首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
41 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
找到
58
篇与
zy123
相关的结果
- 第 9 页
2025-03-21
matlab
matlab笔记 命令行窗口 clc:清屏(命令行窗口) clear all:把命名的变量删掉,不是命令行窗口 命名规则: 变量命名以字母开头,不可以下划线,变量是区分字母大小写的 脚本 %% xxx 注释(百分号+一个空格) % xxx 也是注释 s='a' '"aaaa",字符串 abs(s) 字符s的ascii码,为97 char(97), 输出'a' numtostr(65) ans='65',数字转字符串 length(str),字符串的长度 矩阵 A=[1 2 3 ;4 5 6 ;7 8 9] 分号换行 B=A‘ ,矩阵转置 C=A(:) ,将矩阵拉成一列,按列存储,第一列拼接第二列拼接第三列 D=inv(A) 求逆矩阵 E=zeros(10,5,3) 生成10行5列3维0矩阵 元胞数组 A=cell(1,6),生成1行6列的小格子,每个小格子可以存放各种数据 eye(3),生成3x3的单位阵 A{2}=eye(3),matlab数组从1开始,不是0
杂项
zy123
1年前
0
8
0
2025-03-21
jupyter笔记本
jupyter笔记本 如何打开jupyter? 打开anaconda navigator图形界面,lauch jupyter 打开cmd 敲 jupyter notebook %matplotlib inline 使matplotlib绘制的图像嵌入在jupyter notebook单元格中 常用快捷键! esc进入命令模式 回车进入编辑模式 在命令模式下输入M可以进行markdown格式编写,输入Y可以进行python代码编写 shift+回车:运行当前代码块并跳转到下一块 ctrl+回车:只运行当前代码块 不跳转 B:往下增加一行代码块 A:往上新加一行代码块 DD:删除一行 L:标一个代码块内的行数 公式撰写 $$ x=\frac{-b\pm \sqrt{b^2-4_ac}}{2a} $$
杂项
zy123
1年前
0
8
0
2025-03-21
苍穹外卖
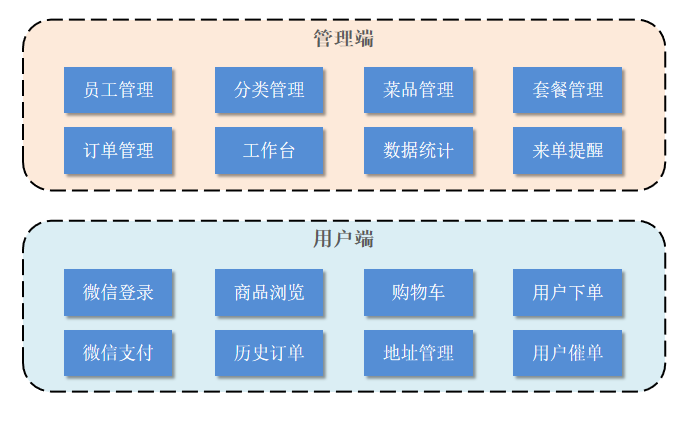
苍穹外卖 项目简介 整体介绍 本项目(苍穹外卖)是专门为餐饮企业(餐厅、饭店)定制的一款软件产品,包括 系统管理后台 和 小程序端应用 两部分。其中系统管理后台主要提供给餐饮企业内部员工使用,可以对餐厅的分类、菜品、套餐、订单、员工等进行管理维护,对餐厅的各类数据进行统计,同时也可进行来单语音播报功能。小程序端主要提供给消费者使用,可以在线浏览菜品、添加购物车、下单、支付、催单等。 1). 管理端功能 员工登录/退出 , 员工信息管理 , 分类管理 , 菜品管理 , 套餐管理 , 菜品口味管理 , 订单管理 ,数据统计,来单提醒。 2). 用户端功能 微信登录 , 收件人地址管理 , 用户历史订单查询 , 菜品规格查询 , 购物车功能 , 下单 , 支付、分类及菜品浏览。 技术选型 1). 用户层 本项目中在构建系统管理后台的前端页面,我们会用到H5、Vue.js、ElementUI、apache echarts(展示图表)等技术。而在构建移动端应用时,我们会使用到微信小程序。 2). 网关层 Nginx是一个服务器,主要用来作为Http服务器,部署静态资源,访问性能高。在Nginx中还有两个比较重要的作用: 反向代理和负载均衡, 在进行项目部署时,要实现Tomcat的负载均衡,就可以通过Nginx来实现。 3). 应用层 SpringBoot: 快速构建Spring项目, 采用 "约定优于配置" 的思想, 简化Spring项目的配置开发。 SpringMVC:SpringMVC是spring框架的一个模块,springmvc和spring无需通过中间整合层进行整合,可以无缝集成。 Spring Task: 由Spring提供的定时任务框架。 httpclient: 主要实现了对http请求的发送。 Spring Cache: 由Spring提供的数据缓存框架 JWT: 用于对应用程序上的用户进行身份验证的标记。 阿里云OSS: 对象存储服务,在项目中主要存储文件,如图片等。 Swagger: 可以自动的帮助开发人员生成接口文档,并对接口进行测试。 POI: 封装了对Excel表格的常用操作。 WebSocket: 一种通信网络协议,使客户端和服务器之间的数据交换更加简单,用于项目的来单、催单功能实现。 4). 数据层 MySQL: 关系型数据库, 本项目的核心业务数据都会采用MySQL进行存储。 Redis: 基于key-value格式存储的内存数据库, 访问速度快, 经常使用它做缓存。 Mybatis: 本项目持久层将会使用Mybatis开发。 pagehelper: 分页插件。 spring data redis: 简化java代码操作Redis的API。 5). 工具 git: 版本控制工具, 在团队协作中, 使用该工具对项目中的代码进行管理。 maven: 项目构建工具。 junit:单元测试工具,开发人员功能实现完毕后,需要通过junit对功能进行单元测试。 postman: 接口测工具,模拟用户发起的各类HTTP请求,获取对应的响应结果。 准备工作 //待完善,最后写一套本地java开发、nginx部署前端;服务器docker部署的方案!!! 前端环境搭建 Windows下 1.构建和打包前端项目 npm install #安装依赖 npm run build #打包,但我TypeScript 检查报错 npm run pure-build #不检查类型打包 2.将构建文件复制到指定目录 Nginx 默认的静态文件根目录通常是 /usr/share/nginx/html,你可以选择将打包好的静态文件拷贝到该目录 或者使用自定义目录/var/www/my-frontend,并修改 Nginx 配置文件来指向这个目录。 3.配置 Nginx 打开 Nginx 的配置文件,通常位于 /etc/nginx/nginx.conf 以下是一个使用自定义目录 /var/www/my-frontend 作为站点根目录的示例配置: server { listen 80; server_name your-domain.com; # 如果没有域名可以使用 _ 或 localhost root /var/www/my-frontend; index index.html; location / { try_files $uri $uri/ /index.html; } } 4.启动或重启 Nginx 启动:双击nginx.exe 重启:nginx -s reload 5.查看是否正在运行 tasklist /FI "IMAGENAME eq nginx.exe" 6.访问前端项目 在浏览器中输入你配置的域名或服务器 IP 地址 终止运行nginx: nginx.exe -s stop 后端环境搭建 工程的每个模块作用说明: 序号 名称 说明 1 sky-take-out maven父工程,统一管理依赖版本,聚合其他子模块 2 sky-common 子模块,存放公共类,例如:工具类、常量类、异常类等 3 sky-pojo 子模块,存放实体类、VO、DTO等 4 sky-server 子模块,后端服务,存放配置文件、Controller、Service、Mapper等 分析sky-common模块的每个包的作用: 名称 说明 constant 存放相关常量类 context 存放上下文类 enumeration 项目的枚举类存储 exception 存放自定义异常类 json 处理json转换的类 properties 存放SpringBoot相关的配置属性类 result 返回结果类的封装 utils 常用工具类 分析sky-pojo模块的每个包的作用: 名称 说明 Entity 实体,通常和数据库中的表对应 DTO 数据传输对象,通常用于程序中各层之间传递数据(接收从web来的数据) VO 视图对象,为前端展示数据提供的对象(响应给web) POJO 普通Java对象,只有属性和对应的getter和setter 分析sky-server模块的每个包的作用: 名称 说明 config 存放配置类 controller 存放controller类 interceptor 存放拦截器类 mapper 存放mapper接口 service 存放service类 SkyApplication 启动类 数据库初始化 执行sky.sql文件 序号 数据表名 中文名称 1 employee 员工表 2 category 分类表 3 dish 菜品表 4 dish_flavor 菜品口味表 5 setmeal 套餐表 6 setmeal_dish 套餐菜品关系表 7 user 用户表 8 address_book 地址表 9 shopping_cart 购物车表 10 orders 订单表 11 order_detail 订单明细表 跨域问题产生方式: 你在地址栏输 http://localhost:8100/api/health,这是浏览器直接导航到该 URL——浏览器会绕过 CORS 机制,直接向服务器发请求并渲染响应结果,这种场景不受 CORS 限制。 但如果你在一个在 http://localhost:3000(或任何不同端口)下运行的前端网页里,用 JavaScript 这样写: fetch('http://localhost:8100/api/health') .then(res => res.json()) .then(data => console.log(data)) .catch(err => console.error(err)); 会触发跨域 Nginx 1.静态资源托管 直接高效地托管前端静态文件(HTML/CSS/JS/图片等)。 server { root /var/www/html; index index.html; location / { try_files $uri $uri/ /index.html; # 支持前端路由(如 React/Vue) } } try_files:按顺序尝试多个文件或路径,直到找到第一个可用的为止。 $uri:尝试直接访问请求的路径对应的文件(例如 /css/style.css)。 $uri/:尝试将路径视为目录(例如 /blog/ 会查找 /blog/index.html)。 /index.html:如果前两者均未找到,最终返回前端入口文件 index.html。 2.nginx 反向代理: 反向代理的好处: 提高访问速度 因为nginx本身可以进行缓存,如果访问的同一接口,并且做了数据缓存,nginx就直接可把数据返回,不需要真正地访问服务端,从而提高访问速度。 保证后端服务安全 因为一般后台服务地址不会暴露,所以使用浏览器不能直接访问,可以把nginx作为请求访问的入口,请求到达nginx后转发到具体的服务中,从而保证后端服务的安全。 统一入口解决跨域问题(无需后端配置 CORS)。 @Configuration public class CorsConfig implements WebMvcConfigurer { @Override public void addCorsMappings(CorsRegistry registry) { // 覆盖所有请求 registry.addMapping("/**") // 允许发送 Cookie .allowCredentials(true) // 放行哪些域名(必须用 patterns,否则 * 会和 allowCredentials 冲突) .allowedOriginPatterns("*") .allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS") .allowedHeaders("*") .exposedHeaders("*"); } } nginx 反向代理的配置方式: server{ listen 80; server_name localhost; location /api/{ proxy_pass http://localhost:8080/admin/; #反向代理 } } 监听80端口号, 然后当我们访问 http://localhost:80/api/../..这样的接口的时候,它会通过 location /api/ {} 这样的反向代理到 http://localhost:8080/admin/上来。 3.负载均衡配置(默认是轮询) 将流量分发到多个后端服务器,提升系统吞吐量和容错能力。 upstream webservers{ server 192.168.100.128:8080; server 192.168.100.129:8080; } server{ listen 80; server_name localhost; location /api/{ proxy_pass http://webservers/admin;#负载均衡 } } 完整流程示例 用户访问:浏览器打开 http://yourdomain.com。 Nginx 返回静态文件:返回 index.html 和前端资源。 前端发起 API 请求:前端代码调用 /api/data。 Nginx 代理请求:将 /api/data 转发到 http://backend_server:3000/api/data。 后端响应:处理请求并返回数据,Nginx 将结果传回前端。 APIFox 使用APIFox管理、测试接口、导出接口文档... 优势: 1.多格式支持 APIFox 能够导入包括 YApi 格式在内的多种接口文档,同时支持导出为 OpenAPI、Postman Collection、Markdown 和 HTML 等格式,使得接口文档在不同工具间无缝迁移和使用。 2.接口调试与 Mock 内置接口调试工具可以直接发送请求、查看返回结果,同时内置 Mock 服务功能,方便前后端联调和接口数据模拟,提升开发效率。 3.易用性与团队协作 界面直观、操作便捷,支持多人协作,通过分支管理和版本控制,团队成员可以并行开发并进行变更管理,确保接口维护有序。 迭代分支功能: 新建迭代分支,新增的待测试的接口在这里充分测试,没问题之后合并回主分支。 导出接口文档: 推荐导出数据格式为OpenAPI Spec,它是一种通用的 API 描述标准,Postman和APIFox都支持。 与Idea集成 安装plugin Apifox-helper,配置token,即可直接在controller层接口右键 "upload to Apifox" Swagger 使得前后端分离开发更加方便,有利于团队协作 接口的文档在线自动生成,降低后端开发人员编写接口文档的负担 功能测试 使用: 1.导入 knife4j 的maven坐标 在pom.xml中添加依赖 <dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-spring-boot-starter</artifactId> </dependency> 2.在配置类中加入 knife4j 相关配置 WebMvcConfiguration.java /** * 通过knife4j生成接口文档 * @return */ @Bean public Docket docket() { ApiInfo apiInfo = new ApiInfoBuilder() .title("苍穹外卖项目接口文档") .version("2.0") .description("苍穹外卖项目接口文档") .build(); Docket docket = new Docket(DocumentationType.SWAGGER_2) .apiInfo(apiInfo) .select() .apis(RequestHandlerSelectors.basePackage("com.sky.controller")) .paths(PathSelectors.any()) .build(); return docket; } 3.设置静态资源映射,否则接口文档页面无法访问 WebMvcConfiguration.java /** * 设置静态资源映射 * @param registry */ protected void addResourceHandlers(ResourceHandlerRegistry registry) { registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/"); registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/"); } 4.访问测试 接口文档访问路径为 http://ip:port/doc.html ---> http://localhost:8080/doc.html 这是根据后端 Java 代码(通常是注解)自动生成接口文档,访问是通过后端服务的端口,这些文档最终会以静态文件的形式存在于 jar 包内,通常存放在 META-INF/resources/ 常用注解 通过注解可以控制生成的接口文档,使接口文档拥有更好的可读性,常用注解如下: 注解 说明 @Api 用在类上,例如Controller,表示对类的说明 @ApiModel 用在类上,例如entity、DTO、VO @ApiModelProperty 用在属性上,描述属性信息 @ApiOperation 用在方法上,例如Controller的方法,说明方法的用途、作用 EmployeeLoginDTO.java @Data @ApiModel(description = "员工登录时传递的数据模型") public class EmployeeLoginDTO implements Serializable { @ApiModelProperty("用户名") private String username; @ApiModelProperty("密码") private String password; } EmployeeController.java @Api(tags = "员工相关接口") public class EmployeeController { @Autowired private EmployeeService employeeService; @Autowired private JwtProperties jwtProperties; /** * 登录 * * @param employeeLoginDTO * @return */ @PostMapping("/login") @ApiOperation(value = "员工登录") public Result<EmployeeLoginVO> login(@RequestBody EmployeeLoginDTO employeeLoginDTO) { //.............. } } 后端部署 项目开发完毕 这种情况下JAVA代码无需改动,直接本地打包maven->package成Jar包复制到服务器上部署: 本项目为multi-module (聚合) Maven 工程,父工程为sky-take-out,子模块有common,pojo,server,其中server依赖common和pojo: <dependency> <groupId>com.sky</groupId> <artifactId>sky-common</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <dependency> <groupId>com.sky</groupId> <artifactId>sky-pojo</artifactId> <version>1.0-SNAPSHOT</version> </dependency> 打包方式(本地): 法一.直接对父工程执行mvn clean install 法二.分别先对子模块common和pojo执行install,再对server执行package 注意:直接对server打包会报错!!! 因为Maven 在构建 sky-server 时,去你本地仓库或远程仓库寻找它依赖的两个 SNAPSHOT 包。 在父工程的pom中添加这段,能将你的应用和所有依赖都打到一个可执行的 “fat jar” 里 <build> <finalName>${project.artifactId}</finalName> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> JAVA项目dockerfile: # 使用 JDK 17 运行时镜像 FROM openjdk:17-jdk-slim # 设置时区为上海 ENV TZ=Asia/Shanghai RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone # 创建工作目录 WORKDIR /app # 复制 Fat Jar,重命名为 app.jar COPY sky-server-1.0-SNAPSHOT.jar ./app.jar # 暴露端口(与 application.properties 中的 server.port 保持一致) EXPOSE 8085 # 以 exec 形式启动 ENTRYPOINT ["java", "-jar", "app.jar"] ENTRYPOINT ["java", "-jar", "app.jar"] 能够启动是因为Spring Boot 的 Maven 插件在打包时已经将你的启动类标记进去了: Spring Boot 的启动器会: 读取 MANIFEST.MF 里的 Start-Class: com.sky.SkyApplication 将 com.sky.SkyApplication 作为入口调用其 main 方法 由于该项目还需依赖Mysql和Redis运行,因此需在docker-compose.yml中统一创建容器环境。(:ro代表只读) version: "3.8" services: mysql: image: mysql:8.0 container_name: sky-mysql restart: always environment: MYSQL_ROOT_PASSWORD: 123456 MYSQL_DATABASE: sky_take_out TZ: Asia/Shanghai volumes: - ./data/mysql:/var/lib/mysql - ./init/sky.sql:/docker-entrypoint-initdb.d/sky.sql:ro - ./mysql-conf/my.cnf:/etc/mysql/conf.d/my.cnf:ro ports: - "3306:3306" networks: - sky-net redis: image: redis:7.0-alpine container_name: sky-redis restart: always command: redis-server --requirepass 123456 volumes: - ./data/redis:/data ports: - "6379:6379" networks: - sky-net app: build: context: . dockerfile: Dockerfile image: sky-server:latest container_name: sky-server depends_on: - mysql - redis volumes: - ./config:/app/config:ro environment: TZ: Asia/Shanghai SPRING_PROFILES_ACTIVE: dev ports: - "8085:8085" restart: always networks: - sky-net volumes: mysql: redis: networks: sky-net: external: true 其中启动数据库要准备两份文件: 初始化脚本sky.sql,用来创建数据库和表 my.cnf:让初始化脚本创建的表中的中文数据正常显示 [client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 [mysqld] character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci init_connect='SET NAMES utf8mb4' 另外: application-dev.yml 是给 Spring Boot 读取的,Spring Boot 会在启动时自动加载它,填充到JAVA项目中。 Docker Compose 里的 environment: 无法读取application-dev.yml,要不就写死、要不就写在.env文件中。 最后项目结构: 滚动开发阶段 1.仅需改动Dokcerfile,docker-compose无需更改: # —— 第一阶段:Maven 构建 —— FROM maven:3.8.7-eclipse-temurin-17-alpine AS builder WORKDIR /workspace # 把项目级 settings.xml 复制到容器里 COPY .mvn/settings.xml /root/.m2/settings.xml # 1) 先把父 POM 和所有子模块的目录结构都复制过来 COPY whut-take-out-backend/pom.xml ./pom.xml COPY whut-take-out-backend/sky-common ./sky-common COPY whut-take-out-backend/sky-pojo ./sky-pojo COPY whut-take-out-backend/sky-server ./sky-server # (可选:如果父 pom 有 <modules>,也可把 settings.xml、父级的其它 POM 拷过来) RUN mvn dependency:go-offline -B # 2) 拷贝所有子模块源码 COPY whut-take-out-backend ./whut-take-out-backend # 3) 只构建 sky-server 模块(并且把依赖模块一并编译) RUN mvn -f whut-take-out-backend/pom.xml clean package \ -pl sky-server -am \ -DskipTests -B # —— 第二阶段:运行时镜像 —— FROM openjdk:17-jdk-slim ENV TZ=Asia/Shanghai RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone WORKDIR /app # 4) 把第一阶段产物(sky-server 模块的 Jar)拷过来 COPY --from=builder \ /workspace/whut-take-out-backend/sky-server/target/sky-server-*.jar \ ./app.jar EXPOSE 8085 ENTRYPOINT ["java", "-jar", "app.jar"] 命令解析: mvn dependency:go-offline -B 这一步只做依赖预取,也就是把所有在父 POM、子模块 POM、以及插件里声明的第三方库都下载到本地仓库(~/.m2/repository) 真正的编译+构建打包步骤: RUN mvn -f whut-take-out-backend/pom.xml clean package \ -pl sky-server -am \ -DskipTests -B -f whut-take-out-backend/pom.xml 指定使用哪个 POM 作为构建入口(父工程)。 clean: 把上一次构建残留的 target/ 目录删掉,保证从零开始构建 package:执行到 package 阶段 生成 JAR/WAR -pl sky-server (--projects) 只针对 sky-server 模块执行后续构建。 -am (--also-make) 如果 sky-server 依赖了多模块工程里的其他子模块(如 common、pojo),就会先把它们编译好,确保 sky-server 拿到最新的本地模块依赖。 -DskipTests 跳过单元测试,加快构建速度。 -B 批处理模式(无交互),适合 Docker 构建。 2.maven构建依赖可能比较慢,需创建.mvn/settings.xml (这个提速非常多!务必添加) <settings xmlns="http://maven.apache.org/SETTINGS/1.1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.1.0 https://maven.apache.org/xsd/settings-1.1.0.xsd"> <mirrors> <mirror> <id>aliyun</id> <name>aliyun maven</name> <url>https://maven.aliyun.com/repository/public</url> <mirrorOf>central,apache.snapshots</mirrorOf> </mirror> </mirrors> </settings> 使用阿里云镜像加速 3.验证:http://124.71.159.195:8085/doc.html 踩坑总结 Maven 默认会用 artifactId-version来命名,eg: <artifactId>group-buying-sys</artifactId> <version>1.0-SNAPSHOT</version> group-buying-sys-app-1.0-SNAPSHOT.jar 如果server模块中的pom中指定了finalName,那么打包出来的文件将命名为finalName中指定的名称,如 example-app.jar <build> <finalName>example-app</finalName> </build> 这个问题导致docker-compose构建镜像时一直报错:Error: Unable to access jarfile app.jar 部署时占用问题端口: Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:13306 -> 0.0.0.0:0: listen tcp 0.0.0.0:13306: bind: An attempt was made to access a socket in a way forbidden by its access permissions. 先查看是否端口被占用: netstat -aon | findstr 5672 如果没有被占用,那么就是windows的bug,在CMD使用管理员权限重启NAT网络服务即可 net stop winnat net start winnat 前端部署 直接部署开发完毕的前端代码,准备: 0)创建docker网络:docker network create sky-net 1)静态资源html文件夹(npm run build 打包源码获得) 2)nginx.conf 注意把nginx.conf中的server改为Docker 容器(或服务)在同一网络中的服务名,如 upstream webservers { server sky-server:8085 weight=90; } 因为同一个网络下的服务名会自动注册DNS,进行地址解析! 3)docker-compose文件 version: "3.8" services: frontend: image: nginx:alpine container_name: sky-frontend ports: - "85:80" volumes: # 把本地 html 目录挂到容器的默认站点目录 - ./html:/usr/share/nginx/html:ro # 把本地的 nginx.conf 覆盖容器里的配置 - ./nginx.conf:/etc/nginx/nginx.conf:ro networks: - sky-net networks: sky-net: external: true 实战开发 分页查询 传统员工分页查询分析: 采用分页插件PageHelper: 在执行empMapper.list()方法时,就是执行:select * from emp 语句,怎么能够实现分页操作呢? 分页插件帮我们完成了以下操作: 先获取到要执行的SQL语句: select * from emp 为了实现分页,第一步是获取符合条件的总记录数。分页插件将原始 SQL 查询中的 SELECT * 改成 SELECT count(*) select count(*) from emp; 一旦知道了总记录数,分页插件会将 SELECT * 的查询语句进行修改,加入 LIMIT 关键字,限制返回的记录数。 select * from emp limit ?, ? 第一个参数(?)是 起始位置,通常是 (当前页 - 1) * 每页显示的记录数,即从哪一行开始查询。 第二个参数(?)是 每页显示的记录数,即返回多少条数据。 执行分页查询,例如,假设每页显示 10 条记录,你请求第 2 页数据,那么 SQL 语句会变成: select * from emp limit 10, 10; #跳过前10条数据,请求接下来的10条,即第2页数据 使用方法: 当使用 PageHelper 分页插件时,无需在 Mapper 中手动处理分页。只需在 Mapper 中编写常规的列表查询。 在 Service 层,调用 Mapper 方法之前,设置分页参数。 调用 Mapper 查询后,自动进行分页,并将结果封装到 PageBean 对象中返回。 1、在pom.xml引入依赖 <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper-spring-boot-starter</artifactId> <version>1.4.2</version> </dependency> 2、EmpMapper @Mapper public interface EmpMapper { //获取当前页的结果列表 @Select("select * from emp") public List<Emp> list(); } 3、EmpServiceImpl 当调用 PageHelper.startPage(page, pageSize) 时,PageHelper 插件会拦截随后的 SQL 查询,自动修改查询,加入 LIMIT 子句来实现分页功能。 @Override public PageBean page(Integer page, Integer pageSize) { // 设置分页参数 PageHelper.startPage(page, pageSize); //page是页号,不是起始索引 // 执行分页查询 List<Emp> empList = empMapper.list(); // 获取分页结果 Page<Emp> p = (Page<Emp>) empList; //封装PageBean PageBean pageBean = new PageBean(p.getTotal(), p.getResult()); return pageBean; } 4、Controller @Slf4j @RestController @RequestMapping("/emps") public class EmpController { @Autowired private EmpService empService; //条件分页查询 @GetMapping public Result page(@RequestParam(defaultValue = "1") Integer page, @RequestParam(defaultValue = "10") Integer pageSize) { //记录日志 log.info("分页查询,参数:{},{}", page, pageSize); //调用业务层分页查询功能 PageBean pageBean = empService.page(page, pageSize); //响应 return Result.success(pageBean); } } 条件分页查询 思路分析: <select id="pageQuery" resultType="com.sky.entity.Employee"> select * from employee <where> <if test="name != null and name != ''"> and name like concat('%',#{name},'%') </if> </where> order by create_time desc /select> 文件上传 阿里云OSS存储 pom文件中添加如下依赖: <dependency> <groupId>com.aliyun.oss</groupId> <artifactId>aliyun-sdk-oss</artifactId> <version>3.15.1</version> </dependency> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> <!-- no more than 2.3.3--> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.3.3</version> </dependency> 上传文件的工具类 /** * 阿里云 OSS 工具类 */ public class AliOssUtil { private String endpoint; private String accessKeyId; private String accessKeySecret; private String bucketName; /** * 文件上传 * * @param bytes * @param objectName * @return */ public String upload(byte[] bytes, String objectName) { // 创建OSSClient实例。 OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret); try { // 创建PutObject请求。 ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(bytes)); } catch (OSSException oe) { System.out.println("Caught an OSSException, which means your request made it to OSS, " + "but was rejected with an error response for some reason."); System.out.println("Error Message:" + oe.getErrorMessage()); System.out.println("Error Code:" + oe.getErrorCode()); System.out.println("Request ID:" + oe.getRequestId()); System.out.println("Host ID:" + oe.getHostId()); } catch (ClientException ce) { System.out.println("Caught an ClientException, which means the client encountered " + "a serious internal problem while trying to communicate with OSS, " + "such as not being able to access the network."); System.out.println("Error Message:" + ce.getMessage()); } finally { if (ossClient != null) { ossClient.shutdown(); } } //文件访问路径规则 https://BucketName.Endpoint/ObjectName StringBuilder stringBuilder = new StringBuilder("https://"); stringBuilder .append(bucketName) .append(".") .append(endpoint) .append("/") .append(objectName); log.info("文件上传到:{}", stringBuilder.toString()); return stringBuilder.toString(); } } 自己搭建FileBrowser存储 public class FileBrowserUtil { private String domain; private String username; private String password; /** * —— 第一步:登录拿 token —— * 调用 /api/login 接口,返回纯 JWT 字符串,或 {"token":"..."} 结构 */ public String login() throws IOException { String url = domain + "/api/login"; try (CloseableHttpClient client = HttpClients.createDefault()) { HttpPost post = new HttpPost(url); post.setHeader("Content-Type", "application/json"); // 构造登录参数 JSONObject cred = new JSONObject(); cred.put("username", username); cred.put("password", password); post.setEntity(new StringEntity(cred.toString(), StandardCharsets.UTF_8)); try (CloseableHttpResponse resp = client.execute(post)) { int status = resp.getStatusLine().getStatusCode(); String body = EntityUtils.toString(resp.getEntity(), StandardCharsets.UTF_8).trim(); if (status >= 200 && status < 300) { // 如果返回 JSON 对象,则解析出 token 字段 if (body.startsWith("{") && body.endsWith("}")) { JSONObject obj = JSONObject.parseObject(body); String token = obj.getString("token"); log.info("登录成功,token={}", token); return token; } // 否则直接当成原始 JWT 返回 log.info("登录成功,token={}", body); return body; } else { log.error("Login failed: HTTP {} - {}", status, body); throw new IOException("Login failed: HTTP " + status); } } } } /** * —— 第二步:上传文件 —— * POST {domain}/api/resources/{encodedPath}?override=true * Header: X-Auth: token */ public String uploadFile(byte[] fileBytes, String fileName) throws IOException { String token = login(); String remotePath = "store/" + fileName; String encodedPath = URLEncoder .encode(remotePath, StandardCharsets.UTF_8) .replace("%2F", "/"); // 根据后缀猜 MIME 类型 String mimeType = URLConnection.guessContentTypeFromName(fileName); if (mimeType == null) { mimeType = "application/octet-stream"; } String uploadUrl = domain + "/api/resources/" + encodedPath + "?override=true"; try (CloseableHttpClient client = HttpClients.createDefault()) { HttpPost post = new HttpPost(uploadUrl); post.setHeader("X-Auth", token); post.setEntity(new ByteArrayEntity(fileBytes, ContentType.create(mimeType))); try (CloseableHttpResponse resp = client.execute(post)) { int status = resp.getStatusLine().getStatusCode(); String respBody = EntityUtils.toString(resp.getEntity(), StandardCharsets.UTF_8); if (status < 200 || status >= 300) { log.error("文件上传失败: HTTP {} - {}", status, respBody); throw new IOException("Upload failed: HTTP " + status); } log.info("文件上传成功,remotePath={}", remotePath); return remotePath; } } } /** * 第三步:生成公开分享链接 * 模拟浏览器的 POST /api/share/{encodedPath} 请求,body 为 "{}" */ public String createShareLink(String remotePath) throws IOException { String token = login(); // URL encode 并保留斜杠 String encodedPath = URLEncoder .encode(remotePath, StandardCharsets.UTF_8) .replace("%2F", "/"); String shareUrl = domain + "/api/share/" + encodedPath; log.info("准备创建分享链接,POST {}", shareUrl); try (CloseableHttpClient client = HttpClients.createDefault()) { HttpPost post = new HttpPost(shareUrl); post.setHeader("Cookie", "auth=" + token); post.setHeader("X-Auth", token); post.setHeader("Content-Type", "text/plain;charset=UTF-8"); post.setEntity(new StringEntity("{}", StandardCharsets.UTF_8)); try (CloseableHttpResponse resp = client.execute(post)) { int status = resp.getStatusLine().getStatusCode(); String body = EntityUtils.toString(resp.getEntity(), StandardCharsets.UTF_8).trim(); if (status < 200 || status >= 300) { log.error("创建分享失败 HTTP {} - {}", status, body); throw new IOException("Share failed: HTTP " + status); } // ========= 这里改为先检测是对象还是数组 ========= JSONObject json; if (body.startsWith("[")) { // 如果真返回数组(老版本可能是 [{...}]) json = JSONArray.parseArray(body).getJSONObject(0); } else if (body.startsWith("{")) { // 当前版本直接返回对象 json = JSONObject.parseObject(body); } else { throw new IOException("Unexpected share response: " + body); } String hash = json.getString("hash"); String publicUrl = domain + "/api/public/dl/" + hash + "/" + remotePath; log.info("创建分享链接成功:{}", publicUrl); return publicUrl; } } } /** * —— 整合示例:上传并立即返回分享链接 —— */ public String uploadAndGetUrl(byte[] fileBytes, String fileName) throws IOException { String remotePath = uploadFile(fileBytes, fileName); return createShareLink(remotePath); } } 数据库密码加密 加密存储确保即使数据库泄露,攻击者也不能轻易获取用户原始密码。 spring security中提供了一个加密类BCryptPasswordEncoder。 它采用哈希算法 SHA-256 +随机盐+密钥对密码进行加密。加密算法是一种可逆的算法,而哈希算法是一种不可逆的算法。 因为有随机盐的存在,所以相同的明文密码经过加密后的密码是不一样的,盐在加密的密码中是有记录的,所以需要对比的时候,springSecurity是可以从中获取到盐的 添加 spring-security-crypto 依赖,无需引入Spring Security 的认证、授权、过滤器链等其它安全组件! <dependency> <groupId>org.springframework.security</groupId> <artifactId>spring-security-crypto</artifactId> </dependency> 添加配置 @Configuration public class SecurityConfig { @Bean public PasswordEncoder passwordEncoder() { // 参数 strength 为工作因子,默认为 10,这里可以根据需要进行调整 return new BCryptPasswordEncoder(10); } } 用户注册、加密 encode @Autowired private PasswordEncoder passwordEncoder; // 对密码进行加密 String encodedPassword = passwordEncoder.encode(rawPassword); 验证密码 matches // 使用 matches 方法来对比明文密码和存储的哈希密码 boolean judge= passwordEncoder.matches(rawPassword, user.getPassword()); BaseContext 如何获得当前登录的用户id? 方法:ThreadLocal ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问。 每次请求代表一个线程!!!注:请求可以先经过拦截器,再经过controller=>service=>mapper,都是在一个线程里。而即使同一个用户,先用两次请求/login、 /upload,它们也不处于同一线程中! public class BaseContext { public static ThreadLocal<Long> threadLocal = new ThreadLocal<>(); public static void setCurrentId(Long id) { threadLocal.set(id); } public static Long getCurrentId() { return threadLocal.get(); } public static void removeCurrentId() { threadLocal.remove(); } } 实现方式:登录成功 -> 生成jwt令牌 (claims中存userId)->前端浏览器保存 后续每次请求携带jwt -> 拦截器检查jwt令牌 -> BaseContext.setCurrentId(jwt中取出的userId); -> BaseContext.getCurrentId(); //service层中获取当前userId 全局异常处理 新增员工时的问题 录入的用户名已存,抛出的异常后没有处理。 法一:每次新增员工前查询一遍数据库,保证无重复username再插入。 法二:插入后系统报“Duplicate entry”再处理。 「乐观策略」减少不必要的查询,只有在冲突时才抛错。 解决方法:定义全局异常处理器 @RestControllerAdvice @Slf4j public class GlobalExceptionHandler { /** * 捕获业务异常 * @param ex * @return */ @ExceptionHandler public Result exceptionHandler(BaseException ex){ log.error("异常信息:{}", ex.getMessage()); return Result.error(ex.getMessage()); } @ExceptionHandler public Result exceptionHandler(SQLIntegrityConstraintViolationException ex){ //Duplicate entry 'zhangsan' for key 'employee.idx_username' String message = ex.getMessage(); log.info(message); if(message.contains("Duplicate entry")){ String[] split = message.split(" "); String username = split[2]; String msg = username + MessageConstant.ALREADY_EXISTS; return Result.error(msg); }else{ return Result.error(MessageConstant.UNKNOWN_ERROR); } } } SQLIntegrityConstraintViolationException用来捕获各种 完整性约束冲突,如唯一/主键约束冲突(向一个设置了 UNIQUE 或者 PRIMARY KEY 的字段重复插入相同的值。)。可以捕捉username重复异常。并以Result.error(msg)返回通用响应。 另外,自定义一个异常BaseException与若干个业务层异常, public class BaseException extends RuntimeException { public BaseException() { } public BaseException(String msg) { super(msg); } } 业务层抛异常: throw new AccountLockedException(MessageConstant.ACCOUNT_LOCKED); 这样抛出异常之后可以被全局异常处理器 exceptionHandler(BaseException ex) 捕获。 SpringMVC的消息转换器(处理日期) Jackson 是一个用于处理 JSON 数据 的流行 Java 库,主要用于: 序列化:将 Java 对象转换为 JSON 字符串(例如:Java对象 → {"name":"Alice"})。Controller 返回值上带有 @ResponseBody 或者使用 @RestController 反序列化:将 JSON 字符串解析为 Java 对象(例如:{"name":"Alice"} → Java对象)。方法参数上标注了 @RequestBody Spring Boot默认集成了Jackson 1). 方式一 在属性上加上注解,对日期进行格式化 但这种方式,需要在每个时间属性上都要加上该注解,使用较麻烦,不能全局处理。 2). 方式二(推荐 ) 在WebMvcConfiguration中扩展SpringMVC的消息转换器,统一对LocalDateTime、LocalDate、LocalTime进行格式处理 /** * 扩展Spring MVC框架的消息转化器 * @param converters */ protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) { log.info("扩展消息转换器..."); //创建一个消息转换器对象 MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter(); //需要为消息转换器设置一个对象转换器,对象转换器可以将Java对象序列化为json数据 converter.setObjectMapper(new JacksonObjectMapper()); //将自己的消息转化器加入容器中,确保覆盖默认的 Jackson 行为 converters.add(0,converter); } JacksonObjectMapper()文件: //直接复用 Jackson 的核心功能,仅覆盖或扩展特定行为。 public class JacksonObjectMapper extends ObjectMapper { public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd"; //LocalDate public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss"; //LocalDateTime // public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm"; public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss"; //LocalTime public JacksonObjectMapper() { super(); //收到未知属性时不报异常 this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false); //反序列化时,属性不存在的兼容处理 this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES); SimpleModule simpleModule = new SimpleModule() .addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT))) .addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT))) .addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT))) .addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT))) .addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT))) .addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT))); //注册功能模块 例如,可以添加自定义序列化器和反序列化器 this.registerModule(simpleModule); } } 数据库操作代码复用 为提高代码复用率,在 Mapper 层统一定义一个通用的 update 方法,利用 MyBatis 的动态 SQL,根据传入的 Employee 对象中非空字段生成对应的 SET 子句。这样: 启用/禁用员工:只需在业务层调用(如 startOrStop),传入带有 id 和 status 的 Employee 实例,底层自动只更新 status 字段。 更新员工信息:调用(如 updateEmployee)时,可传入包含多个属性的 Employee 实例,自动更新那些非空字段。 Controller 层和 Service 层的方法命名可根据不同业务场景进行区分,底层均复用同一个 update方法 在 EmployeeMapper 接口中声明 update 方法: /** * 根据主键动态修改属性 * @param employee */ void update(Employee employee); 在 EmployeeMapper.xml 中编写SQL: <update id="update" parameterType="Employee"> update employee <set> <if test="name != null">name = #{name},</if> <if test="username != null">username = #{username},</if> <if test="password != null">password = #{password},</if> <if test="phone != null">phone = #{phone},</if> <if test="sex != null">sex = #{sex},</if> <if test="idNumber != null">id_Number = #{idNumber},</if> <if test="updateTime != null">update_Time = #{updateTime},</if> <if test="updateUser != null">update_User = #{updateUser},</if> <if test="status != null">status = #{status},</if> </set> where id = #{id} </update> 操作多表时的规范操作 功能:实现批量删除套餐操作,只能删除'非起售中'的套餐,关联表有套餐表和套餐菜品表。 代码1: @Transactional public void deleteBatch(Long[] ids) { for(Long id:ids){ Setmeal setmeal = setmealMapper.getById(id); if(StatusConstant.ENABLE == setmeal.getStatus()){ //起售中的套餐不能删除 throw new DeletionNotAllowedException(MessageConstant.SETMEAL_ON_SALE); } else{ Long setmealId=id; setmealMapper.deleteById(id); setmeal_dishMapper.deleteByDishId(id); } } } 代码2: @Transactional public void deleteBatch(List<Long> ids) { ids.forEach(id -> { Setmeal setmeal = setmealMapper.getById(id); if (StatusConstant.ENABLE == setmeal.getStatus()) { //起售中的套餐不能删除 throw new DeletionNotAllowedException(MessageConstant.SETMEAL_ON_SALE); } }); ids.forEach(setmealId -> { //删除套餐表中的数据 setmealMapper.deleteById(setmealId); //删除套餐菜品关系表中的数据 setmealDishMapper.deleteBySetmealId(setmealId); }); } 代码2更好,因为: 1.把「验证」逻辑和「删除」逻辑分成了两段,职责更单一,读代码的时候一目了然 2.避免不必要的删除操作,第一轮只做 getById 校验,碰到 起售中 马上抛异常,从不执行任何删除 SQL,效率更高。 @Transactional 最典型的场景就是:在同一个业务方法里要执行多条数据库操作(增删改),而且这些操作必须保证“要么都成功、要么都失败” 时,用它来把这些 SQL 语句包裹在同一个事务里,遇到运行时异常就回滚,避免出现“删到一半、中途抛错”导致的数据不一致。也就是说,同时操作多表时,都在方法上加下这个注解! 公共字段自动填充——AOP编程 在数据库操作中,通常需要为某些公共字段(如创建时间、更新时间等)自动赋值。采用AOP: 统一管理这些字段的赋值逻辑 避免在业务代码中重复设置 确保数据一致性 序号 字段名 含义 数据类型 操作类型 1 create_time 创建时间 datetime insert 2 create_user 创建人id bigint insert 3 update_time 修改时间 datetime insert、update 4 update_user 修改人id bigint insert、update 实现步骤: 1). 自定义注解 AutoFill,用于标识需要进行公共字段自动填充的方法 2). 自定义切面类 AutoFillAspect,统一拦截加入了 AutoFill 注解的方法,通过反射为公共字段赋值 客户端 → Service → Mapper接口方法(带@AutoFill) ↓ 切面触发 Before 通知(AutoFillAspect.autoFill) [1] 读取注解,确定 INSERT/UPDATE [2] 从 BaseContext 拿到 currentId [3] 反射调用 entity.setXxx() ↓ 切面执行完毕,回到原方法 Mapper 执行动态 SQL,将已填充的字段写入数据库 3). 在 需要统一填充的Mapper 的方法上加入 AutoFill 注解 **技术点:**枚举、注解、AOP、反射 HttpClient HttpClient作用: 在Java程序中发送HTTP请求 接收响应数据 HttpClient的maven坐标: <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.13</version> </dependency> HttpClient的核心API: HttpClient:Http客户端对象类型,使用该类型对象可发起Http请求。 HttpClients:可认为是构建器,可创建HttpClient对象。 CloseableHttpClient:实现类,实现了HttpClient接口。 HttpGet:Get方式请求类型。 HttpPost:Post方式请求类型。 HttpClient发送请求步骤: 创建HttpClient对象 创建Http请求对象 调用HttpClient的execute方法发送请求 快速入门 @SpringBootTest public class HttpClientTest { /** * 测试通过httpclient发送GET方式的请求 */ @Test public void testGET() throws Exception{ //创建httpclient对象 CloseableHttpClient httpClient = HttpClients.createDefault(); //创建请求对象 HttpGet httpGet = new HttpGet("http://localhost:8080/user/shop/status"); //发送请求,接受响应结果 CloseableHttpResponse response = httpClient.execute(httpGet); //获取服务端返回的状态码 int statusCode = response.getStatusLine().getStatusCode(); System.out.println("服务端返回的状态码为:" + statusCode); HttpEntity entity = response.getEntity(); String body = EntityUtils.toString(entity); System.out.println("服务端返回的数据为:" + body); //关闭资源 response.close(); httpClient.close(); } @Test public void testPOST() throws Exception{ // 创建httpclient对象 CloseableHttpClient httpClient = HttpClients.createDefault(); //创建请求对象 HttpPost httpPost = new HttpPost("http://localhost:8080/admin/employee/login"); JSONObject jsonObject = new JSONObject(); jsonObject.put("username","admin"); jsonObject.put("password","123456"); StringEntity entity = new StringEntity(jsonObject.toString()); //指定请求编码方式 entity.setContentEncoding("utf-8"); //数据格式 entity.setContentType("application/json"); httpPost.setEntity(entity); //发送请求 CloseableHttpResponse response = httpClient.execute(httpPost); //解析返回结果 int statusCode = response.getStatusLine().getStatusCode(); System.out.println("响应码为:" + statusCode); HttpEntity entity1 = response.getEntity(); String body = EntityUtils.toString(entity1); System.out.println("响应数据为:" + body); //关闭资源 response.close(); httpClient.close(); } } 使用时将GET POST方法单独封装到HttpClient工具类中,Service层中直接使用工具类,传入需要的请求体即可。 微信小程序 步骤分析: 小程序端,调用wx.login()获取code,就是授权码。 小程序端,调用wx.request()发送请求并携带code,请求开发者服务器(自己编写的后端服务)。 开发者服务端,通过HttpClient向微信接口服务发送请求,并携带appId+appsecret+code三个参数。 开发者服务端,接收微信接口服务返回的数据,session_key+opendId等。opendId是微信用户的唯一标识。 开发者服务端,自定义登录态,生成令牌token和openid等数据返回给小程序端,方便后绪请求身份校验。 小程序端,收到自定义登录态,存储storage。 小程序端,后绪通过wx.request()发起业务请求时,携带token。 开发者服务端,收到请求后,通过携带的token,解析当前登录用户的id(无需获取openid,因为token中存了userid可以确认用户身份)。 开发者服务端,身份校验通过后,继续相关的业务逻辑处理,最终返回业务数据。 缓存功能 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大。 实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 经典缓存实现代码 缓存逻辑分析: 每个分类下的菜品保存一份缓存数据 数据库中菜品数据有变更时清理缓存数据 @Autowired private RedisTemplate redisTemplate; /** * 根据分类id查询菜品 * * @param categoryId * @return */ @GetMapping("/list") @ApiOperation("根据分类id查询菜品") public Result<List<DishVO>> list(Long categoryId) { //构造redis中的key,规则:dish_分类id String key = "dish_" + categoryId; //查询redis中是否存在菜品数据 List<DishVO> list = (List<DishVO>) redisTemplate.opsForValue().get(key); if(list != null && list.size() > 0){ //如果存在,直接返回,无须查询数据库 return Result.success(list); } //////////////////////////////////////////////////////// Dish dish = new Dish(); dish.setCategoryId(categoryId); dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品 //如果不存在,查询数据库,将查询到的数据放入redis中 list = dishService.listWithFlavor(dish); //////////////////////////////////////////////////////// redisTemplate.opsForValue().set(key, list); return Result.success(list); } 为了保证数据库和Redis中的数据保持一致,修改管理端接口 DishController 的相关方法,加入清理缓存逻辑。 需要改造的方法: 新增菜品 修改菜品 批量删除菜品 起售、停售菜品 清理缓冲方法: private void cleanCache(String pattern){ Set keys = redisTemplate.keys(pattern); redisTemplate.delete(keys); } Spring Cache框架实现缓存 Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> <version>2.7.3</version> </dependency> 在SpringCache中提供了很多缓存操作的注解,常见的是以下的几个: 注解 说明 @EnableCaching 开启缓存注解功能,通常加在启动类上 @Cacheable 在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据(取);如果没有缓存数据,调用方法并将方法返回值放到缓存中 @CachePut 将方法的返回值放到缓存中 @CacheEvict 将一条或多条数据从缓存中删除 1)@CachePut 说明: 作用: 将方法返回值,放入缓存 value: 缓存的名称, 每个缓存名称下面可以有很多key key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法 value 和 cacheNames 属性在用法上是等效的。它们都用来指定缓存区的名称 在Redis中并没有直接的“缓存名”概念,而是通过键(key)来访问数据。Spring Cache通过cacheNames属性来模拟不同的“缓存区”,实际上这是通过将这些名称作为键的一部分来实现的。例如,如果你有一个缓存名为 userCache,那么所有相关的缓存条目的键可能以 "userCache::" 开头。 在save方法上加注解@CachePut @PostMapping @CachePut(value = "userCache", key = "#user.id")//key的生成:userCache::1 public User save(@RequestBody User user){ userMapper.insert(user); return user; } **说明:**key的写法如下 #user.id : #user指的是方法形参的名称, id指的是user的id属性 , 也就是使用user的id属性作为key ; #result.id : #result代表方法返回值,该表达式 代表以返回对象的id属性作为key ; 2)@Cacheable 说明: 作用: 在方法执行前,spring先查看缓存中是否有指定的key的数据,如果有数据,则直接返回缓存数据,不执行后续sql操作;若没有数据,调用方法并将方法返回值放到缓存中。 在getById上加注解@Cacheable @GetMapping @Cacheable(cacheNames = "userCache",key="#id") public User getById(Long id){ User user = userMapper.getById(id); return user; } 3)@CacheEvict 说明: 作用: 清理指定缓存 在 delete 方法上加注解@CacheEvict @DeleteMapping @CacheEvict(cacheNames = "userCache",key = "#id")//删除某个key对应的缓存数据 public void deleteById(Long id){ userMapper.deleteById(id); } @DeleteMapping("/delAll") @CacheEvict(cacheNames = "userCache",allEntries = true)//删除userCache下所有的缓存数据 public void deleteAll(){ userMapper.deleteAll(); } **总结:**新增数据的时候->添加缓存@CachePut ; 查询的时候->判断有无缓存@Cacheable; 删除的时候->删除缓存@CacheEvict。 Spring Cache是经典缓存的上位替代!!! 注意,如果缓存的是套餐分类,即一个套餐分类中含有多个套餐,那么在新增套餐的时候,需要清除相应的套餐分类缓存,因为当你新增一个属于分类 5 的套餐时,原来缓存里那份「分类 5 的列表」已经不再完整──它少了新加的那个套餐。 但是如果缓存的就是套餐本身,新增套餐的时候就可以直接缓存套餐。不要混淆两者! 下单支付 下单 表名 含义 说明 orders 订单表 主要存储订单的基本信息(如: 订单号、状态、金额、支付方式、下单用户、收件地址等) order_detail 订单明细表 主要存储订单详情信息(如: 该订单关联的套餐及菜品的信息) 微信支付 官方文档:https://pay.weixin.qq.com/static/product/product_index.shtml 商户系统调用微信后台: **JSAPI下单:**商户系统调用该接口在微信支付服务后台生成预支付交易单(对应时序图的第5步) 微信小程序调起支付: 通过JSAPI下单接口获取到发起支付的必要参数prepay_id,然后使用微信支付提供的小程序方法调起小程序支付(对应时序图的第10步) 内网穿透 微信后台会调用到商户系统给推送支付的结果,在这里我们就会遇到一个问题,就是微信后台怎么就能调用到我们这个商户系统呢?因为这个调用过程,其实本质上也是一个HTTP请求。 目前,商户系统它的ip地址就是当前自己电脑的ip地址,只是一个局域网内的ip地址,微信后台无法调用到。 解决:内网穿透。通过cpolar软件可以获得一个临时域名,而这个临时域名是一个公网ip,这样,微信后台就可以请求到商户系统了。 1)下载地址:https://dashboard.cpolar.com/get-started 2). cpolar指定authtoken 复制authtoken: 执行命令: 注意,cd到cpolar.exe所在的目录打开cmd 输入代码: cpolar.exe authtoken ZmIwMmQzZDYtZDE2ZS00ZGVjLWE2MTUtOGQ0YTdhOWI2M2Q1 3)获取临时域名 cpolar.exe http 8080 这里的 https://52ac2ecb.r18.cpolar.top 就是与http://localhost:8080对应的临时域名。 原理: 客户端向 cpolar 的中转节点发起 出站(outbound)连接,完成身份认证(authtoken),并在连接上报出要映射的本地端口,比如 HTTP 的 8080 中转节点分配一个公网端点,如abcd1234.cpolar.com 外部用户 访问 http://abcd1234.cpolar.com,落到 cpolar 的中转节点,中转节点 通过先前建立好的持久隧道,把流量转发到你本地运行的客户端。 百度地址解析 优化用户下单功能,加入校验逻辑,如果用户的收货地址距离商家门店超出配送范围(配送范围为5公里内),则下单失败。 思路: 1. 基于百度地图开放平台实现(https://lbsyun.baidu.com/) 2. 注册账号--->创建应用获取AK(服务端应用)--->调用接口 相关接口 https://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding https://lbsyun.baidu.com/index.php?title=webapi/directionlite-v1 商家门店地址可以配置在配置文件中,例如: sky: shop: address: 湖北省武汉市洪山区武汉理工大学 baidu: ak: ${sky.baidu.ak} Spring Task Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑。 **定位:**定时任务框架 **作用:**定时自动执行某段Java代码 cron表达式 cron表达式其实就是一个字符串,通过cron表达式可以定义任务触发的时间 **构成规则:**分为6或7个域,由空格分隔开,每个域代表一个含义 每个域的含义分别为:秒、分钟、小时、日、月、周、年(可选) 通配符: * 表示所有值; ? 表示未说明的值,即不关心它为何值; - 表示一个指定的范围; , 表示附加一个可能值; / 符号前表示开始时间,符号后表示每次递增的值; cron表达式案例: */5 * * * * ? 每隔5秒执行一次 0 0 5-15 * * ? 每天5-15点整点触发 0 0/3 * * * ? 每三分钟触发一次 0 0-5 14 * * ? 在每天下午2点到下午2:05期间的每1分钟触发 0 10/5 14 * * ? 在每天下午2点10分到下午2:55期间的每5分钟触发 0 0/30 9-17 * * ? 朝九晚五工作时间内每半小时 0 0 10,14,16 * * ? 每天上午10点,下午2点,4点 cron表达式在线生成器:https://cron.qqe2.com/ 现在可以直接GPT生成! 入门案例 Spring Task使用步骤 1). 导入maven坐标 spring-context(Spring Boot Starter已包含,无需导入!) 2). 启动类添加注解 @EnableScheduling 开启任务调度 3). 自定义定时任务类,然后只要在方法上标注 @Scheduled(cron = xxx) @Slf4j @Component public class MyTask { //定时任务 每隔5秒触发一次 @Scheduled(cron = "0/5 * * * * ?") public void executed(){ log.info("定時任務開始執行:{}",new Date()); } } 订单状态定时处理 用户下单后可能存在的情况: 下单后未支付,订单一直处于**“待支付”**状态 用户收货后管理端未点击完成按钮,订单一直处于**“派送中”**状态 对于上面两种情况需要通过定时任务来修改订单状态,具体逻辑为: 通过定时任务每分钟检查一次是否存在支付超时订单(下单后超过15分钟仍未支付则判定为支付超时订单),如果存在则修改订单状态为“已取消” 通过定时任务每天凌晨1点(打烊后)检查一次是否存在“派送中”的订单,如果存在则修改订单状态为“已完成” Websocket WebSocket 是基于 TCP 的一种新的网络协议。它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接, 并进行双向数据传输。 HTTP协议和WebSocket协议对比: HTTP是短连接 WebSocket是长连接 HTTP通信是单向的,基于请求响应模式 WebSocket支持双向通信 HTTP和WebSocket底层都是TCP连接 工作流程: 1.握手(Handshake) 客户端发起一个特殊的 HTTP 请求(带有 Upgrade: websocket 和 Connection: Upgrade 头) 服务端如果支持 WebSocket,则返回 HTTP 101 Switching Protocols,双方在同一个 TCP 连接上切换到 WebSocket 协议 2.数据帧交换 握手成功后,客户端和服务端可以互相推送(push)“数据帧”(Frame),不再有 HTTP 的请求/响应模型 3.关闭连接 任一端发送关闭控制帧(Close Frame),对方确认后关闭 TCP 连接 WebSocket应用场景: 视频弹幕、实时聊天、体育实况更新、股票基金实时更新报价 入门案例 实现步骤: 1). 直接使用websocket.html页面作为WebSocket客户端 http://localhost:8080/ws/12345 最主要的是建立websocket连接! 2). 导入WebSocket的maven坐标 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency> 3). 导入WebSocket服务端组件WebSocketServer,用于和客户端通信(比较固定,建立连接、接收消息、关闭连接、发送消息) 基于 JSR-356(Java WebSocket API) 的“注解型”实现 @ServerEndpoint("/ws/{sid}") 来声明一个 WebSocket 端点,容器(如 Tomcat/Jetty)或 Spring 的 ServerEndpointExporter 会扫描并注册它。 @OnOpen、@OnMessage、@OnClose、@OnError 等标注的方法,分别对应连接建立、收到消息、连接关闭和出错时的回调。 /** * WebSocket服务 */ @Component @ServerEndpoint("/ws/{sid}") public class WebSocketServer { //存放会话对象 private static Map<String, Session> sessionMap = new HashMap(); /** * 连接建立成功调用的方法 */ @OnOpen public void onOpen(Session session, @PathParam("sid") String sid) { System.out.println("客户端:" + sid + "建立连接"); sessionMap.put(sid, session); } /** * 收到客户端消息后调用的方法 * * @param message 客户端发送过来的消息 */ @OnMessage public void onMessage(String message, @PathParam("sid") String sid) { System.out.println("收到来自客户端:" + sid + "的信息:" + message); } /** * 连接关闭调用的方法 * * @param sid */ @OnClose public void onClose(@PathParam("sid") String sid) { System.out.println("连接断开:" + sid); sessionMap.remove(sid); } /** * 群发 * * @param message */ public void sendToAllClient(String message) { Collection<Session> sessions = sessionMap.values(); for (Session session : sessions) { try { //服务器向客户端发送消息 session.getBasicRemote().sendText(message); } catch (Exception e) { e.printStackTrace(); } } } } 4). 导入配置类WebSocketConfiguration,注册WebSocket的服务端组件 /** * WebSocket配置类,用于注册WebSocket的Bean */ @Configuration public class WebSocketConfiguration { @Bean public ServerEndpointExporter serverEndpointExporter() { return new ServerEndpointExporter(); } } 作用:找到@ServerEndpoint 的类并注册到容器中。 5). 导入定时任务类WebSocketTask,定时向客户端推送数据 @Component public class WebSocketTask { @Autowired private WebSocketServer webSocketServer; /** * 通过WebSocket每隔5秒向客户端发送消息 */ @Scheduled(cron = "0/5 * * * * ?") public void sendMessageToClient() { webSocketServer.sendToAllClient("这是来自服务端的消息:" + DateTimeFormatter.ofPattern("HH:mm:ss").format(LocalDateTime.now())); } } 这里可以改为来单提醒、催单提醒。 来单提醒 设计思路: 通过WebSocket实现管理端页面和服务端保持长连接状态 当客户支付后,调用WebSocket的相关API实现服务端向客户端推送消息 客户端浏览器解析服务端推送的消息,判断是来单提醒还是客户催单,进行相应的消息提示和语音播报 约定服务端发送给客户端浏览器的数据格式为JSON,字段包括:type,orderId,content type 为消息类型,1为来单提醒 2为客户催单 orderId 为订单id content 为消息内容 数据展示与处理 数据展示 Apache ECharts 是一款基于 Javascript 的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。 官网地址:https://echarts.apache.org/zh/index.html 例:营业额统计 具体返回数据一般由前端来决定,前端展示图表,折线图对应数据是什么格式,是有固定的要求的。所以说,后端需要去适应前端,它需要什么格式的数据,后端就返回什么格式的数据。 导出数据到Excel Apache POI 我们可以使用 POI 在 Java 程序中对Miscrosoft Office各种文件进行读写操作。一般情况下,POI 都是用于操作 Excel 文件。 Apache POI的maven坐标 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.16</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.16</version> </dependency> 实现步骤: 1). 设计Excel模板文件! 2). 查询近30天的运营数据 3). 将查询到的运营数据写入模板文件 row = sheet.getRow(7 + i); //获取行 row.getCell(1).setCellValue(date.toString()); //获取该行的某列,并设值。 4). 通过输出流将Excel文件下载到客户端浏览器
项目
zy123
1年前
0
43
0
2025-03-21
安卓开发
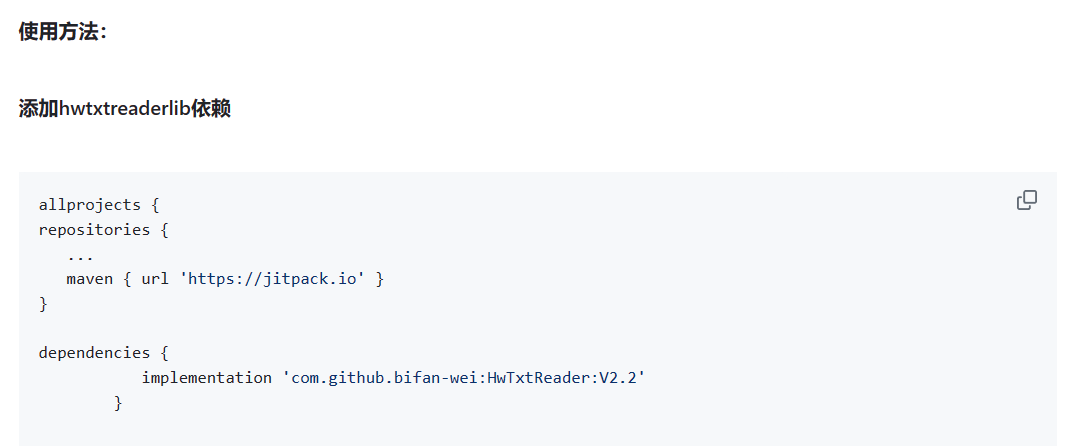
安卓开发 导入功能模块心得 最近想在我的书城中增加一个阅读器的功能,难度颇高,因此在github上找到了一个封装了阅读器功能的项目,仅需获得文件本地存储地址,调用其提供的函数即可进行阅读。 但是,github介绍的使用方法并不总是有效,比如我就经常无法正确添加依赖 因此,我将其项目代码拷贝到本地,手动集成。 依据项目结构,可以发现app是主项目,hwtxtreaderlib是功能模块,根据是这张图: build.gradle(:app)中引入了hwtxtreaderlib的依赖,而app只是个demo测试模块,相当于演示了如果在自己的项目中引用hwtxtreaderlib。因此,手动步骤如下: 将hwtxtreaderlib复制到自己的项目文件夹中 在app的build.gradle中,添加依赖 implementation project(':hwtxtreaderlib') 在settings.gradle中,设置项目包括的模块 include ':app', ':hwtxtreaderlib' syn now! 同步一下,然后android studio中项目结构变成如下图 build没报错基本就稳了,然后就运行试试 这里可能AndroidManifest.xml报错,需要查看原项目中app模块如何编写的,做些适当的修改!我这里卡了很久. 有时候github项目会将项目的详细信息写在wiki中!!! 如何运行本项目? 用前须知: 本项目需联网使用,数据存储在后端云Bmob中,目前续费日期到7.22日结束,之后可能会出现无法运行情况。 内置的阅读小助手调用了chatgpt,但是通过国内网站镜像,因此无须连接vpn,且密钥写在项目中了,无须额外配置,直接使用即可,额度有限,超额小助手会无法响应,但基本不会超额 可以注册用户,也可以直接使用账号:6462 密码:123 登录 如有问题,联系我的qq:3061033470 法一(推荐): 本项目已经打包成签名的发布版APK,可以直接在apk文件夹下找到app-release.apk,发送到安卓手机上下载安装(需要在设置上启用‘安装未知来源的应用’),打开app登录即可使用。效果如下: 注意:可能部分手机打开会出现颜色显示问题,目前未解决该问题 法二 JianShu为项目文件,需要存放在无中文的路径中!!! 下载2022版本的android studio(老旧版本可能出现bug) android studio内置各种安卓模拟机,需要首先打开Device Manager下载,建议下载Pixel 5 API30,下载模拟机可能耗时几分钟 导入本项目,点击根目录 Gradle会自动导入依赖,下载本项目所依赖的文件,若android studio右下角停止加载则说明项目导入成功,第一次加载时间可能比较长 如果意外中断了,可以在Android Studio中,点击File > Sync Project with Gradle Files。 运行项目,第一次运行会在模拟机上安卓该app 出现登录界面则成功
后端学习
zy123
1年前
0
23
0
2025-03-21
Redis
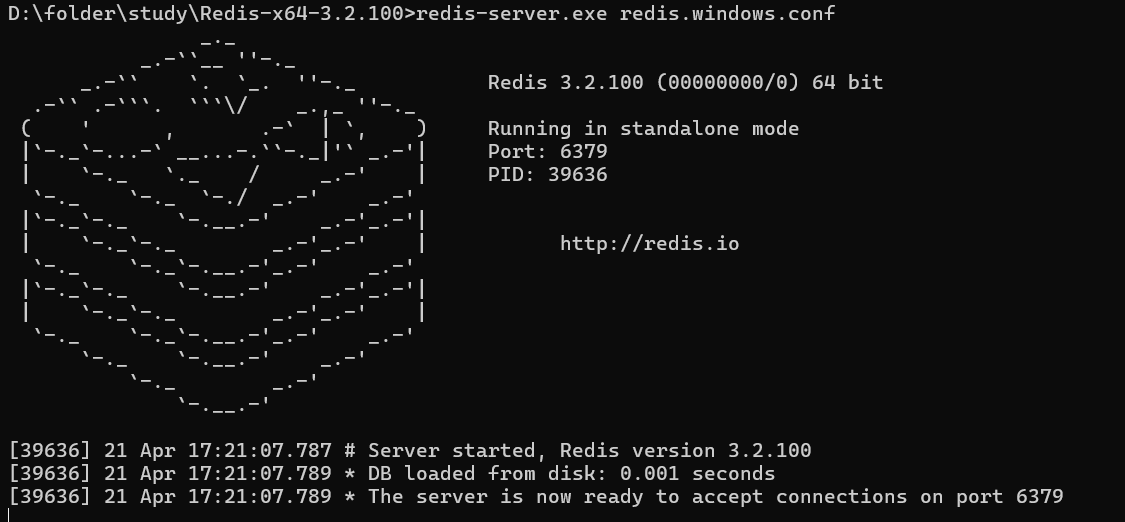
Redis Redis基本定义 Redis是一个基于内存的key-value结构数据库。Redis 是互联网技术领域使用最为广泛的存储中间件。 Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化的NoSql数据库(非关系型)。 典型场景: 热点数据缓存(商品/资讯/秒杀) 会话管理(Session) 排行榜/计数器 消息队列(Stream) NoSQL数据库: 键值型(Redis) 文档型(MongoDB) 列存储(HBase) 图数据库(Neo4j) 下载与使用 Redis安装包分为windows版和Linux版: Windows版下载地址:https://github.com/microsoftarchive/redis/releases Linux版下载地址: https://download.redis.io/releases/ 角色 作用 典型示例 Redis 服务端 数据存储的核心,负责接收/执行命令、管理内存、持久化数据等。需先启动服务端才能使用。 redis-server(默认监听 6379 端口) Redis 客户端 连接服务端并发送命令(如 GET/SET),获取返回结果。可以是命令行工具或代码库。 redis-cli、Java 的 Jedis 库 windows下服务启动/停止: 启动: redis-server.exe redis.windows.conf 这种方式关闭命令行后Redis服务又停止了! 解决方法:安装为 Windows 服务 redis-server --service-install redis.windows.conf --service-name Redis redis-server --service-start 停止: ctrl+c 客户端连接: 直接运行 redis-cli.exe 时,它会尝试连接 本机(127.0.0.1)的 Redis 服务端,并使用默认端口 6379。 等价于手动指定参数: redis-cli -h 127.0.0.1 -p 6379 指定连接: redis-cli -h <IP> -p <端口> -a <密码> redis-cli -h 192.168.1.100 -p 6379 -a yourpassword 退出连接:exit 修改Redis配置文件 设置Redis服务密码,修改redis.windows.conf(windows) redis.conf(linux) requirepass 123456 修改redis服务端口 port 6379 Redis客户端图形工具 默认提供的客户端连接工具界面不太友好,可以使用Another Redis Desktop Manager.exe ,类似Navicat连mysql。 Redis数据类型 Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型: 字符串(string):普通字符串,Redis中最简单的数据类型 哈希(hash):也叫散列,类似于Java中的HashMap结构。(套娃) 列表(list):按照插入顺序排序,可以有重复元素,类似于Java中的LinkedList 集合(set):无序集合,没有重复元素,类似于Java中的HashSet(求交集) 有序集合(sorted set/zset):集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素(排行榜) Redis常用命令 通用命令 Redis的通用命令是不分数据类型的,都可以使用的命令: KEYS pattern 查找所有符合给定模式( pattern)的 key pattern:匹配模式,支持通配符: *:匹配任意多个字符(包括空字符) ?:匹配单个字符 [abc]:匹配 a、b 或 c 中的任意一个字符 [a-z]:匹配 a 到 z 之间的任意一个字符 KEYS user:* #可以返回 形如 "user:1" "user:2" 的 key KEYS * #查找所有key 在线上不要用 KEYS prefix:*,它是阻塞全库扫描,键多时会卡住 Redis。 EXISTS key 检查给定 key 是否存在 TYPE key 返回 key 所储存的值的类型 DEL key 该命令用于在 key 存在时删除 key 字符串 Redis 中字符串类型常用命令: SET key value 设置指定key的值 GET key 获取指定key的值 SET key value EX seconds 设置指定key的值,并将 key 的过期时间设为 seconds 秒(验证码) EX可以换为PX,表示毫秒 SET key value NX EX seconds 只有在 key不存在时设置 key 的值 哈希操作 Redis hash 是一个string类型的 field 和 value 的映射表,hash特别适合用于存储对象,常用命令: HSET key field value 将哈希表 key 中的字段 field 的值设为 value HGET key field 获取存储在哈希表中指定字段的值 HDEL key field 删除存储在哈希表中的指定字段 HKEYS key 获取哈希表中所有字段 HVALS key 获取哈希表中所有值 列表操作 Redis 列表是简单的字符串列表,按照插入顺序排序,常用命令: LPUSH key value1 将一个值插入到列表头部 RPUSH key value1 [value2] 将一个或多个值插入到列表尾部 RPUSH mylist "world" "redis" "rpush" #多个值插入 LRANGE key start stop 获取列表指定范围内的元素(这里L代表List 不是Left) LRANGE mylist 0 -1 #获取整个列表 LLEN key 获取列表长度 RPOP key 移除并获取列表最后一个元素 BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超 时或发现可弹出元素为止 集合操作 Redis set 是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,常用命令: SADD key member1 [member2] 向集合添加一个或多个成员 # 添加单个成员 SADD fruits "apple" # 添加多个成员(自动去重) SADD fruits "banana" "orange" "apple" # "apple" 已存在,不会重复添加 SMEMBERS key 返回集合中的所有成员 SCARD key 获取集合的成员数(基数Cardinality) SINTER key1 [key2] 返回给定所有集合的交集 SUNION key1 [key2] 返回所有给定集合的并集 SREM key member1 [member2] 移除集合中一个或多个成员 有序集合 Redis有序集合是string类型元素的集合,且不允许有重复成员。每个元素都会关联一个double类型的分数。常用命令: 常用命令: ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员(score代表分数) ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员 ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment ZREM key member [member ...] 移除有序集合中的一个或多个成员 可以实现延迟消息 数据结构 延迟队列:ZSET delay:queue member:jobId(或直接存 JSON) score:“到期时间戳”(建议毫秒) 作业数据:HASH job:{jobId}(可选,放 payload、重试次数等) 生产者(投递延迟消息) 计算 due_ts = now + delay_ms ZADD delay:queue due_ts jobId (可选)HSET job:{jobId} payload ... retry 0 消费者(不断拉取到期任务处理) 周期性检查当前时间 now 取到期任务:ZRANGEBYSCORE delay:queue -inf now LIMIT 0 N ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 从有序集合(ZSET)中取出所有 score 在 [min, max] 区间的元素,按分数从小到大返回。 抢占删除(防止并发多消费者重复处理): 方式A(Redis 5+):Lua 脚本里判断并 ZPOPMIN/ZREMRANGEBYRANK 方式B:WATCH + ZREM 比对(不如 Lua 简洁) 处理成功:删除作业数据 DEL job:{jobId}(或标记完成) 处理失败:重试回投,ZADD delay:queue new_due jobId,并在 job:{jobId} 里递增 retry Java中操作Redis Spring Data Redis 是 Spring 的一部分,提供了在 Spring 应用中通过简单的配置就可以访问 Redis 服务,就如同我们使用JDBC操作MySQL数据库一样。 网址:https://spring.io/projects/spring-data-redis 环境搭建 进入到sky-server模块 1). 导入Spring Data Redis的maven坐标(已完成) <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 2). 配置Redis数据源 在application-dev.yml中添加 sky: redis: host: localhost port: 6379 password: 123456 database: 10 解释说明: database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15。 可以通过修改Redis配置文件来指定数据库的数量。 在application.yml中添加读取application-dev.yml中的相关Redis配置 spring: profiles: active: dev redis: host: ${sky.redis.host} port: ${sky.redis.port} password: ${sky.redis.password} database: ${sky.redis.database} 3). 编写配置类,创建RedisTemplate对象 @Configuration @Slf4j public class RedisConfiguration { @Bean public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){ log.info("开始创建redis模板对象..."); RedisTemplate redisTemplate = new RedisTemplate(); //设置redis的连接工厂对象 redisTemplate.setConnectionFactory(redisConnectionFactory); //设置redis key的序列化器 redisTemplate.setKeySerializer(new StringRedisSerializer()); return redisTemplate; } } 解释说明: 当前配置类不是必须的,因为 Spring Boot 框架会自动装配 RedisTemplate 对象,但是默认的key序列化器为 JdkSerializationRedisSerializer,存到 Redis 里会是二进制格式,这里把 key 的序列化器指定为 StringRedisSerializer,就会把所有的 key 都以 UTF‑8 字符串形式写入 Redis,方便观测和调试 功能测试 通过RedisTemplate对象操作Redis,注意要Another Redis Desktop中刷新一下数据库,才能看到数据。 字符串测试 @DataRedisTest @Import(com.sky.config.RedisConfiguration.class) public class SpringDataRedisTest { @Autowired private RedisTemplate redisTemplate; @Test public void testRedisTemplate(){ System.out.println(redisTemplate); } @Test public void testString(){ // SET city "北京" redisTemplate.opsForValue().set("city", "北京"); // GET city String city = (String) redisTemplate.opsForValue().get("city"); System.out.println(city); // SETEX code 180 "1234" (3 分钟 = 180 秒) redisTemplate.opsForValue().set("code", "1234", 3, TimeUnit.MINUTES); // SETNX lock "1" redisTemplate.opsForValue().setIfAbsent("lock", "1"); // (由于上一步 lock 已存在,这里相当于不执行) // SETNX lock "2" redisTemplate.opsForValue().setIfAbsent("lock", "2"); } } 对于非String类型: 写入时序列化 调用 opsForValue().set(key, value) 时,value(比如 List<DishVO>)会先走一遍 ValueSerializer。 默认是 JdkSerializationRedisSerializer,它用 Java 的 ObjectOutputStream 把整个对象图打包成一个 byte[]。 这个 byte[] 直接就存成了 Redis 的 String 值。 读取时反序列化 调用 opsForValue().get(key) 时,RedisTemplate 拿回那段 byte[],再用同一个 JDK 序列化器(ObjectInputStream)把它变回 List<DishVO>。 哈希测试 @Test public void testHash(){ HashOperations hashOperations = redisTemplate.opsForHash(); // HSET 100 "name" "tom" hashOperations.put("100", "name", "tom"); // HSET 100 "age" "20" hashOperations.put("100", "age", "20"); // HGET 100 "name" String name = (String) hashOperations.get("100", "name"); System.out.println(name); // HKEYS 100 Set keys = hashOperations.keys("100"); System.out.println(keys); // HVALS 100 List values = hashOperations.values("100"); System.out.println(values); // HDEL 100 "age" hashOperations.delete("100", "age"); } get获得的是Object类型,keys获得的是set类型,values获得的是List 3). 操作列表类型数据 @Test public void testList(){ ListOperations listOperations = redisTemplate.opsForList(); // LPUSH mylist "a" "b" "c" listOperations.leftPushAll("mylist", "a", "b", "c"); // LPUSH mylist "d" listOperations.leftPush("mylist", "d"); // LRANGE mylist 0 -1 List mylist = listOperations.range("mylist", 0, -1); System.out.println(mylist); // RPOP mylist listOperations.rightPop("mylist"); // LLEN mylist Long size = listOperations.size("mylist"); System.out.println(size); } 4). 操作集合类型数据 @Test public void testSet(){ SetOperations setOperations = redisTemplate.opsForSet(); // SADD set1 "a" "b" "c" "d" setOperations.add("set1", "a", "b", "c", "d"); // SADD set2 "a" "b" "x" "y" setOperations.add("set2", "a", "b", "x", "y"); // SMEMBERS set1 Set members = setOperations.members("set1"); System.out.println(members); // SCARD set1 Long size = setOperations.size("set1"); System.out.println(size); // SINTER set1 set2 Set intersect = setOperations.intersect("set1", "set2"); System.out.println(intersect); // SUNION set1 set2 Set union = setOperations.union("set1", "set2"); System.out.println(union); // SREM set1 "a" "b" setOperations.remove("set1", "a", "b"); } 5). 操作有序集合类型数据 @Test public void testZset(){ ZSetOperations zSetOperations = redisTemplate.opsForZSet(); // ZADD zset1 10 "a" zSetOperations.add("zset1", "a", 10); // ZADD zset1 12 "b" zSetOperations.add("zset1", "b", 12); // ZADD zset1 9 "c" zSetOperations.add("zset1", "c", 9); // ZRANGE zset1 0 -1 Set zset1 = zSetOperations.range("zset1", 0, -1); System.out.println(zset1); // ZINCRBY zset1 10 "c" zSetOperations.incrementScore("zset1", "c", 10); // ZREM zset1 "a" "b" zSetOperations.remove("zset1", "a", "b"); } 6). 通用命令操作 * 匹配零个或多个字符。 ? 匹配任何单个字符。 [abc] 匹配方括号内的任一字符(本例中为 'a'、'b' 或 'c')。 [^abc] 或 [!abc] 匹配任何不在方括号中的单个字符。 @Test public void testCommon(){ // KEYS * Set keys = redisTemplate.keys("*"); System.out.println(keys); // EXISTS name Boolean existsName = redisTemplate.hasKey("name"); System.out.println("name exists? " + existsName); // EXISTS set1 Boolean existsSet1 = redisTemplate.hasKey("set1"); System.out.println("set1 exists? " + existsSet1); for (Object key : keys) { // TYPE <key> DataType type = redisTemplate.type(key); System.out.println(key + " -> " + type.name()); } // DEL mylist redisTemplate.delete("mylist"); } 7)批量清除某个前缀开头的所有缓存 key 1.采用游标机制(非阻塞),每次只扫描一部分 key,适合生产。 @Autowired private StringRedisTemplate stringRedisTemplate; public void clearCacheByPrefix(String prefix) { ScanOptions options = ScanOptions.scanOptions().match(prefix + "*").count(1000).build(); Cursor<byte[]> cursor = stringRedisTemplate.getConnectionFactory() .getConnection() .scan(options); while (cursor.hasNext()) { String key = new String(cursor.next()); stringRedisTemplate.delete(key); } } # 不推荐生产用 KEYS user:* # 推荐生产用(配合 cursor) SCAN 0 MATCH user:* COUNT 1000 2.更优雅的方法是 在业务逻辑上增加一层命名空间,不用真正去删: 缓存的 key 格式:{prefix}:{namespace}:{realKey} 当你要“清空前缀缓存”时,只要更新 namespace(比如加一个时间戳或版本号),旧的 key 就算还在 Redis 中,也会失效,因为不会再被访问到。 String namespace = "v1"; // 放到配置里 String key = prefix + ":" + namespace + ":" + realKey; 当要清理时,把 namespace 改为 v2 即可,所有旧缓存自动失效。 Redisson 快速入门 1. 引入依赖 <dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.26.0</version> </dependency> 2. 在 application.yml 中配置 Redis 连接(Redisson 会自动读取) spring: redis: host: localhost port: 6379 password: # 如无密码则留空 database: 0 3. 可选:自定义 RedissonClient 配置(无需也可不写) @Configuration public class RedissonConfig { @Bean public RedissonClient redissonClient() { org.redisson.config.Config config = new org.redisson.config.Config(); config.useSingleServer() .setAddress("redis://localhost:6379") .setDatabase(0); return org.redisson.Redisson.create(config); } } 4.最简单的锁使用示例(默认看门狗机制) @Service public class SimpleLockService { private final RedissonClient redissonClient; public SimpleLockService(RedissonClient redissonClient) { this.redissonClient = redissonClient; } public void doWithLock(String lockName) { RLock lock = redissonClient.getLock(lockName); try { // 获取锁(阻塞式) lock.lock(); // 在这里执行需要加锁的业务逻辑 System.out.println("执行业务代码..."); } finally { // 释放锁 lock.unlock(); } } } 5.带超时的锁使用示例 @Service public class TimeoutLockService { private final RedissonClient redissonClient; public TimeoutLockService(RedissonClient redissonClient) { this.redissonClient = redissonClient; } public boolean tryDoWithLock(String lockName) { RLock lock = redissonClient.getLock(lockName); try { // 尝试获取锁(最多等待5秒,锁持有10秒后自动释放) if (lock.tryLock(5, 10, TimeUnit.SECONDS)) { try { // 在这里执行需要加锁的业务逻辑 System.out.println("执行业务代码..."); return true; } finally { lock.unlock(); } } return false; } catch (InterruptedException e) { Thread.currentThread().interrupt(); return false; } } }
后端学习
zy123
1年前
0
14
0
上一页
1
...
8
9
10
...
12
下一页