首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
41 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
找到
58
篇与
zy123
相关的结果
- 第 4 页
2025-06-17
强化学习
强化学习 Q-learning 核心更新公式 $$ \boxed{Q(s,a) \gets Q(s,a) + \alpha\left[r + \gamma\,\max_{a'}Q(s',a') - Q(s,a)\right]} $$ - $s$:当前状态 - $a$:当前动作 - $r$:执行 $a$ 后获得的即时奖励 - $s'$:执行后到达的新状态 - $\alpha\in(0,1]$:学习率,决定“这次新信息”对旧值的影响力度 - $\gamma\in[0,1)$:折扣因子,衡量对“后续奖励”的重视程度 - $\max_{a'}Q(s',a')$:新状态下可选动作的最大估值,表示“后续能拿到的最大预期回报” 一般示例 环境设定 状态集合:${S_1, S_2}$ 动作集合:${a_1, a_2}$ 转移与奖励: 在 $S_1$ 选 $a_1$ → 获得 $r=5$,转到 $S_2$ 在 $S_1$ 选 $a_2$ → 获得 $r=0$,转到 $S_2$ 在 $S_2$ 选 $a_1$ → 获得 $r=0$,转到 $S_1$ 在 $S_2$ 选 $a_2$ → 获得 $r=1$,转到 $S_1$ 超参数:$\alpha=0.5$,$\gamma=0.9$ 初始化:所有 $Q(s,a)=0$ 在 Q-Learning 里,智能体并不是“纯随机”地走,也不是“一开始就全凭 Q 表拿最高值”——而是常用一种叫 $\epsilon$-greedy 的策略来平衡: 探索(Exploration):以概率 $\epsilon$(比如 10%)随机选一个动作,帮助智能体发现还没试过、可能更优的路径; 利用(Exploitation):以概率 $1-\epsilon$(比如 90%)选当前状态下 Q 值最高的动作,利用已有经验最大化回报。 下面按序进行 3 步“试—错”更新,并在表格中展示每一步后的 $Q$ 值。 步骤 状态 $s$ 动作 $a$ 奖励 $r$ 到达 $s'$ $\max_{a'}Q(s',a')$ 更新后 $Q(s,a)$ 当前 Q 表 初始 — — — — — — $Q(S_1,a_1)=0,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=0$ 1 $S_1$ $a_1$ 5 $S_2$ 0 $0+0.5,(5+0-0)=2.5$ $Q(S_1,a_1)=2.5,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=0$ 2 $S_2$ $a_2$ 1 $S_1$ $到达S_1状态后选择最优动作:$$\max{2.5,0}=2.5$ $0+0.5,(1+0.9\cdot2.5-0)=1.625$ $Q(S_1,a_1)=2.5,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=1.625$ 3 $S_1$ $a_1$ 5 $S_2$ $\max{0,1.625}=1.625$ $2.5+0.5,(5+0.9\cdot1.625-2.5)\approx4.481$ $Q(S_1,a_1)\approx4.481,;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,;Q(S_2,a_2)=1.625$ 第1步:从 $S_1$ 选 $a_1$,立即回报5,更新后 $Q(S_1,a_1)=2.5$。 第2步:从 $S_2$ 选 $a_2$,回报1,加上对 $S_1$ 后续最优值的 $0.9$ 折扣,得到 $1+0.9\times2.5=3.25$,更新后 $Q(S_2,a_2)=1.625$。 第3步:再一次在 $S_1$ 选 $a_1$,这次考虑了 $S_2$ 的最新估值,最终把 $Q(S_1,a_1)$ 提升到约 4.481。 通过这样一步步的“试—错 + 贝尔曼更新”,Q-Learning 能不断逼近最优 $Q^*(s,a)$,从而让智能体在每个状态都学会选出长期回报最高的动作。 训练结束后,表里每个状态 $s$ 下各动作的 Q 值都相对准确了,我们就可以直接读表来决策: $$ \pi(s) = \arg\max_a Q(s,a) $$ 即“在状态 $s$ 时,选 Q 值最高的动作”。 状态 \ 动作 $a_1$ $a_2$ $S_1$ 4.481 0 $S_2$ 0 1.625 DQN 核心思想:用深度神经网络近似 Q 函数来取代表格,在高维输入上直接做 Q-learning,并通过 经验回放(写进缓冲区 + 随机抽样训练”) + 目标网络(Target Network) 两个稳定化技巧,使 时序差分(TD )学习在非线性函数逼近下仍能收敛。 TD 学习 = 用“即时奖励 + 折扣后的未来估值”作为目标,通过 TD 误差持续修正当前估计。 训练过程 1. 初始化 主网络(Online Network) 定义一个 Q 网络 $Q(s,a;\theta)$,随机初始化参数 $\theta$。 目标网络(Target Network) 复制主网络参数,令 $\theta^- \leftarrow \theta$。 目标网络用于计算贝尔曼目标值,短期内保持不变。 经验回放缓冲区(Replay Buffer) 创建一个固定容量的队列 $\mathcal{D}$,用于存储交互样本 $(s,a,r,s')$。 超参数设置 学习率 $\eta$ 折扣因子 $\gamma$ ε-greedy 探索率 $\epsilon$(初始值) 最小训练样本数阈值 $N_{\min}$ 每次训练的小批量大小 $B$ 目标网络同步频率 $C$(梯度更新次数间隔) 2. 与环境交互并存储经验 在每个时间步 $t$: 动作选择 $$ a_t = \begin{cases} \text{随机动作} & \text{以概率 }\epsilon,\ \arg\max_a Q(s_t,a;\theta) & \text{以概率 }1-\epsilon. \end{cases} $$ 环境反馈 执行动作 $a_t$,得到奖励 $r_t$ 和下一个状态 $s_{t+1}$。 (需预先定义奖励函数) 存入缓冲区 将元组 $(s_t, a_t, r_t, s_{t+1})$ 存入 Replay Buffer $\mathcal{D}$。 如果 $\mathcal{D}$ 已满,则丢弃最早的样本。 3. 批量随机采样并训练 当缓冲区样本数 $\ge N_{\min}$ 时,每隔一次或多次环境交互,就进行一次训练更新: 随机抽取小批量 从 $\mathcal{D}$ 中随机采样 $B$ 条过往经验: $$ {(s_i, a_i, r_i, s'i)}{i=1}^B $$ 计算贝尔曼目标 对每条样本,用目标网络 $\theta^-$ 计算: $$ y_i = r_i + \gamma \max_{a'}Q(s'_i, a'; \theta^-) $$ 算的是:当前获得的即时奖励 $r_i$,加上“到了下一个状态后,做最优动作所能拿到的最大预期回报” 预测当前 Q 值 将当前状态-动作对丢给主网络 $\theta$,得到预测值: $$ \hat Q_i = Q(s_i, a_i;\theta) $$ 算的是:在当前状态 $s_i$、选了样本里那个动作 $a_i$ 时,网络现在估计的价值 构造损失函数 均方误差(MSE)损失: $$ L(\theta) = \frac{1}{B}\sum_{i=1}^B\bigl(y_i - \hat Q_i\bigr)^2 $$ 梯度下降更新主网络 $$ \theta \gets \theta - \eta \nabla_\theta L(\theta) $$ 4. 同步/软更新目标网络 硬同步(Fixed Target): 每做 $C$ 次梯度更新,就执行 $$ \theta^- \gets \theta $$ (可选)软更新: 用小步长 $\tau\ll1$ 平滑跟踪: $$ \theta^- \gets \tau \theta + (1-\tau) \theta^-. $$ 5. 重复训练直至收敛 重复步骤 2-4 直至满足终止条件(如最大回合数或性能指标)。 训练过程中可逐步衰减 $\epsilon$(ε-greedy),从更多探索过渡到更多利用。 示例 假设设定 动作空间:两个动作 ${a_1,a_2}$。 状态向量维度:2 维,记作 $s=(s_1,s_2)$。 目标网络结构(极简线性网络): $$ Q(s;\theta^-) = W^-s + b^-, $$ $W^-$ 是 $2\times2$ 的权重矩阵 (行数为动作数,列数为状态向量维数) $b^-$ 是长度 2 的偏置向量 网络参数(假定已初始化并被冻结): $$ W^- = \begin{pmatrix} 0.5 & -0.2\ 0.1 & ;0.3 \end{pmatrix},\quad b^- = \begin{pmatrix}0.1\-0.1\end{pmatrix}. $$ 折扣因子 $\gamma=0.9$。 样本数据 假设我们抽到的一条经验是 $$ (s_i,a_i,r_i,s'_i) = \bigl((0.0,\;1.0),\;a_1,\;2,\;(1.5,\,-0.5)\bigr). $$ 当前状态 $s_i=(0.0,1.0)$,当时选了动作 $a_1$ 并得到奖励 $r_i=2$。 到达新状态 $s'_i=(1.5,-0.5)$。 计算过程 前向计算目标网络输出 $$ Q(s'_i;\theta^-) = W^-,s'_i + b^- \begin{pmatrix} 0.5 & -0.2\ 0.1 & ;0.3 \end{pmatrix} \begin{pmatrix}1.5\-0.5\end{pmatrix} + \begin{pmatrix}0.1\-0.1\end{pmatrix} \begin{pmatrix} 0.5\cdot1.5 + (-0.2)\cdot(-0.5) + 0.1 \[4pt] 0.1\cdot1.5 + ;0.3\cdot(-0.5) - 0.1 \end{pmatrix} \begin{pmatrix} 0.75 + 0.10 + 0.1 \[3pt] 0.15 - 0.15 - 0.1 \end{pmatrix} \begin{pmatrix} 0.95 \[3pt] -0.10 \end{pmatrix}. $$ 因此, $$ Q(s'_i,a_1;\theta^-)=0.95,\quad Q(s'_i,a_2;\theta^-)= -0.10. $$ 取最大值 $$ \max_{a'}Q(s'_i,a';\theta^-) = \max{0.95,,-0.10} = 0.95. $$ 计算目标 $y_i$ $$ y_i = r_i + \gamma \times 0.95 = 2 + 0.9 \times 0.95 = 2 + 0.855 = 2.855. $$ 这样,我们就得到了 DQN 中训练主网络时的"伪标签" $y_i=2.855$,后续会用它与主网络预测值 $Q(s_i,a_i;\theta)$ 计算均方误差,进而更新 $\theta$。 改进DQN: 一、构造 n-step Transition 维护一个长度为 n 的滑动队列 每步交互(状态 → 动作 → 奖励 → 新状态)后,都向队列里添加这条"单步经验"。 当队列中积累到 n 条经验时,就可以合并成一条"n-step transition"了。 合并过程(一步一步累加) 起始状态:取队列里第 1 条记录中的状态 $s_t$ 起始动作:取第 1 条记录中的动作 $a_t$ 累积奖励:把队列中前 n 条经验的即时奖励按折扣因子 $\gamma$ 一步步加权累加: $$ G_t^{(n)} = r_t + \gamma,r_{t+1} + \gamma^2,r_{t+2} + \cdots + \gamma^{n-1}r_{t+n-1} $$ 形成一条新样本 最终你得到一条合并后的样本: $$ \bigl(s_t,;a_t,;G_t^{(n)},;s_{t+n},;\text{done}_{t+n}\bigr) $$ 然后把它存入主 Replay Buffer。 接着,把滑动队列的最早一条经验丢掉,让它向前滑一格,继续接收下一步新经验。 二、批量随机采样与训练 随机抽取 n-step 样本 训练时,不管它是来自哪一段轨迹,都从 Replay Buffer 里随机挑出一批已经合好的 n-step transition。 每条样本就封装了"从 $s_t$ 出发,执行 $a_t$,经历 n 步后所累积的奖励加 bootstrap"以及到达的末状态。 计算训练目标 对于每条抽出的 n-step 样本 $(s_t,a_t,G_t^{(n)},s_{t+n},\text{done}_{t+n})$, 如果 $\text{done}{t+n}=\text{False}$,则 $$ y = G_t^{(n)} + \gamma^n,\max{a'}Q(s_{t+n},a';\theta^-); $$ 如果 $\text{done}_{t+n}=\text{True}$,则 $$ y = G_t^{(n)}. $$ 主网络给出预测 把样本中的起始状态-动作对 $(s_t,a_t)$ 丢给在线的 Q 网络,得到当前估计的 $\hat{Q}(s_t,a_t)$。 更新网络 用"目标值 $y$"和"预测值 $\hat{Q}$"之间的平方差,构造损失函数。 对损失做梯度下降,调整在线网络参数,使得它的预测越来越贴近那条合并后的真实回报。 VDN 核心思路:将团队 Q 函数写成各智能体局部 Q 的线性和 $Q_{tot}=\sum_{i=1}^{N}\tilde{Q}_i$,在训练时用全局奖励反传梯度,在执行时各智能体独立贪婪决策。 CTDE 指 Centralized Training, Decentralized Execution —— 在训练阶段使用集中式的信息或梯度(可以看到全局状态、联合奖励、各智能体的隐藏变量等)来稳定、加速学习;而在执行阶段,每个智能体只依赖自身可获得的局部观测来独立决策。 采用 CTDE 的好处: 部署高效、可扩展:运行时每个体只需本地观测,无需昂贵通信和同步,适合大规模或通信受限场景。 降低非平稳性:每个智能体看到的“环境”里不再包含 其他正在同时更新的智能体——因为所有参数其实在同一次反向传播里被一起更新,整体策略变化保持同步;对单个智能体而言,环境动态就不会呈现出随机漂移。 避免“懒惰智能体”:只要某个行动对团队回报有正贡献,它在梯度里就能拿到正向信号,不会因为某个体率先学到高收益行为而使其他个体“无所事事”。 核心公式与训练方法 值分解假设 $$ Q\bigl((h_1,\dots,h_d),(a_1,\dots,a_d)\bigr);\approx;\sum_{i=1}^{d},\tilde{Q}_i(h_i,a_i) $$ 其中 $h_i$ 为第 $i$ 个智能体的历史观测,$a_i$ 为其动作。每个 $\tilde{Q}_i$ 只使用局部信息;训练时通过对联合 $Q$ 的 TD 误差求梯度,再"顺着求和"回传到各 $\tilde{Q}_i$ 。这样既避免了为各智能体手工设计奖励,又天然解决了联合动作空间呈指数爆炸的问题。 Q-learning 更新 $$ Q_{t+1}(s_t,a_t);=;(1-\eta_t),Q_{t}(s_t,a_t);+;\eta_t\bigl[r_t+\gamma\max_{a}Q_{t}(s_{t+1},a)\bigr] $$ 论文沿用经典 DQN 的 Q-learning 目标,对 联合 Q 值 计算 TD 误差,然后按上式更新;全局奖励 $r_t$ 会在反向传播时自动分摊到各 $\tilde{Q}_i$ 。 训练过程 使用LSTM:让智能体在「只有局部、瞬时观测」的环境中记住并利用过去若干步的信息。 1. 初始化 组件 说明 在线网络 为每个智能体 $i=1\ldots d$ 建立局部 $Q$ 网络 $\widetilde Q_i(h^i,a^i;\theta_i)$。最后一层是 值分解层:把所有 $\widetilde Q_i$ 相加得到联合 $Q=\sum_i\widetilde Q_i$ 目标网络 为每个体复制参数:$\theta_i^- \leftarrow \theta_i$,用于计算贝尔曼目标。 经验回放缓冲区 存储元组 $(h_t, \mathbf a_t, r_t, o_{t+1}) \rightarrow \mathcal D$,其中 $\mathbf a_t=(a_t^1,\dots,a_t^d)$。 超参数 Adam 学习率 $1\times10^{-4}$,折扣 $\gamma$,BPTT 截断长度 8,Eligibility trace $\lambda=0.9$ ;小批量 $B$、目标同步周期 $C$、$\varepsilon$-greedy 初始值等。 网络骨架:Linear (32) → ReLU → LSTM (32) → Dueling (Value + Advantage) 头产生 $\widetilde Q_i$ 。 2. 与环境交互并存储经验 局部隐藏状态更新(获得 $h_t^i$) 采样观测 $o_t^i \in \mathbb R^{3\times5\times5}$(RGB × 5 × 5 视野) 线性嵌入 + ReLU $x_t^i = \mathrm{ReLU}(W_o,\text{vec}(o_t^i)+b_o),; W_o!\in!\mathbb R^{32\times75}$ 递归更新 LSTM $h_t^i,c_t^i = \text{LSTM}{32}(x_t^i,;h{t-1}^i,c_{t-1}^i)$ (初始 $h_0^i,c_0^i$ 置零;执行期只用本体状态即可) 动作选择(分散执行) $$ a_t^i=\begin{cases} \text{随机动作}, & \text{概率 } \varepsilon,\ \arg\max_{a}\widetilde Q_i(h_t^i,a;\theta_i), & 1-\varepsilon. \end{cases} $$ 环境反馈:执行联合动作 $\mathbf a_t$,获得单条 团队奖励 $r_t$ 以及下一组局部观测 $o_{t+1}^i$。 重要:此处不要直接把 $h_{t+1}^i$ 写入回放池,而是存下 $(h_t^i, a_t^i, r_t, o_{t+1}^i)$。 之后在训练阶段再用同样的“Step 0” 方式,离线地把 $o_{t+1}^i\rightarrow h_{t+1}^i$。 这样可避免把梯度依赖塞进经验池。 写入回放池:$(h_t, \mathbf a_t, r_t, o_{t+1}) \rightarrow \mathcal D$。 3. 批量随机采样并联合训练 对缓冲区达到阈值后,每次更新步骤: 采样 $B$ 条长度为 $L$ 的序列。 假设抽到第 $k$ 条序列的第一个索引是 $t$。 依次取出连续的 $(h_{t+j}, a_{t+j}, r_{t+j}, o_{t+j+1}), j=0, \ldots, L-1$。 先用存储的 $o_{t+j+1}$ 离线重放"Step 0"得到 $h_{t+j+1}$,这样序列就拥有 $(h_{t+j}, h_{t+j+1})$ 前向计算 $$ \hat Q_i^{(k)} = \widetilde Q_i(h^{i,(k)}_t,a^{i,(k)}t;\theta_i), \quad \hat Q^{(k)}=\sum{i}\hat Q_i^{(k)} . $$ 贝尔曼目标(用目标网络) $$ y^{(k)} = r^{(k)} + \gamma \sum_{i}\max_{a}\widetilde Q_i(h^{i,(k)}_{t+1},a;\theta_i^-). $$ 损失 $$ L=\frac1B\sum_{k=1}^{B}\bigl(y^{(k)}-\hat Q^{(k)}\bigr)^2 . $$ 梯度反传(自动信用分配) 因为 $\hat Q=\sum_i\widetilde Q_i$,对每个 $\widetilde Q_i$ 的梯度系数恒为 1, 整个 团队 TD 误差 直接回流到各体网络,无需个体奖励设计 。 参数更新:$\theta_i \leftarrow \theta_i-\eta\nabla_{\theta_i}L$。 4. 同步 / 软更新目标网络 硬同步:每 $C$ 次梯度更新后执行 $\theta_i^- \leftarrow \theta_i$。 软更新:可选 $\theta_i^- \leftarrow \tau\theta_i+(1-\tau)\theta_i^-$。 5. 重复直到收敛 持续循环步骤 2–4,逐步衰减 $\varepsilon$。 训练完成后,每个体只需本地 $\widetilde Q_i$ 就能独立决策,与中心最大化 $\sum_i\widetilde Q_i$ 等价 。
论文
zy123
1年前
0
9
0
2025-06-07
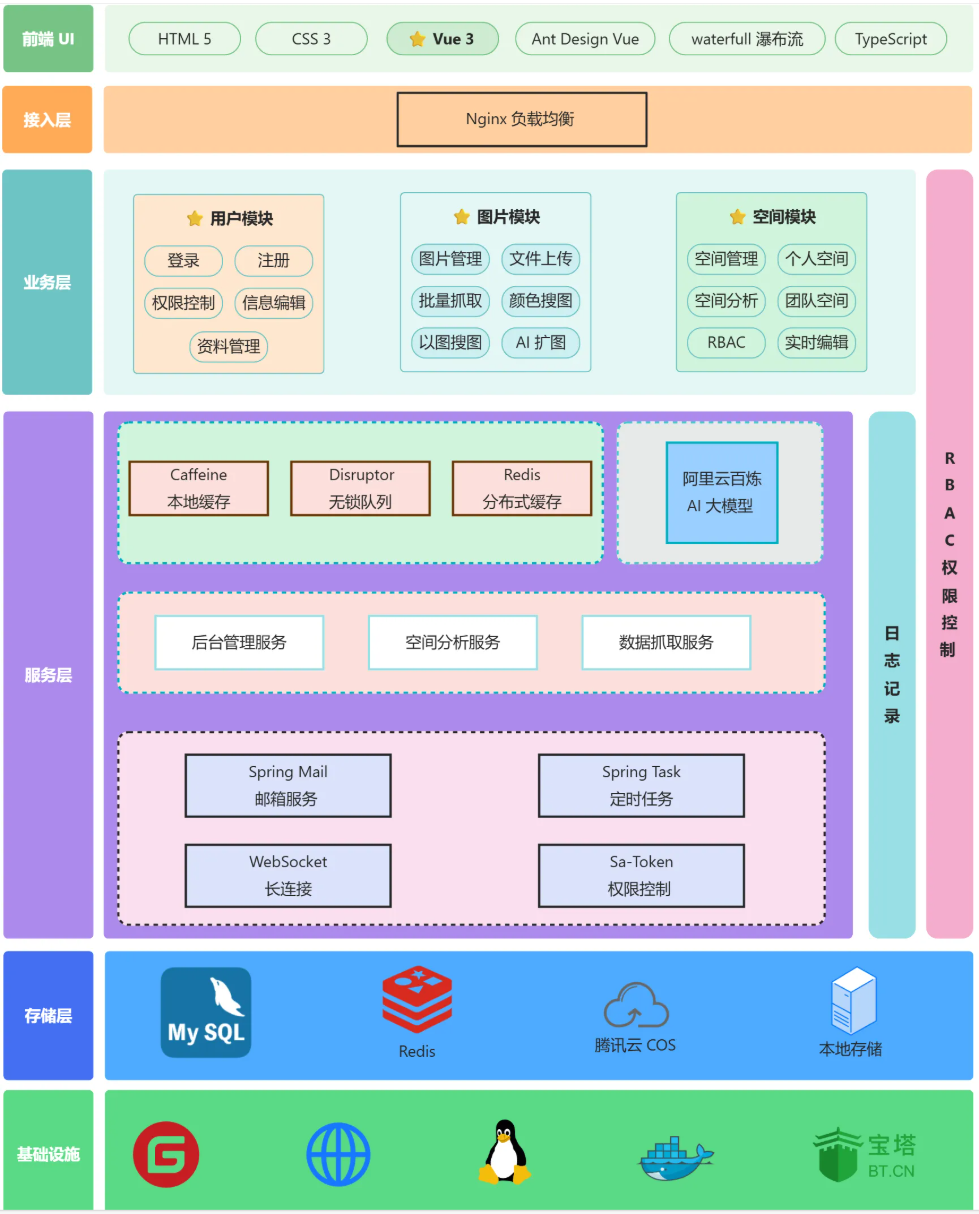
Smile云图库
Smile云图库 整体架构 注意:使用腾讯云OSS存储,12月7号资源包过期!!! 数据库表 picture 表 — 图片表 字段名 类型 说明 id bigint 主键 ID url varchar(512) 图片 URL name varchar(128) 图片名称 introduction varchar(512) 简介 category varchar(64) 分类 tags varchar(512) 标签(JSON 数组) pic_size bigint 图片体积(字节) pic_width int 图片宽度 pic_height int 图片高度 pic_scale double 宽高比例 pic_format varchar(32) 图片格式 user_id bigint 创建用户 ID create_time datetime 创建时间 edit_time datetime 编辑时间 update_time datetime 更新时间(自动更新) is_delete tinyint 是否删除(0 否 1 是) review_status int 审核状态:0 待审核 / 1 通过 / 2 拒绝 review_message varchar(512) 审核信息 reviewer_id bigint 审核人 ID review_time datetime 审核时间 thumbnail_url varchar(512) 缩略图 URL original_url varchar(512) 原图 URL space_id bigint 空间 ID(null 为公共空间) pic_color varchar(16) 图片主色调 space 表 — 空间表 字段名 类型 说明 id bigint 主键 ID space_name varchar(128) 空间名称 space_level int 空间级别:0 普通版 / 1 专业版 / 2 旗舰版 max_size bigint 空间最大可存储总大小 max_count bigint 空间最大图片数量 total_size bigint 当前空间图片总大小 total_count bigint 当前空间图片数量 user_id bigint 创建用户 ID create_time datetime 创建时间 edit_time datetime 编辑时间 update_time datetime 更新时间(自动更新) is_delete tinyint 是否删除 space_type int 空间类型:0 私有 / 1 团队 space_user 表 — 空间与用户关联表 字段名 类型 说明 id bigint 主键 ID space_id bigint 空间 ID user_id bigint 用户 ID space_role varchar(128) 空间角色:viewer / editor / admin create_time datetime 创建时间 update_time datetime 更新时间(自动更新) user 表 — 用户表 字段名 类型 说明 id bigint 主键 ID user_account varchar(256) 用户账号 user_password varchar(512) 用户密码 user_name varchar(256) 用户昵称 user_avatar varchar(1024) 用户头像 user_profile varchar(512) 用户简介 user_role varchar(256) 用户角色(user / admin) user_email varchar(256) 用户邮箱 birthday date 出生日期 user_phone varchar(50) 用户手机号 edit_time datetime 编辑时间 create_time datetime 创建时间 update_time datetime 更新时间(自动更新) is_delete tinyint 是否删除 压测 正式环境:2核4GB运存 首页查询接口: 单测延迟70ms,耗时占比:若干图片json拿缓存+JSON 反序列化+序列化返回给前端+HTTP 传输 14 KB 数据+浏览器 解析 JSON 1秒内1000次请求压测: 为什么压测下这么慢?排查过本地缓存都是命中的。可能是: Caffeine 命中后 → 依旧要 mapper.readValue 做 JSON parse; JSON 体量 ~14 KB,CPU 在高并发下被打爆; Tomcat 线程池也被压满,导致排队。 待完善功能 缓存相关 1. 手动刷新缓存 在某些情况下,数据更新较为频繁,但自动刷新缓存的机制可能存在延迟,这时可以通过手动刷新来解决。例如: 提供一个刷新缓存的接口,仅供管理员调用。 在管理后台提供入口,允许管理员手动刷新指定缓存。 2.热点Key问题 定义:在 Redis 中,某个 key 的访问量远高于其他 key,导致 大量请求集中到同一个 key。 后果: Redis 单线程处理这个 key 的请求,容易形成性能瓶颈。 如果 key 过期或被删除,大量并发请求会直接穿透数据库(缓存击穿)。 目前图片详情页没有缓存,如果少数图片非常热门(比如被放在推荐位或首页大 banner),用户频繁点进去看详情,每次都查数据库,就可能导致 单 key 高并发,数据库被压垮。后续可以用热key 探测技术,实时对图片的访问量进行统计,并自动将热点图片添加到内存缓存。 系统安全 限流、黑名单,降级返回逻辑都未完善,而系统中存在爬虫搜图、AI扩图功能,需要补充这块逻辑。 上传图片体验优化 1.目前仅有公共图库支持管理员批量搜图并上传,私人空间和团队空间都只能一张张上传,或许可以前端优化一下显示,支持批量上传,然后有一个类似扑克卡片那张叠加,每次顶上显示一个图片以及它的基本信息,确认无误点击确认可处理下一张。 2.目前只有管理员界面显示所有图片的管理;用户这边可以记录一个自己上传的图片列表,记录自己什么时候上传了什么图片,是否正在审核中... 图片展示优化 可以使用CDN内容分发网络、浏览器缓存提高图片的加载速度。 协同编辑 1、为防止消息丢失,可以使用 Redis 等高性能存储保存执行的操作记录。目前如果图片已经被编辑了,新用户加入编辑时没办法查看到已编辑的状态,这一点也可以利用 Redis 保存操作记录来解决,新用户加入编辑时读取 Redis 的操作记录即可。 2、支持分布式 WebSocket。只需要保证要编辑同一图片的用户连接的是相同的服务器即可,和游戏分服务器大区、聊天室分房间是类似的原理。(目前单机部署,暂不考虑) 3.目前多人协同编辑,只支持一个人编辑,其他人实时看到最新编辑状态,而且防并发限制只做了前端,即第一个人进入编辑,其他人按钮变灰,这样是不安全的。后端应该使用redis分布式锁。 锁 Key:pic:edit:{pictureId} 锁 Value:{userId}:{uuid}(既能辨认持有者,又能避免误删别人的锁) 加锁:SET key value NX PX <ttl>(拿到返回 OK,拿不到返回 null) 续期:持锁线程每 ttl/3 定时 PEXPIRE key <ttl>(或 SET key value XX PX <ttl> 确保续租) 释放:Lua 脚本「value 匹配才 DEL」,防止误删他人的锁 重入:如果同一用户再次进入,允许他复用自己手上的锁(校验 value 的 userId 部分) 超时兜底:没续期/断线,锁会因 TTL 过期被动释放 踩坑 精度损失和日期格式转换问题 前端 → 后端 日期 前端把日期格式化成后端期待的纯日期字符串,例如 "2025-08-14",后端 DTO 用 LocalDate 接收(配合 @JsonFormat(pattern="yyyy-MM-dd")),Jackson 反序列化成 LocalDate。 精度: JavaScript 的 number 类型只能安全地表示到 2^53−1(约 9×10^15)的整数,超过这个范围就会丢失精度,用 number 传给后端时末尾只能补0; 解决办法:前端 ID 当做字符串传给后端。 Spring MVC 会自动调用 Long.parseLong("1951619197178556418") 并赋值给你方法签名里的 long id(即还是写作long来接收,不变) 后端 → 前端 日期: 后端用 LocalDate / LocalDateTime 之类的 Java 8 类型,经过 Jackson 序列化为指定格式的字符串(比如 "yyyy-MM-dd" / "yyyy-MM-dd HH:mm:ss")供前端消费,避免时间戳或默认格式的不一致。 精度: Java 的 long 可能超过 JavaScript number 的安全范围(2^53−1),直接以数字输出会丢失精度。必须把 long/Long 序列化成字符串(例如 ID 输出为 "1951648800160399362"),前端拿到字符串再展示。 对 Jackson 用作 Spring 的 HTTP 消息转换器的 ObjectMapper 进行配置(日期格式、Java 8 时间支持、Long 转字符串等)示例代码: @Configuration public class JacksonConfig { private static final String DATE_FORMAT = "yyyy-MM-dd"; private static final String DATETIME_FORMAT = "yyyy-MM-dd HH:mm:ss"; private static final String TIME_FORMAT = "HH:mm:ss"; @Bean public Jackson2ObjectMapperBuilderCustomizer jacksonCustomizer() { return builder -> { builder.featuresToDisable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES); builder.simpleDateFormat(DATETIME_FORMAT); builder.featuresToDisable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS); JavaTimeModule javaTime = new JavaTimeModule(); javaTime.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT))); javaTime.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DATE_FORMAT))); javaTime.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(TIME_FORMAT))); javaTime.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT))); javaTime.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DATE_FORMAT))); javaTime.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(TIME_FORMAT))); SimpleModule longToString = new SimpleModule(); longToString.addSerializer(Long.class, ToStringSerializer.instance); longToString.addSerializer(Long.TYPE, ToStringSerializer.instance); builder.modules(javaTime, longToString); }; } } 序列化操作是通过 Jackson 的 ObjectMapper 完成的,它并不依赖于 Serializable 接口。Serializable 接口更多的是用于对象的 Java 原生序列化,例如将对象写入文件或通过网络传输时的序列化,而 Jackson 处理的是 Java 对象和 JSON 之间的序列化与反序列化。 Websocket连接问题 前端请求地址: const protocol = location.protocol === 'https:' ? 'wss' : 'ws' // 线上地址 const host = location.host; const url = `${protocol}://${host}/api/ws/picture/edit?pictureId=${this.pictureId}` this.socket = new WebSocket(url) nginx配置: # ---------- WebSocket 代理 ---------- location /api/ws/ { proxy_pass http://picture_backend; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_buffering off; proxy_read_timeout 86400s; } 坑点在这:由于本项目采用NPM做域名管理,124.71.159.xxx:18096 ->https://picture.bitday.top/ 要把这里的Websockets Supports勾上,不然无法建立连接!排查了很久! 数据库密码加密 加密存储确保即使数据库泄露,攻击者也不能轻易获取用户原始密码。 spring security 中提供了一个加密类BCryptPasswordEncoder。 它采用哈希算法 SHA-256 +随机盐+密钥对密码进行加密。加密算法是一种可逆的算法,而哈希算法是一种不可逆的算法。 因为有随机盐的存在,所以相同的明文密码经过加密后的密码是不一样的,盐在加密的密码中是有记录的,所以需要对比的时候,springSecurity是可以从中获取到盐的 验证密码 matches // 使用 matches 方法来对比明文密码和存储的哈希密码 boolean judge= passwordEncoder.matches(rawPassword, user.getPassword()); 注意,matches的第一个参数必须 是 “原始明文”,第二个参数 必须 是 “已经加密过的密文”!!!顺序不能反!!! 循环依赖问题 PictureController ↓ 注入 PictureServiceImpl PictureServiceImpl ↓ 注入 SpaceServiceImpl SpaceServiceImpl ↓ 注入 SpaceUserServiceImpl SpaceUserServiceImpl ↓ 注入 SpaceServiceImpl ←—— 又回到 SpaceServiceImpl 解决办法:将一方改成 setter 注入并加上 @Lazy注解 如在SpaceUserServiceImpl中 @Resource @Lazy // 必须使用 Spring 的 @Lazy,而非 Groovy 的! private SpaceService spaceService; @Lazy为懒加载,直到真正第一次使用它时才去创建或注入。且这里不能用构造器注入的方式!!! ❌ 构造器注入会立即触发依赖加载,无法解决循环依赖 Redis RDB问题 Caused by: io.lettuce.core.RedisCommandExecutionException: MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error. Redis 默认是支持持久化的(RDB / AOF),其中 RDB 快照是通过后台 bgsave 子进程定期把内存数据写到磁盘。 配置文件里有一条关键参数: stop-writes-on-bgsave-error yes # 默认值 yes:如果 bgsave 持久化失败(写 RDB 文件失败),Redis 会立刻禁止所有写操作(set/del/incr 等)。避免出现数据还在内存里、但落盘失败,用户却误以为写成功了的情况。 如何解决:进入redis的命令行 config set stop-writes-on-bgsave-error no 收获 MybatisX插件简化开发 下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下: 注意,勾选 Actual Column 生成的Bean和表中字段一模一样,取消勾选会进行驼峰转换,即 user_name—>userName 下载GenerateSerailVersionUID插件,可以右键->generate->生成序列ID: private static final long serialVersionUID = -1321880859645675653L; 胡图工具类hutool 引入依赖 <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.26</version> </dependency> ObjUtil.isNotNull(Object obj),仅判断对象是否 不为 null,不关心对象内容是否为空,比如空字符串 ""、空集合 []、数字 0 等都算是“非 null”。 ObjUtil.isNotEmpty(Object obj) 判断对象是否 不为 null 且非“空” 对不同类型的对象判断逻辑不同: CharSequence(String):长度大于 0 Collection:size > 0 Map:非空 Array:长度 > 0 其它对象:只判断是否为 null(默认不认为“空”) StrUtil.isNotEmpty(String str) 只要不是 null 且长度大于 0 就算“非空”。 StrUtil.isNotBlank(String str) 不仅要非 null,还要不能只包含空格、换行、Tab 等空白字符 StrUtil.hasBlank(CharSequence... strs)只要 **至少一个字符串是 blank(空或纯空格)**就返回 true,底层其实就是对每个参数调用 StrUtil.isBlank(...) CollUtil.isNotEmpty(Collection<?> coll)用于判断 集合(Collection)是否非空,功能类似于 ObjUtil.isNotEmpty(...) BeanUtil.toBean :用来把一个 Map、JSONObject 或者另一个对象快速转换成你的目标 JavaBean public class BeanUtilExample { public static class User { private String name; private Integer age; // 省略 getter/setter } public static void main(String[] args) { // 1. 从 Map 转 Bean Map<String, Object> data = new HashMap<>(); data.put("name", "Alice"); data.put("age", 30); User user1 = BeanUtil.toBean(data, User.class); System.out.println(user1.getName()); // Alice // 2. 从另一个对象转 Bean class Temp { public String name = "Bob"; public int age = 25; } Temp temp = new Temp(); User user2 = BeanUtil.toBean(temp, User.class); System.out.println(user2.getAge()); // 25 } } 创建图片的业务流程 方式 1:先上传文件,再提交表单数据 流程: 用户先把图片上传到云存储,系统生成一个 url。 系统不急着写数据库,只是记住这个 url。 用户继续在前端填写图片的标题、描述、标签等信息。 用户点击“提交”后,才把 url + 其它信息 一起存进数据库,生成一条完整记录。 优点: 数据库里不会出现“用户传了文件,但没填写信息”的垃圾数据。 缺点: 如果用户传了文件但中途关掉页面,文件虽然已经占了存储空间,但数据库里没有记录,这个文件可能变成“孤儿文件”,需要后台定期清理。 方式 2:上传文件时就立即建数据库记录 流程: 用户一旦上传成功,后端立即在数据库里生成完整的图片记录(包含能直接解析出来的元信息,如宽高、大小、格式、URL、上传者等)。 后续用户只是在编辑已有的图片记录(补充标题、描述、标签等),而不是新建。 优点: 数据库里能实时反映出当前所有文件的存在状态,方便管理。 即使用户中途不编辑,也能有一条图片记录存在。 缺点: 可能会有很多“不完整”的记录(缺少标题等),需要做清理或状态标记。 可能侵害用户隐私 **针对方式1,**可能存在孤儿文件的问题,解决办法: 上传阶段(放临时区) 用户选图 → 前端调用后端接口拿一个临时上传地址(key 类似 /temp/{userId}/{uuid}.png)。 前端直接把文件上传到 COS 的 temp 文件夹。 这时只是文件存在 COS,数据库里还没有正式的图片记录。 提交阶段(转正) 用户在网页里填写标题、描述等信息后点击提交。 后端接收到提交请求后: 在数据库里创建图片记录(生成 pictureId 等信息) 把 COS 中的文件从 /temp/... 复制(Copy)到正式目录 /prod/{spaceId}/{pictureId}.png 删除 /temp/... 的原文件(节省空间) 把正式文件 URL 保存到数据库中 针对方式2: 新上传的图片记录默认设置为 status = DRAFT,表示草稿状态,仅对上传者可见。 当用户确认并提交(实际是编辑补充信息后)时,将该记录的状态更新为 PUBLISHED,即正式发布。 如果用户在上传后未点击提交而是选择取消,则应立即删除该记录,并同时从 COS 中移除对应的文件。 另外,后端应配置定时任务,定期清理超过 N 小时/天仍处于 DRAFT 状态的记录,并同步删除 COS 上的文件,以避免无效数据和存储浪费。 本项目采取的是方式2!!! 登录校验 BCrypt加密 使用 BCrypt 这类强哈希算法,它不仅仅是简单的 MD5 或 SHA 加密,还融合了盐值(Salt) 和成本因子(Work Factor)。 盐值(Salt): 每个用户的密码在加密前都会叠加一个随机生成的、唯一的字符串(盐)。这意味着即使两个用户的密码相同,它们在数据库里存储的哈希值也完全不同。这有效防御了彩虹表攻击。 成本因子(Work Factor): 它控制着哈希计算的复杂度(迭代次数)。可以动态调整(例如从 10 增加到 12),使得即使未来算力增长,暴力破解的成本依然高昂到不可接受。 比较过程:将用户输入的密码进行哈希计算后与数据库存储的值比对。我们自始至终都只处理哈希值,而不接触或存储用户的明文密码。 // 校验密码 if (!passwordEncoder.matches(userPassword, user.getUserPassword())) { throw new BusinessException(ErrorCode.PARAMS_ERROR, "用户不存在或者密码错误"); } Session登录校验 1.基本原理 服务端:存储会话数据(内存、Redis 等)。 客户端:仅保存会话 ID(如 JSESSIONID),通常通过 Cookie 传递。 2.数据结构 服务端会话存储(Map 或 Redis) { "abc123" -> HttpSession 实例 } HttpSession 结构: HttpSession ├─ id = "abc123" ├─ creationTime = ... ├─ lastAccessedTime = ... └─ attributes └─ "USER_LOGIN_STATE" -> user 实体对象 3.请求流程 首次请求 浏览器没有 JSESSIONID,服务端调用 createSession() 创建一个新会话(ID 通常是 UUID)。 服务端返回响应头 Set-Cookie: JSESSIONID=<新ID>; Max-Age=2592000(30 天有效期)。 浏览器将 JSESSIONID 写入本地 Cookie(持久化保存)。 后续请求 浏览器自动在请求头中附带 Cookie: JSESSIONID=<ID>。 服务端用该 ID 在会话存储中查找对应的 HttpSession 实例,恢复用户状态。 ┌───────────────┐ (带 Cookie JSESSIONID=abc123) │ Browser │ ───────►│ Tomcat │ └───────────────┘ └──────────┘ │ │ 用 abc123 做 key ▼ {abc123 → HttpSession} ← 找到 │ ▼ 取 attributes["USER_LOGIN_STATE"] → 得到 userrequest.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user); 4.后端使用示例 保存登录状态: request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user); request.getSession() 会自动获取当前请求关联的 HttpSession 实例。 获取登录状态: User user = (User) request.getSession().getAttribute(UserConstant.USER_LOGIN_STATE); 退出登录: request.getSession().removeAttribute(UserConstant.USER_LOGIN_STATE); 相当于清空当前会话中的用户信息。浏览器本地的 JSESSIONID 依然存在,只不过后端啥也没了。 优点 会话数据保存在服务端,相比直接将数据存储在客户端更安全(防篡改)。 缺点 分布式集群下 Session 无法自动共享(需借助 Redis 等集中存储)。 客户端禁用 Cookie 时,Session 会失效。 服务端需要维护会话数据,高并发环境下可能带来内存或性能压力。 Redis+Session 前面每次重启服务器都要重新登陆,既然已经整合了 Redis,不妨使用 Redis 管理 Session,更好地维护登录态,且能多实例(集群)共享。 1)先在 Maven 中引入 spring-session-data-redis 库: <!-- Spring Session + Redis --> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency> 2)修改 application.yml 配置文件,更改Session的存储方式和过期时间: 既要设置redis能存30天,发给前端的cookie也要30天有效期。 spring: session: store-type: redis timeout: 30d # 会话不活动超时(maxInactiveInterval) redis: host: 127.0.0.1 port: 6379 server: servlet: session: cookie: max-age: 30d # 发给前端 Cookie 的保存时长 # name: JSESSIONID # 如想保持原名,见下文“Cookie 名称” 存储结构展示: 面试官:Spring Session 中存储的是什么数据? 答:存储的核心数据是用户的登录状态对象。具体来说,就是我代码中 request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user)存入的整个 user实体对象。 从技术实现上看,Spring Session 在 Redis 中存储的是一个标准的 Hash 数据结构。这个 Hash 的 Key 是由 Spring Session 自动生成的一个唯一 Session ID(格式类似于 sessionid:abc123),而 Hash 的各个 Field 则对应着 HttpSession 中的各个 Attribute(如上图的sessionAttr:user_login)。 如果有多个Attribute,那也会有多个filed!!!这里的lastAccessedTime、maxInactiveInterval、creationTime都是固定有的field!!! 面试官:存储用户信息的过程中通常会涉及序列化和反序列化的操作,这有什么作用? 序列化是将内存中的对象转换为一种可以存储或传输的格式(通常是字节流或字符串),而反序列化则是其逆过程,将这种格式重新构建为内存中的对象。 1.为了传输和存储:内存中的对象无法直接存数据库或网络传输,序列化把它变成通用格式(如JSON字符串/二进制流)。 2.为了跨语言和平台:序列化后的数据(如JSON)任何语言都能识别,实现了Java服务、Go服务、前端都能理解同一份数据。 3.为了重建状态:在分布式系统中,反序列化能把存储的数据(如Redis里的字符串)重新变回内存里的对象,恢复用户会话状态(如登录信息)。 普通用户与管理员权限控制 使用AOP切面! 1)定义注解 @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface AuthCheck { /** * 必须具有某个角色 **/ String mustRole() default ""; } 2)写切片类 @Aspect @Component @RequiredArgsConstructor public class AuthInterceptor { private final UserService userService; /** * 执行拦截 * * @param joinPoint 切入点 * @param authCheck 权限校验注解 */ @Around("@annotation(authCheck)") public Object doInterceptor(ProceedingJoinPoint joinPoint, AuthCheck authCheck) throws Throwable { String mustRole = authCheck.mustRole(); RequestAttributes requestAttributes = RequestContextHolder.currentRequestAttributes(); HttpServletRequest request = ((ServletRequestAttributes) requestAttributes).getRequest(); // 获取当前登录用户 User loginUser = userService.getLoginUser(request); UserRoleEnum mustRoleEnum = UserRoleEnum.getEnumByValue(mustRole); // 如果不需要权限,放行 if (mustRoleEnum == null) { return joinPoint.proceed(); } // 以下的代码:必须有权限,才会通过 UserRoleEnum userRoleEnum = UserRoleEnum.getEnumByValue(loginUser.getUserRole()); if (userRoleEnum == null) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR); } // 要求必须有管理员权限,但用户没有管理员权限,拒绝 if (UserRoleEnum.ADMIN.equals(mustRoleEnum) && !UserRoleEnum.ADMIN.equals(userRoleEnum)) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR); } // 通过权限校验,放行 return joinPoint.proceed(); } } 3)使用 /** * 分页获取图片列表(仅管理员可用) */ @PostMapping("/list/page") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Page<Picture>> listPictureByPage(@RequestBody PictureQueryRequest pictureQueryRequest) { long current = pictureQueryRequest.getCurrent(); long size = pictureQueryRequest.getPageSize(); // 查询数据库 Page<Picture> picturePage = pictureService.page(new Page<>(current, size), pictureService.getQueryWrapper(pictureQueryRequest)); return ResultUtils.success(picturePage); } 上传图片(模板方法模式) 本模块采用 模板方法设计模式: 在 抽象类 PictureUploadTemplate 中定义了上传图片的 固定流程(算法骨架)。 将具体步骤(如校验、获取文件名、处理输入源)延迟到 子类实现,以支持不同的上传方式。 目前支持两种上传方式: 本地文件上传(FilePictureUpload) 网络 URL 上传(UrlPictureUpload) 抽象类:PictureUploadTemplate 核心方法:uploadPicture() 定义了上传图片的完整流程,固定步骤如下: 校验图片 → validPicture(inputSource) 检查文件大小、格式是否合法。 生成上传路径与文件名 → getOriginFilename(inputSource) 提取原始文件名并拼接安全的上传路径。 创建临时文件 → processFile(inputSource, tempFile) 将输入源(文件或 URL)转化为本地临时文件。 上传到对象存储(COS) 通过 CosManager 将文件推送至存储桶。 封装返回结果 包含压缩图、缩略图、原图地址以及宽高、大小、格式等信息。 清理临时文件 → deleteTempFile(file) 删除服务器上的临时文件,避免资源泄露。 子类职责 FilePictureUpload 实现文件上传场景 校验文件大小 ≤ 2MB,后缀是否在白名单(jpg/png/webp 等) 使用 MultipartFile.transferTo() 写入临时文件 UrlPictureUpload 实现 URL 上传场景 校验 URL 格式、协议(http/https) 通过 HEAD 请求检查 Content-Type、Content-Length 使用 HttpUtil.downloadFile() 将远程文件保存为临时文件 模板方法模式保证了上传流程的一致性和扩展性。 不同来源的图片上传(文件 / URL)只需实现差异化的步骤,而无需改动整体流程。 图片压缩优化 对象存储 图片持久化处理_腾讯云 项目中存储了三种图片url: 1.原图,仅供下载的时候提供 2.使用腾讯云的数据万象将原图转为Webp格式,作为一般的网页内图片的展示图 3.使用腾讯云的数据万象将原图转为缩略图格式,作为网页中小图的展示(点开图片前) 以图搜图 法一:使用百度 AI 提供的图片搜索 API 或者 Bing以图搜图API 法二:爬虫 以百度搜图网站为例,先体验一遍流程,并且对接口进行分析: 1)进到百度图片搜索百度识图搜索结果,通过 url 上传图片,发现接口:https://graph.baidu.com/upload?uptime= ,该接口的返回值为 “以图搜图的页面地址” 2)访问上一步得到的页面地址,可以在返回值中找到 firstUrl: 3)访问 firstUrl,就能得到 JSON 格式的相似图片列表,里面包含了图片的缩略图和原图地址: 本项目采用法二。 外观模式 目的:简化系统的复杂性,提供一个统一的接口,隐藏系统内部的细节。 实现方式:创建了一个 ImageSearchApiFacade 类,它对外提供了 searchImage 方法,通过这个方法,外部调用者不需要关心图片搜索的具体步骤(如获取页面 URL、获取图片列表等),只需要调用这个简洁的接口即可。 searchImage(String localImagePath):外部调用者通过该方法传入图片路径,ImageSearchApiFacade 会依次调用子系统中的方法获取图片列表,并返回结果。 子系统:GetImagePageUrlApi、GetImageFirstUrlApi、GetImageListApi 等是实现细节,分别负责不同的任务: getImagePageUrl(String localImagePath):该方法向百度的「以图搜图」API 发起上传请求,并获取返回的结果页面 URL。 getImageFirstUrl(String imagePageUrl):根据传入的页面 URL,该方法会请求页面并解析其 HTML 内容,从中找到 firstUrl,即第一张图片的 URL。 getImageList(String imageFirstUrl):该方法使用传入的第一张图片 URL,发起请求到获取图片列表的 API,处理返回的 JSON 数据,提取出图片列表,并将其转换为 ImageSearchResult 对象。 @Slf4j public class ImageSearchApiFacade { /** * 搜索图片 */ public static List<ImageSearchResult> searchImage(String localImagePath) { String imagePageUrl = GetImagePageUrlApi.getImagePageUrl(localImagePath); String imageFirstUrl = GetImageFirstUrlApi.getImageFirstUrl(imagePageUrl); List<ImageSearchResult> imageList = GetImageListApi.getImageList(imageFirstUrl); return imageList; } } 图片功能扩展 按颜色搜图 为了提高性能并避免每次搜索时都进行实时计算,我们建议在图片上传成功后,立即提取图片的主色调并将其存储在数据库中的独立字段中。 完整流程如下: 提取图片颜色: 通过图像处理技术(如云服务 API 或 OpenCV 图像处理库),我们可以提取图片的颜色特征。我们采用主色调作为图片颜色的代表,简单明了,便于后续处理。此处,使用腾讯云提供的 数据万象接口 来获取每张图片的主色调:数据万象 获取图片主色调_腾讯云。 存储颜色特征: 提取到的颜色特征会被存储在数据库中,以便后续快速检索。通过这种方式,我们可以避免每次查询时重新计算图片的颜色特征,提高系统的响应速度。 用户查询输入: 用户可以通过不同的方式来指定颜色查询条件: 颜色选择器:用户可以通过直观的界面选择颜色。 RGB 值输入:用户可以直接输入颜色的 RGB 值。 预定义颜色名称:用户也可以选择常见的颜色名称(如红色、蓝色等)。 计算相似度: 在收到用户的查询条件后,系统会根据用户指定的颜色与数据库中存储的颜色特征进行相似度计算。常用的相似度计算方法包括 欧氏距离、余弦相似度 等,目的是找出与用户要求颜色最接近的图片。 返回结果: 由于每个空间内的图片数量相对较少,我们可以通过计算图片与目标颜色的相似度,对图片进行排序,优先返回最符合用户要求的图片。这种方法不仅提高了用户的搜索体验,也避免了仅返回完全符合指定色调的图片,拓宽了搜索结果的范围。 AI扩图 使用大模型服务平台百炼控制台提供的扩图功能。 异步任务 + 轮询查询模式 当调用的接口处理逻辑较为耗时(如 AI 图像生成、文档转换等),服务端通常不会立即返回最终结果。 为了避免 HTTP 请求长时间占用连接,接口会设计成先提交任务,再异步获取结果。 思想流程 发起任务 调用 create 类型接口,传入任务参数(图片url、调用的model、可选参数控制生成的图片细节)。 返回 taskId(任务唯一标识)以及任务的初始状态(如 pending、processing)。 延迟查询 等待一段时间(几秒或按服务端建议的间隔)。 使用 taskId 调用 get 类型接口查询状态。 轮询直到完成 如果状态为 processing 或 pending,继续间隔查询。 如果状态为 success 或 failed,结束轮询并处理结果。 轮询一般会在前端(或调用方)用定时器来触发,如每隔X秒查一次。 私有空间创建 在业务中,每个用户只能创建一个私人空间,但还允许创建团队空间,所以不能直接在 space 表的 userId 上加唯一索引来限制。需要加锁确保在并发情况下同一用户的创建操作安全且互不干扰。 private static final ConcurrentHashMap<Long, Object> USER_LOCKS = new ConcurrentHashMap<>(); Object lock = USER_LOCKS.computeIfAbsent(userId, id -> new Object()); synchronized (lock) { try { // 执行事务内的空间创建逻辑 } finally { USER_LOCKS.remove(userId, lock); } } 来请求 → 创建/获取锁 → 进入 synchronized → 干活 干完活 → 释放锁(删除掉锁对象) 锁的目的是防止并发创建,锁里面会查数据库防止用户创多个私人空间。 为什么用 ConcurrentHashMap<Long,Object> 管理锁更优? 1. 避免污染常量池 synchronized (userId.toString().intern()) { // 以 userId 为维度的锁 } 如果用 String.intern() 作为锁对象,会将不同的 userId 字符串放入 JVM 字符串常量池。(有则取,无则创建并放入常量池) 随着用户量(userid)增长,常量池(位于元空间/永久代)会不断膨胀,带来 内存压力 和 垃圾回收开销。 ConcurrentHashMap 存储的锁对象是普通堆对象,可控且可回收,不会污染常量池。 2. 锁生命周期可控 ConcurrentHashMap可以显式增删: computeIfAbsent:仅当不存在锁对象时才创建。 remove(userId, lock):业务完成后立即移除,防止内存占用过大。 而 intern() 生成的字符串常驻常量池,生命周期由 JVM 管理,无法手动清理,存在内存泄漏风险。 3.支持高并发下的高性能 ConcurrentHashMap 在 JDK8 及以上采用CAS + 分段锁(或节点锁,多线程 computeIfAbsent 性能优于 HashMap + 全局 synchronized。 computeIfAbsent 是 ConcurrentHashMap提供的一个原子性操作方法,用于实现“如果键不存在则计算并存入,否则直接返回现有值”的线程安全逻辑。 Object lock = USER_LOCKS.computeIfAbsent(userId, id -> new Object()); 单机:用 ConcurrentHashMap + synchronized 就足够。 多机 / 集群:必须用分布式锁(如 Redisson),否则不同节点之间的请求无法感知彼此的锁。 为什么这里用编程式事务而不是 @Transactional 问题背景 声明式事务(@Transactional)是由 Spring AOP 代理在方法进入前就开启事务,在方法返回后才提交。 如果锁(synchronized)在方法内部,事务会比锁早开启、晚提交。 并发风险 线程 A 进入方法 → 事务已开启 进入 synchronized,执行 exists → save,退出锁 事务还没提交(提交在方法返回时) 线程 B 等 A 释放锁后进入 → 此时 A 的事务未提交 B 查询 exists 看不到 A 的未提交数据(READ_COMMITTED 下) 误以为不存在 → 也执行 save 最终可能产生重复记录或唯一索引冲突。 编程式事务的好处 事务开启和提交的时机完全可控,可以放在 synchronized 内部。 保证加锁期间事务已提交或回滚,避免并发读取“看不到未提交数据”的问题。 private static final ConcurrentHashMap<Long, Object> USER_LOCKS = new ConcurrentHashMap<>(); @Autowired private TransactionTemplate transactionTemplate; public void createResource(Long userId) { // 每个用户一把锁 Object lock = USER_LOCKS.computeIfAbsent(userId, id -> new Object()); synchronized (lock) { try { // 在锁内开启事务,确保事务提交时才释放锁 transactionTemplate.execute(status -> { // 模拟:先检查是否存在 boolean exists = checkExists(userId); if (exists) { throw new RuntimeException("已存在记录,不能重复创建"); } // 模拟:执行保存 saveResource(userId); return null; }); } finally { USER_LOCKS.remove(userId, lock); } } } // 以下是伪代码方法 private boolean checkExists(Long userId) { return false; // 假设不存在 } private void saveResource(Long userId) { System.out.println("为用户 " + userId + " 创建资源成功"); } 分库分表 如果某团队空间的图片数量比较多,可以对其数据进行单独的管理。 1、图片信息数据 可以给每个团队空间单独创建一张图片表 picture_{spaceId},也就是分库分表中的分表,而不是和公共图库、私有空间的图片混在一起。这样不仅查询空间内的图片效率更高,还便于整体管理和清理空间。但是要注意,仅对旗舰版空间生效,否则分表的数量会特别多,反而可能影响性能。 要实现的是会随着新增空间不断增加分表数量的动态分表,使用分库分表框架 Apache ShardingSphere 。 2、图片文件数据 已经实现隔离,存到COS上的不同桶内。 思路主要是基于业务需求设计数据分片规则,将数据按一定策略(如取模、哈希、范围或时间)分散存储到多个库或表中,同时开发路由逻辑来决定查询或写入操作的目标库表。 特点 水平分表 垂直分表 拆分方式 按行拆(同样结构,不同数据) 按列拆(不同字段) 解决问题 数据量太大 字段太多 / 热点与冷数据分离 表结构 相同 不同 典型场景 用户表、订单表(数据行数多) 用户信息(基本信息 + 扩展信息) 难点 跨表查询、分布式事务 多表 join、一致性维护 ShardingSphere 分库分表 <!-- 分库分表 --> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId> <version>5.2.0</version> </dependency> 水平分表在 ShardingSphere 里的两种实现:静态分表和动态分表 静态分表 静态分表:在设计阶段,分表的数量和规则就是固定的,不会根据业务增长动态调整,比如 picture_0、picture_1。 分片规则通常基于某一字段(如图片 id)通过简单规则(如取模、范围)来决定数据存储在哪个表或库中。 这种方式的优点是简单、好理解;缺点是不利于扩展,随着数据量增长,可能需要手动调整分表数量并迁移数据。 举个例子,图片表按图片 id 对 3 取模拆分: String tableName = "picture_" + (picture_id % 3) // picture_0 ~ picture_2 静态分表的实现很简单,直接在 application.yml 中编写 ShardingSphere 的配置就能完成分库分表,比如: rules: sharding: tables: picture: # 逻辑表名 actualDataNodes: ds0.picture_${0..2} # 3张物理表:picture_0, picture_1, picture_2 tableStrategy: standard: shardingColumn: picture_id # 按 pictureId 分片 shardingAlgorithmName: pictureIdMod shardingAlgorithms: pictureIdMod: type: INLINE #内置实现,直接在配置类中写规则,即下面的algorithm-expression props: algorithm-expression: picture_${pictureId % 3} # 分片表达式 查询逻辑表 picture 时,ShardingSphere 会根据分片规则自动路由到 picture_0 ~ picture_2。 动态分表 动态分表是指:分表的数量和规则不是预先固定的,而是可以在运行时根据业务需求或数据量动态生成。 例如:按月份动态建表 picture_2025_03、picture_2025_04,或在新建旗舰空间时生成 picture_30001。 String tableName = "picture_" + LocalDate.now().format( DateTimeFormatter.ofPattern("yyyy_MM") ); 配置示例: spring: shardingsphere: datasource: names: smile-picture smile-picture: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/smile-picture username: root password: 123456 rules: sharding: tables: picture: #逻辑表名(业务层永远只写 picture) actual-data-nodes: smile-picture.picture # 逻辑表对应的真实节点 table-strategy: standard: sharding-column: space_id #分片列(字段) sharding-algorithm-name: picture_sharding_algorithm # 使用自定义分片算法 sharding-algorithms: picture_sharding_algorithm: type: CLASS_BASED props: strategy: standard algorithmClassName: edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm props: sql-show: true 自定义分片算法 edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm 全类名。 public class PictureShardingAlgorithm implements StandardShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> preciseShardingValue) { Long spaceId = preciseShardingValue.getValue(); String logicTableName = preciseShardingValue.getLogicTableName(); // spaceId 为 null 表示查询所有图片 if (spaceId == null) { return logicTableName; } // 根据 spaceId 动态生成分表名 String realTableName = "picture_" + spaceId; if (availableTargetNames.contains(realTableName)) { return realTableName; } else { return logicTableName; } } @Override public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) { return new ArrayList<>(); } @Override public Properties getProps() { return null; } @Override public void init(Properties properties) } 关键对应关系 1)逻辑表名: 配置:tables.picture 代码:preciseShardingValue.getLogicTableName() 👉 必须一致,否则 SQL 写的 picture 无法触发分片。 2)分片键 配置:sharding-column: space_id 代码:preciseShardingValue.getValue() 👉 对应 SQL 中 WHERE space_id = xxx 的值。 3)分片算法名 sharding-algorithm-name: picture_sharding_algorithm 和下面算法定义对应: sharding-algorithms: picture_sharding_algorithm: # 算法名字 type: CLASS_BASED props: strategy: standard algorithmClassName: edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm 代码: public class PictureShardingAlgorithm implements StandardShardingAlgorithm<Long> { ... } picture_sharding_algorithm 这个名字要和上面 sharding-algorithm-name 一致。 algorithmClassName 要填完整的 包路径 + 类名,否则 ShardingSphere 找不到。 分表总体思路: 逻辑表:picture(业务层只感知逻辑表)。 物理表: 公共表:普通 / 高级 / 专业版空间 → picture 分片表:旗舰版空间 → picture_<spaceId>(如 picture_30001) 分片键:space_id。 当 SQL 带 space_id 时: 如果是旗舰空间 → 路由到专属表 picture_<spaceId> 否则回退到公共表 picture 当 SQL 没有 space_id 时: 默认走公共表 picture 执行流程示例 SELECT * FROM picture WHERE space_id = 30001; 执行步骤: SQL 解析 → 逻辑表名 picture,分片键 space_id = 30001 调用分片算法 → 算法返回 picture_30001 物理表名 SQL 改写 → SELECT * FROM picture_30001 WHERE space_id = 30001; SQL 执行 → 发送到数据库执行,返回结果 旗舰用户的查询必须强制带上 space_id 如何动态分表 初始化时:项目启动 → 查询已有空间 → 组装所有表名(picture + 各种 picture_xxx)→ 更新 ShardingSphere 的分片配置。 运行时:如果新建了旗舰空间 → 动态建一张新表(物理表picture_xxx)→ 再刷新 ShardingSphere 的分片配置。 逻辑表 picture ├── 物理表 picture ← 公共图库 / 普通空间数据 ├── 物理表 picture_30001 ← 旗舰空间 30001 ├── 物理表 picture_30002 ← 旗舰空间 30002 ... shardingsphere是如何实现分库分表的 ShardingSphere 本质上是一个数据库中间层,它在 JDBC 层拦截 SQL,先用内置的 SQL 解析器把逻辑表、分片键解析出来,然后根据事先配置好的分片规则和算法决定应该路由到哪些真实库表,再把逻辑 SQL 改写成针对真实表的 SQL 并下发执行,最后对多个分片返回的结果做归并(排序、聚合、分页等),让应用层拿到的结果和单库单表一致。这样业务只需要面向逻辑表写代码,不用关心具体分到哪张表,从而实现了分库分表对应用透明化。 注意:本项目VIP 用户 → 查专属的分表 picture_vipXX;普通用户 → 查公共表 picture。 因此路由逻辑能精确定位到 唯一的一张物理表,所以不会有多分片的结果,也就不需要复杂的归并 空间成员权限控制 空间和用户是多对多的关系,还要同时记录用户在某空间的角色,所以需要新建关联表 空间成员表 字段名 类型 默认值 允许为空 注释 id bigint auto_increment 否 id spaceId bigint — 否 空间 id userId bigint — 否 用户 id spaceRole varchar(128) 'viewer' 是 空间角色:viewer / editor / admin createTime datetime CURRENT_TIMESTAMP 否 创建时间 updateTime datetime CURRENT_TIMESTAMP 否 更新时间 RBAC模型 基于角色的访问控制 一般来说,标准的 RBAC 实现需要 5 张表:用户表、角色表、权限表、用户角色关联表、角色权限关联表,还是有一定开发成本的。由于我们的项目中,团队空间不需要那么多角色,可以简化RBAC 的实现方式,比如将 角色 和 权限 直接定义到配置文件中。 本项目角色: 角色 描述 浏览者 仅可查看空间中的图片内容 编辑者 可查看、上传和编辑图片内容 管理员 拥有管理空间和成员的所有权限 本项目权限: 权限键 功能名称 描述 spaceUser:manage 成员管理 管理空间成员,添加或移除成员 picture:view 查看图片 查看空间中的图片内容 picture:upload 上传图片 上传图片到空间中 picture:edit 修改图片 编辑已上传的图片信息 picture:delete 删除图片 删除空间中的图片 角色权限映射: 角色 对应权限键 可执行功能 浏览者 picture:view 查看图片 编辑者 picture:view, picture:upload, picture:edit, picture:delete 查看图片、上传图片、修改图片、删除图片 管理员 spaceUser:manage, picture:view, picture:upload, picture:edit, picture:delete 成员管理、查看图片、上传图片、修改图片、删除图片 RBAC 只是一种权限设计模型,我们在 Java 代码中如何实现权限校验呢? 1)最直接的方案是像之前校验私有空间权限一样,封装个团队空间的权限校验方法;或者类似用户权限校验一样,写个注解 + AOP 切面。 2)对于复杂的角色和权限管理,可以选用现成的第三方权限校验框架来实现,编写一套权限校验规则代码后,就能整体管理系统的权限校验逻辑了。( Sa-Token) Sa-Token 快速入门 1)引入: <!-- Sa-Token 权限认证 --> <dependency> <groupId>cn.dev33</groupId> <artifactId>sa-token-spring-boot-starter</artifactId> <version>1.39.0</version> </dependency> 2)让 Sa-Token 整合 Redis,将用户的登录态等内容保存在 Redis 中。 <!-- Sa-Token 整合 Redis (使用 jackson 序列化方式) --> <dependency> <groupId>cn.dev33</groupId> <artifactId>sa-token-redis-jackson</artifactId> <version>1.39.0</version> </dependency> <!-- 提供Redis连接池 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> 3)基本用法 StpUtil 是 Sa-Token 提供的全局静态工具。 用户登录时调用 login 方法,产生一个新的会话: StpUtil.login(10001); 还可以给会话保存一些信息,比如登录用户的信息: StpUtil.getSession().set("user", user) 接下来就可以判断用户是否登录、获取用户信息了,可以通过代码进行判断: // 检验当前会话是否已经登录, 如果未登录,则抛出异常:`NotLoginException` StpUtil.checkLogin(); // 获取用户信息 StpUtil.getSession().get("user"); 也可以参考 官方文档,使用注解进行鉴权: // 登录校验:只有登录之后才能进入该方法 @SaCheckLogin @RequestMapping("info") public String info() { return "查询用户信息"; } passwordEncoder多账号体系 本项目中存在两套权限校验体系。一套是 user 表的,分为普通用户和管理员;另一套是对团队空间的权限进行校 验。 为了更轻松地扩展项目,减少对原有代码的改动,我们原有的 user 表权限校验依然使用自定义注解 + AOP 的方式实 现。而团队空间权限校验,采用 Sa-Token 来管理。 这种同一项目有多账号体系的情况下,不建议使用 Sa-Token 默认的账号体系,而是使用 Sa-Token 提供的多账号认 证特性,可以将多套账号的授权给区分开,让它们互不干扰。 使用 Kit 模式 实现多账号认证 /** * StpLogic 门面类,管理项目中所有的 StpLogic 账号体系 * 添加 @Component 注解的目的是确保静态属性 DEFAULT 和 SPACE 被初始化 */ @Component public class StpKit { public static final String SPACE_TYPE = "space"; /** * 默认原生会话对象,项目中目前没使用到 */ public static final StpLogic DEFAULT = StpUtil.stpLogic; /** * Space 会话对象,管理 Space 表所有账号的登录、权限认证 */ public static final StpLogic SPACE = new StpLogic(SPACE_TYPE); } 修改用户服务的 userLogin 方法,用户登录成功后,保存登录态到 Sa-Token 的空间账号体系中: //记录用户的登录态 request.getSession().setAttribute(USER_LOGIN_STATE, user); //记录用户登录态到 Sa-token,便于空间鉴权时使用,注意保证该用户信息与 SpringSession 中的信息过期时间一致 StpKit.SPACE.login(user.getId()); StpKit.SPACE.getSession().set(USER_LOGIN_STATE, user); return this.getLoginUserVO(user); 之后就可以在代码中使用账号体系 // 检测当前会话是否以 Space 账号登录,并具有 picture:edit 权限 StpKit.SPACE.checkPermission("picture:edit"); // 获取当前 Space 会话的 Session 对象,并进行写值操作 StpKit.SPACE.getSession().set("user", "zy123"); Sa-Token 权限认证 1.核心:实现 StpInterface Sa-Token 需要知道某个用户 ID 拥有哪些角色和权限,这就要在项目中实现 StpInterface: 参考 官方文档,示例权限认证类如下: @Component public class StpInterfaceImpl implements StpInterface { // 根据用户 ID 查询权限列表 @Override public List<String> getPermissionList(Object loginId, String loginType) { // 实际项目里这里需要查数据库或缓存 return List.of("user.add", "user.update", "art.*"); } // 根据用户 ID 查询角色列表 @Override public List<String> getRoleList(Object loginId, String loginType) { return List.of("admin", "super-admin"); } } 项目权限较少时,可以只做角色校验;权限较多时,建议权限校验;二选一,不建议混用。 本项目 基于权限校验。 2.两种使用方式 方式一:注解式 使用 注解合并 简化代码。 @SaCheckPermission("picture.upload") public void uploadPicture() { ... } 调用接口时,Sa-Token 会在进入方法前自动校验权限(调用你实现的 StpInterface),并强制要求用户已登录。 特点: 优点:写法简洁,声明式安全。 缺点:参数必须通过 HttpServletRequest 获取;无法在方法内部灵活决定是否鉴权。 方式二:编程式 在方法内部的任意位置手动调用权限校验: if (!StpUtil.hasPermission("picture.view")) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR); } 可以先做一些逻辑判断,再决定是否需要权限校验(更灵活)。 适合场景:接口对未登录用户也开放,比如查看公共图片: 用编程式可以先判断是否需要鉴权,比如: 如果资源是公开的 → 不检查权限,直接返回。 如果资源属于某个空间 → 再做 hasPermission 校验。 @GetMapping("/doc/{id}") public BaseResponse<DocumentVO> getDoc(@PathVariable Long id) { // 查询文档 Document doc = docService.getById(id); ThrowUtils.throwIf(doc == null, ErrorCode.NOT_FOUND_ERROR); // 编程式鉴权逻辑 if (doc.isPrivate()) { // 先判断是否已登录 if (!StpUtil.isLogin()) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "请先登录"); } // 再判断是否有查看权限 if (!StpUtil.hasPermission("doc.view")) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "没有查看权限"); } } // 返回数据 return ResultUtils.success(docService.toVO(doc)); } 3. 注解式的登录强制性 注意:只要加了 Sa-Token 的权限/角色注解(例如 @SaCheckPermission),框架就会先检查用户是否已登录。 如果用户未登录,会直接抛异常(比如 NotLoginException),请求不会进入你的方法体。 原因: Sa-Token 的权限注解是在 进入方法前 执行的 AOP 切面逻辑。 在执行权限比对前,它必须知道“当前用户是谁”,所以会强制做登录状态校验。 如果你用的是 @SaSpaceCheckPermission(...),Sa-Token 就会走你 StpInterface#getPermissionList() 的实现,然后去匹配注解里写的权限码。 如果你改成基于角色的鉴权(比如 @SaCheckRole("admin")),那 Sa-Token 就会调用 StpInterface#getRoleList(),再用角色去匹配注解里的值。 注解式鉴权背后流程 拦截请求 → 注解触发 Sa-Token 的 AOP 切面。 获取 Token → 从 Cookie/Header/Param 读取,查 Redis 找到 loginId。 登录校验 → 未登录直接抛异常。 数据加载 → 调用你实现的 getPermissionList() 或 getRoleList()。 匹配比对 → 注解要求的权限/角色 vs 你返回的列表。 放行或拒绝 → 匹配成功执行方法,否则抛鉴权异常。 补充:注解合并 在 Spring 里,我们经常会遇到 注解继承 / 封装 的需求: 复用已有注解的功能,但不想每次都写一堆重复属性。 想要做业务语义化的封装。 这时候就会用到 @AliasFor 来做注解属性的别名映射。 1)定义一个“原始注解” @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface CheckPermission { String value(); // 权限码 String type() default "default"; // 权限类型 } 2)自定义一个“语义化的封装注解” @CheckPermission(type = "space") // 👈 这里已经给 type 赋了固定值 @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface SpacePermission { @AliasFor(annotation = CheckPermission.class, attribute = "value") String[] value(); // 只把 value 暴露出来 } 3)使用 public class SpaceController { // 写法简洁 @SpacePermission("space:add") public void addSpace() {} // 实际等价于: // @CheckPermission(value = "space:add", type = "space") } Spring 在解析注解时,会做“注解合并”。 它会发现 @SpacePermission 上有 @CheckPermission,而且 value 用了 @AliasFor。 最终运行时效果就是 @CheckPermission(type="space", value="space:add")。 type="space"是预设好的,用户不能设置。 协同编辑 WebSocket 事件驱动模型的优势 与生产者直接调用消费者不同,事件驱动模型的核心优势在于 解耦 和 异步性: 解耦:生产者与消费者之间不需要直接依赖彼此的实现。生产者只需触发事件并交由事件分发器处理,消费者则根据事件类型执行相应逻辑。 异步性:通过引入事件分发器这一“中介”,系统可以实现异步消息传递,减少阻塞与等待,提高并发处理能力。 高并发与实时性:事件驱动可以在同一时间处理多个并发任务,更高效地响应实时请求。 如何解决协同冲突? 方案一:单用户编辑锁定: 业务上约定 同一时刻仅允许一位用户进入编辑状态。 其他用户在此期间只能实时查看修改效果,不能直接编辑。当该用户退出编辑后,其他用户才可进入编辑状态。 事件触发者(用户 A 的动作) 事件类型(发送消息) 事件消费者(其他用户的处理) 用户 A 建立连接,加入编辑 INFO 显示"用户 A 加入编辑"的通知 用户 A 进入编辑状态 ENTER_EDIT 其他用户界面显示"用户 A 开始编辑图片",锁定编辑状态 用户 A 执行编辑操作 EDIT_ACTION 放大/缩小/左旋/右旋当前图片 用户 A 退出编辑状态 EXIT_EDIT 解锁编辑状态,提示其他用户可以进入编辑状态 用户 A 断开连接,离开编辑 INFO 显示"用户 A 离开编辑"的通知,并释放编辑状态 用户 A 发送了错误的消息 ERROR 显示错误消息的通知 方案二:实时协同编辑(OT 算法) OT(Operational Transformation)是在线协作中常用的一种算法(例如 Google Docs、石墨文档)。 操作 (Operation):用户对协作内容的修改,例如插入字符、删除字符等。 转化 (Transformation):当多个用户同时修改时,OT 会根据上下文调整操作位置或内容,保证不同顺序执行的结果一致。 因果一致性:保证每个用户的操作都基于他们所看到的最新状态。 举一个简单的例子,假设初始内容是 "abc",用户 A 和 B 同时进行编辑: 用户 A 在位置 1 插入 "x" 用户 B 在位置 2 删除 "b" 如果不使用 OT: A 执行后 → "axbc" B 执行后 → "ac"(直接应用会导致 A 的结果被覆盖) 使用 OT: A 执行后 → "axbc" B 的删除操作经过转化 → 删除 "b" 在 "axbc" 中的新位置 最终结果 → "axc",A 和 B 看到的内容保持一致 OT 的关键难点在于设计合适的操作转化规则,以确保在不同编辑顺序下,最终结果仍然一致。本项目采取方案一!!! WebSocket 特性 HTTP WebSocket 通信模式 半双工 (Half-Duplex) 一问一答,同一时刻只能一端发送 全双工 (Full-Duplex) 双向通信,双方可同时发送和接收数据 连接模型 短连接 请求-响应后连接立即关闭,无状态 长连接 握手后建立持久连接,直到关闭,有状态 数据流向 单向 (客户端发起请求) 服务器不能主动推送数据 双向 服务器和客户端均可主动发送消息 协议开销 大 每次通信都携带完整的HTTP头部(Cookie、UA等) 小 初始握手后,数据传输使用轻量级帧,头部仅几字节 适用场景 传统网页加载、API调用、表单提交等请求-响应模式 实时应用:聊天室、在线游戏、实时数据推送、协同编辑 URL协议 http://或 https:// ws://(非加密) 或 wss://(加密,相当于HTTPS) 本质 文档传输协议,为获取超文本和资源设计 通信协议,为低延迟、实时双向通信设计 业务流程图 引入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency> WebSocket 配置类 @Configuration @EnableWebSocket @RequiredArgsConstructor public class WebSocketConfig implements WebSocketConfigurer { private final PictureEditWebSocketHandler pictureEditWebSocketHandler; private final WsHandshakeInterceptor wsHandshakeInterceptor; @Override public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) { ////当客户端在浏览器中执行new WebSocket("ws://<你的域名或 IP>:<端口>/ws/picture/edit?pictureId=123");就会由 Spring 把这个请求路由到你的 pictureEditWebSocketHandler 实例。 registry.addHandler(pictureEditWebSocketHandler, "/ws/picture/edit") .addInterceptors(wsHandshakeInterceptor) .setAllowedOrigins("*"); } } 任何客户端连接 ws://<host>:<port>/ws/picture/edit 都会交给 pictureEditWebSocketHandler 处理(负责收发消息) 在连接建立前,会先走 WsHandshakeInterceptor 做验证(请求参数是否缺失、用户是否登录、用户是否有编辑权限、图片是否存在、图片所在空间是否存在) 验证通过后,将 当前请求信息 user pictureId 存到 Sesssion中: attributes.put("user", loginUser); 后续取数据: User user = (User) session.getAttributes().get("user"); 协同编辑原理 在协同编辑场景中,我们使用 WebSocket 实现实时通讯。每个图片编辑操作由用户发起,WebSocket 会话(WebSocketSession)则承载每个用户的连接。下面是实现原理: // key: pictureId,value: 这张图下所有活跃的 Session(即各个用户的连接) Map<Long, Set<WebSocketSession>> pictureSessions; WebSocketSession 与用户 当用户 A 在浏览器中打开 pictureId=123 的编辑页面时,会产生一个 WebSocketSession(不同于 HttpSession)。 如果用户 A 在同一浏览器打开了新的标签页,或者在不同的浏览器/设备上再次打开编辑页面,那么每个新的连接都会产生一个 新的 WebSocketSession。 假设系统中有两张图片,pictureId 分别为 123 和 200,当前活跃的 WebSocket 会话(连接)如下: pictureId pictureSessions.get(pictureId) 123 { sessionA, sessionB } (用户 A、B 的连接) 200 { sessionC } (只有用户 C 的连接) 当 某个 WebSocketSession 发消息时,所有与该图片相关的 WebSocketSession(即同一 pictureId 下的所有连接)都会收到这条消息。 策略模式引入 针对不同的消息类型(ENTER_EDIT、EXIT_EDIT、EDIT_ACTION),if-else会导致类越来越臃肿,扩展性差。 优化:采用 策略模式 定义统一接口 PictureEditMessageHandler: public interface PictureEditMessageHandler { String getType(); void handle(PictureEditRequestMessage request, WebSocketSession session, User user, Long pictureId) throws Exception; } 针对不同消息类型定义独立策略: @Component @RequiredArgsConstructor public class EnterEditMessageHandler implements PictureEditMessageHandler { private final PictureEditWebSocketHandler sessionManager; private final UserService userService; private final Map<Long, Long> pictureEditingUsers = new ConcurrentHashMap<>(); @Override public String getType() { return PictureEditMessageTypeEnum.ENTER_EDIT.getValue(); } @Override public void handle(PictureEditRequestMessage request, WebSocketSession session, User user, Long pictureId) throws IOException { if (!pictureEditingUsers.containsKey(pictureId)) { pictureEditingUsers.put(pictureId, user.getId()); PictureEditResponseMessage response = new PictureEditResponseMessage(); response.setType(PictureEditMessageTypeEnum.ENTER_EDIT.getValue()); response.setMessage(String.format("用户 %s 开始编辑图片", user.getUserName())); response.setUser(userService.getUserVO(user)); sessionManager.broadcastToPicture(pictureId, response); } } } 新增消息类型时,只需实现新的 Handler,而不必修改原有代码。 Disruptor 优化 Disruptor原理 在 Spring MVC / WebSocket 场景里,如果接口(或消息处理)内部存在耗时操作,请求线程会被长时间占用,最终可能把 Tomcat 的请求线程/连接池耗尽(默认 200)。 实践中,绝大多数请求是“快请求”(毫秒级),可在请求线程内直接完成;少量“慢请求”(秒级)应当切到异步线程执行,做到快速返回 + 后台处理。 Disruptor 是一套高性能并发框架,核心是无锁(或低锁)的环形队列 RingBuffer,为高吞吐/低延迟场景而生。相较常规队列,Disruptor 通过序号(sequence)、缓存命中和内存屏障等机制,实现了极低延迟与有序消费。 引入 Disruptor 的主要作用: 把耗时的业务处理从 WebSocket / Tomcat 请求线程中解耦出来,交给一个高性能的异步消息通道去处理,从而让前端请求能尽快返回,不会因为几个慢操作就把服务器的请求线程全堵死。 同一条事件流在 RingBuffer 中按序号消费,避免多线程乱序导致的业务问题(比如图片编辑步骤错乱)。 工作流程(直观理解): 1)环形队列初始化:创建固定大小的 RingBuffer(如 8),底层是可复用的事件对象数组,全局使用递增的序号标记事件顺序。 2)生产者写入数据:申请一个可写序号 → 将数据写入事件对象 → 发布(publish)成功后,序号递增。 3)消费者读取数据:按序检查可读序号 → 取出对应事件 → 处理 → 提交后继续下一个序号。 4)环形队列循环使用:写到末尾回到起点(环形),但序号持续递增保证先后顺序。 5)防止数据覆盖:若生产速度追上了消费速度,生产者会等待,确保未处理的数据不会被覆盖(“背压机制(Backpressure)” )。 6)解耦与异步:WebSocket 收到消息后直接投递到 RingBuffer,由 Disruptor 的消费者按序处理,实现快速入队 + 后台串行/并行消费。 WebSocket+Disruptor完整流程 用户 A (前端)通过 WebSocket 发送编辑消息(如旋转图片)。 WebSocket 服务端(Disruptor 生产者 Producer) 接收消息 → 解析成事件对象(如 EditEvent) 从 Disruptor 的 RingBuffer 申请一个可写序号(next())。 将事件数据(用户信息、操作类型等)写入该槽位。 调用 publish() 发布事件,标记为“已可消费”。 Disruptor 消费者 收到已发布的事件(按序号顺序消费); 调用对应的业务逻辑(如图片旋转、滤镜、保存等); 处理完成后触发后续逻辑(如广播消息)。 后端广播:向所有正在编辑该图片的 WebSocket 会话广播消息。 { "type": "EDIT_ACTION", "message": "用户 A 执行了编辑操作: rotate", "user": { "userName": "A" }, "editAction": "rotate" } 前端接收并更新 UI:所有用户(如用户 B)接收到编辑操作的通知,并在界面上实时更新编辑状态。 多实例扩展说明 原则:同一张图片(同一个 pictureId)的所有 WebSocket 连接,必须落在同一后端实例,这样才能: 保证消息顺序一致; 保证广播能触达该图下所有用户; 避免跨实例状态不同步。 不能出现:同一个 pictureId 分别有一部分连接在实例 A、另一部分在实例 B。否则你本地内存里的 pictureSessions Map 就会被割裂,广播、顺序都乱掉。 Disruptor 仅作为 单机内事件队列(即 WebSocket 服务端实例内部的低延迟队列)。它解决的是本机的高性能并发调度问题,不会帮你做跨实例同步。因此,只要保证同一个 pictureId 的连接都路由到同一实例,Disruptor 就能无缝工作,不管集群里有多少实例。 缓存技术 图片列表多级缓存 多级缓存是指结合本地缓存和分布式缓存的优点,在同一业务场景下构建两级缓存系统,这样可以兼顾本地缓存的高性能、以及分布式缓存的数据一致性和可靠性。 缓存Key拼接思路 目前,对图片列表的查询进行了缓存处理,包括公共图库(public)以及私有和团队空间。缓存的 key 由 空间 ID(spaceId)+ 当前页码(current)+ 每页显示数量(size)+ 标签(tags) + 类别(category)+ 搜索框(searchText) 组成。具体缓存Key生成方式如下: // 2) 统一 namespace(便于按空间批量清理) String namespace = (spaceId == null) ? "public" : String.valueOf(spaceId); // 3) 参与哈希的查询参数(稳定顺序 + 规范化) List<String> sortedTags; List<String> tags = queryRequest.getTags(); if (tags == null || tags.isEmpty()) { // 后面不需要往里加元素时用它最省心 sortedTags = Collections.emptyList(); } else { // 拷贝一份,避免改动原始参数 sortedTags = new ArrayList<>(tags); Collections.sort(sortedTags); // 自然顺序排序 } Map<String, Object> params = new LinkedHashMap<>(); params.put("category", Optional.ofNullable(queryRequest.getCategory()).orElse("")); params.put("tags", sortedTags); params.put("searchText", Optional.ofNullable(queryRequest.getSearchText()).orElse("")); params.put("current", current); params.put("size", size); // 4) 稳定序列化 + MD5 String queryJson = JSONUtil.toJsonStr(params); String hash = DigestUtil.md5Hex(queryJson); // 5) 统一 Key:版本 + 空间 + 哈希 String cacheKey = "smilepicture:listPictureVOByPage:v1:" + namespace + ":" + hash; 查缓存整体思路 整体采用 本地缓存(Caffeine) + 分布式缓存(Redis) + 分布式锁 的两级缓存机制,主要流程: 本地缓存(一级缓存)优先(Caffeine) 本地查cacheKey,命中直接返回,最快速,减少 Redis 压力。 Redis 二级缓存 本地未命中时查 Redis,如果命中则回写本地缓存。 分布式互斥锁防击穿 Boolean ok = stringRedisTemplate .opsForValue() .setIfAbsent(lockKey, token, Duration.ofMillis(expireMs)); 如果 Redis 也未命中,则尝试获取 lock:{cacheKey} 的分布式锁(非cacheKey) token:采用UUID生成的唯一标识,确保锁的持有者身份 双重检查:拿到锁后再次查 Redis,防止并发期间已有线程写入。 如果依旧未命中,则回源数据库: 非空数据:正常写入缓存,TTL = redisExpireSeconds。 空数据:写入短期缓存(TTL = 60 秒),防止缓存穿透。 用 Lua 脚本安全释放锁,保证只释放自己的锁。 未拿到锁的线程自旋等待 没拿到锁的线程不会立刻查 DB,而是自旋等待: 每隔 WAIT_INTERVAL_MS=80ms 查询一次 Redis; 最多自旋 WAIT_TIMES=8 次(约 640ms); 如果在等待中 Redis 有数据,则直接返回; 如果等完还没有,就兜底去 DB,但不写缓存(由持锁线程负责)。 防缓存击穿:分布式锁 + 双重检查 + 自旋等待。 防缓存穿透:空值缓存(写入 60 秒的空 JSON 或空集合)。 两级缓存:Caffeine + Redis,提升查询性能。 安全解锁:Lua 脚本校验 token,确保不会误删他人锁。 防缓存雪崩:随机过期时间, int expire = 300 + RandomUtil.*randomInt*(0, 300); 。这样可以确保缓存的失效时间不会同时过期,提升缓存的稳定性。 为什么双重检查? 线程 A 慢查询,锁过期 T0:线程 A 先到,发现缓存没有 → 拿到锁(锁 5s)。 T1:A 去查数据库(假设这一步耗时 6s,很慢)。 T2 (5s 到达):A 还在查 DB,但锁自动过期了(Redis 释放锁)。 T3:线程 B 进来,发现 Redis 里还是没数据 → 成功拿到锁。 T4:线程 A 查完 DB,写入 Redis,但还没来得及释放锁。 T5:线程 B 开始执行 → 如果没有双重检查,它会再查一次 DB。 👉 结果:重复 DB 查询,击穿防护失败一半。 👉 有了双重检查:线程 B 在拿到锁后会再看一眼 Redis,发现 A 已经写好了数据,就不会再查 DB。 缓存删除逻辑 目前,缓存的删除是基于 spaceId 来进行的。逻辑上,当某个空间中的图片发生变化时,需要使该空间下的分页缓存全部失效。 原有删除流程 1.根据空间 ID 拼出 Redis Key 前缀。 2.使用 Redis SCAN 命令批量扫描所有符合前缀的 Key。 3.收集结果后,一次性 DEL 删除,减少网络往返。 4.同步清除本地 Caffeine 缓存中的对应 Key。 现有方案(基于 版本号 + TTL) Key 命名规则 smilepicture:listPictureVOByPage:{namespace}:v{version}:{queryHash} namespace:公开图库用 "public",其它情况用 spaceId。 version:该空间的缓存版本号,存储在 Redis 计数器里。 queryHash:由查询参数(category、tags、searchText、分页参数等)序列化 + MD5 得到,保证不同条件下 key 唯一。 删除流程(O(1) 失效) 1.当空间下的图片发生变化时,不再扫描/删除所有 key。 2.直接对该 namespace 的版本号执行一次 INCR: INCR smilepicture:version:{namespace} 3.新请求自动写入/读取新版本的 Key;旧版本 Key 不再命中。 4.旧缓存依赖 TTL 自动过期清理,无需人工干预。 5.本地缓存 Caffeine 在 bump 版本时同时清理属于该 namespace 的 key。 还可以继续优化 现在的问题就是当某个空间中的图片发生变化时,需要使该空间下的分页缓存全部失效,效率太低。 分层缓存(List Cache + Detail Cache)模式 1)列表缓存(轻量级) Key: gallery:list:{namespace}:v{version}:{queryHash} Value: [101, 102, 103, ...] (只存 ID,顺序信息) 2)详情缓存(精细化) Key: gallery:detail:{id} Value: PictureVO(id、标题、缩略图、时间戳等) 查询流程 用户请求「某空间下第 1 页图片」 先查 列表缓存,得到 ID 数组 [101, 102, 103]。 遍历 ID 数组,批量 MGET 详情缓存: gallery:detail:101 ✅ 命中 gallery:detail:102 ✅ 命中 gallery:detail:103 ❌ 缺失 对于 ❌ 缺失的 ID(比如 103): 回源 DB 查询该图片详情 写入 gallery:detail:103(带 TTL) 拼装成完整的返回结果。 热点Key问题 热点 Key(Hot Key),就是在 Redis 里某个 key 被高并发、大流量频繁访问,导致 单点压力集中,可能出现: Redis 某个节点 CPU 飙升 key 过期瞬间导致 缓存击穿 热点数据频繁刷新,DB 被拖垮 热点检测 在 Redis 前做一层统计,发现哪些 key QPS 异常高。 常见手段: 接入中间件(比如阿里云 Redis、Codis 自带热点监控) 在业务层收集访问日志,做 TopN 统计 1)应用层埋点统计 所有缓存读写操作都会经过一个统一的“入口”,在这个入口里,每次访问某个 key 时,做一次计数。 // 计数器 private final ConcurrentHashMap<String, LongAdder> hotKeyCounter = new ConcurrentHashMap<>(); // 每次访问时调用 public void recordAccess(String key) { hotKeyCounter.computeIfAbsent(key, k -> new LongAdder()).increment(); } // 定期获取 TopN 热点 Key public List<String> getHotKeys(int topN) { return hotKeyCounter.entrySet().stream() .sorted((a, b) -> Long.compare(b.getValue().sum(), a.getValue().sum())) .limit(topN) .map(Map.Entry::getKey) .toList(); } 每隔一段时间(比如 1 分钟)遍历计数器getHotKeys,输出访问量 TopN 的 key。 如果要做 滑动窗口统计,思路是把时间切分成多个小片段(比如每秒一个桶,用数组/环形队列存储),每次请求把计数写到当前时间片。然后定期滚动,把过期的片段丢掉,统计时只合并最近 N 秒的计数。这样就能动态反映出「最近一段时间」的热点 key。用的数据结构一般是 环形数组 + ConcurrentHashMap(每个时间片一个 map),实现简单、并发安全。 解决热点 Key 的常见方法 1)本地缓存 + Redis 二级缓存 2)把一个热点 key 拆成多个副本:原 key hotKey → hotKey:1, hotKey:2, …, hotKey:N 请求时按随机/哈希路由到某个副本。减少单个 key 的压力,让请求分散到多个 key 上。 3)缓存预热 + 永不过期(逻辑过期)对确定的热点 key,在系统启动或活动前 提前写入缓存。缓存里存一个“过期时间字段”,请求先返回旧值,再异步更新。避免热点 key 同时过期,打爆 DB。 缓存值里带一个字段:expireTime。 请求进来时,如果发现 expireTime < now,说明缓存过期: 先返回旧值 给用户(保证不中断服务)。 同时异步启动一个线程,去 DB 拉最新数据,刷新缓存里的值和新的 expireTime。 4)设置随机过期时间(避免雪崩) 5)热点请求打散,只允许一个线程回源,其他线程自旋等待,避免缓存失效时同时回源。
项目
zy123
1年前
0
60
0
2025-05-28
消息队列MQ
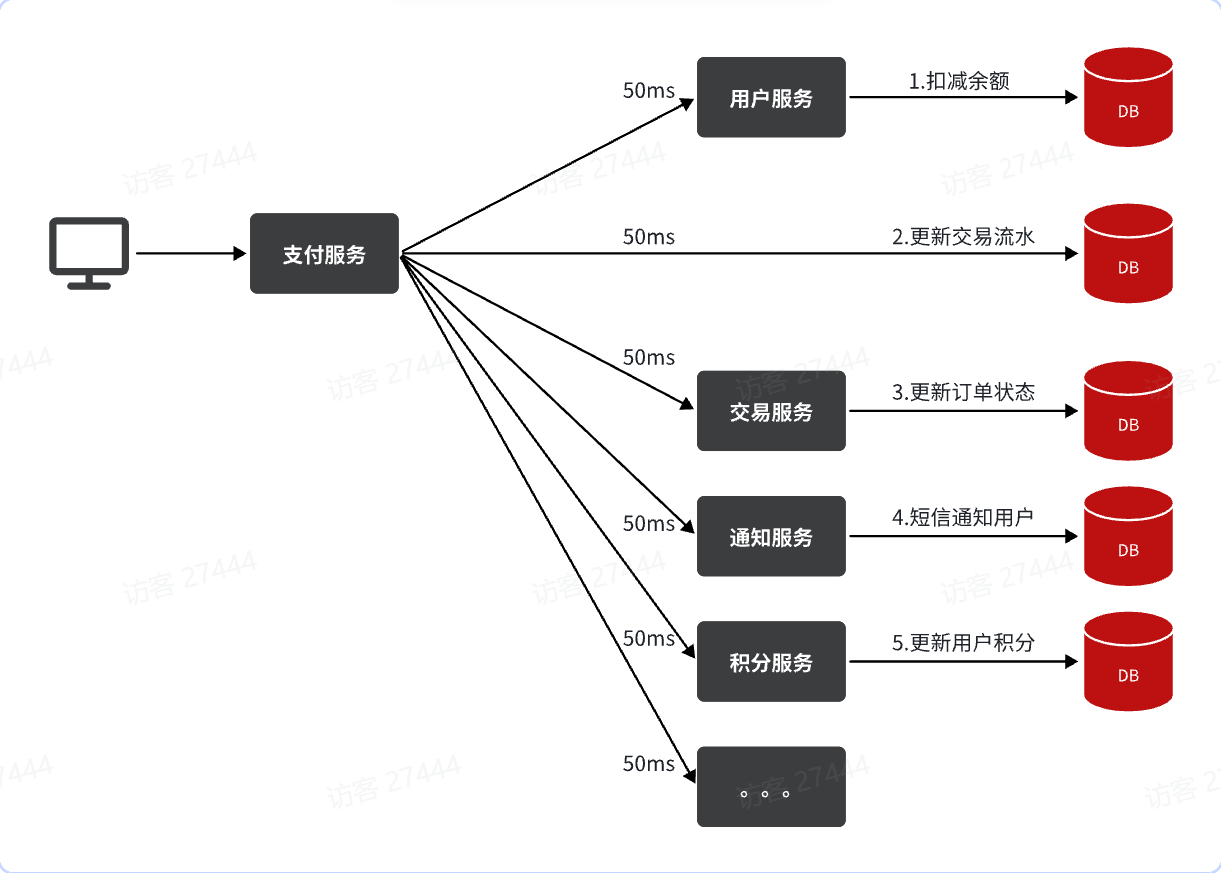
消息队列MQ 初识MQ 同步调用 同步调用有3个问题: 拓展性差,每次有新的需求,现有支付逻辑都要跟着变化,代码经常变动 性能下降,每次远程调用,调用者都是阻塞等待状态。最终整个业务的响应时长就是每次远程调用的执行时长之和 级联失败,当交易服务、通知服务出现故障时,整个事务都会回滚,交易失败。 异步调用 技术选型 RabbitMQ 部署 mq: #消息队列 image: rabbitmq:3.8-management container_name: mq restart: unless-stopped hostname: mq environment: TZ: "Asia/Shanghai" RABBITMQ_DEFAULT_USER: admin RABBITMQ_DEFAULT_PASS: "admin" ports: - "15672:15672" - "5672:5672" volumes: - mq-plugins:/plugins # 持久化数据卷,保存用户/队列/交换机等元数据 - ./mq-data:/var/lib/rabbitmq networks: - hmall-net volumes: mq-plugins: http://localhost:15672/ 访问控制台 架构图 publisher:生产者,发送消息的一方 consumer:消费者,消费消息的一方 queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理 exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。不存储 virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue(每个项目+环境有各自的vhost) 一个队列最多指定给一个消费者! Spring AMQP 快速开始 交换机和队列都是直接在控制台创建,消息的发送和接收在Java应用中实现! 简单案例:直接向队列发送消息,不经过交换机 引入依赖 <!--AMQP依赖,包含RabbitMQ--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> 配置MQ地址,在publisher和consumer服务的application.yml中添加配置: spring: rabbitmq: host: localhost # 你的虚拟机IP port: 5672 # 端口 virtual-host: /hmall # 虚拟主机 username: hmall # 用户名 password: 123 # 密码 消息发送: 然后在publisher服务中编写测试类SpringAmqpTest,并利用**RabbitTemplate**实现消息发送: @SpringBootTest public class SpringAmqpTest { @Autowired private RabbitTemplate rabbitTemplate; @Test public void testSimpleQueue() { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, spring amqp!"; // 发送消息 rabbitTemplate.convertAndSend(queueName, message); } } convertAndSend如果 2 个参数,第一个表示队列名,第二个表示消息; 消息接收 @Component public class SpringRabbitListener { // 利用RabbitListener来声明要监听的队列信息 // 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。 // 可以看到方法体中接收的就是消息体的内容 @RabbitListener(queues = "simple.queue") public void listenSimpleQueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者接收到消息:【" + msg + "】"); } } 然后启动启动类,它能自动从队列中取出消息。取出后队列中就没消息了! 交换机 无论是 直连Direct、主题Topic 还是 扇形Fanout 交换机,你都可以用 同一个 Binding Key 把多条队列绑定到同一个交换机上。 1)fanout:广播给每个绑定的队列 发送消息: convertAndSend如果 3 个参数,第一个表示交换机,第二个表示RoutingKey,第三个表示消息。 @Test public void testFanoutExchange() { // 交换机名称 String exchangeName = "hmall.fanout"; // 消息 String message = "hello, everyone!"; rabbitTemplate.convertAndSend(exchangeName, "", message); } 2)Direct交换机 队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key) 消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。 Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的BindingKey与消息的 Routing key完全一致,才会接收到消息 注意,RoutingKey不等于队列名称 3)Topic交换机 Topic类型的交换机与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。 只不过Topic类型交换机可以让队列在绑定BindingKey 的时候使用通配符! BindingKey一般都是有一个或多个单词组成,多个单词之间以.分割 通配符规则: #:匹配一个或多个词 *:匹配不多不少恰好1个词 举例: item.#:能够匹配item.spu.insert 或者 item.spu item.*:只能匹配item.spu 转发过程:把发送者传来的 Routing Key 按点分成多级,和各队列的 Binding Key(可以带 *、# 通配符)做模式匹配,匹配上的队列统统都能收到消息。 注意:生产者在发送消息时,必须指定一个明确的 RoutingKey,而队列绑定到 Topic Exchange 时,指定的 BindingKey 可以包含通配符。 Routing Key和Binding Key Routing Key(路由键) 由发送者(Producer)在发布消息时指定,附着在消息头上。 用来告诉交换机:“我的这条消息属于哪类/哪个主题”。 Binding Key(绑定键) 由消费者(在应用启动或队列声明时)指定,是把队列绑定到交换机时用的规则。有些 UI 里 Routing Key 等同于 Binding Key! 告诉交换机:“符合这个键的消息,投递到我这个队列”。 交换机本身不设置 Routing Key 或 Binding Key,它只根据类型(Direct/Topic/Fanout/Headers)和已有的“队列–绑定键”关系,把 incoming Routing Key 匹配到对应的队列。 Direct Exchange 路由规则:Routing Key === Binding Key(完全一致) 场景:一对一或一对多的精确路由 Topic Exchange 路由规则 :支持通配符 *:匹配一个单词 #:匹配零个或多个单词 例: Binding Key绑定键 order.* → 能匹配 order.created、order.paid 绑定键 order.# → 能匹配 order.created.success、order 等 Fanout Exchange 路由规则:忽略 Routing/Binding Key,消息广播到所有绑定队列 场景:聊天室广播、缓存失效通知等 消费者处理消息 不同队列: 同一个交换机 + 相同 routing key 绑定到 多个不同的队列 → 每个队列都会收到一份消息,各自独立处理。 👉 相当于多个队列订阅了同类信息,TOPIC 同一个队列: 多个消费者(不管是一个应用里开多个 listener,还是多台实例部署)监听 同一个队列 → 一条消息只会被其中一个消费者消费,起到负载均衡作用。 👉 常用于“任务分摊”。 基于注解声明交换机、队列 前面都是在 RabbitMQ 管理控制台手动创建队列和交换机,开发人员还得把所有配置整理一遍交给运维,既繁琐又容易出错。更好的做法是在应用启动时自动检测所需的队列和交换机,若不存在则直接创建。 基于注解方式来声明 type 默认交换机类型为ExchangeTypes.DIRECT @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue1"), exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT), key = {"red", "blue"} )) public void listenDirectQueue1(String msg){ System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】"); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue2"), exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT), key = {"red", "yellow"} )) public void listenDirectQueue2(String msg){ System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】"); } 检查队列 如果 RabbitMQ 中已经有名为 direct.queue1 的队列,就不会重复创建; 如果不存在,RabbitAdmin 会自动帮你创建一个。 检查交换机 同理,会查看有没有名为 hmall.direct、类型为 direct 的交换机,若不存在就新建。 检查绑定 最后再去声明绑定关系:把 direct.queue1 绑定到 hmall.direct,并且 routing-key 为 "red" 和 "blue"。 如果已有相同的绑定(队列、交换机、路由键都一致),也不会再重复创建。 消息转换器 使用JSON方式来做序列化和反序列化,替换掉默认方式。 更小或可压缩的消息体、易读、易调试 1)引入依赖 <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-xml</artifactId> <version>2.9.10</version> </dependency> 2)配置消息转换器,在publisher和consumer两个服务的启动类中添加一个Bean即可: @Bean public MessageConverter messageConverter(){ // 1.定义消息转换器 Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter(); // 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息 jackson2JsonMessageConverter.setCreateMessageIds(true); return jackson2JsonMessageConverter; } MQ高级 我们要解决消息丢失问题,保证MQ的可靠性,就必须从3个方面入手: 确保生产者一定把消息发送到MQ 确保MQ不会将消息弄丢 确保消费者一定要处理消息 发送者的可靠性 发送者重试 修改发送者模块的application.yaml文件,添加下面的内容: 主要是针对网络连接失败的场景,会自动重试;交换机不存在,不会触发重试。 spring: rabbitmq: connection-timeout: 1s # 设置MQ的连接超时时间 template: retry: enabled: true # 开启超时重试机制 initial-interval: 1000ms # 失败后的初始等待时间 multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multiplier max-attempts: 3 # 最大重试次数 阻塞重试,一般不建议开启。 发送者确认机制 一、机制概述 RabbitMQ 提供两种发送者确认机制,确保消息投递的可靠性: Publisher Confirm:确认消息是否到达 RabbitMQ 服务器 Publisher Return:确认消息是否成功路由到队列 二、配置开启 1.在发送者模块的application.yaml中添加配置: spring: rabbitmq: publisher-confirm-type: correlated # 开启异步confirm机制 publisher-returns: true # 开启return机制 confirm类型说明: none(默认模式):关闭confirm机制,消息由于网络连接失败也不会提醒。 simple:同步阻塞等待MQ的回执 correlated:MQ异步回调返回回执 2.每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置。 @Slf4j @Configuration @RequiredArgsConstructor public class MqConfig { private final RabbitTemplate rabbitTemplate; @PostConstruct public void init() { // 设置全局ReturnCallback rabbitTemplate.setReturnsCallback(returned -> { log.error("消息路由失败 - Exchange: {}, RoutingKey: {}, ReplyCode: {}, ReplyText: {}", returned.getExchange(), returned.getRoutingKey(), returned.getReplyCode(), returned.getReplyText()); // 可在此添加告警或重试逻辑 sendAlert(returned); }); } } 三、ConfirmCallback 使用 消息发送时设置确认回调CorrelationData 这里的CorrelationData中包含两个核心的东西: id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆 SettableListenableFuture:回执结果的Future对象 public void sendMessageWithConfirmation(String exchange, String routingKey, Object message) { // 1. 创建关联数据 CorrelationData correlationData = new CorrelationData(); // 2. 添加确认回调 correlationData.getFuture().addCallback( result -> { if (result.isAck()) { log.info("✅ 消息成功到达MQ服务器"); } else { log.error("❌ 消息发送失败: {}", result.getReason()); // 可在此添加重试逻辑 } }, ex -> { log.error("⚠️ 确认过程发生异常", ex); } ); // 3. 发送消息 rabbitTemplate.convertAndSend(exchange, routingKey, message, correlationData); } 四、消息投递结果分析 场景 网络状态 路由状态 ConfirmCallback ReturnsCallback 最终结果 完全成功 ✅ 成功 ✅ 成功 ACK 不触发 消息入队 网络失败 ❌ 失败 - NACK 不触发 发送失败 路由失败 ✅ 成功 ❌ 失败 ACK 触发 消息丢弃 交换机不存在 ✅ 成功 ❌ 失败 ACK 触发 消息丢弃 端到端投递保障 ConfirmCallback 只告诉你:消息“到”了 RabbitMQ 服务器吗?(ACK:到;NACK:没到) ReturnCallback 只告诉你:到达服务器的消息,能“进”队列吗?(能进就不回;进不了就退) 两者都成功,才能确认:“这条消息真的安全地进了队列,等着消费者去拿。” 🟢 ACK:消息到达MQ服务器(可能路由失败) 🔴 NACK:消息未到达MQ服务器(网络问题) 🔵 Return:消息到达但路由失败(配置问题) 通过组合使用这两种机制,可以实现完整的端到端消息投递保障。如果由于网络问题,NACK了,那么会被correlationData.getFuture().addCallback(...)回调函数捕捉!!! MQ的可靠性 数据持久化 MQ消息持久化就是指当RabbitMQ服务重启后,消息仍然会保留在队列中不会丢失。 非持久化消息:只存储在内存中;持久化消息:同时存储在内存和磁盘中 为了保证数据的可靠性,必须配置数据持久化(从内存保存到磁盘上),包括: 交换机持久化(选Durable) 队列持久化(选Durable) 消息持久化(选Persistent) 控制台方式: 代码方式,默认都是持久化的,不用变动。 消费者可靠性 消费者确认机制 消费者确认机制 (Consumer Acknowledgement) 是为了确认消费者是否成功处理消息。当消费者处理消息结束后,应该向 RabbitMQ 发送一个回执,告知 RabbitMQ 自己消息处理状态: ack:成功处理消息,RabbitMQ 从队列中删除该消息 nack:消息处理失败,RabbitMQ 需要再次投递消息 reject:消息处理失败并拒绝该消息,RabbitMQ 从队列中删除该消息 上述的NACK状态时,MQ会不断向消费者重投消息,直至被正确处理!!! 在消费者方,通过下面的配置可以修改消费者收到消息后的处理方式: none:消费者收到消息后,RabbitMQ 立即自动确认(ACK) manual,手动实现ack; auto(默认模式),自动档,业务逻辑异常返回nack, 消息解析异常 返回reject,其他ack spring: rabbitmq: listener: simple: acknowledge-mode: auto 消费者重试 类似发送者的重试机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。 重试达到最大次数后,会返回reject,消息会被丢弃 修改consumer服务的application.yml文件,添加内容: spring: rabbitmq: listener: simple: retry: enabled: true # 开启消费者失败重试 initial-interval: 1000ms # 初识的失败等待时长为1秒 multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval max-attempts: 3 # 最大重试次数 stateless: true # true无状态(默认);如果业务中包含事务,这里改为false有状态 核心概念:一次事务 vs. 多次事务 想象一下这个场景:你是一个消费者,从MQ收到一条消息,内容是“给用户A的账户增加10元”。你的服务需要执行两个步骤: 处理业务逻辑(更新数据库,给用户A加钱)。 确认消息(告诉MQ消息处理成功了)。 这个“处理业务逻辑”和“确认消息”的过程,可以放在一个数据库事务里。 特性 无状态重试 (stateless: true) 有状态重试 (stateless: false) 本质 本地方法重试 消息重新投递 事务范围 所有重试在同一个事务中 每次重试是独立的事务 MQ感知 MQ完全不知情(只投递1次) MQ完全知情(多次投递) 性能 高(无网络开销) 较低(有网络开销) 安全性 低(易导致重复操作) 高(每次失败都回滚) 适用场景 幂等操作、非DB操作(如HTTP调用) 非幂等操作、数据库事务操作 为什么用了 @Transactional必须有状态重试? 假设是无状态重试,重试是在同一次方法调用/同一事务里循环进行的(拦截器内部重试)。 第一次失败抛出异常后,当前事务被标记为 rollback-only。 接下来即便你第2次、第3次尝试都“业务成功”,提交时也会失败(因为事务早已不可提交)。 结果:不适合与 @Transactional 搭配做数据库更新;更适合无事务或幂等且不涉及DB提交的调用(如外部HTTP、缓存写入等)。 假设是有状态重试(stateless: false) 重试通过把异常抛回给容器,让消息重新投递来实现。 每次投递 → 监听方法重新执行 → 新的事务开启。 每次失败都会完整回滚该次事务;下一次重试是干净的事务上下文。 达到最大次数后,按照你的配置reject(可配合死信队列/失败交换器),从而避免“消息风暴”。 !!!有状态重试相比RabbitMq的默认重试机制:可以配置有限次重试次数,更加灵活。 失败处理策略 只有在开启了消费者重试机制(即配置了 spring.rabbitmq.listener.simple.retry.enabled: true)时才会生效。 当消息消费重试达到最大次数后,默认会直接丢弃,这在要求高可靠性的场景中不可接受。Spring 提供了 MessageRecoverer接口来自定义最终处理策略,主要有三种实现: RejectAndDontRequeueRecoverer 默认策略。直接拒绝消息并丢弃。 ImmediateRequeueMessageRecoverer 让消息重新进入队列,再次被消费(可能导致循环)。 RepublishMessageRecoverer ✅ 推荐方案 将消息路由到一个专用的异常交换机,最终进入异常队列。 优势:实现故障隔离,便于后续人工干预或自动化修复,是保证消息不丢失的优雅方案。 业务幂等性 在程序开发中,幂等则是指同一个业务,执行一次或多次对业务状态的影响是一致的。如: 根据id删除数据 查询数据 新增数据 但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如: 取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况 退款业务。重复退款对商家而言会有经济损失。 所以,我们要尽可能避免业务被重复执行:MQ消息的重复投递、页面卡顿时频繁刷新导致表单重复提交、服务间调用的重试 法一:唯一ID 每一条消息都生成一个唯一的id,与消息一起投递给消费者。 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库。 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。 法一存在业务侵入,因为mq的消息ID与业务无关,现在却多了一张专门记录 ID 的表或结构 法二:业务判断,基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。 综上,支付服务与交易服务之间的订单状态一致性是如何保证的? 首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递的可靠性 最后,我们还在交易服务设置了定时任务,定期查询订单支付状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。 延迟消息 对于超过一定时间未支付的订单,应该立刻取消订单并释放占用的库存。 方案:利用延迟消息实现超时检查 以“订单支付超时时间为30分钟”为例,具体实现流程如下: 创建订单时:在订单入库的同时,向消息队列发送一条延迟时间为30分钟的消息。 消息等待:此消息不会立即被消费,而是由MQ服务器暂存至延迟时间到期。 延迟触发:30分钟后,消息队列自动将该消息投递给消费者服务。 执行检查与操作:消费者接收到消息后,查询该订单的当前支付状态: 若订单仍为“未支付”:则执行取消订单、释放库存等后续操作。 若订单已支付:则忽略此消息,流程结束。 实现延迟消息法一 延迟消息插件 1.下载 GitHub - rabbitmq/rabbitmq-delayed-message-exchange: Delayed Messaging for RabbitMQ 2.上传插件,由于之前docker部署MQ挂载了数据卷 docker volume ls #查看所有数据卷 docker volume inspect hmall_all_mq-plugins #获取数据卷的目录 #"Mountpoint": "/var/lib/docker/volumes/hmall_all_mq-plugins/_data" 我们上传插件到该目录下。 3.安装插件 docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange 声明延迟交换机 额外指定参数 delayed = "true" @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "delay.queue", durable = "true"), exchange = @Exchange(name = "delay.direct", delayed = "true"), key = "delay" )) public void listenDelayMessage(String msg){ log.info("接收到delay.queue的延迟消息:{}", msg); } 发送延迟消息 @Test void testPublisherDelayMessage() { // 1.创建消息 String message = "hello, delayed message"; // 2.发送消息,利用消息后置处理器添加消息头 rabbitTemplate.convertAndSend("delay.direct", "delay", message, new MessagePostProcessor() { @Override public Message postProcessMessage(Message message) throws AmqpException { // 添加延迟消息属性 message.getMessageProperties().setDelay(5000); return message; } }); } 实现延迟消息法二 RabbitMQ (TTL + 死信队列) 1.配置类(配置交换机和队列) 类型 名称 作用 路由键 交换机 order.exchange 业务交换机:接收原始延迟消息 order.delay.key 队列 order.delay.queue 等待队列:消息在此等待TTL过期 - 交换机 order.delay.exchange 死信交换机:接收过期消息 order.delay.key 队列 order.process.queue 处理队列:最终消费消息的队列 - @Configuration public class RabbitMQDelayConfig { // 业务交换机 @Bean public DirectExchange orderExchange() { return new DirectExchange("order.exchange"); } // 死信交换机(作为延迟消息的目标) @Bean public DirectExchange orderDelayExchange() { return new DirectExchange("order.delay.exchange"); } // 业务队列 - 设置死信参数 @Bean public Queue orderDelayQueue() { Map<String, Object> args = new HashMap<>(); // 消息到期后转发的死信交换机 args.put("x-dead-letter-exchange", "order.delay.exchange"); // 死信路由键 args.put("x-dead-letter-routing-key", "order.delay.key"); return new Queue("order.delay.queue", true, false, false, args); } // 最终消费队列 @Bean public Queue orderProcessQueue() { return new Queue("order.process.queue"); } // 绑定:业务队列 -> 业务交换机 @Bean public Binding orderDelayBinding() { return BindingBuilder.bind(orderDelayQueue()) .to(orderExchange()) .with("order.delay.key"); } // 绑定:最终队列 -> 死信交换机 @Bean public Binding orderProcessBinding() { return BindingBuilder.bind(orderProcessQueue()) .to(orderDelayExchange()) .with("order.delay.key"); } } 2. 发送消息(设置TTL) @Service @RequiredArgsConstructor public class OrderService { private final RabbitTemplate rabbitTemplate; public void createOrder(Order order) { // 创建订单逻辑... // 发送延迟消息(30分钟) rabbitTemplate.convertAndSend("order.exchange", "order.delay.key", order.getId(), message -> { // 设置消息的TTL为30分钟 message.getMessageProperties().setExpiration("1800000"); // 毫秒 return message; }); } } 3. 消费者 @Component public class OrderDelayConsumer { @RabbitListener(queues = "order.process.queue") public void processExpiredOrder(String orderId) { // 查询订单状态,如果未支付则取消订单 System.out.println("处理超时订单:" + orderId); } } 超时订单问题 死信交换机 当消息在一个队列中变成“死信(Dead Letter)”后,能被重新投递到的另一个交换机,就是死信交换机(DLX)。 绑定到 DLX 的队列叫死信队列(DLQ),专门用来存放这些“死信”消息。 触发条件 消费者拒绝并不再重投(Consumer Rejection) “消费者这一端”的情况。当消费者明确拒绝消息(发送 basic.reject或 basic.nack)并且设置 requeue=false时,消息会成为死信。 场景:消费者处理消息时遇到无法处理的错误(如业务逻辑错误、数据格式错误),明确告知MQ不要重新投递了。 消息过期(Message TTL Expired) 这与消费者无关。消息在队列中等待的时间超过了设定的生存时间(TTL),会被自动删除并变成死信。 场景:常用于实现延迟队列。例如,下单15分钟未支付订单取消,就可以将消息TTL设为15分钟,过期后成为死信转到DLQ,由DLQ的消费者来处理取消逻辑。 队列溢出(Queue Length Limit Exceeded) 这也与消费者无关。当队列的消息数量达到上限时,新来的消息或队列头部的消息(取决于配置)会被丢弃并变成死信。 场景:用于限制队列容量,防止消息无限堆积,保护系统。 配置 必须用编程式方式来声明,不可用注解式。 @Configuration public class RabbitMQConfig { @Value("${spring.rabbitmq.config.producer.exchange}") private String businessExchangeName; @Value("${spring.rabbitmq.config.producer.topic_team_success.queue}") private String businessQueueName; @Value("${spring.rabbitmq.config.producer.topic_team_success.routing_key}") private String businessRoutingKey; // 1. 定义死信交换机(通常一个应用一个就够了) @Bean public TopicExchange dlxExchange() { return new TopicExchange(businessExchangeName + ".dlx", true, false); } // 2. 定义死信队列 @Bean public Queue dlq() { return new Queue(businessQueueName + ".dlq", true); } // 3. 将死信队列绑定到死信交换机 @Bean public Binding dlqBinding() { return BindingBuilder.bind(dlq()) .to(dlxExchange()) .with(businessRoutingKey + ".dead"); // 使用新的路由键 } // 4. 定义业务交换机 @Bean public TopicExchange businessExchange() { return new TopicExchange(businessExchangeName, true, false); } // 5. 定义业务队列,并配置死信规则(核心!) @Bean public Queue businessQueue() { Map<String, Object> args = new HashMap<>(); // 指定死信交换机 args.put("x-dead-letter-exchange", businessExchangeName + ".dlx"); // 指定死信的路由键(可选,不指定则使用原消息的路由键) args.put("x-dead-letter-routing-key", businessRoutingKey + ".dead"); // 还可以设置其他导致消息成为死信的参数 // args.put("x-message-ttl", 60000); // 消息60秒过期 // args.put("x-max-length", 1000); // 队列最大长度1000条 return new Queue(businessQueueName, true, false, false, args); } // 6. 将业务队列绑定到业务交换机 @Bean public Binding businessBinding() { return BindingBuilder.bind(businessQueue()) .to(businessExchange()) .with(businessRoutingKey); } }
后端学习
zy123
1年前
0
27
0
2025-05-27
Jmeter快速入门
Jmeter快速入门 1.安装Jmeter Jmeter依赖于JDK,所以必须确保当前计算机上已经安装了JDK,并且配置了环境变量。 1.1.下载 可以Apache Jmeter官网下载,地址:http://jmeter.apache.org/download_jmeter.cgi 1.2.解压 因为下载的是zip包,解压缩即可使用,目录结构如下: 其中的bin目录就是执行的脚本,其中包含启动脚本: 1.3.运行 双击即可运行,但是有两点注意: 启动速度比较慢,要耐心等待 启动后黑窗口不能关闭,否则Jmeter也跟着关闭了 2.快速入门 2.1.设置中文语言 默认Jmeter的语言是英文,需要设置: 效果: 注意:上面的配置只能保证本次运行是中文,如果要永久中文,需要修改Jmeter的配置文件 打开jmeter文件夹,在bin目录中找到 jmeter.properties,添加下面配置: language=zh_CN 注意:前面不要出现#,#代表注释,另外这里是下划线,不是中划线 2.2.基本用法 在测试计划上点鼠标右键,选择添加 > 线程(用户) > 线程组: 在新增的线程组中,填写线程信息: 给线程组点鼠标右键,添加http取样器: 编写取样器内容: 添加HTTP Header Content-Type=application/json 添加监听报告: 添加监听结果树: 汇总报告结果: 结果树: 清理结果,一个个监听器清理 或者全部清理: 2.3.保存/导入执行计划 .jmx文件!!!
后端学习
zy123
1年前
0
8
0
2025-05-21
Mybatis&-Plus
Mybatis 快速创建 创建springboot工程(Spring Initializr),并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User 在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。 #驱动类名称 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #数据库连接的url spring.datasource.url=jdbc:mysql://localhost:3306/mybatis #连接数据库的用户名 spring.datasource.username=root #连接数据库的密码 spring.datasource.password=1234 在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper @Mapper注解:表示是mybatis中的Mapper接口 -程序运行时:框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理 @Select注解:代表的就是select查询,用于书写select查询语句 @Mapper public interface UserMapper { //查询所有用户数据 @Select("select * from user") public List<User> list(); } 数据库连接池 数据库连接池是一个容器,负责管理和分配数据库连接(Connection)。 在程序启动时,连接池会创建一定数量的数据库连接。 客户端在执行 SQL 时,从连接池获取连接对象,执行完 SQL 后,将连接归还给连接池,以供其他客户端复用。 如果连接对象长时间空闲且超过预设的最大空闲时间,连接池会自动释放该连接。 优势:避免频繁创建和销毁连接,提高数据库访问效率。 Druid(德鲁伊) Druid连接池是阿里巴巴开源的数据库连接池项目 功能强大,性能优秀,是Java语言最好的数据库连接池之一 把默认的 Hikari 数据库连接池切换为 Druid 数据库连接池: 在pom.xml文件中引入依赖 <dependency> <!-- Druid连接池依赖 --> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency> 在application.properties中引入数据库连接配置 spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.druid.username=root spring.datasource.druid.password=123456 SQL注入问题 SQL注入:由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。 在Mybatis中提供的参数占位符有两种:${...} 、#{...} #{...} 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值 使用时机:参数传递,都使用#{…} ${...} 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题 使用时机:如果对表名、列表进行动态设置时使用 日志输出 只建议开发环境使用:在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果 打开application.properties文件 开启mybatis的日志,并指定输出到控制台 #指定mybatis输出日志的位置, 输出控制台 mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl 驼峰命名法 在 Java 项目中,数据库表字段名一般使用 下划线命名法(snake_case),而 Java 中的变量名使用 驼峰命名法(camelCase)。 小驼峰命名(lowerCamelCase): 第一个单词的首字母小写,后续单词的首字母大写。 例子:firstName, userName, myVariable 大驼峰命名(UpperCamelCase): 每个单词的首字母都大写,通常用于类名或类型名。 例子:MyClass, EmployeeData, OrderDetails 表中查询的数据封装到实体类中 实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。 解决方法: 起别名 结果映射 开启驼峰命名 属性名和表中字段名保持一致 开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射 驼峰命名规则: abc_xyz => abcXyz 表中字段名:abc_xyz 类中属性名:abcXyz 推荐的完整配置: mybatis: #mapper配置文件 mapper-locations: classpath:mapper/*.xml type-aliases-package: com.sky.entity configuration: #开启驼峰命名 map-underscore-to-camel-case: true type-aliases-package: com.sky.entity把 com.sky.entity 包下的所有类都当作别名注册,XML 里就可以直接写 <resultType="Dish"> 而不用写全限定名。可以多添加几个包,用逗号隔开。 增删改 增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void! 作用于单个字段 @Mapper public interface EmpMapper { //SQL语句中的id值不能写成固定数值,需要变为动态的数值 //解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句 /** * 根据id删除数据 * @param id 用户id */ @Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值 public void delete(Integer id); } 上图参数值分离,有效防止SQL注入 作用于多个字段 @Mapper public interface EmpMapper { //会自动将生成的主键值,赋值给emp对象的id属性 @Options(useGeneratedKeys = true,keyProperty = "id") @Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})") public void insert(Emp emp); } 在 @Insert 注解中使用 #{} 来引用 Emp 对象的属性,MyBatis 会自动从 Emp 对象中提取相应的字段并绑定到 SQL 语句中的占位符。 @Options(useGeneratedKeys = true, keyProperty = "id") 这行配置表示,插入时自动生成的主键会赋值给 Emp 对象的 id 属性。 // 调用 mapper 执行插入操作 empMapper.insert(emp); // 现在 emp 对象的 id 属性会被自动设置为数据库生成的主键值 System.out.println("Generated ID: " + emp.getId()); 查 查询案例: 姓名:要求支持模糊匹配 性别:要求精确匹配 入职时间:要求进行范围查询 根据最后修改时间进行降序排序 重点在于模糊查询时where name like '%#{name}%' 会报错。 解决方案: 使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%') CONCAT() 如果其中任何一个参数为 NULL,CONCAT() 返回 NULL,Like NULL会导致查询不到任何结果! NULL和''是完全不同的 @Mapper public interface EmpMapper { @Select("select * from emp " + "where name like concat('%',#{name},'%') " + "and gender = #{gender} " + "and entrydate between #{begin} and #{end} " + "order by update_time desc") public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end); } XML配置文件规范 使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。 在Mybatis中使用XML映射文件方式开发,需要符合一定的规范: XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名) XML映射文件的namespace属性为Mapper接口全限定名一致 XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。 <select>标签:就是用于编写select查询语句的。 resultType属性,指的是查询返回的单条记录所封装的类型(查询必须)。 parameterType属性(可选,MyBatis 会根据接口方法的入参类型(比如 Dish 或 DishPageQueryDTO)自动推断),POJO作为入参,需要使用全类名或是type‑aliases‑package: com.sky.entity 下注册的别名。 <insert id="insert" useGeneratedKeys="true" keyProperty="id"> <select id="pageQuery" resultType="com.sky.vo.DishVO"> <select id="list" resultType="com.sky.entity.Dish" parameterType="com.sky.entity.Dish"> 实现过程: resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件 配置Mapper文件 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="edu.whut.mapper.EmpMapper"> <!-- SQL 查询语句写在这里 --> </mapper> namespace 属性指定了 Mapper 接口的全限定名(即包名 + 类名)。 编写查询语句 <select id="list" resultType="edu.whut.pojo.Emp"> select * from emp where name like concat('%',#{name},'%') and gender = #{gender} and entrydate between #{begin} and #{end} order by update_time desc </select> id="list":指定查询方法的名称,应该与 Mapper 接口中的方法名称一致。 resultType="edu.whut.pojo.Emp":resultType 只在 查询操作 中需要指定。指定查询结果映射的对象类型,这里是 Emp 类。 这里有bug!!! concat('%',#{name},'%')这里应该用<where> <if>标签对name是否为NULL或''进行判断 动态SQL SQL-if,where <if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。 <if test="条件表达式"> 要拼接的sql语句 </if> <where>只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,加了总比不加好 <select id="list" resultType="com.itheima.pojo.Emp"> select * from emp <where> <!-- if做为where标签的子元素 --> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> order by update_time desc </select> SQL-foreach Mapper 接口 @Mapper public interface EmpMapper { //批量删除 public void deleteByIds(List<Integer> ids); } XML 映射文件 <foreach> 标签用于遍历集合,常用于动态生成 SQL 语句中的 IN 子句、批量插入、批量更新等操作。 <foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符" open="遍历开始前拼接的片段" close="遍历结束后拼接的片段"> </foreach> open="(":这个属性表示,在生成的 SQL 语句开始时添加一个 左括号 (。 close=")":这个属性表示,在生成的 SQL 语句结束时添加一个 右括号 )。 例:批量删除实现 <delete id="deleteByIds"> DELETE FROM emp WHERE id IN <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete> 实现效果类似:DELETE FROM emp WHERE id IN (1, 2, 3); Mybatis-Plus MyBatis-Plus 的使命就是——在保留 MyBatis 灵活性的同时,大幅减少模板化、重复的代码编写,让增删改查、分页等常见场景“开箱即用”,以更少的配置、更少的样板文件、更高的开发效率,帮助团队快速交付高质量的数据库访问层。 快速开始 1.引入依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.3.1</version> </dependency> <!-- <dependency>--> <!-- <groupId>org.mybatis.spring.boot</groupId>--> <!-- <artifactId>mybatis-spring-boot-starter</artifactId>--> <!-- <version>2.3.1</version>--> <!-- </dependency>--> 由于这个starter包含对mybatis的自动装配,因此完全可以替换掉Mybatis的starter。 2.定义mapper 为了简化单表CRUD,MybatisPlus提供了一个基础的BaseMapper接口,其中已经实现了单表的CRUD(增删查改): 仅需让自定义的UserMapper接口,继承BaseMapper接口: public interface UserMapper extends BaseMapper<User> { } 测试: @SpringBootTest class UserMapperTest { @Autowired private UserMapper userMapper; @Test void testInsert() { User user = new User(); user.setId(5L); user.setUsername("Lucy"); user.setPassword("123"); user.setPhone("18688990011"); user.setBalance(200); user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}"); user.setCreateTime(LocalDateTime.now()); user.setUpdateTime(LocalDateTime.now()); userMapper.insert(user); } @Test void testSelectById() { User user = userMapper.selectById(5L); System.out.println("user = " + user); } @Test void testSelectByIds() { List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L, 5L)); users.forEach(System.out::println); } @Test void testUpdateById() { User user = new User(); user.setId(5L); user.setBalance(20000); userMapper.updateById(user); } @Test void testDelete() { userMapper.deleteById(5L); } } 3.常见注解 MybatisPlus如何知道我们要查询的是哪张表?表中有哪些字段呢? 约定大于配置 泛型中的User就是与数据库对应的PO. MybatisPlus就是根据PO实体的信息来推断出表的信息,从而生成SQL的。默认情况下: MybatisPlus会把PO实体的类名驼峰转下划线作为表名 UserRecord->user_record MybatisPlus会把PO实体的所有变量名驼峰转下划线作为表的字段名,并根据变量类型推断字段类型 MybatisPlus会把名为id的字段作为主键 但很多情况下,默认的实现与实际场景不符,因此MybatisPlus提供了一些注解便于我们声明表信息。 @TableName 描述:表名注解,标识实体类对应的表 @TableId 描述:主键注解,标识实体类中的主键字段 TableId注解支持两个属性: 属性 类型 必须指定 默认值 描述 value String 否 "" 主键字段名 type Enum 否 IdType.NONE 指定主键类型 @TableName("user_detail") public class User { @TableId(value="id_dd",type=IdType.AUTO) private Long id; private String name; } 这个例子会,映射到数据库中的user_detail表,主键为id_dd,并且插入时采用数据库自增;能自动回写主键,相当于开启useGeneratedKeys=true,执行完 insert(user) 后,user.getId() 就会是数据库分配的主键值,否则默认获得null,但不影响数据表中的内容。 type=dType.ASSIGN_ID 表示用雪花算法生成密码,更加复杂,而不是简单的AUTO自增。它也能自动回写主键。 @TableField 普通字段注解 一般情况下我们并不需要给字段添加@TableField注解,一些特殊情况除外: 成员变量名与数据库字段名不一致 成员变量是以isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。 public class User { private Long id; private String name; private Boolean isActive; // 按 JavaBean 习惯,这里用 isActive,数据表是is_acitive,但MybatisPlus会识别为active } 成员变量名与数据库一致,但是与数据库的**关键字(如order)**冲突。 public class Order { private Long id; private Integer order; // 名字和 SQL 关键字冲突 } 默认MP会生成:SELECT id, order FROM order; 导致报错 一些字段不希望被映射到数据表中,不希望进行增删查改 解决办法: @TableField("is_active") private Boolean isActive; @TableField("`order`") //添加转义字符 private Integer order; @TableField(exist=false) //exist默认是true, private String address; 4.常用配置 大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如: 实体类的别名扫描包 全局id类型 要改也就改这两个即可 mybatis-plus: type-aliases-package: edu.whut.mp.domain.po global-config: db-config: id-type: auto # 全局id类型为自增长 作用:1.把edu.whut.mp.domain.po 包下的所有 PO 类注册为 MyBatis 的 Type Alias。这样在你的 Mapper XML 里就可以直接写 <resultType="User">(或 <parameterType="User">)而不用写全限定类名 edu.whut.mp.domain.po.User 2.无需在每个 @TableId 上都写 type = IdType.AUTO,统一由全局配置管。 核心功能 前面的例子都是根据主键id更新、修改、查询,无法支持复杂条件where。 条件构造器Wrapper 除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持更加复杂的where条件。 Wrapper就是条件构造的抽象类,其下有很多默认实现,继承关系如图: QueryWrapper 在AbstractWrapper的基础上拓展了一个select方法,允许指定查询字段,无论是修改、删除、查询,都可以使用QueryWrapper来构建查询条件。 select方法只需用于 查询 时指定所需的列,完整查询不需要,用于update和delete不需要。 QueryWrapper 里对 like、eq、ge 等方法都做了重载 QueryWrapper<User> qw = new QueryWrapper<>(); qw.like("name", name); //两参版本,第一个参数对应数据库中的列名,如果对应不上,就会报错!!! qw.like(StrUtil.isNotBlank(name), "name", name); //三参,多一个boolean condition 参数 **例1:**查询出名字中带o的,存款大于等于1000元的人的id,username,info,balance: /** * SELECT id,username,info,balance * FROM user * WHERE username LIKE ? AND balance >=? */ @Test void testQueryWrapper(){ QueryWrapper<User> wrapper =new QueryWrapper<User>() .select("id","username","info","balance") .like("username","o") .ge("balance",1000); //查询 List<User> users=userMapper.selectList(wrapper); users.forEach(System.out::println); } UpdateWrapper 基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。 例1: 例如:更新id为1,2,4的用户的余额,扣200,对应的SQL应该是: UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4) @Test void testUpdateWrapper() { List<Long> ids = List.of(1L, 2L, 4L); // 1.生成SQL UpdateWrapper<User> wrapper = new UpdateWrapper<User>() .setSql("balance = balance - 200") // SET balance = balance - 200 .in("id", ids); // WHERE id in (1, 2, 4) // 2.更新,注意第一个参数可以给null,告诉 MP:不要从实体里取任何字段值 // 而是基于UpdateWrapper中的setSQL来更新 userMapper.update(null, wrapper); } 例2: // 用 UpdateWrapper 拼 WHERE + SET UpdateWrapper<User> wrapper = new UpdateWrapper<User>() // WHERE status = 'ACTIVE' .eq("status", "ACTIVE") // SET balance = 2000, name = 'Alice' .set("balance", 2000) .set("name", "Alice"); // 把 entity 参数传 null,MyBatis-Plus 会只用 wrapper 里的 set/where userMapper.update(null, wrapper); LambdaQueryWrapper(推荐) 是QueryWrapper和UpdateWrapper的上位选择!!! 传统的 QueryWrapper/UpdateWrapper 需要把数据库字段名写成字符串常量,既容易拼写出错,也无法在编译期校验。MyBatis-Plus 引入了两种基于 Lambda 的 Wrapper —— LambdaQueryWrapper 和 LambdaUpdateWrapper —— 通过传入实体类的 getter 方法引用,框架会自动解析并映射到对应的列,实现了类型安全和更高的可维护性。 // ——— 传统 QueryWrapper ——— public User findByUsername(String username) { QueryWrapper<User> qw = new QueryWrapper<>(); // 硬编码列名,拼写错了编译不过不了,会在运行时抛数据库异常 qw.eq("user_name", username); return userMapper.selectOne(qw); } // ——— LambdaQueryWrapper ——— public User findByUsername(String username) { // 内部已注入实体 Class 和元数据,方法引用自动解析列名 LambdaQueryWrapper<User> qw = Wrappers.lambdaQuery(User.class) .eq(User::getUserName, username); return userMapper.selectOne(qw); } 自定义sql 即自己编写Wrapper查询条件,再结合Mapper.xml编写SQL **例1:**以 UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4) 为例: 1)先在业务层利用wrapper创建条件,传递参数 @Test void testCustomWrapper() { // 1.准备自定义查询条件 List<Long> ids = List.of(1L, 2L, 4L); QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids); // 2.调用mapper的自定义方法,直接传递Wrapper userMapper.deductBalanceByIds(200, wrapper); } 2)自定义mapper层把wrapper和其他业务参数传进去,自定义sql语句书写sql的前半部分,后面拼接。 public interface UserMapper extends BaseMapper<User> { /** * 注意:更新要用 @Update * - #{money} 会被替换为方法第一个参数 200 * - ${ew.customSqlSegment} 会展开 wrapper 里的 WHERE 子句 */ @Update("UPDATE user " + "SET balance = balance - #{money} " + "${ew.customSqlSegment}") void deductBalanceByIds(@Param("money") int money, @Param("ew") QueryWrapper<User> wrapper); } @Param("ew")就是给这个方法参数在 MyBatis 的 SQL 映射里起一个别名—— ew , Mapper 的注解或 XML 里,MyBatis 想要拿到这个参数,就用它的 @Param 名称——也就是 ew: @Param("ew")中ew是 MP 约定的别名! ${ew.customSqlSegment} 可以自动拼接传入的条件语句 **例2:**查询出所有收货地址在北京的并且用户id在1、2、4之中的用户 普通mybatis: <select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User"> SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id WHERE u.id <foreach collection="ids" separator="," item="id" open="IN (" close=")"> #{id} </foreach> AND a.city = #{city} </select> mp方法: @Test void testCustomJoinWrapper() { // 1.准备自定义查询条件 QueryWrapper<User> wrapper = new QueryWrapper<User>() .in("u.id", List.of(1L, 2L, 4L)) .eq("a.city", "北京"); // 2.调用mapper的自定义方法 List<User> users = userMapper.queryUserByWrapper(wrapper); } @Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}") List<User> queryUserByWrapper(@Param("ew")QueryWrapper<User> wrapper); Service层的常用方法 查询: selectById:根据主键 ID 查询单条记录。 selectBatchIds:根据主键 ID 批量查询记录。 selectOne:根据指定条件查询单条记录。 @Service public class UserService { @Autowired private UserMapper userMapper; public User findByUsername(String username) { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("username", username); return userMapper.selectOne(queryWrapper); } } selectList:根据指定条件查询多条记录。 QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.ge("age", 18); List<User> users = userMapper.selectList(queryWrapper); 插入: insert:插入一条记录。 User user = new User(); user.setUsername("alice"); user.setAge(20); int rows = userMapper.insert(user); 更新 updateById:根据主键 ID 更新记录。 User user = new User(); user.setId(1L); user.setAge(25); int rows = userMapper.updateById(user); update:根据指定条件更新记录。 UpdateWrapper<User> updateWrapper = new UpdateWrapper<>(); updateWrapper.eq("username", "alice"); User user = new User(); user.setAge(30); int rows = userMapper.update(user, updateWrapper); 删除操作 deleteById:根据主键 ID 删除记录。 deleteBatchIds:根据主键 ID 批量删除记录。 delete:根据指定条件删除记录。 QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("username", "alice"); int rows = userMapper.delete(queryWrapper); IService 基本使用 由于Service中经常需要定义与业务有关的自定义方法,因此我们不能直接使用IService,而是自定义Service接口,然后继承IService以拓展方法。同时,让自定义的Service实现类继承ServiceImpl,这样就不用自己实现IService中的接口了。 首先,定义IUserService,继承IService: public interface IUserService extends IService<User> { // 拓展自定义方法 } 然后,编写UserServiceImpl类,继承ServiceImpl,实现UserService: @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { } Controller层中写: @RestController @RequestMapping("/users") @Slf4j @Api(tags = "用户管理接口") public class UserController { @Autowired private IUserService userService; @PostMapping @ApiOperation("新增用户接口") public void saveUser(@RequestBody UserFormDTO userFormDTO){ User user=new User(); BeanUtils.copyProperties(userFormDTO, user); userService.save(user); } @DeleteMapping("{id}") @ApiOperation("删除用户接口") public void deleteUserById(@PathVariable Long id){ userService.removeById(id); } @GetMapping("{id}") @ApiOperation("根据id查询接口") public UserVO queryUserById(@PathVariable Long id){ User user=userService.getById(id); UserVO userVO=new UserVO(); BeanUtils.copyProperties(user,userVO); return userVO; } @PutMapping("/{id}/deduction/{money}") @ApiOperation("根据id扣减余额") public void updateBalance(@PathVariable Long id,@PathVariable Long money){ userService.deductBalance(id,money); } } service层: @Service public class IUserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { @Autowired private UserMapper userMapper; @Override public void deductBalance(Long id, Long money) { //1.查询用户 User user=getById(id); if(user==null || user.getStatus()==2){ throw new RuntimeException("用户状态异常!"); } //2.查验余额 if(user.getBalance()<money){ throw new RuntimeException("用户余额不足!"); } //3.扣除余额 update User set balance=balance-money where id=id userMapper.deductBalance(id,money); } } mapper层: @Mapper public interface UserMapper extends BaseMapper<User> { @Update("update user set balance=balance-#{money} where id=#{id}") void deductBalance(Long id, Long money); } 总结:如果是简单查询,如用id来查询、删除,可以直接在Controller层用Iservice方法,否则自定义业务层Service实现具体任务。 Service层的lambdaQuery IService中还提供了Lambda功能来简化我们的复杂查询及更新功能。 相当于「条件构造」和「执行方法」写在一起 this.lambdaQuery() = LambdaQueryWrapper + 内置的执行方法(如 .list()、.one()) 特性 lambdaQuery() lambdaUpdate() 主要用途 构造查询条件,执行 SELECT 操作 构造更新条件,执行 UPDATE(或逻辑删除)操作 支持的方法 .eq(), .like(), .gt(), .orderBy(), .select() 等 .eq(), .lt(), .set(), .setSql() 等 执行方法 .list(), .one(), .page() 等 .update(), .remove()(逻辑删除 **案例一:**实现一个根据复杂条件查询用户的接口,查询条件如下: name:用户名关键字,可以为空 status:用户状态,可以为空 minBalance:最小余额,可以为空 maxBalance:最大余额,可以为空 @GetMapping("/list") @ApiOperation("根据id集合查询用户") public List<UserVO> queryUsers(UserQuery query){ // 1.组织条件 String username = query.getName(); Integer status = query.getStatus(); Integer minBalance = query.getMinBalance(); Integer maxBalance = query.getMaxBalance(); // 2.查询用户 List<User> users = userService.lambdaQuery() .like(username != null, User::getUsername, username) .eq(status != null, User::getStatus, status) .ge(minBalance != null, User::getBalance, minBalance) .le(maxBalance != null, User::getBalance, maxBalance) .list(); // 3.处理vo return BeanUtil.copyToList(users, UserVO.class); } .eq(status != null, User::getStatus, status),使用User::getStatus方法引用并不直接把'Status'插入到 SQL,而是在运行时会被 MyBatis-Plus 解析成实体属性 Status”对应的数据库列是 status。推荐!!! 可以发现lambdaQuery方法中除了可以构建条件,还需要在链式编程的最后添加一个list(),这是在告诉MP我们的调用结果需要是一个list集合。这里不仅可以用list(),可选的方法有: .one():最多1个结果 .list():返回集合结果 .count():返回计数结果 MybatisPlus会根据链式编程的最后一个方法来判断最终的返回结果。 这里不够规范,业务写在controller层中了。 **案例二:**改造根据id修改用户余额的接口,如果扣减后余额为0,则将用户status修改为冻结状态(2) @Override @Transactional public void deductBalance(Long id, Integer money) { // 1.查询用户 User user = getById(id); // 2.校验用户状态 if (user == null || user.getStatus() == 2) { throw new RuntimeException("用户状态异常!"); } // 3.校验余额是否充足 if (user.getBalance() < money) { throw new RuntimeException("用户余额不足!"); } // 4.扣减余额 update tb_user set balance = balance - ? int remainBalance = user.getBalance() - money; lambdaUpdate() .set(User::getBalance, remainBalance) // 更新余额 .set(remainBalance == 0, User::getStatus, 2) // 动态判断,是否更新status .eq(User::getId, id) .eq(User::getBalance, user.getBalance()) // 乐观锁 .update(); } 批量新增 每 batchSize 条记录作为一个 JDBC batch 提交一次(1000 条就一次) @Test void testSaveBatch() { // 准备10万条数据 List<User> list = new ArrayList<>(1000); long b = System.currentTimeMillis(); for (int i = 1; i <= 100000; i++) { list.add(buildUser(i)); // 每1000条批量插入一次 if (i % 1000 == 0) { userService.saveBatch(list); list.clear(); } } long e = System.currentTimeMillis(); System.out.println("耗时:" + (e - b)); } 之所以把 100 000 条记录分成每 1 000 条一批来插,是为了兼顾 性能、内存 和 数据库/JDBC 限制。 JDBC 或数据库参数限制 很多数据库(MySQL、Oracle 等)对单条 SQL 里 VALUES 列表的长度有上限,一次性插入几十万行可能导致 SQL 过长、参数个数过多,被驱动或数据库拒绝。 即使驱动不直接报错,也可能因为网络包(packet)过大而失败。 内存占用和 GC 压力 JDBC 在执行 batch 时,会把所有要执行的 SQL 和参数暂存在客户端内存里。如果一次性缓存 100 000 条记录的参数(可能是几 MB 甚至十几 MB),容易触发 OOM 或者频繁 GC。 事务日志和回滚压力 一次性插入大量数据,数据库需要在事务日志里记录相应条目,回滚时也要一次性回滚所有操作,性能开销巨大。分批能让每次写入都较为“轻量”,回滚范围也更小。 这种本质上是多条单行 INSERT Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? ) Parameters: user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01 Parameters: user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01 Parameters: user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01 而如果想要得到最佳性能,最好是将多条SQL合并为一条,像这样: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES (user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01), (user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01), (user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01), (user_4, 123, 18688190004, "", 2000, 2023-07-01, 2023-07-01); 需要修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true: url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true 但是会存在上述上事务的问题!!! MQ分页 快速入门 1)引入依赖 <!-- 数据库操作:https://mp.baomidou.com/ --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.9</version> </dependency> <!-- MyBatis Plus 分页插件 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-jsqlparser-4.9</artifactId> </dependency> 2)定义通用分页查询条件实体 @Data @ApiModel(description = "分页查询实体") public class PageQuery { @ApiModelProperty("页码") private Long pageNo; @ApiModelProperty("页码") private Long pageSize; @ApiModelProperty("排序字段") private String sortBy; @ApiModelProperty("是否升序") private Boolean isAsc; } 3)新建一个 UserQuery 类,让它继承自你已有的 PageQuery @Data @ApiModel(description = "用户分页查询实体") public class UserQuery extends PageQuery { @ApiModelProperty("用户名(模糊查询)") private String name; } 4)Service里使用 @Service public class UserService extends ServiceImpl<UserMapper, User> { /** * 用户分页查询(带用户名模糊 + 动态排序) * * @param query 包含 pageNo、pageSize、sortBy、isAsc、name 等字段 */ public Page<User> pageByQuery(UserQuery query) { // 1. 构造 Page 对象 Page<User> page = new Page<>( query.getPageNo(), query.getPageSize() ); // 2. 构造查询条件 LambdaQueryWrapper<User> qw = Wrappers.<User>lambdaQuery() // 当 name 非空时,加上 user_name LIKE '%name%' .like(StrUtil.isNotBlank(query.getName()), User::getUserName, query.getName()); // 3. 动态排序 if (StrUtil.isNotBlank(query.getSortBy())) { String column = StrUtil.toUnderlineCase(query.getSortBy()); boolean asc = Boolean.TRUE.equals(query.getIsAsc()); qw.last("ORDER BY " + column + (asc ? " ASC" : " DESC")); } // 4. 执行分页查询 return this.page(page, qw); } }
后端学习
zy123
1年前
0
21
0
上一页
1
...
3
4
5
...
12
下一页