
Spring AI + Ollama
1. Ollama
- 定位:本地/容器化的 大模型推理服务引擎
- 作用:负责加载模型、执行推理、返回结果
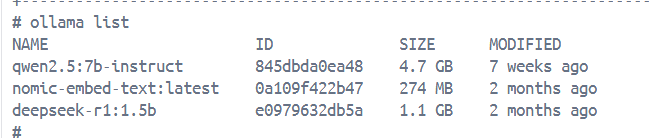
- 支持的模型:Qwen、DeepSeek、nomic-embed-text(embedding 模型)等
- 交互方式:REST API(默认
http://localhost:11434)
ollama run qwen2.5:7b-instruct
2. Spring AI
- 定位:Spring 官方推出的 AI 接入框架
- 作用:统一封装对各种 AI 服务的调用逻辑,让开发者更容易接入(OpenAI、Ollama 等)
- 关键点
OllamaChatModel:封装了调用 Ollama 的对话接口OllamaOptions:指定模型、参数(温度、上下文大小等)PgVectorStore:对接向量数据库(Spring AI 提供的默认向量数据库适配器。)TokenTextSplitter:默认的文本切分器 (Spring AI 内置逻辑)
3.pgVectorStore
pgVectorStore 是 Spring AI 提供的向量存储接口实现,底层基于 PostgreSQL + pgvector 插件。它在项目中的作用:
1)存储向量和元数据:
pgVectorStore.accept(splits);
这行代码会:
1.将 splits 中每个 Document 的 text → 调用 embedding 模型 → 生成向量
2.将生成的向量、原始文本、以及文档元数据统一存入数据库表(默认表名:vector_store);
embedding:存储生成的向量;content:存储原始文本内容;metadata:以 JSONB 形式存储元数据。
2)检索时自动生成 SQL:
List<Document> documents = pgVectorStore.similaritySearch(request);
在执行检索时,pgVectorStore 会自动生成 SQL 查询,
-
解析查询请求中的文本;
-
生成查询向量;
-
自动构造 SQL(结合 pgvector 的
<->向量相似度运算符); -
按相似度排序返回最相关的文档列表。
进一步地,结合 filterExpression(例如 metadata->>'knowledge' = 'xxx')可在相似度计算的基础上进一步进行条件过滤。
配置
ai:
ollama:
base-url: http://ollama:11434 #告诉 Spring AI 去 http://ollama:11434 调用模型接口。
embedding:
options:
num-batch: 512 #批处理参数
model: nomic-embed-text #指定使用的 embedding 模型
rag:
embed: nomic-embed-text
注意,需要提前下载模型:
ollama pull deepseek-r1:1.5b
ollama pull qwen2.5:7b-instruct
ollama pull nomic-embed-text
ollama list
Docker如何开启GPU加速大模型推理
巨坑!
默认是CPU跑大模型,deepseek1.5b勉强能跑动,但速度很慢,一换qwen2.5:7b模型瞬间就跑不动了,这才发现一直在用CPU跑!!
如何排查?
1.查看ollama日志:
load_backend: loaded CPU backend from /usr/lib/ollama/libggml-cpu-alderlake.so
2.本地cmd命令行输入,查看显存占用率。
nvidia-smi
| 0 NVIDIA GeForce RTX 4060 ... WDDM | 00000000:01:00.0 On | N/A |
| N/A 58C P0 24W / 110W | 2261MiB / 8188MiB | 6% Default |
设备状态:
- RTX 4060显卡驱动(576.02)和CUDA 12.9环境正常
- 当前GPU利用率仅6%(
GPU-Util列) - 显存占用2261MB/8188MB(约27.6%)
可见模型推理的时候压根没有用GPU!!!
解决
参考博客:1-3 Windows Docker Desktop安装与设置docker实现容器GPU加速_windows docker gpu-CSDN博客
1)配置WSL2,打开 PowerShell(以管理员身份运行),执行以下命令:
wsl --install -d Ubuntu # 安装 Linux 发行版
wsl --set-default-version 2 # 设为默认版本
wsl --update # 更新内核
- 重启计算机以使更改生效。
2)检查wsl是否安装成功
C:\Users\zhangsan>wsl --list --verbose
NAME STATE VERSION
* Ubuntu Running 2
docker-desktop Running 2
这个命令会列出所有已安装的Linux发行版及其状态。如果看到列出的Linux发行版,说明WSL已成功安装。
3)安装docker desktop默认配置:
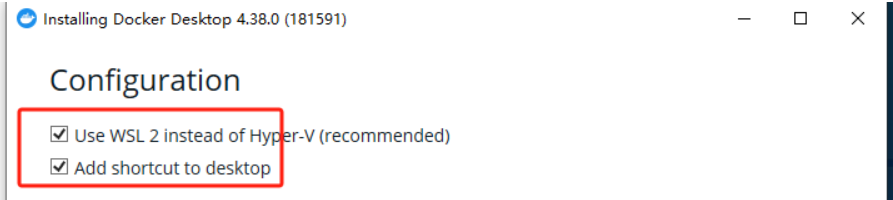
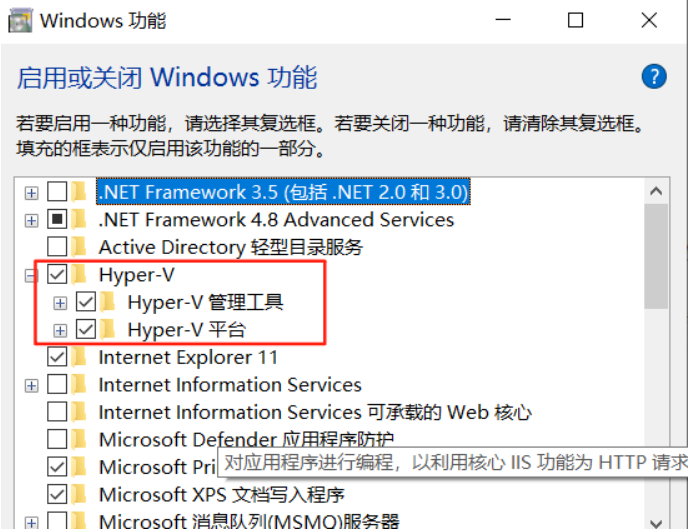
4)保险起见也启用一下开启 Windows 的 Hyper-V 虚拟化技术:
搜索“启用或关闭Windows功能”,勾选:Hyper-V 虚拟化技术。
5) 命令提示符输入 nvidia-smi
C:\Users\zhangsan>nvidia-smi
Tue Aug 19 21:18:11 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 576.02 Driver Version: 576.02 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 ... WDDM | 00000000:01:00.0 On | N/A |
| N/A 55C P4 12W / 129W | 2132MiB / 8188MiB | 33% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
若显示GPU信息(如型号、显存等),则表示支持。
6)Docker Desktop配置**(重要)**
-
打开 Docker 设置 → Resources → WSL Integration → 启用 Ubuntu 实例。
-
进入 Docker 设置 → Docker Engine,添加以下配置:
-
{ "experimental": true, "features": { "buildkit": true }, "registry-mirrors": ["https://registry.docker-cn.com"] // 可选镜像加速 }
-
-
保存并重启 Docker。
7)验证 GPU 加速
docker run --rm -it --gpus=all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
> Windowed mode
> Simulation data stored in video memory
> Single precision floating point simulation
> 1 Devices used for simulation
MapSMtoCores for SM 8.9 is undefined. Default to use 128 Cores/SM
MapSMtoArchName for SM 8.9 is undefined. Default to use Ampere
GPU Device 0: "Ampere" with compute capability 8.9
> Compute 8.9 CUDA device: [NVIDIA GeForce RTX 4060 Laptop GPU]
24576 bodies, total time for 10 iterations: 17.351 ms
= 348.102 billion interactions per second
= 6962.039 single-precision GFLOP/s at 20 flops per interaction
成功输出应包含 GPU 型号及性能指标 [NVIDIA GeForce RTX 4060 Laptop GPU]
8)Ollama验证:
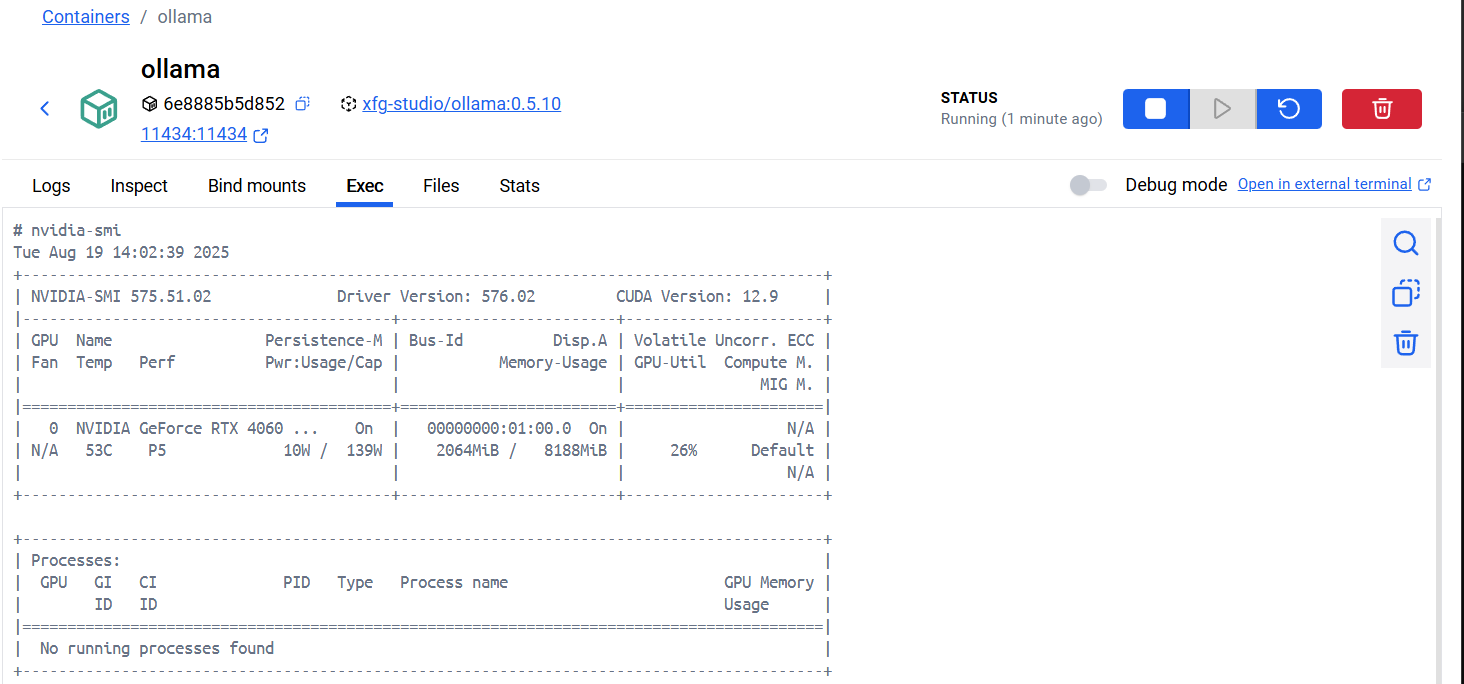
在容器中也能显示GPU了,说明配置成功了!!!
version: '3.9'
services:
ollama:
image: registry.cn-hangzhou.aliyuncs.com/xfg-studio/ollama:0.5.10
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=all
什么原理?
GPU 驱动仍运行在 Windows 主机上;WSL2 作为 Linux 内核子系统,共享访问该 GPU 驱动的底层接口;Docker Desktop 在 WSL2 内运行(作为 Linux 虚拟环境), 通过 NVIDIA Container Runtime (nvidia-container-toolkit) 把 GPU 设备挂载进容器;
最终容器内程序(如 PyTorch、Ollama)能直接使用 GPU 计算。
RAG(检索增强生成)
postgre向量数据库
PostgreSQL也是结构化数据库(关系型数据库)!!!
-
所有数据都遵守固定的结构(Schema);
-
每一列(Column)定义了数据类型;
-
每一行(Row)表示一条记录;
表结构:
@Bean
public PgVectorStore pgVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel) {
return PgVectorStore.builder(jdbcTemplate, embeddingModel).build();
}
PgVectorStore 会自动检测并在首次使用时创建所需的向量表,默认表名是 vector_store;默认表结构是固定格式(id, content, metadata, embedding)。
PgAdmin软件下:ai-rag-knowledge -> 架构 -> public -> 表 -> vector_store
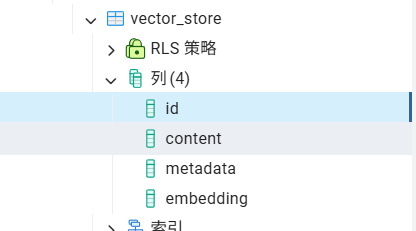
id → 每条数据的唯一标识(主键/uuid)。
content → 存放 chunk 的原始文本。
metadata → 存放 JSON 格式的额外信息(文件名、路径、知识库标签等)。
embedding → 存放向量,类型是 vector(N)(N 由 Embedding 模型决定,比如 768)。
所有文件切分出来的 chunk 都存在这一张表里,每条记录就是一个 chunk。
表的主要用途
1)相似度检索(Retrieval):用embedding <-> 查询向量 进行向量距离计算,找出与输入文本语义最相近的片段。其中<-> 是 pgvector 的距离运算符
2)结果展示(Content Retrieval):检索后,取出距离最近的若干条记录的 content,作为模型回答时的上下文。
3)溯源/过滤:通过 metadata 字段中的信息(如文件名、标签、知识类别等)进行结果筛选或来源追踪,例如:其中 ->> 从 JSON 对象中取出某个字段的值,并以文本(text)形式返回。
INSERT INTO vector_store (content, metadata) VALUES
('公司年度财报分析', '{"knowledge": "finance", "source": "report.pdf"}'),
('销售策略优化', '{"knowledge": "marketing", "source": "plan.docx"}'),
('财务合规指引', '{"knowledge": "finance", "source": "policy.pdf"}'),
('技术架构设计', '{"knowledge": "engineering", "source": "design.md"}');
现在你想只查出属于 “财务领域(finance)” 的内容,可以这样写:
SELECT id, content, metadata
FROM vector_store
WHERE metadata->>'knowledge' = 'finance';
查询
同一般的SQL语句。
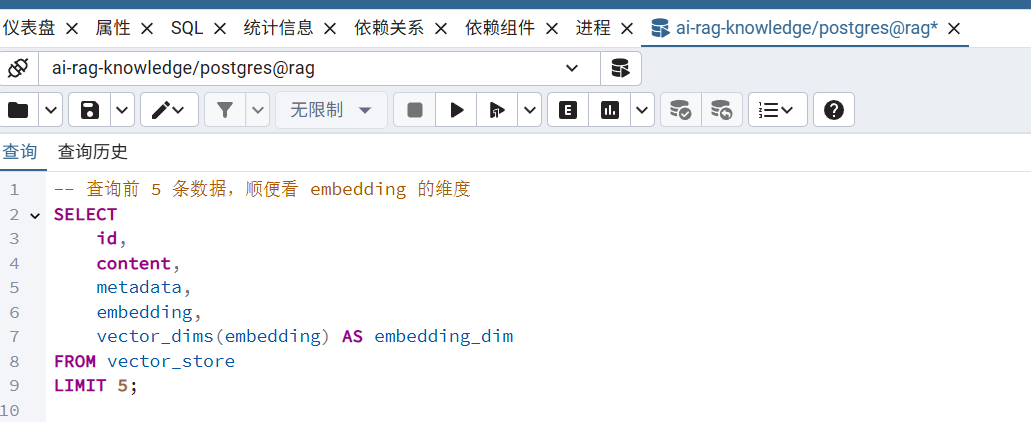

vector_dims(embedding)是内置函数,返回维度大小。
还有 metadata 和embedding 列显示不下。
A. 索引/入库(Ingestion)
这里用了SpringAI提供的:TikaDocumentReader 和 pgVectorStore
-
文档读取器
- 用
TikaDocumentReader把上传的 PDF、Word、TXT、PPT 等文件解析成List<Document>。 - 每个
Document包含text和metadata(比如page、source)。 - 相当于是“把二进制文件 → 转成纯文本段落”。
TikaDocumentReader documentReader = new TikaDocumentReader(resource); List<Document> documents = documentReader.get(); - 用
-
清洗过滤
- 剔除空文本,避免无效数据进入后续流程。
List<Document> docs = new ArrayList<>(documents); docs.removeIf(d -> d.getText() == null || d.getText().trim().isEmpty()); if (docs.isEmpty()) { log.warn("文件内容为空,跳过处理: {}", normalizedPath); return; } -
文档切分器
- 用
TokenTextSplitter把每个Document再切成 chunk(默认 800 tokens 一段,可配置)。 - 目的是避免超长文本超过 Embedding 模型的输入限制。
@Bean public TokenTextSplitter tokenTextSplitter() { return TokenTextSplitter.builder() .withChunkSize(600) // 每段最多 600 token .withMinChunkSizeChars(300) // 每段至少 300 字符 .withMinChunkLengthToEmbed(10) .withMaxNumChunks(10000) .withKeepSeparator(true) .build(); } //使用,省略依赖注入 List<Document> splits = tokenTextSplitter.apply(docs);withMinChunkSizeChars(300): 如果某个切分块的文本少于 300 个字符,TokenTextSplitter会避免直接拆分它,而是尝试 合并它与下一个切分块,直到符合字符数要求。
- 用
-
打元数据
- 给原始文档和 chunk 都加上
knowledge(ragTag)、path、original_filename等信息。 - 方便后续检索时追溯来源。
docs.forEach(doc -> { doc.getMetadata().put("knowledge", ragTag); doc.getMetadata().put("path", normalizedPath); doc.getMetadata().put("original_filename", originalFilename); }); splits.forEach(doc -> { doc.getMetadata().put("knowledge", ragTag); doc.getMetadata().put("path", normalizedPath); doc.getMetadata().put("original_filename", originalFilename); }); - 给原始文档和 chunk 都加上
-
Embedding 模型
- 对 每个 chunk 调用 Ollama 的
nomic-embed-text,生成一个固定维度的向量(如 768 维)。 - 注意:这是对 chunk 整体嵌入,不是对单个 token。
- 对 每个 chunk 调用 Ollama 的
-
向量存储
//配置类 @Bean public PgVectorStore pgVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel) { return PgVectorStore.builder(jdbcTemplate, embeddingModel).build(); } //使用,省略依赖注入 pgVectorStore.accept(splits);- 用
pgvector存储[embedding 向量 + metadata + 原始文本]。 - 向量维度由 Embedding 模型决定,pgvector 表的维度必须保持一致(如 768/1024/1536)。
- 用
B. 检索/回答(Query)
接收用户问题
- 输入用户的问题文本
message。
相似度检索
-
使用同一个 Embedding 模型(如
nomic-embed-text)将问题转为查询向量。 -
在向量库中用 余弦相似度 / 内积 搜索相似 chunk。
-
可附加条件过滤:如
knowledge == 'xxx',只在某个知识库范围内查。 -
常用参数:
topK:取最相似的前 K 个结果(例如 5~8)。minSimilarityScore(可选):过滤低相关度结果。
// 1) 相似度检索(带 ragTag 过滤)
List<Document> documents = pgVectorStore.similaritySearch(
SearchRequest.builder()
.query(message)
.topK(8)
.filterExpression("knowledge == '" + ragTag + "'")
.build()
);
List<Document> documents = pgVectorStore.similaritySearch(request);
拼装文档上下文
- 把检索到的文档片段拼接成系统提示中的 DOCUMENTS 部分。
- 可以在拼接时附带 metadata(如文件名、页码),方便溯源。
String documentContent = documents.stream()
.map(doc -> "[来源:" + doc.getMetadata().get("original_filename") + "]\n" + doc.getText())
.collect(joining("\n\n---\n\n"));
构造提示词(Prompt)
- 使用
SystemPromptTemplate注入 DOCUMENTS 内容。 - System Prompt 应该放在 用户消息之前,确保模型优先遵循规则。
Message ragMessage = new SystemPromptTemplate(SYSTEM_PROMPT)
.createMessage(Map.of("documents", documentContent));
List<Message> messages = new ArrayList<>();
messages.add(ragMessage); // 先放系统提示
messages.add(new UserMessage(message));
调用对话模型(流式返回)
return ollamaChatModel.stream(new Prompt(
messages,
OllamaOptions.builder().model(model).build()
));
优化
1.优化分词逻辑
这块比较复杂,要切的恰到好处...切的不大不小。
2.更新向量嵌入模型
MCP服务
MCP 是“模型与外部世界沟通的桥梁”。它让模型不仅能聊天,还能调用本地文件系统、数据库、网络 API 等服务,实现“有工具可用的 AI”。
基础介绍
| 角色 | 说明 | 举例 |
|---|---|---|
| 🖥️ MCP Server(服务端) | 提供“工具能力”,比如操作文件系统、调用系统命令、执行数据库查询等。 | @modelcontextprotocol/server-filesystem、mcp-server-computer.jar |
| 🤖 MCP Client(客户端) | 嵌入在应用(你的 Spring Boot)中,让模型能访问这些工具。 | 由 spring-ai-mcp-client-webflux-spring-boot-starter 实现 |
快速使用
1)引入依赖(POM)
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-client-webflux-spring-boot-starter</artifactId>
</dependency>
2)配置 MCP 服务(Server)
创建配置文件:resources/config/mcp-servers-config.json
{
"mcpServers": {
"filesystem": {
"command": "npx.cmd",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"D:/folder/MCP-test",
"D:/folder/MCP-test"
]
},
"mcp-server-computer": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-jar",
"D:/folder/study/apache-maven-3.8.4/mvn_repo/edu/whut/mcp/mcp-server-computer/1.0.0/mcp-server-computer-1.0.0.jar"
]
}
}
}
filesystem:定义了一个 MCP 文件系统服务;
- 通过
npx启动; - 调用包
@modelcontextprotocol/server-filesystem; - 并将本地路径
D:/folder/MCP-test暴露给模型访问。
mcp-server-computer:定义了一个自定义的 Java MCP 服务;
- 使用
java -jar启动; - 通过标准输入输出(
stdio)与主程序通信。
Spring配置文件(application.yml)配置 MCP 服务加载路径
spring:
ai:
mcp:
servers-config: classpath:config/mcp-servers-config.json
3)安装并启用 Filesystem MCP 服务
需要提前下载该文件服务,官网: https://www.npmjs.com/package/@modelcontextprotocol/server-filesystem (创建、移动目录,读取、写入文件...)
-
先装 Node.js,配置环境变量
node -v npm -v -
安装 MCP 文件系统服务
npm install -g @modelcontextprotocol/server-filesystem
4)配置客户端
Spring AI 通过 ChatClient 调用大模型,如果你使用多个模型(如 Ollama、OpenAI),可以通过不同的 ChatModel Bean 实例来区分。
@Bean
public OllamaChatModel ollamaChatModel(OllamaApi ollamaApi) {
return OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build())
.build();
}
@Bean
public ChatClient.Builder chatClientBuilder(OllamaChatModel ollamaChatModel) {
return new DefaultChatClientBuilder(
ollamaChatModel,
ObservationRegistry.NOOP,
(ChatClientObservationConvention) null
);
}
注意,ollamaChatModel()是基础模型,创建与Ollama服务交互的底层Chat模型;chatClientBuilder()是客户端构建器,提供高级功能封装(如工具调用)
5)模型调用示例
ollamaChatModel 是连接本地 Ollama 服务的客户端; 具体使用哪个模型(deepseek-r1:1.5b、qwen2.5:7b-instruct 等)是在调用时通过 OllamaOptions 决定的:
ChatResponse response = chatClientBuilder
.defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build())
.build()
.prompt("你好,介绍一下你自己")
.call();
6)测试 MCP 调用
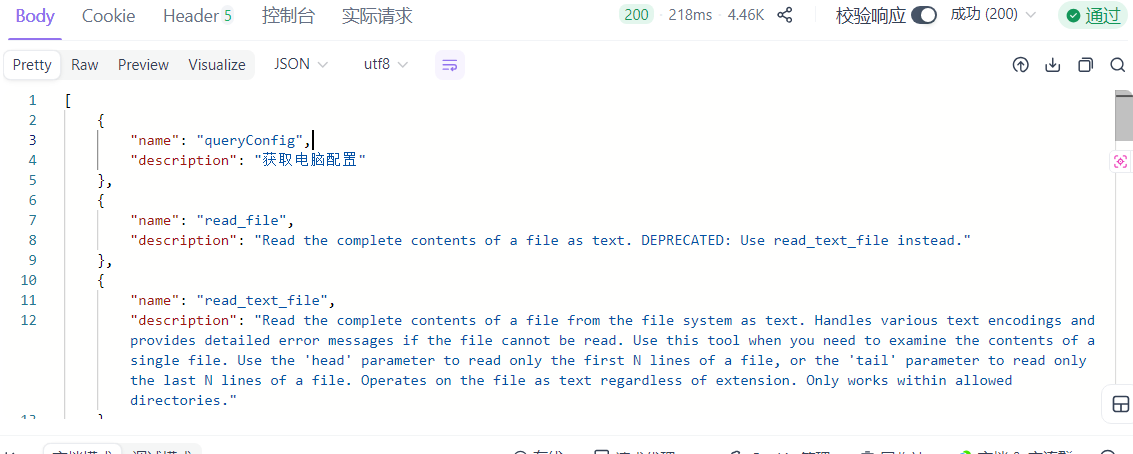
查看当前可用工具
@GetMapping("/tools")
public Object listTools() {
return Arrays.stream(tools.getToolCallbacks())
.map(cb -> Map.of(
"name", cb.getName(),
"description", cb.getDescription()
))
.toList();
}
自动调用工具(含 MCP)
@GetMapping("/test-workflow")
public String testWorkflow(@RequestParam String question) {
var chatClient = chatClientBuilder
.defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build())
.build();
return chatClient.prompt(question).tools(tools).call().chatResponse().toString();
}
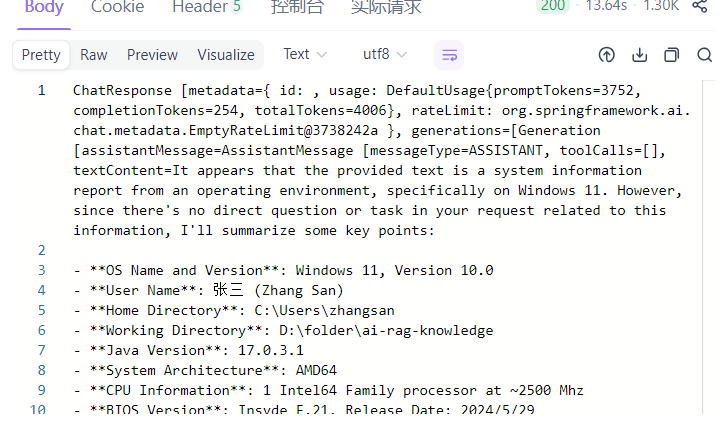
当模型发现某个问题需要使用外部工具(如文件读写、计算服务)时,会自动调用注册在 MCP 中的工具进行操作。
有时候大模型不会去调用Tools,可能是模型能力不够。
注意,docker部署后,这个路径还没改!!!自然查不到可用的工具,因为不是在本地windows中了。
自定义MCP服务
目录结构
mcp-server-demo/
├─ src/
│ └─ main/
│ ├─ java/…/DemoApplication.java
│ ├─ java/…/NoteService.java // 你的工具:@Tool 方法
│ └─ resources/application.yml // 仅需几行
└─ pom.xml
POM 依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
关键配置
spring:
application:
name: mcp-server-demo
ai:
mcp:
server:
name: ${spring.application.name}
version: 1.0.0
# 让它安静点,避免把 MCP JSON 混进正常日志
logging:
level:
org.springframework.ai.mcp: INFO
pattern:
console:
server:
main:
banner-mode: off
# 非 Web 进程(可选)
# web-application-type: none
入口 & 工具
DemoApplication.java
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
启动配置。
NoteService.java
@Service
public class NoteService {
@Tool(description = "把输入转成大写并附带字符数")
public Map<String, Object> toUpper(
@ToolParam(name = "text", description = "要转换的文本") String text) {
if (text == null) text = "";
return Map.of(
"upper", text.toUpperCase(),
"length", text.length()
);
}
}
注意,你的服务方法必须配置 @Tool(description = "获取电脑配置")
多一个注解,就向外多提供一个工具!!!
生成Jar包
在客户端项目中引用
{
"mcpServers": {
"mcp-server-demo": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-jar",
"C:/path/to/target/mcp-server-demo-1.0.0.jar"
]
}
}
}
注意上一步生成的jar包要放到这个"C:/path/to/target/mcp-server-demo-1.0.0.jar"中。
底层调用逻辑
一、启动客户端
假设你运行的客户端配置里包含:
"mcpServers": {
"filesystem": {...},
"mcp-server-computer": {...}
}
当客户端启动时,会做以下几步:
1)客户端启动子进程
客户端发现你声明了两个 MCP 服务器,于是准备分别启动它们。
npx.cmd -y @modelcontextprotocol/server-filesystem D:/folder/MCP-test D:/folder/MCP-test
java -Dspring.ai.mcp.server.stdio=true -jar D:/folder/.../mcp-server-computer-1.0.0.jar
这两个命令都会启动新的独立进程,“挂在”客户端进程下面,通过标准输入/输出通信。
2)客户端 → 服务端 “握手”(initialize)
客户端通过每个子进程的 stdin 写入 MCP 初始化请求:
{
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {
"clientInfo": {"name": "MyClient", "version": "1.0"},
"capabilities": {}
}
}
3)服务端 → 客户端 回应握手结果
你的 mcp-server-computer.jar在内部收到这个 JSON-RPC 请求后,返回:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"serverInfo": {"name": "mcp-server-computer", "version": "1.0.0"},
"capabilities": {"tools": true}
}
}
客户端读取这条 JSON(从 stdout),于是握手成功
4)客户端请求工具清单
紧接着客户端发:
{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/list",
"params": {}
}
服务端返回:
{
"jsonrpc": "2.0",
"id": 2,
"result": {
"tools": [
{ "name": "queryConfig", "description": "获取电脑配置", ... }
]
}
}
客户端现在就知道:“这个 MCP Server 提供一个叫 queryConfig 的工具”。
二、用户发起请求
1)用户发起问题:“请读取这台电脑的配置”。
2)客户端构造 Chat 请求
将用户消息 + 系统消息 + 工具的 JSON Schema(名称、入参、描述)一起发给大模型。
请求里不仅包含用户输入,还要告诉模型——“你可以调用这些工具,这些工具的参数长这样。”
在 Spring AI 中,这一步通常由 ChatClient 或底层 ChatModel 完成
@GetMapping("/test-workflow")
public String testWorkflow(@RequestParam String question) {
log.info("Workflow测试请求接收 - 问题: {}", question);
var chatClient = chatClientBuilder
.defaultOptions(OllamaOptions.builder().model("qwen2.5:7b-instruct").build())
.build();
ChatResponse response = chatClient
.prompt(question)
.system("你必须使用提供的工具完成任务,禁止凭空回答;若没有调用任何工具,不要返回答案。")
.tools(tools)
.call()
.chatResponse();
log.info("工具调用情况: {}", tools.getToolCallbacks());
log.info("模型响应: {}", response);
return response.toString();
}
实际发送给模型的底层 payload 类似这样:
{
"model": "qwen2.5:7b-instruct",
"messages": [
{
"role": "system",
"content": "你必须使用提供的工具完成任务..."
},
{
"role": "user",
"content": "在 D:/folder/MCP-test 下创建配置.txt..."
}
],
"tools": [
{
"type": "function",
"function": {
"name": "queryConfig",
"description": "获取电脑配置(操作系统、用户信息、Java环境等)",
"parameters": {
"type": "object",
"properties": {
"computer": {
"type": "string",
"description": "电脑名称,可为空"
}
}
}
}
},
{
"type": "function",
"function": {
"name": "write_file",
"description": "创建一个文件并写入内容",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string"},
"content": {"type": "string"}
}
}
}
}
],
"tool_choice": "auto"
}
3)模型分析任务 → 决定调用哪个工具
大模型在接收到 prompt 后,会“思考”:
“要回答这个问题,我需要外部信息吗?” “有一个叫 queryConfig 的工具能获取电脑配置,那我就调用它。”
现代指令模型(包括 Qwen、GPT-4o、Claude、Llama)都经过一种专门的微调(finetune):
当输入里包含
"tools"、"parameters"、"function"这样的字段时, 模型学会:
- 识别哪些任务需要调用工具;
- 生成标准 JSON 格式的
tool_calls;- 不胡编乱造工具名;
- 遵守 schema 中参数名的拼写和结构。
于是它返回结构化响应(OpenAI function-calling 格式):
{
"id": "chatcmpl-01",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"tool_calls": [
{
"id": "call_1",
"type": "function",
"function": {
"name": "queryConfig",
"arguments": "{\"computer\": \"DESKTOP-01\"}"
}
}
]
}
}
]
}
4)客户端执行工具调用(MCP 调用链)
Spring AI 的 DefaultToolCallingManager 会检测到(框架自动实现):
if (response.hasToolCalls()) {
executeToolCalls(response.getToolCalls());
}
客户端解析出模型请求调用的工具名 queryConfig,然后通过 MCP 协议向对应的 MCP Server(你的 mcp-server-computer)发送调用请求(通过 stdin):
{
"jsonrpc": "2.0",
"id": 3,
"method": "tools/call",
"params": {
"name": "queryConfig",
"arguments": { "computer": "DESKTOP-01" }
}
}
注意,默认的工具名就是函数名!!!
你的 MCP Server(Spring Boot 进程)接收后,由框架自动路由到 @Tool 方法:
@Service
public class ComputerService {
@Tool(description = "获取电脑配置")
public ComputerFunctionResponse queryConfig(
@ToolParam(name = "computer", description = "电脑名称") String computer
) {
log.info("获取电脑配置信息: {}", computer);
// 读取系统属性 + systeminfo 等命令
...
return response; // 返回 JSON 对象
}
}
6)客户端将结果反馈回模型(第二轮)
客户端收到结果后,会把它作为新的上下文输入发回模型:
{
"role": "tool",
"tool_call_id": "call_1",
"name": "queryConfig",
"content": "{\"osName\": \"Windows 11\", ... }"
}
模型在这时再进行一轮“总结性思考”:
“我得到了电脑配置结果,可以组织成自然语言回答。”
最终返回:
{
"role": "assistant",
"content": "你的电脑运行的是 Windows 11,架构为 x64,用户名为 Jerry。"
}
sequenceDiagram
participant User
participant Client
participant Model
participant MCPServer as MCP Server
User->>Client: "请读取这台电脑的配置"
Client->>Model: 封装 Prompt + Tool Schema<br/>发送请求
Model-->>Client: 返回 tool_calls: queryConfig(...)
Client->>MCPServer: 通过 MCP stdin 发送<br/>tools/call 请求
MCPServer-->>Client: 执行 Java @Tool 方法<br/>返回 JSON 结果
Client->>Model: 将工具结果再发给模型
Model-->>Client: 生成自然语言回答
Client-->>User: 输出最终文本
如果有长的调用链
当模型需要调用多个工具(例如:create_directory → queryConfig → write_file),
Spring AI 会自动进入一个「循环式调用流程」,直到模型自己不再请求调用工具为止。
框架就会自动:
1.发现模型要调用工具;
2.执行工具;
3.把结果回灌给模型;
4.模型如果再要求调用下一个工具,再执行;
5.一直到模型返回纯文本。
while (true) {
ChatResponse response = model.call(currentPrompt);
if (response.hasToolCalls()) {
// 1. 模型请求调用工具
for (ToolCall call : response.getToolCalls()) {
Object result = executeTool(call.name, call.arguments);
// 2. 把结果封装成“tool_result”消息
currentPrompt.addToolResult(call.id, call.name, result);
}
} else {
// 没有工具调用 = 模型给出最终自然语言
return response;
}
}