首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
41 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
找到
16
篇与
后端学习
相关的结果
- 第 3 页
2025-03-21
Java笔记本
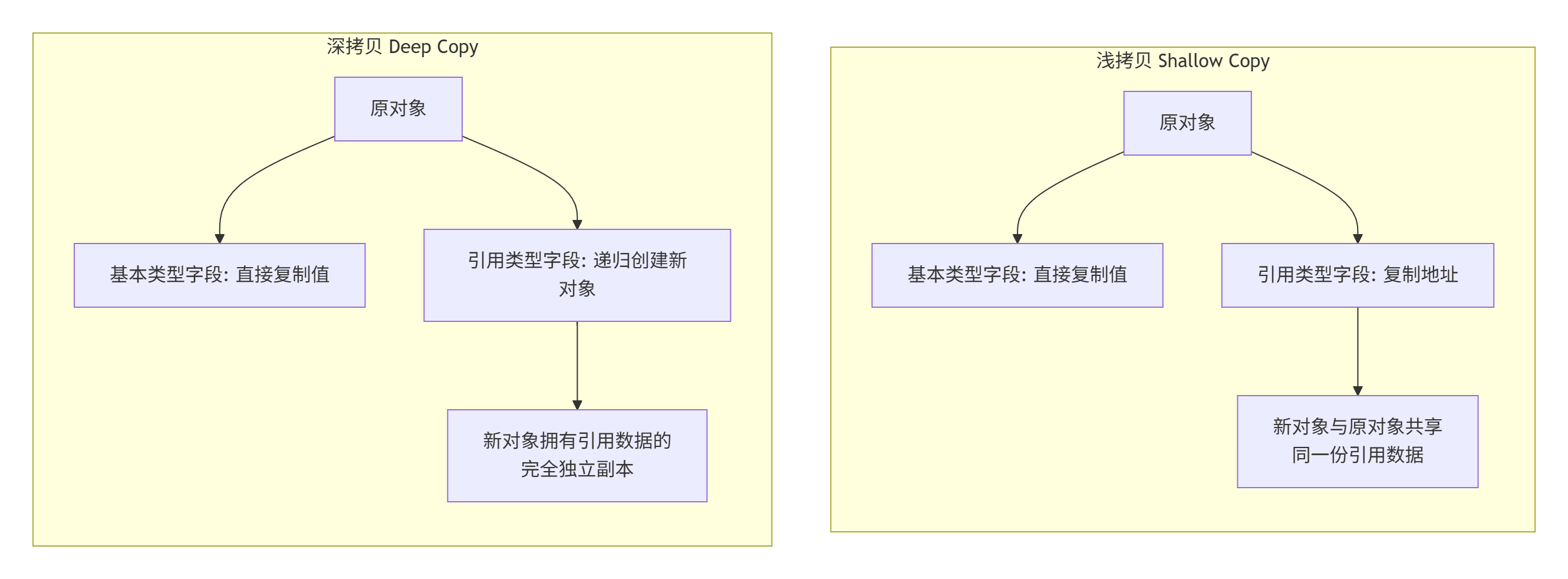
Java笔记本 IDEA基础操作 Intellij Idea创建Java项目: 创建空项目 创建Java module 创建包 package edu.whut.xx 创建类,类名首字母必须大写! IDEA快捷键: Ctrl + L 格式化代码 Ctrl + / 注释/取消注释当前行 Ctrl + D 复制当前行或选中的代码块 Ctrl + N 查找类 shift+shift 在文件中查找代码 alt+ enter “意图操作” “快捷修复” 可以1:service接口类跳转到实现 2:补全函数的返回值 调试快捷键: 快捷键 功能 Shift + F9 调试当前程序 F8 单步执行(不进入方法) F7 单步执行(进入方法) Shift + F8 跳出当前方法 Alt + F9 运行到光标处 Ctrl + F2 停止调试 缩写 生成的代码 说明 psvm public static void main(String[] args) {} 生成 main 方法 sout System.out.println(); 打印到控制台 fori for (int i = 0; i < ; i++) {} 生成 for 循环 iter for (Type item : iterable) {} 生成增强 for 循环 new Test().var Test test = new Test(); 自动补全变量声明 从exsiting file中导入模块: 方法一:复制整个模块到项目文件夹,并导入模块的 *.iml 文件,这种方式保留了模块原有的配置信息。 方法二:新建一个模块,然后将原模块的 src 文件夹下的包复制过去,这种方式更灵活,可以手动调整模块设置。 删除模块: 模块右键,remove module,这只是把它从项目中移除,然后!!打开模块所在文件夹,物理删除,才是真正完全删除。 Java基础 二进制:0b 八进制:0 十六进制:0x 在 System.out.println() 方法中,"ln" 代表 "line",表示换行。因此,println 实际上是 "print line" 的缩写。这个方法会在输出文本后自动换行. System.out.println("nihao "+1.3331); #Java 会自动将数值转换为字符串 一维数组创建: // 方式1:先声明,再指定长度(默认值为0、null等) int[] arr1 = new int[10]; // 创建一个长度为10的int数组 // 方式2:使用初始化列表直接创建数组 int[] arr2 = {1, 2, 3, 4, 5}; // 创建并初始化一个包含5个元素的int数组 String[] strs = {"eat", "tea", "tan", "ate", "nat", "bat"}; // 方式3:结合new关键字和初始化列表创建数组(常用于明确指定类型时) int[] arr3 = new int[]{1, 2, 3, 4, 5}; // 与方式2效果相同 字符串创建 String str = "Hello, World!"; //(1)直接赋值 String str = new String("Hello, World!"); //使用 new 关键字 char[] charArray = {'H', 'e', 'l', 'l', 'o'}; String str = new String(charArray); //通过字符数组创建 switch-case public class SwitchCaseExample { public static void main(String[] args) { // 定义一个 int 类型变量,作为 switch 的表达式 int day = 3; String dayName; // 根据 day 的值执行相应的分支 switch(day) { case 1: dayName = "Monday"; // 当 day 为 1 时 break; // 结束当前 case case 2: dayName = "Tuesday"; // 当 day 为 2 时 break; case 3: dayName = "Wednesday"; // 当 day 为 3 时 break; case 4: dayName = "Thursday"; // 当 day 为 4 时 break; case 5: dayName = "Friday"; // 当 day 为 5 时 break; case 6: dayName = "Saturday"; // 当 day 为 6 时 break; case 7: dayName = "Sunday"; // 当 day 为 7 时 break; default: // 如果 day 不在 1 到 7 之间 dayName = "Invalid day"; } // 输出最终结果 System.out.println("The day is: " + dayName); } } 强制类型转换 double sqrted=Math.sqrt(n); int soft_max=(int) sqrted; Math库常用方法 Math.pow(3, 2)); Math.sqrt(9)); Math.abs(a)); Math.max(a, b)); Math.min(a, b)); 转义符的作用 防止字符被误解: 在字符串中,一些字符(如 " 和 \)有特殊的含义。例如,双引号用于标识字符串的开始和结束,反斜杠通常用于转义。所以当你希望在字符串中包含这些特殊字符时,你需要使用转义符来告诉解析器这些字符是字符串的一部分,而不是特殊符号。 例如,\" 表示在字符串中包含一个双引号字符,而不是字符串的结束标志。 "Hello \"World\"" => 结果是:Hello "World" (双引号被转义) "C:\\Program Files\\App" => 结果是:C:\Program Files\App(反斜杠被转义) 如果只是"C:\Program Files\App" 那么路径就会报错 表示非打印字符: 转义符可以用于表示一些不可见的或非打印的控制字符,如换行符(\n)、制表符(\t)等。这些字符无法直接通过键盘输入,所以使用转义符来表示它们。 枚举 //纯状态枚举 常见于 switch-case、简单条件判断。 public enum OperationType { /** * 更新操作 */ UPDATE, /** * 插入操作 */ INSERT } OperationType opType = OperationType.INSERT; // 声明并初始化 public void execute(OperationType type, Object entity) { switch (type) { case INSERT: insertEntity(entity); break; case UPDATE: updateEntity(entity); break; default: throw new IllegalArgumentException("Unsupported operation: " + type); } } // 携带数据的枚举, 适合“常量 + 不变数据”的场景,如 星期、货币、错误码等。 public enum DayOfWeek { //创建7个 DayOfWeek 类型的对象,分别传入构造参数chineseName和dayNumber,它们叫“枚举常量” MONDAY("星期一", 1), TUESDAY("星期二", 2), WEDNESDAY("星期三", 3), THURSDAY("星期四", 4), FRIDAY("星期五", 5), SATURDAY("星期六", 6), SUNDAY("星期日", 7); // 枚举属性 private final String chineseName; private final int dayNumber; // 构造方法 DayOfWeek(String chineseName, int dayNumber) { this.chineseName = chineseName; this.dayNumber = dayNumber; } // 方法 public String getChineseName() { return chineseName; } public int getDayNumber() { return dayNumber; } } // 使用示例 public class Main { public static void main(String[] args) { DayOfWeek today = DayOfWeek.MONDAY; System.out.println(today.getChineseName()); // 输出: 星期一 System.out.println(today.getDayNumber()); // 输出: 1 } } 枚举类的构造方法必须是 private的,默认就是private的,这意味着只能在枚举内部使用这个构造方法。 枚举类你只需要使用,而不用创建对象,类内部已经定义好了MONDAY、TUESDAY...对象。 Java传参方式 基本数据类型 传递方式:按值传递 每次传递的是变量的值的副本**,对该值的修改不会影响原变量**。例如:int、double、boolean 等类型。 引用类型(对象) 传递方式:对象引用的副本传递 传递的是对象引用的一个副本,指向同一块内存区域。因此,方法内部通过该引用修改对象的状态,会影响到原对象。如数组、集合、String、以及其他所有对象类型。 Integer 属于引用类型,变量 Integer a = 10;中的 a是一个引用,它指向堆中存储的 Integer对象。 注意 StringBuilder s = new StringBuilder(); s.append("hello"); String res = s.toString(); // res = "hello" s.append(" world"); // s = "hello world" System.out.println(res); // 输出还是 "hello" 浅拷贝深拷贝 不可变对象 一个对象一旦被创建并初始化,它的状态(其内部代表的数据)就再也无法被改变,如Integer、String。 不可变”在代码中的具体表现:所有修改操作都返回新对象 String s1 = "Hello"; String s2 = s1.concat(" World"); // 不是修改s1,而是创建新字符串 字符串常量池 String a = "1"; String b = "1"; 变量 a和变量 b会指向同一个内存中的 String对象。 原理:常量池中有,就直接返回其引用;没有,就创建一个放进去再返回。 存放位置: Java 7 之前:字符串常量池逻辑上属于方法区(Method Area) 的运行时常量池(Runtime Constant Pool) 的一部分。而方法区的具体实现是 永久代(PermGen)。 问题:永久代大小有限且难以调整,容易发生 OutOfMemoryError: PermGen space。 Java 7 开始:字符串常量池被从永久代移动到了 Java 堆(Heap) 中。 Java 8 及以后:永久代被彻底移除,取而代之的是元空间(Metaspace)(用于存类元信息、方法码等)。而字符串常量池依然留在堆中。 浅拷贝 拷贝对象本身,但内部成员(例如集合中的元素)只是复制引用,新旧对象的内部成员指向同一份内存。如果内部元素是不可变的(如 Integer、String 等),这种拷贝通常足够。如果元素是可变对象,修改其中一个对象可能会影响另一个。 回溯法用的就是浅拷贝,因为List<Integer> path; 中间的Integer是不可变对象。 List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); //new ArrayList<>(list)的底层行为: //1.新建一个空的 ArrayList实例。 //2.将原集合 list中的所有元素引用逐个复制到新集合中。 //3.返回这个新集合。 //4.新集合和原集合是两个完全独立的容器,只是内容(元素引用)相同。 List<Integer> shallowCopy = new ArrayList<>(list); 可变对象,浅拷贝修改对象会出错! List<Box> list = new ArrayList<>(); list.add(new Box(1)); list.add(new Box(2)); list.add(new Box(3)); List<Box> shallowCopy = new ArrayList<>(list); shallowCopy.get(0).value = 10; // 修改 shallowCopy 中第一个 Box 的 value System.out.println(list); // 输出: [10, 2, 3],因为同一 Box 对象被修改 System.out.println(shallowCopy); // 输出: [10, 2, 3] 深拷贝 不仅复制对象本身,还递归地复制其所有内部成员,从而生成一个完全独立的副本。即使内部元素是可变的,修改新对象也不会影响原始对象。 // 深拷贝 List<MyObject> 的例子 List<MyObject> originalList = new ArrayList<>(); originalList.add(new MyObject(10)); originalList.add(new MyObject(20)); List<MyObject> deepCopy = new ArrayList<>(); for (MyObject obj : originalList) { deepCopy.add(new MyObject(obj)); // 每个元素都创建一个新的对象 } 日期 在Java中: 代表年月日的类型是 LocalDate。LocalDate 类位于 java.time 包下,用于表示没有时区的日期,如年、月、日。 代表年月日时分秒的类型是 LocalDateTime。LocalDateTime 类也位于 java.time 包下,用于表示没有时区的日期和时间,包括年、月、日、时、分、秒。 LocalDateTime.now(),获取当前时间 静态成员变量与静态方法 一、静态成员变量 静态成员变量使用 static 修饰,属于类级别,而非对象,即所有对象共享同一份静态变量。 在类加载时完成初始化,且只执行一次。 可以通过类名直接访问,无需创建对象。 二、静态变量的初始化方式 1)静态代码块,用于对静态变量进行复杂初始化,在类第一次加载到 JVM 时执行一次。 public class MyClass { static int num1, num2; static { num1 = 1; System.out.println("静态代码块1执行"); } static { num2 = 3; System.out.println("静态代码块2执行"); } public static void main(String[] args) { System.out.println("main方法执行"); } } 输出: 静态代码块1执行 静态代码块2执行 main方法执行 类加载时按代码顺序依次执行所有静态代码块。 由于 main() 是静态方法,调用前类已被加载,因此静态代码块先执行。 示例 2:静态代码块 vs 构造方法 class Demo { static { System.out.println("静态代码块"); } Demo() { System.out.println("构造方法"); } } public class Test { public static void main(String[] args) { System.out.println("main开始"); Demo d1 = new Demo(); Demo d2 = new Demo(); } } 输出: main开始 静态代码块 构造方法 构造方法 说明:静态代码块仅在类首次加载时执行一次,构造方法在每次 new 对象时执行。 2)声明时直接初始化 public class MyClass { public static int staticVariable = 42; } 类加载时 staticVariable 直接被赋值为 42。 3)通过静态方法赋值(运行时) public class GlobalCounter { public static int currentCount; public static void initializeCounter(int startValue) { currentCount = startValue; } public static void incrementCounter() { currentCount++; } } public class Main { public static void main(String[] args) { GlobalCounter.initializeCounter(100); System.out.println(GlobalCounter.currentCount); // 输出 100 GlobalCounter.incrementCounter(); System.out.println(GlobalCounter.currentCount); // 输出 101 } } 只有 静态方法 才能在不创建对象的情况下访问或修改静态变量。 三、静态方法 用 static 修饰的方法,属于类本身,不依赖任何实例。 通过类名直接调用,无需创建对象。 public class MathUtils { public static int square(int n) { return n * n; } } int result = MathUtils.square(5); // 直接通过类名调用 四、访问静态成员变量 int value = MyClass.staticVariable; // ✅ 推荐 MyClass obj = new MyClass(); System.out.println(obj.staticVariable); // ✅ 可行,但不推荐 静态成员属于类,与对象无关;推荐使用类名访问。 变量修饰符final、static... 在Java中,变量的修饰符应该按照规定的顺序出现,通常是这样的: 访问修饰符:public、protected、private,或者不写(默认为包级访问)。 非访问修饰符:final、static、abstract、synchronized、volatile等。 数据类型:变量的数据类型,如 int、String、class 等。 变量名:变量的名称。 public static final int MAX_COUNT = 100; #定义常量 protected static volatile int counter; #定义成员变量 虽然final、static都是非访问修饰符,但是一般都是 static final ,不推荐反过来!!! final关键字 final 关键字,意思是最终的、不可修改的,最见不得变化 ,用来修饰类、方法和变量,具有以下特点: 修饰类:类不能继承,final 类中的所有成员方法都会被隐式的指定为 final 方法; 修饰变量:该变量为常量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能让其指向另一个对象。 修饰符方法:方法不能重写 全限定名 全限定名(Fully Qualified Name,简称 FQN)指的是一个类或接口在 Java 中的完整名称,包括它所在的包名。例如: 对于类 Integer,其全限定名是 java.lang.Integer。 对于自定义的类 DeptServiceImpl,如果它位于包 edu.zju.zy123.service.impl 中,那么它的全限定名就是 edu.zju.zy123.service.impl.DeptServiceImpl。 使用全限定名可以消除歧义,确保指定的类型在整个项目中唯一无误。 使用场景: Spring AOP 的 Pointcut 表达式 MyBatis的XML映射文件的namespace属性 synchronized 概念 它的核心在于选择一个对象作为“锁”(也称为“监视器”或“互斥量”)。 synchronized (lockObject) { // 需要同步的代码块(临界区) } lockObject:这是一个对象引用,它作为锁。任何Java对象都可以充当锁。 { ... }:大括号内的代码就是“临界区”。JVM保证同一时刻,只有一个线程可以持有 lockObject这把锁并执行临界区内的代码。其他试图进入的线程必须等待,直到当前线程释放锁。 常见使用形式 类型 写法 锁对象 用途 同步方法(实例) public synchronized void foo() this 保护实例变量 同步方法(静态) public static synchronized void foo() 类对象(ClassName.class) 保护静态变量 同步代码块 synchronized (obj) {...} 任意对象 灵活控制锁粒度 1)同步代码块: class Counter { private int count = 0; private final Object lock = new Object(); public void increment() { synchronized (lock) { count++; System.out.println(Thread.currentThread().getName() + " -> " + count); } } } public class Demo { public static void main(String[] args) { Counter counter = new Counter(); Runnable task = counter::increment; new Thread(task, "A").start(); new Thread(task, "B").start(); } } 2)同步方法 class Counter { private int count = 0; public synchronized void increment() { count++; System.out.println(Thread.currentThread().getName() + " -> " + count); } } public class Test { public static void main(String[] args) { Counter c = new Counter(); for (int i = 0; i < 5; i++) { new Thread(c::increment).start(); } } } synchronized 修饰实例方法时,锁的是当前对象(this)。 同一个对象的同步方法是互斥的。 同一个对象(p1),T1 和 T2 都调用 p1.print(),因为 synchronized 锁的是 p1,所以 T1 和 T2 必须一个执行完,另一个才能进入方法。 不同对象(p2),T3 和 T4 调用的是另一个对象 p2.print() 因此,T1、T2 顺序执行,T3、T4 也顺序执行,它们之间互不影响。 Lambda表达式 函数式接口:有且仅有一个抽象方法的接口。 @FunctionalInterface 注解:这是一个可选的注解,用于表示接口是一个函数式接口。虽然不是强制的,但它可以帮助编译器识别意图,并检查接口是否确实只有一个抽象方法。 这个时候可以用Lambda代替匿名内部类!!! public class LambdaExample { // 定义函数式接口,doSomething 有两个参数 @FunctionalInterface interface MyInterface { void doSomething(int a, int b); } public static void main(String[] args) { // 使用匿名内部类实现接口方法 MyInterface obj = new MyInterface() { @Override public void doSomething(int a, int b) { System.out.println("参数a: " + a + ", 参数b: " + b); } }; obj.doSomething(5, 10); } public static void main(String[] args) { // 使用 Lambda 表达式实现接口方法 MyInterface obj = (a, b) -> { System.out.println("参数a: " + a + ", 参数b: " + b); }; obj.doSomething(5, 10); } } lambda表达式格式:(参数列表) -> { 代码块 }或 (参数列表) ->表达式 如果上述MyInterface接口的doSomething()方法不接受任何参数并且没有返回值: // Lambda 表达式(无参数) MyInterface obj = () -> { System.out.println("doSomething 被调用,无参数!"); }; 以下是lambda表达式的重要特征: 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。 可选的参数圆括号():一个参数无需定义圆括号,但无参数或多个参数需要定义圆括号。 可选的大括号{}:如果主体只有一个语句,可以不使用大括号。 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,使用大括号需显示retrun;如果函数是void则不需要返回值。 // 定义一个函数式接口,只有一个抽象方法 interface Calculator { int add(int a, int b); } public class LambdaReturnExample { public static void main(String[] args) { // 例子1:单个表达式,不使用大括号和 return 关键字 Calculator calc1 = (a, b) -> a + b; System.out.println("calc1: " + calc1.add(5, 3)); // 输出:8 // 例子2:使用大括号,需要显式使用 return 关键字 Calculator calc2 = (a, b) -> { return a + b; }; System.out.println("calc2: " + calc2.add(5, 3)); // 输出:8 } } 示例1: list.forEach这个方法接受一个函数式接口作为参数。它只有一个抽象方法 accept(T t)因此,可以使用 lambda 表达式来实现。 @FunctionalInterface public interface Consumer<T> { void accept(T t); } public class Main { public static void main(String[] args) { List<String> list = Arrays.asList("Apple", "Banana", "Cherry", "Date"); // 使用 Lambda 表达式迭代列表,这段 lambda,就是在“实现” void accept(String item) 这个方法——把每个元素传给 accept,然后打印它。 list.forEach(item -> System.out.println(item)); } } 示例2:为什么可以使用 Lambda 表达式自定义排序? 因为**Comparator<T> 是一个函数式接口**,只有一个抽象方法 compare(T o1, T o2) @FunctionalInterface public interface Comparator<T> { int compare(T o1, T o2); // 唯一的抽象方法 // 其他方法(如 thenComparing、reversed)都是默认方法或静态方法,不影响函数式接口特性 } public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("John", "Jane", "Adam", "Dana"); // 使用Lambda表达式排序 Collections.sort(names, (a, b) -> a.compareTo(b)); // 输出排序结果 names.forEach(name -> System.out.println(name)); } } JAVA面向对象 public class Dog { // 成员变量 private String name; // 构造函数 public Dog(String name) { this.name = name; } // 一个函数:让狗狗“叫” public void bark() { System.out.println(name + " says: Woof! Woof!"); } // (可选)获取狗狗的名字 public String getName() { return name; } // 测试主方法 public static void main(String[] args) { Dog myDog = new Dog("Buddy"); myDog.bark(); // 输出:Buddy says: Woof! Woof! System.out.println("Name: " + myDog.getName()); } } 访问修饰符 public(公共的): 使用public修饰的成员可以被任何其他类访问,无论这些类是否属于同一个包。 例如,如果一个类的成员被声明为public,那么其他类可以通过该类的对象直接访问该成员。 protected(受保护的): 使用protected修饰的成员可以被同一个包中的其他类访问,也可以被不同包中的子类访问。 与包访问级别相比,protected修饰符提供了更广泛的访问权限。 default (no modifier)(默认的,即包访问级别): 如果没有指定任何访问修饰符,则默认情况下成员具有包访问权限。 在同一个包中的其他类可以访问默认访问级别的成员,但是在不同包中的类不能访问。 private(私有的): 使用private修饰的成员只能在声明它们的类内部访问,其他任何类(子类也不行!)都不能访问这些成员。 这种访问级别提供了最高的封装性和安全性。 如果您在另一个类中实例化了包含私有成员的类,那么您无法直接访问该类的私有成员。但是,您可以通过公共方法来间接地访问和操作私有成员。 public class PrivateExample { private int privateVar = 30; // 公共方法,用于访问私有成员 public int getPrivateVar() { return privateVar; } } 则每个实例都有自己的一份拷贝,只有当变量被声明为 static 时,变量才是类级别的,会被所有实例共享。 修饰符不仅可以用来修饰成员变量和方法,也可以用来修饰类。顶级类只能使用 public 或默认(即不写任何修饰符,称为包访问权限)。内部类可以使用所有访问修饰符(public、protected、private 和默认),这使得你可以更灵活地控制嵌套类的访问范围。 public class OuterClass { // 内部类使用private,只能在OuterClass内部访问 private class InnerPrivateClass { // ... } // 内部类使用protected,同包以及其他包中的子类可以访问 protected class InnerProtectedClass { // ... } // 内部类使用默认访问权限,只在同包中可见 class InnerDefaultClass { // ... } // 内部类使用public,任何地方都可访问(但访问时需要通过OuterClass对象) public class InnerPublicClass { // ... } } JAVA三大特性 封装 封装指隐藏对象的状态信息(属性),不允许外部对象直接访问对象的内部信息(private实现)。但是可以提供一些可以被外界访问的方法(public)来操作属性。 优点:隐藏内部实现细节,提升安全性。 继承 [修饰符] class 子类名 extends 父类名{ 类体部分 } //class C extends A, B // 错误:C 不能同时继承 A 和 B Java只支持单继承,不支持多继承。一个类只能有一个父类,不可以有多个父类。 Java支持多层继承(A → B → C )。 Java继承了父类非私有的成员变量和成员方法,但是请注意:子类是无法继承父类的构造方法的。 优点:实现代码复用,减少重复代码。子类可以在继承基础上扩展或修改功能。 多态 指在面向对象编程中,同样的消息(方法调用)可以在不同的对象上触发不同的行为。 方法重写(Override):动态多态;子类从父类继承的某个实例方法无法满足子类的功能需要时,需要在子类中对该实例方法进行重新实现,这样的过程称为重写,也叫做覆写、覆盖。 要求: 必须存在继承关系(子类继承父类)。 子类重写的方法的访问修饰符不能比父类更严格(可以相同或更宽松)。 方法名、参数列表和返回值类型必须与父类中的方法完全相同(Java 5 以后支持协变返回类型,即允许返回子类型)。 向上转型(Upcasting):动态多态;子类对象可以赋值给父类引用,这样做可以隐藏对象的真实类型,只能调用父类中声明的方法。 class Animal { public void makeSound() { System.out.println("Animal makes sound"); } } class Dog extends Animal { @Override public void makeSound() { System.out.println("Dog barks"); } public void fetch() { System.out.println("Dog fetches the ball"); } } public class Test { public static void main(String[] args) { Animal animal = new Dog(); // 向上转型 animal.makeSound(); // 调用的是 Dog 重写的 makeSound() 方法 // animal.fetch(); // 编译错误:Animal 类型没有 fetch() 方法 } } 多态实现总结:继承 + 重写 + 父类引用指向子类对象 = 多态 方法重载(Overload):静态多态;方法名相同但参数列表不同。当调用这些方法时,会根据传递的参数类型或数量选择相应的方法。 参数类型不同;参数数量不同:参数顺序不同;返回类型可以不同,但仅返回类型不同不构成重载 void print(int a) { ... } void print(String a) { ... } // 合法重载 void log(String msg) { ... } void log(String msg, int level) { ... } // 合法重载 void save(int id, String name) { ... } void save(String name, int id) { ... } // 合法重载 优点:提高代码的灵活性和可扩展性。通过统一接口调用不同实现,提高可替换性。 继承与super关键字 类加载与对象实例化顺序 class Parent { static { System.out.println("A"); } Parent() { System.out.println("B"); } } class Child extends Parent { static { System.out.println("C"); } Child() { System.out.println("D"); } } 加载类时: A // 父类静态块先执行 C // 再执行子类静态块 实例化子类对象时: B // 父类构造函数先执行 D // 再执行子类构造函数 记忆口诀:静态先父后子,构造先父后子。(析构则相反,先子后父) new Child()的时候-> 输出顺序为 ACBD Super关键字 super 用于在子类中访问父类的内容: 1)访问父类的成员 当子类与父类存在同名成员时,子类中的成员会**隐藏(shadow)**父类的同名成员。可用 super 显式访问父类版本。 2)调用父类的构造方法 创建子类对象时,一定会先调用父类构造函数。若父类没有无参构造函数,则子类必须显式调用父类构造函数,否则编译报错。使用 super(参数) 调用父类构造方法。 示例: class Parent { int num = 10; Parent(int num) { this.num = num; System.out.println("Parent constructor: num = " + num); } void display() { System.out.println("Parent method"); } } class Child extends Parent { int num = 20; Child(int num) { super(num); // 调用父类构造函数 System.out.println("Child constructor: num = " + num); } void print() { System.out.println("Child num: " + num); // 子类字段 System.out.println("Parent num: " + super.num); // 父类字段 super.display(); // 调用父类方法 } } public class Main { public static void main(String[] args) { Child obj = new Child(30); System.out.println("---- 调用 print() ----"); obj.print(); } } 运行结果: Parent constructor: num = 30 Child constructor: num = 30 ---- 调用 print() ---- Child num: 20 Parent num: 30 Parent method 注意:若父类定义了构造函数(无论是否有参),编译器不会再自动生成默认无参构造函数。 如果父类仅有有参构造函数,子类必须显式调用 super(...) 来选择合适的父类构造函数。 如果有有参+无参,那子类可以不显示调用super(...),系统会自动帮你调用父类的无参构造函数。 抽象类 用 abstract 修饰的类,不能被实例化。可以包含抽象方法(无方法体)和具体方法(有实现)。抽象类可以实现接口,也可以继续保持抽象。 注意:抽象类可以一个抽象方法都没有。 abstract class Animal { public abstract void makeSound(); // 抽象方法 public void sleep() { // 普通方法 System.out.println("Sleeping..."); } } class Dog extends Animal { @Override public void makeSound() { System.out.println("Dog barks"); } } 如何使用抽象类 由于抽象类不能直接实例化,我们通常有两种方法来使用抽象类: 通过子类继承并实现抽象方法: Animal animal = new Dog(); animal.makeSound(); // 输出:Dog barks 使用匿名内部类 Animal a = new Animal() { @Override public void makeSound() { System.out.println("Anonymous sound"); } }; 如何算作实现抽象方法 抽象类的子类必须实现全部抽象方法,否则该子类也必须声明为抽象类。 实现接口时,可选择性实现方法,未实现的交由子类完成。 接口 一组行为规范或契约。接口中的变量默认是 public static final 常量。方法默认是 public abstract(Java 8 之后可包含 default 和 static 方法)。 interface SmartDevice { String DEFAULT_BRAND = "Generic"; void turnOn(); // 抽象方法 default void updateFirmware() { System.out.println("Updating firmware..."); } static void checkConnection() { System.out.println("Checking network..."); } } class SmartLight implements SmartDevice { @Override public void turnOn() { System.out.println("Light is on"); } } 接口特性 支持 多继承(一个类可以实现多个接口)。 接口之间可以使用 extends 继承。 默认方法(default)可提供接口级的默认实现。 抽象类 vs 接口 特性 抽象类 接口 关键字 abstract + class interface 实例化 ❌ 不能 ❌ 不能 方法类型 抽象 + 具体 抽象(默认)、默认方法、静态方法 变量 普通成员变量 public static final 常量 继承 extends(单继承) implements(多实现) 关系 可实现接口 可被类实现、可继承接口 适用场景 表示**“是什么”**(共性与实现) 表示**“能做什么”**(行为约定) 四种内部类 1.成员内部类 定义位置:成员内部类定义在外部类的成员位置。 访问权限:可以无限制地访问外部类的所有成员,包括私有成员、静态成员变量。 实例化方式:需要先创建外部类的实例,然后才能创建内部类的实例。 修改限制:不能有静态字段和静态方法(除非声明为常量final static)。成员内部类属于外部类的一个实例,不能独立存在于类级别上。 用途:适用于内部类与外部类关系密切,需要频繁访问外部类成员的情况。 public class Outer { private static int staticVar = 10; // 外部类静态变量 private int instanceVar = 20; // 外部类实例变量 // 非静态内部类 class Inner { void print() { System.out.println("静态变量: " + staticVar); // 直接访问外部类静态变量 System.out.println("实例变量: " + instanceVar); // 直接访问外部类实例变量 } } public static void main(String[] args) { Outer outer = new Outer(); Outer.Inner inner = outer.new Inner(); // 创建内部类实例 inner.print(); } } 易错题: class A { static class B { void hello() { System.out.println("hello from static A.B"); } } } class C implements A.B { public void hello() { System.out.println("hello from C"); } } 会编译报错,A.B 是一个 非静态内部类(inner class),它隐式地依赖外部类 A 的实例。 2.静态内部类 没有静态类,但是有静态内部类! 定义位置:定义在外部类内部,但使用static修饰。 访问权限:只能直接访问外部类的静态成员,访问非静态成员需要通过外部类实例。 实例化方式:可以直接创建,不需要外部类的实例。 修改限制:可以有自己的静态成员。 用途:适合当内部类工作不依赖外部类实例时使用,常用于实现与外部类关系不那么密切的帮助类。 public class Solution { // 外部类的静态成员 private static String author = "AlgoMaster"; // 外部类的实例成员 private int solveCount = 0; // 静态内部类:二叉树节点 public static class TreeNode { int val; TreeNode left, right; TreeNode(int val) { this.val = val; } public void showInfo() { // ✅ 可以直接访问外部类的静态成员 System.out.println("Created by: " + author); // ❌ 不能直接访问外部类的实例成员 // System.out.println("solveCount: " + solveCount); } // 算法函数:递归求最大深度 public int maxDepth(TreeNode root) { solveCount++; // 访问实例成员 if (root == null) return 0; return 1 + Math.max(maxDepth(root.left), maxDepth(root.right)); } // 测试 public static void main(String[] args) { // ✅ 静态内部类可以脱离外部类实例独立创建 TreeNode root = new TreeNode(1); root.left = new TreeNode(2); root.right = new TreeNode(3); root.left.left = new TreeNode(4); // 展示静态内部类对外部类成员的访问特性 root.showInfo(); // 使用外部类实例来跑算法 Solution sol = new Solution(); System.out.println("Max Depth: " + sol.maxDepth(root)); // 输出 3 } } 如果把辅助类直接写成顶级类,可能导致包里出现一堆“小工具类”。 把它们作为静态内部类放到外部类里,可以让代码结构更紧凑,命名更直观。 例子:在算法题里定义 TreeNode、ListNode 常作为 Solution 的静态内部类。 3.局部内部类 定义位置:局部内部类定义在一个方法或任何块内(如:if语句、循环语句内)。 访问权限:只能访问所在方法的final或事实上的final(即不被后续修改的)局部变量和外部类的成员变量(同成员内部类)。 实例化方式:只能在定义它们的块中创建实例。 修改限制:同样不能有静态字段和方法。 用途:适用于只在方法或代码块中使用的类,有助于将实现细节隐藏在方法内部。 public class OuterClass { public void startThread() { class LocalInnerClass implements Runnable { @override public void run() { System.out.println("局部内部类中的线程正在运行..."); } } LocalInnerClass localInner = new LocalInnerClass(); Thread thread = new Thread(localInner); thread.start(); } public static void main(String[] args) { OuterClass outer = new OuterClass(); outer.startThread(); } } 4.匿名内部类 new 父类/接口() { // 实现或重写方法 @Override void method() { ... } } 在定义的同时直接实例化,而不需要显式地声明一个子类的名称。 用途:适用于创建一次性使用的实例,通常用于接口或抽象类的实现。但匿名内部类并不限于接口或抽象类,只要是非 final 的普通类,都有机会通过匿名内部类来“现场”创建一个它的子类实例。 abstract class Animal { public abstract void makeSound(); } public class Main { public static void main(String[] args) { // 匿名内部类:临时创建一个 Animal 的子类并实例化 Animal dog = new Animal() { // 注意这里的 new Animal() { ... } @Override public void makeSound() { System.out.println("汪汪汪!"); } }; dog.makeSound(); // 输出:汪汪汪! } } 如何理解?可以对比普通子类(显式定义),即显示定义了Dog来继承Animal // 抽象类或接口 abstract class Animal { public abstract void makeSound(); } // 显式定义一个具名的子类 class Dog extends Animal { @Override public void makeSound() { System.out.println("汪汪汪!"); } } public class Main { public static void main(String[] args) { // 实例化具名的子类 Animal dog = new Dog(); dog.makeSound(); // 输出:汪汪汪! } } 容器 Collection 在 Java 中,Collection 是一个接口,它表示一组对象的集合。Collection 接口是 Java 集合框架中最基本的接口之一,定义了一些操作集合的通用方法,例如添加、删除、遍历等。 所有集合类(例如 List、Set、Queue 等)都直接或间接地继承自 Collection 接口。 boolean add(E e):将指定的元素添加到集合中(可选操作)。 boolean remove(Object o):从集合中移除指定的元素(可选操作)。 boolean contains(Object o):如果集合中包含指定的元素,则返回 true。 int size():返回集合中的元素个数。 void clear():移除集合中的所有元素。 boolean isEmpty():如果集合为空,则返回 true。 public class CollectionExample { public static void main(String[] args) { // 创建一个 Collection 对象,使用 ArrayList 作为实现类 Collection<String> fruits = new ArrayList<>(); // 添加元素到集合中 fruits.add("Apple"); fruits.add("Banana"); fruits.add("Cherry"); System.out.println("添加元素后集合大小: " + fruits.size()); // 输出集合大小 // 检查集合是否包含某个元素 System.out.println("集合中是否包含 'Banana': " + fruits.contains("Banana")); // 从集合中移除元素 fruits.remove("Banana"); System.out.println("移除 'Banana' 后集合大小: " + fruits.size()); // 清空集合 fruits.clear(); System.out.println("清空集合后,集合是否为空: " + fruits.isEmpty()); } } Iterator 在 Java 中,Iterator 是一个接口,遍历集合元素。Collection 接口中定义了 iterator() 方法,返回一个 Iterator 对象。 Iterator 接口中包含以下主要方法: hasNext():如果迭代器还有下一个元素,则返回 true,否则返回 false。 next():返回迭代器的下一个元素,并将迭代器移动到下一个位置。 remove():从迭代器当前位置删除元素。该方法是可选的,不是所有的迭代器都支持。 import java.util.ArrayList; import java.util.Iterator; public class Main { public static void main(String[] args) { // 创建一个 ArrayList 集合 ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); int size = list.size(); // 获取列表大小 System.out.println("Size of list: " + size); // 输出 3 // 获取集合的迭代器 Iterator<Integer> iterator = list.iterator(); // 使用迭代器遍历集合并输出元素 while (iterator.hasNext()) { Integer element = iterator.next(); System.out.println(element); } } } ArrayList ArrayList 是 List 接口的一种实现,而 List 接口又继承自 Collection 接口。包括 add()、remove()、contains() 等。 HashSet HashMap // 使用 entrySet() 方法获取 Map 中所有键值对的集合,并使用增强型 for 循环遍历键值对 System.out.println("Entries in the map:"); for (Map.Entry<String, Integer> entry : map.entrySet()) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println("Key: " + key + ", Value: " + value); } PriorityQueue 默认是小根堆,输出1,2,5,8 import java.util.PriorityQueue; public class Main { public static void main(String[] args) { // 创建一个 PriorityQueue 对象 PriorityQueue<Integer> pq = new PriorityQueue<>(); // 添加元素到队列 pq.offer(5); pq.offer(2); pq.offer(8); pq.offer(1); // 打印队列中的元素 System.out.println("Elements in the priority queue:"); while (!pq.isEmpty()) { System.out.println(pq.poll()); } } } offer() 方法用于将元素插入到队列中 poll() 方法用于移除并返回队列中的头部元素 peek() 方法用于返回队列中的头部元素但不移除它。 JAVA异常处理 public class ExceptionExample { // 方法声明中添加 throws 关键字,指定可能抛出的异常类型 public static void main(String[] args) throws SomeException, AnotherException { try { // 可能会抛出异常的代码块 if (someCondition) { throw new SomeException("Something went wrong"); } } catch (SomeException e) { // 处理 SomeException 异常 System.out.println("Caught SomeException: " + e.getMessage()); } catch (AnotherException e) { // 处理 AnotherException 异常 System.out.println("Caught AnotherException: " + e.getMessage()); } finally { // 不管是否发生异常,都会执行的代码块 System.out.println("End of try-catch block"); } } } // 自定义异常类,继承自 Exception 类 public class SomeException extends Exception { // 构造方法,用于设置异常信息 public SomeException(String message) { // 调用父类的构造方法,设置异常信息 super(message); } } JAVA泛型 在类、接口或方法定义时,用类型参数来替代具体的类型,编译时检查类型安全,运行时通过类型擦除映射到原始类型。 <T>: 用于 定义泛型类型。 在 类、接口、方法 的定义中,<T> 是用来指定一个占位符,表示这个类或方法可以接受任何类型。 T 在这里是 类型参数,你可以在类、接口或方法内使用它来代替具体的类型。 public class Box<T> { // <T> 定义了一个泛型类,T 是类型参数 private T value; // 使用 T 来表示某种类型 public void set(T value) { // 使用 T 来表示参数类型 this.value = value; } public T get() { // 使用 T 来表示返回类型 return value; } } 定义一个泛型类 // 定义一个“盒子”类,可以装任何类型的对象 public class Box<T> { private T value; public Box() {} public Box(T value) { this.value = value; } public void set(T value) { this.value = value; } public T get() { return value; } } T 是类型参数(Type Parameter),可任意命名(常见还有 E、K、V 等)。 使用: public class Main { public static void main(String[] args) { // 创建一个只装 String 的盒子 Box<String> stringBox = new Box<>(); stringBox.set("Hello Generics"); String s = stringBox.get(); // 自动类型推断为 String System.out.println(s); // 创建一个只装 Integer 的盒子 Box<Integer> intBox = new Box<>(123); Integer i = intBox.get(); System.out.println(i); } } 定义一个泛型方法 有时候我们只想让某个方法支持多种类型,而不必为此写泛型类,就可以在方法前加上类型声明: public class Utils { //[修饰符] <T> 返回类型 方法名(参数列表) { … } // 泛型方法:打印任意类型的一维数组 public static <T> void printArray(T[] array) { for (T element : array) { System.out.println(element); } } } 方法签名中 <T> 表示这是一个泛型方法,注意这里不是指返回值!!!这个返回值是void!!! 调用时,编译器会根据传入实参自动推断 T。 使用 public class Main { public static void main(String[] args) { String[] names = {"Alice", "Bob", "Charlie"}; Utils.printArray(names); // 等价于 Utils.<String>printArray(names); Integer[] nums = {10, 20, 30}; Utils.printArray(nums); // 等价于 Utils.<Integer>printArray(nums); } } 好用的方法 toString() **Arrays.toString()**转一维数组 **Arrays.deepToString()**转二维数组 这个方法是是用来将数组转换成String类型输出的,入参可以是long,float,double,int,boolean,byte,object 型的数组。 import java.util.Arrays; public class Main { public static void main(String[] args) { // 一维数组示例 int[] oneD = {1, 2, 3, 4, 5}; System.out.println("一维数组输出: " + Arrays.toString(oneD)); // 二维数组示例 int[][] twoD = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; // 使用 Arrays.deepToString() 输出二维数组 System.out.println("二维数组输出: " + Arrays.deepToString(twoD)); } } 自定义对象的toString() 方法 每个 Java 对象默认都有 toString() 方法(可以根据需要覆盖) 当直接打印一个没有重写 toString() 方法的对象时,其输出格式通常为: java.lang.Object@15db9742 当打印重写toString() 方法的对象时: class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{name='" + name + "', age=" + age + "}"; } } public class Main { public static void main(String[] args) { Person person = new Person("Alice", 30); System.out.println(person); //会自动调用对象的 toString() 方法 //Person{name='Alice', age=30} } } 对象拷贝属性 public void save(EmployeeDTO employeeDTO) { Employee employee = new Employee(); //对象属性拷贝 BeanUtils.copyProperties(employeeDTO, employee,"id"); } employeeDTO的内容拷贝给employee,跳过字段为"id"的属性。 StartOrStopDTO dto = new StartOrStopDTO(1, 100L); // 用 Builder 拷贝 id 和 status Employee employee = Employee.builder() .id(dto.getId()) .status(dto.getStatus()) .build(); Java 8 Stream API SpaceUserRole role = SPACE_USER_AUTH_CONFIG.getRoles() .stream() // 1 .filter(r -> r.getKey().equals(spaceUserRole)) // 2 .findFirst() // 3 .orElse(null); // 4 stream() 把 List<SpaceUserRole> 转换成一个 Stream<SpaceUserRole>,Stream 是 Java 8 引入的对集合进行函数式操作的管道。 .filter(r -> r.getKey().equals(spaceUserRole)) filter 接受一个 Predicate<T>(这里是从每个 SpaceUserRole r 中调用 r.getKey().equals(...)),只保留“满足该条件”的元素,其余都丢弃。 .findFirst() 在过滤后的流中,取第一个元素,返回一个 Optional<SpaceUserRole>。即使流是空的,它也会返回一个空的 Optional,而不会抛异常。 .orElse(null) 从 Optional 中取值:如果存在就返回该值,不存在就返回 null。 等价于下面的老式写法(Java 7 及以前): SpaceUserRole role = null; for (SpaceUserRole r : SPACE_USER_AUTH_CONFIG.getRoles()) { if (r.getKey().equals(spaceUserRole)) { role = r; break; } } 类加载器和获取资源文件路径 在Java中,类加载器的主要作用是根据**类路径(Classpath)**加载类文件以及其他资源文件。 启动类加载器(Bootstrap ClassLoader):加载 Java 运行时环境的核心类库,包括 Java 的标准库和 JVM 必须的类,比如 java.lang.* 包中的类。 扩展类加载器:加载 Java 扩展目录中的类库,这些库通常是 ext 目录中的 JAR 文件(例如,$JAVA_HOME/jre/lib/ext/)。 系统类加载器:加载应用程序的类路径(classpath)下的类和资源文件,通常用于加载项目中的类和 JAR 包。 自定义类加载器:这个类加载器是由开发者自定义实现的,用于加载非标准的类或动态加载类。它是 Java 提供的类加载机制的扩展,允许你根据特定需求来自定义类加载的行为。 双亲委派机制的基本原理: 双亲委派机制的核心思想是:一个类加载器在加载类时,首先将请求委托给它的父类加载器,只有当父类加载器无法加载该类时,当前加载器才会自己去加载。 原因: 1.避免类的重复加载 2.保证核心类的安全性,如 java.lang.Object 类等是 Java 核心类库的一部分,必须由启动类加载器(Bootstrap ClassLoader)加载。 类路径是JVM在运行时用来查找类文件和资源文件的一组目录或JAR包。在许多项目(例如Maven或Gradle项目)中,src/main/resources目录下的内容在编译时会被复制到输出目录(如target/classes),src/main/java 下编译后的 class 文件也会放到这里。 src/ ├── main/ │ ├── java/ │ │ └── com/ │ │ └── example/ │ │ └── App.java │ └── resources/ │ ├── application.yml │ └── static/ │ └── logo.png └── test/ ├── java/ │ └── com/ │ └── example/ │ └── AppTest.java └── resources/ └── test-data.json 映射到 target/ 后: target/ ├── classes/ ← 主代码和资源的输出根目录 │ ├── com/ │ │ └── example/ │ │ └── App.class ← 编译自 src/main/java/com/example/App.java │ ├── application.yml ← 复制自 src/main/resources/application.yml │ └── static/ │ └── logo.png ← 复制自 src/main/resources/static/logo.png └── test-classes/ ← 测试代码和测试资源的输出根目录 ├── com/ │ └── example/ │ └── AppTest.class ← 编译自 src/test/java/com/example/AppTest.java └── test-data.json ← 复制自 src/test/resources/test-data.json // 获取 resources 根目录下的 emp.xml 文件路径 String empFileUrl = this.getClass().getClassLoader().getResource("emp.xml").getFile(); // 获取 resources/static 目录下的 tt.img 文件路径 URL resourceUrl = getClass().getClassLoader().getResource("static/tt.img"); String ttImgPath = resourceUrl != null ? resourceUrl.getFile() : null; this.getClass():获取当前对象(即调用该代码的对象)的 Class 对象。 .getClassLoader():获取该 Class 对象的类加载器(ClassLoader)。 .getResource("emp.xml"):从类路径中获取名为 "emp.xml" 的资源,并返回一个 URL 对象,该 URL 对象指向 "emp.xml" 文件的位置。 .getFile():从 URL 对象中获取文件路径部分,即获取 "emp.xml" 文件的绝对路径字符串。 **类路径(Classpath)**是 Java 虚拟机(JVM)用于查找类文件和其他资源文件的一组路径。 是的,类加载器的主要作用之一确实是从类路径中加载类文件(.class 文件)以及其他资源(如图片、配置文件等)。在 Java 项目启动时,类加载器不仅会加载类文件,还会把这些类文件转换为 Java 程序可以使用的 Class 对象,并将它们放入 运行时数据区,即 方法区(Method Area) 和 堆区(Heap)。 反射 反射技术的关键之一是能够在 运行时动态加载 类的字节码并将其转换为 Class 对象,并以编程的方法解刨出类中的各个成分(成员变量、方法、构造器等)。 .class 是静态的文件,加载到内存并解析后,就会创建一个对应的 java.lang.Class 实例即 Class对象,是动态的。 反射技术例子:IDEA通过反射技术就可以获取到类中有哪些方法,并且把方法的名称以提示框的形式显示出来,所以你能看到这些提示了。 获取类的字节码(Class对象) 有三种方法: public class Test1Class{ public static void main(String[] args){ Class c1 = Student.class; System.out.println(c1.getName()); //获取全类名:edu.whut.pojo.Student System.out.println(c1.getSimpleName()); //获取简单类名: Student Class c2 = Class.forName("edu.whut.pojo.Student"); //全类名 System.out.println(c1 == c2); //true Student s = new Student(); Class c3 = s.getClass(); System.out.println(c2 == c3); //true } } 类的 Class 对象(字节码对象)是类的模具,不会直接存放数据。 类的 实例对象obj是用 new 出来的,它代表着 实际的运行时对象,会在堆(Heap)里开辟内存,存放实例字段的数据。每次 new 一下,就会有一个独立的实例,它们共享同一个 Class,但各自的数据独立。 1.获取类的元信息 类名:getName()、getSimpleName()、getPackage() 父类和接口:getSuperclass()、getInterfaces() 修饰符:getModifiers()(配合 Modifier 工具类解析 public、private、abstract 等) 注解:getAnnotation() / getAnnotations() 获取类上的注解!!! 2.获取类的构造器 定义类 public class Cat{ private String name; private int age; public Cat(){} private Cat(String name, int age){ } } 获取构造器列表 public class TestConstructor { @Test public void testGetAllConstructors() { // 1. 获取类的 Class 对象 Class<?> c = Cat.class; // 2. 获取类的全部构造器(包括public、private等) Constructor<?>[] constructors = c.getDeclaredConstructors(); // 3. 遍历并打印构造器信息 for (Constructor<?> constructor : constructors) { System.out.println( constructor.getName() + " --> 参数个数:" + constructor.getParameterCount() ); } } } c.getDeclaredConstructors() 会返回所有声明的构造器(包含私有构造器),而 c.getConstructors() 只会返回公共构造器。 constructor.getParameterCount() 用于获取该构造器的参数个数。 获取某个构造器:指定参数类型! public class Test2Constructor(){ @Test public void testGetConstructor(){ //1、反射第一步:必须先得到这个类的Class对象 Class c = Cat.class; /2、获取private修饰的有两个参数的构造器,第一个参数String类型,第二个参数int类型 Constructor constructor = c.getDeclaredConstructor(String.class,int.class); constructor.setAccessible(true); //禁止检查访问权限,可以使用private构造函数 Cat cat=(Cat)constructor.newInstance("叮当猫",3); //初始化Cat对象 } } c.getDeclaredConstructor(String.class, int.class):根据参数列表获取特定的构造器。 如果构造器是private修饰的,先需要调用setAccessible(true) 表示禁止检查访问控制,然后再调用newInstance(实参列表) 就可以执行构造器,完成对象的初始化了。 Constructor 本身就是用来创建对象实例的,它的职责是生成实例,而不是操作某个已经存在的实例。 3.获取类的成员变量 获取类的成员变量 方法 说明 public Field[] getFields() 获取类的全部成员变量(只能获取 public 修饰的) public Field[] getDeclaredFields() 获取类的全部成员变量(只要存在就能拿到) public Field getField(String name) 获取类的某个成员变量(只能获取 public 修饰的) public Field getDeclaredField(String name) 获取类的某个成员变量(只要存在就能拿到) 设置与获取字段值 方法 说明 void set(Object obj, Object value) 设置字段值 Object get(Object obj) 获取字段值 public void setAccessible(boolean flag) 设置为 true,表示禁止检查访问控制(暴力反射) 不管是设置值还是获取值,都需要: 获取 Field 对象 —— 先通过 Class 对象拿到目标字段的 Field 实例。 指定目标实例 —— 操作字段时必须传入具体的对象实例,告诉 JVM 要修改或读取哪一个对象的该字段。 处理访问权限 —— 如果字段是私有的,需要调用 setAccessible(true) 来关闭 Java 的访问检查(俗称“暴力反射”)。 import java.lang.reflect.Field; public class ReflectionExample { // 示例类 public static class MyClass { public String publicField = "Public Field"; private String privateField = "Private Field"; } public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException { // 创建 MyClass 的实例 MyClass obj = new MyClass(); // 获取 MyClass 的 Class 对象 Class<?> clazz = obj.getClass(); // 获取 public 字段 Field publicField = clazz.getField("publicField"); System.out.println("Public Field: " + publicField.get(obj)); // 获取并输出 publicField 的值 // 获取 private 字段(使用 getDeclaredField) Field privateField = clazz.getDeclaredField("privateField"); // 设置私有字段为可访问(通过 setAccessible) privateField.setAccessible(true); System.out.println("Private Field: " + privateField.get(obj)); // 获取并输出 privateField 的值 // 修改 private 字段的值 privateField.set(obj, "New Private Value"); System.out.println("Updated Private Field: " + privateField.get(obj)); // 获取修改后的值 } } 4.获取类的成员方法 获取单个指定的成员方法:第一个参数填方法名、第二个参数填方法中的参数类型 执行:第一个参数传入一个对象实例,然后是若干方法参数(无参可不写)... 示例:Cat 类与测试类 public class Cat { private String name; public int age; public Cat() { this.name = "Tom"; this.age = 1; } public void meow() { System.out.println("Meow! My name is " + this.name); } private void purr() { System.out.println("Purr... I'm a happy cat!"); } } public class FieldReflectionTest { @Test public void testMethodAccess() throws Exception { // 1. 获取 Cat 类的 Class 对象 Class<?> catClass = Cat.class; // 2. 创建 Cat 对象实例 Cat cat = new Cat(); // ---------------------- // A. 获取并调用 public 方法 // ---------------------- // 获取名为 "meow"、无参数的方法 Method meowMethod = catClass.getMethod("meow"); // 调用该方法 meowMethod.invoke(cat); // ---------------------- // B. 获取并调用 private 方法 // ---------------------- // 获取名为 "purr"、无参数的私有方法 Method purrMethod = catClass.getDeclaredMethod("purr"); purrMethod.setAccessible(true); // 关闭权限检查 purrMethod.invoke(cat); } } 注解 在 Java 中,注解用于给程序元素(类、方法、字段等)添加元数据,这些元数据可被编译器、工具或运行时反射读取,以实现配置、检查、代码生成以及框架支持(如依赖注入、AOP 等)功能,而不直接影响代码的业务逻辑。 比如:Junit框架的 @Test 注解可以用在方法上,用来标记这个方法是测试方法,被@Test标记的方法能够被Junit框架执行。 再比如:@Override 注解可以用在方法上,用来标记这个方法是重写方法,被@Override注解标记的方法能够被IDEA识别进行语法检查。 使用注解 元注解 是修饰注解的注解。 @Retention(RetentionPolicy.SOURCE) //只在源码阶段保留,编译后 `.class` 文件中不会有这个注解信息。 @Retention(RetentionPolicy.RUNTIME) //指定注解的生命周期,即在运行时有效,可用于反射等用途。 @Target(ElementType.TYPE) //类上的注解(包含类、接口、枚举等类型) @Target(ElementType.METHOD) //方法上的注解 @Target(ElementType.FIELD) //字段上的注解 注意,若想在运行时通过反射读取,只能设置@Retention(RetentionPolicy.RUNTIME) 定义注解 使用 @interface 定义注解 // 定义注解 @Retention(RetentionPolicy.RUNTIME) // 生命周期:运行时保留,可反射获取 @Target(ElementType.METHOD) // 目标:作用于方法 public @interface MyAnnotation { String description() default "This is a default description"; int value() default 0; } 用法: // 1. 只传 value,可省略属性名 @MyAnnotation(5) public void someMethod() {} // 2. 多属性赋值必须指明名称 @MyAnnotation(value = 5, description = "Specific description") public void anotherMethod() {} // 3. 使用默认值 @MyAnnotation public void defaultMethod() {} 解析注解 在 Java 中,注解本质上是类的元数据,要在运行时获取注解信息,必须依赖反射 API 来读取。 下面示例展示了如何通过反射获取方法上的自定义注解 @MyAnnotation。 1.定义示例类与注解 // 自定义注解 @Retention(RetentionPolicy.RUNTIME) // 运行时保留,可反射获取 @Target(ElementType.METHOD) // 仅可作用于方法 public @interface MyAnnotation { String value(); } // 使用注解 public class MyClass { @MyAnnotation(value = "specific value") public void myMethod() { // 方法实现 } } 2.通过反射获取注解 import java.lang.reflect.Method; public class AnnotationReader { public static void main(String[] args) throws NoSuchMethodException { // 获取MyClass的Class对象 Class<MyClass> obj = MyClass.class; // 获取myMethod方法的Method对象 Method method = obj.getMethod("myMethod"); // 获取方法上的MyAnnotation注解实例 MyAnnotation annotation = method.getAnnotation(MyAnnotation.class); if (annotation != null) { // 输出注解的value值 System.out.println("注解的value: " + annotation.value()); } } } // 反射调用链: // Class → 通过类加载器获取类的运行时描述对象; // Method → 从 Class 对象中获取方法的反射对象; // getAnnotation() → 从方法反射对象中获取注解实例。 3.快速判断注解是否存在 if (method.isAnnotationPresent(MyAnnotation.class)) { // 如果存在MyAnnotation注解,则执行相应逻辑 } Junit 单元测试 步骤 1.导入依赖 将 JUnit 框架的 jar 包添加到项目中(注意:IntelliJ IDEA 默认集成了 JUnit,无需手动导入)。 2.编写测试类 为待测业务方法创建对应的测试类。 测试类中定义测试方法,要求方法必须为 public 且返回类型为 void。 3.添加测试注解 在测试方法上添加 @Test 注解,确保 JUnit 能自动识别并执行该方法。 4.运行测试 在测试方法上右键选择“JUnit运行”。 测试通过显示绿色标志; 测试失败显示红色标志。 public class UserMapperTest { @Test public void testListUser() { UserMapper userMapper = new UserMapper(); List<User> list = userMapper.list(); Assert.assertNotNull("User list should not be null", list); list.forEach(System.out::println); } } 注意,如果需要使用依赖注入,需要在测试类上加@SpringBootTest注解 它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如自动装配、依赖注入、配置加载等 @RunWith(SpringRunner.class) @SpringBootTest public class UserMapperTest { @Autowired private UserMapper userMapper; @Test public void testListUser() { List<User> list = userMapper.list(); Assert.assertNotNull("User list should not be null", list); list.forEach(System.out::println); } } 写了@Test注解,那么该测试函数就可以直接运行!若一个测试类中写了多个测试方法,可以全部执行! 原理可能是: //自定义注解 @Retention(RetentionPolicy.RUNTIME) //指定注解在运行时可用,这样才能通过反射获取到该注解。 @Target(ElementType.METHOD) //指定注解可用于方法上。 public @interface MyTest { } public class AnnotationTest4 { @MyTest public void test() { System.out.println("===test4==="); } public static void main(String[] args) throws Exception { AnnotationTest4 instance = new AnnotationTest4(); // 1. 获取 Class 对象 Class<?> clazz = AnnotationTest4.class; // 2. 获取类中声明的所有方法 Method[] methods = clazz.getDeclaredMethods(); // 3. 遍历方法,执行带 @MyTest 的方法 for (Method method : methods) { if (method.isAnnotationPresent(MyTest.class)) { method.invoke(instance); // 反射调用方法 } } } } 在Springboot中,如何快速生成单元测试? 选中类名,右键: JAVA笔试题总结 1)构造函数用于初始化当前类的对象,不能被继承。子类会调用父类的构造函数(通过 super),但这不是继承。 2)try-finally public static int func() { try { return 1; // 这个返回值被"吞噬" } finally { return 0; // 这个返回值覆盖了try中的值 } } // 结果: 返回 0 因此极不推荐在 finally 中使用 return 3)关于 Java 的包和部署,下列说法正确的是(单选题)? A. Java 虚拟机在使用 JAR 的 class 之前必须先将其解压缩 B. 编译包中的类时,完整名称必须和目录结构一致 C. 同一源文件中的不同类可以放到不同的包中 D. JAR 是保存 .class 文件的标准目录 解析: A 错误:JVM 可以直接读取 JAR 中的 .class 文件,无需解压(JAR 本质是 ZIP 格式,JVM 能直接加载)。 B 正确:Java 要求包名必须与文件目录结构完全匹配(例如 com.example.Test需放在 com/example/Test.java中),否则编译失败。 C 错误:同一 .java 源文件中的多个类默认属于同一个包,且只能有一个 public 类,不能拆分到不同包中。 D 错误:JAR 是压缩文件(归档格式),不是标准目录;标准目录是文件系统本身的文件夹结构。
后端学习
zy123
1年前
0
16
0
2025-03-21
微服务
微服务 踩坑总结 Mybatis-PLUS 分页不生效,因为mybatis-plus自3.5.9起,默认不包含分页插件,需要自己引入。 <dependencyManagement> <dependencies> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-bom</artifactId> <version>3.5.9</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <!-- MyBatis Plus 分页插件 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-jsqlparser-4.9</artifactId> </dependency> config包下新建: @Configuration @MapperScan("edu.whut.smilepicturebackend.mapper") public class MybatisPlusConfig { /** * 拦截器配置 * * @return {@link MybatisPlusInterceptor} */ @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); // 分页插件 interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); return interceptor; } } 雪花算法表示精度问题 “雪花算法”(Snowflake)生成的 ID 本质上是一个 64 位的整数(Java等后端里通常对应 long ),而浏览器端的 JavaScript Number 类型只能安全地表示到 2^53−1 以内的整数,超出这个范围就会出现 “精度丢失”──即低位那几位数字可能会被四舍五入掉,导致 ID 读取或比对出错。因此,最佳实践是: 后端依然用 long(或等价的 64 位整数)存储和处理雪花 ID。 对外接口(REST/graphQL 等)返回时,将这类超出 JS 安全范围的整数序列化为字符串,比如: @Configuration public class JacksonConfig { private static final String DATE_FORMAT = "yyyy-MM-dd"; private static final String DATETIME_FORMAT = "yyyy-MM-dd HH:mm:ss"; private static final String TIME_FORMAT = "HH:mm:ss"; @Bean public Jackson2ObjectMapperBuilderCustomizer jacksonCustomizer() { return builder -> { // 将所有 long / Long 类型序列化成 String SimpleModule longToString = new SimpleModule(); longToString.addSerializer(Long.class, ToStringSerializer.instance); longToString.addSerializer(Long.TYPE, ToStringSerializer.instance); builder.modules(longToString); }; } } 包扫描问题(非常容易出错!) 以 Spring Boot 为例,框架默认会扫描启动类所在包及其子包中的组件(@Component/@Service/@Repository/@Configuration 等),将它们注册到 Spring 容器中。 问题:当你把某些业务组件、配置类或第三方模块放在了启动类的同级或平级包下(而非子包),却没有手动指定扫描路径,就会出现 “无法注入 Bean” 的情况。 // 启动类 @SpringBootApplication public class OrderServiceApplication { … } // 业务类位于 com.example.common 包 @Service public class PaymentClient { … } 如果项目结构是: com.example.orderservice ← 启动类 com.example.common ← 依赖组件 默认情况下 com.example.common 不会被扫描到,导致注入 PaymentClient 时抛出 NoSuchBeanDefinitionException。 解决方案: 1)显式指定扫描路径**: @SpringBootApplication @ComponentScan(basePackages = { "com.example.orderservice", "com.example.common" }) public class OrderServiceApplication { … } 2)使用 @Import 或者 Spring Cloud 的自动配置机制(如编写 spring.factories,让依赖模块自动装配)。 数据库连接池 为什么需要? 每次通过 JDBC 调用 DriverManager.getConnection(...),都要完成网络握手、权限验证、初始化会话等大量开销,通常耗时在几十到几百毫秒不等。连接池通过提前建立好 N 条物理连接并在应用各处循环复用,避免了反复的开销。 流程 数据库连接池在应用启动时预先创建一定数量的物理连接,并将它们保存在空闲队列中;当业务需要访问数据库时,直接从池中“借用”一个连接(无需新建),用完后调用 close() 即把它归还池中;池会根据空闲超时或最大寿命策略自动回收旧连接,并在借出或定期扫描时执行简单心跳(如 SELECT 1)来剔除失效连接,确保始终有可用、健康的连接供高并发场景下快速复用。 ┌─────────────────────────────────────────┐ │ 应用线程 A 调用 getConnection() │ │ ┌──────────┐ ┌─────────────┐ │ │ │ 空闲连接队列 │──取出──▶│ 物理连接 │───┐│ │ └──────────┘ └─────────────┘ ││ │ (代理包装) ││ │ 返回代理连接给业务代码 ││ └─────────────────────────────────────────┘ │ │ ┌─────────────────────────────────────────┐ │ │ 业务执行 SQL,最后调用 close() │ │ ┌───────────────┐ ┌────────────┐ │ │ │ 代理 Connection │──归还──▶│ 空闲连接队列 │◀─────┘ │ └───────────────┘ └────────────┘ └─────────────────────────────────────────┘ 当你从连接池里拿到一个底层已被远程关闭的连接时,HikariCP(以及大多数成熟连接池)会在“借出”前先做一次简易校验(默认为 Connection.isValid(),或你配置的 connection-test-query)。如果校验失败,连接池会自动将这条“死”连接销毁,并尝试从池里或新建一个新的物理连接来替换,再把新的健康连接返给业务;只有当新的连接也创建或校验失败到达池的最大重试次数时,才会抛出拿不到连接的超时异常。 遇到的问题 如果本地启动了 Java 应用和前端 Nginx,而 MySQL 部署在远程服务器上,Java 应用通过连接池与远程数据库建立的 TCP 连接在 5 分钟内若无任何 SQL 操作,就会因中间网络设备(如 NAT、负载均衡器、防火墙)超时断开,且应用层不会主动感知,导致后续 SQL 请求失败。 13:20:01:383 WARN 43640 --- [nio-8084-exec-4] com.zaxxer.hikari.pool.PoolBase : HikariPool-1 - Failed to validate connection com.mysql.cj.jdbc.ConnectionImpl@36e971ae (No operations allowed after connection closed.). Possibly consider using a shorter maxLifetime value. 13:20:01:384 ERROR 43640 --- [nio-8084-exec-4] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException: ### Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30048ms. 为了解决这个问题, 1.只需在 Spring Boot 配置中为 HikariCP 添加定期心跳,让连接池在真正断连前保持流量: spring: datasource: hikari: keepalive-time: 180000 # 3 分钟发送一次心跳(维持 TCP 活跃) 这样,HikariCP 会每隔 3 分钟自动对空闲连接执行轻量级的验证操作(如 Connection.isValid()),确保中间网络链路不会因长时间静默而被强制关闭。 2.如果JAVA应用和Mysql在同一服务器上(可互通),就不会有上述问题! Sentinel无数据 sentinel 控制台可以发现哪些微服务连接了,但是Dashboard 在尝试去拿各个微服务上报的规则(端点 /getRules)和指标(端点 /metric)时,一直连不上它们,因为JAVA微服务是在本地私网内部署的,Dashboard无法连接上。 Failed to fetch metric from http://192.168.0.107:8725/metric?… Failed to fetch metric from http://192.168.0.107:8721/metric?… HTTP request failed: http://192.168.0.107:8721/getRules?type=flow java.net.ConnectException: Operation timed out 解决办法: 1.将JAVA应用部署到服务器,但我的服务器内存不够 2.将Dashboard部署到本机docker中,和JAVA应用可互通。 Nacos迁移后的 No DataSource set 原本Nacos和Mysql都是部署到公网服务器,mysql容器对外暴露3307,因此Nacos的env文件中可以是: MYSQL_SERVICE_DB_NAME=124.xxx.xxx.xxx MYSQL_SERVICE_PORT=3307 填的mysql的公网ip,以及它暴露的端口3307,这是OK的 但是如果将它们部署在docker同一网络中,应该这样写: MYSQL_SERVICE_DB_NAME=mysql MYSQL_SERVICE_PORT=3306 mysql是服务名,不能写localhost(或 127.0.0.1),它永远只会指向「当前容器自己」!!! 注意,Nacos中的配置文件也要迁移过来,导入nacos配置列表中,并且修改JAVA项目中nacos的地址 Docker Compose问题 1)如果你把某个服务从 docker-compose.yml 里删掉,然后再执行: docker compose down 默认情况下 并不会 停止或删除那个已经“离开”了 Compose 配置的容器。 只能: docker compose down --remove-orphans #清理这些“孤儿”容器 或者手动清理: docker ps #列出容器 docker stop <container_id_or_name> docker rm <container_id_or_name> 2)端口占用问题 Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:5672 -> 0.0.0.0:0: listen tcp 0.0.0.0:5672: bind: An attempt was made to access a socket in a way forbidden by its access permissions. 先查看是否端口被占用: netstat -aon | findstr 5672 如果没有被占用,那么就是windows的bug,在CMD使用管理员权限重启NAT网络服务即可 net stop winnat net start winnat 3)ip地址问题 seata-server: image: seataio/seata-server:1.5.2 container_name: seata-server restart: unless-stopped depends_on: - mysql - nacos environment: # 指定 Seata 注册中心和配置中心地址 - SEATA_IP=192.168.10.218 # IDEA 可以访问到的宿主机 IP - SEATA_SERVICE_PORT=17099 - SEATA_CONFIG_TYPE=file # 可视情况再加:SEATA_NACOS_SERVER_ADDR=nacos:8848 networks: - hmall-net ports: - "17099:7099" # TC 服务端口 - "8099:8099" # 服务管理端口(Console) volumes: - ./seata:/seata-server/resources SEATA_IP配置的是宿主机IP,你的电脑换了IP,如从教室到寝室,那这里的IP也要跟着变:ipconfig查看宿主机ip 认识微服务 微服务架构,首先是服务化,就是将单体架构中的功能模块从单体应用中拆分出来,独立部署为多个服务。 SpringCloud 使用Spring Cloud 2021.0.x以及Spring Boot 2.7.x版本(需要对应)。 在父pom中的<dependencyManagement>锁定版本,使得后续你在子模块里引用 Spring Cloud 或 Spring Cloud Alibaba 的各个组件时,不需要再写 <version>,Maven 会统一采用你在父 POM 中指定的版本。 微服务拆分 微服务拆分时: 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖,或者依赖接口的稳定性要强。 一般微服务项目有两种不同的工程结构: 完全解耦:每一个微服务都创建为一个独立的工程,甚至可以使用不同的开发语言来开发,项目完全解耦。 优点:服务之间耦合度低 缺点:每个项目都有自己的独立仓库,管理起来比较麻烦 Maven聚合:整个项目为一个Project,然后每个微服务是其中的一个Module 优点:项目代码集中,管理和运维方便 缺点:服务之间耦合,编译时间较长 ,每个模块都要有:pom.xml application.yml controller service mapper pojo 启动类 IDEA配置小技巧 1.自动导包 2.配置service窗口,以显示多个微服务启动类 3.如何在idea中虚拟多服务负载均衡? More options->Add VM options -> -Dserver.port=xxxx 这边设置不同的端口号! 服务注册和发现 注册中心、服务提供者、服务消费者三者间关系如下: 流程如下: 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署) 调用者自己对实例列表负载均衡,挑选一个实例 调用者向该实例发起远程调用 当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢? 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求) 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表 当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表(防止服务调用者继续调用挂逼的服务) Nacos部署: 1.依赖mysql中的一个数据库 ,可由nacos.sql初始化 2.需要.env文件,配置和数据库的连接信息: PREFER_HOST_MODE=hostname MODE=standalone SPRING_DATASOURCE_PLATFORM=mysql MYSQL_SERVICE_HOST=124.71.159.*** MYSQL_SERVICE_DB_NAME=nacos MYSQL_SERVICE_PORT=3307 MYSQL_SERVICE_USER=root MYSQL_SERVICE_PASSWORD=******* MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai 3.docker部署: nacos: image: nacos/nacos-server:v2.1.0 container_name: nacos-server restart: unless-stopped env_file: - ./nacos/custom.env # 自定义环境变量文件 ports: - "8848:8848" # Nacos 控制台端口 - "9848:9848" # RPC 通信端口 (TCP 长连接/心跳) - "9849:9849" # gRPC 通信端口 networks: - hm-net depends_on: - mysql volumes: - ./nacos/init.d:/docker-entrypoint-init.d # 如果需要额外初始化脚本,可选 启动完成后,访问地址:http://ip:8848/nacos/ 初始账号密码都是nacos 服务注册 1.在item-service的pom.xml中添加依赖: <!--nacos 服务注册发现--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> 2.配置Nacos 在item-service的application.yml中添加nacos地址配置: spring: application: name: item-service #服务名 cloud: nacos: server-addr: 124.71.159.***:8848 # nacos地址 注意,服务注册默认连9848端口!云服务需要开启该端口! 配置里的item-service就是服务名! 多个实例注册 version: '3' services: item-service-1: image: item-service container_name: item-service-1 environment: - spring.application.name=item-service - nacos.server-addr=124.71.159.***:8848 ports: - "8081:8080" # 映射端口 8081 item-service-2: image: item-service container_name: item-service-2 environment: - spring.application.name=item-service - nacos.server-addr=124.71.159.***:8848 ports: - "8082:8080" # 映射端口 8082 item-service-1 和 item-service-2 都会向 Nacos 注册为名为 item-service 的服务实例,但它们是不同的容器实例,具有不同的端口和 instanceId。 这样就能实现多实例部署,可以负载均衡了。 服务发现 前两步同服务注册 3.通过 DiscoveryClient 发现服务实例列表,然后通过负载均衡算法,选择一个实例去调用 discoveryClient发现服务 + restTemplate远程调用 @Service public class CartServiceImpl { @Autowired private DiscoveryClient discoveryClient; // 注入 DiscoveryClient @Autowired private RestTemplate restTemplate; // 用于发 HTTP 请求 private void handleCartItems(List<CartVO> vos) { // 1. 获取商品 id 列表 Set<Long> itemIds = vos.stream() .map(CartVO::getItemId) .collect(Collectors.toSet()); // 2.1. 发现 item-service 服务的实例列表 List<ServiceInstance> instances = discoveryClient.getInstances("item-service"); // 2.2. 负载均衡:随机挑选一个实例 ServiceInstance instance = instances.get( RandomUtil.randomInt(instances.size()) ); // 2.3. 发送请求,查询商品详情 String url = instance.getUri().toString() + "/items?ids={ids}"; ResponseEntity<List<ItemDTO>> response = restTemplate.exchange( url, HttpMethod.GET, null, new ParameterizedTypeReference<List<ItemDTO>>() {}, String.join(",", itemIds) ); // 2.4. 处理结果 if (response.getStatusCode().is2xxSuccessful()) { List<ItemDTO> items = response.getBody(); // … 后续处理 … } else { throw new RuntimeException("查询商品失败: " + response.getStatusCode()); } } } OpenFeign 让远程调用像本地方法调用一样简单 快速入门 1.引入依赖 <!--openFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <!--负载均衡器--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> 2.启用OpenFeign 在服务调用者cart-service的CartApplication启动类上添加注解: @EnableFeignClients 3.编写OpenFeign客户端 在cart-service中,定义一个新的接口,编写Feign客户端: @FeignClient("item-service") public interface ItemClient { @GetMapping("/items") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); } queryItemByIds这个方法名可以随便取,但@GetMapping("/items") 和 @RequestParam("ids") 要跟 item-service 服务中实际暴露的接口路径和参数名保持一致(直接参考服务提供者的Controller层对应方法对应即可); 一个客户端对应一个服务,可以在ItemClient里面写多个方法。 4.使用 List<ItemDTO> items = itemClient.queryItemByIds(Arrays.asList(1L, 2L, 3L)); Feign 会帮你把 ids=[1,2,3] 序列化成一个 HTTP GET 请求,URL 形如: GET http://item-service/items?ids=1&ids=2&ids=3 连接池 Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括: HttpURLConnection:默认实现,不支持连接池 Apache HttpClient :支持连接池 OKHttp:支持连接池 这里用带有连接池的HttpClient 替换默认的 1.引入依赖 <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> </dependency> 2.开启连接池 feign: httpclient: enabled: true # 使用 Apache HttpClient(默认关闭) 重启服务,连接池就生效了。 最佳实践 如果拆分了交易微服务(trade-service),它也需要远程调用item-service中的根据id批量查询商品功能。这个需求与cart-service中是一样的。那么会再次定义ItemClient接口导致重复编程。 思路1:抽取到微服务之外的公共module,需要调用client就引用该module的坐标。 思路2:每个微服务自己抽取一个module,比如item-service,将需要共享的domain实体放在item-dto模块,需要供其他微服务调用的cilent放在item-api模块,自己维护自己的,然后其他微服务引入maven坐标直接使用。 大型项目思路2更清晰、更合理。但这里选择思路1,方便起见。 拆分之后重启报错:Parameter 0 of constructor in com.hmall.cart.service.impl.CartServiceImpl required a bean of type 'com.hmall.api.client.ItemClient' that could not be found. 是因为:Feign Client 没被扫描到,Spring Boot 默认只会在主应用类所在包及其子包里扫描 @FeignClient。 需要额外设置basePackages package com.hmall.cart; @MapperScan("com.hmall.cart.mapper") @EnableFeignClients(basePackages= "com.hmall.api.client") @SpringBootApplication public class CartApplication { public static void main(String[] args) { SpringApplication.run(CartApplication.class, args); } } 网关 在微服务拆分后的联调过程中,经常会遇到以下问题: 不同业务数据分布在各自微服务,需要维护多套地址和端口,调用繁琐且易错; 前端无法直接访问注册中心(如 Nacos),无法实时获取服务列表,导致接口切换不灵活。 此外,单体架构下只需完成一次登录与身份校验,所有业务模块即可共享用户信息;但在微服务架构中: 每个微服务是否都要重复实现登录校验和用户信息获取? 服务间调用时,如何安全、可靠地传递用户身份? 通过引入 API 网关,我们可以在统一入口处解决以上问题:它提供动态路由与负载均衡,前端只需调用一个地址;它与注册中心集成,实时路由调整;它还在网关层集中完成登录鉴权和用户信息透传,下游服务无需重复实现安全逻辑。 快速入门 网关本身也是一个独立的微服务,因此也需要创建一个模块开发功能。大概步骤如下: 创建网关微服务 引入 SpringCloudGateway 、NacosDiscovery依赖 编写启动类 配置网关路由 1.依赖引入: <!-- 网关 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!-- Nacos Discovery --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- 负载均衡 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> 2.配置网关路由 id:给这条路由起个唯一的标识,方便你在日志、监控里看是哪个规则。(最好和服务名一致) uri: lb://xxx:xxx 必须和服务注册时的名字一模一样(比如 Item-service 或全大写 ITEM-SERVICE,取决于你在微服务启动时 spring.application.name 配置) server: port: 8080 spring: application: name: gateway cloud: nacos: server-addr: 192.168.150.101:8848 gateway: routes: - id: item # 路由规则id,自定义,唯一 uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表 predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务 - Path=/items/**,/search/** # 支持多个路径模式,用逗号隔开 - id: cart uri: lb://cart-service predicates: - Path=/carts/** - id: user uri: lb://user-service predicates: - Path=/users/**,/addresses/** - id: trade uri: lb://trade-service predicates: - Path=/orders/** - id: pay uri: lb://pay-service predicates: - Path=/pay-orders/** predicates:路由断言,其实就是匹配条件 After 是某个时间点后的请求 - After=2037-01-20T17:42:47.789-07:00[America/Denver] Before 是某个时间点之前的请求 - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] Path 请求路径必须符合指定规则 - Path=/red/{segment},/blue/** 如果(predicates)符合这些规则,就把请求送到(uri)这里去。 Ant风格路径 用来灵活地匹配文件或请求路径: ?:匹配单个字符(除了 /)。 例如,/user/??/profile 能匹配 /user/ab/profile,但不能匹配 /user/a/profile 或 /user/abc/profile。 *:匹配任意数量的字符(零 个或 多个),但不跨越路径分隔符 /。 例如,/images/*.png 能匹配 /images/a.png、/images/logo.png,却不匹配 /images/icons/logo.png。 **:匹配任意层级的路径(可以跨越多个 /)。 例如,/static/** 能匹配 /static/、/static/css/style.css、/static/js/lib/foo.js,甚至 /static/a/b/c/d。 AntPathMatcher 是 Spring Framework 提供的一个工具类,用来对“Ant 风格”路径模式做匹配 @Component @ConfigurationProperties(prefix = "auth") public class AuthProperties { private List<String> excludePaths; // getter + setter } @Component public class AuthInterceptor implements HandlerInterceptor { private final AntPathMatcher pathMatcher = new AntPathMatcher(); private final List<String> exclude; public AuthInterceptor(AuthProperties props) { this.exclude = props.getExcludePaths(); } @Override public boolean preHandle(HttpServletRequest req, HttpServletResponse res, Object handler) { String path = req.getRequestURI(); // e.g. "/search/books/123" // 检查是否匹配任何一个“放行”模式 for (String pattern : exclude) { if (pathMatcher.match(pattern, path)) { return true; // 放行,不做 auth } } // 否则执行认证逻辑 // ... return false; } } 当然 predicates: - Path=/users/**,/addresses/** 这里不需要手写JAVA逻辑进行路径匹配,因为Gateway自动实现了。但是后面自定义Gateway过滤器的时候就需要AntPathMatcher了! 登录校验 我们需要实现一个网关过滤器,有两种可选: GatewayFilter:路由过滤器,作用范围比较灵活,可以是任意指定的路由Route. GlobalFilter:全局过滤器,作用范围是所有路由,不可配置。 网关需要实现两个功能: JWT 校验:网关会拦截请求,验证 JWT Token 的有效性。如果 Token 无效,返回 401 错误。如果 Token 有效,提取用户 ID,并将其作为请求头的一部分传递给微服务。 传递用户信息:网关将 user-info(用户 ID)传递给微服务。微服务的拦截器会从请求头中获取并保存用户信息到 ThreadLocal,后续代码可以方便地获取。 网关过滤器 - JWT 校验 + 用户信息传递 @Component @RequiredArgsConstructor public class AuthGlobalFilter implements GlobalFilter, Ordered { private final JwtTool jwtTool; private final AuthProperties authProperties; private final AntPathMatcher antPathMatcher = new AntPathMatcher(); @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { // 获取请求 ServerHttpRequest request = exchange.getRequest(); // 判断是否不需要拦截 if (isExclude(request.getPath().toString())) { return chain.filter(exchange); // 跳过不需要拦截的路径 } // 获取 Token String token = request.getHeaders().getFirst("authorization"); // 校验并解析 Token Long userId = null; try { userId = jwtTool.parseToken(token); // 校验 Token 并获取用户 ID } catch (UnauthorizedException e) { ServerHttpResponse response = exchange.getResponse(); response.setRawStatusCode(401); // Token 校验失败,返回 401 return response.setComplete(); } // 将用户信息添加到请求头 ServerWebExchange modifiedExchange = exchange.mutate() .request(builder -> builder.header("user-info", userId.toString())) .build(); // 放行请求,继续执行后续过滤器 return chain.filter(modifiedExchange); } private boolean isExclude(String path) { // 判断路径是否是需要排除的路径(不需要拦截) for (String pattern : authProperties.getExcludePaths()) { if (antPathMatcher.match(pattern, path)) { return true; } } return false; } @Override public int getOrder() { return 0; // 优先级,数字越小优先级越高 } } JWT 校验:通过 jwtTool.parseToken(token) 校验 Token 是否有效。如果有效,就提取用户 ID;如果无效,返回 401 Unauthorized 错误。 传递用户信息:将 user-info(用户 ID)添加到请求头中,然后放行请求。 isExclude 方法:检查当前请求路径是否匹配不需要拦截的路径(如登录、注册等)。 微服务拦截器 - 获取用户信息 为了统一处理微服务中的用户信息提取,我们将拦截器放在 common 模块中。拦截器的作用是从请求头中获取 user-info,并将其保存到 UserContext 中,供后续业务逻辑使用。具体的拦截和校验逻辑由 网关过滤器 处理,而拦截器的职责仅仅是将用户信息存入 ThreadLocal,避免每个微服务都实现相同的逻辑。 1.用户信息拦截器 public class UserInfoInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 1.获取请求头中的用户信息 String userInfo = request.getHeader("user-info"); // 2.判断是否为空 if (StrUtil.isNotBlank(userInfo)) { // 不为空,保存到ThreadLocal UserContext.setUser(Long.valueOf(userInfo)); } // 3.放行 return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { // 移除用户 UserContext.removeUser(); } } 2.配置拦截器 在 common 模块中,我们通过配置类 MvcConfig 来注册拦截器,使其在微服务应用中生效。该配置类实现了 WebMvcConfigurer 接口,并在 addInterceptors 方法中注册 UserInfoInterceptor。 @Configuration @ConditionalOnClass(DispatcherServlet.class) public class MvcConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new UserInfoInterceptor()); } } 3.解决包扫描问题 由于 common 模块与其他微服务模块(如 item、cart)是平级的,common 包无法被微服务自动扫描到。因此,我们需要通过以下方式确保微服务能够加载 common 模块中的拦截器配置。解决方法: 1.在每个微服务的启动类上添加包扫描 @SpringBootApplication( scanBasePackages = {"com.hmall.item", "com.hmall.common"} // 扫描 item 和 common 包 ) public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } 主包以及common包 2.通过 @Import 引入配置类 @SpringBootApplication @Import(com.hmall.common.config.MvcConfig.class) // 引入 common 模块中的拦截器配置 public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } 3.将 common 模块做成 Spring Boot 自动配置 1)在 common 模块的 src/main/resources/META-INF/spring.factories 文件中声明: org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.hmall.common.config.MvcConfig 2)在 common 模块里给 MvcConfig 加上 @Configuration @ConditionalOnClass(DispatcherServlet.class) //网关不生效 spring服务生效 public class MvcConfig { … } 3)这样,任何微服务只要依赖了 common 模块,MvcConfig 配置就会自动加载,拦截器会自动生效,无需修改微服务的 @SpringBootApplication 配置。 OpenFeign传递用户 前端发起的请求都会经过网关再到微服务,微服务可以轻松获取登录用户信息。但是,有些业务是比较复杂的,请求到达微服务后还需要调用其它多个微服务,微服务之间的调用无法传递用户信息,因为不在一个上下文(线程)中! 解决思路:让每一个由OpenFeign发起的请求自动携带登录用户信息。要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor public class DefaultFeignConfig { @Bean public RequestInterceptor userInfoRequestInterceptor(){ return new RequestInterceptor() { @Override public void apply(RequestTemplate template) { // 获取登录用户 Long userId = UserContext.getUser(); if(userId == null) { // 如果为空则直接跳过 return; } // 如果不为空则放入请求头中,传递给下游微服务 template.header("user-info", userId.toString()); } }; } } 同时,需要在服务调用者的启动类上添加: @EnableFeignClients( basePackages = "com.hmall.api.client", defaultConfiguration = DefaultFeignConfig.class ) @SpringBootApplication public class PayApplication { 这样 DefaultFeignConfig.class 会对于所有Client类生效 @FeignClient(value = "item-service", configuration = DefaultFeignConfig.class) public interface ItemClient { @GetMapping("/items") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); } 这种只对ItemClient生效! 整体流程图 配置管理 微服务共享的配置可以统一交给Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。 配置共享 在nacos控制台的配置管理中添加配置文件 数据库ip:通过${hm.db.host:192.168.150.101}配置了默认值为192.168.150.101,同时允许通过${hm.db.host}来覆盖默认值 配置读取流程: 微服务整合Nacos配置管理的步骤如下: 1)引入依赖: <!--nacos配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> 2)新建bootstrap.yaml 在cart-service中的resources目录新建一个bootstrap.yaml文件: 主要给nacos的信息 spring: application: name: cart-service # 服务名称 profiles: active: dev cloud: nacos: server-addr: 192.168.150.101 # nacos地址 config: file-extension: yaml # 文件后缀名 shared-configs: # 共享配置 - dataId: shared-jdbc.yaml # 共享mybatis配置 - dataId: shared-log.yaml # 共享日志配置 - dataId: shared-swagger.yaml # 共享日志配置 3)修改application.yaml server: port: 8082 feign: okhttp: enabled: true # 开启OKHttp连接池支持 hm: swagger: title: 购物车服务接口文档 package: com.hmall.cart.controller db: database: hm-cart 配置热更新 有很多的业务相关参数,将来可能会根据实际情况临时调整,如何不重启服务,直接更改配置文件生效呢? 示例:购物车中的商品上限数量需动态调整。 1)在nacos中添加配置 在nacos中添加一个配置文件,将购物车的上限数量添加到配置中: 文件的dataId格式: [服务名]-[spring.active.profile].[后缀名] 文件名称由三部分组成: 服务名:我们是购物车服务,所以是cart-service spring.active.profile:就是spring boot中的spring.active.profile,可以省略,则所有profile共享该配置(不管local还是dev还是prod) 后缀名:例如yaml 示例:cart-service.yaml hm: cart: maxAmount: 1 # 购物车商品数量上限 2)在微服务中配置 @Data @Component @ConfigurationProperties(prefix = "hm.cart") public class CartProperties { private Integer maxAmount; } 3)下次,只需改nacos中的配置文件 =》发布,即可实现热更新。 动态路由 1.监听Nacos的配置变更 NacosConfigManager可以获取ConfigService 配置信息 String configInfo = nacosConfigManager.getConfigService() 内容是带换行和缩进的 YAML 文本或者 JSON 格式(取决于你的配置文件格式): //多条路由 [ { "id": "user-service", "uri": "lb://USER-SERVICE", "predicates": [ "Path=/user/**" ], "filters": [ "StripPrefix=1" ] }, { "id": "order-service", "uri": "lb://ORDER-SERVICE", "predicates": [ "Path=/order/**" ], "filters": [ "StripPrefix=1", "AddRequestHeader=X-Order-Source,cloud" ] } ] 因为YAML格式解析不方便,故配置文件采用 JSON 格式保存、读取、解析! String getConfigAndSignListener( String dataId, // 配置文件id String group, // 配置组,走默认 long timeoutMs, // 读取配置的超时时间 Listener listener // 监听器 ) throws NacosException; getConfigAndSignListener既可以在第一次读配置文件又可以在后面进行监听 每当 Nacos 上该配置有变更,会触发其内部receiveConfigInfo(...) 方法 2.然后手动把最新的路由更新到路由表中。 RouteDefinitionWriter public interface RouteDefinitionWriter { /** * 更新路由到路由表,如果路由id重复,则会覆盖旧的路由 */ Mono<Void> save(Mono<RouteDefinition> route); /** * 根据路由id删除某个路由 */ Mono<Void> delete(Mono<String> routeId); } @Slf4j @Component @RequiredArgsConstructor public class DynamicRouteLoader { private final RouteDefinitionWriter writer; private final NacosConfigManager nacosConfigManager; // 路由配置文件的id和分组 private final String dataId = "gateway-routes.json"; private final String group = "DEFAULT_GROUP"; // 保存更新过的路由id private final Set<String> routeIds = new HashSet<>(); //order-service ... @PostConstruct public void initRouteConfigListener() throws NacosException { // 1.注册监听器并首次拉取配置 String configInfo = nacosConfigManager.getConfigService() .getConfigAndSignListener(dataId, group, 5000, new Listener() { @Override public Executor getExecutor() { return null; } @Override public void receiveConfigInfo(String configInfo) { updateConfigInfo(configInfo); } }); // 2.首次启动时,更新一次配置 updateConfigInfo(configInfo); } private void updateConfigInfo(String configInfo) { log.debug("监听到路由配置变更,{}", configInfo); // 1.反序列化 List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class); // 2.更新前先清空旧路由 // 2.1.清除旧路由 for (String routeId : routeIds) { writer.delete(Mono.just(routeId)).subscribe(); } routeIds.clear(); // 2.2.判断是否有新的路由要更新 if (CollUtils.isEmpty(routeDefinitions)) { // 无新路由配置,直接结束 return; } // 3.更新路由 routeDefinitions.forEach(routeDefinition -> { // 3.1.更新路由 writer.save(Mono.just(routeDefinition)).subscribe(); // 3.2.记录路由id,方便将来删除 routeIds.add(routeDefinition.getId()); }); } } 可以在项目启动时先更新一次路由,后续随着配置变更通知到监听器,完成路由更新。 服务保护 服务保护方案 1)请求限流 限制或控制接口访问的并发流量,避免服务因流量激增而出现故障。 2)线程隔离 为了避免某个接口故障或压力过大导致整个服务不可用,我们可以限定每个接口可以使用的资源范围,也就是将其“隔离”起来。 3)服务熔断 线程隔离虽然避免了雪崩问题,但故障服务(商品服务)依然会拖慢购物车服务(服务调用方)的接口响应速度。 所以,我们要做两件事情: 编写服务降级逻辑:就是服务调用失败后的处理逻辑,根据业务场景,可以抛出异常,也可以返回友好提示或默认数据。 异常统计和熔断:统计服务提供方的异常比例,当比例过高表明该接口会影响到其它服务,应该拒绝调用该接口,而是直接走降级逻辑。 无非就是停止无意义的等待,直接返回Fallback方案。 Sentinel 介绍和安装 Sentinel是阿里巴巴开源的一款服务保护框架,quick-start | Sentinel 特性 Sentinel (阿里巴巴) Hystrix (网飞) 线程隔离 信号量隔离 线程池隔离 / 信号量隔离 熔断策略 基于慢调用比例或异常比例 基于异常比率 限流 基于 QPS,支持流量整形 有限的支持 Fallback 支持 支持 控制台 开箱即用,可配置规则、查看秒级监控、机器发现等 不完善 配置方式 基于控制台,重启后失效 基于注解或配置文件,永久生效 安装: 1)下载jar包 https://github.com/alibaba/Sentinel/releases 2)将jar包放在任意非中文、不包含特殊字符的目录下,重命名为sentinel-dashboard.jar 然后运行如下命令启动控制台: java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar 3)访问http://localhost:8090页面,就可以看到sentinel的控制台了 账号和密码,默认都是:sentinel 微服务整合 1)引入依赖 <!--sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> 2)配置控制台 修改application.yaml文件(可以用共享配置nacos),添加如下: spring: cloud: sentinel: transport: dashboard: localhost:8090 我们的SpringMVC接口是按照Restful风格设计,因此购物车的查询、删除、修改等接口全部都是/carts路径。默认情况下Sentinel会把路径作为簇点资源的名称,无法区分路径相同但请求方式不同的接口。 可以在application.yml中添加下面的配置 然后,重启服务 spring: cloud: sentinel: transport: dashboard: localhost:8090 http-method-specify: true # 开启请求方式前缀 OpenFeign整合Sentinel 默认sentinel只会整合spring mvc中的接口。 修改cart-service模块的application.yml文件,可开启Feign的sentinel功能: feign: sentinel: enabled: true # 开启feign对sentinel的支持 调用的别的服务(/item-service)的接口也会显示在这。 限流: 直接在sentinel控制台->簇点链路->流控 里面设置QPS 线程隔离 阈值类型选 并发线程数 ,代表这个接口所能用的线程数。 Fallback 触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,采用FallbackFactory,可以对远程调用的异常做处理。 业务场景:购物车服务需要同时openFeign调用服务B和商品服务,现在对商务服务做了线程隔离,在高并发的时候,会疯狂抛异常,现在做个fallback让它返回默认值。 步骤一:在hm-api模块中给ItemClient定义降级处理类,实现FallbackFactory: public class ItemClientFallback implements FallbackFactory<ItemClient> { @Override public ItemClient create(Throwable cause) { return new ItemClient() { @Override public List<ItemDTO> queryItemByIds(Collection<Long> ids) { log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause); // 查询购物车允许失败,查询失败,返回空集合 return CollUtils.emptyList(); } @Override public void deductStock(List<OrderDetailDTO> items) { // 库存扣减业务需要触发事务回滚,查询失败,抛出异常 throw new BizIllegalException(cause); } }; } } 步骤二:在hm-api模块中的com.hmall.api.config.DefaultFeignConfig类中将ItemClientFallback注册为一个Bean: @Bean public ItemClientFallback itemClientFallback(){ return new ItemClientFallback(); } 步骤三:在hm-api模块中的ItemClient接口中使用ItemClientFallbackFactory: @FeignClient(value = "item-service",fallbackFactory = ItemClientFallback.class) public interface ItemClient { @GetMapping("/items") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); } 重启后,再次测试 熔断器 分布式事务 场景:订单服务依次调用了购物车服务和库存服务,它们各自操作不同的数据库。当清空购物车操作成功、库存扣减失败时,订单服务能捕获到异常,却无法通知已完成操作的购物车服务,导致数据不一致。虽然每个微服务内部都能保证本地事务的 ACID 特性,但跨服务调用缺乏全局协调,无法实现端到端的一致性。 Seeta 要解决这个问题,只需引入一个统一的事务协调者,负责跟每个分支通信,检测状态,并统一决定全局提交或回滚。 在 Seata 中,对应三大角色: TC(Transaction Coordinator)事务协调者 维护全局事务和各分支事务的状态,负责发起全局提交或回滚指令。 TM(Transaction Manager)事务管理器 定义并启动全局事务,最后根据应用调用决定调用提交或回滚。 RM(Resource Manager)资源管理器 嵌入到各微服务中,负责注册分支事务、上报执行结果,并在接到 TC 指令后执行本地提交或回滚。 其中,TM 和 RM 作为客户端依赖,直接集成到业务服务里;TC 则是一个独立部署的微服务,承担全局协调的职责。这样,无论有多少分支参与,都能保证“要么都成功、要么都回滚”的一致性。 部署TC服务 1)准备数据库表 seata-tc.sql 运行初始化脚本 2)准备配置文件 3)Docker部署 seeta-server: image: seataio/seata-server:1.5.2 container_name: seata-server restart: unless-stopped depends_on: - mysql - nacos environment: # 指定 Seata 注册中心和配置中心地址 - SEATA_IP=192.168.0.107 # IDEA 可以访问到的宿主机 IP - SEATA_SERVICE_PORT=17099 - SEATA_CONFIG_TYPE=file # 可视情况再加:SEATA_NACOS_SERVER_ADDR=nacos:8848 networks: - hmall-net ports: - "17099:7099" # TC 服务端口 - "8099:8099" # 服务管理端口(Console) volumes: - ./seata:/seata-server/resources 微服务集成Seata 1)引入依赖 <!--统一配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> <!--seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency> 2)在nacos上添加一个共享的seata配置,命名为shared-seata.yaml,你在bootstrap中引入该配置即可: seata: registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址 type: nacos # 注册中心类型 nacos nacos: server-addr: 192.168.0.107:8848 # 替换为自己的nacos地址 namespace: "" # namespace,默认为空 group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP application: seata-server # seata服务名称 username: nacos password: nacos tx-service-group: hmall # 事务组名称 service: vgroup-mapping: # 事务组与tc集群的映射关系 hmall: "default" 这段配置是告诉你的微服务如何去「找到并使用」Seata 的 TC(Transaction Coordinator)服务,以便在本地发起、提交或回滚分布式事务。 XA模式 XA模式的优点是什么? 事务的强一致性,满足ACID原则 常用数据库都支持,实现简单,并且没有代码侵入 XA模式的缺点是什么? 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差 依赖关系型数据库实现事务 实现方式 1)在Nacos中的共享shared-seata.yaml配置文件中设置: seata: data-source-proxy-mode: XA 2)利用@GlobalTransactional标记分布式事务的入口方法 @GlobalTransactional public Long createOrder(OrderFormDTO orderFormDTO) { ... } 3)子事务中方法前添加@Transactional ,方便回滚 AT模式 简述AT模式与XA模式最大的区别是什么? XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。 XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。 XA模式强一致;AT模式最终一致(存在短暂不一致) 实现方式: 1)为需要的微服务数据库中创建undo_log表 -- for AT mode you must to init this sql for you business database. the seata server not need it. CREATE TABLE IF NOT EXISTS `undo_log` ( `branch_id` BIGINT NOT NULL COMMENT 'branch transaction id', `xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id', `context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization', `rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info', `log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status', `log_created` DATETIME(6) NOT NULL COMMENT 'create datetime', `log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime', UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table'; 2)微服务的配置中设置(其实不设置,默认也是AT模式) seata: data-source-proxy-mode: AT
后端学习
zy123
1年前
0
47
0
2025-03-21
Mysql数据库
Mysql数据库 安装启动Mysql mysql 是 MySQL 的命令行客户端工具,用于连接、查询和管理 MySQL 数据库。 你可以通过它来执行 SQL 命令、查看数据和管理数据库。 mysqld 是 MySQL 服务器守护进程,也就是 MySQL 数据库的实际运行程序。 它负责处理数据库的存储、查询、并发访问、用户验证等核心任务。 添加环境变量: 将'\path\to\mysql-8.0.31-winx64\bin\'目录添加到 PATH 环境变量中,便于命令行操作。 启动Mysql net start mysql // 启动mysql服务 net stop mysql // 停止mysql服务 修改root账户密码 mysqladmin -u root password 123456 本地windows下的账号:root 密码: 123456 登录 mysql -u用户名 -p密码 [-h数据库服务器的IP地址 -P端口号] mysql -uroot -p123456 -h 参数不加,默认连接的是本地 127.0.0.1 的MySQL服务器 -P 参数不加,默认连接的端口号是 3306 图形化工具 推荐Navicat Mysql简介 通用语法 1、SQL语句可以单行或多行书写,以分号结尾。 2、SQL语句可以使用空格/缩进来增强语句的可读性。因为SQL语句在执行时,数据库会忽略额外的空格和换行符 SELECT name, age, address FROM users WHERE age > 18; 3、MySQL数据库的SQL语句不区分大小写。 4、注释: 单行注释:-- 注释内容 或 # 注释内容(MySQL特有) 多行注释: /* 注释内容 */ 分类 分类 全称 说明 DDL Data Definition Language 数据定义语言,用来定义数据库对象(数据库,表,字段) DML Data Manipulation Language 数据操作语言,用来对数据库表中的数据进行增删改 DQL Data Query Language 数据查询语言,用来查询数据库中表的记录 DCL Data Control Language 数据控制语言,用来创建数据库用户、控制数据库的访问权限 数据类型 字符串类型 CHAR(n):声明的字段如果数据类型为char,则该字段占据的长度固定为声明时的值,例如:char(4),存入值 'ab',其长度仍为4. VARCHAR(n):varchar(100)表示最多可以存100个字符,每个字符占用的字节数取决于所使用的字符集。存储开销:除了存储实际数据外,varchar 类型还会额外存储 1 或 2 个字节来记录字符串的长度。 TEXT:用于存储大文本数据,存储长度远大于 VARCHAR,但不支持索引整列内容(通常索引长度有限制)。 日期时间类型: 类型 大小 范围 格式 描述 DATE 3 1000-01-01 至 9999-12-31 YYYY-MM-DD 日期值 TIME 3 -838:59:59 至 838:59:59 HH:MM:SS 时间值或持续时间 DATETIME 8 1000-01-01 00:00:00 至 9999-12-31 23:59:59 YYYY-MM-DD HH:MM:SS 混合日期和时间值 注意:字符串和日期时间型数据在 SQL 语句中应包含在引号内,例如:'2025-03-29'、'hello'。 数值类型 类型 大小 有符号(SIGNED)范围 无符号(UNSIGNED)范围 描述 TINYINT 1byte (-128,127) (0,255) 小整数值 INT/INTEGER 4bytes (-2^31,2^31-1) (0,2^32-1) 大整数值 FLOAT 4bytes (-3.402823466 E+38,3.402823466351 E+38) 0 和 (1.175494351 E-38,3.402823466 E+38) 单精度浮点数值 DECIMAL 依赖于M(精度)和D(标度)的值 依赖于M(精度)和D(标度)的值 小数值(精确定点数) DECIMAL(M, D):定点数类型,M 表示总位数,D 表示小数位数,适合存储精度要求较高的数值(如金钱)。 DDL(数据定义语言) 数据库操作 查询所有数据库: show databases; 创建一个itcast数据库。 create database itcast; 切换到itcast数据 use itcast; 查询当前正常使用的数据库: select database(); 删除itcast数据库 drop database if exists itcast; -- itcast数据库存在时删除,不存在也不报错 表操作 查询当前数据库下所有表 show tables; 查看指定表的结构(字段) desc tb_tmps; ( tb_tmps为表名) 创建表 通常一个列定义的顺序如下: 列名(字段) 字段类型 可选的字符集或排序规则(如果需要) 约束:例如 NOT NULL、UNIQUE、PRIMARY KEY、DEFAULT 等 特殊属性:例如 AUTO_INCREMENT 注释:例如 COMMENT '说明' create table 表名( 字段1 字段1类型 [约束] [comment '字段1注释' ], 字段2 字段2类型 [约束] [comment '字段2注释' ], ...... 字段n 字段n类型 [约束] [comment '字段n注释' ] ) [ comment '表注释' ] ; 注意: [ ] 中的内容为可选参数; 最后一个字段后面没有逗号 eg: create table tb_user ( id int comment 'ID,唯一标识', # id是一行数据的唯一标识(不能重复) username varchar(20) comment '用户名', name varchar(10) comment '姓名', age int comment '年龄', gender char(1) comment '性别' ) comment '用户表'; 复制某个表的结构: CREATE TABLE new_table LIKE old_table; 删除表 DROP TABLE demo; 约束 约束 描述 关键字 非空约束 限制该字段值不能为null not null 唯一约束 保证字段的所有数据都是唯一、不重复的 unique 主键约束 主键是一行数据的唯一标识,要求非空且唯一 primary key 默认约束 保存数据时,如果未指定该字段值,则采用默认值 default 外键约束 让两张表的数据建立连接,保证数据的一致性和完整性 foreign key CREATE TABLE tb_user ( id INT PRIMARY KEY AUTO_INCREMENT COMMENT 'ID,唯一标识', username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名', name VARCHAR(10) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', gender CHAR(1) DEFAULT '男' COMMENT '性别' ) COMMENT '用户表'; -- 假设我们有一个 orders 表,它将 tb_user 表的 id 字段作为外键 CREATE TABLE orders ( order_id INT PRIMARY KEY AUTO_INCREMENT COMMENT '订单ID', order_date DATE COMMENT '订单日期', user_id INT, FOREIGN KEY (user_id) REFERENCES tb_user(id) ON DELETE CASCADE ON UPDATE CASCADE, COMMENT '订单表' ); foreign key: 保证数据的一致性和完整性 ON DELETE CASCADE:如果父表中的某行被删除,那么子表中所有与之关联的行也会被自动删除。 ON DELETE SET NULL:如果父表中的某行被删除,子表中的相关外键列会被设置为 NULL。 ON UPDATE CASCADE:如果父表中的外键值被更新,那么子表中的相关外键值也会自动更新。 注意:在实际的 Java 项目中,特别是在一些微服务架构或分布式系统中,通常不直接依赖数据库中的外键约束。相反,开发者通常会在代码中通过逻辑来确保数据的一致性和完整性。 auto_increment: 每次插入新的行记录时,数据库自动生成id字段(主键)下的值 具有auto_increment的数据列是一个正数序列且整型(从1开始自增) 不能应用于多个字段 设计表的字段时,还应考虑: id:主键,唯一标志这条记录 create_time :插入记录的时间 now()函数可以获取当前时间 update_time:最后修改记录的时间 DCL(数据控制语言) GRANT(授予权限) GRANT 权限列表 ON 数据库对象 TO 用户名 [WITH GRANT OPTION]; # 授予用户 user1对表 students的 查询权限: GRANT SELECT ON students TO user1; REVOKE(撤销权限) REVOKE 权限列表 ON 数据库对象 FROM 用户名; # 撤销用户 user1对表 students的 修改权限: REVOKE UPDATE ON students FROM user1; DML(增删改) DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。 添加数据(INSERT) 修改数据(UPDATE) 删除数据(DELETE) INSERT insert语法: 向指定字段添加数据 insert into 表名 (字段名1, 字段名2) values (值1, 值2); 全部字段添加数据 insert into 表名 values (值1, 值2, ...); 批量添加数据(指定字段) insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2); 批量添加数据(全部字段) insert into 表名 values (值1, 值2, ...), (值1, 值2, ...); “如果不存在,就插入一条新记录;如果已存在,则返回已存在那条的 id。” INSERT INTO orders (user_id, idempotency_key, ...) VALUES (:uid, :key, ...) ON DUPLICATE KEY UPDATE id = LAST_INSERT_ID(id); SELECT LAST_INSERT_ID() AS order_id; 保证操作是幂等的;同一 idempotency_key 的重复请求,只会返回同一条订单 ID。 UPDATE update语法: update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ; 案例1:将tb_emp表中id为1的员工,姓名name字段更新为'张三' update tb_emp set name='张三',update_time=now() where id=1; 案例2:将tb_emp表的所有员工入职日期更新为'2010-01-01' update tb_emp set entrydate='2010-01-01',update_time=now(); **注意!**不带where会更新表中所有记录! DELETE delete语法: delete from 表名 [where 条件] ; 案例1:删除tb_emp表中id为1的员工 delete from tb_emp where id = 1; 案例2:删除tb_emp表中所有员工(记录) delete from tb_emp; DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。 DQL(查询) DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。 查询关键字:SELECT 查询操作是所有SQL语句当中最为常见,也是最为重要的操作。 语法 SELECT 字段列表 FROM 表名列表 ----基本查询 WHERE 条件列表 ----条件查询 GROUP BY 分组字段列表 HAVING 分组后条件列表 ----分组查询 ORDER BY 排序字段列表 ----排序查询 LIMIT 分页参数 ----分页查询 基本查询 查询多个字段 select 字段1, 字段2, 字段3 from 表名; 查询所有字段(通配符) select * from 表名; 设置别名 select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名; 去除重复记录 select distinct 字段列表 from 表名; eg:select distinct job from tb_emp; 条件查询 比较运算符 功能 between ... and ... 在某个范围之内(含最小、最大值) in(...) 在in之后的列表中的值,多选一 like 占位符 模糊匹配(_匹配单个字符, %匹配任意个字符) is null 是null = 等于 逻辑运算符 功能 and 或 && 并且 (多个条件同时成立) or 或 || 或者 (多个条件任意一个成立) not 或 ! 非 , 不是 表数据: id name gender job entrydate 1 张三 2 2 2005-04-15 2 李四 1 3 2007-07-22 3 王五 2 4 2011-09-01 4 赵六 1 2 2008-06-11 案例1:查询 入职时间 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间 且 性别为女 的员工信息 select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2; 案例2:查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息 select * from tb_emp where job in (2,3,4); 案例3:查询 姓名 为两个字的员工信息 常见的 LIKE 模式匹配符包括: %:表示零个或多个字符。 _:表示一个字符。 select * from tb_emp where name like '__'; # 通配符 "_" 代表任意1个字符 字符串、数值函数 字符串函数: 函数 作用 示例 结果 LENGTH(str) 字符串长度(字节) LENGTH('abc') 3 CHAR_LENGTH(str) 字符数(推荐用这个) CHAR_LENGTH('中文') 2 CONCAT(s1, s2, …) 拼接字符串 CONCAT('a','b') ab UPPER(str) 转大写 UPPER('abc') ABC LOWER(str) 转小写 LOWER('ABC') abc SUBSTRING(str, pos, len) 截取子串 SUBSTRING('abcdef',2,3) bcd REPLACE(str, from, to) 替换 REPLACE('a,b,c',',','-') a-b-c TRIM(str) 去掉首尾空格 TRIM(' hi ') hi 示例:清理和格式化 SELECT TRIM(LOWER(name)) AS clean_name, LOWER(email) AS email_lower FROM users; 数值函数: 函数 作用 示例 结果 ABS(x) 绝对值 ABS(-5) 5 ROUND(x, d) 四舍五入 ROUND(3.1415,2) 3.14 CEIL(x) 向上取整 CEIL(2.3) 3 FLOOR(x) 向下取整 FLOOR(2.9) 2 MOD(x, y) 取余数 MOD(10,3) 1 ROUND(x) 表示四舍五入到整数。 示例:计算总价并四舍五入 SELECT product, ROUND(price * quantity, 2) AS total_price FROM sales; 聚合函数 之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对分组后的每一组数据在纵向方向上进行计算。如果没有分组,则默认整张表是“一组”。 聚合函数: 函数 功能 count 统计数量 max 最大值 min 最小值 avg 平均值 sum 求和 语法: select 聚合函数(字段名、列名) from 表名 ; 注意 : 聚合函数会忽略空值,对NULL值不作为统计。 # count(*) 推荐此写法(MySQL底层进行了优化) select count(*) from tb_emp; -- 统计记录数 SELECT SUM(amount) FROM tb_sales; -- 统计amount列的总金额 组合使用字符串、数值函数和聚合函数 1)聚合函数放里层,数值/字符串函数放外层(最常见) SELECT CONCAT(UPPER(student_name), ' 平均分: ', ROUND(AVG(score), 1)) AS summary FROM students s JOIN exam_results e ON s.student_id = e.student_id GROUP BY s.student_name; AVG(price) → 先求平均值(聚合) ROUND(..., 2) → 再四舍五入保留 2 位小数 2)先处理再聚合 SELECT AVG(ROUND(score)) AS avg_rounded_score FROM exam_results; 每次考试的成绩先 ROUND(score) 四舍五入; 再计算平均值。 3)错误示例 -- ❌ 错误示例:聚合函数嵌在聚合函数内 SELECT SUM(AVG(price)) FROM products; SQL 不允许聚合函数再嵌套聚合函数。 分组+Having过滤 分组: 分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。 分组查询通常会使用聚合函数进行计算。 没有 GROUP BY 的话,所有行就是一组。 select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]; orders表: customer_id amount 1 100 1 200 2 150 2 300 例如,假设我们有一个名为 orders 的表,其中包含 customer_id 和 amount 列,我们想要计算每个客户的订单总金额,可以这样写查询: SELECT customer_id, SUM(amount) AS total_amount FROM orders GROUP BY customer_id; 结果: customer_id total_amount 2 450 1 300 在这个例子中,GROUP BY customer_id 将结果按照 customer_id 列的值进行分组,并对每个客户的订单金额求和,生成每个客户的总金额。 过滤 SELECT customer_id, SUM(amount) AS total_amount FROM orders GROUP BY customer_id HAVING total_amount > specified_amount; 在这个查询中,HAVING 子句用于筛选出消费金额(total_amount)大于指定数目(specified_amount)的记录。你需要将 specified_amount 替换为你指定的金额数目。 注意事项: 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义 执行顺序:WHERE → GROUP BY(分组)→ 聚合函数 → HAVING WHERE 在聚合前过滤,HAVING 在聚合后过滤。 进阶 那如果按多个字段分组呢? 农场表 farm_id farm_name 1 Green Valley Farm 2 Sunshine Acres 作物表 crop_id crop_name crop_type 1 小麦 谷物 2 玉米 谷物 3 水稻 谷物 4 番茄 蔬菜 作物种植数据 farm_id crop_id ... 1 1 ... 1 2 ... 2 3 ... 2 4 ... 农场1(Green Valley Farm)有:小麦、玉米 农场2(Sunshine Acres)有:水稻、番茄 按作物统计(跨农场) GROUP BY crop_name 一行一个作物 按农场统计(跨作物) GROUP BY farm_name 一行一个农场 按农场 + 作物统计 GROUP BY farm_name, crop_name 一行代表农场中的一种作物 按农场 + 作物 + 类型统计 GROUP BY farm_name, crop_name, crop_type 最细粒度 注意:只能 SELECT 分组字段或聚合函数 排序查询 语法: select 字段列表 from 表名 [where 条件列表] [group by 分组字段 ] order by 字段1 排序方式1 , 字段2 排序方式2 … ; 排序方式: ASC :升序(默认值) DESC:降序 select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp order by entrydate ASC; -- 按照entrydate字段下的数据进行升序排序 分页查询 有两种写法: select 字段列表 from 表名 limit 起始索引(offset), 每页显示记录数 ; # 推荐 select 字段列表 from 表名 limit 记录数 OFFSET 起始索引; 前端传过来的一般是页码,要计算起始索引 两者并不等价!!! 注意事项: 起始索引从0开始。 计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数 例子 1:第 3 页,每页 20 条 SELECT id, title, created_at FROM post WHERE status = 'PUBLISHED' ORDER BY created_at DESC, id DESC LIMIT 20 OFFSET 40; -- 等价: LIMIT 40, 20 多表设计 外键约束 外键约束的语法: -- 创建表时指定 CREATE TABLE child_table ( id INT PRIMARY KEY, parent_id INT, -- 外键字段 FOREIGN KEY (parent_id) REFERENCES parent_table (id) ON DELETE CASCADE -- 可选,表示父表数据删除时,子表数据也会删除 ON UPDATE CASCADE -- 可选,表示父表数据更新时,子表数据会同步更新 ); -- 建完表后,添加外键 ALTER TABLE child_table ADD CONSTRAINT fk_parent_id -- 外键约束的名称,可选 FOREIGN KEY (parent_id) REFERENCES parent_table (id) ON DELETE CASCADE ON UPDATE CASCADE; 一对多 一对多关系实现:在数据库表中多的一方,添加外键字段(如dept_id),来关联'一'这方的主键(id)。 一对一 一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分。一对一的应用场景: 用户表=》基本信息表+身份信息表,以此来提高数据的操作效率。 基本信息:用户的ID、姓名、性别、手机号、学历 身份信息:民族、生日、身份证号、身份证签发机关,身份证的有效期(开始时间、结束时间) 一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE) 多对多 多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。 案例:学生与课程的关系 关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择 实现关系:建立第三张中间表(选课表),中间表至少包含两个外键,分别关联两方主键 多表查询 分类 多表查询可以分为: 连接查询 内连接:相当于查询A、B交集部分数据 外连接 左外连接:查询左表所有数据(包括两张表交集部分数据) 右外连接:查询右表所有数据(包括两张表交集部分数据) 子查询 内连接 内连接(INNER JOIN)只返回两个表中连接条件完全匹配的行。如果某行在一个表中存在但在另一个表中没有匹配项,则该行不会出现在结果集中。 隐式内连接语法: select 字段列表 from 表1 , 表2 where 条件 ... ; 显式内连接语法: select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ; [inner]可省略 案例:查询员工的姓名及所属的部门名称 隐式内连接实现 select tb_emp.name , tb_dept.name -- 分别查询两张表中的数据 from tb_emp , tb_dept -- 关联两张表 where tb_emp.dept_id = tb_dept.id; -- 消除笛卡尔积 显示内连接 select tb_emp.name , tb_dept.name from tb_emp inner join tb_dept on tb_emp.dept_id = tb_dept.id; 使用场景:获取严格关联的数据(查询所有有订单的客户信息) 外连接 左外连接语法结构: select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ; 左外连接相当于查询表1(左表)的所有行,当然也包含表1和表2交集部分的数据。 右外连接语法结构: select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ; 右外连接相当于查询表2(右表)的所有行,当然也包含表1和表2交集部分的数据。 案例:查询所有员工及其部门信息(包括没有分配部门的员工) -- 左外连接:以left join关键字左边的表为主表,查询主表中所有数据,以及和主表匹配的右边表中的数据 select emp.name , dept.name from tb_emp AS emp left join tb_dept AS dept on emp.dept_id = dept.id; 外连接的作用:1.查询主表所有记录及相关联信息(查询所有员工及其部门信息(包括没有分配部门的员工)) 2.查找缺失数据(找出没有订单的客户) FULL OUTER JOIN(全外连接) 左外连接 (LEFT JOIN):保留左表全部 + 右表匹配 右外连接 (RIGHT JOIN):保留右表全部 + 左表匹配 全外连接 (FULL OUTER JOIN):保留左表全部 + 右表全部,即“左外 ∪ 右外” MySQL 的实现方式:用 LEFT JOIN ∪ RIGHT JOIN -- 左外连接:保证所有员工都能查出来 select emp.*, dept.deptName from t_emp emp left join t_dept dept on emp.deptId = dept.id union -- 右外连接:保证所有部门都能查出来 select emp.*, dept.deptName from t_emp emp right join t_dept dept on emp.deptId = dept.id; 子查询 SQL语句中嵌套select语句,称为嵌套查询,又称子查询。 SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... ); 子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。 标量子查询 子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。 常用的操作符: = <> > >= < <= 案例1:查询"教研部"的所有员工信息 可以将需求分解为两步: 查询 "教研部" 部门ID 根据 "教研部" 部门ID,查询员工信息 -- 1.查询"教研部"部门ID select id from tb_dept where name = '教研部'; #查询结果:2 -- 2.根据"教研部"部门ID, 查询员工信息 select * from tb_emp where dept_id = 2; -- 合并出上两条SQL语句 select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部'); 列子查询 子查询返回的结果是一列(可以是多行,即多条记录),这种子查询称为列子查询。 常用的操作符: 操作符 描述 IN 在指定的集合范围之内,多选一 NOT IN 不在指定的集合范围之内 案例:查询"教研部"和"咨询部"的所有员工信息 分解为以下两步: 查询 "销售部" 和 "市场部" 的部门ID 根据部门ID, 查询员工信息 -- 1.查询"销售部"和"市场部"的部门ID select id from tb_dept where name = '教研部' or name = '咨询部'; #查询结果:3,2 -- 2.根据部门ID, 查询员工信息 select * from tb_emp where dept_id in (3,2); -- 合并以上两条SQL语句 select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部'); 行子查询 子查询返回的结果是一行(可以是多列,即多字段),这种子查询称为行子查询。 常用的操作符:= 、<> 、IN 、NOT IN 案例:查询与"韦一笑"的入职日期及职位都相同的员工信息 可以拆解为两步进行: 查询 "韦一笑" 的入职日期 及 职位 查询与"韦一笑"的入职日期及职位相同的员工信息 -- 查询"韦一笑"的入职日期 及 职位 select entrydate , job from tb_emp where name = '韦一笑'; #查询结果: 2007-01-01 , 2 -- 查询与"韦一笑"的入职日期及职位相同的员工信息 select * from tb_emp where (entrydate,job) = ('2007-01-01',2); -- 合并以上两条SQL语句 select * from tb_emp where (entrydate,job) = (select entrydate , job from tb_emp where name = '韦一笑'); 表子查询 子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。 案例:查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息 分解为两步执行: 查询入职日期是 "2006-01-01" 之后的员工信息 基于查询到的员工信息,在查询对应的部门信息 select * from emp where entrydate > '2006-01-01'; select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ; 存储过程/函数 存储过程 把一段 SQL 逻辑封装起来,存到数据库里, 以后只要执行名字,就能重复调用。 可以执行 INSERT/UPDATE/DELETE,可返回多结果集。 用法举例: DELIMITER // CREATE PROCEDURE add_user(IN username VARCHAR(50), IN age INT) BEGIN INSERT INTO users(name, age, created_at) VALUES (username, age, NOW()); END // DELIMITER ; 调用: CALL add_user('Alice', 25); 补充语法说明: 1)DELIMITER 用来修改 MySQL 命令结束符(分隔符)。 默认情况下,MySQL 认为每条 SQL 命令以 ; 结束。但是存储过程里,本身也会包含很多语句(每句都要以 ; 结尾)。如果不改分隔符,MySQL 就会误以为存储过程还没写完就已经结束了。 2)BEGIN ... END 用来包裹一段可执行的语句块。 3)SELECT age INTO age_val FROM users WHERE id = 1; 把结果存入变量 age_val 中 函数 函数和存储过程很像,但它必须返回一个值,通常用于查询计算(比如求平均、格式化、拼接等)。 一般只读(不能修改数据),只能返回一个标量。 DELIMITER // CREATE PROCEDURE get_user_age(IN uid INT) BEGIN DECLARE age_val INT; -- 从 users 表取 age,赋给变量 age_val SELECT age INTO age_val FROM users WHERE id = uid; -- 输出结果 SELECT CONCAT('用户年龄是: ', age_val); END // DELIMITER ; 执行: CALL get_user_age(5); 结果: 用户年龄是: 23 游标 游标(Cursor)是用来逐行读取查询结果集的指针。 普通的 SQL 一次会返回整张表的结果: SELECT name, age FROM users; 但在存储过程中,有时你希望像“遍历数组”一样——一行一行地取数据、处理逻辑、再取下一行。这时就要用到 游标。 游标使用的4个步骤: 步骤 关键语句 说明 1️⃣ 声明游标 DECLARE cursor_name CURSOR FOR SELECT ... 定义要遍历的结果集 2️⃣ 打开游标 OPEN cursor_name; 执行查询,准备读取 3️⃣ 取数据 FETCH cursor_name INTO var1, var2; 每次取一行结果 4️⃣ 关闭游标 CLOSE cursor_name; 释放资源 遍历所有用户,把他们的年龄大于 30 的标记为“中年用户”。 DELIMITER // CREATE PROCEDURE mark_middle_age() BEGIN -- 定义变量 DECLARE done INT DEFAULT 0; DECLARE uid INT; DECLARE uage INT; -- 定义游标(要遍历的结果集) DECLARE cur CURSOR FOR SELECT id, age FROM users; -- 定义结束条件(游标读完) DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; -- 打开游标 OPEN cur; -- 开始循环读取 read_loop: LOOP FETCH cur INTO uid, uage; -- 把当前行取出到变量 IF done THEN LEAVE read_loop; -- 没数据就退出循环 END IF; -- 条件判断逻辑 IF uage >= 30 THEN UPDATE users SET tag = '中年用户' WHERE id = uid; END IF; END LOOP; -- 关闭游标 CLOSE cur; END // DELIMITER ; 事务 事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 手动提交事务使用步骤: 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务 -- 开启事务 start transaction ; -- 删除学工部 delete from tb_dept where id = 1; -- 删除学工部的员工 delete from tb_emp where dept_id = 1; 上述的这组SQL语句,如果如果执行成功,则提交事务 -- 提交事务 (成功时执行) commit ; 上述的这组SQL语句,如果如果执行失败,则回滚事务 -- 回滚事务 (出错时执行) rollback ; 面试题:事务有哪些特性? 1)原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。 2)一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。 约束层面一致性主要指 数据要符合数据库定义的各种约束,主键约束、外键约束、唯一约束等必须始终成立。 业务层面一致性:部门和该部门下的员工数据全部删除 3)隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行(事务还没commit,那么别的窗口就看不到该修改 )。在 MySQL(InnoDB 引擎)里,隔离性主要是通过 事务隔离级别 + MVCC(多版本并发控制) + 锁机制 来实现的。 SQL 标准定义了 4 种隔离级别(MySQL 都支持): 读未提交 (READ UNCOMMITTED) 能读到别的事务未提交的数据(脏读)。 几乎没隔离,效率最高。 读已提交 (READ COMMITTED) 只能读到别的事务已提交的数据。 Oracle 默认级别,避免脏读,但会出现不可重复读。 可重复读 (REPEATABLE READ) MySQL 默认级别。 在同一个事务里,多次读同一行结果一致(避免不可重复读)。 InnoDB 在此级别下还能避免幻读(通过间隙锁)。 串行化 (SERIALIZABLE) 所有事务串行执行(加锁),最安全但效率最低。 4)持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。 事务的四大特性简称为:ACID 索引 索引(index):是帮助数据库高效获取数据的数据结构 。 创建索引 -- 添加索引 create index idx_sku_sn on tb_sku (sn); #在添加索引时,也需要消耗时间 -- 查询数据(使用了索引) select * from tb_sku where sn = '100000003145008'; 查看索引 show index from 表名; 案例:查询 tb_emp 表的索引信息 show index from tb_emp; 删除索引 drop index 索引名 on 表名; 案例:删除 tb_emp 表中name字段的索引 drop index idx_emp_name on tb_emp; 优点: 提高数据查询的效率,降低数据库的IO成本。 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。 缺点: 索引会占用存储空间。 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。 因为插入一条数据,要重新维护索引结构 注意事项: 主键字段,在建表时,会自动创建主键索引 (primarily key) 添加唯一约束时,数据库实际上会添加唯一索引 (unique约束) 结构 mysql默认采用B+树来作索引 采用二叉搜索树或者是红黑树来作为索引的结构有什么问题? 答案 最大的问题就是在数据量大的情况下,树的层级比较深,会影响检索速度。因为不管是二叉搜索数还是红黑数,一个节点下面只能有两个子节点。此时在数据量大的情况下,就会造成数的高度比较高,树的高度一旦高了,检索速度就会降低。 说明:如果数据结构是红黑树,那么查询1000万条数据,根据计算树的高度大概是23左右,这样确实比之前的方式快了很多,但是如果高并发访问,那么一个用户有可能需要23次磁盘IO,那么100万用户,那么会造成效率极其低下。所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。这种数据结构例如BTree就满足。 下面我们来看看B+Tree(多路平衡搜索树)结构中如何避免这个问题: B+Tree结构: 每一个节点,可以存储多个key(有n个key,就有n个指针) 节点分为:叶子节点、非叶子节点 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
后端学习
zy123
1年前
0
7
0
2025-03-21
力扣Hot 100题
力扣Hot 100题 杂项 最大值:Integer.MAX_VALUE 最小值:Integer.MIN_VALUE 数组集合比较 Arrays.equals(array1, array2) 用于比较两个数组是否相等(内容相同)。 支持多种类型的数组(如 int[]、char[]、Object[] 等)。 int[] arr1 = {1, 2, 3}; int[] arr2 = {1, 2, 3}; boolean isEqual = Arrays.equals(arr1, arr2); // true Collections 类本身没有直接提供类似 Arrays.equals 的方法来比较两个集合的内容是否相等。不过,Java 中的集合类(如 List、Set、Map)已经实现了 equals 方法 List<Integer> list1 = Arrays.asList(1, 2, 3); List<Integer> list2 = Arrays.asList(1, 2, 3); List<Integer> list3 = Arrays.asList(3, 2, 1); System.out.println(list1.equals(list2)); // true System.out.println(list1.equals(list3)); // false(顺序不同) 逻辑比较 boolean flag = false; if (!flag) { //! 是 Java 中的逻辑非运算符,只能用于对布尔值取反。 System.out.println("flag 是 false"); } if (flag == false) { //更常用! System.out.println("flag 是 false"); } //java中没有 if(not flag) 这种写法! Character好用的方法 Character.isDigit(char c)用于判断一个字符是否是一个数字字符 Character.isLetter(char c)用于判断字符是否是一个字母(大小写字母都可以)。 Character.isLowerCase(char c)判断字符是否是小写字母。 Character.toLowerCase(char c)将字符转换为小写字母。 Integer好用的方法 Integer.parseInt(String s):将字符串 s 解析为一个整数(int)。 Integer.parseInt(String s, int radix) :指定进制,指定字符串所用的进制,返回十进制的int值 int num1 = Integer.parseInt("1010", 2); // 二进制 1010 → 十进制 10 int num2 = Integer.parseInt("A", 16); // 十六进制 A → 十进制 10 System.out.println(num1); // 10 System.out.println(num2); // 10 Integer.toString(int i):将 int 转换为字符串。 Integer.compare(int a,int b) 比较a和b的大小,内部实现类似: public static int compare(int x, int y) { return (x < y) ? -1 : ((x == y) ? 0 : 1); } 避免了 整数溢出 的风险,在排序中建议使用Integer.compare(a,b)代替 a-b。注意,仅支持Integer[] arr,不支持int[] arr。 int->String public class BaseConverter { // 将十进制数 n 转换为 base 进制(2 <= base <= 36) public static String toBase(int n, int base) { if (n == 0) return "0"; StringBuilder sb = new StringBuilder(); boolean negative = n < 0; // 处理负数 if (negative) n = -n; while (n > 0) { int digit = n % base; // 取余得到最后一位 if (digit < 10) { sb.append((char) (digit + '0')); // 0~9 } else { sb.append((char) (digit - 10 + 'A')); // 10~35 → A~Z } n /= base; } if (negative) sb.append('-'); // 负数加符号 return sb.reverse().toString(); // 翻转得到正确顺序 } public static void main(String[] args) { System.out.println(toBase(255, 2)); // 二进制: 11111111 System.out.println(toBase(255, 8)); // 八进制: 377 System.out.println(toBase(255, 16)); // 十六进制: FF System.out.println(toBase(12345, 36));// 36进制: 9IX } } String 转为字符串: String s1 = String.valueOf(123); // "123" String s2 = String.valueOf(true); // "true" String s3 = String.valueOf('a'); // "a" 比较: a.compareTo(b); 比较字符串a和b的大小。 格式化: String result = String.format(String format, Object... args); format:格式模板(里面包含占位符)。 args:传入的参数,会依次替换占位符。 %s —— 字符串 %d —— 整数 %f —— 浮点数(默认保留 6 位小数) %n —— 换行 //1. 拼接字符串 String name = "Alice"; int age = 23; String result = String.format("My name is %s, I am %d years old.", name, age); System.out.println(result); // 输出: My name is Alice, I am 23 years old. //2. 控制浮点数精度 double pi = 3.14159265358979; String result = String.format("PI = %.2f", pi); System.out.println(result); // 输出: PI = 3.14 排序: 需要String先转为char [] 数组,排序好之后再转为String类型!! char[] charArray = str.toCharArray(); Arrays.sort(charArray); //{'2', '2', '9', '9'} String sortedStr = new String(charArray); "2299" iter遍历,也要先转为char[]数组 int[]cnt=new int[26]; for (Character c : s.toCharArray()) { cnt[c-'a']++; } 取字符: charAt(int index) 方法返回指定索引处的 char 值。 char 是基本数据类型,占用 2 个字节,表示一个 Unicode 字符。 HashSet<Character> set = new HashSet<Character>(); 取子串: substring(int beginIndex, int endIndex) 方法返回从 beginIndex 到 endIndex - 1 的子字符串。 返回的是 String 类型,即使子字符串只有一个字符。 去除开头结尾空字符: trim() 分割字符串: split() 方法,可以用来分割字符串,并返回一个字符串数组。参数是String类型的正则表达式。 String str = "apple, banana, orange grape"; String[] fruits = str.split(",\\s*"); // 按逗号后可能存在的空格分割 // apple banana orange grape s = "ababbc" String[] parts = s.split("c"); // ["ababb"] 仅用stringbuilder: public static List<String> splitBySpace(String s) { List<String> words = new ArrayList<>(); StringBuilder sb = new StringBuilder(); for (int i = 0; i < s.length(); i++) { char c = s.charAt(i); if (c != ' ') { // 累积字母 sb.append(c); } else { // 遇到空格:如果 sb 里有内容,则构成一个单词 if (sb.length() > 0) { words.add(sb.toString()); sb.setLength(0); // 清空,准备下一个单词 } // 如果连续多个空格,则这里会跳过 sb.length()==0 的情况 } } // 循环结束后,sb 里可能还剩最后一个单词 if (sb.length() > 0) { words.add(sb.toString()); } return words; } 位运算 按位与 &:只有两个对应位都为 1 时,结果位才为 1。 int a = 5; // 0101₂ int b = 3; // 0011₂ int c = a & b; // 0001₂ = 1 System.out.println(c); // 输出 1 典型用途: 清零低位:x & (~((1<<k)-1)) 清掉最低 k 位; (1<<3)-1 = 0000_0111 ~((1<<3)-1) = 1111_1000 判断奇偶:x & 1,若结果是 1 说明奇数,若 0 说明偶数; 掩码提取:只保留想要的位置,其他位置置 0。 取低8位:与0xFF(二进制 11111111)进行按位与(&)操作 按位或 |: 只要两个对应位有一个为 1,结果位就为 1。 int a = 5; // 0101₂ int b = 3; // 0011₂ int c = a | b; // 0111₂ = 7 System.out.println(c); // 输出 7 典型用途: 置位:x | (1<<k) 把第 k 位置 1; 合并标志:将两个掩码或在一起。 按位异或 ^: 两个对应位不同则为 1,相同则为 0。 int a = 5; // 0101₂ int b = 3; // 0011₂ int c = a ^ b; // 0110₂ = 6 System.out.println(c); // 输出 6 算术左移 <<: 整体二进制左移 n 位,右侧补 0;相当于乘以 2ⁿ。(因为最高位可能走出符号位,结果符号可能翻转) int a = 3; // 0011₂ int b = a << 2; // 1100₂ = 12 System.out.println(b); // 输出 12 逻辑(无符号)右移>>>:在最高位一律补 0,不管原符号位是什么。 Random Random 是伪随机数生成器 nextInt() 任意 int Integer.MIN_VALUE … Integer.MAX_VALUE nextInt(bound) 0(含)至 bound(不含) [0, bound) import java.util.Random; import java.util.stream.IntStream; public class RandomDemo { public static void main(String[] args) { Random rnd = new Random(); // 随机种子 Random seeded = new Random(2025L); // 固定种子 // 1) 随机整数 int a = rnd.nextInt(); // 任意 int int b = rnd.nextInt(100); // [0,100) System.out.println("a=" + a + ", b=" + b); // 2) 随机浮点数与布尔 double d = rnd.nextDouble(); // [0.0,1.0) boolean flag = rnd.nextBoolean(); System.out.println("d=" + d + ", flag=" + flag); } } 想生成5 到 10 之间的整数: public class RandomRangeDemo { public static void main(String[] args) { Random rnd = new Random(); int min = 5; int max = 10; int n = rnd.nextInt(max - min + 1) + min; System.out.println("随机数 = " + n); } } 常用数据结构 StringBuilder StringBuffer 是线程安全的,它的方法是同步的 (synchronized),这意味着在多线程环境下使用 StringBuffer 是安全的。 StringBuilder 不是线程安全的,它的方法没有同步机制,因此在单线程环境中,StringBuilder 的性能通常要比 StringBuffer 更好。 它们都是 Java 中用于操作可变字符串的类,拥有相同的方法! 1.append(String str) 向字符串末尾追加内容。 2.insert(int offset, String str) 在指定位置插入字符串。(有妙用,头插法可以实现倒序)insert(0,str) 3.delete(int start, int end) 删除从 start 到 end 索引之间的字符。(包括start,不包括end) 4.deleteCharAt(int index) 删除指定位置的字符。 5.replace(int start, int end, String str) 替换指定范围内的字符。 6.reverse() 将字符串反转。String未提供 重要内容!!!! 7.toString() 返回当前字符串缓冲区的内容,转换为 String 对象。 sb.toString()会创建并返回一个新的、独立的 String 对象,之后setLength(0)不会影响这个 String 对象 8.setLength(int newLength) 设置字符串的长度。 //sb.setLength(0); 用作清空字符串 9.charAt(int index) 返回指定位置的字符。 10.length() 返回当前字符串的长度。 StringBuffer 的 append() 方法不仅支持添加普通的字符串,也可以直接将另一个 StringBuffer 对象添加到当前的 StringBuffer。 StringBuffer 插入int类型的数字时,会自动转为字符串插入。 HashMap 基于哈希表实现,查找、插入和删除的平均时间复杂度为 O(1)。 不保证元素的顺序。 import java.util.HashMap; import java.util.Map; public class HashMapExample { public static void main(String[] args) { // 创建 HashMap Map<String, Integer> map = new HashMap<>(); // 添加键值对 map.put("apple", 10); map.put("banana", 20); map.put("orange", 30); // 获取值 int appleCount = map.get("apple"); //如果获取不存在的元素,返回null System.out.println("Apple count: " + appleCount); // 输出 10 // 遍历 HashMap for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println(entry.getKey() + ": " + entry.getValue()); } // 输出: // apple: 10 // banana: 20 // orange: 30 // 检查是否包含某个键 boolean containsBanana = map.containsKey("banana"); System.out.println("Contains banana: " + containsBanana); // 输出 true // 删除键值对 map.remove("orange"); //删除不存在的元素也不会报错 System.out.println("After removal: " + map); // 输出 {apple=10, banana=20} } } 如何在创建的时候初始化?“双括号”初始化 Map<Integer, Character> map = new HashMap<>() {{ put(1, 'a'); put(2, 'b'); put(3, 'c'); }}; 记录二维数组中某元素是否被访问过,推荐使用: int m = grid.length; int n = grid[0].length; boolean[][] visited = new boolean[m][n]; // 访问 (i, j) 时标记为已访问 visited[i][j] = true; 而非创建自定义Pair二元组作为键用Map记录。 统计每个字母出现的次数: int[] cnt = new int[26]; for (char c : magazine.toCharArray()) { cnt[c - 'a']++; } 修改键值对中的键值: Map<Character, Integer> counts = new HashMap<>(); counts.put(ch, counts.getOrDefault(ch, 0) + 1); 如何遍历Map? 只关心 键 的时候: Map<String, Integer> map = new HashMap<>(); map.put("Tom", 18); map.put("Jerry", 20); // 遍历 key for (String key : map.keySet()) { System.out.println("key = " + key); } 只关心 值 的时候: for (Integer value : map.values()) { System.out.println("value = " + value); } 同时获取 键和值: for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println(entry.getKey() + " -> " + entry.getValue()); } HashSet 基于哈希表实现,查找、插入和删除的平均时间复杂度为 O(1)。 不保证元素的顺序!!因此不太用iterator迭代,而是用contains判断是否有xx元素。 import java.util.HashSet; import java.util.Set; public class HashSetExample { public static void main(String[] args) { // 创建 HashSet Set<Integer> set = new HashSet<>(); // 添加元素 set.add(10); set.add(20); set.add(30); set.add(10); // 重复元素,不会被添加 // 检查元素是否存在 boolean contains20 = set.contains(20); System.out.println("Contains 20: " + contains20); // 输出 true // 遍历 HashSet for (int num : set) { System.out.println(num); } // 输出: // 20 // 10 // 30 // 删除元素 set.remove(20); System.out.println("After removal: " + set); // 输出 [10, 30] } } public void isHappy() { Set<Integer> set1 = new HashSet<>(List.of(1,2,3)); Set<Integer> set2 = new HashSet<>(List.of(2,3,1)); Set<Integer> set3 = new HashSet<>(List.of(3,2,1)); Set<Set<Integer>> sset = new HashSet<>(); sset.add(set1); sset.add(set2); sset.add(set3); } 这里最终sset的size为1 如何从List中初始化Set? Set<String> set1 = new HashSet<>(wordList); //构造器直接初始化 如何从Array中初始化? Set<String> set1 = new HashSet<>(Arrays.asList(wordList)); //构造器直接初始化 PriorityQueue 基于优先堆(最小堆或最大堆)实现,元素按优先级排序。 默认是最小堆,即队首元素是最小的。 new PriorityQueue<>(Comparator.reverseOrder());定义最大堆 支持自定义排序规则,通过 Comparator 实现。 常用方法: add(E e) / offer(E e): 功能:将元素插入队列。 时间复杂度:O(log n) 区别 add:当队列满时会抛出异常。 offer:当队列满时返回 false,不会抛出异常。 remove() / poll(): 功能:移除并返回队首元素。 时间复杂度:O(log n) 区别 remove:队列为空时抛出异常。 poll:队列为空时返回 null。 element() / peek(): 功能:查看队首元素,但不移除。 时间复杂度:O(1) 区别 element:队列为空时抛出异常。 peek:队列为空时返回 null。 clear(): 功能:清空队列。 时间复杂度:O(n)(因为需要删除所有元素) import java.util.PriorityQueue; import java.util.Comparator; public class PriorityQueueExample { public static void main(String[] args) { // 创建 PriorityQueue(默认是最小堆) PriorityQueue<Integer> minHeap = new PriorityQueue<>(); // 添加元素 minHeap.add(10); minHeap.add(20); minHeap.add(5); // 查看队首元素 System.out.println("队首元素: " + minHeap.peek()); // 输出 5 // 遍历 PriorityQueue(注意:遍历顺序不保证有序) System.out.println("遍历 PriorityQueue:"); for (int num : minHeap) { System.out.println(num); } // 输出: // 5 // 10 // 20 // 移除队首元素 System.out.println("移除队首元素: " + minHeap.poll()); // 输出 5 // 再次查看队首元素 System.out.println("队首元素: " + minHeap.peek()); // 输出 10 // 创建最大堆(通过自定义 Comparator) PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Comparator.reverseOrder()); maxHeap.add(10); maxHeap.add(20); maxHeap.add(5); // 查看队首元素 System.out.println("最大堆队首元素: " + maxHeap.peek()); // 输出 20 // 清空队列 minHeap.clear(); System.out.println("队列是否为空: " + minHeap.isEmpty()); // 输出 true } } 自定义排序 按第二个元素的值构建小根堆 如果比较器返回负数,则第一个数排在前面->优先级高->在堆顶 public class CustomPriorityQueue { public static void main(String[] args) { // 定义一个 PriorityQueue,其中每个元素是 int[],并且按照数组第二个元素升序排列 PriorityQueue<int[]> minHeap = new PriorityQueue<>( (a, b) -> a[1] - b[1] ); // 添加数组 minHeap.offer(new int[]{1, 2}); minHeap.offer(new int[]{3, 4}); minHeap.offer(new int[]{0, 5}); // 依次取出元素,输出结果 while (!minHeap.isEmpty()) { int[] arr = minHeap.poll(); System.out.println(Arrays.toString(arr)); } } } 不用lambda版本(不推荐): PriorityQueue<int[]> minHeap = new PriorityQueue<>(new Comparator<int[]>() { @Override public int compare(int[] a, int[] b) { return a[1] - b[1]; } }); 自己实现小根堆 父节点:对于任意索引 i,其父节点的索引为 (i - 1) // 2。 左子节点:索引为 i 的节点,其左子节点的索引为 2 * i + 1。 右子节点:索引为 i 的节点,其右子节点的索引为 2 * i + 2。 上滤与下滤操作 上滤(Sift-Up): 用于插入操作。将新加入的元素与其父节点不断比较,若小于父节点则交换,直到满足堆序性质。 下滤(Sift-Down): 用于删除操作或建堆。将根节点或某个节点与其子节点中较小的进行比较,若大于子节点则交换,直至满足堆序性质。 建堆:从数组中最后一个非叶节点开始(索引为 heapSize/2 - 1),对每个节点执行下滤操作(sift-down) 插入元素:将新元素插入到堆的末尾,然后执行上滤操作(sift-up),以保持堆序性质。 弹出元素(删除堆顶):弹出操作一般是删除堆顶元素(小根堆中即最小值),然后用堆尾元素替代堆顶,再进行下滤操作。 class MinHeap { private int[] heap; // 数组存储堆元素 private int size; // 当前堆中元素的个数 // 构造函数,初始化堆,capacity为堆的最大容量 public MinHeap(int capacity) { heap = new int[capacity]; size = 0; } // 插入元素:先将新元素添加到数组末尾,然后执行上滤操作恢复堆序性质 public void insert(int value) { if (size >= heap.length) { throw new RuntimeException("Heap is full"); } // 将新元素放到末尾 heap[size] = value; int i = size; size++; // 上滤操作:不断与父节点比较,若新元素小于父节点则交换 while (i > 0) { int parent = (i - 1) / 2; if (heap[i] < heap[parent]) { swap(heap, i, parent); i = parent; } else { break; } } } // 弹出堆顶元素:移除堆顶(最小值),用最后一个元素替换堆顶,然后下滤恢复堆序 public int pop() { if (size == 0) { throw new RuntimeException("Heap is empty"); } int min = heap[0]; // 将最后一个元素移到堆顶 heap[0] = heap[size - 1]; size--; // 对新的堆顶执行下滤操作,恢复堆序性质 minHeapify(heap, 0, size); return min; } // 建堆:将无序数组a构造成小根堆,heapSize为数组长度 public static void buildMinHeap(int[] a, int heapSize) { for (int i = heapSize / 2 - 1; i >= 0; --i) { minHeapify(a, i, heapSize); } } // 下滤操作:从索引i开始,将子树调整为小根堆 public static void minHeapify(int[] a, int i, int heapSize) { int l = 2 * i + 1, r = 2 * i + 2; int smallest = i; // 判断左子节点是否存在且比当前节点小 if (l < heapSize && a[l] < a[smallest]) { smallest = l; } // 判断右子节点是否存在且比当前最小节点小 if (r < heapSize && a[r] < a[smallest]) { smallest = r; } // 如果最小值不是当前节点,交换后继续对被交换的子节点执行下滤操作 if (smallest != i) { swap(a, i, smallest); minHeapify(a, smallest, heapSize); } } // 交换数组中两个位置的元素 public static void swap(int[] a, int i, int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; } } 改为大根堆只需要把里面 ''<'' 符号改为 ''>'' ArrayList 1.基本特性 基于数组实现,支持动态扩展。 随机访问效率高:get()、set() 时间复杂度为 O(1)。 末尾插入/删除效率高:add(E e)、remove(size-1) 时间复杂度为 O(1)(均摊)。 指定位置插入/删除效率低:add(int index, E e)、remove(int index) 时间复杂度为 O(n),因为需要移动元素。 2.常用操作 添加元素 List<Integer> list = new ArrayList<>(); list.add(10); list.add(20); list.add(30); 获取大小 int size = list.size(); // 3 访问和修改元素 int first = list.get(0); // 10 list.set(1, 25); // 修改第二个元素为 25 删除元素 list.remove(2); // 删除索引为2的元素 遍历 //增强 for: for (int num : list) { System.out.println(num); } //普通 for: for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } 3.批量操作 复制列表 List<Integer> list1 = new ArrayList<>(); // 假设 list1 中已有数据 // 方法一:addAll List<Integer> list2 = new ArrayList<>(); list2.addAll(list1); // 方法二:构造函数 List<Integer> list3 = new ArrayList<>(list1); 清空列表 list.clear(); 复制到数组 推荐手动遍历;Java 自带 toArray 也能用但较麻烦。 int[] arr = new int[list.size()]; for (int i = 0; i < list.size(); i++) { arr[i] = list.get(i); } 4.二维 ArrayList 如果事先不知道嵌套列表的大小如何遍历呢? //增强 for: for (List<Integer> row : list) { for (int num : row) { System.out.print(num + " "); } System.out.println(); } //普通 for: for (int i = 0; i < list.size(); i++) { for (int j = 0; j < list.get(i).size(); j++) { System.out.print(list.get(i).get(j) + " "); } System.out.println(); } 数组(Array) 数组是一种固定长度的数据结构,用于存储相同类型的元素。数组的特点包括: 固定长度:数组的长度在创建时确定,无法动态扩展。 快速访问:通过索引访问元素的时间复杂度为 O(1)。 连续内存:数组的元素在内存中是连续存储的。 public class ArrayExample { public static void main(String[] args) { // 创建数组 int[] array = new int[5]; // 创建一个长度为 5 的整型数组 // 添加元素 array[0] = 10; array[1] = 20; array[2] = 30; array[3] = 40; array[4] = 50; // 获取元素 int firstElement = array[0]; System.out.println("First element: " + firstElement); // 输出 10 // 修改元素 array[1] = 25; // 将第二个元素改为 25 System.out.println("After modification:"); for (int num : array) { System.out.println(num); } // 输出: // 10 // 25 // 30 // 40 // 50 // 遍历数组 System.out.println("Iterating through array:"); for (int i = 0; i < array.length; i++) { System.out.println("Index " + i + ": " + array[i]); } // 输出: // Index 0: 10 // Index 1: 25 // Index 2: 30 // Index 3: 40 // Index 4: 50 // 删除元素(数组长度固定,无法直接删除,可以通过覆盖实现) int indexToRemove = 2; // 要删除的元素的索引 for (int i = indexToRemove; i < array.length - 1; i++) { array[i] = array[i + 1]; // 将后面的元素向前移动 } array[array.length - 1] = 0; // 最后一个元素置为 0(或其他默认值) System.out.println("After removal:"); for (int num : array) { System.out.println(num); } // 输出: // 10 // 25 // 40 // 50 // 0 // 数组长度 int length = array.length; System.out.println("Array length: " + length); // 输出 5 } } 复制数组: int[] source = {1, 2, 3, 4, 5}; int[] destination = Arrays.copyOf(source, source.length); int[] partialArray = Arrays.copyOfRange(source, 1, 4); //复制指定元素,不包括索引4 初始化: int double 数值默认初始化为0,boolean默认初始化为false //一维 int[] memo = new int[nums.length]; Arrays.fill(memo, -1); //二维 int[][] test=new int[2][2]; for (int[] ints : test) { Arrays.fill(ints,1); } 注意:数组求size: xx.length; String求size:xx.length(); List求size:xx.size(); 二维数组 int[][] res = new int[rows][]; 只指定了二维数组的“行数”,没有指定“列数”。这是 Java 里允许的。 int rows = 3; int cols = 3; int[][] array = new int[rows][cols]; // 填充数据 for (int i = 0; i < rows; i++) { for (int j = 0; j < cols; j++) { array[i][j] = i * cols + j + 1; } } //创建并初始化 int[][] array = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; // 遍历二维数组,不知道几行几列 public void setZeroes(int[][] matrix) { // 遍历每一行 for (int i = 0; i < matrix.length; i++) { // 遍历当前行的每一列 for (int j = 0; j < matrix[i].length; j++) { // 这里可以处理 matrix[i][j] 的元素 System.out.print(matrix[i][j] + " "); } System.out.println(); // 换行,便于输出格式化 } } [[1, 0]] 是一行两列数组。 Queue 队尾插入,队头取! import java.util.Queue; import java.util.LinkedList; public class QueueExample { public static void main(String[] args) { // 创建一个队列 Queue<Integer> queue = new LinkedList<>(); // 添加元素到队列中 queue.add(10); // 使用 add() 方法添加元素 queue.offer(20); // 使用 offer() 方法添加元素 queue.add(30); System.out.println("队列内容:" + queue); // 查看队头元素,不移除 int head = queue.peek(); System.out.println("队头元素(peek): " + head); // 移除队头元素 int removed = queue.poll(); System.out.println("移除的队头元素(poll): " + removed); System.out.println("队列内容:" + queue); // 再次移除队头元素 int removed2 = queue.remove(); System.out.println("移除的队头元素(remove): " + removed2); System.out.println("队列内容:" + queue); } } Deque(双端队列+栈) 支持在队列的两端(头和尾)进行元素的插入和删除。这使得 **Deque 既能作为队列(FIFO)又能作为栈(LIFO)使用。**栈可以看作双端队列的特例,即使用一端。 LinkedList 是基于双向链表实现的,每个节点存储数据和指向前后节点的引用。 ArrayDeque 则基于动态数组实现,内部使用循环数组来存储数据。 ArrayDeque 在大多数情况下性能更好,因为数组在内存中连续,缓存友好,且操作(如 push/pop)开销更小。 栈 Deque<Integer> stack = new ArrayDeque<>(); //Deque<Integer> stack = new LinkedList<>(); stack.push(1); // 入栈 Integer top1=stack.peek() Integer top = stack.pop(); // 出栈 双端队列 在队头操作 offerFirst(E e):在队头插入元素,返回 true 或 false 表示是否成功。 peekFirst():查看队头元素,不移除;队列为空返回 null。 pollFirst():移除并返回队头元素;队列为空返回 null。 poll() :移除并返回队头元素 在队尾操作 offerLast(E e):在队尾插入元素,返回 true 或 false 表示是否成功。 offer(E e) : 把元素放到 队尾 peekLast():查看队尾元素,不移除;队列为空返回 null。 pollLast():移除并返回队尾元素;队列为空返回 null。 import java.util.Deque; import java.util.ArrayDeque; public class DequeExampleSafe { public static void main(String[] args) { // 使用 ArrayDeque 实现双端队列 Deque<Integer> deque = new ArrayDeque<>(); /* ========= 在队列两端“安全”地添加元素 ========= */ deque.offerFirst(10); // 队头 ← 10 deque.offerLast(20); // 20 ← 队尾 deque.offerFirst(5); // 队头 ← 5,10,20 deque.offerLast(30); // 队尾 → 5,10,20,30 System.out.println("双端队列内容:" + deque); /* ========= “安全”地查看队头/队尾 ========= */ Integer first = deque.peekFirst(); // 队头元素(5) Integer last = deque.peekLast(); // 队尾元素(30) System.out.println("队头元素:" + first); System.out.println("队尾元素:" + last); /* ========= “安全”地移除队头/队尾 ========= */ Integer removedFirst = deque.pollFirst(); // 移除并返回队头(5) System.out.println("移除队头元素:" + removedFirst); Integer removedLast = deque.pollLast(); // 移除并返回队尾(30) System.out.println("移除队尾元素:" + removedLast); System.out.println("双端队列最终内容:" + deque); } } 栈和双端队列的对应关系 栈只有队头! 添加元素:push(e) ⇒ addFirst(e) (安全版:offerFirst(e)) 删除元素:pop() ⇒ removeFirst() (安全版:pollFirst()) 查看栈顶:peek() ⇒ peekFirst() Iterator HashMap、HashSet、ArrayList 和 PriorityQueue 都实现了 Iterable 接口,支持 iterator() 方法。 Iterator 接口中包含以下主要方法: hasNext():如果迭代器还有下一个元素,则返回 true,否则返回 false。 next():返回迭代器的下一个元素,并将迭代器移动到下一个位置。 remove():从迭代器当前位置删除元素。该方法是可选的,不是所有的迭代器都支持。 import java.util.ArrayList; import java.util.Iterator; public class Main { public static void main(String[] args) { // 创建一个 ArrayList 集合 ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); // 获取集合的迭代器 Iterator<Integer> iterator = list.iterator(); // 使用迭代器遍历集合并输出元素 while (iterator.hasNext()) { Integer element = iterator.next(); System.out.println(element); } } } Collections工具类 1.排序 参数必须是 List<T> Collections.sort(list); 对 list 进行升序排序(要求元素实现了 Comparable 接口,比如 Integer、String)。 Collections.sort(list, Collections.reverseOrder()); 2.反转 参数也是 List<?>。 Collections.reverse(list); //[1,2,3] → [3,2,1] 3.最大 / 最小值 参数是 Collection,可以是Set Collections.max(list); Collections.min(list); 查找 二分查找 public static int lowerBound(int[] arr, int target) { int left = 0, right = arr.length; // 注意 right = arr.length,而不是 arr.length-1 while (left < right) { int mid = (left + right) / 2; if (arr[mid] >= target) { right = mid; // 收缩右边界 } else { left = mid + 1; // 收缩左边界 } } return left; // 最终 left 就是答案 } 排序 快速排序 基本思想: 快速排序是一种基于“分治”思想的排序算法,通过选定一个“枢轴元素(pivot)”,将数组划分为左右两个子区间:左边都小于等于 pivot,右边都大于等于 pivot;然后对这两个子区间递归排序,最终使整个数组有序。 public class QuickSort { /** * 对数组 arr 在下标 low 到 high 范围内进行快速排序 * 使用“挖坑填坑”方式,不再调用 swap 方法 */ public static void quickSort(int[] arr, int low, int high) { if (low < high) { int pivotPos = partition(arr, low, high); // 划分 quickSort(arr, low, pivotPos - 1); // 递归排序左子表 quickSort(arr, pivotPos + 1, high); // 递归排序右子表 } } /** * 划分函数:以 arr[low] 作为枢轴,通过“挖坑—填坑”将小于枢轴的元素移到左边, * 大于枢轴的元素移到右边,最后返回枢轴的最终下标 */ private static int partition(int[] arr, int low, int high) { int pivot = arr[low]; // 先保存枢轴 while (low < high) { // 从右向左找第一个小于 pivot 的元素,填到 left 这个“坑”里 while (low < high && arr[high] >= pivot) { high--; } arr[low] = arr[high]; // 从左向右找第一个大于 pivot 的元素,填到 right 这个“坑”里 while (low < high && arr[low] <= pivot) { low++; } arr[high] = arr[low]; } // 最后把枢轴填回中心位置 arr[low] = pivot; return low; } } 时间复杂度: 1)单次划分(partition):每次调用 partition,都要从数组的两端向中间扫描一遍,直到两个指针相遇。所以 一次 partition 操作的时间复杂度是 O(n) 2)快速排序的核心是 分治:每次划分,把数组分成左右两个子数组,然后分别递归排序。如果每次 pivot 都把数组近似平均分成两半,那么递归树高度大约是 log n。 Java随机 mport java.util.Random; public class RandomDemo { public static void main(String[] args) { Random random = new Random(); int num = random.nextInt(6); // 生成 [0, 5] 的随机整数 System.out.println(num); } } 快速选择 时间复杂度: O(n) public class QuickSelect { /** * 在数组 arr 的 [low..high] 区间内,寻找第 k 小的元素(k 从 0 开始计数) * 使用快速选择(Quick Select)算法,平均时间复杂度 O(n) */ public int quickselect(int[] arr, int low, int high, int k) { if (low <= high) { int pivotPos = partition(arr, low, high); // 划分操作,返回枢轴的最终下标 if (pivotPos == k) { // 找到了第 k 小的元素 return arr[pivotPos]; } else if (k < pivotPos) { // 如果第 k 小元素在枢轴左边 return quickselect(arr, low, pivotPos - 1, k); } else { // 如果第 k 小元素在枢轴右边 return quickselect(arr, pivotPos + 1, high, k); } } // 正常情况下不会走到这里(除非 k 越界) throw new IllegalArgumentException("k is out of bounds"); } /** * 划分函数(partition)—— 挖坑填坑法 * 功能:以 arr[low] 为枢轴,将小于 pivot 的放左边,大于 pivot 的放右边 * 返回枢轴的最终位置(low == high 时) */ private int partition(int[] arr, int low, int high) { int pivot = arr[low]; // 选取枢轴(第一个元素) // “挖坑填坑”过程 while (low < high) { // 从右向左找第一个小于 pivot 的元素 while (low < high && arr[high] >= pivot) { high--; } arr[low] = arr[high]; // 填到左边的“坑”里 // 从左向右找第一个大于 pivot 的元素 while (low < high && arr[low] <= pivot) { low++; } arr[high] = arr[low]; // 填到右边的“坑”里 } // 最后将枢轴填回当前位置 arr[low] = pivot; return low; // 返回枢轴的最终位置 } /** * 返回数组中第 k 大的元素(k 从 1 开始) * 例如:k=1 表示最大值,k=2 表示次大值 */ public int findKthLargest(int[] nums, int k) { int n = nums.length; // 第 k 大 == 第 (n - k) 小 return quickselect(nums, 0, n - 1, n - k); } } 冒泡排序 基本思想: 【每次将最小/大元素,通过依次交换顺序,放到首/尾位。】 从后往前(或从前往后)两两比较相邻元素的值,若为逆序, 则交换它们,直到序列比较完。我们称它为第一趟冒泡,结果是将最小的元素交换到待排序列的第一个位置(或将最大的元素交换到待排序列的最后一个位置); 下一趟冒泡时,前一趟确定的最小元素不再参与比较,每趟冒泡的结果是把序列中的最小元素(或最大元素)放到了序列的最终位置。 ……这样最多做n - 1趟冒泡就能把所有元素排好序。 如若有一趟没有元素交换位置,则可提前说明已排好序。 public void bubbleSort(int[] arr){ //n-1 趟冒泡 for (int i = 0; i < arr.length-1; i++) { boolean flag=false; //冒泡 for (int j = arr.length-1; j >i ; j--) { if (arr[j-1]>arr[j]){ swap(arr,j-1,j); flag=true; } } //本趟遍历后没有发生交换,说明表已经有序 if (!flag){ return; } } } private void swap(int[] arr,int i,int j){ int temp=arr[i]; arr[i]=arr[j]; arr[j]=temp; } 归并排序 数组归并排序 基本思想: 将待排序的数组视为多个有序子表,每个子表的长度为 1,通过两两归并逐步合并成一个有序数组。 实现思路 分解:递归地将数组拆分成两个子数组,直到每个子数组只有一个元素。 合并:将两个有序子数组合并为一个有序数组。 时间复杂度: O(n log n),无论最坏、最好、平均情况。 public class MergeSort { /** * 归并排序(入口函数) * @param arr 待排序数组 */ public static void mergeSort(int[] arr) { if (arr == null || arr.length <= 1) { return; // 边界条件 } int[] temp = new int[arr.length]; // 辅助数组 mergeSort(arr, 0, arr.length - 1, temp); } private static void mergeSort(int[] arr, int left, int right, int[] temp) { if (left < right) { int mid = (right + left) / 2; mergeSort(arr, left, mid, temp); // 递归左子数组 mergeSort(arr, mid + 1, right, temp); // 递归右子数组 merge(arr, left, mid, right, temp); // 合并两个有序子数组 } } private static void merge(int[] arr, int left, int mid, int right, int[] temp) { int i = left; // 左子数组起始指针 int j = mid + 1; // 右子数组起始指针 int t = 0; // 辅助数组指针 // 1. 按序合并两个子数组到temp while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { // 注意等号保证稳定性 temp[t++] = arr[i++]; } else { temp[t++] = arr[j++]; } } // 2. 将剩余元素拷贝到temp while (i <= mid) { temp[t++] = arr[i++]; } while (j <= right) { temp[t++] = arr[j++]; } // 3. 将temp中的数据复制回原数组 t = 0; while (left <= right) { arr[left++] = temp[t++]; } } } 链表归并排序 // 简易链表归并排序示意 ListNode sortList(ListNode head) { if (head == null || head.next == null) return head; // ① 快慢指针找中点并断链 ListNode slow = head, fast = head.next; while (fast != null && fast.next != null) { slow = slow.next; fast = fast.next.next; } ListNode mid = slow.next; slow.next = null; // ② 递归排序左右两段 ListNode left = sortList(head); ListNode right = sortList(mid); // ③ 合并 return merge(left, right); } ListNode merge(ListNode a, ListNode b) { ListNode dummy = new ListNode(-1), p = dummy; while (a != null && b != null) { if (a.val <= b.val) { p.next = a; a = a.next; } else { p.next = b; b = b.next; } p = p.next; } p.next = (a != null ? a : b); return dummy.next; } 快慢指针找 “中点” 和找 “环” 的出发点为什么会不一样? 目标 常见写法 为什么这么设 若改成另一种写法会怎样 拆链/找中点(归并排序、回文检测等) slow = headfast = head.next - 偶数长度更均匀: len = 4 → 最终 slow 停在第 2 个结点(左半长 2,右半长 2)- mid = slow.next 一定非 null(当链长 ≥ 2),递归不会拿到空指针 - fast = head 时 len = 4 → slow 停在第 3 个结点(左半长 3,右半长 1),越分越偏; len = 2 → 左 1 右 0,也能跑,但更不平衡 检测环 slow = headfast = head - 只要两指针步幅不同,就会在环内相遇;- 起点放哪都行,写成同一起点最直观,也少一次空指针判断 如果写成 fast = head.next 也能检测环,但需先判断 head.next 是否为空,代码更啰嗦;并且两指针初始就“错开一步”,相遇时步数不同,求环长或入环点时要再做偏移 总之:自己模拟一遍,奇数和偶数的情况。 堆排序 下滤 从一个节点出发,如果它不满足堆的性质(父节点比子节点小——针对最大堆),就和它的较大子节点交换, 然后继续向下检查,直到满足堆性质或到达叶子节点。 堆排序示例 初始数组:[7, 3, 4, 2, 6, 8] 1️⃣ 建堆(Build Max Heap) 使整个数组满足“父节点 ≥ 子节点”的性质。 从最后一个非叶子节点开始下滤(i = n/2 - 1 = 2) (1) i = 2 → 元素 4 子节点:5=8 → 8 比 4 大 → 交换 → [7, 3, 8, 2, 6, 4] (2) i = 1 → 元素 3 子节点:3=2, 4=6 → 最大子节点为 6 → 交换 → [7, 6, 8, 2, 3, 4] (3) i = 0 → 元素 7 子节点:1=6, 2=8 → 最大子节点是 8 → 交换 → [8, 6, 7, 2, 3, 4] 建堆完成(最大堆) 2️⃣ 交换堆顶与末尾元素 把最大值放到数组末尾,相当于固定下来了。 3️⃣ 调整堆(Heapify) 重新调整剩余部分为最大堆。 4️⃣ 重复步骤 2 和 3,直到排序完成。 基数排序 时间复杂度: O(d × (n + k)) 其中 d 是数字的位数,k 是每位的取值范围(例如 0–9)。 排序0-999范围的整数: 创建10个桶(对应数字0-9) 按个位数字分配到桶中 按十位数字重新分配 按百位数字最后分配 按顺序收集桶中元素 示例: [352, 143, 129, 457, 65, 97, 8, 452, 72, 290] 第一步:按个位数分配 桶0: 290 桶1: 桶2: 352, 452, 72 桶3: 143 桶4: 桶5: 65 桶6: 桶7: 457, 97 桶8: 8 桶9: 129 收集结果:[290, 352, 452, 72, 143, 65, 457, 97, 8, 129] 第二步:按十位数分配 桶0: 8 桶1: 桶2: 129 桶3: 桶4: 143 桶5: 352, 452, 457 桶6: 65 桶7: 72 桶8: 桶9: 290, 97 收集结果:[8, 129, 143, 352, 452, 457, 65, 72, 290, 97] 第三步:按百位数分配 桶0: 8, 65, 72, 97 桶1: 129, 143 桶2: 290 桶3: 352 桶4: 452, 457 桶5: 桶6: 桶7: 桶8: 桶9: 收集结果:[8, 65, 72, 97, 129, 143, 290, 352, 452, 457] 数组排序 1)默认升序: Arrays.sort(array) 会对整个数组升序排序。 也可以指定区间 [fromIndex, toIndex),只排序部分数组。 import java.util.Arrays; public class ArraySortExample { public static void main(String[] args) { int[] numbers = {5, 2, 9, 1, 5, 6}; Arrays.sort(numbers); // 全部升序排序 System.out.println(Arrays.toString(numbers)); // [1, 2, 5, 5, 6, 9] Arrays.sort(numbers, 1, 4); // 只对下标 [1,4) → {2,9,1} 排序 System.out.println(Arrays.toString(numbers)); } } 2)自定义降序: 如果数组元素是 对象类型(如 Integer[]、String[] 或自定义类),可以直接使用 Comparator 实现复杂排序规则。 import java.util.*; public class DescendingSortExample { public static void main(String[] args) { Integer[] arr = {5, 2, 9, 1, 5, 6}; // 使用 Comparator + Lambda 实现降序 Arrays.sort(arr, (a, b) -> Integer.compare(b, a)); // 或者使用内置的 reverseOrder() Arrays.sort(arr, Collections.reverseOrder()); // 也可以指定区间 [1,4),对 {2,9,1} 排序 Arrays.sort(arr, 1, 4, Collections.reverseOrder()); System.out.println(Arrays.toString(arr)); } } 3)基本类型数组的降序 Arrays.sort() 对基本类型(int[]、double[] 等)只支持 升序。 如果要降序,需要先升序,再反转数组。 public class DescendingPrimitiveSort { public static void main(String[] args) { int[] arr = {5, 2, 9, 1, 5, 6}; // 先排序(升序) Arrays.sort(arr); // 反转数组 for (int i = 0; i < arr.length / 2; i++) { int temp = arr[i]; arr[i] = arr[arr.length - 1 - i]; arr[arr.length - 1 - i] = temp; } // 输出结果 System.out.println(Arrays.toString(arr)); } } 集合排序 java 里通常说的“集合”,是指 实现了 java.util.Collection 接口的类,以及 Map 相关的类。 1)自然顺序排序(默认升序): Collections.sort(numbers); 等价于: numbers.sort(null); // Java 8 推荐写法 适用于元素实现了 Comparable 接口(如 Integer、String)。 2)降序排序 Collections.sort(numbers, Collections.reverseOrder()); 或者: numbers.sort((a, b) -> Integer.compare(b,a)); 3)自定义降序(Comparator + Lambda) List<String> names = Arrays.asList("Tom", "Jerry", "Alice", "Bob"); // 按字符串长度升序 names.sort((s1, s2) -> Integer.compare(s1.length(), s2.length())); 补充: Comparator.reverseOrder() // `Comparator<T>` 接口的静态方法 //等价于 Collections.reverseOrder() 自定义排序Comparator 说明 要实现接口自定义排序,必须实现 Comparator<T> 接口的 compare(T o1, T o2) 方法。 @FunctionalInterface public interface Comparator<T> { int compare(T o1, T o2); // 唯一抽象方法 ✅ // 以下都是 default 或 static 方法(不是抽象方法) default Comparator<T> reversed() { ... } static <T extends Comparable<? super T>> Comparator<T> reverseOrder() { ... } } Comparator 接口中定义的 compare(T o1, T o2) 方法返回一个整数(非布尔值!!),这个整数的正负意义如下: 如果返回负数,说明 o1 排在 o2前面。 如果返回零,说明 o1 等于 o2。 如果返回正数,说明 o1 排在 o2后面。 示例:对象排序(按年龄升序) import java.util.*; class Person { String name; int age; Person(String name, int age) { this.name = name; this.age = age; } public String toString() { return name + " (" + age + ")"; } } public class ComparatorExample { public static void main(String[] args) { List<Person> people = Arrays.asList( new Person("Alice", 25), new Person("Bob", 20), new Person("Charlie", 30) ); // 使用 Comparator + Lambda 按年龄排序 people.sort((p1, p2) -> Integer.compare(p1.age, p2.age)); System.out.println(people); // [Bob (20), Alice (25), Charlie (30)] } } 补充:String比较 a.compareTo(b); 题型 常见术语 子串(Substring):子字符串 是字符串中连续的 非空 字符序列 回文串(Palindrome):回文 串是向前和向后读都相同的字符串。 子序列((Subsequence)):可以通过删除原字符串中任意个字符(不改变剩余字符的相对顺序)得到的序列,不要求连续。例如 "abc" 的 "ac" 就是一个子序列。 子数组:数组中连续的部分。 前缀 (Prefix) :从字符串起始位置开始的连续字符序列,如 "leetcode" 的前缀 "lee"。 字母异位词 (Anagram):由相同字符组成但排列顺序不同的字符串。例如 "abc" 与 "cab" 就是异位词。 子集、幂集:数组的 子集 是从数组中选择一些元素(可能为空)。例如,对于集合 S = {1, 2},其幂集为: { ∅, {1}, {2}, {1, 2} },子集有{1} 链表 “头插法”本质上就是把新节点“插”到已构建链表的头部 1.反转链表 2.从头开始构建链表(逆序插入) ListNode buildList(int[] arr) { ListNode head = null; for (int i = 0; i < arr.length; i++) { ListNode node = new ListNode(arr[i]); node.next = head; // 头插:新节点指向原 head head = node; // head 指向新节点 } return head; } // 结果链表的顺序是 arr 最后一个元素在最前面,如果你想保持原序,可以倒序遍历 arr。 输入:arr[0] -> arr[1] -> … -> arr[n-1] 输出:arr[n-1]-> arr[n-2]-> …->arr[0] Floyd判环法:快慢指针 public boolean hasCycle(ListNode head) { if (head == null) return false; // 快慢指针都从 head 出发 ListNode slow = head; ListNode fast = head; // 当 fast 或 fast.next 为 null 时,说明已经到链表末尾,无环 while (fast != null && fast.next != null) { slow = slow.next; // 慢指针走一步 fast = fast.next.next; // 快指针走两步 // 每走一步就检查一次相遇 if (slow == fast) { return true; // 相遇则有环 } } return false; // 跳出循环说明没有环 } 何时需要定义dummy节点? 当你的操作有可能“改”到原始的头节点(插入到最前面,或删除掉第一个节点)时,就定义一个 dummy,把它挂在 head 之前,之后所有插入/删除都操作 dummy.next 及其后继,最后返回 dummy.next。 哈希 问题分析: 确定是否需要快速查找或存储数据。 判断是否需要统计元素频率或检查元素是否存在。 适用场景 快速查找: 当需要频繁查找元素时,哈希表可以提供 O(1) 的平均时间复杂度。 统计频率: 统计元素出现次数时,哈希表是常用工具。 去重: 需要去除重复元素时,HashSet 可以有效实现。 双指针 题型: 同向双指针:两个指针从同一侧开始移动,通常用于滑动窗口或链表问题。 对向双指针:两个指针从两端向中间移动,通常用于有序数组或回文问题。重点是考虑移动哪个指针可能优化结果!!! 快慢指针:两个指针以不同速度移动,通常用于链表中的环检测或中点查找。 适用场景: 有序数组的两数之和: 在对向双指针的帮助下,可以在 O(n) 时间内找到两个数,使它们的和等于目标值。 滑动窗口: 用于解决子数组或子字符串问题,如同向双指针可以在 O(n) 时间内找到满足条件的最短或最长子数组。 链表中的环检测: 快慢指针可以用于检测链表中是否存在环,并找到环的起点。 回文问题: 对向双指针可以用于判断字符串或数组是否是回文。 合并有序数组或链表: 双指针可以用于合并两个有序数组或链表,时间复杂度为 O(n)。 前缀和 前缀和的定义 定义前缀和 preSum[i] 为数组 nums 从索引 0 到 i 的元素和,即 $$ \text{preSum}[i] = \sum_{j=0}^{i} \text{nums}[j] $$ 子数组和的关系 对于任意子数组 nums[i+1..j](其中 0 ≤ i < j < n),其和可以表示为 $$ \text{sum}(i+1,j) = \text{preSum}[j] - \text{preSum}[i] $$ 当这个子数组的和等于 k 时,有 $$ \text{preSum}[j] - \text{preSum}[i] = k $$ 即 $$ \text{preSum}[i] = \text{preSum}[j] - k $$ $\text{preSum}[j] - k$表示 "以当前位置结尾的子数组和为k" 利用哈希表存储前缀和 我们可以使用一个哈希表 prefix 来存储每个前缀和出现的次数。 初始时,prefix[0] = 1,表示前缀和为 0 出现一次(对应空前缀)。 遍历数组,每计算一个新的前缀和 preSum,就查看 preSum - k 是否在哈希表中。如果存在,则说明之前有一个前缀和等于 preSum - k,那么从该位置后一个位置到当前索引的子数组和为 k,累加其出现的次数。 时间复杂度 该方法只需要遍历数组一次,时间复杂度为 O(n)。 遍历二叉树 递归法中序 public void inOrderTraversal(TreeNode root, List<Integer> list) { if (root != null) { inOrderTraversal(root.left, list); // 遍历左子树 list.add(root.val); // 访问当前节点 inOrderTraversal(root.right, list); // 遍历右子树 } } 迭代法中序 public void inOrderTraversalIterative(TreeNode root, List<Integer> list) { Deque<TreeNode> stack = new ArrayDeque<>(); TreeNode curr = root; while (curr != null || !stack.isEmpty()) { // 一路向左入栈 while (curr != null) { stack.push(curr); // push = addFirst curr = curr.left; } // 弹出栈顶并访问 curr = stack.pop(); // pop = removeFirst list.add(curr.val); // 转向右子树 curr = curr.right; } } 迭代法前序 public void preOrderTraversalIterative(TreeNode root, List<Integer> list) { if (root == null) return; Deque<TreeNode> stack = new ArrayDeque<>(); stack.push(root); while (!stack.isEmpty()) { TreeNode node = stack.pop(); list.add(node.val); // 先访问当前节点 // 注意:先压右子节点,再压左子节点 // 因为栈是“后进先出”的,先弹出的是左子节点 if (node.right != null) { stack.push(node.right); } if (node.left != null) { stack.push(node.left); } } } 层序遍历BFS public List<List<Integer>> levelOrder(TreeNode root) { List<List<Integer>> result = new ArrayList<>(); if (root == null) return result; Queue<TreeNode> queue = new LinkedList<>(); queue.offer(root); while (!queue.isEmpty()) { int levelSize = queue.size(); List<Integer> level = new ArrayList<>(); for (int i = 0; i < levelSize; i++) { TreeNode node = queue.poll(); level.add(node.val); if (node.left != null) { queue.offer(node.left); } if (node.right != null) { queue.offer(node.right); } } result.add(level); } return result; } 回溯法 回溯算法用于 搜索一个问题的所有的解 ,即爆搜(暴力解法),通过深度优先遍历的思想实现。核心思想是: 1.逐步构建解答: 回溯算法通过逐步构造候选解,当构造的部分解满足条件时继续扩展;如果发现当前解不符合要求,则“回溯”到上一步,尝试其他可能性。 2.剪枝(Pruning): 在构造候选解的过程中,算法会判断当前部分解是否有可能扩展成最终的有效解。如果判断出无论如何扩展都不可能得到正确解,就立即停止继续扩展该分支,从而节省计算资源。 3.递归调用 回溯通常通过递归来实现。递归函数在每一层都尝试不同的选择,并在尝试失败或达到终点时返回上一层重新尝试其他选择。 例:以数组 [1, 2, 3] 的全排列为例。 先写以 1 开头的全排列,它们是:[1, 2, 3], [1, 3, 2],即 1 + [2, 3] 的全排列(注意:递归结构体现在这里); 再写以 2 开头的全排列,它们是:[2, 1, 3], [2, 3, 1],即 2 + [1, 3] 的全排列; 最后写以 3 开头的全排列,它们是:[3, 1, 2], [3, 2, 1],即 3 + [1, 2] 的全排列。 public class Permute { public List<List<Integer>> permute(int[] nums) { List<List<Integer>> res = new ArrayList<>(); // 用来标记数组中数字是否被使用 boolean[] used = new boolean[nums.length]; List<Integer> path = new ArrayList<>(); backtrack(nums, used, path, res); return res; } private void backtrack(int[] nums, boolean[] used, List<Integer> path, List<List<Integer>> res) { // 当path中元素个数等于nums数组的长度时,说明已构造出一个排列 if (path.size() == nums.length) { res.add(new ArrayList<>(path)); return; } // 遍历数组中的每个数字 for (int i = 0; i < nums.length; i++) { // 如果该数字已经在当前排列中使用过,则跳过 if (used[i]) { continue; } // 选择数字nums[i] used[i] = true; path.add(nums[i]); // 递归构造剩余的排列 backtrack(nums, used, path, res); // 回溯:撤销选择,尝试其他数字 path.remove(path.size() - 1); used[i] = false; } } } 大小根堆 题目描述:给定一个整数数组 nums 和一个整数 k,返回出现频率最高的前 k 个元素,返回顺序可以任意。 解法一:大根堆(最大堆) 思路: 使用 HashMap 统计每个元素的出现频率。 构建一个大根堆(PriorityQueue + 自定义比较器),根据频率降序排列。 将所有元素加入堆中,弹出前 k 个元素即为答案。 适合场景: 实现简单,适用于对全部元素排序后取前 k 个。 时间复杂度:O(n log n),因为需要将所有 n 个元素都加入堆。 **解法二:小根堆(最小堆)**推荐 思路: 使用 HashMap 统计频率。 构建一个小根堆,堆中仅保存前 k 个高频元素。 遍历每个元素: 如果堆未满,直接加入。 如果当前元素频率大于堆顶(最小频率),则弹出堆顶,加入当前元素。 最终堆中保存的就是前 k 个高频元素。 方法 适合场景 时间复杂度 空间复杂度 大根堆 k ≈ n,简单易写 O(n log n) O(n) 小根堆 k ≪ n,更高效 O(n log k) O(n) 动态规划 解题步骤: 确定 dp 数组以及下标的含义(很关键!不跑偏) 目的:明确 dp 数组中存储的状态或结果。 关键:下标往往对应问题中的一个“阶段”或“子问题”,而数组的值则表示这一阶段的最优解或累计结果。 示例:在背包问题中,可以设 dp[i] 表示前 i 个物品能够达到的最大价值。 确定递推公式 目的:找到状态之间的转移关系,表明如何从已解决的子问题求解更大规模的问题。 关键:分析每个状态可能来源于哪些小状态,写出数学或逻辑表达式。 示例:对于 0-1 背包问题,递推公式通常为 $$ dp[i]=max(dp[i],dp[i−weight]+value) $$ dp 数组如何初始化 目的:给定初始状态,为所有可能情况设置基础值。 关键:通常初始化基础的情况(如 dp[0]=0),或者用极大或极小值标示未计算状态。 示例:在求最短路径问题中,可以用较大值(如 infinity)初始化所有状态,然后设定起点状态为 0。 确定遍历顺序 目的:按照正确的顺序计算每个状态,确保依赖的子问题都已经计算完毕。 关键:遍历顺序需要与递推公式保持一致,既可以是正向(从小到大)也可以是反向(从大到小),取决于问题要求。 示例:对背包问题,为避免重复计算,每个物品的更新通常采用反向遍历。 举例推导 dp 数组 目的:通过一个具体例子来演示递推公式的应用,直观理解每一步计算。 关键:选择简单案例,从初始化、更新到最终结果展示整个过程。 示例:对一个简单的路径问题,展示如何从起点逐步更新 dp 数组,最后得到终点的最优解。 例题 题目: 746. 使用最小花费爬楼梯 (MinCostClimbingStairs) 描述:给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。 你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。 请你计算并返回达到楼梯顶部的最低花费。 示例 2: 输入:cost = [10,15,20] 输出:15 解释:你将从下标为 1 的台阶开始。 支付 15 ,向上爬两个台阶,到达楼梯顶部。 总花费为 15 。 链接:https://leetcode.cn/problems/min-cost-climbing-stairs/ 1.确定dp数组以及下标的含义 dp[i]的定义:到达第i台阶所花费的最少体力为dp[i]。 2.确定递推公式 可以有两个途径得到dp[i],一个是dp[i-1] 一个是dp[i-2]。 dp[i - 1] 跳到 dp[i] 需要花费 dp[i - 1] + cost[i - 1]。 dp[i - 2] 跳到 dp[i] 需要花费 dp[i - 2] + cost[i - 2]。 那么究竟是选从dp[i - 1]跳还是从dp[i - 2]跳呢? 一定是选最小的,所以dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]); 3.dp数组如何初始化 看一下递归公式,dp[i]由dp[i - 1],dp[i - 2]推出,既然初始化所有的dp[i]是不可能的,那么只初始化dp[0]和dp[1]就够了,其他的最终都是dp[0]、dp[1]推出。 由“你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。” =》初始化 dp[0] = 0,dp[1] = 0 4.确定遍历顺序 因为是模拟台阶,而且dp[i]由dp[i-1]dp[i-2]推出,所以是从前到后遍历cost数组就可以了。 5.举例推导dp数组 拿示例:cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] ,来模拟一下dp数组的状态变化,如下: 背包问题 总结:背包问题不仅可以求能装的物品的最大价值,还可以求背包是否可以装满,还可以求组合总和。 背包是否可以装满示例说明 假设背包容量为 10,物品的重量分别为 [3, 4, 7]。我们希望判断是否可以恰好填满容量 10。 其中 dp[j] 表示在容量 j 下,能装入的最大重量(保证不超过 j)。如果dp[10]=10,代表能装满 public boolean canFillBackpack(int[] weights, int capacity) { // dp[j] 表示在不超过背包容量 j 的前提下,能装入的最大重量 int[] dp = new int[capacity + 1]; // 初始状态: 背包容量为0时,能够装入的重量为0,其他位置初始为0 // 遍历每一个物品(0/1背包,每个物品只能使用一次) for (int i = 0; i < weights.length; i++) { // 逆序遍历背包容量,防止当前物品被重复使用 for (int j = capacity; j >= weights[i]; j--) { dp[j] = Math.max(dp[j], dp[j - weights[i]] + weights[i]); } } // 如果 dp[capacity] 恰好等于 capacity,则说明背包正好被装满 return dp[capacity] == capacity; } 求组合总和 统计数组中有多少种组合(子集)使得其和正好为 P ? dp[j] 表示从数组中选取若干个数,使得这些数的和正好为 j 的方法数。 状态转移: 对于数组中的每个数字 num,从 dp 数组后向前(逆序)遍历,更新: dp[j]=dp[j]+dp[j−num] 这里的意思是: 如果不选当前数字,方法数保持不变; 如果选当前数字,那么原来凑出和 j−num 的方案都可以扩展成凑出和 j 的方案。 初始条件: dp[0] = 1,代表凑出和为 0 只有一种方式,即不选任何数字。 代码随想录 完全背包是01背包稍作变化而来,即:完全背包的物品数量是无限的。 0/1背包(一) 描述:有n件物品和一个最多能背重量为 w 的背包。第 i 件物品的重量是 weight[i],得到的价值是 value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。 1.确定dp数组以及下标的含义 因为有两个维度需要分别表示:物品 和 背包容量,所以 dp为二维数组。 即 dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。 2. 确定递推公式 考虑 dp[i][j],有两种情况: 不放物品i:背包容量为 j ,里面不放物品 i 的最大价值是 dp[i - 1][j]。 放物品i:背包空出物品i的容量后,背包容量为 j - weight[i],dp[i - 1][j - weight[i]] 为背包容量为j - weight[i] 且不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值 递归公式: dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 3. dp数组如何初始化 (1)首先从 dp[i][j] 的定义出发,如果背包容量 j 为0的话,即 dp[i][0] ,无论是选取哪些物品,背包价值总和一定为0。 (2)由状态转移方程 dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出i 是由 i-1 推导出来,那么 i 为0的时候就一定要初始化。 此时就看存放编号0的物品的时候,各个容量的背包所能存放的最大价值。 (3)其他地方初始化为0 4.确定遍历顺序 都可以,但推荐先遍历物品 // weight数组的大小 就是物品个数 for(int i = 1; i < weight.size(); i++) { // 遍历物品 for(int j = 0; j <= bagweight; j++) { // 遍历背包容量 if (j < weight[i]) dp[i][j] = dp[i - 1][j]; else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); } } 5.举例推导dp数组 略 代码: public int knapsack(int[] weight, int[] value, int capacity) { int n = weight.length; // 物品的总个数 // 定义二维 dp 数组: // dp[i][j] 表示从下标为 [0, i] 的物品中任意选择,放入容量为 j 的背包中,能够获得的最大价值 int[][] dp = new int[n][capacity + 1]; // 1. 初始化第 0 行:只考虑第 0 个物品的情况 // 当背包容量 j >= weight[0] 时,可以选择放入第 0 个物品,价值为 value[0];否则为 0 for (int j = 0; j <= capacity; j++) { if (j >= weight[0]) { dp[0][j] = value[0]; } else { dp[0][j] = 0; } } // 2. 状态转移:从第 1 个物品开始,逐步填表 // 遍历物品,物品下标从 1 到 n-1 for (int i = 1; i < n; i++) { // 遍历背包容量,从 0 到 capacity for (int j = 0; j <= capacity; j++) { // 情况一:不放第 i 个物品,则最大价值不变,继承上一行的值 dp[i][j] = dp[i - 1][j]; // 情况二:如果当前背包容量 j 大于等于物品 i 的重量,则考虑放入当前物品 if (j >= weight[i]) { dp[i][j] = Math.max(dp[i][j], dp[i - 1][j - weight[i]] + value[i]); } } } // 返回考虑所有物品,背包容量为 capacity 时的最大价值 return dp[n - 1][capacity]; } 0/1背包(二) 可以将二维 dp 优化为一维 dp 的典型条件包括: 1.状态转移只依赖于之前的状态(例如上一行或上一个层次),而不是当前行中动态更新的状态。 例如在 0/1 背包问题中,二维 dp[i][j] 只依赖于 dp[i-1][j] 和 dp[i-1][j - weight[i]]。 2.存在确定的遍历顺序(例如逆序或正序)能够确保在更新一维 dp 时,所依赖的值不会被当前更新覆盖。 逆序遍历:例如 0/1 背包问题,为了防止同一个物品被重复使用,需要对容量 j 从大到小遍历,确保 dp[j - weight] 的值还是上一轮(上一行)的。 正序遍历:在一些问题中,如果状态更新不会导致当前状态被重复利用(例如完全背包问题),可以顺序遍历。 3.状态数足够简单,不需要记录多维信息,仅一个维度的状态即可准确表示和转移问题状态。 1.确定 dp 数组以及下标的含义 使用一维 dp 数组 dp[j] 表示「在当前考虑的物品下,背包容量为 j 时能够获得的最大价值」。 2.确定递推公式 当考虑当前物品 i (重量为 weight[i],价值为 value[i])时,有两种选择: 不选当前物品 i: 此时的最大价值为 dp[j](即前面的状态没有变化)。 选当前物品 i: 当背包容量至少为 weight[i] 时,如果选择物品 i ,剩余容量变为 j - weight[i],则最大价值为 dp[j - weight[i]] 加上 value[i]。 因此,状态转移方程为: $$ dp[j]=max(dp[j], dp[j−weight[i]]+value[i]) $$ **3.dp 数组如何初始化** dp[0] = 0,表示当背包容量为 0 时,能获得的最大价值自然为 0。 对于其他容量 dp[j] ,初始值也设为 0,dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了。确保值不被初始值覆盖即可。 4.一维dp数组遍历顺序 外层遍历物品: 从第一个物品到最后一个物品,依次做决策。 内层遍历背包容量(逆序遍历): 遍历容量从 capacity 到当前物品的重量,进行状态更新。 逆序遍历的目的在于确保当前物品在更新过程中只会被使用一次,因为 dp[j - weight[i]] 代表的是上一轮(当前物品未使用前)的状态,不会被当前物品更新后的状态覆盖。 假设物品 $w=2$, $v=3$,背包容量 $C=5$。 错误的正序遍历($j=2 \to 5$) $j=2$: $dp[2] = \max(0, dp[0]+3) = 3$ $\Rightarrow dp = [0, 0, 3, 0, 0, 0]$ $j=4$: $dp[4] = \max(0, dp[2]+3) = 6$ $\Rightarrow$ 错误:物品被重复使用两次! 5.举例推导dp数组 略 代码: public int knapsack(int[] weight, int[] value, int capacity) { int n = weight.length; // 定义 dp 数组,dp[j] 表示背包容量为 j 时的最大价值 int[] dp = new int[capacity + 1]; // 初始化:所有 dp[j] 初始为0,dp[0] = 0(无须显式赋值) // 外层:遍历每一个物品 for (int i = 0; i < n; i++) { // 内层:逆序遍历背包容量,保证每个物品只被选择一次 for (int j = capacity; j >= weight[i]; j--) { // 更新状态:选择不放入或者放入当前物品后的最大价值 dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]); } } // 返回背包总容量为 capacity 时获得的最大价值 return dp[capacity]; } 完全背包(一) 完全背包和01背包问题唯一不同的地方就是,每种物品有无限件。 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 例:背包最大重量为4,物品为: 物品 重量 价值 物品0 1 15 物品1 3 20 物品2 4 30 1. 确定dp数组以及下标的含义 dp[i][j] 表示从下标为[0-i]的物品,每个物品可以取无限次,放进容量为j的背包,价值总和最大是多少。 2. 确定递推公式 不放物品i:背包容量为j,里面不放物品i的最大价值是dp[i - 1][j]。 放物品i:背包空出物品i的容量后,背包容量为j - weight[i],dp[i][j - weight[i]] 为背包容量为j - weight[i]且不放物品i的最大价值,那么dp[i][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值 递推公式: dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]); 01背包中是 dp[i - 1][j - weight[i]] + value[i]) 因为在完全背包中,物品是可以放无限个,所以 即使空出物品1空间重量,那背包中也可能还有物品1,所以此时我们依然考虑放 物品0 和 物品1 的最大价值即: dp[1][1], 而不是 dp[0][1]。而0/1背包中,既然空出物品1,那背包中也不会再有物品1,即dp[0][1]。 for (int i = 1; i < n; i++) { for (int j = 0; j <= capacity; j++) { // 不选物品 i,价值不变 dp[i][j] = dp[i - 1][j]; // 如果当前背包容量 j 能放下物品 i,则考虑选取物品 i(完全背包内层循环正序或逆序都可以,但这里通常建议正序) if (j >= weight[i]) { // 注意:这里选取物品 i 后仍然可以继续选取物品 i, // 所以状态转移方程为 dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]) dp[i][j] = Math.max(dp[i][j], dp[i][j - weight[i]] + value[i]); } } } 3. dp数组如何初始化 如果背包容量j为0的话,即dp[i][0],无论是选取哪些物品,背包价值总和一定为0。 由递推公式,有一个方向 i 是由 i-1 推导出来,那么i为0的时候就一定要初始化。即:存放编号0的物品的时候,各个容量的背包所能存放的最大价值。 for (int j = 0; j <= capacity; j++) { // 当 j 小于第 0 个物品重量时,无法选取,所以价值为 0 if (j < weight[0]) { dp[0][j] = 0; } else { // 完全背包允许多次使用物品 0,所以递归地累加 dp[0][j] = dp[0][j - weight[0]] + value[0]; } } 4. 确定遍历顺序 先物品或先背包容量都可,但推荐先物品。 完全背包(二) 压缩成一维dp数组,也就是将上一层拷贝到当前层。 将上一层dp[i-1] 的那一层拷贝到 当前层 dp[i] ,那么递推公式由 dp[i][j] = max(dp[i - 1][j], dp[i][j - weight[i]] + value[i]) 变成: dp[i][j] = max(dp[i][j], dp[i][j - weight[i]] + value[i]) 压缩成一维,即dp[j] = max(dp[j], dp[j - weight[i]] + value[i]) 根据题型选择先遍历物品或者背包, 如果求组合数就是外层for循环遍历物品,内层for遍历背包。 如果求排列数就是外层for遍历背包,内层for循环遍历物品。 组合数(顺序不同的序列视为相同)排列数(顺序不同的序列视为不同)排列数大于等于组合数!!!。 内层循环正序,不要逆序!因为要利用已经更新的dp数组,允许同一物品重复使用! 注意,完全背包和0/1背包的一维dp形式的递推公式一样,但是遍历顺序不同!! public int completeKnapsack(int[] weight, int[] value, int capacity) { int n = weight.length; // dp[j] 表示容量为 j 时的最大价值,初始化为 0 int[] dp = new int[capacity + 1]; // 遍历每件物品 for (int i = 0; i < n; i++) { // 完全背包:正序遍历容量 for (int j = weight[i]; j <= capacity; j++) { // 如果拿 i 号物品,更新 dp[j] dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]); } } return dp[capacity]; } 多重背包 有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。 重量 价值 数量 物品0 1 15 2 物品1 3 20 3 物品2 4 30 2 把每种物品按数量展开,就转化为0/1背包问题了!相当于物品0-a 物品0-b 物品1-a ....,每个只能用一次。 public int multipleKnapsack(int V, int[] weight, int[] value, int[] count) { // 将每件物品按数量展开成 0/1 背包的多个物品 List<Integer> wList = new ArrayList<>(); List<Integer> vList = new ArrayList<>(); for (int i = 0; i < weight.length; i++) { for (int k = 0; k < count[i]; k++) { wList.add(weight[i]); vList.add(value[i]); } } // 0/1 背包 DP int[] dp = new int[V + 1]; int N = wList.size(); for (int i = 0; i < N; i++) { int wi = wList.get(i); int vi = vList.get(i); for (int j = V; j >= wi; j--) { dp[j] = Math.max(dp[j], dp[j - wi] + vi); } } return dp[V]; } 并查集 for (int i = 0; i < 26; i++) { parent[i] = i; //初始化 } public void union(int[] parent, int index1, int index2) { // 先分别找到 index1 和 index2 的根节点,再把 root(index1) 的父指针指向 root(index2) parent[find(parent, index1)] = find(parent, index2); } //查找 index 元素所在集合的根节点(同时做路径压缩) public int find(int[] parent, int index) { // 当 parent[index] == index 时,说明已经是根节点 while (parent[index] != index) { // 路径压缩:将当前节点直接挂到它父节点的父节点上 // 这样可以让树变得更扁平,后续查找更快 parent[index] = parent[parent[index]]; // 跳到上一级,继续判断是否到根 index = parent[index]; } // 循环结束时,index 即为根节点下标 return index; } 快速幂 LeetCode 50. Pow(x, n) 实现函数 pow(x, n),即计算 x 的 n 次幂(x^n)。 输入:x = 2.00000, n = 10 输出:1024.00000 快速幂思想 核心思想: 快速幂就是把指数写成二进制,每一位对应一个“平方后的 x”,如果那一位是 1,就把它乘进结果里。 例子: n = 13 (二进制 1101) 13 = 8 + 4 + 1 x^13 = x^(8+4+1) = x^8 * x^4 * x^1 也就是说: 我们只需要把 x 不断平方,得到 x^1, x^2, x^4, x^8 ... 然后根据 n 的二进制位是否为 1,决定是否把这个幂次乘到答案里。 算法步骤 如果 n < 0,转换为 x = 1/x, n = -n。 (注意:n 可能是 Integer.MIN_VALUE,取负数会溢出,所以要先转成 long。) 初始化结果 ans = 1.0。 循环处理指数的每一位: 如果最低位是 1,就把当前的 x 累乘进结果。 每次循环后,x 自身平方,指数右移一位。 循环结束,返回结果。 JAVA实现 public class MyPow { public double myPow(double x, int n) { if (x == 0) return 0; if (n == 0) return 1; // 处理负指数,注意转为 long 防止溢出 long N = n; if (N < 0) { x = 1 / x; N = -N; } double ans = 1.0; while (N > 0) { if ((N & 1) == 1) { // 判断最低位是否为 1 ans *= x; } x *= x; // 翻倍:x, x^2, x^4, x^8 ... N >>= 1; // 右移一位,处理下一位 } return ans; } } ACM风格输入输出 ** * 题目描述 * * 给定一个整数数组 Array,请计算该数组在每个指定区间内元素的总和。 * * 输入描述 * * 第一行输入为整数数组 Array 的长度 n,接下来 n 行,每行一个整数,表示数组的元素。随后的输入为需要计算总和的区间下标:a,b (b > = a),直至文件结束。 * 输入示例: * 5 * 1 * 2 * 3 * 4 * 5 * 0 1 * 1 3 *输出: * 3 * 9 * 输出每个指定区间内元素的总和。 */ import java.util.*; import java.io.*; public class Main { public static void main(String[] args) throws IOException { // 快速 IO BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); PrintWriter out = new PrintWriter(System.out); String line; // 1)读数组长度 line = br.readLine(); if (line == null) return; int n = Integer.parseInt(line.trim()); // 2)读数组元素并构造前缀和 long[] prefix = new long[n + 1]; for (int i = 0; i < n; i++) { line = br.readLine(); if (line == null) throw new IOException("Unexpected EOF when reading array"); prefix[i + 1] = prefix[i] + Long.parseLong(line.trim()); } // 3)依次读查询直到 EOF // 每行两个整数 a, b (0 ≤ a ≤ b < n) while ((line = br.readLine()) != null) { line = line.trim(); if (line.isEmpty()) continue; StringTokenizer st = new StringTokenizer(line); int a = Integer.parseInt(st.nextToken()); int b = Integer.parseInt(st.nextToken()); // 区间和 = prefix[b+1] - prefix[a] long sum = prefix[b + 1] - prefix[a]; out.println(sum); } out.flush(); } } line.trim() 是把原 line 首尾的所有空白字符(空格、制表符、换行符等)都去掉之后的结果。 StringTokenizer st = new StringTokenizer(line);把一整行字符串 line 按默认的分隔符(空格、制表符、换行符等)拆成一个一个的“词”(token) StringTokenizer st = new StringTokenizer(line, ",;"); 第二个参数 ",;" 中的每个字符都会被当作分隔符;如果想把空白也当分隔符,可以在里边加上空格 " ,; " Scanner版本:简单,但效率低。 import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 把分隔符改成 “逗号 或 空白” 默认只能按空格分隔!!! sc.useDelimiter("[,\\s]+"); // 1)读数组长度 if (!sc.hasNextInt()) return; int n = sc.nextInt(); // 2)读数组元素并构造前缀和 long[] prefix = new long[n + 1]; for (int i = 0; i < n; i++) { prefix[i + 1] = prefix[i] + sc.nextLong(); } // 3)依次读查询直到 EOF while (sc.hasNextInt()) { int a = sc.nextInt(); int b = sc.nextInt(); long sum = prefix[b + 1] - prefix[a]; System.out.println(sum); } } } Scanner 是 按空白分隔符(空格、换行、制表符)来划分输入的。 也就是说,sc.nextInt() 会忽略一切空白,把下一个整数读出来,不管它是在同一行还是下一行。 sc.useDelimiter("[,\\s]+"); 这里的 [,] 就表示:分隔符可以是 , 这个字符。 [,\\s] 外面的 + 表示匹配“一个或多个” ,即有连续的空格、逗号它也能匹配。 Scanner 读取字符串 public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 用 next() 读 System.out.print("请输入两个单词(中间空格分隔): "); String word1 = sc.next(); // 读第一个单词 String word2 = sc.next(); // 读第二个单词 System.out.println("next() 得到: " + word1 + " 和 " + word2); sc.nextLine(); // 把上一次输入残余的换行符吃掉 // 用 nextLine() 读 System.out.print("请输入一整行文本: "); String line = sc.nextLine(); // 读整行 System.out.println("nextLine() 得到: " + line); } } //输入 //hello world //I love Java programming //输出: //请输入两个单词(中间空格分隔): next() 得到: hello 和 world //请输入一整行文本: nextLine() 得到: I love Java programming import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); sc.useDelimiter("[,\\s]+"); // 逗号或空白分隔 if (!sc.hasNextInt()) return; int n = sc.nextInt(); long[] arr = readArray(sc, n); // 只读输入 PrefixSum ps = new PrefixSum(arr); // 核心逻辑 StringBuilder out = new StringBuilder(); while (sc.hasNextInt()) { int a = sc.nextInt(); int b = sc.nextInt(); out.append(ps.query(a, b)).append('\n'); // 调用核心 } System.out.print(out.toString()); } // === IO 辅助:读取 n 个 long === private static long[] readArray(Scanner sc, int n) { long[] a = new long[n]; for (int i = 0; i < n; i++) a[i] = sc.nextLong(); return a; } // === 核心:前缀和与区间查询(不涉及 IO)=== static final class PrefixSum { private final long[] pref; // pref[i] = a[0..i-1] 之和 PrefixSum(long[] a) { pref = new long[a.length + 1]; for (int i = 0; i < a.length; i++) pref[i + 1] = pref[i] + a[i]; } /** 查询闭区间 [l, r] 的和 */ long query(int l, int r) { if (l < 0 || r >= pref.length - 1 || l > r) { throw new IllegalArgumentException("Invalid range: [" + l + ", " + r + "]"); } return pref[r + 1] - pref[l]; } } }
后端学习
zy123
1年前
0
14
0
2025-03-21
Redis
Redis Redis基本定义 Redis是一个基于内存的key-value结构数据库。Redis 是互联网技术领域使用最为广泛的存储中间件。 Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化的NoSql数据库(非关系型)。 典型场景: 热点数据缓存(商品/资讯/秒杀) 会话管理(Session) 排行榜/计数器 消息队列(Stream) NoSQL数据库: 键值型(Redis) 文档型(MongoDB) 列存储(HBase) 图数据库(Neo4j) 下载与使用 Redis安装包分为windows版和Linux版: Windows版下载地址:https://github.com/microsoftarchive/redis/releases Linux版下载地址: https://download.redis.io/releases/ 角色 作用 典型示例 Redis 服务端 数据存储的核心,负责接收/执行命令、管理内存、持久化数据等。需先启动服务端才能使用。 redis-server(默认监听 6379 端口) Redis 客户端 连接服务端并发送命令(如 GET/SET),获取返回结果。可以是命令行工具或代码库。 redis-cli、Java 的 Jedis 库 windows下服务启动/停止: 启动: redis-server.exe redis.windows.conf 这种方式关闭命令行后Redis服务又停止了! 解决方法:安装为 Windows 服务 redis-server --service-install redis.windows.conf --service-name Redis redis-server --service-start 停止: ctrl+c 客户端连接: 直接运行 redis-cli.exe 时,它会尝试连接 本机(127.0.0.1)的 Redis 服务端,并使用默认端口 6379。 等价于手动指定参数: redis-cli -h 127.0.0.1 -p 6379 指定连接: redis-cli -h <IP> -p <端口> -a <密码> redis-cli -h 192.168.1.100 -p 6379 -a yourpassword 退出连接:exit 修改Redis配置文件 设置Redis服务密码,修改redis.windows.conf(windows) redis.conf(linux) requirepass 123456 修改redis服务端口 port 6379 Redis客户端图形工具 默认提供的客户端连接工具界面不太友好,可以使用Another Redis Desktop Manager.exe ,类似Navicat连mysql。 Redis数据类型 Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型: 字符串(string):普通字符串,Redis中最简单的数据类型 哈希(hash):也叫散列,类似于Java中的HashMap结构。(套娃) 列表(list):按照插入顺序排序,可以有重复元素,类似于Java中的LinkedList 集合(set):无序集合,没有重复元素,类似于Java中的HashSet(求交集) 有序集合(sorted set/zset):集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素(排行榜) Redis常用命令 通用命令 Redis的通用命令是不分数据类型的,都可以使用的命令: KEYS pattern 查找所有符合给定模式( pattern)的 key pattern:匹配模式,支持通配符: *:匹配任意多个字符(包括空字符) ?:匹配单个字符 [abc]:匹配 a、b 或 c 中的任意一个字符 [a-z]:匹配 a 到 z 之间的任意一个字符 KEYS user:* #可以返回 形如 "user:1" "user:2" 的 key KEYS * #查找所有key 在线上不要用 KEYS prefix:*,它是阻塞全库扫描,键多时会卡住 Redis。 EXISTS key 检查给定 key 是否存在 TYPE key 返回 key 所储存的值的类型 DEL key 该命令用于在 key 存在时删除 key 字符串 Redis 中字符串类型常用命令: SET key value 设置指定key的值 GET key 获取指定key的值 SET key value EX seconds 设置指定key的值,并将 key 的过期时间设为 seconds 秒(验证码) EX可以换为PX,表示毫秒 SET key value NX EX seconds 只有在 key不存在时设置 key 的值 哈希操作 Redis hash 是一个string类型的 field 和 value 的映射表,hash特别适合用于存储对象,常用命令: HSET key field value 将哈希表 key 中的字段 field 的值设为 value HGET key field 获取存储在哈希表中指定字段的值 HDEL key field 删除存储在哈希表中的指定字段 HKEYS key 获取哈希表中所有字段 HVALS key 获取哈希表中所有值 列表操作 Redis 列表是简单的字符串列表,按照插入顺序排序,常用命令: LPUSH key value1 将一个值插入到列表头部 RPUSH key value1 [value2] 将一个或多个值插入到列表尾部 RPUSH mylist "world" "redis" "rpush" #多个值插入 LRANGE key start stop 获取列表指定范围内的元素(这里L代表List 不是Left) LRANGE mylist 0 -1 #获取整个列表 LLEN key 获取列表长度 RPOP key 移除并获取列表最后一个元素 BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超 时或发现可弹出元素为止 集合操作 Redis set 是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,常用命令: SADD key member1 [member2] 向集合添加一个或多个成员 # 添加单个成员 SADD fruits "apple" # 添加多个成员(自动去重) SADD fruits "banana" "orange" "apple" # "apple" 已存在,不会重复添加 SMEMBERS key 返回集合中的所有成员 SCARD key 获取集合的成员数(基数Cardinality) SINTER key1 [key2] 返回给定所有集合的交集 SUNION key1 [key2] 返回所有给定集合的并集 SREM key member1 [member2] 移除集合中一个或多个成员 有序集合 Redis有序集合是string类型元素的集合,且不允许有重复成员。每个元素都会关联一个double类型的分数。常用命令: 常用命令: ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员(score代表分数) ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员 ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment ZREM key member [member ...] 移除有序集合中的一个或多个成员 可以实现延迟消息 数据结构 延迟队列:ZSET delay:queue member:jobId(或直接存 JSON) score:“到期时间戳”(建议毫秒) 作业数据:HASH job:{jobId}(可选,放 payload、重试次数等) 生产者(投递延迟消息) 计算 due_ts = now + delay_ms ZADD delay:queue due_ts jobId (可选)HSET job:{jobId} payload ... retry 0 消费者(不断拉取到期任务处理) 周期性检查当前时间 now 取到期任务:ZRANGEBYSCORE delay:queue -inf now LIMIT 0 N ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 从有序集合(ZSET)中取出所有 score 在 [min, max] 区间的元素,按分数从小到大返回。 抢占删除(防止并发多消费者重复处理): 方式A(Redis 5+):Lua 脚本里判断并 ZPOPMIN/ZREMRANGEBYRANK 方式B:WATCH + ZREM 比对(不如 Lua 简洁) 处理成功:删除作业数据 DEL job:{jobId}(或标记完成) 处理失败:重试回投,ZADD delay:queue new_due jobId,并在 job:{jobId} 里递增 retry Java中操作Redis Spring Data Redis 是 Spring 的一部分,提供了在 Spring 应用中通过简单的配置就可以访问 Redis 服务,就如同我们使用JDBC操作MySQL数据库一样。 网址:https://spring.io/projects/spring-data-redis 环境搭建 进入到sky-server模块 1). 导入Spring Data Redis的maven坐标(已完成) <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 2). 配置Redis数据源 在application-dev.yml中添加 sky: redis: host: localhost port: 6379 password: 123456 database: 10 解释说明: database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15。 可以通过修改Redis配置文件来指定数据库的数量。 在application.yml中添加读取application-dev.yml中的相关Redis配置 spring: profiles: active: dev redis: host: ${sky.redis.host} port: ${sky.redis.port} password: ${sky.redis.password} database: ${sky.redis.database} 3). 编写配置类,创建RedisTemplate对象 @Configuration @Slf4j public class RedisConfiguration { @Bean public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){ log.info("开始创建redis模板对象..."); RedisTemplate redisTemplate = new RedisTemplate(); //设置redis的连接工厂对象 redisTemplate.setConnectionFactory(redisConnectionFactory); //设置redis key的序列化器 redisTemplate.setKeySerializer(new StringRedisSerializer()); return redisTemplate; } } 解释说明: 当前配置类不是必须的,因为 Spring Boot 框架会自动装配 RedisTemplate 对象,但是默认的key序列化器为 JdkSerializationRedisSerializer,存到 Redis 里会是二进制格式,这里把 key 的序列化器指定为 StringRedisSerializer,就会把所有的 key 都以 UTF‑8 字符串形式写入 Redis,方便观测和调试 功能测试 通过RedisTemplate对象操作Redis,注意要Another Redis Desktop中刷新一下数据库,才能看到数据。 字符串测试 @DataRedisTest @Import(com.sky.config.RedisConfiguration.class) public class SpringDataRedisTest { @Autowired private RedisTemplate redisTemplate; @Test public void testRedisTemplate(){ System.out.println(redisTemplate); } @Test public void testString(){ // SET city "北京" redisTemplate.opsForValue().set("city", "北京"); // GET city String city = (String) redisTemplate.opsForValue().get("city"); System.out.println(city); // SETEX code 180 "1234" (3 分钟 = 180 秒) redisTemplate.opsForValue().set("code", "1234", 3, TimeUnit.MINUTES); // SETNX lock "1" redisTemplate.opsForValue().setIfAbsent("lock", "1"); // (由于上一步 lock 已存在,这里相当于不执行) // SETNX lock "2" redisTemplate.opsForValue().setIfAbsent("lock", "2"); } } 对于非String类型: 写入时序列化 调用 opsForValue().set(key, value) 时,value(比如 List<DishVO>)会先走一遍 ValueSerializer。 默认是 JdkSerializationRedisSerializer,它用 Java 的 ObjectOutputStream 把整个对象图打包成一个 byte[]。 这个 byte[] 直接就存成了 Redis 的 String 值。 读取时反序列化 调用 opsForValue().get(key) 时,RedisTemplate 拿回那段 byte[],再用同一个 JDK 序列化器(ObjectInputStream)把它变回 List<DishVO>。 哈希测试 @Test public void testHash(){ HashOperations hashOperations = redisTemplate.opsForHash(); // HSET 100 "name" "tom" hashOperations.put("100", "name", "tom"); // HSET 100 "age" "20" hashOperations.put("100", "age", "20"); // HGET 100 "name" String name = (String) hashOperations.get("100", "name"); System.out.println(name); // HKEYS 100 Set keys = hashOperations.keys("100"); System.out.println(keys); // HVALS 100 List values = hashOperations.values("100"); System.out.println(values); // HDEL 100 "age" hashOperations.delete("100", "age"); } get获得的是Object类型,keys获得的是set类型,values获得的是List 3). 操作列表类型数据 @Test public void testList(){ ListOperations listOperations = redisTemplate.opsForList(); // LPUSH mylist "a" "b" "c" listOperations.leftPushAll("mylist", "a", "b", "c"); // LPUSH mylist "d" listOperations.leftPush("mylist", "d"); // LRANGE mylist 0 -1 List mylist = listOperations.range("mylist", 0, -1); System.out.println(mylist); // RPOP mylist listOperations.rightPop("mylist"); // LLEN mylist Long size = listOperations.size("mylist"); System.out.println(size); } 4). 操作集合类型数据 @Test public void testSet(){ SetOperations setOperations = redisTemplate.opsForSet(); // SADD set1 "a" "b" "c" "d" setOperations.add("set1", "a", "b", "c", "d"); // SADD set2 "a" "b" "x" "y" setOperations.add("set2", "a", "b", "x", "y"); // SMEMBERS set1 Set members = setOperations.members("set1"); System.out.println(members); // SCARD set1 Long size = setOperations.size("set1"); System.out.println(size); // SINTER set1 set2 Set intersect = setOperations.intersect("set1", "set2"); System.out.println(intersect); // SUNION set1 set2 Set union = setOperations.union("set1", "set2"); System.out.println(union); // SREM set1 "a" "b" setOperations.remove("set1", "a", "b"); } 5). 操作有序集合类型数据 @Test public void testZset(){ ZSetOperations zSetOperations = redisTemplate.opsForZSet(); // ZADD zset1 10 "a" zSetOperations.add("zset1", "a", 10); // ZADD zset1 12 "b" zSetOperations.add("zset1", "b", 12); // ZADD zset1 9 "c" zSetOperations.add("zset1", "c", 9); // ZRANGE zset1 0 -1 Set zset1 = zSetOperations.range("zset1", 0, -1); System.out.println(zset1); // ZINCRBY zset1 10 "c" zSetOperations.incrementScore("zset1", "c", 10); // ZREM zset1 "a" "b" zSetOperations.remove("zset1", "a", "b"); } 6). 通用命令操作 * 匹配零个或多个字符。 ? 匹配任何单个字符。 [abc] 匹配方括号内的任一字符(本例中为 'a'、'b' 或 'c')。 [^abc] 或 [!abc] 匹配任何不在方括号中的单个字符。 @Test public void testCommon(){ // KEYS * Set keys = redisTemplate.keys("*"); System.out.println(keys); // EXISTS name Boolean existsName = redisTemplate.hasKey("name"); System.out.println("name exists? " + existsName); // EXISTS set1 Boolean existsSet1 = redisTemplate.hasKey("set1"); System.out.println("set1 exists? " + existsSet1); for (Object key : keys) { // TYPE <key> DataType type = redisTemplate.type(key); System.out.println(key + " -> " + type.name()); } // DEL mylist redisTemplate.delete("mylist"); } 7)批量清除某个前缀开头的所有缓存 key 1.采用游标机制(非阻塞),每次只扫描一部分 key,适合生产。 @Autowired private StringRedisTemplate stringRedisTemplate; public void clearCacheByPrefix(String prefix) { ScanOptions options = ScanOptions.scanOptions().match(prefix + "*").count(1000).build(); Cursor<byte[]> cursor = stringRedisTemplate.getConnectionFactory() .getConnection() .scan(options); while (cursor.hasNext()) { String key = new String(cursor.next()); stringRedisTemplate.delete(key); } } # 不推荐生产用 KEYS user:* # 推荐生产用(配合 cursor) SCAN 0 MATCH user:* COUNT 1000 2.更优雅的方法是 在业务逻辑上增加一层命名空间,不用真正去删: 缓存的 key 格式:{prefix}:{namespace}:{realKey} 当你要“清空前缀缓存”时,只要更新 namespace(比如加一个时间戳或版本号),旧的 key 就算还在 Redis 中,也会失效,因为不会再被访问到。 String namespace = "v1"; // 放到配置里 String key = prefix + ":" + namespace + ":" + realKey; 当要清理时,把 namespace 改为 v2 即可,所有旧缓存自动失效。 Redisson 快速入门 1. 引入依赖 <dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.26.0</version> </dependency> 2. 在 application.yml 中配置 Redis 连接(Redisson 会自动读取) spring: redis: host: localhost port: 6379 password: # 如无密码则留空 database: 0 3. 可选:自定义 RedissonClient 配置(无需也可不写) @Configuration public class RedissonConfig { @Bean public RedissonClient redissonClient() { org.redisson.config.Config config = new org.redisson.config.Config(); config.useSingleServer() .setAddress("redis://localhost:6379") .setDatabase(0); return org.redisson.Redisson.create(config); } } 4.最简单的锁使用示例(默认看门狗机制) @Service public class SimpleLockService { private final RedissonClient redissonClient; public SimpleLockService(RedissonClient redissonClient) { this.redissonClient = redissonClient; } public void doWithLock(String lockName) { RLock lock = redissonClient.getLock(lockName); try { // 获取锁(阻塞式) lock.lock(); // 在这里执行需要加锁的业务逻辑 System.out.println("执行业务代码..."); } finally { // 释放锁 lock.unlock(); } } } 5.带超时的锁使用示例 @Service public class TimeoutLockService { private final RedissonClient redissonClient; public TimeoutLockService(RedissonClient redissonClient) { this.redissonClient = redissonClient; } public boolean tryDoWithLock(String lockName) { RLock lock = redissonClient.getLock(lockName); try { // 尝试获取锁(最多等待5秒,锁持有10秒后自动释放) if (lock.tryLock(5, 10, TimeUnit.SECONDS)) { try { // 在这里执行需要加锁的业务逻辑 System.out.println("执行业务代码..."); return true; } finally { lock.unlock(); } } return false; } catch (InterruptedException e) { Thread.currentThread().interrupt(); return false; } } }
后端学习
zy123
1年前
0
14
0
上一页
1
2
3
4
下一页