首页
关于
Search
1
同步本地Markdown至Typecho站点
146 阅读
2
微服务
47 阅读
3
苍穹外卖
43 阅读
4
动态图神经网络
40 阅读
5
JavaWeb——后端
36 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
找到
16
篇与
后端学习
相关的结果
2025-07-31
测试
测试 小明今天15岁了,它是天水小学上学。
后端学习
zy123
1年前
0
7
0
2025-07-05
Mybatis&-Plus
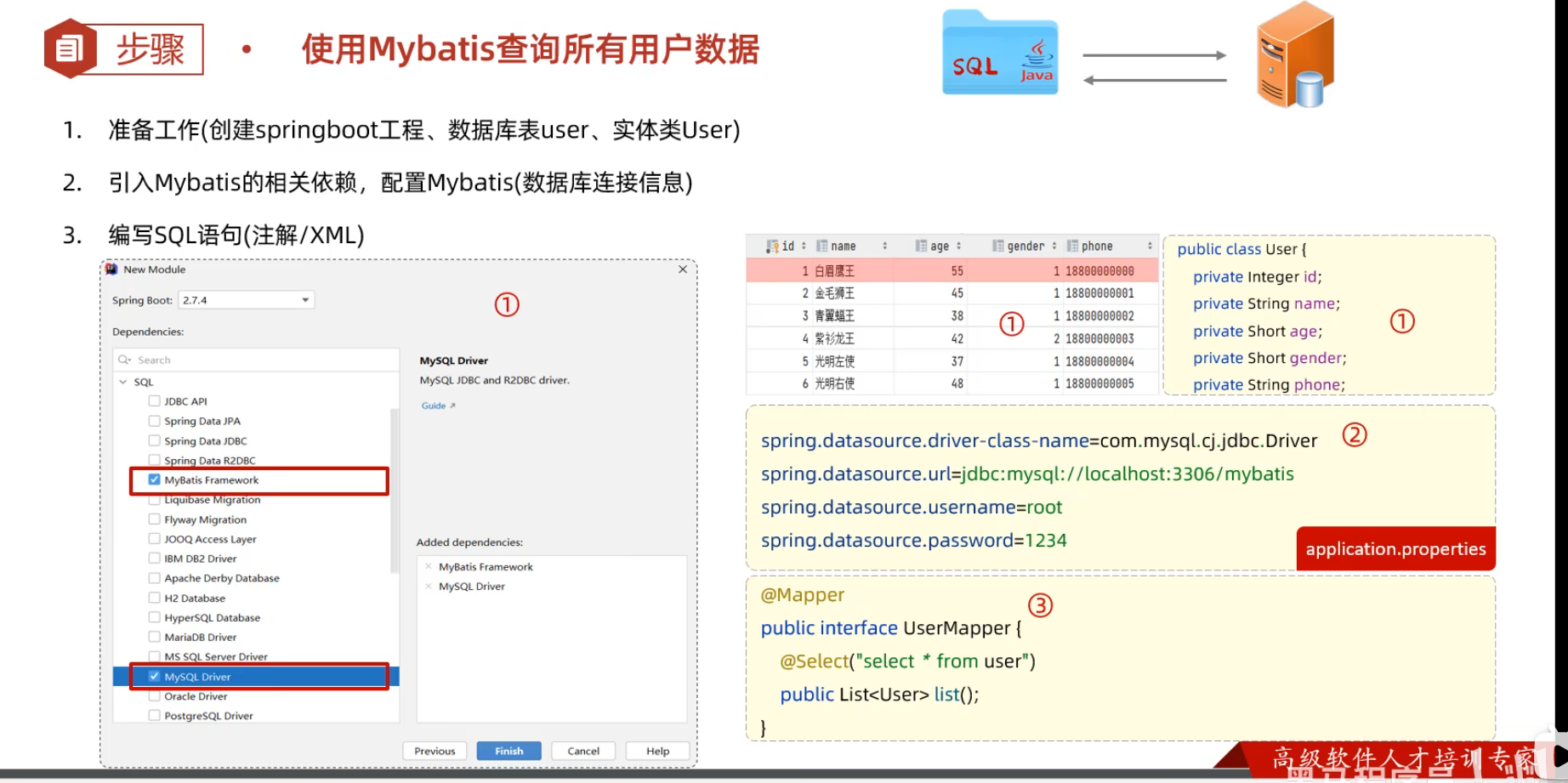
Mybatis 快速创建 创建springboot工程(Spring Initializr),并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User 在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。 #驱动类名称 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #数据库连接的url spring.datasource.url=jdbc:mysql://localhost:3306/mybatis #连接数据库的用户名 spring.datasource.username=root #连接数据库的密码 spring.datasource.password=1234 在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper @Mapper注解:表示是mybatis中的Mapper接口 -程序运行时:框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理 @Select注解:代表的就是select查询,用于书写select查询语句 @Mapper public interface UserMapper { //查询所有用户数据 @Select("select * from user") public List<User> list(); } 数据库连接池 数据库连接池是一个容器,负责管理和分配数据库连接(Connection)。 在程序启动时,连接池会创建一定数量的数据库连接。 客户端在执行 SQL 时,从连接池获取连接对象,执行完 SQL 后,将连接归还给连接池,以供其他客户端复用。 如果连接对象长时间空闲且超过预设的最大空闲时间,连接池会自动释放该连接。 优势:避免频繁创建和销毁连接,提高数据库访问效率。 Druid(德鲁伊) Druid连接池是阿里巴巴开源的数据库连接池项目 功能强大,性能优秀,是Java语言最好的数据库连接池之一 把默认的 Hikari 数据库连接池切换为 Druid 数据库连接池: 在pom.xml文件中引入依赖 <dependency> <!-- Druid连接池依赖 --> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency> 在application.properties中引入数据库连接配置 spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.druid.username=root spring.datasource.druid.password=123456 SQL注入问题$和# SQL注入:由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。 在Mybatis中提供的参数占位符有两种:${...} 、#{...} #{...} 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值 使用时机:参数传递,都使用#{…} ${...} 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题 使用时机:如果对表名、列表进行动态设置时使用 <select id="selectFromDynamicTable" resultType="User"> SELECT * FROM ${tableName} WHERE id = #{id} </select> userMapper.selectFromDynamicTable("user_2025", 1); 驼峰命名法 在 Java 项目中,数据库表字段名一般使用 下划线命名法(snake_case),而 Java 中的变量名使用 驼峰命名法(camelCase)。 小驼峰命名(lowerCamelCase): 第一个单词的首字母小写,后续单词的首字母大写。 例子:firstName, userName, myVariable 大驼峰命名(UpperCamelCase): 每个单词的首字母都大写,通常用于类名或类型名。 例子:MyClass, EmployeeData, OrderDetails 表中查询的数据封装到实体类中 实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。 解决方法: 起别名 结果映射 开启驼峰命名 属性名和表中字段名保持一致 开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射 驼峰命名规则: abc_xyz => abcXyz 表中字段名:abc_xyz 类中属性名:abcXyz 增删改 增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void! 作用于单个字段 @Mapper public interface EmpMapper { //SQL语句中的id值不能写成固定数值,需要变为动态的数值 //解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句 /** * 根据id删除数据 * @param id 用户id */ @Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值 public void delete(Integer id); } 上图参数值分离,有效防止SQL注入 作用于多个字段 @Mapper public interface EmpMapper { //会自动将生成的主键值,赋值给emp对象的id属性 @Options(useGeneratedKeys = true,keyProperty = "id") @Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})") public void insert(Emp emp); } 在 @Insert 注解中使用 #{} 来引用 Emp 对象的属性,MyBatis 会自动从 Emp 对象中提取相应的字段并绑定到 SQL 语句中的占位符。 @Options(useGeneratedKeys = true, keyProperty = "id") 这行配置表示,插入时自动生成的主键会赋值给 Emp 对象的 id 属性。 // 调用 mapper 执行插入操作 empMapper.insert(emp); // 现在 emp 对象的 id 属性会被自动设置为数据库生成的主键值 System.out.println("Generated ID: " + emp.getId()); 查 查询案例: 姓名:要求支持模糊匹配 性别:要求精确匹配 入职时间:要求进行范围查询 根据最后修改时间进行降序排序 重点在于模糊查询时where name like '%#{name}%' 会报错。 为什么? where name like '%#{name}%' MyBatis 会先解析 #{name},并用 ? 替换: where name like '%?%' 于是 SQL 就变成了一个 非法语法,数据库执行时会报错。 解决方案: 使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%') CONCAT() 如果其中任何一个参数为 NULL,CONCAT() 返回 NULL,Like NULL会导致查询不到任何结果! NULL和''是完全不同的 当 #{name} = '张三' → 结果是 '%张三%',能正常匹配。 当 #{name} = ''(空字符串) → 结果是 '%%',等价于 %,会匹配所有字符串。 当 #{name} = NULL → 结果是 NULL,SQL 变成: @Mapper public interface EmpMapper { @Select("select * from emp " + "where name like concat('%',#{name},'%') " + "and gender = #{gender} " + "and entrydate between #{begin} and #{end} " + "order by update_time desc") public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end); } 为了避免无意义查询,如果name == null或name=='' 就不要拼接like 条件,后面动态SQL会做优化。 XML配置文件规范 使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。 在Mybatis中使用XML映射文件方式开发,需要符合一定的规范: XML映射文件的namespace属性为Mapper接口全限定名一致 XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。 XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(非必须) <select>标签:就是用于编写select查询语句的。 resultType属性,指的是查询返回的单条记录所封装的类型(查询必须)。 parameterType属性(可选,MyBatis 会根据接口方法的入参类型(比如 Dish 或 DishPageQueryDTO)自动推断),POJO作为入参,需要使用全类名或是type‑aliases‑package: com.sky.entity 下注册的别名。 <insert id="insert" useGeneratedKeys="true" keyProperty="id"> <select id="pageQuery" resultType="com.sky.vo.DishVO"> <select id="list" resultType="com.sky.entity.Dish" parameterType="com.sky.entity.Dish"> 实现过程: resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件 配置Mapper文件 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="edu.whut.mapper.EmpMapper"> <!-- SQL 查询语句写在这里 --> </mapper> namespace 属性指定了 Mapper 接口的全限定名(即包名 + 类名)。 编写查询语句 <select id="findByName" parameterType="String" resultType="edu.whut.pojo.Emp"> SELECT id, name, gender, entrydate, update_time FROM emp WHERE name = #{name} </select> id="list":指定查询方法的名称,应该与 Mapper 接口中的方法名称一致。 resultType="edu.whut.pojo.Emp":resultType 只在 查询操作 中需要指定。指定查询结果映射的对象类型,这里是 Emp 类。 推荐的完整配置 mybatis: #mapper配置文件 mapper-locations: classpath:mapper/*.xml type-aliases-package: com.sky.entity configuration: #开启驼峰命名 map-underscore-to-camel-case: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl type-aliases-package: com.sky.entity把 com.sky.entity 包下的所有类都当作别名注册,XML 里就可以直接写 <resultType="Dish"> 而不用写全限定名。可以多添加几个包,用逗号隔开。 log-impl:org.apache.ibatis.logging.stdout.StdOutImpl只建议开发环境使用:在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果 map-underscore-to-camel-case: true 如果都是简单字段,开启之后XML 中不用写 <resultMap>: <resultMap id="dataMap" type="edu.whut.infrastructure.dao.po.PayOrder"> <id column="id" property="id"/> <result column="user_id" property="userId"/> <result column="product_id" property="productId"/> <result column="product_name" property="productName"/> </resultMap> 动态SQL SQL-if,where <if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。 <if test="条件表达式"> 要拼接的sql语句 </if> <where>只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,加了总比不加好 <select id="list" resultType="com.itheima.pojo.Emp"> select * from emp <where> <!-- if做为where标签的子元素 --> <if test="name != null"> and name like concat('%',#{name},'%') </if> <if test="gender != null"> and gender = #{gender} </if> <if test="begin != null and end != null"> and entrydate between #{begin} and #{end} </if> </where> order by update_time desc </select> 不加判空条件时 如果 name == null,大多数数据库里 CONCAT('%', NULL, '%') 会返回 NULL,于是条件变成了 WHERE name LIKE NULL ,不会匹配任何行。 如果 name == ""(空串),CONCAT('%','', '%') 得到 "%%",name LIKE '%%' 对所有非null name 都成立,相当于“不过滤”这段条件,不影响结果,因此可以不判断空串。 加了判空 <if> 之后 <where> <if test="name != null and name != ''"> AND name LIKE CONCAT('%', #{name}, '%') </if> <!-- 其它条件类似 --> </where> 当 name 为 null 或 "" 时,这段 <if> 块不会被拼到最终的 SQL 里,等价于忽略了 name 这个过滤条件。 SQL-foreach Mapper 接口 @Mapper public interface EmpMapper { //批量删除 public void deleteByIds(@Param("ids") List<Integer> ids); } XML 映射文件 <foreach> 标签用于遍历集合,常用于动态生成 SQL 语句中的 IN 子句、批量插入、批量更新等操作。 <foreach collection="集合参数名" item="当前遍历项" index="当前索引(可选)" separator="每次遍历间的分隔符" open="遍历开始前拼接的片段" close="遍历结束后拼接的片段"> #{item} </foreach> open="(":这个属性表示,在生成的 SQL 语句开始时添加一个 左括号 (。 close=")":这个属性表示,在生成的 SQL 语句结束时添加一个 右括号 )。 例:批量删除实现 <delete id="deleteByIds"> DELETE FROM emp WHERE id IN <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete> int deleteByIds(@Param("ids") List<Long> ids); #{id} 代表集合里的一个元素。item 里定义的是什么,就要在 #{} 里用相同的名字。 这里一定要加 @Param("ids"),这样 MyBatis 才知道这个集合对应 XML 里的 collection="ids"。 实现效果类似:DELETE FROM emp WHERE id IN (1, 2, 3); Mybatis-Plus MyBatis-Plus 的使命就是——在保留 MyBatis 灵活性的同时,大幅减少模板化、重复的代码编写,让增删改查、分页等常见场景“开箱即用”,以更少的配置、更少的样板文件、更高的开发效率,帮助团队快速交付高质量的数据库访问层。 快速开始 1.引入依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.3.1</version> </dependency> <!-- <dependency>--> <!-- <groupId>org.mybatis.spring.boot</groupId>--> <!-- <artifactId>mybatis-spring-boot-starter</artifactId>--> <!-- <version>2.3.1</version>--> <!-- </dependency>--> 由于这个starter包含对mybatis的自动装配,因此完全可以替换掉Mybatis的starter。 2.定义mapper 为了简化单表CRUD,MybatisPlus提供了一个基础的BaseMapper接口,其中已经实现了单表的CRUD(增删查改): 仅需让自定义的UserMapper接口,继承BaseMapper接口: public interface UserMapper extends BaseMapper<User> { } 测试: @SpringBootTest class UserMapperTest { @Autowired private UserMapper userMapper; @Test void testInsert() { User user = new User(); user.setId(5L); user.setUsername("Lucy"); user.setPassword("123"); user.setPhone("18688990011"); user.setBalance(200); user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}"); user.setCreateTime(LocalDateTime.now()); user.setUpdateTime(LocalDateTime.now()); userMapper.insert(user); } @Test void testSelectById() { User user = userMapper.selectById(5L); System.out.println("user = " + user); } @Test void testSelectByIds() { List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L, 5L)); users.forEach(System.out::println); } @Test void testUpdateById() { User user = new User(); user.setId(5L); user.setBalance(20000); userMapper.updateById(user); } @Test void testDelete() { userMapper.deleteById(5L); } } 3.常见注解 MybatisPlus如何知道我们要查询的是哪张表?表中有哪些字段呢? 约定大于配置 泛型中的User就是与数据库对应的PO. MybatisPlus就是根据PO实体的信息来推断出表的信息,从而生成SQL的。默认情况下: MybatisPlus会把PO实体的类名驼峰转下划线作为表名 UserRecord->user_record MybatisPlus会把PO实体的所有变量名驼峰转下划线作为表的字段名,并根据变量类型推断字段类型 MybatisPlus会把名为id的字段作为主键 但很多情况下,默认的实现与实际场景不符,因此MybatisPlus提供了一些注解便于我们声明表信息。 @TableName 描述:表名注解,标识实体类对应的表 @TableId 描述:主键注解,标识实体类中的主键字段 TableId注解支持两个属性: 属性 类型 必须指定 默认值 描述 value String 否 "" 主键字段名 type Enum 否 IdType.NONE 指定主键类型 @TableName("user_detail") public class User { @TableId(value="id_dd",type=IdType.AUTO) private Long id; private String name; } 这个例子会,映射到数据库中的user_detail表,主键为id_dd,并且插入时采用数据库自增;能自动回写主键,相当于开启useGeneratedKeys=true,执行完 insert(user) 后,user.getId() 就会是数据库分配的主键值,否则默认获得null,但不影响数据表中的内容。 type=dType.ASSIGN_ID 表示用雪花算法生成密码,更加复杂,而不是简单的AUTO自增。它也能自动回写主键。 @TableField 普通字段注解 一般情况下我们并不需要给字段添加@TableField注解,一些特殊情况除外: 成员变量名与数据库字段名不一致 成员变量是以isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。 public class User { private Long id; private String name; private Boolean isActive; // 按 JavaBean 习惯,这里用 isActive,数据表是is_acitive,但MybatisPlus会识别为active } 成员变量名与数据库一致,但是与数据库的**关键字(如order)**冲突。 public class Order { private Long id; private Integer order; // 名字和 SQL 关键字冲突 } 默认MP会生成:SELECT id, order FROM order; 导致报错 一些字段不希望被映射到数据表中,不希望进行增删查改 解决办法: @TableField("is_active") private Boolean isActive; @TableField("`order`") //添加转义字符 private Integer order; @TableField(exist=false) //exist默认是true, private String address; 4.常用配置 大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如: 实体类的别名扫描包 全局id类型 要改也就改这两个即可 mybatis-plus: type-aliases-package: edu.whut.mp.domain.po global-config: db-config: id-type: auto # 全局id类型为自增长 作用:1.把edu.whut.mp.domain.po 包下的所有 PO 类注册为 MyBatis 的 Type Alias。这样在你的 Mapper XML 里就可以直接写 <resultType="User">(或 <parameterType="User">)而不用写全限定类名 edu.whut.mp.domain.po.User 2.无需在每个 @TableId 上都写 type = IdType.AUTO,统一由全局配置管。 核心功能 前面的例子都是根据主键id更新、修改、查询,无法支持复杂条件where。 条件构造器Wrapper 除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持更加复杂的where条件。 Wrapper就是条件构造的抽象类,其下有很多默认实现,继承关系如图: QueryWrapper 在AbstractWrapper的基础上拓展了一个select方法,允许指定查询字段,无论是修改、删除、查询,都可以使用QueryWrapper来构建查询条件。 select方法只需用于 查询 时指定所需的列,完整查询不需要,用于update和delete不需要。 QueryWrapper 里对 like、eq、ge 等方法都做了重载 QueryWrapper<User> qw = new QueryWrapper<>(); qw.like("name", name); //两参版本,第一个参数对应数据库中的列名,如果对应不上,就会报错!!! qw.like(StrUtil.isNotBlank(name), "name", name); //三参,多一个boolean condition 参数 **例1:**查询出名字中带o的,存款大于等于1000元的人的id,username,info,balance: /** * SELECT id,username,info,balance * FROM user * WHERE username LIKE ? AND balance >=? */ @Test void testQueryWrapper(){ QueryWrapper<User> wrapper =new QueryWrapper<User>() .select("id","username","info","balance") .like("username","o") .ge("balance",1000); //查询 List<User> users=userMapper.selectList(wrapper); users.forEach(System.out::println); } UpdateWrapper 基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。 例1: 例如:更新id为1,2,4的用户的余额,扣200,对应的SQL应该是: UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4) @Test void testUpdateWrapper() { List<Long> ids = List.of(1L, 2L, 4L); // 1.生成SQL UpdateWrapper<User> wrapper = new UpdateWrapper<User>() .setSql("balance = balance - 200") // SET balance = balance - 200 .in("id", ids); // WHERE id in (1, 2, 4) // 2.更新,注意第一个参数可以给null,告诉 MP:不要从实体里取任何字段值 // 而是基于UpdateWrapper中的setSQL来更新 userMapper.update(null, wrapper); } 例2: // 用 UpdateWrapper 拼 WHERE + SET UpdateWrapper<User> wrapper = new UpdateWrapper<User>() // WHERE status = 'ACTIVE' .eq("status", "ACTIVE") // SET balance = 2000, name = 'Alice' .set("balance", 2000) .set("name", "Alice"); // 把 entity 参数传 null,MyBatis-Plus 会只用 wrapper 里的 set/where userMapper.update(null, wrapper); LambdaQueryWrapper(推荐) 是QueryWrapper和UpdateWrapper的上位选择!!! 传统的 QueryWrapper/UpdateWrapper 需要把数据库字段名写成字符串常量,既容易拼写出错,也无法在编译期校验。MyBatis-Plus 引入了两种基于 Lambda 的 Wrapper —— LambdaQueryWrapper 和 LambdaUpdateWrapper —— 通过传入实体类的 getter 方法引用,框架会自动解析并映射到对应的列,实现了类型安全和更高的可维护性。 // ——— 传统 QueryWrapper ——— public User findByUsername(String username) { QueryWrapper<User> qw = new QueryWrapper<>(); // 硬编码列名,拼写错了编译不过不了,会在运行时抛数据库异常 qw.eq("user_name", username); return userMapper.selectOne(qw); } // ——— LambdaQueryWrapper ——— public User findByUsername(String username) { // 内部已注入实体 Class 和元数据,方法引用自动解析列名 LambdaQueryWrapper<User> qw = Wrappers.lambdaQuery(User.class) .eq(User::getUserName, username); return userMapper.selectOne(qw); } 自定义sql 即自己编写Wrapper查询条件,再结合Mapper.xml编写SQL **例1:**以 UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4) 为例: 1)先在业务层利用wrapper创建条件,传递参数 @Test void testCustomWrapper() { // 1.准备自定义查询条件 List<Long> ids = List.of(1L, 2L, 4L); QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids); // 2.调用mapper的自定义方法,直接传递Wrapper userMapper.deductBalanceByIds(200, wrapper); } 2)自定义mapper层把wrapper和其他业务参数传进去,自定义sql语句书写sql的前半部分,后面拼接。 public interface UserMapper extends BaseMapper<User> { /** * 注意:更新要用 @Update * - #{money} 会被替换为方法第一个参数 200 * - ${ew.customSqlSegment} 会展开 wrapper 里的 WHERE 子句 */ @Update("UPDATE user " + "SET balance = balance - #{money} " + "${ew.customSqlSegment}") void deductBalanceByIds(@Param("money") int money, @Param("ew") QueryWrapper<User> wrapper); } @Param("ew")就是给这个方法参数在 MyBatis 的 SQL 映射里起一个别名—— ew , Mapper 的注解或 XML 里,MyBatis 想要拿到这个参数,就用它的 @Param 名称——也就是 ew: @Param("ew")中ew是 MP 约定的别名! ${ew.customSqlSegment} 可以自动拼接传入的条件语句 **例2:**查询出所有收货地址在北京的并且用户id在1、2、4之中的用户 普通mybatis: <select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User"> SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id WHERE u.id <foreach collection="ids" separator="," item="id" open="IN (" close=")"> #{id} </foreach> AND a.city = #{city} </select> mp方法: @Test void testCustomJoinWrapper() { // 1.准备自定义查询条件 QueryWrapper<User> wrapper = new QueryWrapper<User>() .in("u.id", List.of(1L, 2L, 4L)) .eq("a.city", "北京"); // 2.调用mapper的自定义方法 List<User> users = userMapper.queryUserByWrapper(wrapper); } @Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}") List<User> queryUserByWrapper(@Param("ew")QueryWrapper<User> wrapper); Service层的常用方法 查询: selectById:根据主键 ID 查询单条记录。 selectBatchIds:根据主键 ID集合 批量查询记录。 selectOne:根据指定条件查询单条记录。 @Service public class UserService { @Autowired private UserMapper userMapper; public User findByUsername(String username) { // 查询 ID 为 1, 2, 3 的用户 List<Long> ids = Arrays.asList(1L, 2L, 3L); List<User> users = userMapper.selectBatchIds(ids); --------------分割线------------- QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("username", username); return userMapper.selectOne(queryWrapper); } } selectList:根据指定条件查询多条记录。 QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.ge("age", 18); List<User> users = userMapper.selectList(queryWrapper); 插入: insert:插入一条记录。 User user = new User(); user.setUsername("alice"); user.setAge(20); int rows = userMapper.insert(user); 更新 updateById:根据主键 ID 更新记录。 User user = new User(); user.setId(1L); user.setAge(25); int rows = userMapper.updateById(user); update:根据指定条件更新记录。 UpdateWrapper<User> updateWrapper = new UpdateWrapper<>(); updateWrapper.eq("username", "alice"); User user = new User(); user.setAge(30); int rows = userMapper.update(user, updateWrapper); 删除操作 类似query deleteById:根据主键 ID 删除记录。 deleteBatchIds:根据主键 ID集合 批量删除记录。 delete:根据指定条件删除记录。 QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("username", "alice"); int rows = userMapper.delete(queryWrapper); IService 基本使用 由于Service中经常需要定义与业务有关的自定义方法,因此我们不能直接使用IService,而是自定义Service接口,然后继承IService以拓展方法。同时,让自定义的Service实现类继承ServiceImpl,这样就不用自己实现IService中的接口了。 首先,定义IUserService,继承IService: public interface IUserService extends IService<User> { // 拓展自定义方法 } 然后,编写UserServiceImpl类,继承ServiceImpl(通用实现类),实现UserService: @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { } Controller层中写: @RestController @RequestMapping("/users") @Slf4j @Api(tags = "用户管理接口") public class UserController { @Autowired private IUserService userService; @PostMapping @ApiOperation("新增用户接口") public void saveUser(@RequestBody UserFormDTO userFormDTO){ User user=new User(); BeanUtils.copyProperties(userFormDTO, user); userService.save(user); } @DeleteMapping("{id}") @ApiOperation("删除用户接口") public void deleteUserById(@PathVariable Long id){ userService.removeById(id); } @GetMapping("{id}") @ApiOperation("根据id查询接口") public UserVO queryUserById(@PathVariable Long id){ User user=userService.getById(id); UserVO userVO=new UserVO(); BeanUtils.copyProperties(user,userVO); return userVO; } @PutMapping("/{id}/deduction/{money}") @ApiOperation("根据id扣减余额") public void updateBalance(@PathVariable Long id,@PathVariable Long money){ userService.deductBalance(id,money); } } service层: @Service public class IUserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { @Autowired private UserMapper userMapper; @Override public void deductBalance(Long id, Long money) { //1.查询用户 User user=getById(id); if(user==null || user.getStatus()==2){ throw new RuntimeException("用户状态异常!"); } //2.查验余额 if(user.getBalance()<money){ throw new RuntimeException("用户余额不足!"); } //3.扣除余额 update User set balance=balance-money where id=id userMapper.deductBalance(id,money); } } mapper层: @Mapper public interface UserMapper extends BaseMapper<User> { @Update("update user set balance=balance-#{money} where id=#{id}") void deductBalance(Long id, Long money); } 总结:如果是简单查询,如用id来查询、删除,可以直接在Controller层用Iservice方法,否则自定义业务层Service实现具体任务。 Service层的lambdaQuery IService中还提供了Lambda功能来简化我们的复杂查询及更新功能。 相当于「条件构造」和「执行方法」写在一起 this.lambdaQuery() = LambdaQueryWrapper + 内置的执行方法(如 .list()、.one()) // 返回 LambdaQueryChainWrapper,可以直接执行查询 List<User> users = userService.lambdaQuery() .eq(User::getUsername, "john") .eq(User::getStatus, 1) .list(); // 直接获取结果 或者先构建条件,后面再动态查询: // 只构建条件,不执行查询 LambdaQueryWrapper<User> wrapper = userService.lambdaQuery() .eq(User::getUsername, "john") .eq(User::getStatus, 1); // 后续可能添加更多条件 if (someCondition) { wrapper.like(User::getEmail, "example"); } // 在需要的时候才执行查询 List<User> users = userService.list(wrapper); 而Mapper 层的 lambdaQuery,只构造条件,不负责执行。法一: // 创建 LambdaQueryWrapper 对象 LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>() .eq(User::getUsername, "john") .eq(User::getStatus, 1); // 执行查询 List<User> users = userMapper.selectList(wrapper); 法二:Wrappers.lambdaQuery() // 方式1:使用 Wrappers.lambdaQuery() LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery(User.class) .eq(User::getUsername, "john") .eq(User::getStatus, 1); 特性 lambdaQuery() lambdaUpdate() 主要用途 构造查询条件,执行 SELECT 操作 构造更新条件,执行 UPDATE(或逻辑删除)操作 支持的方法 .eq(), .like(), .gt(), .orderBy(), .select() 等 .eq(), .lt(), .set(), .setSql() 等 执行方法 .list(), .one(), .page() 等 .update(), .remove()(逻辑删除 **案例一:**实现一个根据复杂条件查询用户的接口,查询条件如下: name:用户名关键字,可以为空 status:用户状态,可以为空 minBalance:最小余额,可以为空 maxBalance:最大余额,可以为空 @GetMapping("/list") @ApiOperation("根据id集合查询用户") public List<UserVO> queryUsers(UserQuery query){ // 1.组织条件 String username = query.getName(); Integer status = query.getStatus(); Integer minBalance = query.getMinBalance(); Integer maxBalance = query.getMaxBalance(); // 2.查询用户 List<User> users = userService.lambdaQuery() .like(username != null, User::getUsername, username) .eq(status != null, User::getStatus, status) .ge(minBalance != null, User::getBalance, minBalance) .le(maxBalance != null, User::getBalance, maxBalance) .list(); // 3.处理vo return BeanUtil.copyToList(users, UserVO.class); } .eq(status != null, User::getStatus, status),使用User::getStatus方法引用并不直接把'Status'插入到 SQL,而是在运行时会被 MyBatis-Plus 解析成实体属性 Status”对应的数据库列是 status。推荐!!! 可以发现lambdaQuery方法中除了可以构建条件,还需要在链式编程的最后添加一个list(),这是在告诉MP我们的调用结果需要是一个list集合。这里不仅可以用list(),可选的方法有: .one():最多1个结果 .list():返回集合结果 .count():返回计数结果 MybatisPlus会根据链式编程的最后一个方法来判断最终的返回结果。 这里不够规范,业务写在controller层中了。 **案例二:**改造根据id修改用户余额的接口,如果扣减后余额为0,则将用户status修改为冻结状态(2) @Override @Transactional public void deductBalance(Long id, Integer money) { // 1.查询用户 User user = getById(id); // 2.校验用户状态 if (user == null || user.getStatus() == 2) { throw new RuntimeException("用户状态异常!"); } // 3.校验余额是否充足 if (user.getBalance() < money) { throw new RuntimeException("用户余额不足!"); } // 4.扣减余额 update tb_user set balance = balance - ? int remainBalance = user.getBalance() - money; lambdaUpdate() //在service层中!!!相当于this.lambdaUpdate() .set(User::getBalance, remainBalance) // 更新余额 .set(remainBalance == 0, User::getStatus, 2) // 动态判断,是否更新status .eq(User::getId, id) .eq(User::getBalance, user.getBalance()) // 乐观锁 .update(); } 批量新增 每 batchSize 条记录作为一个 JDBC batch 提交一次(1000 条就一次) @Test void testSaveBatch() { // 准备10万条数据 List<User> list = new ArrayList<>(1000); long b = System.currentTimeMillis(); for (int i = 1; i <= 100000; i++) { list.add(buildUser(i)); // 每1000条批量插入一次 if (i % 1000 == 0) { userService.saveBatch(list); list.clear(); } } long e = System.currentTimeMillis(); System.out.println("耗时:" + (e - b)); } 之所以把 100 000 条记录分成每 1 000 条一批来插,是为了兼顾 性能、内存 和 数据库/JDBC 限制。 JDBC 或数据库参数限制 很多数据库(MySQL、Oracle 等)对单条 SQL 里 VALUES 列表的长度有上限,一次性插入几十万行可能导致 SQL 过长、参数个数过多,被驱动或数据库拒绝。 即使驱动不直接报错,也可能因为网络包(packet)过大而失败。 内存占用和 GC 压力 JDBC 在执行 batch 时,会把所有要执行的 SQL 和参数暂存在客户端内存里。如果一次性缓存 100 000 条记录的参数(可能是几 MB 甚至十几 MB),容易触发 OOM 或者频繁 GC。 事务日志和回滚压力 一次性插入大量数据,数据库需要在事务日志里记录相应条目,回滚时也要一次性回滚所有操作,性能开销巨大。分批能让每次写入都较为“轻量”,回滚范围也更小。 但是这样拆分插入,本质上还是逐条插入,效率很低 <!-- 低效:逐条插入 --> <insert id="insertBatch"> <foreach collection="list" item="item"> INSERT INTO user (username, email, age) VALUES (#{item.username}, #{item.email}, #{item.age}); </foreach> </insert> 实际执行的SQL: INSERT INTO user (username, email, age) VALUES ('user1', 'user1@test.com', 20); INSERT INTO user (username, email, age) VALUES ('user2', 'user2@test.com', 21); INSERT INTO user (username, email, age) VALUES ('user3', 'user3@test.com', 22); -- ... 总共1000条独立的INSERT语句 而如果想要得到最佳性能,最好是将VALUES 多行: <!-- 高效:VALUES多行插入 --> <insert id="insertBatch"> INSERT INTO user (username, email, age) VALUES <foreach collection="list" item="item" separator=","> (#{item.username}, #{item.email}, #{item.age}) </foreach> </insert> INSERT INTO user (username, email, age) VALUES ('user1', 'user1@test.com', 20), ('user2', 'user2@test.com', 21), ('user3', 'user3@test.com', 22), 需要修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true: url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true 或者直接自定义批量SQL,不用mabatis-plus框架。 MQ分页 快速入门 1)引入依赖 <!-- 数据库操作:https://mp.baomidou.com/ --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.9</version> </dependency> <!-- MyBatis Plus 分页插件 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-jsqlparser-4.9</artifactId> </dependency> 2)定义通用分页查询条件实体 @Data @ApiModel(description = "分页查询实体") public class PageQuery { @ApiModelProperty("页码") private Long pageNo; @ApiModelProperty("页码") private Long pageSize; @ApiModelProperty("排序字段") private String sortBy; @ApiModelProperty("是否升序") private Boolean isAsc; } 3)新建一个 UserQuery 类,让它继承自你已有的 PageQuery @Data @ApiModel(description = "用户分页查询实体") public class UserQuery extends PageQuery { @ApiModelProperty("用户名(模糊查询)") private String name; } 4)Service里使用 @Service public class UserService extends ServiceImpl<UserMapper, User> { /** * 用户分页查询(带用户名模糊 + 动态排序) * * @param query 包含 pageNo、pageSize、sortBy、isAsc、name 等字段 */ public Page<User> pageByQuery(UserQuery query) { // 1. 构造 Page 对象 Page<User> page = new Page<>( query.getPageNo(), query.getPageSize() ); // 2. 构造查询条件 LambdaQueryWrapper<User> qw = Wrappers.<User>lambdaQuery() // 当 name 非空时,加上 user_name LIKE '%name%' .like(StrUtil.isNotBlank(query.getName()), User::getUserName, query.getName()); // 3. 动态排序 if (StrUtil.isNotBlank(query.getSortBy())) { String column = StrUtil.toUnderlineCase(query.getSortBy()); boolean asc = Boolean.TRUE.equals(query.getIsAsc()); qw.last("ORDER BY " + column + (asc ? " ASC" : " DESC")); } // 4. 执行分页查询 return this.page(page, qw); } }
后端学习
zy123
1年前
0
14
0
2025-06-27
DDD领域驱动设计
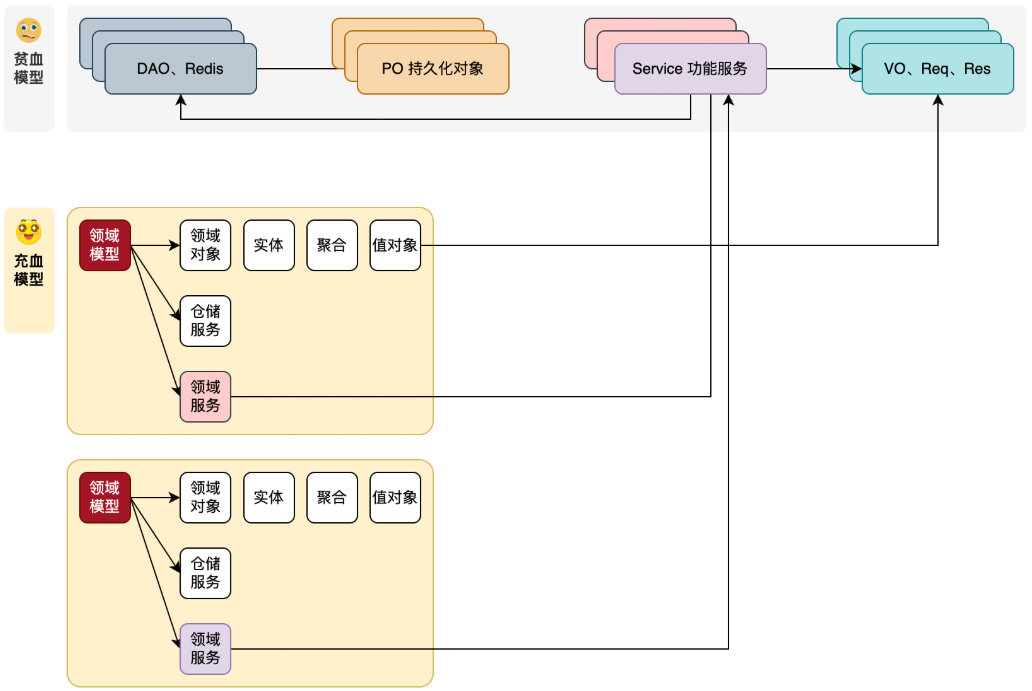
DDD领域驱动设计 什么是 DDD? DDD(领域驱动设计,Domain-Driven Design)是一种软件设计方法论,它为软件工程设计提供了一套完整的指导思想与实践手段。通过领域、界限上下文、实体、值对象、聚合、工厂、仓储等概念,DDD 帮助我们合理划分工程模型,从而在前期投入更多思考,规划出可持续迭代和演进的系统架构。 在工程实践中,DDD 通常分为两个层面的设计: 1. 战略设计 战略设计关注复杂业务的宏观拆分。通过限界上下文和子域划分,将系统分治为独立模块或服务。拆分是否合理取决于上线效率:若每次改动牵涉多个服务,即是失败的“微服务单体”。更实用的方式是:以少数中等规模的核心应用为主体,构建周边服务生态,既保持灵活性,又避免过度拆分。 2. 战术设计 战术设计关注如何在代码层面表达业务概念。它强调通过面向对象建模,将业务逻辑封装进领域模型,并以实体、值对象、聚合和领域服务来承载业务行为,确保代码贴合业务语义。 传统的 MVC 三层架构往往只是 Service 层加数据模型的简单组合,容易导致 Service 类臃肿、逻辑复杂,甚至出现“贫血模型”问题——数据与行为分离,增加了维护难度。DDD 的战术设计通过丰富的领域模型来规避这一问题,使系统结构更清晰、业务逻辑更可维护。 为什么要用DDD? 先说说传统Spring MVC: Spring MVC 传统上多采用 分层架构(Controller-Service-DAO)。 对于 简单业务 或 原型开发,这种方式足够清晰,开发成本低,上手快。 说说Spring MVC的不足: 在 复杂业务场景(核心逻辑复杂、规则频繁变化的系统)中,传统分层模式会暴露出明显问题: 1)业务逻辑分散: 大量 if-else、规则判断和外部调用混杂在 Service 中。 代码难以维护,稍有业务变更,就需要在已有方法里继续堆条件分支。 @Service public class OrderService { @Autowired private OrderRepository orderRepository; @Autowired private PaymentGateway paymentGateway; public void payOrder(Long orderId, String payMethod) { Order order = orderRepository.findById(orderId); // 校验订单 if (order == null) { throw new IllegalArgumentException("订单不存在"); } if (!order.getStatus().equals("UNPAID")) { throw new IllegalStateException("订单状态不允许支付"); } // 校验金额 if (order.getAmount().compareTo(BigDecimal.ZERO) <= 0) { throw new IllegalStateException("订单金额异常"); } // 支付逻辑 boolean success = paymentGateway.pay(order.getId(), order.getAmount(), payMethod); if (!success) { throw new RuntimeException("支付失败"); } // 修改状态 order.setStatus("PAID"); orderRepository.save(order); } } 一个 Service 同时承担校验、业务逻辑、状态修改、持久化和外部调用,演变成“上帝类”。 2)贫血模型:Entity/POJO 只存数据,业务逻辑全堆在 Service,对象与业务语义严重脱节,比如Order 类里找不到 pay(),只能在 OrderService 找到 payOrder()。 3)随着需求增长,Service 越来越庞大,修改风险高、测试困难。 引出DDD的价值 1)业务逻辑回归领域模型(充血模型) 通过 实体、值对象、聚合、领域服务 等概念,把业务规则放回领域模型中,实现高内聚: public class Order { private Long id; private BigDecimal amount; private String status; // 领域方法:支付 public void pay(PaymentGateway paymentGateway, String payMethod) { validateBeforePay(); boolean success = paymentGateway.pay(this.id, this.amount, payMethod); if (!success) { throw new RuntimeException("支付失败"); } this.status = "PAID"; } private void validateBeforePay() { if (!"UNPAID".equals(this.status)) { throw new IllegalStateException("订单状态不允许支付"); } if (amount.compareTo(BigDecimal.ZERO) <= 0) { throw new IllegalStateException("订单金额异常"); } } } @Service public class OrderAppService { @Autowired private OrderRepository orderRepository; @Autowired private PaymentGateway paymentGateway; public void payOrder(Long orderId, String payMethod) { Order order = orderRepository.findById(orderId); order.pay(paymentGateway, payMethod); // 业务逻辑放在 Order 里 orderRepository.save(order); } } 扩展更容易:如果要加优惠券逻辑,只需要在 Order 里扩展,而不是在 Service 里继续堆 if-else。 2)统一语言(Ubiquitous Language) DDD 强调与业务专家使用一致的术语建模,保证沟通顺畅: 传统写法: Controller: OrderController.create() Service: OrderService.saveOrder() DAO: OrderRepository.insert() 业务专家说:“下单” 。开发说:“调用 create() 接口,service.saveOrder(),repository.insert()。” DDD 写法: 团队必须先和业务专家一起挖掘、定义业务概念。 然后这些词汇会 直接落到模型、聚合、实体、方法名 上。 Customer.placeOrder() (客户下单) Order.markAsPendingPayment() (订单标记为待支付) OrderRepository.save(order) (仓储保存订单) 业务专家说:“下单 → 待支付” 。开发说:“placeOrder() → markAsPendingPayment()。” 3)技术解耦与可演进性 1)领域层不依赖技术实现,领域模型只关心业务,不关心底层是 MySQL、Redis、ES 还是文件。 所有外部依赖都通过 接口 定义,比如 OrderRepository。具体的存储实现交给 适配器,在基础设施层完成。 2)遵循依赖倒置原则,领域层依赖抽象接口,而不是依赖具体实现,当技术实现需要调整(如 MySQL → Redis),只需要改适配器。领域模型的变更只来自业务规则的变化,而不是技术变更。 **面试官可能追问:**你只是把service层中的逻辑移动到了实体类中,将臃肿的代码逻辑转移到了别处? 回答: 表面上看,DDD 确实是把 Service 里的逻辑挪到了实体,但本质不是搬家,而是职责重构。 在贫血模型里,实体只是数据容器,业务规则分散在不同 Service 里,导致代码臃肿、逻辑重复。 在充血模型里,规则和实体强绑定,代码语义更贴近业务: 规则归属清晰:订单的支付校验、发货校验都收拢在 Order 聚合里,不会分散在多个 Service。 统一语言:order.pay() 就等于业务里的“订单支付”,减少沟通成本。 复杂度可控:领域服务负责编排,聚合/实体承载业务逻辑,基础设施负责实现,避免出现‘上帝 Service’。 更易维护扩展:新增优惠券逻辑只需在 Order 内扩展,而不是在庞大的 Service 里继续加 if-else。 所以 DDD 的意义在于让领域模型成为业务的表达中心,而不仅仅是逻辑搬家。 如何理解聚合根? 我把聚合理解为一组强相关的实体和值对象,它们必须作为一个整体来保证业务一致性。聚合根是这组对象对外唯一的入口。所有修改必须通过聚合根来进行,它负责维护不变式,并定义事务边界;仓储也以聚合根为单位。跨聚合我们通过 ID 引用与领域事件实现最终一致,避免大事务。例如在订单域,Order 是聚合根,OrderLine、Address 在聚合内;总价计算、状态流转等不变式在一次事务里由 Order 保证;库存属于另一个聚合,通过“订单已提交”事件去扣减库存。这样既保证一致性,又降低耦合、便于扩展。 DDD概念理论 充血模型 vs 贫血模型 定义 贫血模型:对象仅包含数据属性和简单的 getter/setter,业务逻辑由外部服务处理。 充血模型:对象既包含数据,也封装相关业务逻辑,符合面向对象设计原则。 特点 贫血模型 充血模型 封装性 数据和逻辑分离 数据和逻辑封装在同一对象内 职责分离 服务类负责业务逻辑,对象负责数据 对象同时负责数据和自身的业务逻辑 适用场景 简单的增删改查、DTO 传输对象 复杂的领域逻辑和业务建模 优点 简单易用,职责清晰 高内聚,符合面向对象设计思想 缺点 服务层臃肿,领域模型弱化 复杂度增加,不适合简单场景 面向对象原则 违反封装原则 符合封装原则 贫血模型: // 1. “贫血”的订单实体 (Entity) // 它只是一个数据袋子,没有行为,只有getter/setter public class Order { private Long id; private String status; private BigDecimal amount; // ... 一堆getter和setter方法 } // 2. “贫血”的商品实体 (Entity) public class Product { private Long id; private String name; private Integer stock; // 库存 // ... 一堆getter和setter方法 } // 3. 庞大的“服务层” (Service) 包含所有业务逻辑 @Service public class OrderService { @Autowired private ProductRepository productRepository; public void decreaseStock(Long productId, Integer quantity) { // 步骤1: 查询商品 Product product = productRepository.findById(productId); // 步骤2: 检查库存(业务规则) if (product.getStock() < quantity) { throw new RuntimeException("库存不足"); } // 步骤3: 计算并设置新库存(业务逻辑) Integer newStock = product.getStock() - quantity; product.setStock(newStock); // 对象的状态由外部服务来修改 // 步骤4: 保存回数据库 productRepository.save(product); } } 问题:所有业务逻辑(检查库存、计算新库存)都放在了 OrderService这个外部服务里。Product对象本身只是个“傻傻的”数据载体,它对自己的业务规则(如“库存不能为负”)一无所知,谁都可以随意setStock,非常容易出错。这就是 “贫血模型”。 充血模型: // 1. “充血”的商品实体 (Entity/Aggregate Root) // 它不仅有数据,更有行为(方法),它对自己的业务规则负责 public class Product { private Long id; private String name; private Integer stock; // 库存 // 核心业务行为:减少库存 // 这个方法是直接写在这个实体对象内部的! public void decreaseStock(Integer quantity) { // 守护业务规则:库存不能减少为负数 if (this.stock < quantity) { throw new DomainException("商品库存不足,无法减少"); } // 业务逻辑:修改自身状态 this.stock -= quantity; } // 其他行为,如增加库存... public void increaseStock(Integer quantity) { this.stock += quantity; } } // 2. 变得很“薄”的服务层 (Service/Application Service) // 它的职责不再是处理业务逻辑,而是协调事务、调用仓库、发布事件等 @Service public class OrderApplicationService { @Autowired private ProductRepository productRepository; public void decreaseStock(Long productId, Integer quantity) { // 步骤1: 获取领域对象(聚合根) Product product = productRepository.findById(productId); // 步骤2: 调用领域对象自身的业务方法! product.decreaseStock(quantity); // 逻辑在Product内部 // 步骤3: 保存这个发生了变化的对象 productRepository.save(product); } } 这样的方式可以在使用一个对象时,就顺便拿到这个对象的提供的一系列业务方法,所有使用对象的逻辑方法,都不需要自己再次处理同类逻辑。 但不要只是把充血模型,仅限于一个类的设计和一个类内的方法设计。充血还可以是整个包结构**(领域模型)**,一个包下包括了用于实现此包 Service 服务所需的各类零部件(模型、仓储、工厂),也可以被看做充血模型。 同时我们还会再一个同类的类下,提供对应的内部类,如用户实名,包括了通信类、实名卡、银行卡、四要素等。它们都被写进到一个用户类下的内部子类,这样在代码编写中也会清晰的看到子类的所属信息,更容易理解代码逻辑,也便于维护迭代。 我的实体类本身还是偏贫血模型,主要负责承载数据和基本的不变式校验。**但在领域层里,我会把仓储、领域服务和实体组合在一起,所有业务逻辑都在领域模型中闭环实现,不会散落到外层,这样整体上就是充血思想。**实体保证自身一致性,复杂逻辑交给领域服务来实现。 限界上下文 限界上下文是指一个明确的边界,规定了某个子领域的业务模型和语言,确保在该上下文内的术语、规则、模型不与其他上下文混淆。是一个 业务设计概念。 表达 语义环境 实际含义 "我吃得很饱,现在不能动了" 日常用餐 字面意思:吃到肚子很满 "我吃得很饱,今天的演讲让人充实" 知识分享 比喻:得到了很大满足 限界上下文的作用 定义业务边界:类似于语义环境,为通用语言划定范围 消除歧义:确保团队对领域对象、事件的认知一致 领域转换:同一对象在不同上下文有不同名称(goods在电商称"商品",运输称"货物") 模型隔离:防止不同业务领域的模型相互干扰 在代码工程里,每个上下文拥有独立包结构 领域模型 指特定业务领域内,业务规则、策略以及业务流程的抽象和封装。在设计手段上,通过风暴模型拆分领域模块,形成界限上下文。最大的区别在于把原有的众多 Service + 数据模型的方式,拆分为独立的有边界的领域模块。每个领域内创建自身所属的;领域对象(实体、聚合、值对象)、仓储服务(DAO 操作)、工厂、端口适配器Port(调用外部接口的手段)等。 在原本的 Service + 贫血的数据模型开发指导下,Service 串联调用每一个功能模块。这些基础设施(对象、方法、接口)是被相互调用的。这也是因为贫血模型并没有面向对象的设计,所有的需求开发只有详细设计。 换到充血模型下,现在我们以一个领域功能为聚合,拆分一个领域内所需的 Service 为领域服务,VO、Req、Res 重新设计为领域对象,DAO、Redis 等持久化操作为仓储等。举例:一套账户服务中的,授信认证、开户、提额降额等,每一个都是一个独立的领域,在每个独立的领域内,创建自身领域所需的各项信息。 领域模型还有一个特点,它自身只关注业务功能实现,不与外部任何接口和服务直连。如:不会直接调用 DAO 操作库,也不会调用缓存操作 Redis,更不会直接引入 RPC 连接其他微服务。而是通过仓库Repository和端口适配器port,定义调用外部数据的含有出入参对象的接口标准,让基础设施层做具体的调用实现——通过这样的方式让领域只关心业务实现,同时做好防腐。(依赖倒置) 领域服务 一组无状态的业务操作,封装那些“不属于任何单个实体/聚合”的领域逻辑。 职责 执行跨聚合、跨实体的业务场景—— 处理一个订单支付时,可能需要处理与 订单、账户、支付信息 等多个实体的交互。 在这种情况下,领域服务负责协调这些实体之间的交互。 协调仓储接口、调用多个聚合根的方法,但本身不持有长期状态。 领域服务自己不持有数据状态,它的职责是调度和协调。它通过调用聚合根(或实体)的方法来完成业务操作。它也不会涉及持久化(数据存储),这些通常是通过仓储层来管理的。 典型示例 订单支付功能: 涉及订单、用户账户、支付信息等多个实体,适合放在领域服务中实现 订单(Order):包含订单的详细信息。 账户(Account):用户的账户信息,包括余额。 支付信息(PaymentDetails):支付的具体信息,例如支付方式、金额等。 @Service public class PaymentService { @Transactional public void processPayment(Order order, PaymentDetails paymentDetails, Account account) { // 调用领域对象的行为 account.pay(paymentDetails.getAmount()); //负责余额检查与扣款 order.markAsPaid(); //负责支付状态变更 paymentDetails.recordPayment(order); // 保存这些聚合(Repository 层操作) orderRepository.save(order); accountRepository.save(account); paymentRepository.save(paymentDetails); } } 领域对象 实体 实体是基于持久化层数据和领域服务功能目标设计的领域对象。与持久化的 PO(持久化对象)不同,PO 只是原子类对象,缺乏业务语义,而实体对象不仅具备业务语义,还具有唯一标识。实体对象与领域服务方法紧密结合,跟随其生命周期进行操作。 例如,用户的 PO 对象可能包括用户开户信息、授信信息和额度信息等多个方面,而订单则可能涉及多个实体,例如商品下单时的购物车实体。实体通常作为领域服务方法的入参对象。 在代码中,实体通常表现为具有唯一标识的业务对象,标识属性(如 ID)是其核心特征。例如: 订单实体:通过订单 ID 唯一标识 用户实体:通过用户 ID 唯一标识 核心特征: 实体的属性随着时间变化而变化。 唯一标识(ID)保持不变,确保实体的唯一性。 实体对象通常在代码中以实体类的形式存在,并且通常采用 充血模型 实现,即将与该实体相关的业务逻辑和行为写入实体类中,而不仅仅是存储数据。 **作用:**实体类的作用是用来建模领域中的“唯一业务对象”,它通过 ID 保证唯一性,随着生命周期发生状态变化,并将与自身相关的业务逻辑和行为封装在内部,是领域建模的核心元素。 值对象 值对象是没有唯一标识的业务对象,具有以下特征: 创建后不可修改(immutable) 只能通过整体替换来更新 通常用于描述实体的属性和特征 在开发值对象的时候,通常不会提供 setter 方法,而是提供构造函数或者 Builder 方法来实例化对象。这个对象通常不会独立作为方法的入参对象,但做可以独立作为出参对象使用。 作用: 表达领域概念:用值对象建模能让代码更贴近业务,比如用枚举类XXStatus代替1、2、3。 保证一致性与正确性:值对象可以在内部封装校验逻辑,比如金额不能为负数。 可复用:多个实体都可以组合使用相同的值对象。 用于:枚举类、VO返回对象 聚合与聚合根 ”高内聚、低耦合“,代码中直观的感受就是仓储层中,传入的如果是聚合根,意味着要对不同的表进行处理,因此对应方法上一般要加@Transactional-------拼团中的锁单、退单都是如此!!! 锁单:同时操作拼团表和拼团明细表;退单:拼团表+拼团明细表+消息通知表。 在领域驱动设计(DDD)中,聚合是一组紧密关联的 **实体 **和 值对象的组合,这些对象在业务上共同协作,形成一个统一的一致性与事务边界。 聚合根 是聚合的唯一入口,负责对外提供操作接口,并维护聚合内部的一致性和业务规则。 1. 聚合(逻辑边界) 聚合内的所有变更必须在同一事务中完成,要么全部成功,要么全部失败,确保内部业务不变式始终成立。例:订单的总金额必须等于所有订单项金额之和。 一次事务只允许跨越一个聚合,避免分布式事务的复杂性。 外部代码不得直接修改聚合内除聚合根之外的对象,所有操作都必须通过聚合根进行。例:外部不能直接改 OrderItem 数量,而是调用 Order.changeItemQuantity()。 示例: 一个订单聚合可能包含: 订单实体(聚合根):Order,全局唯一 ID,提供操作方法;包含订单总金额 totalAmount。 订单明细实体:OrderItem,描述商品项(数量、单价)。 收货地址值对象:ShippingAddress,不可变,存储地址信息。 2. 聚合根(物理入口) 唯一入口:对外唯一的访问点Order,聚合内的所有修改必须经由聚合根发起。 全局标识:聚合根是一个拥有全局唯一 ID 的实体。 规则守护者:负责封装聚合内部的业务逻辑、数据校验及不变式维护。 跨聚合交互:与其他聚合交互时,只传递 ID 或使用领域服务,不直接持有对方实体的引用,避免跨边界耦合。 3.代码示例(订单聚合) // 聚合根:订单 public class Order { private final String orderId; private List<OrderItem> items; private ShippingAddress address; private double totalAmount; // 总金额作为不变式 public Order(String orderId, ShippingAddress shippingAddress) { this.orderId = orderId; this.address = shippingAddress; this.items = new ArrayList<>(); this.totalAmount = 0.0; } // 添加商品 public void addItem(String productId, int quantity, double price) { OrderItem item = new OrderItem(productId, quantity, price); items.add(item); recalculateTotalAmount(); } // 修改订单项数量(外部必须通过聚合根调用) public void changeItemQuantity(String productId, int newQuantity) { for (OrderItem item : items) { if (item.getProductId().equals(productId)) { item.changeQuantity(newQuantity); // 修改子实体 recalculateTotalAmount(); // 重新计算总金额 return; } } throw new IllegalArgumentException("未找到商品:" + productId); } // 聚合内规则:每次修改都要维护不变式 private void recalculateTotalAmount() { this.totalAmount = items.stream() .mapToDouble(OrderItem::totalPrice) .sum(); } public double getTotalAmount() { return totalAmount; } } 比如订单聚合根,有自己唯一orderid,以及totalamount总金额,订单明细实体,地址值对象; 每次添加新的商品+数量,就自动调用一次更新总金额;保证事务的一致性。 仓储服务 特征 封装持久化操作:Repository负责封装所有与数据源交互的操作,如创建、读取、更新和删除(CRUD)操作。这样,领域层的代码就可以避免直接处理数据库或其他存储机制的复杂性。 抽象接口:Repository定义了一个与持久化机制无关的接口,这使得领域层的代码可以在不同的持久化机制之间切换,而不需要修改业务逻辑。 职责分离 领域层 只定义 Repository 接口,关注“需要做哪些数据操作”(增删改查、复杂查询),不关心具体实现。 基础设施层 实现这些接口(ORM、JDBC、Redis、ES、RPC、HTTP、MQ 推送等),封装所有外部资源的访问细节。 仓储解耦的手段使用了依赖倒置的设计。 示例: 只定义接口,由基础设施层来实现。 public interface IActivityRepository { GroupBuyActivityDiscountVO queryGroupBuyActivityDiscountVO(String source, String channel); SkuVO querySkuByGoodsId(String goodsId); } 使用:在应用程序中使用依赖注入(DI)来将具体的Repository实现注入到需要它们的领域服务或应用服务中。 聚合和领域服务和仓储服务的比较 有状态(Stateful): 一个订单(Order)聚合,它可能会记录订单的状态,比如“未支付”或“已支付”,以及订单项(OrderItem)的列表。在处理订单时,这些状态会发生变化(例如,当订单支付时,它的状态从“未支付”变为“已支付”)。 无状态: 一个计算价格的服务(PricingService)是无状态的,它接收输入(例如商品数量、商品价格等),然后计算并返回结果。它不会记住上一次计算的结果,每次计算都是独立的。 特性 聚合(Aggregate) 领域服务(Domain Service) 仓储(Repository) 本质 相关实体和值对象的组合,以“聚合根”为唯一访问入口 无状态的业务逻辑单元,封装跨实体 / 跨聚合规则 抽象的数据访问接口,隐藏底层存储细节,为聚合提供持久化能力 状态 有状态——内部维护数据与不变式 无状态——仅暴露行为 无业务状态;实现层可能有缓存,但对外看作无状态 职责 1. 内部一致性2. 定义事务边界3. 提供领域行为(order.pay() 等) 1. 承载跨实体规则2. 协调多个聚合完成业务动作 1. 加载 / 保存聚合根2. 把 PO ↔️ Entity 映射3. 屏蔽 SQL/ORM/缓存等技术细节 边界 聚合边界:内部操作要么全部成功要么全部失败 无一致性边界,仅调用聚合或仓储 持久化边界:一次操作针对一个聚合;不负责业务事务(由应用层控制) 典型用法 Order.addItem(),Order.cancel() PricingService.calculate(...),InventoryService.reserveStock(...) orderRepository.findById(id),orderRepository.save(order) **自己总结:**领域服务纯编排流程并注入仓储服务; 仓储服务只写接口,规定一个具体的'动作'; 然后基础设施层中子类实现该仓储接口,并注入若干Dao,一个'动作'可能调用多个Dao来实现; Dao直接与数据库打交道,实现增删查改。 API层 提供给其他服务直接依赖、并通过 RPC 调用本服务的契约。 这个 api 模块会被单独打成一个 Jar 包,其他服务只需要 依赖这个 jar,就能拿到: 1.请求 DTO 2.服务接口(通常供 RPC/Dubbo、HTTP 控制器或内部模块调用) 3.统一响应包装 response 基础设施层 1.持久化实现(Repository 实现类) 在领域层你只定义了 仓储接口(Repository Interface),比如 OrderRepository。 在基础设施层才写具体实现,比如用 JPA、MyBatis、Hibernate、JDBC 去操作数据库。 2.外部系统适配 对接第三方服务、消息队列例如:支付服务调用的 HttpClient 实现;拼团通过http请求小型支付商城的xx接口,或发rabbitmq。 3.基础设施组件封装 通用的技术性工具代码,不涉及业务逻辑,比如DCC动态配置中心,邮件的调用,AOP切面类动态限流 4.事件与消息机制 提供消息队列的具体实现,配置与发送。 Trriger触发器层 触发器层主要负责 “接收外部输入,触发应用/领域逻辑” 1.HTTP 接口(Controller) 2.消息监听(Listener / Consumer) 3.定时任务(Job / Scheduler) 比如超时退款、拼团组队成功通知等。 4.RPC 接口(Dubbo、gRPC、Thrift 等) 作为服务提供方,暴露给其他系统调用的接口。 Types通用类型层 目录 作用 示例 annotations 自定义注解及其拦截器。 DCCValue、RateLimiterAccessInterceptor:比如做参数校验、限流、配置注入等。 common 全局常量、通用工具类。 Constants:放系统级别的常量、公共配置Key等。 design.framework 设计模式或通用策略框架的封装。tree、link 子包像是策略路由、责任链等可复用的实现。 AbstractStrategyRouter、StrategyHandler:策略路由器抽象,供业务模块按需继承。 enums 系统级枚举。和业务场景相关但通用的状态、返回码等。 ActivityStatusEnumVO、GroupBuyOrderStatusEnumVO、ResponseCode 等。 event 基础事件类型,领域事件的通用父类。 BaseEvent:其他模块可继承实现自定义事件。 exception 自定义异常体系。 AppException:统一异常封装,便于全局处理。 DDD架构设计 四层架构 用户接口层interface:处理用户交互和展示 应用层application:协调领域对象完成业务用例 领域层domain:包含核心业务逻辑和领域模型 基础设施层infrastructure:提供技术实现支持 如何从MVC架构映射到DDD架构? 六边形架构 领域模型设计 方式1;DDD 领域科目类型分包,类型之下写每个业务逻辑。 **方式2;**业务领域分包,每个业务领域之下有自己所需的 DDD 领域科目。(拼团营销系统是方式2)
后端学习
zy123
1年前
0
22
0
2025-05-28
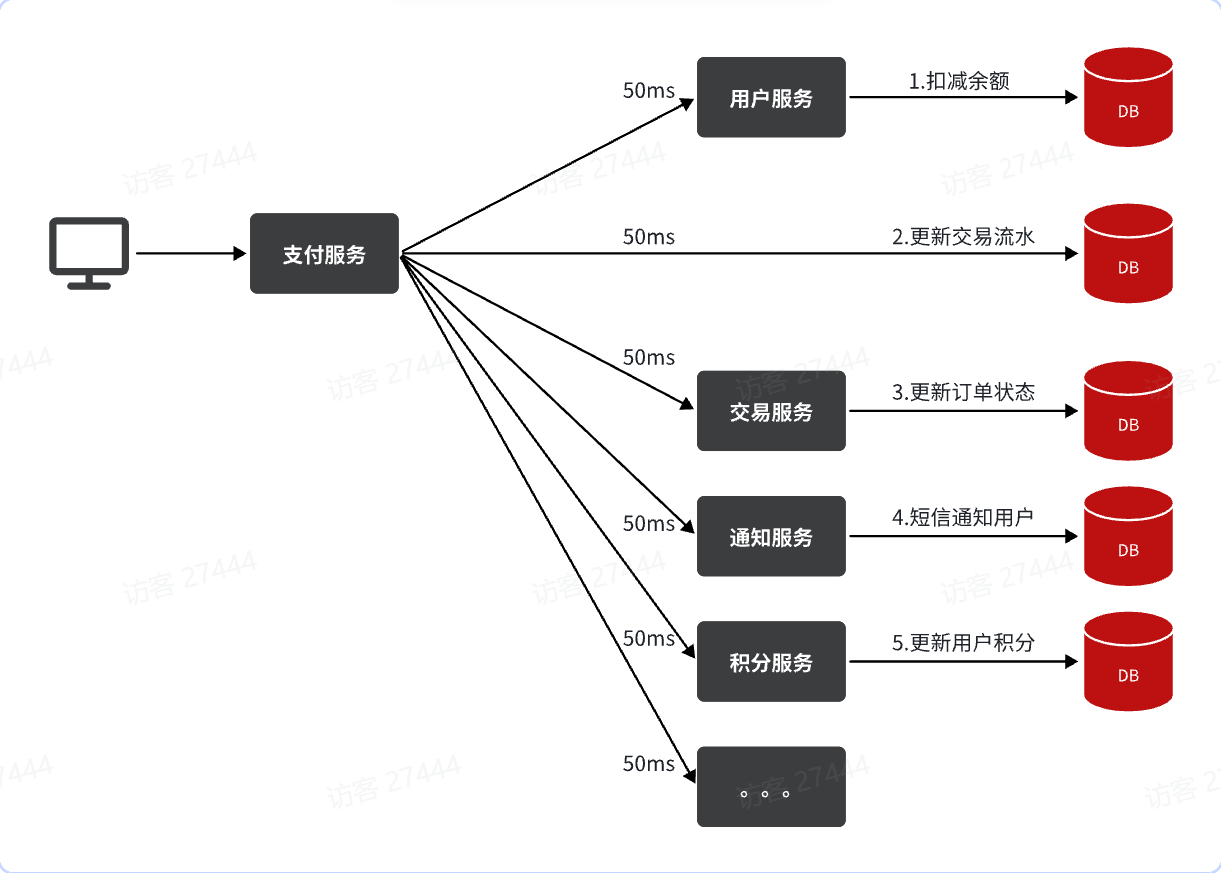
消息队列MQ
消息队列MQ 初识MQ 同步调用 同步调用有3个问题: 拓展性差,每次有新的需求,现有支付逻辑都要跟着变化,代码经常变动 性能下降,每次远程调用,调用者都是阻塞等待状态。最终整个业务的响应时长就是每次远程调用的执行时长之和 级联失败,当交易服务、通知服务出现故障时,整个事务都会回滚,交易失败。 异步调用 技术选型 RabbitMQ 部署 mq: #消息队列 image: rabbitmq:3.8-management container_name: mq restart: unless-stopped hostname: mq environment: TZ: "Asia/Shanghai" RABBITMQ_DEFAULT_USER: admin RABBITMQ_DEFAULT_PASS: "admin" ports: - "15672:15672" - "5672:5672" volumes: - mq-plugins:/plugins # 持久化数据卷,保存用户/队列/交换机等元数据 - ./mq-data:/var/lib/rabbitmq networks: - hmall-net volumes: mq-plugins: http://localhost:15672/ 访问控制台 架构图 publisher:生产者,发送消息的一方 consumer:消费者,消费消息的一方 queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理 exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。不存储 virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue(每个项目+环境有各自的vhost) 一个队列最多指定给一个消费者! Spring AMQP 快速开始 交换机和队列都是直接在控制台创建,消息的发送和接收在Java应用中实现! 简单案例:直接向队列发送消息,不经过交换机 引入依赖 <!--AMQP依赖,包含RabbitMQ--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> 配置MQ地址,在publisher和consumer服务的application.yml中添加配置: spring: rabbitmq: host: localhost # 你的虚拟机IP port: 5672 # 端口 virtual-host: /hmall # 虚拟主机 username: hmall # 用户名 password: 123 # 密码 消息发送: 然后在publisher服务中编写测试类SpringAmqpTest,并利用**RabbitTemplate**实现消息发送: @SpringBootTest public class SpringAmqpTest { @Autowired private RabbitTemplate rabbitTemplate; @Test public void testSimpleQueue() { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, spring amqp!"; // 发送消息 rabbitTemplate.convertAndSend(queueName, message); } } convertAndSend如果 2 个参数,第一个表示队列名,第二个表示消息; 消息接收 @Component public class SpringRabbitListener { // 利用RabbitListener来声明要监听的队列信息 // 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。 // 可以看到方法体中接收的就是消息体的内容 @RabbitListener(queues = "simple.queue") public void listenSimpleQueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者接收到消息:【" + msg + "】"); } } 然后启动启动类,它能自动从队列中取出消息。取出后队列中就没消息了! 交换机 无论是 直连Direct、主题Topic 还是 扇形Fanout 交换机,你都可以用 同一个 Binding Key 把多条队列绑定到同一个交换机上。 1)fanout:广播给每个绑定的队列 发送消息: convertAndSend如果 3 个参数,第一个表示交换机,第二个表示RoutingKey,第三个表示消息。 @Test public void testFanoutExchange() { // 交换机名称 String exchangeName = "hmall.fanout"; // 消息 String message = "hello, everyone!"; rabbitTemplate.convertAndSend(exchangeName, "", message); } 2)Direct交换机 队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key) 消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。 Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的BindingKey与消息的 Routing key完全一致,才会接收到消息 注意,RoutingKey不等于队列名称 3)Topic交换机 Topic类型的交换机与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。 只不过Topic类型交换机可以让队列在绑定BindingKey 的时候使用通配符! BindingKey一般都是有一个或多个单词组成,多个单词之间以.分割 通配符规则: #:匹配一个或多个词 *:匹配不多不少恰好1个词 举例: item.#:能够匹配item.spu.insert 或者 item.spu item.*:只能匹配item.spu 转发过程:把发送者传来的 Routing Key 按点分成多级,和各队列的 Binding Key(可以带 *、# 通配符)做模式匹配,匹配上的队列统统都能收到消息。 注意:生产者在发送消息时,必须指定一个明确的 RoutingKey,而队列绑定到 Topic Exchange 时,指定的 BindingKey 可以包含通配符。 Routing Key和Binding Key Routing Key(路由键) 由发送者(Producer)在发布消息时指定,附着在消息头上。 用来告诉交换机:“我的这条消息属于哪类/哪个主题”。 Binding Key(绑定键) 由消费者(在应用启动或队列声明时)指定,是把队列绑定到交换机时用的规则。有些 UI 里 Routing Key 等同于 Binding Key! 告诉交换机:“符合这个键的消息,投递到我这个队列”。 交换机本身不设置 Routing Key 或 Binding Key,它只根据类型(Direct/Topic/Fanout/Headers)和已有的“队列–绑定键”关系,把 incoming Routing Key 匹配到对应的队列。 Direct Exchange 路由规则:Routing Key === Binding Key(完全一致) 场景:一对一或一对多的精确路由 Topic Exchange 路由规则 :支持通配符 *:匹配一个单词 #:匹配零个或多个单词 例: Binding Key绑定键 order.* → 能匹配 order.created、order.paid 绑定键 order.# → 能匹配 order.created.success、order 等 Fanout Exchange 路由规则:忽略 Routing/Binding Key,消息广播到所有绑定队列 场景:聊天室广播、缓存失效通知等 消费者处理消息 不同队列: 同一个交换机 + 相同 routing key 绑定到 多个不同的队列 → 每个队列都会收到一份消息,各自独立处理。 👉 相当于多个队列订阅了同类信息,TOPIC 同一个队列: 多个消费者(不管是一个应用里开多个 listener,还是多台实例部署)监听 同一个队列 → 一条消息只会被其中一个消费者消费,起到负载均衡作用。 👉 常用于“任务分摊”。 基于注解声明交换机、队列 前面都是在 RabbitMQ 管理控制台手动创建队列和交换机,开发人员还得把所有配置整理一遍交给运维,既繁琐又容易出错。更好的做法是在应用启动时自动检测所需的队列和交换机,若不存在则直接创建。 基于注解方式来声明 type 默认交换机类型为ExchangeTypes.DIRECT @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue1"), exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT), key = {"red", "blue"} )) public void listenDirectQueue1(String msg){ System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】"); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "direct.queue2"), exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT), key = {"red", "yellow"} )) public void listenDirectQueue2(String msg){ System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】"); } 检查队列 如果 RabbitMQ 中已经有名为 direct.queue1 的队列,就不会重复创建; 如果不存在,RabbitAdmin 会自动帮你创建一个。 检查交换机 同理,会查看有没有名为 hmall.direct、类型为 direct 的交换机,若不存在就新建。 检查绑定 最后再去声明绑定关系:把 direct.queue1 绑定到 hmall.direct,并且 routing-key 为 "red" 和 "blue"。 如果已有相同的绑定(队列、交换机、路由键都一致),也不会再重复创建。 消息转换器 使用JSON方式来做序列化和反序列化,替换掉默认方式。 更小或可压缩的消息体、易读、易调试 1)引入依赖 <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-xml</artifactId> <version>2.9.10</version> </dependency> 2)配置消息转换器,在publisher和consumer两个服务的启动类中添加一个Bean即可: @Bean public MessageConverter messageConverter(){ // 1.定义消息转换器 Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter(); // 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息 jackson2JsonMessageConverter.setCreateMessageIds(true); return jackson2JsonMessageConverter; } MQ高级 我们要解决消息丢失问题,保证MQ的可靠性,就必须从3个方面入手: 确保生产者一定把消息发送到MQ 确保MQ不会将消息弄丢 确保消费者一定要处理消息 发送者的可靠性 发送者重试 修改发送者模块的application.yaml文件,添加下面的内容: 主要是针对网络连接失败的场景,会自动重试;交换机不存在,不会触发重试。 spring: rabbitmq: connection-timeout: 1s # 设置MQ的连接超时时间 template: retry: enabled: true # 开启超时重试机制 initial-interval: 1000ms # 失败后的初始等待时间 multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multiplier max-attempts: 3 # 最大重试次数 阻塞重试,一般不建议开启。 发送者确认机制 一、机制概述 RabbitMQ 提供两种发送者确认机制,确保消息投递的可靠性: Publisher Confirm:确认消息是否到达 RabbitMQ 服务器 Publisher Return:确认消息是否成功路由到队列 二、配置开启 1.在发送者模块的application.yaml中添加配置: spring: rabbitmq: publisher-confirm-type: correlated # 开启异步confirm机制 publisher-returns: true # 开启return机制 confirm类型说明: none(默认模式):关闭confirm机制,消息由于网络连接失败也不会提醒。 simple:同步阻塞等待MQ的回执 correlated:MQ异步回调返回回执 2.每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置。 @Slf4j @Configuration @RequiredArgsConstructor public class MqConfig { private final RabbitTemplate rabbitTemplate; @PostConstruct public void init() { // 设置全局ReturnCallback rabbitTemplate.setReturnsCallback(returned -> { log.error("消息路由失败 - Exchange: {}, RoutingKey: {}, ReplyCode: {}, ReplyText: {}", returned.getExchange(), returned.getRoutingKey(), returned.getReplyCode(), returned.getReplyText()); // 可在此添加告警或重试逻辑 sendAlert(returned); }); } } 三、ConfirmCallback 使用 消息发送时设置确认回调CorrelationData 这里的CorrelationData中包含两个核心的东西: id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆 SettableListenableFuture:回执结果的Future对象 public void sendMessageWithConfirmation(String exchange, String routingKey, Object message) { // 1. 创建关联数据 CorrelationData correlationData = new CorrelationData(); // 2. 添加确认回调 correlationData.getFuture().addCallback( result -> { if (result.isAck()) { log.info("✅ 消息成功到达MQ服务器"); } else { log.error("❌ 消息发送失败: {}", result.getReason()); // 可在此添加重试逻辑 } }, ex -> { log.error("⚠️ 确认过程发生异常", ex); } ); // 3. 发送消息 rabbitTemplate.convertAndSend(exchange, routingKey, message, correlationData); } 四、消息投递结果分析 场景 网络状态 路由状态 ConfirmCallback ReturnsCallback 最终结果 完全成功 ✅ 成功 ✅ 成功 ACK 不触发 消息入队 网络失败 ❌ 失败 - NACK 不触发 发送失败 路由失败 ✅ 成功 ❌ 失败 ACK 触发 消息丢弃 交换机不存在 ✅ 成功 ❌ 失败 ACK 触发 消息丢弃 端到端投递保障 ConfirmCallback 只告诉你:消息“到”了 RabbitMQ 服务器吗?(ACK:到;NACK:没到) ReturnCallback 只告诉你:到达服务器的消息,能“进”队列吗?(能进就不回;进不了就退) 两者都成功,才能确认:“这条消息真的安全地进了队列,等着消费者去拿。” 🟢 ACK:消息到达MQ服务器(可能路由失败) 🔴 NACK:消息未到达MQ服务器(网络问题) 🔵 Return:消息到达但路由失败(配置问题) 通过组合使用这两种机制,可以实现完整的端到端消息投递保障。如果由于网络问题,NACK了,那么会被correlationData.getFuture().addCallback(...)回调函数捕捉!!! MQ的可靠性 数据持久化 MQ消息持久化就是指当RabbitMQ服务重启后,消息仍然会保留在队列中不会丢失。 非持久化消息:只存储在内存中;持久化消息:同时存储在内存和磁盘中 为了保证数据的可靠性,必须配置数据持久化(从内存保存到磁盘上),包括: 交换机持久化(选Durable) 队列持久化(选Durable) 消息持久化(选Persistent) 控制台方式: 代码方式,默认都是持久化的,不用变动。 消费者可靠性 消费者确认机制 消费者确认机制 (Consumer Acknowledgement) 是为了确认消费者是否成功处理消息。当消费者处理消息结束后,应该向 RabbitMQ 发送一个回执,告知 RabbitMQ 自己消息处理状态: ack:成功处理消息,RabbitMQ 从队列中删除该消息 nack:消息处理失败,RabbitMQ 需要再次投递消息 reject:消息处理失败并拒绝该消息,RabbitMQ 从队列中删除该消息 上述的NACK状态时,MQ会不断向消费者重投消息,直至被正确处理!!! 在消费者方,通过下面的配置可以修改消费者收到消息后的处理方式: none:消费者收到消息后,RabbitMQ 立即自动确认(ACK) manual,手动实现ack; auto(默认模式),自动档,业务逻辑异常返回nack, 消息解析异常 返回reject,其他ack spring: rabbitmq: listener: simple: acknowledge-mode: auto 消费者重试 类似发送者的重试机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。 重试达到最大次数后,会返回reject,消息会被丢弃 修改consumer服务的application.yml文件,添加内容: spring: rabbitmq: listener: simple: retry: enabled: true # 开启消费者失败重试 initial-interval: 1000ms # 初识的失败等待时长为1秒 multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval max-attempts: 3 # 最大重试次数 stateless: true # true无状态(默认);如果业务中包含事务,这里改为false有状态 核心概念:一次事务 vs. 多次事务 想象一下这个场景:你是一个消费者,从MQ收到一条消息,内容是“给用户A的账户增加10元”。你的服务需要执行两个步骤: 处理业务逻辑(更新数据库,给用户A加钱)。 确认消息(告诉MQ消息处理成功了)。 这个“处理业务逻辑”和“确认消息”的过程,可以放在一个数据库事务里。 特性 无状态重试 (stateless: true) 有状态重试 (stateless: false) 本质 本地方法重试 消息重新投递 事务范围 所有重试在同一个事务中 每次重试是独立的事务 MQ感知 MQ完全不知情(只投递1次) MQ完全知情(多次投递) 性能 高(无网络开销) 较低(有网络开销) 安全性 低(易导致重复操作) 高(每次失败都回滚) 适用场景 幂等操作、非DB操作(如HTTP调用) 非幂等操作、数据库事务操作 为什么用了 @Transactional必须有状态重试? 假设是无状态重试,重试是在同一次方法调用/同一事务里循环进行的(拦截器内部重试)。 第一次失败抛出异常后,当前事务被标记为 rollback-only。 接下来即便你第2次、第3次尝试都“业务成功”,提交时也会失败(因为事务早已不可提交)。 结果:不适合与 @Transactional 搭配做数据库更新;更适合无事务或幂等且不涉及DB提交的调用(如外部HTTP、缓存写入等)。 假设是有状态重试(stateless: false) 重试通过把异常抛回给容器,让消息重新投递来实现。 每次投递 → 监听方法重新执行 → 新的事务开启。 每次失败都会完整回滚该次事务;下一次重试是干净的事务上下文。 达到最大次数后,按照你的配置reject(可配合死信队列/失败交换器),从而避免“消息风暴”。 !!!有状态重试相比RabbitMq的默认重试机制:可以配置有限次重试次数,更加灵活。 失败处理策略 只有在开启了消费者重试机制(即配置了 spring.rabbitmq.listener.simple.retry.enabled: true)时才会生效。 当消息消费重试达到最大次数后,默认会直接丢弃,这在要求高可靠性的场景中不可接受。Spring 提供了 MessageRecoverer接口来自定义最终处理策略,主要有三种实现: RejectAndDontRequeueRecoverer 默认策略。直接拒绝消息并丢弃。 ImmediateRequeueMessageRecoverer 让消息重新进入队列,再次被消费(可能导致循环)。 RepublishMessageRecoverer ✅ 推荐方案 将消息路由到一个专用的异常交换机,最终进入异常队列。 优势:实现故障隔离,便于后续人工干预或自动化修复,是保证消息不丢失的优雅方案。 业务幂等性 在程序开发中,幂等则是指同一个业务,执行一次或多次对业务状态的影响是一致的。如: 根据id删除数据 查询数据 新增数据 但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如: 取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况 退款业务。重复退款对商家而言会有经济损失。 所以,我们要尽可能避免业务被重复执行:MQ消息的重复投递、页面卡顿时频繁刷新导致表单重复提交、服务间调用的重试 法一:唯一ID 每一条消息都生成一个唯一的id,与消息一起投递给消费者。 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库。 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。 法一存在业务侵入,因为mq的消息ID与业务无关,现在却多了一张专门记录 ID 的表或结构 法二:业务判断,基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。 综上,支付服务与交易服务之间的订单状态一致性是如何保证的? 首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递的可靠性 最后,我们还在交易服务设置了定时任务,定期查询订单支付状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。 延迟消息 对于超过一定时间未支付的订单,应该立刻取消订单并释放占用的库存。 方案:利用延迟消息实现超时检查 以“订单支付超时时间为30分钟”为例,具体实现流程如下: 创建订单时:在订单入库的同时,向消息队列发送一条延迟时间为30分钟的消息。 消息等待:此消息不会立即被消费,而是由MQ服务器暂存至延迟时间到期。 延迟触发:30分钟后,消息队列自动将该消息投递给消费者服务。 执行检查与操作:消费者接收到消息后,查询该订单的当前支付状态: 若订单仍为“未支付”:则执行取消订单、释放库存等后续操作。 若订单已支付:则忽略此消息,流程结束。 实现延迟消息法一 延迟消息插件 1.下载 GitHub - rabbitmq/rabbitmq-delayed-message-exchange: Delayed Messaging for RabbitMQ 2.上传插件,由于之前docker部署MQ挂载了数据卷 docker volume ls #查看所有数据卷 docker volume inspect hmall_all_mq-plugins #获取数据卷的目录 #"Mountpoint": "/var/lib/docker/volumes/hmall_all_mq-plugins/_data" 我们上传插件到该目录下。 3.安装插件 docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange 声明延迟交换机 额外指定参数 delayed = "true" @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "delay.queue", durable = "true"), exchange = @Exchange(name = "delay.direct", delayed = "true"), key = "delay" )) public void listenDelayMessage(String msg){ log.info("接收到delay.queue的延迟消息:{}", msg); } 发送延迟消息 @Test void testPublisherDelayMessage() { // 1.创建消息 String message = "hello, delayed message"; // 2.发送消息,利用消息后置处理器添加消息头 rabbitTemplate.convertAndSend("delay.direct", "delay", message, new MessagePostProcessor() { @Override public Message postProcessMessage(Message message) throws AmqpException { // 添加延迟消息属性 message.getMessageProperties().setDelay(5000); return message; } }); } 实现延迟消息法二 RabbitMQ (TTL + 死信队列) 1.配置类(配置交换机和队列) 类型 名称 作用 路由键 交换机 order.exchange 业务交换机:接收原始延迟消息 order.delay.key 队列 order.delay.queue 等待队列:消息在此等待TTL过期 - 交换机 order.delay.exchange 死信交换机:接收过期消息 order.delay.key 队列 order.process.queue 处理队列:最终消费消息的队列 - @Configuration public class RabbitMQDelayConfig { // 业务交换机 @Bean public DirectExchange orderExchange() { return new DirectExchange("order.exchange"); } // 死信交换机(作为延迟消息的目标) @Bean public DirectExchange orderDelayExchange() { return new DirectExchange("order.delay.exchange"); } // 业务队列 - 设置死信参数 @Bean public Queue orderDelayQueue() { Map<String, Object> args = new HashMap<>(); // 消息到期后转发的死信交换机 args.put("x-dead-letter-exchange", "order.delay.exchange"); // 死信路由键 args.put("x-dead-letter-routing-key", "order.delay.key"); return new Queue("order.delay.queue", true, false, false, args); } // 最终消费队列 @Bean public Queue orderProcessQueue() { return new Queue("order.process.queue"); } // 绑定:业务队列 -> 业务交换机 @Bean public Binding orderDelayBinding() { return BindingBuilder.bind(orderDelayQueue()) .to(orderExchange()) .with("order.delay.key"); } // 绑定:最终队列 -> 死信交换机 @Bean public Binding orderProcessBinding() { return BindingBuilder.bind(orderProcessQueue()) .to(orderDelayExchange()) .with("order.delay.key"); } } 2. 发送消息(设置TTL) @Service @RequiredArgsConstructor public class OrderService { private final RabbitTemplate rabbitTemplate; public void createOrder(Order order) { // 创建订单逻辑... // 发送延迟消息(30分钟) rabbitTemplate.convertAndSend("order.exchange", "order.delay.key", order.getId(), message -> { // 设置消息的TTL为30分钟 message.getMessageProperties().setExpiration("1800000"); // 毫秒 return message; }); } } 3. 消费者 @Component public class OrderDelayConsumer { @RabbitListener(queues = "order.process.queue") public void processExpiredOrder(String orderId) { // 查询订单状态,如果未支付则取消订单 System.out.println("处理超时订单:" + orderId); } } 超时订单问题 死信交换机 当消息在一个队列中变成“死信(Dead Letter)”后,能被重新投递到的另一个交换机,就是死信交换机(DLX)。 绑定到 DLX 的队列叫死信队列(DLQ),专门用来存放这些“死信”消息。 触发条件 消费者拒绝并不再重投(Consumer Rejection) “消费者这一端”的情况。当消费者明确拒绝消息(发送 basic.reject或 basic.nack)并且设置 requeue=false时,消息会成为死信。 场景:消费者处理消息时遇到无法处理的错误(如业务逻辑错误、数据格式错误),明确告知MQ不要重新投递了。 消息过期(Message TTL Expired) 这与消费者无关。消息在队列中等待的时间超过了设定的生存时间(TTL),会被自动删除并变成死信。 场景:常用于实现延迟队列。例如,下单15分钟未支付订单取消,就可以将消息TTL设为15分钟,过期后成为死信转到DLQ,由DLQ的消费者来处理取消逻辑。 队列溢出(Queue Length Limit Exceeded) 这也与消费者无关。当队列的消息数量达到上限时,新来的消息或队列头部的消息(取决于配置)会被丢弃并变成死信。 场景:用于限制队列容量,防止消息无限堆积,保护系统。 配置 必须用编程式方式来声明,不可用注解式。 @Configuration public class RabbitMQConfig { @Value("${spring.rabbitmq.config.producer.exchange}") private String businessExchangeName; @Value("${spring.rabbitmq.config.producer.topic_team_success.queue}") private String businessQueueName; @Value("${spring.rabbitmq.config.producer.topic_team_success.routing_key}") private String businessRoutingKey; // 1. 定义死信交换机(通常一个应用一个就够了) @Bean public TopicExchange dlxExchange() { return new TopicExchange(businessExchangeName + ".dlx", true, false); } // 2. 定义死信队列 @Bean public Queue dlq() { return new Queue(businessQueueName + ".dlq", true); } // 3. 将死信队列绑定到死信交换机 @Bean public Binding dlqBinding() { return BindingBuilder.bind(dlq()) .to(dlxExchange()) .with(businessRoutingKey + ".dead"); // 使用新的路由键 } // 4. 定义业务交换机 @Bean public TopicExchange businessExchange() { return new TopicExchange(businessExchangeName, true, false); } // 5. 定义业务队列,并配置死信规则(核心!) @Bean public Queue businessQueue() { Map<String, Object> args = new HashMap<>(); // 指定死信交换机 args.put("x-dead-letter-exchange", businessExchangeName + ".dlx"); // 指定死信的路由键(可选,不指定则使用原消息的路由键) args.put("x-dead-letter-routing-key", businessRoutingKey + ".dead"); // 还可以设置其他导致消息成为死信的参数 // args.put("x-message-ttl", 60000); // 消息60秒过期 // args.put("x-max-length", 1000); // 队列最大长度1000条 return new Queue(businessQueueName, true, false, false, args); } // 6. 将业务队列绑定到业务交换机 @Bean public Binding businessBinding() { return BindingBuilder.bind(businessQueue()) .to(businessExchange()) .with(businessRoutingKey); } }
后端学习
zy123
1年前
0
27
0
2025-05-27
Jmeter快速入门
Jmeter快速入门 1.安装Jmeter Jmeter依赖于JDK,所以必须确保当前计算机上已经安装了JDK,并且配置了环境变量。 1.1.下载 可以Apache Jmeter官网下载,地址:http://jmeter.apache.org/download_jmeter.cgi 1.2.解压 因为下载的是zip包,解压缩即可使用,目录结构如下: 其中的bin目录就是执行的脚本,其中包含启动脚本: 1.3.运行 双击即可运行,但是有两点注意: 启动速度比较慢,要耐心等待 启动后黑窗口不能关闭,否则Jmeter也跟着关闭了 2.快速入门 2.1.设置中文语言 默认Jmeter的语言是英文,需要设置: 效果: 注意:上面的配置只能保证本次运行是中文,如果要永久中文,需要修改Jmeter的配置文件 打开jmeter文件夹,在bin目录中找到 jmeter.properties,添加下面配置: language=zh_CN 注意:前面不要出现#,#代表注释,另外这里是下划线,不是中划线 2.2.基本用法 在测试计划上点鼠标右键,选择添加 > 线程(用户) > 线程组: 在新增的线程组中,填写线程信息: 给线程组点鼠标右键,添加http取样器: 编写取样器内容: 添加HTTP Header Content-Type=application/json 添加监听报告: 添加监听结果树: 汇总报告结果: 结果树: 清理结果,一个个监听器清理 或者全部清理: 2.3.保存/导入执行计划 .jmx文件!!!
后端学习
zy123
1年前
0
8
0
1
2
...
4
下一页