 将 JUnit 框架的 jar 包添加到项目中(注意:IntelliJ IDEA 默认集成了 JUnit,无需手动导入)。 2.编写测试类 为待测业务方法创建对应的测试类。 测试类中定义测试方法,要求方法必须为 public 且返回类型为 void。 3.添加测试注解 在测试方法上添加 @Test 注解,确保 JUnit 能自动识别并执行该方法。 4.运行测试 在测试方法上右键选择“JUnit运行”。 测试通过显示绿色标志; 测试失败显示红色标志。 public class UserMapperTest { @Test public void testListUser() { UserMapper userMapper = new UserMapper(); List<User> list = userMapper.list(); Assert.assertNotNull("User list should not be null", list); list.forEach(System.out::println); } } 注意,如果需要使用依赖注入,需要在测试类上加@SpringBootTest注解 它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如自动装配、依赖注入、配置加载等 @RunWith(SpringRunner.class) @SpringBootTest public class UserMapperTest { @Autowired private UserMapper userMapper; @Test public void testListUser() { List<User> list = userMapper.list(); Assert.assertNotNull("User list should not be null", list); list.forEach(System.out::println); } } 写了@Test注解,那么该测试函数就可以直接运行!若一个测试类中写了多个测试方法,可以全部执行! 原理可能是: //自定义注解 @Retention(RetentionPolicy.RUNTIME) //指定注解在运行时可用,这样才能通过反射获取到该注解。 @Target(ElementType.METHOD) //指定注解可用于方法上。 public @interface MyTest { } public class AnnotationTest4 { @MyTest public void test() { System.out.println("===test4==="); } public static void main(String[] args) throws Exception { AnnotationTest4 instance = new AnnotationTest4(); // 1. 获取 Class 对象 Class<?> clazz = AnnotationTest4.class; // 2. 获取类中声明的所有方法 Method[] methods = clazz.getDeclaredMethods(); // 3. 遍历方法,执行带 @MyTest 的方法 for (Method method : methods) { if (method.isAnnotationPresent(MyTest.class)) { method.invoke(instance); // 反射调用方法 } } } } 在Springboot中,如何快速生成单元测试? 选中类名,右键: JAVA笔试题总结 1)构造函数用于初始化当前类的对象,不能被继承。子类会调用父类的构造函数(通过 super),但这不是继承。 2)try-finally public static int func() { try { return 1; // 这个返回值被"吞噬" } finally { return 0; // 这个返回值覆盖了try中的值 } } // 结果: 返回 0 因此极不推荐在 finally 中使用 return 3)关于 Java 的包和部署,下列说法正确的是(单选题)? A. Java 虚拟机在使用 JAR 的 class 之前必须先将其解压缩 B. 编译包中的类时,完整名称必须和目录结构一致 C. 同一源文件中的不同类可以放到不同的包中 D. JAR 是保存 .class 文件的标准目录 解析: A 错误:JVM 可以直接读取 JAR 中的 .class 文件,无需解压(JAR 本质是 ZIP 格式,JVM 能直接加载)。 B 正确:Java 要求包名必须与文件目录结构完全匹配(例如 com.example.Test需放在 com/example/Test.java中),否则编译失败。 C 错误:同一 .java 源文件中的多个类默认属于同一个包,且只能有一个 public 类,不能拆分到不同包中。 D 错误:JAR 是压缩文件(归档格式),不是标准目录;标准目录是文件系统本身的文件夹结构。
后端学习
zy123
1年前
0
16
0
2025-03-21
JavaWeb——后端
JavaWeb——后端 好用的操作 右键文件/文件夹选择Copy Path/Reference,可以获得完整的包路径 Java版本解决方案 单个Java文件运行: Edit Configurations 针对单个运行配置:每个 Java 运行配置(如主类、测试类等)可以独立设置其运行环境(如 JRE 版本、程序参数、环境变量等)。 不影响全局项目:修改某个运行配置的环境不会影响其他运行配置或项目的全局设置。 如何调整全局项目的环境 打开 File -> Project Structure -> Project。 在 Project SDK 中选择全局的 JDK 版本(如 JDK 17)。 在 Project language level 中设置全局的语言级别(如 17)。 Java Compiler File -> Settings -> Build, Execution, Deployment -> Compiler -> Java Compiler Maven Runner File -> Settings -> Build, Execution, Deployment -> Build Tools -> Maven -> Runner 三者之间的关系 全局项目环境 是基准,决定项目的默认 JDK 和语言级别。 Java Compiler 控制编译行为,可以覆盖全局的 Project language level。 Maven Runner 控制 Maven 命令的运行环境,可以覆盖全局的 Project SDK。 Maven 项目: 确保 pom.xml 中的 <maven.compiler.source> 和 <maven.compiler.target> 与 Project SDK 和 Java Compiler 的配置一致。 确保 Maven Runner 中的 JRE 与 Project SDK 一致。 如果还是不行,pom文件右键点击maven->reload project HTTP协议 响应状态码 状态码分类 说明 1xx 响应中 --- 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 2xx 成功 --- 表示请求已经被成功接收,处理已完成 3xx 重定向 --- 重定向到其它地方,让客户端再发起一个请求以完成整个处理 4xx 客户端错误 --- 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 5xx 服务器端错误 --- 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 状态码 英文描述 解释 200 OK 客户端请求成功,即处理成功,这是我们最想看到的状态码 302 Found 指示所请求的资源已移动到由Location响应头给定的 URL,浏览器会自动重新访问到这个页面 304 Not Modified 告诉客户端,你请求的资源至上次取得后,服务端并未更改,你直接用你本地缓存吧。隐式重定向 400 Bad Request 客户端请求有语法错误,不能被服务器所理解 403 Forbidden 服务器收到请求,但是拒绝提供服务,比如:没有权限访问相关资源 404 Not Found 请求资源不存在,一般是URL输入有误,或者网站资源被删除了 405 Method Not Allowed 请求方式有误,比如应该用GET请求方式的资源,用了POST 429 Too Many Requests 指示用户在给定时间内发送了太多请求(“限速”),配合 Retry-After(多长时间后可以请求)响应头一起使用 500 Internal Server Error 服务器发生不可预期的错误。服务器出异常了,赶紧看日志去吧 503 Service Unavailable 服务器尚未准备好处理请求,服务器刚刚启动,还未初始化好 开发规范 REST风格 在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。 什么是REST风格呢? REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。 传统URL风格如下: http://localhost:8080/user/getById?id=1 GET:查询id为1的用户 http://localhost:8080/user/saveUser POST:新增用户 http://localhost:8080/user/updateUser PUT:修改用户 http://localhost:8080/user/deleteUser?id=1 DELETE:删除id为1的用户 我们看到,原始的传统URL,定义比较复杂,而且将资源的访问行为对外暴露出来了。 基于REST风格URL如下: http://localhost:8080/users/1 GET:查询id为1的用户 http://localhost:8080/users POST:新增用户 http://localhost:8080/users PUT:修改用户 http://localhost:8080/users/1 DELETE:删除id为1的用户 其中总结起来,就一句话:通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。 REST风格后端代码: @RestController @RequestMapping("/depts") //定义当前控制器的请求前缀 public class DeptController { // GET: 查询资源 @GetMapping("/{id}") public Dept getDept(@PathVariable Long id) { ... } // POST: 新增资源 @PostMapping public void createDept(@RequestBody Dept dept) { ... } // PUT: 更新资源 @PutMapping public void updateDept(@RequestBody Dept dept) { ... } // DELETE: 删除资源 @DeleteMapping("/{id}") public void deleteDept(@PathVariable Long id) { ... } } GET:查询,用 URL 传参,不能带 body。 POST:创建/提交,可以用 body 传数据(JSON、表单)。 PUT:更新,可以用 body 。 DELETE:删除,一般无 body,只要 -X DELETE。 开发流程 查看页面原型明确需求 根据页面原型和需求,进行表结构设计、编写接口文档(已提供) 阅读接口文档 思路分析 功能接口开发 就是开发后台的业务功能,一个业务功能,我们称为一个接口(Controller 中一个完整的处理请求的方法) 功能接口测试 功能开发完毕后,先通过Postman进行功能接口测试,测试通过后,再和前端进行联调测试 前后端联调测试 和前端开发人员开发好的前端工程一起测试 SpringBoot Servlet 容器 是用于管理和运行 Web 应用的环境,它负责加载、实例化和管理 Servlet 组件,处理 HTTP 请求并将请求分发给对应的 Servlet。常见的 Servlet 容器包括 Tomcat、Jetty、Undertow 等。 SpringBoot的WEB默认内嵌了tomcat服务器,非常方便!!! 浏览器与 Tomcat 之间通过 HTTP 协议进行通信,而 Tomcat 则充当了中间的桥梁,将请求路由到你的 Java 代码,并最终将处理结果返回给浏览器。 查看springboot版本:查看pom文件 <parent> <artifactId>spring-boot-starter-parent</artifactId> <groupId>org.springframework.boot</groupId> <version>2.7.3</version> </parent> 版本为2.7.3 快速启动 新建spring initializr project 删除以下文件 新建HelloController类 @RestController public class HelloController { @RequestMapping("/hello") public String hello(){ System.out.println("hello"); return "hello"; } } 然后启动服务器,main程序 package edu.whut; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class SprintbootQuickstartApplication { public static void main(String[] args) { SpringApplication.run(SprintbootQuickstartApplication.class, args); } } 然后浏览器访问 localhost:8080/hello。 SpringBoot请求 简单参数 在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。 @RestController public class RequestController { // http://localhost:8080/simpleParam?name=Tom&age=10 // 第1个请求参数: name=Tom 参数名:name,参数值:Tom // 第2个请求参数: age=10 参数名:age , 参数值:10 //springboot方式 @RequestMapping("/simpleParam") public String simpleParam(String name , Integer age ){//形参名和请求参数名保持一致 System.out.println(name+" : "+age); return "OK"; } } 如果方法形参名称与请求参数名称不一致,controller方法中的形参还能接收到请求参数值吗? 解决方案:可以使用Spring提供的@RequestParam注解完成映射 在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。代码如下: @RestController public class RequestController { // http://localhost:8080/simpleParam?name=Tom&age=20 // 请求参数名:name //springboot方式 @RequestMapping("/simpleParam") public String simpleParam(@RequestParam("name") String username , Integer age ){ System.out.println(username+" : "+age); return "OK"; } } 实体参数 复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下: User类中有一个Address类型的属性(Address是一个实体类) 复杂实体对象的封装,需要遵守如下规则: 请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。 注意:这里User前面不能加@RequestBody是因为请求方式是 Query 或 路径 参数;如果是JSON请求体(Body)就必须加。 @RequestMapping("/complexpojo") public String complexpojo(User user){ System.out.println(user); return "OK"; } @Data @NoArgsConstructor @AllArgsConstructor public class User { private String name; private Integer age; private Address address; } @Data @NoArgsConstructor @AllArgsConstructor public class Address { private String province; private String city; } 数组参数 数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数 @RestController public class RequestController { //数组集合参数 @RequestMapping("/arrayParam") public String arrayParam(String[] hobby){ System.out.println(Arrays.toString(hobby)); return "OK"; } } 路径参数 请求的URL中传递的参数 称为路径参数。例如: http://localhost:8080/user/1 http://localhost:880/user/1/0 注意,路径参数使用大括号 {} 定义 @RestController public class RequestController { //路径参数 @RequestMapping("/path/{id}/{name}") public String pathParam2(@PathVariable Integer id, @PathVariable String name){ System.out.println(id+ " : " +name); return "OK"; } } 在路由定义里用 {id} 只是一个占位符,实际请求时 不要 带大括号 JSON格式参数 { "backtime": [ "与中标人签订合同后 5日内", "投标截止时间前撤回投标文件并书面通知招标人的,2日内", "开标现场投标文件被拒收,开标结束后,2日内" ], "employees": [ { "firstName": "John", "lastName": "Doe" }, { "firstName": "Anna", "lastName": "Smith" }, { "firstName": "Peter", "lastName": "Jones" } ] } JSON 格式的核心特征 接口文档中的请求参数中是 'Body' 发送数据 数据为键值对:数据存储在键值对中,键和值用冒号分隔。在你的示例中,每个对象有两个键值对,如 "firstName": "John"。 使用大括号表示对象:JSON 使用大括号 {} 包围对象,对象可以包含多个键值对。 使用方括号表示数组:JSON 使用方括号 [] 表示数组,数组中可以包含多个值,包括数字、字符串、对象等。在该示例中:"employees" 是一个对象数组,数组中的每个元素都是一个对象。 Postman如何发送JSON格式数据: 服务端Controller方法如何接收JSON格式数据: 传递json格式的参数,在Controller中会使用实体类进行封装。 封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。 @Data @NoArgsConstructor @AllArgsConstructor public class DataDTO { private List<String> backtime; private List<Employee> employees; } @Data @NoArgsConstructor @AllArgsConstructor public class Employee { private String firstName; private String lastName; } @RestController public class DataController { @PostMapping("/data") public String receiveData(@RequestBody DataDTO data) { System.out.println("Backtime: " + data.getBacktime()); System.out.println("Employees: " + data.getEmployees()); return "OK"; } } JSON格式工具包 用于高效地进行 JSON 与 Java 对象之间的序列化和反序列化操作。 引入依赖: <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.76</version> </dependency> 使用: import com.alibaba.fastjson.JSON; public class FastJsonDemo { public static void main(String[] args) { // 创建一个对象 User user = new User("Alice", 30); // 对象转 JSON 字符串 String jsonString = JSON.toJSONString(user); System.out.println("JSON String: " + jsonString); // JSON 字符串转对象 User parsedUser = JSON.parseObject(jsonString, User.class); System.out.println("Parsed User: " + parsedUser); } } // JSON String: {"age":30,"name":"Alice"} // Parsed User: User(name=Alice, age=30) SpringBoot响应 @ResponseBody注解: 位置:书写在Controller方法上或类上 作用:将方法返回值直接响应给浏览器 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器 @RestController = @Controller + @ResponseBody 统一响应结果: 下图返回值分别是字符串、对象、集合。 定义统一返回结果类 响应状态码:当前请求是成功,还是失败 状态码信息:给页面的提示信息 返回的数据:给前端响应的数据(字符串、对象、集合) 定义在一个实体类Result来包含以上信息。代码如下: @Data @NoArgsConstructor @AllArgsConstructor public class Result { private Integer code;//响应码,1 代表成功; 0 代表失败 private String msg; //响应信息 描述字符串 private Object data; //返回的数据 //增删改 成功响应 public static Result success(){ return new Result(1,"success",null); } //查询 成功响应 public static Result success(Object data){ return new Result(1,"success",data); } //失败响应 public static Result error(String msg){ return new Result(0,msg,null); } } Spring分层架构 三层架构 Controller层接收请求,调用Service层;Service层先调用Dao层获取数据,然后实现自己的业务逻辑处理部分,最后返回给Controller层;Controller层再响应数据。可理解为递归的过程。 **传统模式:**对象的创建、管理和依赖关系都由程序员手动编写代码完成,程序内部控制对象的生命周期。 例如: public class A { private B b; public A() { b = new B(); // A 自己创建并管理 B 的实例 } } 假设有类 A 依赖类 B,在传统方式中,类 A 可能在构造方法或方法内部直接调用 new B() 来创建 B 的实例。 如果 B 的创建方式发生变化,A 也需要修改代码。这就导致了耦合度较高。 软件设计原则:高内聚低耦合。 高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。 低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。 IOC控制反转 将对象的创建和依赖关系的管理交给容器,而不是由程序中的各个组件自行管理。 在 IOC 中,容器负责以下几件事: 管理对象的创建:容器根据配置或注解实例化项目中的类,将它们变成“Bean”。 维护依赖关系:容器跟踪各个 Bean 之间的依赖,并在需要时自动注入它们的依赖。 管理生命周期:容器负责控制对象的生命周期,包括对象的初始化和销毁。 依赖注入DI 类 A 不再自己创建 B,而是声明自己需要一个 B,容器在创建 A 时会自动将 B 的实例提供给 A。 DI 是实现 IOC 的一种方式。 public class A { private B b; // 通过构造器注入依赖 public A(B b) { this.b = b; } } 1.Autowird注入 @Autowired private PaymentClient paymentClient; // 字段直接加 @Autowired 2.构造器注入(推荐) 1)手写构造器 public class OrderService { private final PaymentClient paymentClient; // 在构造器上无需加 @Autowired(Spring Boot 下可省略) public OrderService(PaymentClient paymentClient) { this.paymentClient = paymentClient; } } 2)Lombok @RequiredArgsConstructor 用 Lombok 自动为所有 final 字段生成构造器,进一步简化写法: @RequiredArgsConstructor public class OrderService { private final PaymentClient paymentClient; // Lombok 会在编译期生成构造器 } controller层应注入接口类,而不是子类,如果只有一个子类实现类,那么直接注入即可,否则需要指定注入哪一个 @Service("categoryServiceImplV1") public class CategoryServiceImplV1 implements CategoryService { … } @Service("categoryServiceImplV2") public class CategoryServiceImplV2 implements CategoryService { … } @RestController @RequiredArgsConstructor // 推荐构造器注入 public class CategoryController { @Qualifier("categoryServiceImplV2") // 指定注入 V2 private final CategoryService categoryService; } 分层解耦 Bean 对象:在 Spring 中,被容器管理的对象称为 Bean。通过注解(如 @Component, @Service, @Repository, @Controller),可以将一个普通的 Java 类声明为 Bean,容器会负责它的创建、初始化以及生命周期管理。 Component衍生注解 注解 说明 位置 @Controller @Component的衍生注解 标注在控制器类上Controller @Service @Component的衍生注解 标注在业务类上Service @Repository @Component的衍生注解 标注在数据访问类上(由于与mybatis整合,用的少)DAO @Component 声明bean的基础注解 不属于以上三类时,用此注解 注:@Mapper 注解本身并不是 Spring 框架提供的,是用于 MyBatis 数据层的接口标识,但效果类似。 SpringBoot原理 配置文件 配置优先级 在SpringBoot项目当中,常见的属性配置方式有5种, 3种配置文件,加上2种外部属性的配置(Java系统属性、命令行参数)。优先级(从低到高): application.yaml(忽略) application.yml application.properties java系统属性(-Dxxx=xxx) 命令行参数(--xxx=xxx) 在 Spring Boot 项目中,通常使用的是 application.yml 或 application.properties 文件,这些文件通常放在项目的 src/main/resources 目录下。 如果项目已经打包上线了,这个时候我们又如何来设置Java系统属性和命令行参数呢? java -Dserver.port=9000 -jar XXXXX.jar --server.port=10010 在这个例子中,由于命令行参数的优先级高于 Java 系统属性,最终生效的 server.port 是 10010。 properties 位置:src/main/resources/application.properties 将配置信息写在application.properties,用注解@Value获取配置文件中的数据 yml配置文件(推荐!!!) 位置:src/main/resources/application.yml 了解下yml配置文件的基本语法: 大小写敏感 数据前边必须有空格,作为分隔符 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格) 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可 #表示注释,从这个字符一直到行尾,都会被解析器忽略 对象/map集合 user: name: zhangsan detail: age: 18 password: "123456" 数组/List/Set集合 hobby: - java - game - sport //获取示例 @Value("${hobby}") private List<String> hobby; 以上获取配置文件中的属性值,需要通过@Value注解,有时过于繁琐!!! @ConfigurationProperties 是用来将外部配置(如 application.yml)映射到一个 POJO 上的。 在 Spring Boot 中,根据 驼峰命名转换规则,自动将 YAML 配置文件中的 键名(例如 user-token-name user_token_name)映射到 Java 类中的属性(例如 userTokenName)。 @Data @Component @ConfigurationProperties(prefix = "aliyun.oss") public class AliOssProperties { private String endpoint; private String accessKeyId; private String accessKeySecret; private String bucketName; } Spring提供的简化方式套路: 需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致 比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法 ==》@Data 需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象 ==>@Component 在实体类上添加@ConfigurationProperties注解,并通过perfix属性来指定配置参数项的前缀 (可选)引入依赖pom.xml (自动生成配置元数据,让 IDE 能识别并补全你在 application.properties/yml 中的自定义配置项,提高开发体验,不加不影响运行!) <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> </dependency> 隐私数据配置 通常设置一个 application-local.yml 存放隐私数据,且加入 .gitignore ,表示仅存储在本地;然后application.yml 通过占位符引入该文件,eg: application.yml # 主配置文件,导入本地隐私文件,并通过占位符引用 spring: config: # Spring Boot 2.4+ 推荐用 import import: optional:classpath:/application-local.yml myapp: datasource: url: jdbc:mysql://localhost:3306/pay_mall # 下面两个会从 application-local.yml 里拿 username: ${datasource.username} password: ${datasource.password} application-local.yml # 本地专属配置,激活时才会加载 datasource: username: root password: 123456 这里有个松散绑定的原则,对于 ${datasource.username} 这里匹配有效: userName username user-name user_name 这四个是等价的 底层做法是: 全部字符转小写 → username 去掉分隔符(-、_、.、空格) → username 再匹配到 Java Bean 里的驼峰字段 userName(或直接 username,视你写的字段而定) Bean 的获取和管理 获取Bean 1.自动装配(@Autowired) @Service public class MyService { @Autowired private MyRepository myRepository; // 自动注入 MyRepository Bean } 2.手动获取(ApplicationContext) ApplicationContext 是 Spring 的 IoC 容器,可以手动获取 Bean: Spring 会默认采用类名并将首字母小写作为 Bean 的名称。例如,类名为 DeptController 的组件默认名称就是 deptController。 @RunWith(SpringRunner.class) @SpringBootTest public class SpringbootWebConfig2ApplicationTests { @Autowired private ApplicationContext applicationContext; // IoC 容器 @Test public void testGetBean() { // 根据 Bean 名称获取 DeptController bean = (DeptController) applicationContext.getBean("deptController"); System.out.println(bean); } } 默认情况下,Spring 在容器启动时会创建所有单例 Bean(饿汉模式);使用 @Lazy 注解则可实现延迟加载(懒汉模式) bean的作用域 作用域 说明 singleton 容器内同名称的bean只有一个实例(单例)(默认) prototype 每次使用该bean时会创建新的实例(非单例) 在设计单例类时,通常要求它们是无状态的,不仅要确保成员变量不可变,还需要确保成员方法不会对共享的、可变的状态进行不受控制的修改,从而实现整体的线程安全。 @Service public class CalculationService { // 不可变的成员变量 private final double factor = 2.0; // 成员方法仅依赖方法参数和不可变成员变量 public double multiply(double value) { return value * factor; } } 更改作用域方法: 在bean类上加注解@Scope("prototype")(或其他作用域标识)即可。 第三方 Bean配置 如果需要管理的 Bean 不是自己写的类(如第三方库提供的对象),不能用 @Component,必须借助 @Bean 注册: @Configuration // 配置类 public class CommonConfig { // 定义第三方 Bean,并交给 IoC 容器管理 @Bean public SAXReader reader(DeptService deptService) { System.out.println(deptService); return new SAXReader(); } } 默认 Bean 名称:方法名 → "reader"。 Bean 类型:返回值类型 → SAXReader。 使用: @Service public class XmlProcessingService { // 按类型注入 @Autowired private SAXReader reader; public void parse(String xmlPath) throws DocumentException { Document doc = reader.read(new File(xmlPath)); // ... 处理 Document ... } } 只有一个同类型 Bean 时:@Autowired 按类型注入,字段名如(reader)不必和 @Bean 方法名一致。 多个同类型 Bean 时:需要用 @Qualifier 或 @Resource 指定 Bean 名称。 SpirngBoot原理 如果我们直接基于Spring框架进行项目的开发,会比较繁琐。SpringBoot框架之所以使用起来更简单更快捷,是因为SpringBoot框架底层提供了两个非常重要的功能:一个是起步依赖,一个是自动配置。 起步依赖 Spring Boot 只需要引入一个起步依赖(例如 springboot-starter-web)就能满足项目开发需求。这是因为: Maven 依赖传递: 起步依赖内部已经包含了开发所需的常见依赖(如 JSON 解析、Web、WebMVC、Tomcat 等),无需开发者手动引入其它依赖。 结论: 起步依赖的核心原理就是 Maven 的依赖传递机制。 自动装配 在传统 Spring 开发中,需要在 applicationContext.xml 或 @Configuration 类里手工声明大量 Bean。Spring Boot 为了简化配置,引入了 自动装配(Auto Configuration),让我们只需少量注解就能“开箱即用”。 自动配置原理源码入口就是@SpringBootApplication注解,在这个注解中封装了3个注解,分别是: @SpringBootConfiguration 声明当前类是一个配置类,作用类似 @Configuration,但作为 Spring Boot 的专用配置入口标识。 @ComponentScan 用于 扫描项目自定义的 Bean,比如 @Component、@Service、@Repository、@Controller 等。 默认扫描 启动类所在包及其子包。 如果项目分为 server、common 等模块,可以通过: @ComponentScan({"com.your.package.server", "com.your.package.common"}) 来显式指定需要扫描的包路径。 @EnableAutoConfiguration(自动配置核心注解) 导入自动配置类 通过元注解 @Import(AutoConfigurationImportSelector.class),在启动时读取所有 JAR 包中 META‑INF/spring.factories 中声明的自动配置类,并注册到容器。 按条件注册 Bean 配置类内部使用条件注解(@ConditionalOnClass、@ConditionalOnMissingBean、@ConditionalOnProperty 等)。 仅在 类路径、配置属性、已有 Bean 满足条件时,才创建对应 Bean。 典型示例 DataSourceAutoConfiguration:检测到 JDBC 驱动和 spring.datasource. 配置时自动创建数据源。 WebMvcAutoConfiguration:配置 Spring MVC 默认组件;若用户提供了自定义 MVC 配置,则自动“退让”(Back Off)。 自动配置的效果: 如何让第三方bean以及配置类生效? 在 Spring Boot 中,默认只会扫描 启动类所在包及其子包 下的组件。 如果某些类或配置类(如 CommonConfig)不在扫描路径内,就不会被容器加载,需要手动导入。 常见的三种方式如下: 1.使用 @ComponentScan(批量导入) 通过指定包路径,扩大扫描范围,让其中的组件或配置类被容器加载: @SpringBootApplication(scanBasePackages = {"com.example.server", "com.example.common"}) public class DemoApplication {} 特点:适合批量导入,但可能引入无关类,配置繁琐、性能相对较低。 2.使用 @Import(精确导入) @Import 可以直接将类或配置类导入到容器中,更加灵活精准。 导入普通类 即使类上没有 @Component,也能被 Spring 管理: public class TokenParser { public void parse() { System.out.println("TokenParser ... parse ..."); } } @SpringBootApplication @Import(TokenParser.class) // 导入普通类 public class DemoApplication {} 导入配置类 配置类中集中定义多个 Bean: @Configuration public class HeaderConfig { @Bean public HeaderParser headerParser() { return new HeaderParser(); } @Bean public HeaderGenerator headerGenerator() { return new HeaderGenerator(); } } @SpringBootApplication @Import(HeaderConfig.class) // 导入配置类 public class DemoApplication {} 3.使用 @EnableXxx 注解(推荐) 很多第三方依赖会提供一个 @EnableXxx 注解,内部基于 @Import 封装,可以一次性导入多个配置类或 Bean。 @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) @Import(MyImportSelector.class) // 指定要导入的 Bean 或配置类 public @interface EnableHeaderConfig {} 应用启动时,只需加上该注解即可: @EnableHeaderConfig // 开启第三方依赖提供的功能 @SpringBootApplication public class DemoApplication {} 特点:最常用、最优雅的方式,Spring Boot 内置的很多功能(如 @EnableScheduling、@EnableAsync、@EnableWebMvc)都是通过这种模式实现的。 如何自定义 Starter 实现自动装配 1.准备一个服务类 这是你希望自动装配到 Spring 容器中的类,比如一个简单的业务类。 package com.example.demo.service; public class HelloService { public String sayHello(String name) { return "Hello, " + name; } } 2.编写自动配置类 使用 @Configuration 注解,把上面的服务注册为一个 Spring Bean。 package com.example.demo.autoconfig; import com.example.demo.service.HelloService; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class HelloServiceAutoConfiguration { @Bean public HelloService helloService() { return new HelloService(); } } 3.在 META-INF/spring.factories 中声明 在你的项目(或者 starter jar 包)里新建一个文件: src/main/resources/META-INF/spring.factories ,内容如下: org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.example.demo.autoconfig.HelloServiceAutoConfiguration Spring Boot 启动时会读取所有依赖里的 spring.factories 文件,把里面的配置类自动加载。 4.打包成 Starter Jar 把项目打成一个独立的 Jar(通常命名为 xxx-spring-boot-starter),发布到本地或远程仓库。 5.在应用中使用 只要在别的 Spring Boot 应用里引入这个依赖,就能直接注入并使用: @RestController public class TestController { private final HelloService helloService; public TestController(HelloService helloService) { this.helloService = helloService; //构造器注入 } @GetMapping("/hi") public String hi(String name) { return helloService.sayHello(name); } } Spring Boot 的 自动配置类(通过 spring.factories 声明的)通常是 打包成一个独立的 Jar(Starter),然后给别的项目引用。这样别人只要在 pom.xml 或 build.gradle 里加上依赖,就能自动获得你配置的 Bean。 常见的注解!! @RequestMapping("/jsonParam"):可以用于控制器级别,也可以用于方法级别。 用于方法:HTTP 请求路径为 /jsonParam 的请求将调用该方法。 @RequestMapping("/jsonParam") public String jsonParam(@RequestBody User user){ System.out.println(user); return "OK"; } 用于控制器: 所有方法的映射路径都会以这个前缀开始。 @RestController @RequestMapping("/depts") public class DeptController { @GetMapping("/{id}") public Dept getDept(@PathVariable Long id) { // 实现获取部门逻辑 } @PostMapping public void createDept(@RequestBody Dept dept) { // 实现新增部门逻辑 } } @RequestBody:这是一个方法参数级别的注解,用于告诉Spring框架将请求体的内容解析为指定的Java对象。 @RestController:这是一个类级别的注解,它告诉Spring框架这个类是一个控制器(Controller),并且处理HTTP请求并返回响应数据。与 @Controller 注解相比,@RestController 注解还会自动将控制器方法返回的数据转换为 JSON 格式,并写入到HTTP响应中,得益于@ResponseBody 。 @RestController = @Controller + @ResponseBody @PathVariable 注解用于将路径参数 {id} 的值绑定到方法的参数 id 上。当请求的路径是 "/path/123" 时,@PathVariable 会将路径中的 "123" 值绑定到方法的参数 id 上。 public String pathParam(@PathVariable Integer id) { System.out.println(id); return "OK"; } //参数名与路径名不同 @GetMapping("/{id}") public ResponseEntity<User> getUserById(@PathVariable("id") Long userId) { } @RequestParam, 1)如果方法的参数名与请求参数名不同,需要在 @RequestParam 注解中指定请求参数的名字。 类似@PathVariable,可以指定参数名称。 @RequestMapping("/example") public String exampleMethod(@RequestParam String name, @RequestParam("age") int userAge) { // 在方法内部使用获取到的参数值进行处理 System.out.println("Name: " + name); System.out.println("Age: " + userAge); return "OK"; } 2)还可以设置默认值 @RequestMapping("/greet") public String greet(@RequestParam(defaultValue = "Guest") String name) { return "Hello, " + name; } 3)如果既改请求参数名字,又要设置默认值 @RequestMapping("/greet") public String greet(@RequestParam(value = "age", defaultValue = "25") int userAge) { return "Age: " + userAge; } 4)如果方法参数是简单类型(int/Integer、String、boolean/Boolean 等及它们的一维数组),那么无需使用@RequestParam,如果是Collection集合类型,必须使用。 List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); 控制反转与依赖注入: @Component、@Service、@Repository 用于标识 bean 并让容器管理它们,从而实现 IoC。 @Autowired、@Configuration、@Bean 用于实现 DI,通过容器自动装配或配置 bean 的依赖。 数据库相关。 @Mapper注解:表示是mybatis中的Mapper接口,程序运行时,框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理 @Select注解:代表的就是select查询,用于书写select查询语句 @SpringBootTest:它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如自动装配、依赖注入、配置加载等。 lombok的相关注解。非常实用的工具库。 在pom.xml文件中引入依赖 <!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> 在实体类上添加以下注解(加粗为常用) 注解 作用 @Getter/@Setter 为所有的属性提供get/set方法 @ToString 会给类自动生成易阅读的 toString 方法 @EqualsAndHashCode 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 @Data 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) @NoArgsConstructor 为实体类生成无参的构造器方法 @AllArgsConstructor 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 @Slf4j 可以log.info("输出日志信息"); //equals 方法用于比较两个对象的内容是否相同 Address addr1 = new Address("SomeProvince", "SomeCity"); Address addr2 = new Address("SomeProvince", "SomeCity"); System.out.println(addr1.equals(addr2)); // 输出 true log: log.info("应用启动成功"); Long empId = 12L; log.info("当前员工id:{}", empId); //带占位符,推荐! log.info("当前员工id:" + empId); //不错,但不推荐 log.info("当前员工id:", empId); //错误的! @Test,Junit测试单元,可在测试类中定义测试函数,一次性执行所有@Test注解下的函数,不用写main方法 @Override,当一个方法在子类中覆盖(重写)了父类中的同名方法时,为了确保正确性,可以使用 @Override 注解来标记这个方法,这样编译器就能够帮助检查是否正确地重写了父类的方法。 @DateTimeFormat将日期转化为指定的格式。Spring会尝试将接收到的字符串参数转换为控制器方法参数的相应类型。 @RestController public class DateController { // 例如:请求 URL 为 /search?begin=2025-03-28 @GetMapping("/search") public String search(@RequestParam("begin") @DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin) { // 此时 begin 已经是 LocalDate 类型,可以直接使用 return "接收到的日期是: " + begin; } } @RestControllerAdvice= @ControllerAdvice + @ResponseBody。加上这个注解就代表我们定义了一个全局异常处理器,而且处理异常的方法返回值会转换为json后再响应给前端 @RestControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(Exception.class) @ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR) public String handleException(Exception ex) { // 返回错误提示或错误详情 return "系统发生异常:" + ex.getMessage(); } } @Configuration和@Bean配合使用,可以对第三方bean进行集中的配置管理,依赖注入!!@Bean用于方法上。加了@Configuration,当Spring Boot应用启动时,它会执行一系列的自动配置步骤。 @ComponentScan指定了Spring应该在哪些包下搜索带有@Component、@Service、@Repository、@Controller等注解的类,以便将这些类自动注册为Spring容器管理的Bean.@SpringBootApplication它是一个便利的注解,组合了@Configuration、@EnableAutoConfiguration和@ComponentScan注解。 @Async 注解,异步执行 1.在你的配置类或主启动类上添加: @Configuration @EnableAsync public class AsyncConfig { // 可以自定义线程池 Bean(可选) } 2.在你希望异步执行的方法或它所在的 Bean 上,添加 @Async @Service public class EmailService { @Async public void sendWelcomeEmail(String userId) { // 这个方法会在独立线程中执行 // 调用线程会立即返回,不会等待方法内部逻辑完成 // … 发送邮件的耗时操作 … } } 登录校验 会话技术 会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。比如:1、2、3这三个请求都是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web服务器关了,那么所有的会话就都结束了。 会话跟踪技术有三种: Cookie(客户端会话跟踪技术) Session(服务端会话跟踪技术) 令牌技术 Cookie 原理:会话数据存储在客户端浏览器中,通过浏览器自动管理。 优点:HTTP协议中支持的技术(像Set-Cookie 响应头的解析以及 Cookie 请求头数据的携带,都是浏览器自动进行的,是无需我们手动操作的) 缺点: 移动端APP(Android、IOS)中无法使用Cookie 不安全,用户可以自己禁用Cookie Cookie不能跨域传递 Session 1.基本原理 服务端:存储会话数据(内存、Redis 等)。 客户端:仅保存会话 ID(如 JSESSIONID),通常通过 Cookie 传递。 2.数据结构 服务端会话存储(Map 或 Redis) { "abc123" -> HttpSession 实例 } HttpSession 结构: HttpSession ├─ id = "abc123" ├─ creationTime = ... ├─ lastAccessedTime = ... └─ attributes └─ "USER_LOGIN_STATE" -> user 实体对象 3.请求流程 首次请求 浏览器没有 JSESSIONID,服务端调用 createSession() 创建一个新会话(ID 通常是 UUID)。 服务端返回响应头 Set-Cookie: JSESSIONID=<新ID>; Max-Age=2592000(30 天有效期)。 浏览器将 JSESSIONID 写入本地 Cookie(持久化保存)。 后续请求 浏览器自动在请求头中附带 Cookie: JSESSIONID=<ID>。 服务端用该 ID 在会话存储中查找对应的 HttpSession 实例,恢复用户状态。 ┌───────────────┐ (带 Cookie JSESSIONID=abc123) │ Browser │ ───────►│ Tomcat │ └───────────────┘ └──────────┘ │ │ 用 abc123 做 key ▼ {abc123 → HttpSession} ← 找到 │ ▼ 取 attributes["USER_LOGIN_STATE"] → 得到 userrequest.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user); 4.后端使用示例 保存登录状态: request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user); request.getSession() 会自动获取当前请求关联的 HttpSession 实例。 获取登录状态: User user = (User) request.getSession().getAttribute(UserConstant.USER_LOGIN_STATE); 退出登录: request.getSession().removeAttribute(UserConstant.USER_LOGIN_STATE); 相当于清空当前会话中的用户信息。浏览器本地的 JSESSIONID 依然存在,只不过后端啥也没了。 优点 会话数据保存在服务端,相比直接将数据存储在客户端更安全(防篡改)。 缺点 分布式集群下 Session 无法自动共享(需借助 Redis 等集中存储)。 客户端禁用 Cookie 时,Session 会失效。 服务端需要维护会话数据,高并发环境下可能带来内存或性能压力。 令牌JWT(推荐) 优点: 支持PC端、移动端 解决集群环境下的认证问题 减轻服务器的存储压力(无需在服务器端存储) 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验) 跨域问题 跨域问题指的是在浏览器中,一个网页试图去访问另一个域下的资源时,浏览器出于安全考虑,默认会阻止这种操作。这是浏览器的同源策略(Same-Origin Policy)导致的行为。 同源策略(Same-Origin Policy) 同源策略是浏览器的一种安全机制,它要求: 协议(如 http、https) 域名/IP(如 example.com) 端口(如 80 或 443) 这三者必须完全相同,才能被视为同源。 举例: http://192.168.150.200/login.html ----------> https://192.168.150.200/login [协议不同,跨域] http://192.168.150.200/login.html ----------> http://192.168.150.100/login [IP不同,跨域] http://192.168.150.200/login.html ----------> http://192.168.150.200:8080/login [端口不同,跨域] http://192.168.150.200/login.html ----------> http://192.168.150.200/login [不跨域] 解决跨域问题的方法: CORS(Cross-Origin Resource Sharing)是解决跨域问题的标准机制。它允许服务器在响应头中加上特定的 CORS 头部信息,明确表示允许哪些外域访问其资源。 服务器端配置:服务器返回带有 Access-Control-Allow-Origin 头部的响应,告诉浏览器允许哪些域访问资源。 Access-Control-Allow-Origin: *(表示允许所有域访问) Access-Control-Allow-Origin: http://site1.com(表示只允许 http://site1.com 访问) 全局统一配置 import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.CorsRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; @Configuration public class WebCorsConfig implements WebMvcConfigurer { @Override public void addCorsMappings(CorsRegistry registry) { registry.addMapping("/api/**") // 匹配所有 /api/** 路径 .allowedOrigins("http://allowed-domain.com") // 允许的域名 .allowedMethods("GET","POST","PUT","DELETE","OPTIONS") .allowedHeaders("Content-Type","Authorization") .allowCredentials(true) // 是否允许携带 Cookie .maxAge(3600); // 预检请求缓存 1 小时 } } Nginx解决方案 统一域名入口: 前端和 API 均通过 Nginx 以相同的域名(例如 https://example.com)提供服务。前端发送 AJAX 请求时,目标也是该域名的地址,如 https://example.com/api,从而避免了跨域校验。 Nginx 作为中间代理: Nginx 将特定路径(例如 /api/)的请求转发到后端服务器。对浏览器来说,请求和响应均来自同一域名,代理过程对浏览器透明。 “黑匣子”处理: 浏览器只与 Nginx 交互,不关心 Nginx 内部如何转发请求。无论后端位置如何,浏览器都认为响应源自统一域名,从而解决跨域问题。 总结 普通的跨域请求依然会送达服务器,服务器并不主动拦截;它只是通过响应头声明哪些来源被允许访问,而真正的拦截与安全检查,则由浏览器根据同源策略来完成。 JWT令牌 特性 Session JWT(JSON Web Token) 存储方式 服务端存储会话数据(如内存、Redis) 客户端存储完整的令牌(通常在 Header 或 Cookie) 标识方式 客户端持有一个 Session ID 客户端持有一个自包含的 Token 状态管理 有状态(Stateful),服务器要维护会话 无状态(Stateless),服务器不存会话 生成和校验 引入依赖 <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9.1</version> </dependency> 生成令牌与解析令牌: public class JwtUtils { private static String signKey = "zy123"; private static Long expire = 43200000L; //单位毫秒 12小时 /** * 生成JWT令牌 * @param claims JWT第二部分负载 payload 中存储的内容 * @return */ public static String generateJwt(Map<String, Object> claims){ String jwt = Jwts.builder() .addClaims(claims) .signWith(SignatureAlgorithm.HS256, signKey) .setExpiration(new Date(System.currentTimeMillis() + expire)) .compact(); return jwt; } /** * 解析JWT令牌 * @param jwt JWT令牌 * @return JWT第二部分负载 payload 中存储的内容 */ public static Claims parseJWT(String jwt){ Claims claims = Jwts.parser() .setSigningKey(signKey) .parseClaimsJws(jwt) .getBody(); return claims; } } 令牌可以存储当前登录用户的信息:id、username等等,传入claims Object 类型能够容纳字符串、数字等各种对象。 Map<String, Object> claims = new HashMap<>(); claims.put("id", emp.getId()); // 假设 emp.getId() 返回一个数字(如 Long 类型) claims.put("name", e.getName()); // 假设 e.getName() 返回一个字符串 claims.put("username", e.getUsername()); // 假设 e.getUsername() 返回一个字符串 String jwt = JwtUtils.generateJwt(claims); 解析令牌: @Autowired private HttpServletRequest request; String jwt = request.getHeader("token"); Claims claims = JwtUtils.parseJWT(jwt); // 解析 JWT 令牌 // 获取存储的 id, name, username Long id = (Long) claims.get("id"); // 如果 "id" 是 Long 类型 String name = (String) claims.get("name"); String username = (String) claims.get("username"); JWT 登录认证流程 用户登录 用户发起登录请求,校验密码、登录成功后,生成 JWT 令牌,并将其返回给前端。 前端存储令牌 前端接收到 JWT 令牌,存储在浏览器中(通常存储在 LocalStorage 或 Cookie 中)。 // 登录成功后,存储 JWT 令牌到 LocalStorage const token = response.data.token; // 从响应中获取令牌 localStorage.setItem('token', token); // 存储到 LocalStorage // 在后续请求中获取令牌并附加到请求头 const storedToken = localStorage.getItem('token'); fetch("https://your-api.com/protected-endpoint", { method: "GET", headers: { "token": storedToken // 添加 token 到请求头 } }) .then(response => response.json()) .then(data => console.log(data)) .catch(error => console.log('Error:', error)); 请求带上令牌 后续的每次请求,前端将 JWT 令牌携带上。 服务端校验令牌 服务端接收到请求后,拦截请求并检查是否携带令牌。若没有令牌,拒绝访问;若令牌存在,校验令牌的有效性(包括有效期),若有效则放行,进行请求处理。 注意,使用APIFOX测试时,需要在headers中添加 {token:"jwt令牌..."}否则会无法通过拦截器。 拦截器(Interceptor) 在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。 快速入门 定义拦截器,实现HandlerInterceptor接口,并重写其所有方法 //自定义拦截器 @Component public class JwtTokenUserInterceptor implements HandlerInterceptor { //目标资源方法执行前执行。 返回true:放行 返回false:不放行 @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { System.out.println("preHandle .... "); return true; //true表示放行 } //目标资源方法执行后执行 @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { System.out.println("postHandle ... "); } //视图渲染完毕后执行,最后执行 @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { System.out.println("afterCompletion .... "); } } 注意: preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行 postHandle方法:目标资源方法执行后执行 afterCompletion方法:视图渲染完毕后执行,最后执行 注册配置拦截器,实现WebMvcConfigurer接口,并重写addInterceptors方法 @Configuration public class WebConfig implements WebMvcConfigurer { //自定义的拦截器对象 @Autowired private JwtTokenUserInterceptor jwtTokenUserInterceptor; @Override protected void addInterceptors(InterceptorRegistry registry) { log.info("开始注册自定义拦截器..."); registry.addInterceptor(jwtTokenUserInterceptor) .addPathPatterns("/user/**") .excludePathPatterns("/user/user/login") .excludePathPatterns("/user/shop/status"); } } WebMvcConfigurer接口: 拦截器配置 通过实现 addInterceptors 方法,可以添加自定义的拦截器,从而在请求进入处理之前或之后执行一些逻辑操作,如权限校验、日志记录等。 静态资源映射 通过 addResourceHandlers 方法,可以自定义静态资源(如 HTML、CSS、JavaScript)的映射路径,这对于使用前后端分离或者集成第三方文档工具(如 Swagger/Knife4j)非常有用。 消息转换器扩展 通过 extendMessageConverters 方法,可以在默认配置的基础上,追加自定义的 HTTP 消息转换器,如将 Java 对象转换为 JSON 格式。 跨域配置 使用 addCorsMappings 方法,可以灵活配置跨域资源共享(CORS)策略,方便前后端跨域请求。 拦截路径 addPathPatterns指定拦截路径; 调用excludePathPatterns("不拦截的路径")方法,指定哪些资源不需要拦截。 拦截路径 含义 举例 /* 一级路径 能匹配/depts,/emps,/login,不能匹配 /depts/1 /** 任意级路径 能匹配/depts,/depts/1,/depts/1/2 /depts/* /depts下的一级路径 能匹配/depts/1,不能匹配/depts/1/2,/depts /depts/** /depts下的任意级路径 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 登录校验 主要在preHandle中写逻辑 public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //判断当前拦截到的是Controller的方法还是其他资源 if (!(handler instanceof HandlerMethod)) { //当前拦截到的不是动态方法,直接放行 return true; } //1、从请求头中获取令牌 String token = request.getHeader(jwtProperties.getUserTokenName()); //2、校验令牌 try { log.info("jwt校验:{}", token); Claims claims = JwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token); Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString()); log.info("当前用户id:", userId); BaseContext.setCurrentId(userId); //3、通过,放行 return true; } catch (Exception ex) { //4、不通过,响应401状态码 response.setStatus(401); return false; } } 全局异常处理 **当前问题:**如果程序因不知名原因报错,响应回来的数据是一个JSON格式的数据,但这种JSON格式的数据不符合开发规范当中所提到的统一响应结果Result,导致前端不能解析出响应的JSON数据。 当我们没有做任何的异常处理时,我们三层架构处理异常的方案: Mapper接口在操作数据库的时候出错了,此时异常会往上抛(谁调用Mapper就抛给谁),会抛给service。 service 中也存在异常了,会抛给controller。 而在controller当中,我们也没有做任何的异常处理,所以最终异常会再往上抛。最终抛给框架之后,框架就会返回一个JSON格式的数据,里面封装的就是错误的信息,但是框架返回的JSON格式的数据并不符合我们的开发规范。 如何解决: 方案一:在所有Controller的所有方法中进行try…catch处理 缺点:代码臃肿(不推荐) 方案二:全局异常处理器 好处:简单、优雅(推荐) 全局异常处理 定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解**@RestControllerAdvice**,加上这个注解就代表我们定义了一个全局异常处理器。 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解**@ExceptionHandler**。通过 @ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。 @RestControllerAdvice public class GlobalExceptionHandler { //处理 RuntimeException 异常 @ExceptionHandler(RuntimeException.class) public Result handleRuntimeException(RuntimeException e) { e.printStackTrace(); return Result.error("系统错误,请稍后再试"); } // 处理 NullPointerException 异常 @ExceptionHandler(NullPointerException.class) public Result handleNullPointerException(NullPointerException e) { e.printStackTrace(); return Result.error("空指针异常,请检查代码逻辑"); } //处理异常 @ExceptionHandler(Exception.class) //指定能够处理的异常类型,Exception.class捕获所有异常 public Result ex(Exception e){ e.printStackTrace();//打印堆栈中的异常信息 //捕获到异常之后,响应一个标准的Result return Result.error("对不起,操作失败,请联系管理员"); } } 模拟NullPointerException String str = null; // 调用 null 对象的方法会抛出 NullPointerException System.out.println(str.length()); // 这里会抛出 NullPointerException 模拟RuntimeException int res=10/0; 事务 场景与问题: @Slf4j @Service public class DeptServiceImpl implements DeptService { @Autowired private DeptMapper deptMapper; @Autowired private EmpMapper empMapper; //根据部门id,删除部门信息及部门下的所有员工 @Override public void delete(Integer id){ //根据部门id删除部门信息 deptMapper.deleteById(id); //模拟:异常发生 int i = 1/0; //删除部门下的所有员工信息 empMapper.deleteByDeptId(id); } } 问题:出现异常后,部门已被删除,但员工记录仍然存在,造成数据不一致。 原因:整组操作没有被事务包裹,无法做到“要么全部成功,要么全部失败”。 @Transactional 注解 位置 作用 方法级 仅当前方法受事务管理 类级 类中所有方法受事务管理 接口级 接口下 所有实现类 的全部方法受事务管理 在实际开发中,推荐只在 Service 层的方法或类上标注,保持粒度清晰。 常用属性 属性 说明 默认值 rollbackFor 指定哪些异常触发回滚 仅 RuntimeException propagation 指定事务传播行为 Propagation.REQUIRED ① 回滚规则(rollbackFor) @Transactional(rollbackFor = Exception.class) // 捕获所有异常并回滚 public void delete(Integer id) { ... } 如果只写 @Transactional,则 仅 运行时异常(RuntimeException)会触发回滚。 如要让 检查时异常(Exception)也能回滚,就需显式指定 rollbackFor。 ② 事务传播行为(propagation) 传播行为 父事务已存在时 父事务不存在时 典型用途 / 说明 REQUIRED (默认) 加入父事务→ 共提交 / 回滚 创建新事务 日常业务写操作,保持一致性 REQUIRES_NEW 挂起父事务→ 自己新建事务 自己新建事务 写日志、发送 MQ 等:外层失败也要单独成功 SUPPORTS 加入父事务 非事务方式执行 只读查询:有事务跟随一致性,没有就轻量查询 NOT_SUPPORTED 挂起父事务→ 非事务方式执行 非事务方式执行 大批量/耗时操作,避免长事务锁表 MANDATORY 加入父事务 立即抛异常 防御性编程:强制要求调用方已开启事务 NEVER 立即抛异常 非事务方式执行 禁止在事务里跑的代码(如特殊 DDL) NESTED 同一物理事务,打 SAVEPOINT→ 子回滚只回到保存点 创建新事务(与 REQUIRED 效果相同) 分段回滚;需 DB / JDBC 支持保存点 需要“互不影响”时用 REQUIRES_NEW——强制新建事务: @Transactional // 外层保存订单 public void saveOrder(Order order){ orderMapper.insert(order); // 总是单独提交日志 logService.saveLog(...); // 后面出现异常 if(order.getAmount() < 0){ throw new IllegalArgumentException("非法金额"); } } //操作日志、审计表、MQ 消息等,不能因为业务失败而丢记录。 @Transactional(propagation = Propagation.REQUIRES_NEW) public void saveLog(Log log) { ... } 调试:Spring事务日志开关 在 application.yml 中添加: logging: level: org.springframework.jdbc.support.JdbcTransactionManager: debug 效果:控制台会打印事务生命周期日志(开启、提交、回滚等),方便排查。 总结 当 Service 层发生异常 时,Spring 会按照以下顺序处理: 事务的回滚:如果 Service 层抛出了一个异常(如 RuntimeException),并且这个方法是 @Transactional 注解标注的,Spring 会在方法抛出异常时 回滚事务。Spring 事务管理器会自动触发回滚操作。 异常传播到 Controller 层:如果异常在 Service 层处理后未被捕获,它会传播到 Controller 层(即调用 Service 方法的地方)。 全局异常处理器:当异常传播到 Controller 层时,全局异常处理器(@RestControllerAdvice 或 @ControllerAdvice)会捕获并处理该异常,返回给前端一个标准的错误响应。 AOP AOP(Aspect-Oriented Programming,面向切面编程)是一种编程思想,旨在将横切关注点(如日志、性能监控等)从核心业务逻辑中分离出来。简单来说,AOP 是通过对特定方法的增强(如统计方法执行耗时)来实现代码复用和关注点分离。 快速入门 实现业务方法执行耗时统计的步骤 定义模板方法:将记录方法执行耗时的公共逻辑提取到模板方法中。 记录开始时间:在方法执行前记录开始时间。 执行原始业务方法:中间部分执行实际的业务方法。 记录结束时间:在方法执行后记录结束时间,计算并输出执行时间。 通过 AOP,我们可以在不修改原有业务代码的情况下,完成对方法执行耗时的统计。 实现步骤: 导入依赖:在pom.xml中导入AOP的依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency> 编写AOP程序:针对于特定方法根据业务需要进行编程 @Component @Aspect //当前类为切面类 @Slf4j public class TimeAspect { ////第一个星号表示任意返回值,第二个星号表示类/接口,第三个星号表示所有方法。 @Around("execution(* edu.whut.zy123.service.*.*(..))") public Object recordTime(ProceedingJoinPoint pjp) throws Throwable { //记录方法执行开始时间 long begin = System.currentTimeMillis(); //执行原始方法 Object result = pjp.proceed(); //记录方法执行结束时间 long end = System.currentTimeMillis(); //计算方法执行耗时,pjp.getSignature()获得函数名 log.info(pjp.getSignature()+"执行耗时: {}毫秒",end-begin); return result; } } 我们通过AOP入门程序完成了业务方法执行耗时的统计,那其实AOP的功能远不止于此,常见的应用场景如下: 记录系统的操作日志 权限控制 事务管理:我们前面所讲解的Spring事务管理,底层其实也是通过AOP来实现的,只要添加@Transactional注解之后,AOP程序自动会在原始方法运行前先来开启事务,在原始方法运行完毕之后提交或回滚事务 核心概念 1. 连接点:JoinPoint,可以被AOP控制的方法,代表方法的执行位置 2. 通知:Advice,指对目标方法的“增强”操作 (体现为额外的代码) 3. 切入点:PointCut,是一个表达式,匹配连接点的条件,它指定了 在目标方法的哪些位置插入通知,比如在哪些方法调用之前、之后、或者哪些方法抛出异常时进行增强。 4. 切面:Aspect,通知与切入点的结合 5.目标对象:Target,被 AOP 代理的对象,通知会作用到目标对象的对应方法上。 示例: @Slf4j @Component @Aspect public class MyAspect { @Before("execution(* edu.whut.zy123.service.MyService.doSomething(..))") public void beforeMethod(JoinPoint joinPoint) { // 连接点:目标方法执行位置 System.out.println("Before method: " + joinPoint.getSignature().getName()); } } joinPoint 代表的是 doSomething() 方法执行的连接点。 beforeMethod() 方法就是一个前置通知 "execution(* com.example.service.MyService.doSomething(..))"是切入点 MyAspect是切面。 com.example.service.MyService 类的实例是目标对象 通知类型 @Around:环绕通知。此通知会在目标方法前后都执行。 @Before:前置通知。此通知在目标方法执行之前执行。 @After :后置通知。此通知在目标方法执行后执行,无论方法是否抛出异常。 @AfterReturning : 返回后通知。此通知在目标方法正常返回后执行,发生异常时不会执行。 @AfterThrowing : 异常后通知。此通知在目标方法抛出异常后执行。 在使用通知时的注意事项: @Around 通知必须调用 ProceedingJoinPoint.proceed() 才能执行目标方法,其他通知不需要。 @Around 通知的返回值必须是 Object 类型,用于接收原始方法的返回值。 只有@Around需要在通知中主动执行方法,其他通知只能获取目标方法的参数等。 通知执行顺序 默认情况下,不同切面类的通知执行顺序由类名的字母顺序决定。 可以通过 @Order 注解指定切面类的执行顺序,数字越小,优先级越高。 例如:@Order(1) 表示该切面类的通知优先执行。 @Aspect @Order(1) // 优先级1 @Component public class AspectOne { @Before("execution(* edu.whut.zy123.service.MyService.*(..))") public void beforeMethod() { System.out.println("AspectOne: Before method"); } } @Aspect @Order(2) // 优先级2 @Component public class AspectTwo { @Before("execution(* edu.whut.zy123.service.MyService.*(..))") public void beforeMethod() { System.out.println("AspectTwo: Before method"); } } 如果调用 MyService 中的某个方法,AspectOne切面类中的通知会先执行。 结论:目标方法前的通知方法,Order小的或者类名的字母顺序在前的先执行。 目标方法后的通知方法,Order小的或者类名的字母顺序在前的后执行。 相对于显式设置(Order)的通知,默认通知的优先级最低。 切入点表达式 作用:主要用来决定项目中的哪些方法需要加入通知 常见形式: execution(……):根据方法的签名来匹配 @annotation(……) :根据注解匹配 execution execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为: execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?) 其中带?的表示可以省略的部分 访问修饰符:可省略(比如: public、protected) 包名.类名.: 可省略,但不建议 throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常) 示例: //如果希望匹配 public void delete(Integer id) @Before("execution(void edu.whut.zy123.service.impl.DeptServiceImpl.delete(java.lang.Integer))") //如果希望匹配 public void delete(int id) @Before("execution(void edu.whut.zy123.service.impl.DeptServiceImpl.delete(int))") 在 Pointcut 表达式中,为了确保匹配准确,通常建议对非基本数据类型使用全限定名。这意味着,对于像 Integer 这样的类,最好写成 java.lang.Integer 可以使用通配符描述切入点 * :单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分 execution(* edu.*.service.*.update*(*)) 这里update后面的'星'即通配方法名的一部分,() 中的'*'表示有且仅有一个任意参数 可以匹配: package edu.zju.service; public class UserService { public void updateUser(String username) { // 方法实现 } } .. :多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数 execution(* com.example.service.UserService.*(..)) 公共表示@Pointcut 使用 @Pointcut 注解可以将切点表达式提取到一个独立的方法中,提高代码复用性和可维护性。 @Aspect @Component public class LoggingAspect { // 定义一个切点,匹配com.example.service包下 UserService 类的所有方法 @Pointcut("execution(public * com.example.service.UserService.*(..))") public void userServiceMethods() { // 该方法仅用来作为切点标识,无需实现任何内容 } // 在目标方法执行前执行通知,引用上面的切点 @Before("userServiceMethods()") public void beforeUserServiceMethods() { System.out.println("【日志】即将执行 UserService 中的方法"); } } @annotation 在实际项目中,有时我们需要对多个方法(比如 list() 和 delete())进行统一拦截,这些方法可能命名无规律、无法用 execution() 之类的表达式轻松匹配。 这时就可以: 给这些方法统一加一个自定义注解; 在 AOP 切面里用 @annotation(...) 表达式匹配这些方法; 这样写的切入点既简单又易维护。 实现步骤: ① 定义注解 import java.lang.annotation.*; @Retention(RetentionPolicy.RUNTIME) // 运行时可反射获取 @Target(ElementType.METHOD) // 只能标记方法 public @interface MyLog { String description() default "default description"; // 描述信息 int value() default 0; // 额外参数 } @Retention(RUNTIME) 保证运行时可以通过反射拿到注解。 @Target(METHOD) 限制只能用于方法。 ②在业务方法上加注解 @Service public class DeptService { @MyLog(description = "删除部门", value = 1) public void delete(Integer id) { deptMapper.delete(id); } @MyLog(description = "查询部门列表") public List<Dept> list() { return deptMapper.findAll(); } } ③定义切面 @Aspect @Component public class MyLogAspect { @Before("@annotation(myLog)") // 绑定注解对象到参数 public void before(JoinPoint joinPoint, MyLog myLog) { String methodName = joinPoint.getSignature().getName(); System.out.println("方法:" + methodName); System.out.println("注解描述:" + myLog.description()); System.out.println("注解值:" + myLog.value()); } } @annotation(myLog) 表示匹配所有带 @MyLog 的方法; myLog 参数 会直接被赋值为该方法上的注解实例,可以直接读取注解里的属性值; 不需要手动反射去找注解,Spring AOP 自动完成了注解解析和注入。 连接点JoinPoint 执行: ProceedingJoinPoint 和 JoinPoint 都是调用 proceed() 就会执行被代理的方法 Object result = joinPoint.proceed(); 获取调用方法时传递的参数 ,即使只有一个参数, 也以数组形式返回: Object[] args = joinPoint.getArgs(); getSignature(): 返回一个Signature类型的对象,这个对象包含了被拦截点的签名信息。在方法调用的上下文中,这包括了方法的名称、声明类型等信息。 方法名称:可以通过调用getName()方法获得。 声明类型:方法所在的类或接口的完全限定名,可以通过getDeclaringTypeName()方法获取。 返回类型(对于方法签名):可以通过将Signature对象转换为更具体的MethodSignature类型,并调用getReturnType()方法获取。 WEB开发总体图
后端学习
zy123
1年前
0
36
0
上一页
1
...
10
11
12
下一页