首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
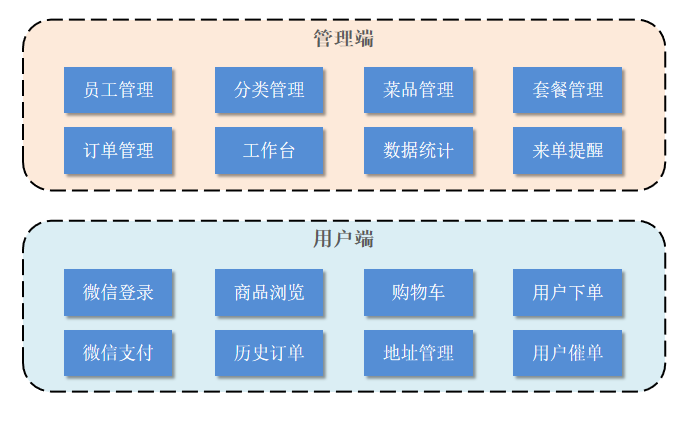
苍穹外卖
43 阅读
4
动态图神经网络
41 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
推荐文章
推荐
拼团设计模式
项目
1年前
0
12
0
推荐
拼团交易系统
项目
1年前
0
41
1
推荐
Smile云图库
项目
1年前
0
60
0
热门文章
146 ℃
同步本地Markdown至Typecho站点
项目
1年前
0
146
0
47 ℃
微服务
后端学习
1年前
0
47
0
43 ℃
苍穹外卖
项目
1年前
0
43
0
最新发布
2025-03-21
力扣Hot 100题
力扣Hot 100题 杂项 最大值:Integer.MAX_VALUE 最小值:Integer.MIN_VALUE 数组集合比较 Arrays.equals(array1, array2) 用于比较两个数组是否相等(内容相同)。 支持多种类型的数组(如 int[]、char[]、Object[] 等)。 int[] arr1 = {1, 2, 3}; int[] arr2 = {1, 2, 3}; boolean isEqual = Arrays.equals(arr1, arr2); // true Collections 类本身没有直接提供类似 Arrays.equals 的方法来比较两个集合的内容是否相等。不过,Java 中的集合类(如 List、Set、Map)已经实现了 equals 方法 List<Integer> list1 = Arrays.asList(1, 2, 3); List<Integer> list2 = Arrays.asList(1, 2, 3); List<Integer> list3 = Arrays.asList(3, 2, 1); System.out.println(list1.equals(list2)); // true System.out.println(list1.equals(list3)); // false(顺序不同) 逻辑比较 boolean flag = false; if (!flag) { //! 是 Java 中的逻辑非运算符,只能用于对布尔值取反。 System.out.println("flag 是 false"); } if (flag == false) { //更常用! System.out.println("flag 是 false"); } //java中没有 if(not flag) 这种写法! Character好用的方法 Character.isDigit(char c)用于判断一个字符是否是一个数字字符 Character.isLetter(char c)用于判断字符是否是一个字母(大小写字母都可以)。 Character.isLowerCase(char c)判断字符是否是小写字母。 Character.toLowerCase(char c)将字符转换为小写字母。 Integer好用的方法 Integer.parseInt(String s):将字符串 s 解析为一个整数(int)。 Integer.parseInt(String s, int radix) :指定进制,指定字符串所用的进制,返回十进制的int值 int num1 = Integer.parseInt("1010", 2); // 二进制 1010 → 十进制 10 int num2 = Integer.parseInt("A", 16); // 十六进制 A → 十进制 10 System.out.println(num1); // 10 System.out.println(num2); // 10 Integer.toString(int i):将 int 转换为字符串。 Integer.compare(int a,int b) 比较a和b的大小,内部实现类似: public static int compare(int x, int y) { return (x < y) ? -1 : ((x == y) ? 0 : 1); } 避免了 整数溢出 的风险,在排序中建议使用Integer.compare(a,b)代替 a-b。注意,仅支持Integer[] arr,不支持int[] arr。 int->String public class BaseConverter { // 将十进制数 n 转换为 base 进制(2 <= base <= 36) public static String toBase(int n, int base) { if (n == 0) return "0"; StringBuilder sb = new StringBuilder(); boolean negative = n < 0; // 处理负数 if (negative) n = -n; while (n > 0) { int digit = n % base; // 取余得到最后一位 if (digit < 10) { sb.append((char) (digit + '0')); // 0~9 } else { sb.append((char) (digit - 10 + 'A')); // 10~35 → A~Z } n /= base; } if (negative) sb.append('-'); // 负数加符号 return sb.reverse().toString(); // 翻转得到正确顺序 } public static void main(String[] args) { System.out.println(toBase(255, 2)); // 二进制: 11111111 System.out.println(toBase(255, 8)); // 八进制: 377 System.out.println(toBase(255, 16)); // 十六进制: FF System.out.println(toBase(12345, 36));// 36进制: 9IX } } String 转为字符串: String s1 = String.valueOf(123); // "123" String s2 = String.valueOf(true); // "true" String s3 = String.valueOf('a'); // "a" 比较: a.compareTo(b); 比较字符串a和b的大小。 格式化: String result = String.format(String format, Object... args); format:格式模板(里面包含占位符)。 args:传入的参数,会依次替换占位符。 %s —— 字符串 %d —— 整数 %f —— 浮点数(默认保留 6 位小数) %n —— 换行 //1. 拼接字符串 String name = "Alice"; int age = 23; String result = String.format("My name is %s, I am %d years old.", name, age); System.out.println(result); // 输出: My name is Alice, I am 23 years old. //2. 控制浮点数精度 double pi = 3.14159265358979; String result = String.format("PI = %.2f", pi); System.out.println(result); // 输出: PI = 3.14 排序: 需要String先转为char [] 数组,排序好之后再转为String类型!! char[] charArray = str.toCharArray(); Arrays.sort(charArray); //{'2', '2', '9', '9'} String sortedStr = new String(charArray); "2299" iter遍历,也要先转为char[]数组 int[]cnt=new int[26]; for (Character c : s.toCharArray()) { cnt[c-'a']++; } 取字符: charAt(int index) 方法返回指定索引处的 char 值。 char 是基本数据类型,占用 2 个字节,表示一个 Unicode 字符。 HashSet<Character> set = new HashSet<Character>(); 取子串: substring(int beginIndex, int endIndex) 方法返回从 beginIndex 到 endIndex - 1 的子字符串。 返回的是 String 类型,即使子字符串只有一个字符。 去除开头结尾空字符: trim() 分割字符串: split() 方法,可以用来分割字符串,并返回一个字符串数组。参数是String类型的正则表达式。 String str = "apple, banana, orange grape"; String[] fruits = str.split(",\\s*"); // 按逗号后可能存在的空格分割 // apple banana orange grape s = "ababbc" String[] parts = s.split("c"); // ["ababb"] 仅用stringbuilder: public static List<String> splitBySpace(String s) { List<String> words = new ArrayList<>(); StringBuilder sb = new StringBuilder(); for (int i = 0; i < s.length(); i++) { char c = s.charAt(i); if (c != ' ') { // 累积字母 sb.append(c); } else { // 遇到空格:如果 sb 里有内容,则构成一个单词 if (sb.length() > 0) { words.add(sb.toString()); sb.setLength(0); // 清空,准备下一个单词 } // 如果连续多个空格,则这里会跳过 sb.length()==0 的情况 } } // 循环结束后,sb 里可能还剩最后一个单词 if (sb.length() > 0) { words.add(sb.toString()); } return words; } 位运算 按位与 &:只有两个对应位都为 1 时,结果位才为 1。 int a = 5; // 0101₂ int b = 3; // 0011₂ int c = a & b; // 0001₂ = 1 System.out.println(c); // 输出 1 典型用途: 清零低位:x & (~((1<<k)-1)) 清掉最低 k 位; (1<<3)-1 = 0000_0111 ~((1<<3)-1) = 1111_1000 判断奇偶:x & 1,若结果是 1 说明奇数,若 0 说明偶数; 掩码提取:只保留想要的位置,其他位置置 0。 取低8位:与0xFF(二进制 11111111)进行按位与(&)操作 按位或 |: 只要两个对应位有一个为 1,结果位就为 1。 int a = 5; // 0101₂ int b = 3; // 0011₂ int c = a | b; // 0111₂ = 7 System.out.println(c); // 输出 7 典型用途: 置位:x | (1<<k) 把第 k 位置 1; 合并标志:将两个掩码或在一起。 按位异或 ^: 两个对应位不同则为 1,相同则为 0。 int a = 5; // 0101₂ int b = 3; // 0011₂ int c = a ^ b; // 0110₂ = 6 System.out.println(c); // 输出 6 算术左移 <<: 整体二进制左移 n 位,右侧补 0;相当于乘以 2ⁿ。(因为最高位可能走出符号位,结果符号可能翻转) int a = 3; // 0011₂ int b = a << 2; // 1100₂ = 12 System.out.println(b); // 输出 12 逻辑(无符号)右移>>>:在最高位一律补 0,不管原符号位是什么。 Random Random 是伪随机数生成器 nextInt() 任意 int Integer.MIN_VALUE … Integer.MAX_VALUE nextInt(bound) 0(含)至 bound(不含) [0, bound) import java.util.Random; import java.util.stream.IntStream; public class RandomDemo { public static void main(String[] args) { Random rnd = new Random(); // 随机种子 Random seeded = new Random(2025L); // 固定种子 // 1) 随机整数 int a = rnd.nextInt(); // 任意 int int b = rnd.nextInt(100); // [0,100) System.out.println("a=" + a + ", b=" + b); // 2) 随机浮点数与布尔 double d = rnd.nextDouble(); // [0.0,1.0) boolean flag = rnd.nextBoolean(); System.out.println("d=" + d + ", flag=" + flag); } } 想生成5 到 10 之间的整数: public class RandomRangeDemo { public static void main(String[] args) { Random rnd = new Random(); int min = 5; int max = 10; int n = rnd.nextInt(max - min + 1) + min; System.out.println("随机数 = " + n); } } 常用数据结构 StringBuilder StringBuffer 是线程安全的,它的方法是同步的 (synchronized),这意味着在多线程环境下使用 StringBuffer 是安全的。 StringBuilder 不是线程安全的,它的方法没有同步机制,因此在单线程环境中,StringBuilder 的性能通常要比 StringBuffer 更好。 它们都是 Java 中用于操作可变字符串的类,拥有相同的方法! 1.append(String str) 向字符串末尾追加内容。 2.insert(int offset, String str) 在指定位置插入字符串。(有妙用,头插法可以实现倒序)insert(0,str) 3.delete(int start, int end) 删除从 start 到 end 索引之间的字符。(包括start,不包括end) 4.deleteCharAt(int index) 删除指定位置的字符。 5.replace(int start, int end, String str) 替换指定范围内的字符。 6.reverse() 将字符串反转。String未提供 重要内容!!!! 7.toString() 返回当前字符串缓冲区的内容,转换为 String 对象。 sb.toString()会创建并返回一个新的、独立的 String 对象,之后setLength(0)不会影响这个 String 对象 8.setLength(int newLength) 设置字符串的长度。 //sb.setLength(0); 用作清空字符串 9.charAt(int index) 返回指定位置的字符。 10.length() 返回当前字符串的长度。 StringBuffer 的 append() 方法不仅支持添加普通的字符串,也可以直接将另一个 StringBuffer 对象添加到当前的 StringBuffer。 StringBuffer 插入int类型的数字时,会自动转为字符串插入。 HashMap 基于哈希表实现,查找、插入和删除的平均时间复杂度为 O(1)。 不保证元素的顺序。 import java.util.HashMap; import java.util.Map; public class HashMapExample { public static void main(String[] args) { // 创建 HashMap Map<String, Integer> map = new HashMap<>(); // 添加键值对 map.put("apple", 10); map.put("banana", 20); map.put("orange", 30); // 获取值 int appleCount = map.get("apple"); //如果获取不存在的元素,返回null System.out.println("Apple count: " + appleCount); // 输出 10 // 遍历 HashMap for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println(entry.getKey() + ": " + entry.getValue()); } // 输出: // apple: 10 // banana: 20 // orange: 30 // 检查是否包含某个键 boolean containsBanana = map.containsKey("banana"); System.out.println("Contains banana: " + containsBanana); // 输出 true // 删除键值对 map.remove("orange"); //删除不存在的元素也不会报错 System.out.println("After removal: " + map); // 输出 {apple=10, banana=20} } } 如何在创建的时候初始化?“双括号”初始化 Map<Integer, Character> map = new HashMap<>() {{ put(1, 'a'); put(2, 'b'); put(3, 'c'); }}; 记录二维数组中某元素是否被访问过,推荐使用: int m = grid.length; int n = grid[0].length; boolean[][] visited = new boolean[m][n]; // 访问 (i, j) 时标记为已访问 visited[i][j] = true; 而非创建自定义Pair二元组作为键用Map记录。 统计每个字母出现的次数: int[] cnt = new int[26]; for (char c : magazine.toCharArray()) { cnt[c - 'a']++; } 修改键值对中的键值: Map<Character, Integer> counts = new HashMap<>(); counts.put(ch, counts.getOrDefault(ch, 0) + 1); 如何遍历Map? 只关心 键 的时候: Map<String, Integer> map = new HashMap<>(); map.put("Tom", 18); map.put("Jerry", 20); // 遍历 key for (String key : map.keySet()) { System.out.println("key = " + key); } 只关心 值 的时候: for (Integer value : map.values()) { System.out.println("value = " + value); } 同时获取 键和值: for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println(entry.getKey() + " -> " + entry.getValue()); } HashSet 基于哈希表实现,查找、插入和删除的平均时间复杂度为 O(1)。 不保证元素的顺序!!因此不太用iterator迭代,而是用contains判断是否有xx元素。 import java.util.HashSet; import java.util.Set; public class HashSetExample { public static void main(String[] args) { // 创建 HashSet Set<Integer> set = new HashSet<>(); // 添加元素 set.add(10); set.add(20); set.add(30); set.add(10); // 重复元素,不会被添加 // 检查元素是否存在 boolean contains20 = set.contains(20); System.out.println("Contains 20: " + contains20); // 输出 true // 遍历 HashSet for (int num : set) { System.out.println(num); } // 输出: // 20 // 10 // 30 // 删除元素 set.remove(20); System.out.println("After removal: " + set); // 输出 [10, 30] } } public void isHappy() { Set<Integer> set1 = new HashSet<>(List.of(1,2,3)); Set<Integer> set2 = new HashSet<>(List.of(2,3,1)); Set<Integer> set3 = new HashSet<>(List.of(3,2,1)); Set<Set<Integer>> sset = new HashSet<>(); sset.add(set1); sset.add(set2); sset.add(set3); } 这里最终sset的size为1 如何从List中初始化Set? Set<String> set1 = new HashSet<>(wordList); //构造器直接初始化 如何从Array中初始化? Set<String> set1 = new HashSet<>(Arrays.asList(wordList)); //构造器直接初始化 PriorityQueue 基于优先堆(最小堆或最大堆)实现,元素按优先级排序。 默认是最小堆,即队首元素是最小的。 new PriorityQueue<>(Comparator.reverseOrder());定义最大堆 支持自定义排序规则,通过 Comparator 实现。 常用方法: add(E e) / offer(E e): 功能:将元素插入队列。 时间复杂度:O(log n) 区别 add:当队列满时会抛出异常。 offer:当队列满时返回 false,不会抛出异常。 remove() / poll(): 功能:移除并返回队首元素。 时间复杂度:O(log n) 区别 remove:队列为空时抛出异常。 poll:队列为空时返回 null。 element() / peek(): 功能:查看队首元素,但不移除。 时间复杂度:O(1) 区别 element:队列为空时抛出异常。 peek:队列为空时返回 null。 clear(): 功能:清空队列。 时间复杂度:O(n)(因为需要删除所有元素) import java.util.PriorityQueue; import java.util.Comparator; public class PriorityQueueExample { public static void main(String[] args) { // 创建 PriorityQueue(默认是最小堆) PriorityQueue<Integer> minHeap = new PriorityQueue<>(); // 添加元素 minHeap.add(10); minHeap.add(20); minHeap.add(5); // 查看队首元素 System.out.println("队首元素: " + minHeap.peek()); // 输出 5 // 遍历 PriorityQueue(注意:遍历顺序不保证有序) System.out.println("遍历 PriorityQueue:"); for (int num : minHeap) { System.out.println(num); } // 输出: // 5 // 10 // 20 // 移除队首元素 System.out.println("移除队首元素: " + minHeap.poll()); // 输出 5 // 再次查看队首元素 System.out.println("队首元素: " + minHeap.peek()); // 输出 10 // 创建最大堆(通过自定义 Comparator) PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Comparator.reverseOrder()); maxHeap.add(10); maxHeap.add(20); maxHeap.add(5); // 查看队首元素 System.out.println("最大堆队首元素: " + maxHeap.peek()); // 输出 20 // 清空队列 minHeap.clear(); System.out.println("队列是否为空: " + minHeap.isEmpty()); // 输出 true } } 自定义排序 按第二个元素的值构建小根堆 如果比较器返回负数,则第一个数排在前面->优先级高->在堆顶 public class CustomPriorityQueue { public static void main(String[] args) { // 定义一个 PriorityQueue,其中每个元素是 int[],并且按照数组第二个元素升序排列 PriorityQueue<int[]> minHeap = new PriorityQueue<>( (a, b) -> a[1] - b[1] ); // 添加数组 minHeap.offer(new int[]{1, 2}); minHeap.offer(new int[]{3, 4}); minHeap.offer(new int[]{0, 5}); // 依次取出元素,输出结果 while (!minHeap.isEmpty()) { int[] arr = minHeap.poll(); System.out.println(Arrays.toString(arr)); } } } 不用lambda版本(不推荐): PriorityQueue<int[]> minHeap = new PriorityQueue<>(new Comparator<int[]>() { @Override public int compare(int[] a, int[] b) { return a[1] - b[1]; } }); 自己实现小根堆 父节点:对于任意索引 i,其父节点的索引为 (i - 1) // 2。 左子节点:索引为 i 的节点,其左子节点的索引为 2 * i + 1。 右子节点:索引为 i 的节点,其右子节点的索引为 2 * i + 2。 上滤与下滤操作 上滤(Sift-Up): 用于插入操作。将新加入的元素与其父节点不断比较,若小于父节点则交换,直到满足堆序性质。 下滤(Sift-Down): 用于删除操作或建堆。将根节点或某个节点与其子节点中较小的进行比较,若大于子节点则交换,直至满足堆序性质。 建堆:从数组中最后一个非叶节点开始(索引为 heapSize/2 - 1),对每个节点执行下滤操作(sift-down) 插入元素:将新元素插入到堆的末尾,然后执行上滤操作(sift-up),以保持堆序性质。 弹出元素(删除堆顶):弹出操作一般是删除堆顶元素(小根堆中即最小值),然后用堆尾元素替代堆顶,再进行下滤操作。 class MinHeap { private int[] heap; // 数组存储堆元素 private int size; // 当前堆中元素的个数 // 构造函数,初始化堆,capacity为堆的最大容量 public MinHeap(int capacity) { heap = new int[capacity]; size = 0; } // 插入元素:先将新元素添加到数组末尾,然后执行上滤操作恢复堆序性质 public void insert(int value) { if (size >= heap.length) { throw new RuntimeException("Heap is full"); } // 将新元素放到末尾 heap[size] = value; int i = size; size++; // 上滤操作:不断与父节点比较,若新元素小于父节点则交换 while (i > 0) { int parent = (i - 1) / 2; if (heap[i] < heap[parent]) { swap(heap, i, parent); i = parent; } else { break; } } } // 弹出堆顶元素:移除堆顶(最小值),用最后一个元素替换堆顶,然后下滤恢复堆序 public int pop() { if (size == 0) { throw new RuntimeException("Heap is empty"); } int min = heap[0]; // 将最后一个元素移到堆顶 heap[0] = heap[size - 1]; size--; // 对新的堆顶执行下滤操作,恢复堆序性质 minHeapify(heap, 0, size); return min; } // 建堆:将无序数组a构造成小根堆,heapSize为数组长度 public static void buildMinHeap(int[] a, int heapSize) { for (int i = heapSize / 2 - 1; i >= 0; --i) { minHeapify(a, i, heapSize); } } // 下滤操作:从索引i开始,将子树调整为小根堆 public static void minHeapify(int[] a, int i, int heapSize) { int l = 2 * i + 1, r = 2 * i + 2; int smallest = i; // 判断左子节点是否存在且比当前节点小 if (l < heapSize && a[l] < a[smallest]) { smallest = l; } // 判断右子节点是否存在且比当前最小节点小 if (r < heapSize && a[r] < a[smallest]) { smallest = r; } // 如果最小值不是当前节点,交换后继续对被交换的子节点执行下滤操作 if (smallest != i) { swap(a, i, smallest); minHeapify(a, smallest, heapSize); } } // 交换数组中两个位置的元素 public static void swap(int[] a, int i, int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; } } 改为大根堆只需要把里面 ''<'' 符号改为 ''>'' ArrayList 1.基本特性 基于数组实现,支持动态扩展。 随机访问效率高:get()、set() 时间复杂度为 O(1)。 末尾插入/删除效率高:add(E e)、remove(size-1) 时间复杂度为 O(1)(均摊)。 指定位置插入/删除效率低:add(int index, E e)、remove(int index) 时间复杂度为 O(n),因为需要移动元素。 2.常用操作 添加元素 List<Integer> list = new ArrayList<>(); list.add(10); list.add(20); list.add(30); 获取大小 int size = list.size(); // 3 访问和修改元素 int first = list.get(0); // 10 list.set(1, 25); // 修改第二个元素为 25 删除元素 list.remove(2); // 删除索引为2的元素 遍历 //增强 for: for (int num : list) { System.out.println(num); } //普通 for: for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } 3.批量操作 复制列表 List<Integer> list1 = new ArrayList<>(); // 假设 list1 中已有数据 // 方法一:addAll List<Integer> list2 = new ArrayList<>(); list2.addAll(list1); // 方法二:构造函数 List<Integer> list3 = new ArrayList<>(list1); 清空列表 list.clear(); 复制到数组 推荐手动遍历;Java 自带 toArray 也能用但较麻烦。 int[] arr = new int[list.size()]; for (int i = 0; i < list.size(); i++) { arr[i] = list.get(i); } 4.二维 ArrayList 如果事先不知道嵌套列表的大小如何遍历呢? //增强 for: for (List<Integer> row : list) { for (int num : row) { System.out.print(num + " "); } System.out.println(); } //普通 for: for (int i = 0; i < list.size(); i++) { for (int j = 0; j < list.get(i).size(); j++) { System.out.print(list.get(i).get(j) + " "); } System.out.println(); } 数组(Array) 数组是一种固定长度的数据结构,用于存储相同类型的元素。数组的特点包括: 固定长度:数组的长度在创建时确定,无法动态扩展。 快速访问:通过索引访问元素的时间复杂度为 O(1)。 连续内存:数组的元素在内存中是连续存储的。 public class ArrayExample { public static void main(String[] args) { // 创建数组 int[] array = new int[5]; // 创建一个长度为 5 的整型数组 // 添加元素 array[0] = 10; array[1] = 20; array[2] = 30; array[3] = 40; array[4] = 50; // 获取元素 int firstElement = array[0]; System.out.println("First element: " + firstElement); // 输出 10 // 修改元素 array[1] = 25; // 将第二个元素改为 25 System.out.println("After modification:"); for (int num : array) { System.out.println(num); } // 输出: // 10 // 25 // 30 // 40 // 50 // 遍历数组 System.out.println("Iterating through array:"); for (int i = 0; i < array.length; i++) { System.out.println("Index " + i + ": " + array[i]); } // 输出: // Index 0: 10 // Index 1: 25 // Index 2: 30 // Index 3: 40 // Index 4: 50 // 删除元素(数组长度固定,无法直接删除,可以通过覆盖实现) int indexToRemove = 2; // 要删除的元素的索引 for (int i = indexToRemove; i < array.length - 1; i++) { array[i] = array[i + 1]; // 将后面的元素向前移动 } array[array.length - 1] = 0; // 最后一个元素置为 0(或其他默认值) System.out.println("After removal:"); for (int num : array) { System.out.println(num); } // 输出: // 10 // 25 // 40 // 50 // 0 // 数组长度 int length = array.length; System.out.println("Array length: " + length); // 输出 5 } } 复制数组: int[] source = {1, 2, 3, 4, 5}; int[] destination = Arrays.copyOf(source, source.length); int[] partialArray = Arrays.copyOfRange(source, 1, 4); //复制指定元素,不包括索引4 初始化: int double 数值默认初始化为0,boolean默认初始化为false //一维 int[] memo = new int[nums.length]; Arrays.fill(memo, -1); //二维 int[][] test=new int[2][2]; for (int[] ints : test) { Arrays.fill(ints,1); } 注意:数组求size: xx.length; String求size:xx.length(); List求size:xx.size(); 二维数组 int[][] res = new int[rows][]; 只指定了二维数组的“行数”,没有指定“列数”。这是 Java 里允许的。 int rows = 3; int cols = 3; int[][] array = new int[rows][cols]; // 填充数据 for (int i = 0; i < rows; i++) { for (int j = 0; j < cols; j++) { array[i][j] = i * cols + j + 1; } } //创建并初始化 int[][] array = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; // 遍历二维数组,不知道几行几列 public void setZeroes(int[][] matrix) { // 遍历每一行 for (int i = 0; i < matrix.length; i++) { // 遍历当前行的每一列 for (int j = 0; j < matrix[i].length; j++) { // 这里可以处理 matrix[i][j] 的元素 System.out.print(matrix[i][j] + " "); } System.out.println(); // 换行,便于输出格式化 } } [[1, 0]] 是一行两列数组。 Queue 队尾插入,队头取! import java.util.Queue; import java.util.LinkedList; public class QueueExample { public static void main(String[] args) { // 创建一个队列 Queue<Integer> queue = new LinkedList<>(); // 添加元素到队列中 queue.add(10); // 使用 add() 方法添加元素 queue.offer(20); // 使用 offer() 方法添加元素 queue.add(30); System.out.println("队列内容:" + queue); // 查看队头元素,不移除 int head = queue.peek(); System.out.println("队头元素(peek): " + head); // 移除队头元素 int removed = queue.poll(); System.out.println("移除的队头元素(poll): " + removed); System.out.println("队列内容:" + queue); // 再次移除队头元素 int removed2 = queue.remove(); System.out.println("移除的队头元素(remove): " + removed2); System.out.println("队列内容:" + queue); } } Deque(双端队列+栈) 支持在队列的两端(头和尾)进行元素的插入和删除。这使得 **Deque 既能作为队列(FIFO)又能作为栈(LIFO)使用。**栈可以看作双端队列的特例,即使用一端。 LinkedList 是基于双向链表实现的,每个节点存储数据和指向前后节点的引用。 ArrayDeque 则基于动态数组实现,内部使用循环数组来存储数据。 ArrayDeque 在大多数情况下性能更好,因为数组在内存中连续,缓存友好,且操作(如 push/pop)开销更小。 栈 Deque<Integer> stack = new ArrayDeque<>(); //Deque<Integer> stack = new LinkedList<>(); stack.push(1); // 入栈 Integer top1=stack.peek() Integer top = stack.pop(); // 出栈 双端队列 在队头操作 offerFirst(E e):在队头插入元素,返回 true 或 false 表示是否成功。 peekFirst():查看队头元素,不移除;队列为空返回 null。 pollFirst():移除并返回队头元素;队列为空返回 null。 poll() :移除并返回队头元素 在队尾操作 offerLast(E e):在队尾插入元素,返回 true 或 false 表示是否成功。 offer(E e) : 把元素放到 队尾 peekLast():查看队尾元素,不移除;队列为空返回 null。 pollLast():移除并返回队尾元素;队列为空返回 null。 import java.util.Deque; import java.util.ArrayDeque; public class DequeExampleSafe { public static void main(String[] args) { // 使用 ArrayDeque 实现双端队列 Deque<Integer> deque = new ArrayDeque<>(); /* ========= 在队列两端“安全”地添加元素 ========= */ deque.offerFirst(10); // 队头 ← 10 deque.offerLast(20); // 20 ← 队尾 deque.offerFirst(5); // 队头 ← 5,10,20 deque.offerLast(30); // 队尾 → 5,10,20,30 System.out.println("双端队列内容:" + deque); /* ========= “安全”地查看队头/队尾 ========= */ Integer first = deque.peekFirst(); // 队头元素(5) Integer last = deque.peekLast(); // 队尾元素(30) System.out.println("队头元素:" + first); System.out.println("队尾元素:" + last); /* ========= “安全”地移除队头/队尾 ========= */ Integer removedFirst = deque.pollFirst(); // 移除并返回队头(5) System.out.println("移除队头元素:" + removedFirst); Integer removedLast = deque.pollLast(); // 移除并返回队尾(30) System.out.println("移除队尾元素:" + removedLast); System.out.println("双端队列最终内容:" + deque); } } 栈和双端队列的对应关系 栈只有队头! 添加元素:push(e) ⇒ addFirst(e) (安全版:offerFirst(e)) 删除元素:pop() ⇒ removeFirst() (安全版:pollFirst()) 查看栈顶:peek() ⇒ peekFirst() Iterator HashMap、HashSet、ArrayList 和 PriorityQueue 都实现了 Iterable 接口,支持 iterator() 方法。 Iterator 接口中包含以下主要方法: hasNext():如果迭代器还有下一个元素,则返回 true,否则返回 false。 next():返回迭代器的下一个元素,并将迭代器移动到下一个位置。 remove():从迭代器当前位置删除元素。该方法是可选的,不是所有的迭代器都支持。 import java.util.ArrayList; import java.util.Iterator; public class Main { public static void main(String[] args) { // 创建一个 ArrayList 集合 ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); // 获取集合的迭代器 Iterator<Integer> iterator = list.iterator(); // 使用迭代器遍历集合并输出元素 while (iterator.hasNext()) { Integer element = iterator.next(); System.out.println(element); } } } Collections工具类 1.排序 参数必须是 List<T> Collections.sort(list); 对 list 进行升序排序(要求元素实现了 Comparable 接口,比如 Integer、String)。 Collections.sort(list, Collections.reverseOrder()); 2.反转 参数也是 List<?>。 Collections.reverse(list); //[1,2,3] → [3,2,1] 3.最大 / 最小值 参数是 Collection,可以是Set Collections.max(list); Collections.min(list); 查找 二分查找 public static int lowerBound(int[] arr, int target) { int left = 0, right = arr.length; // 注意 right = arr.length,而不是 arr.length-1 while (left < right) { int mid = (left + right) / 2; if (arr[mid] >= target) { right = mid; // 收缩右边界 } else { left = mid + 1; // 收缩左边界 } } return left; // 最终 left 就是答案 } 排序 快速排序 基本思想: 快速排序是一种基于“分治”思想的排序算法,通过选定一个“枢轴元素(pivot)”,将数组划分为左右两个子区间:左边都小于等于 pivot,右边都大于等于 pivot;然后对这两个子区间递归排序,最终使整个数组有序。 public class QuickSort { /** * 对数组 arr 在下标 low 到 high 范围内进行快速排序 * 使用“挖坑填坑”方式,不再调用 swap 方法 */ public static void quickSort(int[] arr, int low, int high) { if (low < high) { int pivotPos = partition(arr, low, high); // 划分 quickSort(arr, low, pivotPos - 1); // 递归排序左子表 quickSort(arr, pivotPos + 1, high); // 递归排序右子表 } } /** * 划分函数:以 arr[low] 作为枢轴,通过“挖坑—填坑”将小于枢轴的元素移到左边, * 大于枢轴的元素移到右边,最后返回枢轴的最终下标 */ private static int partition(int[] arr, int low, int high) { int pivot = arr[low]; // 先保存枢轴 while (low < high) { // 从右向左找第一个小于 pivot 的元素,填到 left 这个“坑”里 while (low < high && arr[high] >= pivot) { high--; } arr[low] = arr[high]; // 从左向右找第一个大于 pivot 的元素,填到 right 这个“坑”里 while (low < high && arr[low] <= pivot) { low++; } arr[high] = arr[low]; } // 最后把枢轴填回中心位置 arr[low] = pivot; return low; } } 时间复杂度: 1)单次划分(partition):每次调用 partition,都要从数组的两端向中间扫描一遍,直到两个指针相遇。所以 一次 partition 操作的时间复杂度是 O(n) 2)快速排序的核心是 分治:每次划分,把数组分成左右两个子数组,然后分别递归排序。如果每次 pivot 都把数组近似平均分成两半,那么递归树高度大约是 log n。 Java随机 mport java.util.Random; public class RandomDemo { public static void main(String[] args) { Random random = new Random(); int num = random.nextInt(6); // 生成 [0, 5] 的随机整数 System.out.println(num); } } 快速选择 时间复杂度: O(n) public class QuickSelect { /** * 在数组 arr 的 [low..high] 区间内,寻找第 k 小的元素(k 从 0 开始计数) * 使用快速选择(Quick Select)算法,平均时间复杂度 O(n) */ public int quickselect(int[] arr, int low, int high, int k) { if (low <= high) { int pivotPos = partition(arr, low, high); // 划分操作,返回枢轴的最终下标 if (pivotPos == k) { // 找到了第 k 小的元素 return arr[pivotPos]; } else if (k < pivotPos) { // 如果第 k 小元素在枢轴左边 return quickselect(arr, low, pivotPos - 1, k); } else { // 如果第 k 小元素在枢轴右边 return quickselect(arr, pivotPos + 1, high, k); } } // 正常情况下不会走到这里(除非 k 越界) throw new IllegalArgumentException("k is out of bounds"); } /** * 划分函数(partition)—— 挖坑填坑法 * 功能:以 arr[low] 为枢轴,将小于 pivot 的放左边,大于 pivot 的放右边 * 返回枢轴的最终位置(low == high 时) */ private int partition(int[] arr, int low, int high) { int pivot = arr[low]; // 选取枢轴(第一个元素) // “挖坑填坑”过程 while (low < high) { // 从右向左找第一个小于 pivot 的元素 while (low < high && arr[high] >= pivot) { high--; } arr[low] = arr[high]; // 填到左边的“坑”里 // 从左向右找第一个大于 pivot 的元素 while (low < high && arr[low] <= pivot) { low++; } arr[high] = arr[low]; // 填到右边的“坑”里 } // 最后将枢轴填回当前位置 arr[low] = pivot; return low; // 返回枢轴的最终位置 } /** * 返回数组中第 k 大的元素(k 从 1 开始) * 例如:k=1 表示最大值,k=2 表示次大值 */ public int findKthLargest(int[] nums, int k) { int n = nums.length; // 第 k 大 == 第 (n - k) 小 return quickselect(nums, 0, n - 1, n - k); } } 冒泡排序 基本思想: 【每次将最小/大元素,通过依次交换顺序,放到首/尾位。】 从后往前(或从前往后)两两比较相邻元素的值,若为逆序, 则交换它们,直到序列比较完。我们称它为第一趟冒泡,结果是将最小的元素交换到待排序列的第一个位置(或将最大的元素交换到待排序列的最后一个位置); 下一趟冒泡时,前一趟确定的最小元素不再参与比较,每趟冒泡的结果是把序列中的最小元素(或最大元素)放到了序列的最终位置。 ……这样最多做n - 1趟冒泡就能把所有元素排好序。 如若有一趟没有元素交换位置,则可提前说明已排好序。 public void bubbleSort(int[] arr){ //n-1 趟冒泡 for (int i = 0; i < arr.length-1; i++) { boolean flag=false; //冒泡 for (int j = arr.length-1; j >i ; j--) { if (arr[j-1]>arr[j]){ swap(arr,j-1,j); flag=true; } } //本趟遍历后没有发生交换,说明表已经有序 if (!flag){ return; } } } private void swap(int[] arr,int i,int j){ int temp=arr[i]; arr[i]=arr[j]; arr[j]=temp; } 归并排序 数组归并排序 基本思想: 将待排序的数组视为多个有序子表,每个子表的长度为 1,通过两两归并逐步合并成一个有序数组。 实现思路 分解:递归地将数组拆分成两个子数组,直到每个子数组只有一个元素。 合并:将两个有序子数组合并为一个有序数组。 时间复杂度: O(n log n),无论最坏、最好、平均情况。 public class MergeSort { /** * 归并排序(入口函数) * @param arr 待排序数组 */ public static void mergeSort(int[] arr) { if (arr == null || arr.length <= 1) { return; // 边界条件 } int[] temp = new int[arr.length]; // 辅助数组 mergeSort(arr, 0, arr.length - 1, temp); } private static void mergeSort(int[] arr, int left, int right, int[] temp) { if (left < right) { int mid = (right + left) / 2; mergeSort(arr, left, mid, temp); // 递归左子数组 mergeSort(arr, mid + 1, right, temp); // 递归右子数组 merge(arr, left, mid, right, temp); // 合并两个有序子数组 } } private static void merge(int[] arr, int left, int mid, int right, int[] temp) { int i = left; // 左子数组起始指针 int j = mid + 1; // 右子数组起始指针 int t = 0; // 辅助数组指针 // 1. 按序合并两个子数组到temp while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { // 注意等号保证稳定性 temp[t++] = arr[i++]; } else { temp[t++] = arr[j++]; } } // 2. 将剩余元素拷贝到temp while (i <= mid) { temp[t++] = arr[i++]; } while (j <= right) { temp[t++] = arr[j++]; } // 3. 将temp中的数据复制回原数组 t = 0; while (left <= right) { arr[left++] = temp[t++]; } } } 链表归并排序 // 简易链表归并排序示意 ListNode sortList(ListNode head) { if (head == null || head.next == null) return head; // ① 快慢指针找中点并断链 ListNode slow = head, fast = head.next; while (fast != null && fast.next != null) { slow = slow.next; fast = fast.next.next; } ListNode mid = slow.next; slow.next = null; // ② 递归排序左右两段 ListNode left = sortList(head); ListNode right = sortList(mid); // ③ 合并 return merge(left, right); } ListNode merge(ListNode a, ListNode b) { ListNode dummy = new ListNode(-1), p = dummy; while (a != null && b != null) { if (a.val <= b.val) { p.next = a; a = a.next; } else { p.next = b; b = b.next; } p = p.next; } p.next = (a != null ? a : b); return dummy.next; } 快慢指针找 “中点” 和找 “环” 的出发点为什么会不一样? 目标 常见写法 为什么这么设 若改成另一种写法会怎样 拆链/找中点(归并排序、回文检测等) slow = headfast = head.next - 偶数长度更均匀: len = 4 → 最终 slow 停在第 2 个结点(左半长 2,右半长 2)- mid = slow.next 一定非 null(当链长 ≥ 2),递归不会拿到空指针 - fast = head 时 len = 4 → slow 停在第 3 个结点(左半长 3,右半长 1),越分越偏; len = 2 → 左 1 右 0,也能跑,但更不平衡 检测环 slow = headfast = head - 只要两指针步幅不同,就会在环内相遇;- 起点放哪都行,写成同一起点最直观,也少一次空指针判断 如果写成 fast = head.next 也能检测环,但需先判断 head.next 是否为空,代码更啰嗦;并且两指针初始就“错开一步”,相遇时步数不同,求环长或入环点时要再做偏移 总之:自己模拟一遍,奇数和偶数的情况。 堆排序 下滤 从一个节点出发,如果它不满足堆的性质(父节点比子节点小——针对最大堆),就和它的较大子节点交换, 然后继续向下检查,直到满足堆性质或到达叶子节点。 堆排序示例 初始数组:[7, 3, 4, 2, 6, 8] 1️⃣ 建堆(Build Max Heap) 使整个数组满足“父节点 ≥ 子节点”的性质。 从最后一个非叶子节点开始下滤(i = n/2 - 1 = 2) (1) i = 2 → 元素 4 子节点:5=8 → 8 比 4 大 → 交换 → [7, 3, 8, 2, 6, 4] (2) i = 1 → 元素 3 子节点:3=2, 4=6 → 最大子节点为 6 → 交换 → [7, 6, 8, 2, 3, 4] (3) i = 0 → 元素 7 子节点:1=6, 2=8 → 最大子节点是 8 → 交换 → [8, 6, 7, 2, 3, 4] 建堆完成(最大堆) 2️⃣ 交换堆顶与末尾元素 把最大值放到数组末尾,相当于固定下来了。 3️⃣ 调整堆(Heapify) 重新调整剩余部分为最大堆。 4️⃣ 重复步骤 2 和 3,直到排序完成。 基数排序 时间复杂度: O(d × (n + k)) 其中 d 是数字的位数,k 是每位的取值范围(例如 0–9)。 排序0-999范围的整数: 创建10个桶(对应数字0-9) 按个位数字分配到桶中 按十位数字重新分配 按百位数字最后分配 按顺序收集桶中元素 示例: [352, 143, 129, 457, 65, 97, 8, 452, 72, 290] 第一步:按个位数分配 桶0: 290 桶1: 桶2: 352, 452, 72 桶3: 143 桶4: 桶5: 65 桶6: 桶7: 457, 97 桶8: 8 桶9: 129 收集结果:[290, 352, 452, 72, 143, 65, 457, 97, 8, 129] 第二步:按十位数分配 桶0: 8 桶1: 桶2: 129 桶3: 桶4: 143 桶5: 352, 452, 457 桶6: 65 桶7: 72 桶8: 桶9: 290, 97 收集结果:[8, 129, 143, 352, 452, 457, 65, 72, 290, 97] 第三步:按百位数分配 桶0: 8, 65, 72, 97 桶1: 129, 143 桶2: 290 桶3: 352 桶4: 452, 457 桶5: 桶6: 桶7: 桶8: 桶9: 收集结果:[8, 65, 72, 97, 129, 143, 290, 352, 452, 457] 数组排序 1)默认升序: Arrays.sort(array) 会对整个数组升序排序。 也可以指定区间 [fromIndex, toIndex),只排序部分数组。 import java.util.Arrays; public class ArraySortExample { public static void main(String[] args) { int[] numbers = {5, 2, 9, 1, 5, 6}; Arrays.sort(numbers); // 全部升序排序 System.out.println(Arrays.toString(numbers)); // [1, 2, 5, 5, 6, 9] Arrays.sort(numbers, 1, 4); // 只对下标 [1,4) → {2,9,1} 排序 System.out.println(Arrays.toString(numbers)); } } 2)自定义降序: 如果数组元素是 对象类型(如 Integer[]、String[] 或自定义类),可以直接使用 Comparator 实现复杂排序规则。 import java.util.*; public class DescendingSortExample { public static void main(String[] args) { Integer[] arr = {5, 2, 9, 1, 5, 6}; // 使用 Comparator + Lambda 实现降序 Arrays.sort(arr, (a, b) -> Integer.compare(b, a)); // 或者使用内置的 reverseOrder() Arrays.sort(arr, Collections.reverseOrder()); // 也可以指定区间 [1,4),对 {2,9,1} 排序 Arrays.sort(arr, 1, 4, Collections.reverseOrder()); System.out.println(Arrays.toString(arr)); } } 3)基本类型数组的降序 Arrays.sort() 对基本类型(int[]、double[] 等)只支持 升序。 如果要降序,需要先升序,再反转数组。 public class DescendingPrimitiveSort { public static void main(String[] args) { int[] arr = {5, 2, 9, 1, 5, 6}; // 先排序(升序) Arrays.sort(arr); // 反转数组 for (int i = 0; i < arr.length / 2; i++) { int temp = arr[i]; arr[i] = arr[arr.length - 1 - i]; arr[arr.length - 1 - i] = temp; } // 输出结果 System.out.println(Arrays.toString(arr)); } } 集合排序 java 里通常说的“集合”,是指 实现了 java.util.Collection 接口的类,以及 Map 相关的类。 1)自然顺序排序(默认升序): Collections.sort(numbers); 等价于: numbers.sort(null); // Java 8 推荐写法 适用于元素实现了 Comparable 接口(如 Integer、String)。 2)降序排序 Collections.sort(numbers, Collections.reverseOrder()); 或者: numbers.sort((a, b) -> Integer.compare(b,a)); 3)自定义降序(Comparator + Lambda) List<String> names = Arrays.asList("Tom", "Jerry", "Alice", "Bob"); // 按字符串长度升序 names.sort((s1, s2) -> Integer.compare(s1.length(), s2.length())); 补充: Comparator.reverseOrder() // `Comparator<T>` 接口的静态方法 //等价于 Collections.reverseOrder() 自定义排序Comparator 说明 要实现接口自定义排序,必须实现 Comparator<T> 接口的 compare(T o1, T o2) 方法。 @FunctionalInterface public interface Comparator<T> { int compare(T o1, T o2); // 唯一抽象方法 ✅ // 以下都是 default 或 static 方法(不是抽象方法) default Comparator<T> reversed() { ... } static <T extends Comparable<? super T>> Comparator<T> reverseOrder() { ... } } Comparator 接口中定义的 compare(T o1, T o2) 方法返回一个整数(非布尔值!!),这个整数的正负意义如下: 如果返回负数,说明 o1 排在 o2前面。 如果返回零,说明 o1 等于 o2。 如果返回正数,说明 o1 排在 o2后面。 示例:对象排序(按年龄升序) import java.util.*; class Person { String name; int age; Person(String name, int age) { this.name = name; this.age = age; } public String toString() { return name + " (" + age + ")"; } } public class ComparatorExample { public static void main(String[] args) { List<Person> people = Arrays.asList( new Person("Alice", 25), new Person("Bob", 20), new Person("Charlie", 30) ); // 使用 Comparator + Lambda 按年龄排序 people.sort((p1, p2) -> Integer.compare(p1.age, p2.age)); System.out.println(people); // [Bob (20), Alice (25), Charlie (30)] } } 补充:String比较 a.compareTo(b); 题型 常见术语 子串(Substring):子字符串 是字符串中连续的 非空 字符序列 回文串(Palindrome):回文 串是向前和向后读都相同的字符串。 子序列((Subsequence)):可以通过删除原字符串中任意个字符(不改变剩余字符的相对顺序)得到的序列,不要求连续。例如 "abc" 的 "ac" 就是一个子序列。 子数组:数组中连续的部分。 前缀 (Prefix) :从字符串起始位置开始的连续字符序列,如 "leetcode" 的前缀 "lee"。 字母异位词 (Anagram):由相同字符组成但排列顺序不同的字符串。例如 "abc" 与 "cab" 就是异位词。 子集、幂集:数组的 子集 是从数组中选择一些元素(可能为空)。例如,对于集合 S = {1, 2},其幂集为: { ∅, {1}, {2}, {1, 2} },子集有{1} 链表 “头插法”本质上就是把新节点“插”到已构建链表的头部 1.反转链表 2.从头开始构建链表(逆序插入) ListNode buildList(int[] arr) { ListNode head = null; for (int i = 0; i < arr.length; i++) { ListNode node = new ListNode(arr[i]); node.next = head; // 头插:新节点指向原 head head = node; // head 指向新节点 } return head; } // 结果链表的顺序是 arr 最后一个元素在最前面,如果你想保持原序,可以倒序遍历 arr。 输入:arr[0] -> arr[1] -> … -> arr[n-1] 输出:arr[n-1]-> arr[n-2]-> …->arr[0] Floyd判环法:快慢指针 public boolean hasCycle(ListNode head) { if (head == null) return false; // 快慢指针都从 head 出发 ListNode slow = head; ListNode fast = head; // 当 fast 或 fast.next 为 null 时,说明已经到链表末尾,无环 while (fast != null && fast.next != null) { slow = slow.next; // 慢指针走一步 fast = fast.next.next; // 快指针走两步 // 每走一步就检查一次相遇 if (slow == fast) { return true; // 相遇则有环 } } return false; // 跳出循环说明没有环 } 何时需要定义dummy节点? 当你的操作有可能“改”到原始的头节点(插入到最前面,或删除掉第一个节点)时,就定义一个 dummy,把它挂在 head 之前,之后所有插入/删除都操作 dummy.next 及其后继,最后返回 dummy.next。 哈希 问题分析: 确定是否需要快速查找或存储数据。 判断是否需要统计元素频率或检查元素是否存在。 适用场景 快速查找: 当需要频繁查找元素时,哈希表可以提供 O(1) 的平均时间复杂度。 统计频率: 统计元素出现次数时,哈希表是常用工具。 去重: 需要去除重复元素时,HashSet 可以有效实现。 双指针 题型: 同向双指针:两个指针从同一侧开始移动,通常用于滑动窗口或链表问题。 对向双指针:两个指针从两端向中间移动,通常用于有序数组或回文问题。重点是考虑移动哪个指针可能优化结果!!! 快慢指针:两个指针以不同速度移动,通常用于链表中的环检测或中点查找。 适用场景: 有序数组的两数之和: 在对向双指针的帮助下,可以在 O(n) 时间内找到两个数,使它们的和等于目标值。 滑动窗口: 用于解决子数组或子字符串问题,如同向双指针可以在 O(n) 时间内找到满足条件的最短或最长子数组。 链表中的环检测: 快慢指针可以用于检测链表中是否存在环,并找到环的起点。 回文问题: 对向双指针可以用于判断字符串或数组是否是回文。 合并有序数组或链表: 双指针可以用于合并两个有序数组或链表,时间复杂度为 O(n)。 前缀和 前缀和的定义 定义前缀和 preSum[i] 为数组 nums 从索引 0 到 i 的元素和,即 $$ \text{preSum}[i] = \sum_{j=0}^{i} \text{nums}[j] $$ 子数组和的关系 对于任意子数组 nums[i+1..j](其中 0 ≤ i < j < n),其和可以表示为 $$ \text{sum}(i+1,j) = \text{preSum}[j] - \text{preSum}[i] $$ 当这个子数组的和等于 k 时,有 $$ \text{preSum}[j] - \text{preSum}[i] = k $$ 即 $$ \text{preSum}[i] = \text{preSum}[j] - k $$ $\text{preSum}[j] - k$表示 "以当前位置结尾的子数组和为k" 利用哈希表存储前缀和 我们可以使用一个哈希表 prefix 来存储每个前缀和出现的次数。 初始时,prefix[0] = 1,表示前缀和为 0 出现一次(对应空前缀)。 遍历数组,每计算一个新的前缀和 preSum,就查看 preSum - k 是否在哈希表中。如果存在,则说明之前有一个前缀和等于 preSum - k,那么从该位置后一个位置到当前索引的子数组和为 k,累加其出现的次数。 时间复杂度 该方法只需要遍历数组一次,时间复杂度为 O(n)。 遍历二叉树 递归法中序 public void inOrderTraversal(TreeNode root, List<Integer> list) { if (root != null) { inOrderTraversal(root.left, list); // 遍历左子树 list.add(root.val); // 访问当前节点 inOrderTraversal(root.right, list); // 遍历右子树 } } 迭代法中序 public void inOrderTraversalIterative(TreeNode root, List<Integer> list) { Deque<TreeNode> stack = new ArrayDeque<>(); TreeNode curr = root; while (curr != null || !stack.isEmpty()) { // 一路向左入栈 while (curr != null) { stack.push(curr); // push = addFirst curr = curr.left; } // 弹出栈顶并访问 curr = stack.pop(); // pop = removeFirst list.add(curr.val); // 转向右子树 curr = curr.right; } } 迭代法前序 public void preOrderTraversalIterative(TreeNode root, List<Integer> list) { if (root == null) return; Deque<TreeNode> stack = new ArrayDeque<>(); stack.push(root); while (!stack.isEmpty()) { TreeNode node = stack.pop(); list.add(node.val); // 先访问当前节点 // 注意:先压右子节点,再压左子节点 // 因为栈是“后进先出”的,先弹出的是左子节点 if (node.right != null) { stack.push(node.right); } if (node.left != null) { stack.push(node.left); } } } 层序遍历BFS public List<List<Integer>> levelOrder(TreeNode root) { List<List<Integer>> result = new ArrayList<>(); if (root == null) return result; Queue<TreeNode> queue = new LinkedList<>(); queue.offer(root); while (!queue.isEmpty()) { int levelSize = queue.size(); List<Integer> level = new ArrayList<>(); for (int i = 0; i < levelSize; i++) { TreeNode node = queue.poll(); level.add(node.val); if (node.left != null) { queue.offer(node.left); } if (node.right != null) { queue.offer(node.right); } } result.add(level); } return result; } 回溯法 回溯算法用于 搜索一个问题的所有的解 ,即爆搜(暴力解法),通过深度优先遍历的思想实现。核心思想是: 1.逐步构建解答: 回溯算法通过逐步构造候选解,当构造的部分解满足条件时继续扩展;如果发现当前解不符合要求,则“回溯”到上一步,尝试其他可能性。 2.剪枝(Pruning): 在构造候选解的过程中,算法会判断当前部分解是否有可能扩展成最终的有效解。如果判断出无论如何扩展都不可能得到正确解,就立即停止继续扩展该分支,从而节省计算资源。 3.递归调用 回溯通常通过递归来实现。递归函数在每一层都尝试不同的选择,并在尝试失败或达到终点时返回上一层重新尝试其他选择。 例:以数组 [1, 2, 3] 的全排列为例。 先写以 1 开头的全排列,它们是:[1, 2, 3], [1, 3, 2],即 1 + [2, 3] 的全排列(注意:递归结构体现在这里); 再写以 2 开头的全排列,它们是:[2, 1, 3], [2, 3, 1],即 2 + [1, 3] 的全排列; 最后写以 3 开头的全排列,它们是:[3, 1, 2], [3, 2, 1],即 3 + [1, 2] 的全排列。 public class Permute { public List<List<Integer>> permute(int[] nums) { List<List<Integer>> res = new ArrayList<>(); // 用来标记数组中数字是否被使用 boolean[] used = new boolean[nums.length]; List<Integer> path = new ArrayList<>(); backtrack(nums, used, path, res); return res; } private void backtrack(int[] nums, boolean[] used, List<Integer> path, List<List<Integer>> res) { // 当path中元素个数等于nums数组的长度时,说明已构造出一个排列 if (path.size() == nums.length) { res.add(new ArrayList<>(path)); return; } // 遍历数组中的每个数字 for (int i = 0; i < nums.length; i++) { // 如果该数字已经在当前排列中使用过,则跳过 if (used[i]) { continue; } // 选择数字nums[i] used[i] = true; path.add(nums[i]); // 递归构造剩余的排列 backtrack(nums, used, path, res); // 回溯:撤销选择,尝试其他数字 path.remove(path.size() - 1); used[i] = false; } } } 大小根堆 题目描述:给定一个整数数组 nums 和一个整数 k,返回出现频率最高的前 k 个元素,返回顺序可以任意。 解法一:大根堆(最大堆) 思路: 使用 HashMap 统计每个元素的出现频率。 构建一个大根堆(PriorityQueue + 自定义比较器),根据频率降序排列。 将所有元素加入堆中,弹出前 k 个元素即为答案。 适合场景: 实现简单,适用于对全部元素排序后取前 k 个。 时间复杂度:O(n log n),因为需要将所有 n 个元素都加入堆。 **解法二:小根堆(最小堆)**推荐 思路: 使用 HashMap 统计频率。 构建一个小根堆,堆中仅保存前 k 个高频元素。 遍历每个元素: 如果堆未满,直接加入。 如果当前元素频率大于堆顶(最小频率),则弹出堆顶,加入当前元素。 最终堆中保存的就是前 k 个高频元素。 方法 适合场景 时间复杂度 空间复杂度 大根堆 k ≈ n,简单易写 O(n log n) O(n) 小根堆 k ≪ n,更高效 O(n log k) O(n) 动态规划 解题步骤: 确定 dp 数组以及下标的含义(很关键!不跑偏) 目的:明确 dp 数组中存储的状态或结果。 关键:下标往往对应问题中的一个“阶段”或“子问题”,而数组的值则表示这一阶段的最优解或累计结果。 示例:在背包问题中,可以设 dp[i] 表示前 i 个物品能够达到的最大价值。 确定递推公式 目的:找到状态之间的转移关系,表明如何从已解决的子问题求解更大规模的问题。 关键:分析每个状态可能来源于哪些小状态,写出数学或逻辑表达式。 示例:对于 0-1 背包问题,递推公式通常为 $$ dp[i]=max(dp[i],dp[i−weight]+value) $$ dp 数组如何初始化 目的:给定初始状态,为所有可能情况设置基础值。 关键:通常初始化基础的情况(如 dp[0]=0),或者用极大或极小值标示未计算状态。 示例:在求最短路径问题中,可以用较大值(如 infinity)初始化所有状态,然后设定起点状态为 0。 确定遍历顺序 目的:按照正确的顺序计算每个状态,确保依赖的子问题都已经计算完毕。 关键:遍历顺序需要与递推公式保持一致,既可以是正向(从小到大)也可以是反向(从大到小),取决于问题要求。 示例:对背包问题,为避免重复计算,每个物品的更新通常采用反向遍历。 举例推导 dp 数组 目的:通过一个具体例子来演示递推公式的应用,直观理解每一步计算。 关键:选择简单案例,从初始化、更新到最终结果展示整个过程。 示例:对一个简单的路径问题,展示如何从起点逐步更新 dp 数组,最后得到终点的最优解。 例题 题目: 746. 使用最小花费爬楼梯 (MinCostClimbingStairs) 描述:给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。 你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。 请你计算并返回达到楼梯顶部的最低花费。 示例 2: 输入:cost = [10,15,20] 输出:15 解释:你将从下标为 1 的台阶开始。 支付 15 ,向上爬两个台阶,到达楼梯顶部。 总花费为 15 。 链接:https://leetcode.cn/problems/min-cost-climbing-stairs/ 1.确定dp数组以及下标的含义 dp[i]的定义:到达第i台阶所花费的最少体力为dp[i]。 2.确定递推公式 可以有两个途径得到dp[i],一个是dp[i-1] 一个是dp[i-2]。 dp[i - 1] 跳到 dp[i] 需要花费 dp[i - 1] + cost[i - 1]。 dp[i - 2] 跳到 dp[i] 需要花费 dp[i - 2] + cost[i - 2]。 那么究竟是选从dp[i - 1]跳还是从dp[i - 2]跳呢? 一定是选最小的,所以dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]); 3.dp数组如何初始化 看一下递归公式,dp[i]由dp[i - 1],dp[i - 2]推出,既然初始化所有的dp[i]是不可能的,那么只初始化dp[0]和dp[1]就够了,其他的最终都是dp[0]、dp[1]推出。 由“你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。” =》初始化 dp[0] = 0,dp[1] = 0 4.确定遍历顺序 因为是模拟台阶,而且dp[i]由dp[i-1]dp[i-2]推出,所以是从前到后遍历cost数组就可以了。 5.举例推导dp数组 拿示例:cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] ,来模拟一下dp数组的状态变化,如下: 背包问题 总结:背包问题不仅可以求能装的物品的最大价值,还可以求背包是否可以装满,还可以求组合总和。 背包是否可以装满示例说明 假设背包容量为 10,物品的重量分别为 [3, 4, 7]。我们希望判断是否可以恰好填满容量 10。 其中 dp[j] 表示在容量 j 下,能装入的最大重量(保证不超过 j)。如果dp[10]=10,代表能装满 public boolean canFillBackpack(int[] weights, int capacity) { // dp[j] 表示在不超过背包容量 j 的前提下,能装入的最大重量 int[] dp = new int[capacity + 1]; // 初始状态: 背包容量为0时,能够装入的重量为0,其他位置初始为0 // 遍历每一个物品(0/1背包,每个物品只能使用一次) for (int i = 0; i < weights.length; i++) { // 逆序遍历背包容量,防止当前物品被重复使用 for (int j = capacity; j >= weights[i]; j--) { dp[j] = Math.max(dp[j], dp[j - weights[i]] + weights[i]); } } // 如果 dp[capacity] 恰好等于 capacity,则说明背包正好被装满 return dp[capacity] == capacity; } 求组合总和 统计数组中有多少种组合(子集)使得其和正好为 P ? dp[j] 表示从数组中选取若干个数,使得这些数的和正好为 j 的方法数。 状态转移: 对于数组中的每个数字 num,从 dp 数组后向前(逆序)遍历,更新: dp[j]=dp[j]+dp[j−num] 这里的意思是: 如果不选当前数字,方法数保持不变; 如果选当前数字,那么原来凑出和 j−num 的方案都可以扩展成凑出和 j 的方案。 初始条件: dp[0] = 1,代表凑出和为 0 只有一种方式,即不选任何数字。 代码随想录 完全背包是01背包稍作变化而来,即:完全背包的物品数量是无限的。 0/1背包(一) 描述:有n件物品和一个最多能背重量为 w 的背包。第 i 件物品的重量是 weight[i],得到的价值是 value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。 1.确定dp数组以及下标的含义 因为有两个维度需要分别表示:物品 和 背包容量,所以 dp为二维数组。 即 dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。 2. 确定递推公式 考虑 dp[i][j],有两种情况: 不放物品i:背包容量为 j ,里面不放物品 i 的最大价值是 dp[i - 1][j]。 放物品i:背包空出物品i的容量后,背包容量为 j - weight[i],dp[i - 1][j - weight[i]] 为背包容量为j - weight[i] 且不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值 递归公式: dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 3. dp数组如何初始化 (1)首先从 dp[i][j] 的定义出发,如果背包容量 j 为0的话,即 dp[i][0] ,无论是选取哪些物品,背包价值总和一定为0。 (2)由状态转移方程 dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出i 是由 i-1 推导出来,那么 i 为0的时候就一定要初始化。 此时就看存放编号0的物品的时候,各个容量的背包所能存放的最大价值。 (3)其他地方初始化为0 4.确定遍历顺序 都可以,但推荐先遍历物品 // weight数组的大小 就是物品个数 for(int i = 1; i < weight.size(); i++) { // 遍历物品 for(int j = 0; j <= bagweight; j++) { // 遍历背包容量 if (j < weight[i]) dp[i][j] = dp[i - 1][j]; else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); } } 5.举例推导dp数组 略 代码: public int knapsack(int[] weight, int[] value, int capacity) { int n = weight.length; // 物品的总个数 // 定义二维 dp 数组: // dp[i][j] 表示从下标为 [0, i] 的物品中任意选择,放入容量为 j 的背包中,能够获得的最大价值 int[][] dp = new int[n][capacity + 1]; // 1. 初始化第 0 行:只考虑第 0 个物品的情况 // 当背包容量 j >= weight[0] 时,可以选择放入第 0 个物品,价值为 value[0];否则为 0 for (int j = 0; j <= capacity; j++) { if (j >= weight[0]) { dp[0][j] = value[0]; } else { dp[0][j] = 0; } } // 2. 状态转移:从第 1 个物品开始,逐步填表 // 遍历物品,物品下标从 1 到 n-1 for (int i = 1; i < n; i++) { // 遍历背包容量,从 0 到 capacity for (int j = 0; j <= capacity; j++) { // 情况一:不放第 i 个物品,则最大价值不变,继承上一行的值 dp[i][j] = dp[i - 1][j]; // 情况二:如果当前背包容量 j 大于等于物品 i 的重量,则考虑放入当前物品 if (j >= weight[i]) { dp[i][j] = Math.max(dp[i][j], dp[i - 1][j - weight[i]] + value[i]); } } } // 返回考虑所有物品,背包容量为 capacity 时的最大价值 return dp[n - 1][capacity]; } 0/1背包(二) 可以将二维 dp 优化为一维 dp 的典型条件包括: 1.状态转移只依赖于之前的状态(例如上一行或上一个层次),而不是当前行中动态更新的状态。 例如在 0/1 背包问题中,二维 dp[i][j] 只依赖于 dp[i-1][j] 和 dp[i-1][j - weight[i]]。 2.存在确定的遍历顺序(例如逆序或正序)能够确保在更新一维 dp 时,所依赖的值不会被当前更新覆盖。 逆序遍历:例如 0/1 背包问题,为了防止同一个物品被重复使用,需要对容量 j 从大到小遍历,确保 dp[j - weight] 的值还是上一轮(上一行)的。 正序遍历:在一些问题中,如果状态更新不会导致当前状态被重复利用(例如完全背包问题),可以顺序遍历。 3.状态数足够简单,不需要记录多维信息,仅一个维度的状态即可准确表示和转移问题状态。 1.确定 dp 数组以及下标的含义 使用一维 dp 数组 dp[j] 表示「在当前考虑的物品下,背包容量为 j 时能够获得的最大价值」。 2.确定递推公式 当考虑当前物品 i (重量为 weight[i],价值为 value[i])时,有两种选择: 不选当前物品 i: 此时的最大价值为 dp[j](即前面的状态没有变化)。 选当前物品 i: 当背包容量至少为 weight[i] 时,如果选择物品 i ,剩余容量变为 j - weight[i],则最大价值为 dp[j - weight[i]] 加上 value[i]。 因此,状态转移方程为: $$ dp[j]=max(dp[j], dp[j−weight[i]]+value[i]) $$ **3.dp 数组如何初始化** dp[0] = 0,表示当背包容量为 0 时,能获得的最大价值自然为 0。 对于其他容量 dp[j] ,初始值也设为 0,dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了。确保值不被初始值覆盖即可。 4.一维dp数组遍历顺序 外层遍历物品: 从第一个物品到最后一个物品,依次做决策。 内层遍历背包容量(逆序遍历): 遍历容量从 capacity 到当前物品的重量,进行状态更新。 逆序遍历的目的在于确保当前物品在更新过程中只会被使用一次,因为 dp[j - weight[i]] 代表的是上一轮(当前物品未使用前)的状态,不会被当前物品更新后的状态覆盖。 假设物品 $w=2$, $v=3$,背包容量 $C=5$。 错误的正序遍历($j=2 \to 5$) $j=2$: $dp[2] = \max(0, dp[0]+3) = 3$ $\Rightarrow dp = [0, 0, 3, 0, 0, 0]$ $j=4$: $dp[4] = \max(0, dp[2]+3) = 6$ $\Rightarrow$ 错误:物品被重复使用两次! 5.举例推导dp数组 略 代码: public int knapsack(int[] weight, int[] value, int capacity) { int n = weight.length; // 定义 dp 数组,dp[j] 表示背包容量为 j 时的最大价值 int[] dp = new int[capacity + 1]; // 初始化:所有 dp[j] 初始为0,dp[0] = 0(无须显式赋值) // 外层:遍历每一个物品 for (int i = 0; i < n; i++) { // 内层:逆序遍历背包容量,保证每个物品只被选择一次 for (int j = capacity; j >= weight[i]; j--) { // 更新状态:选择不放入或者放入当前物品后的最大价值 dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]); } } // 返回背包总容量为 capacity 时获得的最大价值 return dp[capacity]; } 完全背包(一) 完全背包和01背包问题唯一不同的地方就是,每种物品有无限件。 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 例:背包最大重量为4,物品为: 物品 重量 价值 物品0 1 15 物品1 3 20 物品2 4 30 1. 确定dp数组以及下标的含义 dp[i][j] 表示从下标为[0-i]的物品,每个物品可以取无限次,放进容量为j的背包,价值总和最大是多少。 2. 确定递推公式 不放物品i:背包容量为j,里面不放物品i的最大价值是dp[i - 1][j]。 放物品i:背包空出物品i的容量后,背包容量为j - weight[i],dp[i][j - weight[i]] 为背包容量为j - weight[i]且不放物品i的最大价值,那么dp[i][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值 递推公式: dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]); 01背包中是 dp[i - 1][j - weight[i]] + value[i]) 因为在完全背包中,物品是可以放无限个,所以 即使空出物品1空间重量,那背包中也可能还有物品1,所以此时我们依然考虑放 物品0 和 物品1 的最大价值即: dp[1][1], 而不是 dp[0][1]。而0/1背包中,既然空出物品1,那背包中也不会再有物品1,即dp[0][1]。 for (int i = 1; i < n; i++) { for (int j = 0; j <= capacity; j++) { // 不选物品 i,价值不变 dp[i][j] = dp[i - 1][j]; // 如果当前背包容量 j 能放下物品 i,则考虑选取物品 i(完全背包内层循环正序或逆序都可以,但这里通常建议正序) if (j >= weight[i]) { // 注意:这里选取物品 i 后仍然可以继续选取物品 i, // 所以状态转移方程为 dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]) dp[i][j] = Math.max(dp[i][j], dp[i][j - weight[i]] + value[i]); } } } 3. dp数组如何初始化 如果背包容量j为0的话,即dp[i][0],无论是选取哪些物品,背包价值总和一定为0。 由递推公式,有一个方向 i 是由 i-1 推导出来,那么i为0的时候就一定要初始化。即:存放编号0的物品的时候,各个容量的背包所能存放的最大价值。 for (int j = 0; j <= capacity; j++) { // 当 j 小于第 0 个物品重量时,无法选取,所以价值为 0 if (j < weight[0]) { dp[0][j] = 0; } else { // 完全背包允许多次使用物品 0,所以递归地累加 dp[0][j] = dp[0][j - weight[0]] + value[0]; } } 4. 确定遍历顺序 先物品或先背包容量都可,但推荐先物品。 完全背包(二) 压缩成一维dp数组,也就是将上一层拷贝到当前层。 将上一层dp[i-1] 的那一层拷贝到 当前层 dp[i] ,那么递推公式由 dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]) 变成: dp[i][j] = max(dp[i][j], dp[i][j - weight[i]] + value[i]) 压缩成一维,即dp[j] = max(dp[j], dp[j - weight[i]] + value[i]) 根据题型选择先遍历物品或者背包, 如果求组合数就是外层for循环遍历物品,内层for遍历背包。 如果求排列数就是外层for遍历背包,内层for循环遍历物品。 组合数(顺序不同的序列视为相同)排列数(顺序不同的序列视为不同)排列数大于等于组合数!!!。 内层循环正序,不要逆序!因为要利用已经更新的dp数组,允许同一物品重复使用! 注意,完全背包和0/1背包的一维dp形式的递推公式一样,但是遍历顺序不同!! public int completeKnapsack(int[] weight, int[] value, int capacity) { int n = weight.length; // dp[j] 表示容量为 j 时的最大价值,初始化为 0 int[] dp = new int[capacity + 1]; // 遍历每件物品 for (int i = 0; i < n; i++) { // 完全背包:正序遍历容量 for (int j = weight[i]; j <= capacity; j++) { // 如果拿 i 号物品,更新 dp[j] dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]); } } return dp[capacity]; } 多重背包 有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。 重量 价值 数量 物品0 1 15 2 物品1 3 20 3 物品2 4 30 2 把每种物品按数量展开,就转化为0/1背包问题了!相当于物品0-a 物品0-b 物品1-a ....,每个只能用一次。 public int multipleKnapsack(int V, int[] weight, int[] value, int[] count) { // 将每件物品按数量展开成 0/1 背包的多个物品 List<Integer> wList = new ArrayList<>(); List<Integer> vList = new ArrayList<>(); for (int i = 0; i < weight.length; i++) { for (int k = 0; k < count[i]; k++) { wList.add(weight[i]); vList.add(value[i]); } } // 0/1 背包 DP int[] dp = new int[V + 1]; int N = wList.size(); for (int i = 0; i < N; i++) { int wi = wList.get(i); int vi = vList.get(i); for (int j = V; j >= wi; j--) { dp[j] = Math.max(dp[j], dp[j - wi] + vi); } } return dp[V]; } 并查集 for (int i = 0; i < 26; i++) { parent[i] = i; //初始化 } public void union(int[] parent, int index1, int index2) { // 先分别找到 index1 和 index2 的根节点,再把 root(index1) 的父指针指向 root(index2) parent[find(parent, index1)] = find(parent, index2); } //查找 index 元素所在集合的根节点(同时做路径压缩) public int find(int[] parent, int index) { // 当 parent[index] == index 时,说明已经是根节点 while (parent[index] != index) { // 路径压缩:将当前节点直接挂到它父节点的父节点上 // 这样可以让树变得更扁平,后续查找更快 parent[index] = parent[parent[index]]; // 跳到上一级,继续判断是否到根 index = parent[index]; } // 循环结束时,index 即为根节点下标 return index; } 快速幂 LeetCode 50. Pow(x, n) 实现函数 pow(x, n),即计算 x 的 n 次幂(x^n)。 输入:x = 2.00000, n = 10 输出:1024.00000 快速幂思想 核心思想: 快速幂就是把指数写成二进制,每一位对应一个“平方后的 x”,如果那一位是 1,就把它乘进结果里。 例子: n = 13 (二进制 1101) 13 = 8 + 4 + 1 x^13 = x^(8+4+1) = x^8 * x^4 * x^1 也就是说: 我们只需要把 x 不断平方,得到 x^1, x^2, x^4, x^8 ... 然后根据 n 的二进制位是否为 1,决定是否把这个幂次乘到答案里。 算法步骤 如果 n < 0,转换为 x = 1/x, n = -n。 (注意:n 可能是 Integer.MIN_VALUE,取负数会溢出,所以要先转成 long。) 初始化结果 ans = 1.0。 循环处理指数的每一位: 如果最低位是 1,就把当前的 x 累乘进结果。 每次循环后,x 自身平方,指数右移一位。 循环结束,返回结果。 JAVA实现 public class MyPow { public double myPow(double x, int n) { if (x == 0) return 0; if (n == 0) return 1; // 处理负指数,注意转为 long 防止溢出 long N = n; if (N < 0) { x = 1 / x; N = -N; } double ans = 1.0; while (N > 0) { if ((N & 1) == 1) { // 判断最低位是否为 1 ans *= x; } x *= x; // 翻倍:x, x^2, x^4, x^8 ... N >>= 1; // 右移一位,处理下一位 } return ans; } } ACM风格输入输出 ** * 题目描述 * * 给定一个整数数组 Array,请计算该数组在每个指定区间内元素的总和。 * * 输入描述 * * 第一行输入为整数数组 Array 的长度 n,接下来 n 行,每行一个整数,表示数组的元素。随后的输入为需要计算总和的区间下标:a,b (b > = a),直至文件结束。 * 输入示例: * 5 * 1 * 2 * 3 * 4 * 5 * 0 1 * 1 3 *输出: * 3 * 9 * 输出每个指定区间内元素的总和。 */ import java.util.*; import java.io.*; public class Main { public static void main(String[] args) throws IOException { // 快速 IO BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); PrintWriter out = new PrintWriter(System.out); String line; // 1)读数组长度 line = br.readLine(); if (line == null) return; int n = Integer.parseInt(line.trim()); // 2)读数组元素并构造前缀和 long[] prefix = new long[n + 1]; for (int i = 0; i < n; i++) { line = br.readLine(); if (line == null) throw new IOException("Unexpected EOF when reading array"); prefix[i + 1] = prefix[i] + Long.parseLong(line.trim()); } // 3)依次读查询直到 EOF // 每行两个整数 a, b (0 ≤ a ≤ b < n) while ((line = br.readLine()) != null) { line = line.trim(); if (line.isEmpty()) continue; StringTokenizer st = new StringTokenizer(line); int a = Integer.parseInt(st.nextToken()); int b = Integer.parseInt(st.nextToken()); // 区间和 = prefix[b+1] - prefix[a] long sum = prefix[b + 1] - prefix[a]; out.println(sum); } out.flush(); } } line.trim() 是把原 line 首尾的所有空白字符(空格、制表符、换行符等)都去掉之后的结果。 StringTokenizer st = new StringTokenizer(line);把一整行字符串 line 按默认的分隔符(空格、制表符、换行符等)拆成一个一个的“词”(token) StringTokenizer st = new StringTokenizer(line, ",;"); 第二个参数 ",;" 中的每个字符都会被当作分隔符;如果想把空白也当分隔符,可以在里边加上空格 " ,; " Scanner版本:简单,但效率低。 import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 把分隔符改成 “逗号 或 空白” 默认只能按空格分隔!!! sc.useDelimiter("[,\\s]+"); // 1)读数组长度 if (!sc.hasNextInt()) return; int n = sc.nextInt(); // 2)读数组元素并构造前缀和 long[] prefix = new long[n + 1]; for (int i = 0; i < n; i++) { prefix[i + 1] = prefix[i] + sc.nextLong(); } // 3)依次读查询直到 EOF while (sc.hasNextInt()) { int a = sc.nextInt(); int b = sc.nextInt(); long sum = prefix[b + 1] - prefix[a]; System.out.println(sum); } } } Scanner 是 按空白分隔符(空格、换行、制表符)来划分输入的。 也就是说,sc.nextInt() 会忽略一切空白,把下一个整数读出来,不管它是在同一行还是下一行。 sc.useDelimiter("[,\\s]+"); 这里的 [,] 就表示:分隔符可以是 , 这个字符。 [,\\s] 外面的 + 表示匹配“一个或多个” ,即有连续的空格、逗号它也能匹配。 Scanner 读取字符串 public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 用 next() 读 System.out.print("请输入两个单词(中间空格分隔): "); String word1 = sc.next(); // 读第一个单词 String word2 = sc.next(); // 读第二个单词 System.out.println("next() 得到: " + word1 + " 和 " + word2); sc.nextLine(); // 把上一次输入残余的换行符吃掉 // 用 nextLine() 读 System.out.print("请输入一整行文本: "); String line = sc.nextLine(); // 读整行 System.out.println("nextLine() 得到: " + line); } } //输入 //hello world //I love Java programming //输出: //请输入两个单词(中间空格分隔): next() 得到: hello 和 world //请输入一整行文本: nextLine() 得到: I love Java programming import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); sc.useDelimiter("[,\\s]+"); // 逗号或空白分隔 if (!sc.hasNextInt()) return; int n = sc.nextInt(); long[] arr = readArray(sc, n); // 只读输入 PrefixSum ps = new PrefixSum(arr); // 核心逻辑 StringBuilder out = new StringBuilder(); while (sc.hasNextInt()) { int a = sc.nextInt(); int b = sc.nextInt(); out.append(ps.query(a, b)).append('\n'); // 调用核心 } System.out.print(out.toString()); } // === IO 辅助:读取 n 个 long === private static long[] readArray(Scanner sc, int n) { long[] a = new long[n]; for (int i = 0; i < n; i++) a[i] = sc.nextLong(); return a; } // === 核心:前缀和与区间查询(不涉及 IO)=== static final class PrefixSum { private final long[] pref; // pref[i] = a[0..i-1] 之和 PrefixSum(long[] a) { pref = new long[a.length + 1]; for (int i = 0; i < a.length; i++) pref[i + 1] = pref[i] + a[i]; } /** 查询闭区间 [l, r] 的和 */ long query(int l, int r) { if (l < 0 || r >= pref.length - 1 || l > r) { throw new IllegalArgumentException("Invalid range: [" + l + ", " + r + "]"); } return pref[r + 1] - pref[l]; } } }
后端学习
zy123
1年前
0
14
0
2025-03-21
Jupyter notebook快速上手
Jupyter notebook快速上手 张子豪 同济大学研究生 的Bilibili视频教程:同济子豪兄 知乎专栏:人工智能小技巧 简书专栏:人工智能小技巧 子豪兄的粉丝答疑交流QQ群:953712961 Jupyter notebook快速上手 为什么学Jupyter notebook? Jupyter notebook——在浏览器网页中运行python Ipython内核——更高级的python解释器 安装Jupyter notebook 运行Jupyter notebook 用Jupyter notebook写python代码 写下并运行第一行python代码 蓝绿两模式:命令模式、编辑模式 两种单元格:代码单元格和Markdown单元格 抛弃鼠标,只用键盘 最常用快捷键(必会) 所有快捷键 在Markdown单元格中输入数学公式 数据分析与可视化实战案例:学习时间与成绩的关系(线性回归) 用Jupyter notebook制作ppt并在线分享 参考博客 为什么学Jupyter notebook? 能够编写、运行python文件的程序很多,比如python安装自带的IDLE、程序员喜爱的pycharm、数据科学全家桶Anaconda,还有Spyder、Thonny等。 而我,独爱jupyter notebook。 Jupyter notebook是用python进行数据科学、机器学习的必备工具。 突出优点: 学习Jupyter notebook非常容易,按照我的视频教程一步步做,再自己尝试一下,之后写代码即可健步如飞。 能够独立运行一个、几个或全部python代码块,更容易看到中间变量的值,从而进行调试 可以插入Markdown说明文字和Latex数学公式,让枯燥的代码充满颜值,可读性爆表 能够调用Ipython丰富的“魔法函数”,比如程序计时、重复运行、显示图片等 写好的代码和文档能够以网页和ppt的形式在线分享。在线看Jupyter notebook文件 可以在云端远程服务器运行,不需本地安装配置各种环境。体验一下 比如下图,包含了Markdown说明文档、代码块、代码运行结果、图片嵌入等元素,特别适合Python数据科学和机器学习撰写文档。 吴恩达的《深度学习》慕课的课后编程作业、大数据竞赛网站Kaggle上的代码文档、美国大学的数据科学课程的课后资料及编程作业,都是以jupyter notebook文件的形式给出的,也就是.ipynb文件。 其实Jupyter notebook不止可以运行python,还可以运行julia、R、Javascript等语言,这也是jupyter这个名字的由来。Jupyter notebook支持的编程语言 Jupyter notebook集编程和写作于一身,这就叫做“文学编程”。 Jupyter notebook——在浏览器网页中运行python Ipython内核——更高级的python解释器 Jupyter notebook是基于Ipython内核的,在浏览器中以网页形式运行Python代码的工具,十分方便。 Ipython是啥? Ipython可以理解成更高级的python解释器,相比原生的python交互式命令行,Ipython有更强大的命令计数、自动补全等交互功能。 Spyder和Jupyter notebook都是以Ipython为内核的。 安装Jupyter notebook 如果你安装了python数据科学全家桶Anaconda,那么其中自带了Jupyter notebook。 如果你没安装Anaconda,可以直接在命令行里运行这行命令 pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple 运行Jupyter notebook 打开命令行,输入jupter notebook,回车。稍等片刻即可跳出浏览器网页。 点击右边的New-Python3即可创建python文档。 点击New-Folder可以创建新文件夹。 点击New-Text File可以创建空的.txt文件。 点击New-Terminal可以打开操作系统命令行,你可以使用操作系统对应的命令行进行目录切换、解压文件等操作。 勾选文件夹,点击rename即可重命名 最常用的是点击右边的New-Python3,创建python文档。 用Jupyter notebook写python代码 写下并运行第一行python代码 点击左上角Untitled给新建的python文档文件重新命名。 在代码框中输入第一行python代码,shift+回车运行 蓝绿两模式:命令模式、编辑模式 Jupyter notebook中,代码和文档都存在于一个个单元格中,每个单元格都有蓝色和绿色两种状态。 命令模式(蓝色):用于执行键盘输入的快捷命令(新增单元格、剪切、复制等等)。通过 Esc 键从绿色的编辑模式切换到蓝色的命令模式,此时单元左侧显示蓝色竖线。 编辑模式(绿色):编辑文本和代码。选中单元并按 Enter 键进入编辑模式,此时单元左侧显示绿色竖线。 命令模式和编辑模式,其实是源自于著名的vim编辑器,vim编辑器以特别难学和学成之后可以超神而闻名于世。 两种单元格:代码单元格和Markdown单元格 Jupyter notebook中,有两种单元格:代码单元格和Markdown单元格。 代码单元格:这里是你编写代码的地方,通过按 Shift + Enter 运行代码,其结果显示在本单元下方。代码单元左边有 In [1]: 这样的序列标记,方便人们查看代码的执行次序。在蓝色命令模式下,按y键可以将Markdown单元格转换为代码单元格。 Markdown 单元格:在这里对文本进行编辑,采用 markdown 的语法规范,可以设置文本格式、插入链接、图片甚至数学公式。同样使用 Shift + Enter 运行 markdown 单元来显示渲染后的文本。在蓝色命令模式下按m键可以将代码单元格转换为Markdown单元格。 Markdown是程序员通用的撰写文档的语法,可以轻松实现标题、引用、链接、图片等,非常简洁易学,Github代码托管网站、有道云笔记、简书、知乎、CSDN论坛、电子邮件等都支持Markdown语法。 学习Markdown,推荐我制作的博客和视频教程: 二十分钟精通排版神器Markdown,从此word和秀米是路人 Bilibili视频:二十分钟精通排版神器Markdown 编辑Markdown单元格,输入以下内容: # 我是Markdown一号标题 ## 我是Markdown二号标题 ### 我是Markdown三号标题 >我是引用,我这行开头有一个灰色竖杠 [我是外部链接,点我上百度](www.baidu.com)  然后按shift+Enter运行该单元格。 抛弃鼠标,只用键盘 下面介绍Jupyter notebook快捷键,掌握这些快捷键之后,你将彻底解放你拿鼠标的那只手,更专注、高效地敲代码了。 最常用快捷键(必会) h 查看所有快捷键 Enter 从命令模式进入编辑模式 Esc 从编辑模式退回到命令模式 m 将代码单元格转换为Markdown单元格 y 将Markdown单元格转换为代码单元格 shift+Enter 运行本单元格,选择下面的代码块 ctrl+Enter 运行本单元格 alt+Enter 运行本单元格,在下方新建一个单元格 a 在上方新建一个单元格(above) b 在下方新建一个单元格(below) d 删除选中的单元格(delete) x 剪切本单元格 c 复制本单元格 shift v 粘贴到上面 v 粘贴到下面 l 显示代码行号 所有快捷键 h 查看所有快捷键 在Markdown单元格中输入数学公式 分别在两个Markdown单元格内输入以下内容: 这是爱因斯坦的质能转换方程$E=mc^2$,揭示了质量和能量之间的关系 这是一元二次方程求解公式 $x = \frac{-b\pm \sqrt{b^2-4ac}}{2a}$ 初中数学内容 按shift+Enter渲染运行: 数据分析与可视化实战案例:学习时间与成绩的关系(线性回归) 先用excel把玩数据 观察数据、导入数据、划分特征和标签、划分训练集和测试集、构建模型,模型可视化 用Jupyter notebook制作ppt并在线分享 参考博客 左手代码,右手写作:你必须会的Jupyter Notebook 二十分钟精通排版神器Markdown,从此word和秀米是路人 Bilibili视频:二十分钟精通排版神器Markdown
杂项
zy123
1年前
0
5
0
2025-03-21
Docker指南
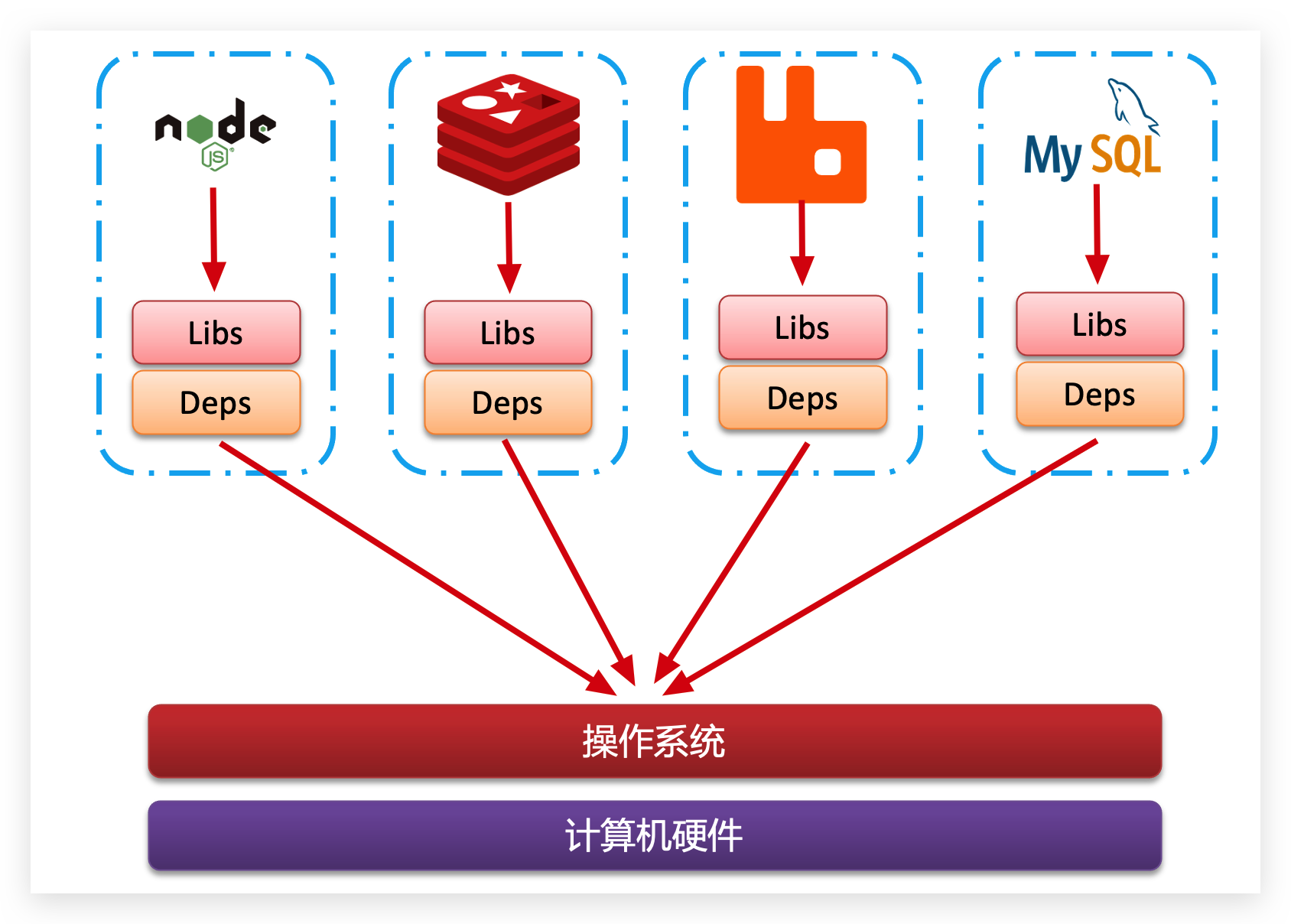
Docker docker基础知识 镜像和容器 Docker中有几个重要的概念: 镜像(Image):Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像,是只读的。 容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器进程做隔离,对外不可见。因此一个镜像可以启动多次,形成多个容器进程。 一切应用最终都是代码组成,都是硬盘中的一个个的字节形成的文件。只有运行时,才会加载到内存,形成进程。 Docker为了解决依赖的兼容问题的,采用了两个手段: 将应用的Libs(函数库)、Deps(依赖)、配置与应用一起打包 将每个应用放到一个隔离容器去运行,避免互相干扰 这样打包好的应用包中,既包含应用本身,也保护应用所需要的Libs、Deps,无需在操作系统上安装这些,自然就不存在不同应用之间的兼容问题了。 DockerHub http://dockerhub.com/ 开源应用程序非常多,打包这些应用往往是重复的劳动。为了避免这些重复劳动,人们就会将自己打包的应用镜像,例如Redis、MySQL镜像放到网络上,共享使用,就像GitHub的代码共享一样。 DockerHub:DockerHub是一个官方的Docker镜像的托管平台。这样的平台称为Docker Registry。 国内也有类似于DockerHub 的公开服务,比如 网易云镜像服务、阿里云镜像库等。 注意:很多国内的镜像现在也不能用了!需要换源! Docker架构 我们要使用Docker来操作镜像、容器,就必须要安装Docker。 Docker是一个CS架构的程序,由两部分组成: 服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等 客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令。 如图: 镜像操作 docker push,将本地镜像上传到远程仓库(例如 Docker Hub) docker login #docker hub登录 # 假设已有本地镜像 myimage,需要先打上标签: docker tag myimage yourusername/myimage:latest # 上传镜像到远程仓库: docker push yourusername/myimage:latest docker pull ,从远程仓库拉取镜像到本地。 docker pull yourusername/myimage:latest docker save,将本地镜像保存为 tar 文件,方便备份或传输 docker save -o myimage.tar yourusername/myimage:latest docker load,从 tar 文件中加载镜像到本地 Docker。 docker load -i myimage.tar docker images ,查看本地镜像 docker images docker build ,构建镜像 -t后面跟镜像名 docker build -t yourusername/myimage:latest . 清理悬空、无名镜像 docker image prune 容器操作 1.docker run 创建并运行一个新容器 -d:以后台模式运行容器,不会占用当前终端。 --name <容器名> :为容器指定一个自定义名称,便于后续管理。 -p <宿主机端口>:<容器端口> : 将容器内部的端口映射到宿主机,使外部可以访问容器提供的服务,如果不写的话,只有容器内部网络能访问它比如mysql,如果写''-p 3307:3306',那么可以用navicat连接localhost:3307访问这个数据库。 --restart <策略> :设置容器的重启策略,如 no(默认不重启)、on-failure(失败时重启)、always(总是重启)或 unless-stopped(最重要!docker服务重启时,它也跟着重启,但它不会读取最新的compose文件,只会恢复中断前容器内元数据)。 -v <宿主机目录>:<容器目录>或--volume : 如 -v /host/data:/app/data docker run --name test-container -d test:latest 2.docker exec 在正在运行的 test-container 内执行命令 -it : 给当前进入的容器创建一个标准输入、输出终端 docker exec -it test-container sh 3.docker logs ,查看 test-container 的日志输出: docker logs --since 1h test-container #查看最近1h docker logs --since 5m test-container #查看最近5分钟 4.docker stop 停止正在运行的 test-container: docker stop test-container 5.docker start 启动一个已停止的 test-container: docker start test-container 6.docker cp 复制文件(或目录)到容器内部,先cd到文件所在目录 docker cp localfile.txt test-container:/target_dir/ 7.docker stats ,查看docker中运行的所有容器的运行状态(CPU 内存占用) docker stats 8.docker container ls,查看运行容器的创建时间、端口映射等 docker container ls 9.docker ps 查看 Docker 容器的状态,默认情况下,它只显示正在运行的容器 docker ps -a #查看所有容器,包括已经停止或启动失败的容器 数据卷操作 **数据卷(volume)**是一个虚拟目录,指向宿主机文件系统中的某个目录。 一旦完成数据卷挂载,对容器的一切操作都会作用在数据卷对应的宿主机目录了。 这样,我们操作宿主机的/var/lib/docker/volumes/html目录,就等于操作容器内的/usr/share/nginx/html目录了 有两种挂载方式: 绑定挂载(Bind Mounts)更加推荐! 原理:直接将宿主机上的一个目录或文件挂载到容器内。 特点 数据存储在宿主机上,容器可以直接访问宿主机的文件系统。 适合需要在开发过程中频繁修改代码或数据共享的场景。 依赖宿主机的目录结构,移植性较低。 示例:将宿主机的 /path/on/host 挂载到容器内的 /app/data: docker run -v /path/on/host:/app/data your_image 命名卷(Docker Volumes) 原理:由 Docker 管理的数据卷,存储在 Docker 的默认目录(通常在 /var/lib/docker/volumes/),或通过 Docker 卷插件存储到其他位置。 特点 Docker 负责管理这些卷,提供更好的隔离和数据持久性。 与宿主机的具体目录结构无关,便于迁移和备份。 常用于生产环境中数据的持久化。 示例:创建并挂载名为 my_volume 的卷到容器内的 /app/data: docker run -v my_volume:/app/data your_image 创建命名卷 docker volume create my_volume 查看命名卷,这将列出所有 Docker 管理的卷。 docker volume ls 显示该命名卷的详细信息 zy123@hcss-ecs-588d:~/zbparse$ sudo docker volume inspect html [ { "CreatedAt": "2025-02-25T18:46:10+08:00", "Driver": "local", "Labels": null, "Mountpoint": "/var/lib/docker/volumes/html/_data", "Name": "html", "Options": null, "Scope": "local" } ] Mountpoint是宿主机上的路径,也就是 Docker 存储该数据卷数据的实际位置 docker网络 Docker 网络的主要作用是实现容器之间的通信和隔离,同时也能控制容器与外部主机或网络的连接。通过创建自定义网络,你可以让属于同一网络的容器通过名称互相访问,而不必暴露所有服务到外部网络,这既提升了安全性又简化了容器间的交互。 举例说明 假设你有两个容器,一个运行 MySQL 数据库,另一个运行 Web 应用程序。你希望 Web 应用能够通过数据库容器的别名来访问 MySQL,而不需要硬编码 IP 地址。 1.创建自定义网络 ,名为 app-net docker network create app-net 2.启动 MySQL 容器,并加入 app-net 网络,同时为其指定别名 db docker run -d --name mysql \ --network app-net \ --network-alias db \ -e MYSQL_ROOT_PASSWORD=my-secret-pw \ mysql:latest Docker CLI 命令(如 docker ps、docker exec)需要使用 container_name 来操作容器。 但如果 另一个容器需要访问它,不能直接用 mysql容器名,而要用 IP 地址或 network-alias。 --network-alias db(网络别名),只在特定网络中生效 注意:不使用docker-compose就没有服务名,可以通过容器名,网络别名实现同网络的容器间通信 3.启动 Web 应用容器,加入同一个 app-net 网络 docker run -d --name webapp \ --network app-net \ your_webapp_image:latest 4.验证容器间通信,进入 Web 应用容器,尝试通过别名 db 连接 MySQL: docker exec -it webapp bash # 在 webapp 容器内执行,比如使用 ping 测试网络连通性: ping db 举个例子,如果你的 Java 应用运行在容器 B 中,而数据库容器 A 已经通过 --network-alias db 起了别名,那么在 Java 应用中,你只需要写: String dbUrl = "jdbc:mysql://db:3306/your_database"; 而不必关心数据库容器的实际 IP 地址。 否则: String dbUrl = "jdbc:mysql://<宿主机IP或localhost>:3306/your_database"; 因为会通过宿主机IP映射到容器内的IP 5.连接一个正在运行或已创建的容器到网络 接时可以使用 --alias 参数为容器在该网络中设置别名 docker network connect app-net mysql --alias db 6.断开连接 docker network disconnect app-net mysql 7.删除网络 需要注意的是,只有当网络中没有容器连接时才能删除。 docker network rm app-net docker network prune #删除所有未使用的网络 docker安装: 1.卸载旧版 首先如果系统中已经存在旧的Docker,则先卸载: sudo apt-get remove docker docker-engine docker.io containerd runc 说明:该命令会删除系统中现有的 Docker 相关包,但不会删除 Docker 镜像、容器、卷等数据。如果需要彻底清理,可以手动删除相关目录。 2.安装 Docker 依赖 在安装新版 Docker 前,需要更新 apt 源并安装一些依赖包,以便能够通过 HTTPS 协议访问 Docker 官方仓库。 sudo apt-get update sudo apt-get install apt-transport-https ca-certificates curl gnupg lsb-release 说明:这些软件包包括用于 HTTPS 传输的支持库、CA 证书、curl 工具、GPG 密钥管理工具以及 Debian 版本识别工具。 3.添加 Docker 官方 GPG 密钥 curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg 说明:此命令从 Docker 官方获取 GPG 密钥并保存为二进制格式,供后续验证软件包使用。 4.设置 Docker 仓库 使用以下命令将 Docker 稳定版仓库添加到 apt 源列表中: 这是最关键的一步,配置docker官方地址,往往很难下载!!! echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null 推荐使用以下阿里云的镜像加速源 echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null cat /etc/apt/sources.list.d/docker.list 可以查看是否配置成功 5.安装 Docker Engine 更新 apt 缓存后,安装最新版的 Docker Engine、CLI 工具和 containerd: sudo apt update #如果是docker官方,这一步可能失败! sudo apt install docker-ce docker-ce-cli containerd.io 6.启动和校验 # 启动Docker systemctl start docker # 停止Docker systemctl stop docker # 重启 systemctl restart docker # 设置开机自启 systemctl enable docker # 执行docker ps命令,如果不报错,说明安装启动成功 docker ps 以上docker安装,最关键的就是第4步和第5步 linux vim: finalshell中粘贴会出现粘贴的文本一行比一行靠右,看起来乱成一团。比较快的解决办法是,在粘贴文档前,在命令行模式下,输入 :set paste 删除全文: 控制模式下 %d docker配置代理 sudo vim /etc/systemd/system/docker.service.d/http-proxy.conf [Service] Environment="HTTP_PROXY=http://127.0.0.1:7890" Environment="HTTPS_PROXY=http://127.0.0.1:7890" Environment="NO_PROXY=localhost,127.0.0.1" sudo systemctl daemon-reload //加载配置文件,更新环境变量 sudo systemctl restart docker systemctl show --property=Environment docker //验证是否配置成功 经验总结:貌似配置代理+启动VPN没卵用,如果拉取不到镜像,还是老老实实配置国内镜像吧,另外注意GPT给出的镜像:tag是否真的存在!!!有时候可能是虚假的,根本拉不到。 docker配置镜像: 1.编辑 Docker 配置文件,如果该文件不存在,可以创建一个新的文件。 sudo vim /etc/docker/daemon.json 2.添加多个镜像仓库配置 { "registry-mirrors": [ "http://hub-mirror.c.163.com", "https://mirrors.tuna.tsinghua.edu.cn", "https://ustc-edu-cn.mirror.aliyuncs.com", "https://rnsxnws9.mirror.aliyuncs.com", "https://registry.docker-cn.com", "https://reg-mirror.qiniu.com" ] } 3.重启 Docker 服务以应用 sudo systemctl restart docker 4.验证配置 docker info Dockerfile语法 我们只需要告诉Docker,我们的镜像的组成,需要哪些BaseImage、需要拷贝什么文件、需要安装什么依赖、启动脚本是什么,将来Docker会帮助我们构建镜像。 而描述上述信息的文件就是Dockerfile文件 。 EXPOSE 8090 是一个声明性的指令,EXPOSE 本身不会进行端口映射 在 Dockerfile 中,RUN 指令用于在构建镜像的过程中执行命令,这些命令会在镜像的一个临时容器中执行,然后将执行结果作为新的镜像层保存下来。常见的用途包括安装软件包、修改系统配置、编译代码等。 RUN cd $JAVA_DIR \ && tar -xf ./jdk8.tar.gz \ && mv ./jdk1.8.0_144 ./java8 减少重复构建镜像 当你修改原镜像时,只需使用相同的镜像名执行: docker build -t zbparse . Docker 会根据 Dockerfile 和上下文的变化来判断哪些层需要重建,只重建受影响的部分,而未变的层会使用缓存。 优化建议: 把变化较少的步骤(如 FROM 和设置工作目录和requirements.txt)放在前面。 将容易变化的步骤(比如 COPY . .)放在后面。 这样,即使修改了 项目的代码,其他层仍可复用缓存,从而减少重复构建的开销。 这样会有一个问题,如果新镜像与旧镜像名字一致,那么旧的镜像名会变成none! 以下方法可以删除none镜像。 # 查找无标签镜像 docker images -f "dangling=true" # 删除无标签镜像 docker rmi $(docker images -f "dangling=true" -q) 在构建命令中使用 --no-cache 选项可以强制 Docker 重新执行所有步骤,这在某些情况下是必要的,但通常应避免使用它以利用缓存。 docker启动服务全流程 编写dockerfile文件(假设你已经有一个打包好的 app.jar:) # 使用官方 OpenJDK 作为基础镜像 FROM openjdk:17-jdk-slim # 设置工作目录 WORKDIR /app # 复制 jar 包到容器中 COPY app.jar app.jar # 暴露应用端口(假设应用监听 8080) EXPOSE 8080 # 启动应用 CMD ["java", "-jar", "app.jar"] 构造镜像 -t后面是镜像名 ,最后的点号 (.) 代表当前目录 docker build -t my-java-app . 运行容器 -p后面,第一个8080代表宿主机端口,第二个8080代表容器内端口 ,my-java-container为创建的容器名,my-java-app是使用的镜像名字 docker run -d -p 8080:8080 --name my-java-container my-java-app 查看日志 ,若无报错贼容器正常启动 docker logs -f my-java-container docker logs --since 1h [容器ID或名称] 查看最近1小时的日志 停止和删除容器,先停止后删除 docker stop zbparse-container docker rm zbparse-container 查看镜像 docker images 删除镜像 docker rmi zbparse 保存与加载镜像 docker save -o my-java-app.tar my-java-app docker load -i my-java-app.tar 上传到 Docker Hub docker login docker tag my-java-app yourusername/my-java-app:latest docker push yourusername/my-java-app:latest 进入容器(查看容器内数据) docker exec -it my-java-container /bin/bash 注意!denied: requested access to the resource is denied 原因:docker hub上只能使用一个命名空间,也就是说 docker tag my-java-app 646228430smile/my-java-app:latest 这里的646228430smile是用户名,保持不变 Docker部署可能遇到的问题 镜像拉取失败 排除镜像站的问题,如果拉取不到镜像,很有可能是你使用的TAG不正确!! 直接去maven Tags | Docker Hub上看看你输入的TAG是否存在,比如: Docker Hub 如果你输入的都是个错误的TAG,那肯定拉不下来。 端口占用问题 Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:5672 -> 0.0.0.0:0: listen tcp 0.0.0.0:5672: bind: An attempt was made to access a socket in a way forbidden by its access permissions. 先查看是否端口被占用: netstat -aon | findstr 5672 如果没有被占用,那么就是windows的bug,在CMD使用管理员权限重启NAT网络服务即可 net stop winnat net start winnat windows下部署,端口安全问题 Windows 对低端口(<1024)的特殊保护,非管理员或没有对应防火墙放行的进程,可能被系统直接拦截或拒绝绑定。因此这种需要手动在防火墙开个入站规则(类似linux云服务器的设置开放端口),或者干脆用一个高端口(>1024)来映射。 构建镜像失败 RuntimeError: can‘t start new thread。 解释原因:线程资源限制: Docker 容器可能有默认或显式设置的资源限制,如 CPU 限制、内存限制和可用线程数限制。在这种情况下,pip 的进度条尝试创建新线程来处理进度条更新,这可能会超出容器允许的线程数上限。 解决方法:在dockerfile文件中增加一行关闭pip进度条展示 RUN pip config set global.progress_bar off => [flask_app internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 982B 0.0s => ERROR [flask_app internal] load metadata for docker.io/library/python:3.8-slim 60.4s ------ > [flask_app internal] load metadata for docker.io/library/python:3.8-slim: ------ failed to solve: python:3.8-slim: failed to resolve source metadata for docker.io/library/python:3.8-slim: unexpected status from HEAD request to https://ustc-edu-cn.mirror.aliyuncs.com/v2/library/python/manifests/3.8-slim?ns=docker.io: 403 Forbidden exit status 1 原因:在构建镜像时,Docker 在尝试从 ustc-edu-cn 镜像站获取 python:3.8-slim 镜像的元数据时被拒绝了(403 Forbidden) 解决方法:1.单独拉取该镜像 2.添加别的镜像源(可能清华源镜像有问题!!) docker运行权限问题 OpenBLAS blas_thread_init: pthread_create failed for thread 1 of 4: Operation not permitted OpenBLAS blas_thread_init: RLIMIT_NPROC -1 current, -1 max 解决方法: docker run --name zbparse-container --security-opt seccomp=unconfined zbparse Docker-Compose docker-compose安装: **方式1:**从 Docker 20.10 开始,Docker 官方就将 Docker Compose 作为插件集成在 Docker Engine 中,所以在安装 Docker Engine 时,它也会一并安装 Docker Compose 插件。无需额外安装 验证安装 docker compose version **方式2:**安装独立版 Docker Compose 二进制文件 下载二进制文件(或者下载别人的镜像复制到服务器中的/usr/local/bin下) sudo curl -L "https://mirrors.aliyun.com/docker-ce/linux/static/stable/x86_64/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose 赋予执行权限 sudo chmod +x /usr/local/bin/docker-compose 验证安装 docker-compose --version 这两者功能基本一致,大部分命令和参数都是相同的,只是命令前缀不同。 docker-compose.yml语法 1.services 常见子配置: image:指定服务使用的镜像。 build:指定构建上下文或 Dockerfile 路径。 ports:映射容器端口到主机端口。 environment:设置环境变量。 volumes:挂载主机目录或数据卷到容器。 depends_on:定义服务启动顺序的依赖关系。 2.networks 定义和管理自定义网络,方便容器间通信。 3.volumes 定义数据卷,用于数据持久化或者在多个容器间共享数据。 version: '3' services: web_app: build: context: ./web_app # 指定web_app的上下文 dockerfile: Dockerfile # 在./web_app下寻找Dockerfile container_name: web_app ports: - "8080:80" # 将主机8080端口映射到容器的80端口 environment: - DATABASE_HOST=db - DATABASE_USER=root - DATABASE_PASSWORD=root - DATABASE_NAME=my_database depends_on: - db networks: - my_network db: image: mysql:8 container_name: mysql_db environment: MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: my_database ports: - "3306:3306" volumes: - db_data:/var/lib/mysql # 将命名数据卷挂载到MySQL数据目录 networks: - my_network restart: always networks: my_network: driver: bridge # 使用桥接网络驱动 volumes: db_data: build: context: ./web_app dockerfile: Dockerfile build: ./web_app #两种写法是等效的 容器名、服务名 1:默认 当使用 docker-compose build 构建镜像时,镜像的标签格式通常是 项目名_服务名 docker-compose up生成的容器名默认是 项目名_服务名_索引号 索引号(Index Number):这是一个用于区分多个相同服务实例的数字索引。第一次启动时为 1,后续实例依次递增。 服务名是指你在docker-compose中设置的服务名称(services:下的名称)。 项目名默认是当前目录名,如果你使用了 -p 选项指定项目名,则使用指定的项目名,如 docker-compose -p my_custom_project up -d 2.在docker-compose.yml中指定容器名 version: '3' services: web: build: . container_name: my_custom_web_container restart: always 设置自动启动 ports: - "5005:5005" db: image: mysql:5.7 container_name: my_custom_db_container environment: MYSQL_ROOT_PASSWORD: example docker-compose常用命令 **1)构建镜像:**这个命令根据 docker-compose.yml 中各服务的配置构建镜像。如果你修改了 Dockerfile 或者项目代码需要打包进镜像时,就需要运行该命令来构建新的镜像。 docker-compose build 2)启动容器: docker-compose up -d 第一次执行 会根据 docker-compose.yml 中的 build: 或 image: 信息来 构建镜像 或 拉取镜像,然后启动容器。 再次执行 如果 docker-compose.yml 文件或依赖的配置没有变,默认不会重建镜像,只是重用已有的镜像和容器。 如果配置和现有容器不一致,compose 会删除旧容器并基于镜像重新创建新容器。 但 镜像本身不会重建,除非: Dockerfile 或构建上下文有变化; 你显式加了 --build 参数; 或者你手动先 docker-compose build。 -d 参数 正确:表示容器在后台运行(detached mode)。 3)进入容器: docker compose exec -it filebrowser sh 注意!一般进入数据卷挂载,直接在宿主机上操作容器内部就可以了!!!!! 4)启动或更新指定服务 镜像不存在或需重建时才构建,配置变动(或镜像变动)则重建容器,都没变则一动不动 docker compose up -d pyapp !!注意在使用docker-compose命令时,需要指定服务名,不能使用容器名!!! 5)查看所有服务状态 docker-compose ps 6)查看服务的日志输出(flask_app为服务名) docker-compose logs flask_app --since 1h #只显示最近 1 小时 7)停止运行的容器 只停止容器,容器还在磁盘上,docker compose start或docker compose up时容器会带着之前的状态继续运行 docker-compose stop docker-compose stop flask_app #指定某个服务 8)删除停止的容器 默认不会删除网络、卷 docker-compose rm # 删除所有已停止的服务容器(会交互式询问要不要删除) docker-compose rm flask_app # 只删除指定服务的容器 9)停止并删除所有由 docker-compose 启动的容器、网络等(默认不影响挂载卷)。 下次再 up,就得重新创建容器、网络,但镜像不受影响(除非你显式用 --rmi 删除镜像)。 docker-compose down #不能单独指定 10)启动服务 docker-compose start #启动所有停止的.. docker-compose start flask_app 11)重启服务(停止+启动) docker-compose restart docker-compose restart flask_app #指定某个服务 Docker Compose 使用与最佳实践 核心说明 服务名和网络别名 在同一个网络中的容器之间,可以通过 服务名(如 mysql、web_app)进行通信,Docker 会自动注册 DNS 记录。 容器名虽然也能用于通信,但极不推荐,因为容器名容易变化、可移植性差。 服务名的用途 在 docker compose up、docker compose logs、docker compose restart 等 compose 命令里,可以用服务名来操作。 容器名的用途 容器名主要用于 docker 命令,例如: docker ps → 查看容器列表 docker logs <容器名> → 查看日志 docker exec -it <容器名> bash → 进入容器 默认网络 一个 docker-compose.yml 中的所有服务,默认会被挂到同一个网络(<项目名>_default),因此能通过服务名互相访问。 镜像复用 不同的 Compose 文件可以使用相同的镜像(如 mysql:8.0),Docker 会自动复用镜像,而不会重复下载。 问题类型 可能的冲突 解决方案 端口冲突 容器监听相同的宿主机端口(如 3306:3306) 在不同 docker-compose.yml 中映射不同端口(如 3307:3306) 数据卷冲突 多个 MySQL 实例共享相同的 /var/lib/mysql 使用不同的 named volume(如 mysql-data-app1、mysql-data-app2) 网络冲突 默认网络可能导致 DNS 解析失败 在 docker-compose.yml 里创建独立的 network 最佳实践1——集中式数据库 部署一个单独的 MySQL 服务(独立 Compose 文件或 Compose 中的单独服务)。 所有需要访问该 MySQL 的应用加入同一个共享网络。 在数据库内部用 不同的库和用户 来隔离各应用。 数据卷 mysql-data 仍然只对应一个实例,数据完全由该实例管控。 适合 小团队或测试环境,运维更轻松。 最佳实践2——应用 + 数据库成对部署 每个应用和它专属的 MySQL 一起定义在同一个 docker-compose.yml 文件中。 这样应用和数据库天然在同一网络中,互相隔离。 注意事项: 独立数据卷:每个 MySQL 实例用不同的卷名,避免数据冲突。 不同端口映射:宿主机上不能都用 3306:3306,比如 3307:3306、3308:3306。 适合 多应用强隔离场景,但会占用更多资源。(我基本用这种) 实践:部署微服务集群 需求:将之前学习的cloud-demo微服务集群利用DockerCompose部署 实现思路: ① 查看课前资料提供的cloud-demo文件夹,里面已经编写好了docker-compose文件 ② 修改自己的cloud-demo项目,将数据库、nacos地址都命名为docker-compose中的服务名 ③ 使用maven打包工具,将项目中的每个微服务都打包为app.jar ④ 将打包好的app.jar拷贝到cloud-demo中的每一个对应的子目录中 ⑤ 将cloud-demo上传至虚拟机,利用 docker-compose up -d 来部署 compose文件 查看课前资料提供的cloud-demo文件夹,里面已经编写好了docker-compose文件,而且每个微服务都准备了一个独立的目录: 内容如下: version: "3.2" services: nacos: image: nacos/nacos-server environment: MODE: standalone ports: - "8848:8848" mysql: image: mysql:5.7.25 environment: MYSQL_ROOT_PASSWORD: 123 volumes: - "$PWD/mysql/data:/var/lib/mysql" - "$PWD/mysql/conf:/etc/mysql/conf.d/" userservice: build: ./user-service orderservice: build: ./order-service gateway: build: ./gateway ports: - "10010:10010" 可以看到,其中包含5个service服务: nacos:作为注册中心和配置中心 image: nacos/nacos-server: 基于nacos/nacos-server镜像构建 environment:环境变量 MODE: standalone:单点模式启动 ports:端口映射,这里暴露了8848端口 mysql:数据库 image: mysql:5.7.25:镜像版本是mysql:5.7.25 environment:环境变量 MYSQL_ROOT_PASSWORD: 123:设置数据库root账户的密码为123 volumes:数据卷挂载,这里挂载了mysql的data、conf目录,其中有我提前准备好的数据 userservice、orderservice、gateway:都是基于Dockerfile临时构建的 查看mysql目录,可以看到其中已经准备好了cloud_order、cloud_user表: 查看微服务目录,可以看到都包含Dockerfile文件: 内容如下: FROM java:8-alpine COPY ./app.jar /tmp/app.jar ENTRYPOINT java -jar /tmp/app.jar 修改微服务配置 因为微服务将来要部署为docker容器,而容器之间互联不是通过IP地址,而是通过容器名。这里我们将order-service、user-service、gateway服务的mysql、nacos地址都修改为基于服务名的访问。 如下所示: spring: datasource: url: jdbc:mysql://mysql:3306/cloud_order?useSSL=false username: root password: 123 driver-class-name: com.mysql.jdbc.Driver application: name: orderservice cloud: nacos: server-addr: nacos:8848 # nacos服务地址 打包 接下来需要将我们的每个微服务都打包。因为之前查看到Dockerfile中的jar包名称都是app.jar,因此我们的每个微服务都需要用这个名称。 可以通过修改pom.xml中的打包名称来实现,每个微服务都需要修改: <build> <!-- 服务打包的最终名称 --> <finalName>app</finalName> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> 打包后: 拷贝jar包到部署目录 编译打包好的app.jar文件,需要放到Dockerfile的同级目录中。注意:每个微服务的app.jar放到与服务名称对应的目录,别搞错了。 user-service: order-service: gateway: 部署 最后,我们需要将文件整个cloud-demo文件夹上传到虚拟机中,理由DockerCompose部署。 上传到任意目录: 部署: 进入cloud-demo目录,然后运行下面的命令: docker-compose up -d
杂项
zy123
1年前
0
5
0
2025-03-21
Mysql数据库
Mysql数据库 安装启动Mysql mysql 是 MySQL 的命令行客户端工具,用于连接、查询和管理 MySQL 数据库。 你可以通过它来执行 SQL 命令、查看数据和管理数据库。 mysqld 是 MySQL 服务器守护进程,也就是 MySQL 数据库的实际运行程序。 它负责处理数据库的存储、查询、并发访问、用户验证等核心任务。 添加环境变量: 将'\path\to\mysql-8.0.31-winx64\bin\'目录添加到 PATH 环境变量中,便于命令行操作。 启动Mysql net start mysql // 启动mysql服务 net stop mysql // 停止mysql服务 修改root账户密码 mysqladmin -u root password 123456 本地windows下的账号:root 密码: 123456 登录 mysql -u用户名 -p密码 [-h数据库服务器的IP地址 -P端口号] mysql -uroot -p123456 -h 参数不加,默认连接的是本地 127.0.0.1 的MySQL服务器 -P 参数不加,默认连接的端口号是 3306 图形化工具 推荐Navicat Mysql简介 通用语法 1、SQL语句可以单行或多行书写,以分号结尾。 2、SQL语句可以使用空格/缩进来增强语句的可读性。因为SQL语句在执行时,数据库会忽略额外的空格和换行符 SELECT name, age, address FROM users WHERE age > 18; 3、MySQL数据库的SQL语句不区分大小写。 4、注释: 单行注释:-- 注释内容 或 # 注释内容(MySQL特有) 多行注释: /* 注释内容 */ 分类 分类 全称 说明 DDL Data Definition Language 数据定义语言,用来定义数据库对象(数据库,表,字段) DML Data Manipulation Language 数据操作语言,用来对数据库表中的数据进行增删改 DQL Data Query Language 数据查询语言,用来查询数据库中表的记录 DCL Data Control Language 数据控制语言,用来创建数据库用户、控制数据库的访问权限 数据类型 字符串类型 CHAR(n):声明的字段如果数据类型为char,则该字段占据的长度固定为声明时的值,例如:char(4),存入值 'ab',其长度仍为4. VARCHAR(n):varchar(100)表示最多可以存100个字符,每个字符占用的字节数取决于所使用的字符集。存储开销:除了存储实际数据外,varchar 类型还会额外存储 1 或 2 个字节来记录字符串的长度。 TEXT:用于存储大文本数据,存储长度远大于 VARCHAR,但不支持索引整列内容(通常索引长度有限制)。 日期时间类型: 类型 大小 范围 格式 描述 DATE 3 1000-01-01 至 9999-12-31 YYYY-MM-DD 日期值 TIME 3 -838:59:59 至 838:59:59 HH:MM:SS 时间值或持续时间 DATETIME 8 1000-01-01 00:00:00 至 9999-12-31 23:59:59 YYYY-MM-DD HH:MM:SS 混合日期和时间值 注意:字符串和日期时间型数据在 SQL 语句中应包含在引号内,例如:'2025-03-29'、'hello'。 数值类型 类型 大小 有符号(SIGNED)范围 无符号(UNSIGNED)范围 描述 TINYINT 1byte (-128,127) (0,255) 小整数值 INT/INTEGER 4bytes (-2^31,2^31-1) (0,2^32-1) 大整数值 FLOAT 4bytes (-3.402823466 E+38,3.402823466351 E+38) 0 和 (1.175494351 E-38,3.402823466 E+38) 单精度浮点数值 DECIMAL 依赖于M(精度)和D(标度)的值 依赖于M(精度)和D(标度)的值 小数值(精确定点数) DECIMAL(M, D):定点数类型,M 表示总位数,D 表示小数位数,适合存储精度要求较高的数值(如金钱)。 DDL(数据定义语言) 数据库操作 查询所有数据库: show databases; 创建一个itcast数据库。 create database itcast; 切换到itcast数据 use itcast; 查询当前正常使用的数据库: select database(); 删除itcast数据库 drop database if exists itcast; -- itcast数据库存在时删除,不存在也不报错 表操作 查询当前数据库下所有表 show tables; 查看指定表的结构(字段) desc tb_tmps; ( tb_tmps为表名) 创建表 通常一个列定义的顺序如下: 列名(字段) 字段类型 可选的字符集或排序规则(如果需要) 约束:例如 NOT NULL、UNIQUE、PRIMARY KEY、DEFAULT 等 特殊属性:例如 AUTO_INCREMENT 注释:例如 COMMENT '说明' create table 表名( 字段1 字段1类型 [约束] [comment '字段1注释' ], 字段2 字段2类型 [约束] [comment '字段2注释' ], ...... 字段n 字段n类型 [约束] [comment '字段n注释' ] ) [ comment '表注释' ] ; 注意: [ ] 中的内容为可选参数; 最后一个字段后面没有逗号 eg: create table tb_user ( id int comment 'ID,唯一标识', # id是一行数据的唯一标识(不能重复) username varchar(20) comment '用户名', name varchar(10) comment '姓名', age int comment '年龄', gender char(1) comment '性别' ) comment '用户表'; 复制某个表的结构: CREATE TABLE new_table LIKE old_table; 删除表 DROP TABLE demo; 约束 约束 描述 关键字 非空约束 限制该字段值不能为null not null 唯一约束 保证字段的所有数据都是唯一、不重复的 unique 主键约束 主键是一行数据的唯一标识,要求非空且唯一 primary key 默认约束 保存数据时,如果未指定该字段值,则采用默认值 default 外键约束 让两张表的数据建立连接,保证数据的一致性和完整性 foreign key CREATE TABLE tb_user ( id INT PRIMARY KEY AUTO_INCREMENT COMMENT 'ID,唯一标识', username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名', name VARCHAR(10) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', gender CHAR(1) DEFAULT '男' COMMENT '性别' ) COMMENT '用户表'; -- 假设我们有一个 orders 表,它将 tb_user 表的 id 字段作为外键 CREATE TABLE orders ( order_id INT PRIMARY KEY AUTO_INCREMENT COMMENT '订单ID', order_date DATE COMMENT '订单日期', user_id INT, FOREIGN KEY (user_id) REFERENCES tb_user(id) ON DELETE CASCADE ON UPDATE CASCADE, COMMENT '订单表' ); foreign key: 保证数据的一致性和完整性 ON DELETE CASCADE:如果父表中的某行被删除,那么子表中所有与之关联的行也会被自动删除。 ON DELETE SET NULL:如果父表中的某行被删除,子表中的相关外键列会被设置为 NULL。 ON UPDATE CASCADE:如果父表中的外键值被更新,那么子表中的相关外键值也会自动更新。 注意:在实际的 Java 项目中,特别是在一些微服务架构或分布式系统中,通常不直接依赖数据库中的外键约束。相反,开发者通常会在代码中通过逻辑来确保数据的一致性和完整性。 auto_increment: 每次插入新的行记录时,数据库自动生成id字段(主键)下的值 具有auto_increment的数据列是一个正数序列且整型(从1开始自增) 不能应用于多个字段 设计表的字段时,还应考虑: id:主键,唯一标志这条记录 create_time :插入记录的时间 now()函数可以获取当前时间 update_time:最后修改记录的时间 DCL(数据控制语言) GRANT(授予权限) GRANT 权限列表 ON 数据库对象 TO 用户名 [WITH GRANT OPTION]; # 授予用户 user1对表 students的 查询权限: GRANT SELECT ON students TO user1; REVOKE(撤销权限) REVOKE 权限列表 ON 数据库对象 FROM 用户名; # 撤销用户 user1对表 students的 修改权限: REVOKE UPDATE ON students FROM user1; DML(增删改) DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。 添加数据(INSERT) 修改数据(UPDATE) 删除数据(DELETE) INSERT insert语法: 向指定字段添加数据 insert into 表名 (字段名1, 字段名2) values (值1, 值2); 全部字段添加数据 insert into 表名 values (值1, 值2, ...); 批量添加数据(指定字段) insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2); 批量添加数据(全部字段) insert into 表名 values (值1, 值2, ...), (值1, 值2, ...); “如果不存在,就插入一条新记录;如果已存在,则返回已存在那条的 id。” INSERT INTO orders (user_id, idempotency_key, ...) VALUES (:uid, :key, ...) ON DUPLICATE KEY UPDATE id = LAST_INSERT_ID(id); SELECT LAST_INSERT_ID() AS order_id; 保证操作是幂等的;同一 idempotency_key 的重复请求,只会返回同一条订单 ID。 UPDATE update语法: update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ; 案例1:将tb_emp表中id为1的员工,姓名name字段更新为'张三' update tb_emp set name='张三',update_time=now() where id=1; 案例2:将tb_emp表的所有员工入职日期更新为'2010-01-01' update tb_emp set entrydate='2010-01-01',update_time=now(); **注意!**不带where会更新表中所有记录! DELETE delete语法: delete from 表名 [where 条件] ; 案例1:删除tb_emp表中id为1的员工 delete from tb_emp where id = 1; 案例2:删除tb_emp表中所有员工(记录) delete from tb_emp; DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。 DQL(查询) DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。 查询关键字:SELECT 查询操作是所有SQL语句当中最为常见,也是最为重要的操作。 语法 SELECT 字段列表 FROM 表名列表 ----基本查询 WHERE 条件列表 ----条件查询 GROUP BY 分组字段列表 HAVING 分组后条件列表 ----分组查询 ORDER BY 排序字段列表 ----排序查询 LIMIT 分页参数 ----分页查询 基本查询 查询多个字段 select 字段1, 字段2, 字段3 from 表名; 查询所有字段(通配符) select * from 表名; 设置别名 select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名; 去除重复记录 select distinct 字段列表 from 表名; eg:select distinct job from tb_emp; 条件查询 比较运算符 功能 between ... and ... 在某个范围之内(含最小、最大值) in(...) 在in之后的列表中的值,多选一 like 占位符 模糊匹配(_匹配单个字符, %匹配任意个字符) is null 是null = 等于 逻辑运算符 功能 and 或 && 并且 (多个条件同时成立) or 或 || 或者 (多个条件任意一个成立) not 或 ! 非 , 不是 表数据: id name gender job entrydate 1 张三 2 2 2005-04-15 2 李四 1 3 2007-07-22 3 王五 2 4 2011-09-01 4 赵六 1 2 2008-06-11 案例1:查询 入职时间 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间 且 性别为女 的员工信息 select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2; 案例2:查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息 select * from tb_emp where job in (2,3,4); 案例3:查询 姓名 为两个字的员工信息 常见的 LIKE 模式匹配符包括: %:表示零个或多个字符。 _:表示一个字符。 select * from tb_emp where name like '__'; # 通配符 "_" 代表任意1个字符 字符串、数值函数 字符串函数: 函数 作用 示例 结果 LENGTH(str) 字符串长度(字节) LENGTH('abc') 3 CHAR_LENGTH(str) 字符数(推荐用这个) CHAR_LENGTH('中文') 2 CONCAT(s1, s2, …) 拼接字符串 CONCAT('a','b') ab UPPER(str) 转大写 UPPER('abc') ABC LOWER(str) 转小写 LOWER('ABC') abc SUBSTRING(str, pos, len) 截取子串 SUBSTRING('abcdef',2,3) bcd REPLACE(str, from, to) 替换 REPLACE('a,b,c',',','-') a-b-c TRIM(str) 去掉首尾空格 TRIM(' hi ') hi 示例:清理和格式化 SELECT TRIM(LOWER(name)) AS clean_name, LOWER(email) AS email_lower FROM users; 数值函数: 函数 作用 示例 结果 ABS(x) 绝对值 ABS(-5) 5 ROUND(x, d) 四舍五入 ROUND(3.1415,2) 3.14 CEIL(x) 向上取整 CEIL(2.3) 3 FLOOR(x) 向下取整 FLOOR(2.9) 2 MOD(x, y) 取余数 MOD(10,3) 1 ROUND(x) 表示四舍五入到整数。 示例:计算总价并四舍五入 SELECT product, ROUND(price * quantity, 2) AS total_price FROM sales; 聚合函数 之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对分组后的每一组数据在纵向方向上进行计算。如果没有分组,则默认整张表是“一组”。 聚合函数: 函数 功能 count 统计数量 max 最大值 min 最小值 avg 平均值 sum 求和 语法: select 聚合函数(字段名、列名) from 表名 ; 注意 : 聚合函数会忽略空值,对NULL值不作为统计。 # count(*) 推荐此写法(MySQL底层进行了优化) select count(*) from tb_emp; -- 统计记录数 SELECT SUM(amount) FROM tb_sales; -- 统计amount列的总金额 组合使用字符串、数值函数和聚合函数 1)聚合函数放里层,数值/字符串函数放外层(最常见) SELECT CONCAT(UPPER(student_name), ' 平均分: ', ROUND(AVG(score), 1)) AS summary FROM students s JOIN exam_results e ON s.student_id = e.student_id GROUP BY s.student_name; AVG(price) → 先求平均值(聚合) ROUND(..., 2) → 再四舍五入保留 2 位小数 2)先处理再聚合 SELECT AVG(ROUND(score)) AS avg_rounded_score FROM exam_results; 每次考试的成绩先 ROUND(score) 四舍五入; 再计算平均值。 3)错误示例 -- ❌ 错误示例:聚合函数嵌在聚合函数内 SELECT SUM(AVG(price)) FROM products; SQL 不允许聚合函数再嵌套聚合函数。 分组+Having过滤 分组: 分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。 分组查询通常会使用聚合函数进行计算。 没有 GROUP BY 的话,所有行就是一组。 select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]; orders表: customer_id amount 1 100 1 200 2 150 2 300 例如,假设我们有一个名为 orders 的表,其中包含 customer_id 和 amount 列,我们想要计算每个客户的订单总金额,可以这样写查询: SELECT customer_id, SUM(amount) AS total_amount FROM orders GROUP BY customer_id; 结果: customer_id total_amount 2 450 1 300 在这个例子中,GROUP BY customer_id 将结果按照 customer_id 列的值进行分组,并对每个客户的订单金额求和,生成每个客户的总金额。 过滤 SELECT customer_id, SUM(amount) AS total_amount FROM orders GROUP BY customer_id HAVING total_amount > specified_amount; 在这个查询中,HAVING 子句用于筛选出消费金额(total_amount)大于指定数目(specified_amount)的记录。你需要将 specified_amount 替换为你指定的金额数目。 注意事项: 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义 执行顺序:WHERE → GROUP BY(分组)→ 聚合函数 → HAVING WHERE 在聚合前过滤,HAVING 在聚合后过滤。 进阶 那如果按多个字段分组呢? 农场表 farm_id farm_name 1 Green Valley Farm 2 Sunshine Acres 作物表 crop_id crop_name crop_type 1 小麦 谷物 2 玉米 谷物 3 水稻 谷物 4 番茄 蔬菜 作物种植数据 farm_id crop_id ... 1 1 ... 1 2 ... 2 3 ... 2 4 ... 农场1(Green Valley Farm)有:小麦、玉米 农场2(Sunshine Acres)有:水稻、番茄 按作物统计(跨农场) GROUP BY crop_name 一行一个作物 按农场统计(跨作物) GROUP BY farm_name 一行一个农场 按农场 + 作物统计 GROUP BY farm_name, crop_name 一行代表农场中的一种作物 按农场 + 作物 + 类型统计 GROUP BY farm_name, crop_name, crop_type 最细粒度 注意:只能 SELECT 分组字段或聚合函数 排序查询 语法: select 字段列表 from 表名 [where 条件列表] [group by 分组字段 ] order by 字段1 排序方式1 , 字段2 排序方式2 … ; 排序方式: ASC :升序(默认值) DESC:降序 select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp order by entrydate ASC; -- 按照entrydate字段下的数据进行升序排序 分页查询 有两种写法: select 字段列表 from 表名 limit 起始索引(offset), 每页显示记录数 ; # 推荐 select 字段列表 from 表名 limit 记录数 OFFSET 起始索引; 前端传过来的一般是页码,要计算起始索引 两者并不等价!!! 注意事项: 起始索引从0开始。 计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数 例子 1:第 3 页,每页 20 条 SELECT id, title, created_at FROM post WHERE status = 'PUBLISHED' ORDER BY created_at DESC, id DESC LIMIT 20 OFFSET 40; -- 等价: LIMIT 40, 20 多表设计 外键约束 外键约束的语法: -- 创建表时指定 CREATE TABLE child_table ( id INT PRIMARY KEY, parent_id INT, -- 外键字段 FOREIGN KEY (parent_id) REFERENCES parent_table (id) ON DELETE CASCADE -- 可选,表示父表数据删除时,子表数据也会删除 ON UPDATE CASCADE -- 可选,表示父表数据更新时,子表数据会同步更新 ); -- 建完表后,添加外键 ALTER TABLE child_table ADD CONSTRAINT fk_parent_id -- 外键约束的名称,可选 FOREIGN KEY (parent_id) REFERENCES parent_table (id) ON DELETE CASCADE ON UPDATE CASCADE; 一对多 一对多关系实现:在数据库表中多的一方,添加外键字段(如dept_id),来关联'一'这方的主键(id)。 一对一 一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分。一对一的应用场景: 用户表=》基本信息表+身份信息表,以此来提高数据的操作效率。 基本信息:用户的ID、姓名、性别、手机号、学历 身份信息:民族、生日、身份证号、身份证签发机关,身份证的有效期(开始时间、结束时间) 一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE) 多对多 多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。 案例:学生与课程的关系 关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择 实现关系:建立第三张中间表(选课表),中间表至少包含两个外键,分别关联两方主键 多表查询 分类 多表查询可以分为: 连接查询 内连接:相当于查询A、B交集部分数据 外连接 左外连接:查询左表所有数据(包括两张表交集部分数据) 右外连接:查询右表所有数据(包括两张表交集部分数据) 子查询 内连接 内连接(INNER JOIN)只返回两个表中连接条件完全匹配的行。如果某行在一个表中存在但在另一个表中没有匹配项,则该行不会出现在结果集中。 隐式内连接语法: select 字段列表 from 表1 , 表2 where 条件 ... ; 显式内连接语法: select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ; [inner]可省略 案例:查询员工的姓名及所属的部门名称 隐式内连接实现 select tb_emp.name , tb_dept.name -- 分别查询两张表中的数据 from tb_emp , tb_dept -- 关联两张表 where tb_emp.dept_id = tb_dept.id; -- 消除笛卡尔积 显示内连接 select tb_emp.name , tb_dept.name from tb_emp inner join tb_dept on tb_emp.dept_id = tb_dept.id; 使用场景:获取严格关联的数据(查询所有有订单的客户信息) 外连接 左外连接语法结构: select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ; 左外连接相当于查询表1(左表)的所有行,当然也包含表1和表2交集部分的数据。 右外连接语法结构: select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ; 右外连接相当于查询表2(右表)的所有行,当然也包含表1和表2交集部分的数据。 案例:查询所有员工及其部门信息(包括没有分配部门的员工) -- 左外连接:以left join关键字左边的表为主表,查询主表中所有数据,以及和主表匹配的右边表中的数据 select emp.name , dept.name from tb_emp AS emp left join tb_dept AS dept on emp.dept_id = dept.id; 外连接的作用:1.查询主表所有记录及相关联信息(查询所有员工及其部门信息(包括没有分配部门的员工)) 2.查找缺失数据(找出没有订单的客户) FULL OUTER JOIN(全外连接) 左外连接 (LEFT JOIN):保留左表全部 + 右表匹配 右外连接 (RIGHT JOIN):保留右表全部 + 左表匹配 全外连接 (FULL OUTER JOIN):保留左表全部 + 右表全部,即“左外 ∪ 右外” MySQL 的实现方式:用 LEFT JOIN ∪ RIGHT JOIN -- 左外连接:保证所有员工都能查出来 select emp.*, dept.deptName from t_emp emp left join t_dept dept on emp.deptId = dept.id union -- 右外连接:保证所有部门都能查出来 select emp.*, dept.deptName from t_emp emp right join t_dept dept on emp.deptId = dept.id; 子查询 SQL语句中嵌套select语句,称为嵌套查询,又称子查询。 SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... ); 子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。 标量子查询 子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。 常用的操作符: = <> > >= < <= 案例1:查询"教研部"的所有员工信息 可以将需求分解为两步: 查询 "教研部" 部门ID 根据 "教研部" 部门ID,查询员工信息 -- 1.查询"教研部"部门ID select id from tb_dept where name = '教研部'; #查询结果:2 -- 2.根据"教研部"部门ID, 查询员工信息 select * from tb_emp where dept_id = 2; -- 合并出上两条SQL语句 select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部'); 列子查询 子查询返回的结果是一列(可以是多行,即多条记录),这种子查询称为列子查询。 常用的操作符: 操作符 描述 IN 在指定的集合范围之内,多选一 NOT IN 不在指定的集合范围之内 案例:查询"教研部"和"咨询部"的所有员工信息 分解为以下两步: 查询 "销售部" 和 "市场部" 的部门ID 根据部门ID, 查询员工信息 -- 1.查询"销售部"和"市场部"的部门ID select id from tb_dept where name = '教研部' or name = '咨询部'; #查询结果:3,2 -- 2.根据部门ID, 查询员工信息 select * from tb_emp where dept_id in (3,2); -- 合并以上两条SQL语句 select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部'); 行子查询 子查询返回的结果是一行(可以是多列,即多字段),这种子查询称为行子查询。 常用的操作符:= 、<> 、IN 、NOT IN 案例:查询与"韦一笑"的入职日期及职位都相同的员工信息 可以拆解为两步进行: 查询 "韦一笑" 的入职日期 及 职位 查询与"韦一笑"的入职日期及职位相同的员工信息 -- 查询"韦一笑"的入职日期 及 职位 select entrydate , job from tb_emp where name = '韦一笑'; #查询结果: 2007-01-01 , 2 -- 查询与"韦一笑"的入职日期及职位相同的员工信息 select * from tb_emp where (entrydate,job) = ('2007-01-01',2); -- 合并以上两条SQL语句 select * from tb_emp where (entrydate,job) = (select entrydate , job from tb_emp where name = '韦一笑'); 表子查询 子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。 案例:查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息 分解为两步执行: 查询入职日期是 "2006-01-01" 之后的员工信息 基于查询到的员工信息,在查询对应的部门信息 select * from emp where entrydate > '2006-01-01'; select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ; 存储过程/函数 存储过程 把一段 SQL 逻辑封装起来,存到数据库里, 以后只要执行名字,就能重复调用。 可以执行 INSERT/UPDATE/DELETE,可返回多结果集。 用法举例: DELIMITER // CREATE PROCEDURE add_user(IN username VARCHAR(50), IN age INT) BEGIN INSERT INTO users(name, age, created_at) VALUES (username, age, NOW()); END // DELIMITER ; 调用: CALL add_user('Alice', 25); 补充语法说明: 1)DELIMITER 用来修改 MySQL 命令结束符(分隔符)。 默认情况下,MySQL 认为每条 SQL 命令以 ; 结束。但是存储过程里,本身也会包含很多语句(每句都要以 ; 结尾)。如果不改分隔符,MySQL 就会误以为存储过程还没写完就已经结束了。 2)BEGIN ... END 用来包裹一段可执行的语句块。 3)SELECT age INTO age_val FROM users WHERE id = 1; 把结果存入变量 age_val 中 函数 函数和存储过程很像,但它必须返回一个值,通常用于查询计算(比如求平均、格式化、拼接等)。 一般只读(不能修改数据),只能返回一个标量。 DELIMITER // CREATE PROCEDURE get_user_age(IN uid INT) BEGIN DECLARE age_val INT; -- 从 users 表取 age,赋给变量 age_val SELECT age INTO age_val FROM users WHERE id = uid; -- 输出结果 SELECT CONCAT('用户年龄是: ', age_val); END // DELIMITER ; 执行: CALL get_user_age(5); 结果: 用户年龄是: 23 游标 游标(Cursor)是用来逐行读取查询结果集的指针。 普通的 SQL 一次会返回整张表的结果: SELECT name, age FROM users; 但在存储过程中,有时你希望像“遍历数组”一样——一行一行地取数据、处理逻辑、再取下一行。这时就要用到 游标。 游标使用的4个步骤: 步骤 关键语句 说明 1️⃣ 声明游标 DECLARE cursor_name CURSOR FOR SELECT ... 定义要遍历的结果集 2️⃣ 打开游标 OPEN cursor_name; 执行查询,准备读取 3️⃣ 取数据 FETCH cursor_name INTO var1, var2; 每次取一行结果 4️⃣ 关闭游标 CLOSE cursor_name; 释放资源 遍历所有用户,把他们的年龄大于 30 的标记为“中年用户”。 DELIMITER // CREATE PROCEDURE mark_middle_age() BEGIN -- 定义变量 DECLARE done INT DEFAULT 0; DECLARE uid INT; DECLARE uage INT; -- 定义游标(要遍历的结果集) DECLARE cur CURSOR FOR SELECT id, age FROM users; -- 定义结束条件(游标读完) DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; -- 打开游标 OPEN cur; -- 开始循环读取 read_loop: LOOP FETCH cur INTO uid, uage; -- 把当前行取出到变量 IF done THEN LEAVE read_loop; -- 没数据就退出循环 END IF; -- 条件判断逻辑 IF uage >= 30 THEN UPDATE users SET tag = '中年用户' WHERE id = uid; END IF; END LOOP; -- 关闭游标 CLOSE cur; END // DELIMITER ; 事务 事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 手动提交事务使用步骤: 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务 -- 开启事务 start transaction ; -- 删除学工部 delete from tb_dept where id = 1; -- 删除学工部的员工 delete from tb_emp where dept_id = 1; 上述的这组SQL语句,如果如果执行成功,则提交事务 -- 提交事务 (成功时执行) commit ; 上述的这组SQL语句,如果如果执行失败,则回滚事务 -- 回滚事务 (出错时执行) rollback ; 面试题:事务有哪些特性? 1)原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。 2)一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。 约束层面一致性主要指 数据要符合数据库定义的各种约束,主键约束、外键约束、唯一约束等必须始终成立。 业务层面一致性:部门和该部门下的员工数据全部删除 3)隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行(事务还没commit,那么别的窗口就看不到该修改 )。在 MySQL(InnoDB 引擎)里,隔离性主要是通过 事务隔离级别 + MVCC(多版本并发控制) + 锁机制 来实现的。 SQL 标准定义了 4 种隔离级别(MySQL 都支持): 读未提交 (READ UNCOMMITTED) 能读到别的事务未提交的数据(脏读)。 几乎没隔离,效率最高。 读已提交 (READ COMMITTED) 只能读到别的事务已提交的数据。 Oracle 默认级别,避免脏读,但会出现不可重复读。 可重复读 (REPEATABLE READ) MySQL 默认级别。 在同一个事务里,多次读同一行结果一致(避免不可重复读)。 InnoDB 在此级别下还能避免幻读(通过间隙锁)。 串行化 (SERIALIZABLE) 所有事务串行执行(加锁),最安全但效率最低。 4)持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。 事务的四大特性简称为:ACID 索引 索引(index):是帮助数据库高效获取数据的数据结构 。 创建索引 -- 添加索引 create index idx_sku_sn on tb_sku (sn); #在添加索引时,也需要消耗时间 -- 查询数据(使用了索引) select * from tb_sku where sn = '100000003145008'; 查看索引 show index from 表名; 案例:查询 tb_emp 表的索引信息 show index from tb_emp; 删除索引 drop index 索引名 on 表名; 案例:删除 tb_emp 表中name字段的索引 drop index idx_emp_name on tb_emp; 优点: 提高数据查询的效率,降低数据库的IO成本。 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。 缺点: 索引会占用存储空间。 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。 因为插入一条数据,要重新维护索引结构 注意事项: 主键字段,在建表时,会自动创建主键索引 (primarily key) 添加唯一约束时,数据库实际上会添加唯一索引 (unique约束) 结构 mysql默认采用B+树来作索引 采用二叉搜索树或者是红黑树来作为索引的结构有什么问题? 答案 最大的问题就是在数据量大的情况下,树的层级比较深,会影响检索速度。因为不管是二叉搜索数还是红黑数,一个节点下面只能有两个子节点。此时在数据量大的情况下,就会造成数的高度比较高,树的高度一旦高了,检索速度就会降低。 说明:如果数据结构是红黑树,那么查询1000万条数据,根据计算树的高度大概是23左右,这样确实比之前的方式快了很多,但是如果高并发访问,那么一个用户有可能需要23次磁盘IO,那么100万用户,那么会造成效率极其低下。所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。这种数据结构例如BTree就满足。 下面我们来看看B+Tree(多路平衡搜索树)结构中如何避免这个问题: B+Tree结构: 每一个节点,可以存储多个key(有n个key,就有n个指针) 节点分为:叶子节点、非叶子节点 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
后端学习
zy123
1年前
0
7
0
2025-03-21
JavaWeb——前端
JavaWeb JavaWeb学习路线 前后端分离开发 需求分析:首先我们需要阅读需求文档,分析需求,理解需求。 接口定义:查询接口文档中关于需求的接口的定义,包括地址,参数,响应数据类型等等 前后台并行开发:各自按照接口文档进行开发,实现需求 测试:前后台开发完了,各自按照接口文档进行测试 前后段联调测试:前段工程请求后端工程,测试功能 Html/CSS 标签速记: 不闭合标签: 空格占位符: 正文格式:line-height:设置行高;text-indent:设置首行缩进;text-align:规定文本的水平对齐方式 CSS引入方式 名称 语法描述 示例 行内样式 在标签内使用style属性,属性值是css属性键值对 <h1 style="xxx:xxx;">中国新闻网</h1> 内嵌样式 定义<style>标签,在标签内部定义css样式 <style> h1 {...} </style> 外联样式 定义<link>标签,通过href属性引入外部css文件 <link rel="stylesheet" href="css/news.css"> CSS选择器 1.元素(标签)选择器: 选择器的名字必须是标签的名字 作用:选择器中的样式会作用于所有同名的标签上 元素名称 { css样式名:css样式值; } 例子如下: div{ color: red; } 2.id选择器: 选择器的名字前面需要加上# 作用:选择器中的样式会作用于指定id的标签上,而且有且只有一个标签(由于id是唯一的) #id属性值 { css样式名:css样式值; } 例子如下: #did { color: blue; } 3.类选择器: 选择器的名字前面需要加上 . 作用:选择器中的样式会作用于所有class的属性值和该名字一样的标签上,可以是多个 .class属性值 { css样式名:css样式值; } 例子如下: .cls{ color: green; } 这里使用了第二种CSS引入方式,内嵌样式,<style>包裹,里面用了三种CSS选择器 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>焦点访谈:中国底气 新思想夯实大国粮仓</title> <style> h1 { color: #4D4F53; } /* 元素选择器 */ /* span { color: red; } */ /* 类选择器 */ /* .cls { color: green; } */ /* ID选择器 */ #time { color: #968D92; font-size: 13px; /* 设置字体大小 */ } </style> </head> <body> <img src="img/news_logo.png"> 新浪政务 > 正文 <h1>焦点访谈:中国底气 新思想夯实大国粮仓</h1> <hr> <span class="cls" id="time">2023年03月02日 21:50</span> <span class="cls">央视网</span> <hr> </body> </html> 页面布局 盒子模型,盒子部分指的是border及以内的部分,不包括margin 布局标签:实际开发网页中,会大量频繁的使用 div 和 span 这两个没有语义的布局标签。 标签: 特点: div标签: 一行只显示一个(独占一行) 宽度默认是父元素的宽度,高度默认由内容撑开 可以设置宽高(width、height) span标签: 一行可以显示多个 宽度和高度默认由内容撑开 不可以设置宽高(width、height) box-sizing: border-box,此时指定width height为盒子的高宽,而不是content的高宽 表格标签 table> : 用于定义整个表格, 可以包裹多个 <tr>, 常用属性如下: border:规定表格边框的宽度 width:规定表格的宽度 cellspacing: 规定单元之间的空间 <tr> : 表格的行,可以包裹多个 <td> <td> : 表格单元格(普通),可以包裹内容 , 如果是表头单元格,可以替换为 <th> ,th具有加粗居中展示的效果 表单标签 表单场景: 表单就是在网页中负责数据采集功能的,如:注册、登录的表单。 表单标签: <form> 表单属性: action: 规定表单提交时,向何处发送表单数据,表单提交的URL。 method: 规定用于发送表单数据的方式,常见为: GET、POST。 GET:表单数据是拼接在url后面的, 如: xxxxxxxxxxx?username=Tom&age=12,url中能携带的表单数据大小是有限制的。 POST: 表单数据是在请求体(消息体)中携带的,大小没有限制。 表单项标签: 不同类型的input元素、下拉列表、文本域等。 input: 定义表单项,通过type属性控制输入形式 type取值 描述 text 默认值,定义单行的输入字段 password 定义密码字段 radio 定义单选按钮 checkbox 定义复选框 file 定义文件上传按钮 date/time/datetime-local 定义日期/时间/日期时间 number 定义数字输入框 email 定义邮件输入框 hidden 定义隐藏域 submit / reset / button 定义提交按钮 / 重置按钮 / 可点击按钮 select: 定义下拉列表 textarea: 定义文本域 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>HTML-表单项标签</title> </head> <body> <!-- value: 表单项提交的值 --> <form action="" method="post"> 姓名: <input type="text" name="name"> <br><br> 密码: <input type="password" name="password"> <br><br> 性别: <input type="radio" name="gender" value="1"> 男 <label><input type="radio" name="gender" value="2"> 女 </label> <br><br> 爱好: <label><input type="checkbox" name="hobby" value="java"> java </label> <label><input type="checkbox" name="hobby" value="game"> game </label> <label><input type="checkbox" name="hobby" value="sing"> sing </label> <br><br> 图像: <input type="file" name="image"> <br><br> 生日: <input type="date" name="birthday"> <br><br> 时间: <input type="time" name="time"> <br><br> 日期时间: <input type="datetime-local" name="datetime"> <br><br> 邮箱: <input type="email" name="email"> <br><br> 年龄: <input type="number" name="age"> <br><br> 学历: <select name="degree"> <option value="">----------- 请选择 -----------</option> <option value="1">大专</option> <option value="2">本科</option> <option value="3">硕士</option> <option value="4">博士</option> </select> <br><br> 描述: <textarea name="description" cols="30" rows="10"></textarea> <br><br> <input type="hidden" name="id" value="1"> <!-- 表单常见按钮 --> <input type="button" value="按钮"> <input type="reset" value="重置"> <input type="submit" value="提交"> <br> </form> </body> </html> name="gender":这个属性定义了单选按钮组的名称,它们被分为同一个组,因此只能选择其中的一个按钮。在这种情况下,所有具有相同 name 属性值的单选按钮都被视为同一组。 value="1" 和 value="2":这些是单选按钮的值。当用户选择某个单选按钮时,该单选按钮的值将被提交到服务器。在这种情况下,value="1" 表示选择男性,而 value="2" 表示选择女性。 用户在浏览器中看到的文本内容是 "男" 和 "女"。 女 这里的label意味着用户不仅可以点击单选按钮本身来选择选项,当用户单击 "女" 这个标签文本时,与之关联的单选按钮也会被选中。 JavaScript JS引入方式 **第一种方式:**内部脚本,将JS代码定义在HTML页面中 JavaScript代码必须位于<script></script>标签之间 在HTML文档中,可以在任意地方,放置任意数量的<script> 一般会把脚本置于<body>元素的底部,可改善显示速度 例子: <script> alert("Hello JavaScript") </script> **第二种方式:**外部脚本将, JS代码定义在外部 JS文件中,然后引入到 HTML页面中 外部JS文件中,只包含JS代码,不包含<script>标签 引入外部js的<script>标签,必须是双标签 例子: <script src="js/demo.js"></script> 注意:demo.js中只有js代码,没有<script>标签 JS基础语法 书写语法 区分大小写:与 Java 一样,变量名、函数名以及其他一切东西都是区分大小写的 每行结尾的分号可有可无 大括号表示代码块 注释: 单行注释:// 注释内容 多行注释:/* 注释内容 */ 输出的三种形式: api 描述 window.alert() 警告框 document.write() 在HTML 输出内容 console.log() 写入浏览器控制台 变量 关键字 解释 var 早期ECMAScript5中用于变量声明的关键字 let ECMAScript6中新增的用于变量声明的关键字,相比较var,let只在代码块内生效(大括号) const 声明常量的,常量一旦声明,不能修改 var:作用域比较大,全局的;可以重复定义,后面的覆盖前面的 let:局部变量(代码块内生效{}),不可重复定义。 const: const pi=3.14 数据类型和运算符 数据类型 描述 number 数字(整数、小数、NaN(Not a Number)) string 字符串,单双引皆可 boolean 布尔。true,false null 对象为空 undefined 当声明的变量未初始化时,该变量的默认值是 undefined 运算规则 运算符 算术运算符 + , - , * , / , % , ++ , -- 赋值运算符 = , += , -= , *= , /= , %= 比较运算符 > , < , >= , <= , != , == , === 注意 == 会进行类型转换,=== 不会进行类型转换 逻辑运算符 && , || , ! 三元运算符 条件表达式 ? true_value: false_value parseint() ,将其他类型转化为数字 函数 第一种: function 函数名(参数1,参数2..){ 要执行的代码 } 因为JavaScript是弱数据类型的语言,所以有如下几点需要注意: 形式参数不需要声明类型,并且JavaScript中不管什么类型都是let或者var去声明,加上也没有意义。 返回值也不需要声明类型,直接return即可 如下示例: function add(a, b){ return a + b; } var result=add(10,20)可以接收返回值 第二种可以通过var去定义函数的名字,具体格式如下: var functionName = function (参数1,参数2..){ //要执行的代码 } 如下示例: var add = function(a,b){ return a + b; } var result = add(10,20); 函数的调用不变 JS对象 Array对象 方式1: var 变量名 = new Array(元素列表); 例如: var arr = new Array(1,2,3,4); //1,2,3,4 是存储在数组中的数据(元素) 方式2: var 变量名 = [ 元素列表 ]; 例如: var arr = [1,2,3,4]; //1,2,3,4 是存储在数组中的数据(元素) 长度可变=》可以直接arr[10]=100,不会报错 类型可变=》arr[1]="hello",可以既存数字又存字符串 属性: 属性 描述 length 设置或返回数组中元素的数量。 方法: 方法方法 描述 forEach() 遍历数组中的每个有值的元素,并调用一次传入的函数 push() 将新元素添加到数组的末尾,并返回新的长度 splice() 从数组中删除元素 普通for循环:会遍历每个数组元素,无论是否有值 var arr = [1,2,3,4]; arr[10] = 50; for (let i = 0; i < arr.length; i++) { console.log(arr[i]); } foreach: arr.forEach(function(e){ console.log(e); }) 在ES6中,引入箭头函数的写法,语法类似java中lambda表达式,修改上述代码如下: arr.forEach((e) => { console.log(e); }) push: arr.push(7,8,9) 可以一次添加多个元素 splice: arr.splice(start,cnt),从start开始,删cnt个元素 String字符串 String对象也提供了一些常用的属性和方法,如下表格所示: 属性: 属性 描述 length 字符串的长度。 方法: 方法 描述 charAt() 返回在指定位置的字符。 indexOf() 检索字符串。 trim() 去除字符串两边的空格 substring() 提取字符串中两个指定的索引号之间的字符。 length属性: length属性可以用于返回字符串的长度,添加如下代码: //length console.log(str.length); charAt()函数: charAt()函数用于返回在指定索引位置的字符,函数的参数就是索引。添加如下代码: console.log(str.charAt(4)); indexOf()函数 indexOf()函数用于检索指定内容在字符串中的索引位置的,返回值是索引,参数是指定的内容。添加如下代码: console.log(str.indexOf("lo")); trim()函数 trim()函数用于去除字符串两边的空格的。添加如下代码: var s = str.trim(); console.log(s.length); substring()函数 substring()函数用于截取字符串的,函数有2个参数。 参数1:表示从那个索引位置开始截取。包含 参数2:表示到那个索引位置结束。不包含 console.log(s.substring(0,5)); JSON对象 自定义对象 var 对象名 = { 属性名1: 属性值1, 属性名2: 属性值2, 属性名3: 属性值3, 函数名称: function(形参列表){} }; 我们可以通过如下语法调用属性: 对象名.属性名 通过如下语法调用函数: 对象名.函数名() json对象 JSON对象:JavaScript Object Notation,JavaScript对象标记法。是通过JavaScript标记法书写的文本。其格式如下: { "key":value, "key":value, "key":value } 其中,key必须使用引号并且是双引号标记,value可以是任意数据类型。 JSON字符串示例: var jsonstr = '{"name":"Tom", "age":18, "addr":["北京","上海","西安"]}'; alert(jsonstr.name); 注意外层的单引号不要忘记! JSON字符串=》JS对象 var obj = JSON.parse(jsonstr); 对象.属性 就可以获得key对应的值 JS对象=》JS字符串 var jsonstr=JSON.stringify(obj) JSON格式数据 {"name":"666"} 是一个 JSON 对象,[{"name":"666"},{"name":"li"}] 是一个 JSON 数组,它们都是 JSON 格式的数据。 BOM对象 重点学习的是Window对象、Location(地址栏)对象 window对象 常用方法:通过可简写,window.alert()->alert() 函数 描述 alert() 显示带有一段消息和一个确认按钮的警告框。 comfirm() 显示带有一段消息以及确认按钮和取消按钮的对话框。 setInterval() 按照指定的周期(以毫秒计)来调用函数或计算表达式。 setTimeout() 在指定的毫秒数后调用函数或计算表达式。 setInterval(fn,毫秒值):定时器,用于周期性的执行某个功能,并且是循环执行。该函数需要传递2个参数: fn:函数,需要周期性执行的功能代码 毫秒值:间隔时间 //定时器 - setInterval -- 周期性的执行某一个函数 var i = 0; setInterval(function(){ i++; console.log("定时器执行了"+i+"次"); },2000); setTimeout(fn,毫秒值) :定时器,只会在一段时间后执行一次功能。参数和上述setInterval一致 注释掉之前的代码,添加代码如下: //定时器 - setTimeout -- 延迟指定时间执行一次 setTimeout(function(){ alert("JS"); },3000); 浏览器打开,3s后弹框,关闭弹框,发现再也不会弹框了。 Location对象 location是指代浏览器的地址栏对象,对于这个对象,我们常用的是href属性,用于获取或者设置浏览器的地址信息,添加如下代码: //获取浏览器地址栏信息 alert(location.href); //设置浏览器地址栏信息 location.href = "https://www.itcast.cn"; 设置后会自动跳转到该地址。 DOM对象 DOM介绍 DOM:Document Object Model 文档对象模型。也就是 JavaScript 将 HTML 文档的各个组成部分封装为对象。 封装的对象分为 Document:整个文档对象 Element:元素对象 Attribute:属性对象 Text:文本对象 Comment:注释对象 那么我们学习DOM技术有什么用呢?主要作用如下: 改变 HTML 元素的内容 改变 HTML 元素的样式(CSS) 对 HTML DOM 事件作出反应 添加和删除 HTML 元素 从而达到动态改变页面效果目的。 DOM获取 函数 描述 document.getElementById() 根据id属性值获取,返回单个Element对象 document.getElementsByTagName() 根据标签名称获取,返回Element对象数组 document.getElementsByName() 根据name属性值获取,返回Element对象数组 document.getElementsByClassName() 根据class属性值获取,返回Element对象数组 示例代码: <body> <img id="h1" src="img/off.gif"> <br><br> <div class="cls">传智教育</div> <br> <div class="cls">黑马程序员</div> <br> <input type="checkbox" name="hobby"> 电影 <input type="checkbox" name="hobby"> 旅游 <input type="checkbox" name="hobby"> 游戏 </body> document.getElementById(): 根据标签的id属性获取标签对象,id是唯一的,所以获取到是单个标签对象。 <script> //1. 获取Element元素 //1.1 获取元素-根据ID获取 var img = document.getElementById('h1'); alert(img); </script> document.getElementsByTagName() : 根据标签的名字获取标签对象,同名的标签有很多,所以返回值是数组。重点! var divs = document.getElementsByTagName('div'); for (let i = 0; i < divs.length; i++) { alert(divs[i]); } DOM修改 同上面的例子: 你想要如何操作获取到的DOM元素,你需要查阅手册,看它支持的属性 var divs = document.getElementsByClassName('cls'); var div1 = divs[0]; div1.innerHTML = "传智教育666"; JS事件 JavaScript对于事件的绑定提供了2种方式: 方式1:通过html标签中的事件属性进行绑定 <input type="button" id="btn1" value="事件绑定1" onclick="on()"> <script> function on(){ alert("按钮1被点击了..."); } </script> 方式2:通过DOM中Element元素的事件属性进行绑定 <input type="button" id="btn2" value="事件绑定2"> <script> document.getElementById('btn2').onclick = function(){ alert("按钮2被点击了..."); } </script> 常见事件: 事件属性名 说明 onclick 鼠标单击事件 onblur 元素失去焦点 onfocus 元素获得焦点 onload 某个页面或图像被完成加载 onsubmit 当表单提交时触发该事件 onmouseover 鼠标被移到某元素之上 onmouseout 鼠标从某元素移开 VUE VUE简介 我们引入了一种叫做MVVM(Model-View-ViewModel)的前端开发思想,即让我们开发者更加关注数据,而非数据绑定到视图这种机械化的操作。那么具体什么是MVVM思想呢? MVVM:其实是Model-View-ViewModel的缩写,有3个单词,具体释义如下: Model: 数据模型,特指前端中通过请求从后台获取的数据 View: 视图,用于展示数据的页面,可以理解成我们的html+css搭建的页面,但是没有数据 ViewModel: 数据绑定到视图,负责将数据(Model)通过JavaScript的DOM技术,将数据展示到视图(View)上 基于上述的MVVM思想,其中的Model我们可以通过Ajax来发起请求从后台获取;对于View部分,我们将来会学习一款ElementUI框架来替代HTML+CSS来更加方便的搭建View;而今天我们要学习的就是侧重于ViewModel部分开发的vue前端框架,用来替代JavaScript的DOM操作,让数据展示到视图的代码开发变得更加的简单。 VUE快速上手 第一步:在VS Code中创建名为12. Vue-快速入门.html的文件,并且在html文件同级创建js目录,将资料/vue.js文件目录下得vue.js拷贝到js目录 第二步:然后编写<script>标签来引入vue.js文件,代码如下: <script src="js/vue.js"></script> 第三步:在js代码区域定义vue对象,代码如下: <script> //定义Vue对象 new Vue({ el: "#app", //vue接管区域 data:{ message: "Hello Vue" } }) </script> 在创建vue对象时,有几个常用的属性: el: 用来指定哪儿些标签受 Vue 管理。 该属性取值 #app 中的 app 需要是受管理的标签的id属性值 data: 用来定义数据模型 methods: 用来定义函数。这个我们在后面就会用到 第四步:在html区域编写视图,其中{{}}是插值表达式,用来将vue对象中定义的model展示到页面上的 <body> <div id="app"> <input type="text" v-model="message"> {{message}} </div> </body> Vue指令 **指令:**HTML 标签上带有 v- 前缀的特殊属性,不同指令具有不同含义。 指令 作用 v-bind 为HTML标签绑定属性值,如设置 href , css样式等 v-model 在表单元素上创建双向数据绑定 v-on 为HTML标签绑定事件 v-if 条件性的渲染某元素,判定为true时渲染,否则不渲染 v-else v-else-if v-show 根据条件展示某元素,区别在于切换的是display属性的值 v-for 列表渲染,遍历容器的元素或者对象的属性 V-bind和v-model v-bind: 为HTML标签绑定属性值,如设置 href , css样式等。当vue对象中的数据模型发生变化时,标签的属性值会随之发生变化。单向绑定! v-model: 在表单元素上创建双向数据绑定。什么是双向? vue对象的data属性中的数据变化,视图展示会一起变化 视图数据发生变化,vue对象的data属性中的数据也会随着变化。 data属性中数据变化,我们知道可以通过赋值来改变,但是视图数据为什么会发生变化呢?只有表单项标签!所以双向绑定一定是使用在表单项标签上的。 <body> <div id="app"> <a v-bind:href="url">链接1</a> <a :href="url">链接2</a> <input type="text" v-model="url"> </div> </body> <script> //定义Vue对象 new Vue({ el: "#app", //vue接管区域 data:{ url: "https://www.baidu.com" } }) </script> v-on v-on: 用来给html标签绑定事件的 <input type="button" value="点我一下" v-on:click="handle()"> 简写: <input type="button" value="点我一下" @click="handle()"> script: <script> //定义Vue对象 new Vue({ el: "#app", //vue接管区域 data:{ }, methods: { handle: function(){ alert("你点我了一下..."); } } }) </script> v-if和v-show 年龄<input type="text" v-model="age">经判定,为: <span v-if="age <= 35">年轻人(35及以下)</span> <span v-else-if="age > 35 && age < 60">中年人(35-60)</span> <span v-else>老年人(60及以上)</span> 年龄<input type="text" v-model="age">经判定,为: <span v-show="age <= 35">年轻人(35及以下)</span> <span v-show="age > 35 && age < 60">中年人(35-60)</span> <span v-show="age >= 60">老年人(60及以上)</span> v-show和v-if的作用效果是一样的,只是原理不一样。v-if指令,不满足条件的标签代码直接没了,而v-show指令中,不满足条件的代码依然存在,只是添加了css样式来控制标签不去显示。 vue-for v-for: 从名字我们就能看出,这个指令是用来遍历的。其语法格式如下: <div id="app"> <div v-for="addr in addrs">{{addr}}</div> <hr> <div v-for="(addr,index) in addrs">{{index}} : {{addr}}</div> </div> <script> //定义Vue对象 new Vue({ el: "#app", //vue接管区域 data:{ addrs:["北京", "上海", "西安", "成都", "深圳"] }, methods: { } }) </script> index从0开始 Vue生命周期 状态 阶段周期 beforeCreate 创建前 created 创建后 beforeMount 挂载前 mounted 挂载完成 beforeUpdate 更新前 updated 更新后 beforeDestroy 销毁前 destroyed 销毁后 其中我们需要重点关注的是**mounted,**其他的我们了解即可。 与methods平级 mounted:挂载完成,Vue初始化成功,HTML页面渲染成功。以后我们一般用于页面初始化自动的ajax请求后台数据 Ajax-Axios Ajax: 全称Asynchronous JavaScript And XML,异步的JavaScript和XML。其作用有如下2点: 与服务器进行数据交换:通过Ajax可以给服务器发送请求,并获取服务器响应的数据。 异步交互:可以在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页的技术,如:搜索联想、用户名是否可用的校验等等。 现在Ajax已经淘汰,用Axios了,是对Ajax的封装 Axios快速上手 Axios的使用比较简单,主要分为2步: 引入Axios文件 <script src="js/axios-0.18.0.js"></script> 使用Axios发送请求,并获取响应结果,官方提供的api很多,此处给出2种,如下 发送 get 请求 axios({ method:"get", url:"http://localhost:8080/ajax-demo1/aJAXDemo1?username=zhangsan" }).then(function (resp){ alert(resp.data); }) 发送 post 请求 axios({ method:"post", url:"http://localhost:8080/ajax-demo1/aJAXDemo1", data:"username=zhangsan" }).then(function (resp){ alert(resp.data); }); 推荐以下方法! 方法 描述 axios.get(url [, config]) 发送get请求 axios.delete(url [, config]) 发送delete请求 axios.post(url [, data[, config]]) 发送post请求 axios.put(url [, data[, config]]) 发送put请求 axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { console.log(result.data); }) axios.post("http://yapi.smart-xwork.cn/mock/169327/emp/deleteById","id=1").then(result => { console.log(result.data); }) axios使用步骤: 步骤: 首先创建文件,提前准备基础代码,包括表格以及vue.js和axios.js文件的引入 我们需要在vue的mounted钩子函数中发送ajax请求,获取数据 拿到数据,数据需要绑定给vue的data属性 在<tr>标签上通过v-for指令遍历数据,展示数据,这里同Vue中的步骤。 <script> new Vue({ el: "#app", data: { emps:[] }, mounted () { //发送异步请求,加载数据 axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => { console.log(result.data); this.emps = result.data.data; }) } }); </script> Vue中先定义emps空数组,再axios将数据取到里面 this.emps=xxxx Nginx docker-compose.yml version: '3.8' networks: group-buy-network: external: true services: # 前端(保持不变) group-buy-market-front: image: nginx:alpine ports: ['86:80'] volumes: - ./nginx/html:/usr/share/nginx/html - ./nginx/conf/nginx.conf:/etc/nginx/nginx.conf:ro networks: - group-buy-network # 后端实例1 group-buying-sys-1: image: smile/group-buying-sys:latest ports: ['8091:8091'] networks: - group-buy-network # 后端实例2 group-buying-sys-2: image: smile/group-buying-sys:latest # 使用相同镜像 ports: ['8092:8091'] # 宿主机端口不同,容器内部端口相同 networks: - group-buy-network nginx.conf # 全局配置块 user nginx; # 以nginx用户身份运行worker进程(安全性考虑) worker_processes auto; # 自动根据CPU核心数设置工作进程数量(优化性能) error_log /var/log/nginx/error.log warn; # 错误日志路径,只记录警告及以上级别的错误 pid /var/run/nginx.pid; # 存储Nginx主进程ID的文件位置(用于进程管理) # 事件处理模块配置 events { worker_connections 1024; # 每个worker进程能处理的最大并发连接数 # 总并发量 = worker_processes * worker_connections } # HTTP服务器配置 http { # 基础文件类型支持 include /etc/nginx/mime.types; # 包含MIME类型定义文件(扩展名与Content-Type映射) default_type application/octet-stream; # 默认MIME类型(当无法识别文件类型时使用) # 性能优化参数 sendfile on; # 启用高效文件传输模式(零拷贝技术) keepalive_timeout 65; # 客户端保持连接的超时时间(秒),减少TCP握手开销 # 上游服务器组定义(负载均衡) upstream gbm_backend { # 负载均衡配置(两个后端实例) server group-buying-sys-1:8091 weight=3; # 后端实例1,权重为3(获得60%流量) server group-buying-sys-2:8091 weight=2; # 后端实例2,权重为2(获得40%流量) keepalive 32; # 保持到后端服务器的长连接数(提升性能) } # 支付服务上游(单实例) upstream pay_backend { server pay-mall:8092; # 支付服务地址(Docker服务名) } # 虚拟主机配置(一个server代表一个网站) server { # 监听配置 listen 80 default_server; # 监听IPv4的80端口,作为默认服务器 listen [::]:80 default_server; # 监听IPv6的80端口 server_name groupbuy.bitday.top; # 绑定的域名(支持多个,用空格分隔) # 静态文件服务配置 root /usr/share/nginx/html; # 前端静态文件根目录(Docker需挂载此目录) index index.html; # 默认访问的索引文件 # 前端路由处理(适配Vue/React等单页应用) location / { try_files $uri $uri/ /index.html; # 尝试顺序:匹配文件→匹配目录→回退到index.html } # 组购系统API代理配置 location /api/v1/gbm/ { proxy_pass http://gbm_backend; # 请求转发到负载均衡组 proxy_set_header Host $host; # 传递原始域名 proxy_set_header X-Real-IP $remote_addr; # 传递客户端真实IP proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 代理链IP信息 } # 支付/登录API代理(正则匹配) location ~ ^/api/v1/(alipay|login)/ { proxy_pass http://pay_backend; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } } 注意事项: 1.由于是docker部署,要区别宿主机端口与容器内端口!比如 server group-buying-sys-1:8091 weight=3; 这里的8091就是 group-buying-sys-1 这个容器内端口。类似地,nginx也是docker部署,通过宿主机端口86映射到group-buy-market-front这个容器内的80端口。nginx.conf配置中的端口一定是和容器内挂钩的,而不是和宿主机!!! 2.如果不是docker部署,比如在本地windows运行nginx.exe ,那么 就没有 ports: ['8091:8091'] 这种映射关系,你的java项目中写的端口是多少,那么nginx.conf就配置多少 3.docker部署,如果 nginx 与 group-buying-sys 位于同一网络中,可以服务名:容器内端口 等价于 宿主机ip:端口。比如 group-buying-sys-2 中 ports: ['8092:8091'] ,假设服务器ip地址为124.71.159.xxx ,那么 upstream gbm_backend { server group-buying-sys-2:8091 weight=2; #推荐! nginx->后端容器 } upstream gbm_backend { server 124.71.159.xxx:8092 weight=2; #非常不推荐!相关nginx->宿主机->后端容器 } 两种效果一样,但推荐第一种!!! 4.Nginx 反向代理的核心配置 location /api/v1/gbm/ { proxy_pass http://gbm_backend; # 请求转发到负载均衡组 proxy_set_header Host $host; # 传递原始域名 proxy_set_header X-Real-IP $remote_addr; # 传递客户端真实IP proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 代理链IP信息 } 将所有匹配 /api/v1/gbm/ 路径的请求转发到 gbm_backend 这个后端容器(可负载均衡为多台)。 请求 http://nginx-server/api/v1/gbm/order → 转发到 http://gbm_backend/api/v1/gbm/order **注意,**如果 location /api/v1/gbm/ { proxy_pass http://gbm_backend/; # 注意末尾的斜杠 } 请求 http://nginx-server/api/v1/gbm/order → 转发到 http://gbm_backend/order(/api/v1/gbm/ 被移除) 5.如果配置了反向代理(第4点内容),那么前端调用后端接口时,HTML、JS中无需写具体的后端服务器所在地址(ip:端口),而且如果做了负载均衡,有多台,这里也不好指定哪一台。 为什么? 比如前端发送请求fetch(/api/v1/gbm/index/query_group_buy_market_config) 发现匹配 /api/v1/gbm ,nginx根据配置就发给http://gbm_backend负载均衡组,组里有group-buying-sys-1和 group-buying-sys-2,根据负载均衡规则转发到其中一台后端服务器。 6.静态文件挂载 server { ... # 静态文件服务配置 root /usr/share/nginx/html; # 前端静态文件根目录(Docker需挂载此目录) index index.html; ... } root 要指定静态文件根目录,如果是docker部署,一定要写容器内的位置;index.html 这个文件是/usr/share/nginx/html目录下的。 坑点: 如果要上传文件,可能会报413错误:单次请求的 整体 body 大小超限(默认1MB) 若后端需要解析比较耗时,还可能报503错误:超时间限制(默认60秒) 业务涉及 大文件上传 或 长时间任务,务必调整这些配置!如: location /api/ { proxy_pass http://ai-rag-knowledge-app:8095; proxy_http_version 1.1; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; client_max_body_size 50M; # 允许上传 50MB # 添加代理超时设置(单位:秒) proxy_connect_timeout 3600s; proxy_send_timeout 3600s; proxy_read_timeout 3600s; }
杂项
zy123
1年前
0
6
0
上一页
1
...
9
10
11
12
下一页