首页
关于
Search
1
同步本地Markdown至Typecho站点
108 阅读
2
微服务
43 阅读
3
苍穹外卖
36 阅读
4
JavaWeb——后端
28 阅读
5
动态图神经网络
20 阅读
后端学习
项目
杂项
科研
论文
默认分类
登录
推荐文章
推荐
拼团设计模式
项目
8月11日
0
8
0
推荐
拼团交易系统
项目
6月20日
0
29
1
推荐
Smile云图库
项目
6月7日
0
40
0
热门文章
108 ℃
同步本地Markdown至Typecho站点
项目
3月22日
0
108
0
43 ℃
微服务
后端学习
3月21日
0
43
0
36 ℃
苍穹外卖
项目
3月21日
0
36
0
最新发布
2025-10-29
Cursor使用
Cursor 插件、环境安装 1)Chinese (Simplified) Language Pack,中文界面插件。 2)Extension Pack for Java 只要安装了 “Extension Pack for Java”,其它插件(Maven、Debugger、Language Support、Test Runner、Project Manager 等)都是它自动帮你装好的,不需要你一个个手动点安装。 这样打开项目文件夹(包含 pom.xml 的根目录)时: 它会自动检测项目类型 → 加载 Maven → 解析依赖。底部出现 Java: Ready、Building [Done],说明依赖已经下载并索引完毕。默认使用的是系统环境变量MAVEN_HOME的地址。 或者在这里指定: 自动选择jdk版本: 查看pom中配置,Cursor 会用这个版本作为编译目标。 <properties> <java.version>1.8</java.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> 运行时版本由“系统环境或 Cursor 配置”决定,系统变量里的 JAVA_HOME,就是 你系统默认使用的 JDK。随便打开一个终端 java -version ,可以看到使用的是jdk17。 3) Spring Boot Extension Pack 左侧多出一个 Spring Boot Dashboard; 自动识别所有带 @SpringBootApplication 的项目; 可以直接在面板里点击 ▶️ 启动; application.yml会出现智能提示,比如: spring.datasource.url spring.datasource.username spring.datasource.password 4)IntelliJ IDEA Keybindings 装上它之后,你在 Cursor 里按的快捷键和 IDEA 几乎一样; 5)“Want to launch Cursor from the command line? You can add the code or cursor commands now, or later with Ctrl+Shift+P and typing ‘install code command’.” 这是一个 可选的小功能提示,翻译:“想要从命令行启动 Cursor 吗?你可以现在添加 code 或 cursor 命令,也可以之后按 Ctrl + Shift + P,输入 install code command 来添加。” 作用:直接通过命令行(例如 PowerShell、CMD、终端),打开项目或文件。 cursor . 表示: 用 Cursor 打开当前文件夹(.) 或者:cursor C:\project\group-buying-sys 表示: 用 Cursor 打开指定路径下的项目。 如何查看配置? Ctrl+shift+P 快捷键,输入 open user settings 可以打开用户配置。 输入 project setting 可以打开项目配置文件 或者左下角JAVA PROJECTS,点击Configure JAVA Runtime: 运行JAVA项目 Maven编译 运行 1)打开启动类,点击run/debug 2) 编辑器界面 ┌────────────────────────────────────────────┐ │ 顶部菜单栏(File / 编辑 / 选择 / 查看...)│ ├────────────────────────────────────────────┤ │ 左侧侧边栏(文件树 / 项目 / Git 等) │ ├────────────────────────────────────────────┤ │ 中间主编辑区(代码编辑) │ ├────────────────────────────────────────────┤ │ 右侧 AI 面板(Cursor 智能助手 / Chat) │ ├────────────────────────────────────────────┤ │ 底部状态栏(分支 / 文件类型 / 行列信息等) │ └────────────────────────────────────────────┘ 如何使用 Cursor 的 AI 功能 功能 作用 快捷键(默认) 🧠 Inline Edit 选中一段代码 → Ctrl + K(或右键 “Ask Cursor”)→ 输入自然语言指令(如“优化正则表达式”) Ctrl + K 🤖 Agent 面板 打开一个“聊天窗口”,直接和 Cursor 对话(如“帮我写个登录验证函数”) Ctrl + I ✨ Tab 补全 在代码中输入时,Cursor 自动预测后续内容 Tab 🔁 重新生成建议 当灰色提示出现但不理想时,按 `Alt + ``(或右键 “Regenerate”) `Alt + `` 选择一段代码+CTRL+K 修改指定的代码,直接在代码编辑区弹出修改窗口调用大模型。CTRL+ENTER 或者鼠标点击 应用修改 CTRL+N 或者 **鼠标点击 **拒绝修改 CTRL+I 1)图中设置的Auto表示自动选择模型; 2)@ 可以添加文件、文件夹到当前对话上下文,如果你在代码编辑区选择一段代码再 CTRL+I 或者 CTRL+L,也会自动将它添加进来。还可以直接拖拽资源管理器中的文件到AI对话框中。 3)+Browser 模式可以让模型看到整个项目文件 任务 你可以直接问 Cursor 找函数定义 “verifyPassword 函数定义在哪个文件?” 查找引用 “verifyCode 被调用了多少次?” 理解架构 “帮我总结整个项目的模块结构。” 改代码 “把所有 JS 文件里的 var 改成 let。” 生成文档 “根据这个项目代码生成一份 README。” 4)对话模式 Agent模式,默认的对话模式,功能最全,AI 不仅能回答,还会“主动思考、规划和执行”。可以理解为:“帮我干活”的模式。 Plan 模式,它可以浏览整个项目文件,但不会直接改代码,而是会:把你的需求拆分成多个步骤;告诉你“下一步该干什么”;有时生成一份修改计划或脚本方案。 Ask 模式:问答模式,和网页版使用大模型一样。 TAB 一般注释起手,如果出现灰色预测文字时,直接 Tab 就能接受 AI 自动补全 ,按ESC可以拒绝这个建议;否则就是普通的缩进。 触发逻辑 传统 IDE(比如 VS Code、IntelliJ) 的补全是词法或语法级触发: 你输入 “pri” → 提示 “print()”; 它只是基于关键字匹配。 而 Cursor 的补全 是“语义级”的: AI 根据上下文 推断你下一步可能在做什么。 它会综合考虑: 当前光标前后的代码; 注释 / 函数签名; 文件名; 项目中的其他定义; 甚至最近你在这个 Tab 里做的事。 阶段 触发动作 AI 响应 检测阶段 监听输入变化(按键、换行、注释等) 分析上下文语义树(AST) 预测阶段 生成“意图向量” 模型推断用户下一步目标 展示阶段 在光标后显示灰色 ghost text 等待你按 Tab 接受 触发时机 类型 触发条件 示例 行为 函数触发 输入 function / def function check... 预测参数和函数体 控制语句触发 输入 if / for 等 if (phone) 预测条件或逻辑块 注释触发 输入 //、#、/** // 校验邮箱格式 按注释生成实现 模板触发 class / import / try class User 预测类体、导入内容 上下文模仿 类似已有代码块 第二个函数定义 模仿风格 文件结构触发 同名模块、utils utils. 补出函数名 空行预测 新行、缩进后 空一行 猜测下一个合逻辑语句 Index&Docs Codebase Indexing(代码索引): Cursor 会扫描整个项目文件夹; 提取文件路径、函数定义、类名、依赖关系; 生成语义向量(embeddings)并存储(只保存索引,不上传源代码)。 界面说明:索引完成度100%;已被索引的文件数量为 78; Index New Folders: 当你创建或添加新文件夹时,Cursor 是否自动索引它。 Ignore Files in .cursorignore: 告诉 Cursor 哪些文件不要被索引。类似.gitignore Docs(文档索引): 可以手动添加官方文档、API 文档、开发指南,让它当作参考知识。 添加一个 README.md 或内部 API 规范; 或添加外部文档(如一个 SDK 的文档网站); 之后在 Chat 里用 @doc 引用 如何撤销修改 在AI编辑窗口提问,应用修改,点击Accept 应用完之后,若想回退版本,可以点击提问右边的回撤箭头。 整体思路(重要) 1)先打开项目,然后用browser模式,让AI对这个项目生成一个 .cursorignore 文件,自动忽略哪些文件无需添加进上下文。 2)打开设置,Index&docs,重新索引一下。 3)把项目相关的需求文档、接口文档、技术文档,全部录入到docs中,作为知识库以作备用。这与项目代码文件夹解耦的。 4)在项目根目录下创建 .cursorrules 文件,不需要 @ 引用,自动生效。 .cursorrules 就是 Cursor 的 AI 指令与代码风格规则文件,用来告诉 AI:在这个项目里写代码、命名、注释、格式化时都按照这些规则来做。是一个 系统级提示词 。 eg: ai_behavior: - 所有回答必须使用中文 - 代码中添加必要的注释 style: indentation: 4 spaces naming_convention: variables: camelCase AI 背后接收到的系统指令:你是一个 Java 开发助手。 遵循以下项目规则: 所有回答必须使用中文。 代码中添加必要的注释。 使用 4 空格缩进。 变量名使用 camelCase。 用户请求: 「写一个计算阶乘的 Java 函数」。
杂项
zy123
10月29日
0
4
0
2025-09-20
deepwalk
DeepWalk DeepWalk 的最终目标是—— 把图中的每个节点,用一个低维向量表示(embedding)出来,使得结构相似的节点在向量空间中也接近。 也就是说,如果两个节点在图上经常“一起出现”(相连、同社群等),那它们的 embedding 也应该相似。 主要思想 将图结构转化为“序列语料”: 在图上做 随机游走(random walks),生成顶点序列,类似于自然语言中的“句子”。 将随机游走得到的序列输入 Skip-Gram 模型,学习节点的低维嵌入表示。 学到的嵌入能捕捉到 邻居相似性、社区结构,可用于分类、聚类、链路预测等任务。 输入 & 输出 输入:图结构 $G=(V,E)$,随机游走参数(步长 $t$,次数 $\gamma$,窗口大小 $w$),嵌入维度 $d$。 输出:节点嵌入矩阵 $\Phi \in \mathbb{R}^{|V|\times d}$。 关键公式与目标 随机游走生成“句子”: 从某个顶点 $v_i$ 出发,采样一个长度为 $t$ 的随机游走序列: $$ W_{v_i} = (v_i, v_{i+1}, \dots, v_{i+t}) $$ 生成的序列 $W_{v_i}$ 就是一句“话”,用来训练 Skip-Gram 模型。在这些序列中,如果两个节点经常在相邻位置出现,就表示它们关系密切。 ["A", "B", "C", "D"] Skip-Gram 目标函数: 现在我们用 Word2Vec 的思想:对于一句话 ["A", "B", "C", "D"],假设窗口大小 $w = 1$,也就是每个节点只看它的邻居。那么训练样本是这样的: 中心节点 它要预测的邻居 A B B A, C C B, D D C 模型要学的是: “给我节点 B,我要能预测出 A 和 C。” “给我节点 C,我要能预测出 B 和 D。” 于是就有这个公式,给定中心节点 $v_i$,最大化其上下文窗口内邻居节点的条件概率: $$ \max_{\Phi} \sum_{i=1}^{|V|} \sum_{u \in \mathcal{N}_w(v_i)} \log Pr(u \mid \Phi(v_i)) $$ 其中 $\mathcal{N}_w(v_i)$ 表示在随机游走序列中,窗口大小 $w$ 内的上下文节点。 我希望模型能学到这样一种 embedding:中心节点 $v_i$ 能够高概率预测出它周围的邻居 $u$。 优化形式(负对数似然): 就是把上面的最大化目标,改写成一个最小化损失函数。 最大化“好事”(邻居出现的概率)= 最小化“坏事”(邻居预测错误的概率) $$ \min_{\Phi} - \log Pr\big( {v_{i-w},\dots,v_{i+w}} \mid \Phi(v_i) \big) $$ 概率建模(Hierarchical Softmax 或 Negative Sampling): $$ Pr(u \mid \Phi(v_i)) = \frac{\exp\big( \Phi(u) \cdot \Phi(v_i) \big)}{\sum_{v \in V} \exp\big( \Phi(v) \cdot \Phi(v_i) \big)} $$ 这相当于用 Softmax 把所有节点的相似度转成概率分布。 其中: 分子:中心节点和邻居节点的相似度(点积越大越相似); 分母:所有节点的相似度和(用来归一化成概率)。 如果 $u$ 是 $v_i$ 的邻居,那么 $\Phi(u)$ 与 $\Phi(v_i)$ 的点积就应更大。 例子 想象你是个“社交分析师”: 你观察到小明每天都和小红、小刚一起出现; 而小明几乎从不和小李在一起; 那你自然会说:小明和小红、小刚的关系更近。 DeepWalk 就是通过“随机游走 + 预测邻居”这个机制, 自动学出“谁跟谁关系近”的数值表示。 训练逻辑 1)加载 10+1 张图 A_list = [A100, A101, ..., A110] 我们取前 10 张作为输入,最后一张作为真实标签。 2)对每一个时间步的图做 DeepWalk for t in range(100, 110): emb_t = DeepWalk(A_t) 每张图 $A_t$ 都独立训练一个 节点 embedding(比如 400×64)。 400是节点数,64是嵌入维数 embedding 就是每个节点在这一时刻的“语义坐标”。 训练目标是:让在图里常相邻的节点在 embedding 空间也靠得近。 可以理解成: DeepWalk 把图结构变成“节点的向量表示”。 3)拼接成时间序列特征(10步) 对每对节点 (i, j),你把过去10个时间步的 embedding 拿出来,计算每步的 Hadamard积(元素乘): feats = [emb100[i]*emb100[j], emb101[i]*emb101[j], ..., emb109[i]*emb109[j]] X_ij = concatenate(feats) 每个节点对 (i, j) → 一个 10×64 = 640 维的特征; 这 640 维包含了它俩“过去10步的相似度变化轨迹”。 白话理解: 这个特征就像是“节点对关系的时间切片”。 如果两人(节点)经常靠得近 → 向量相似; 如果逐渐靠近 → 特征会呈现变化趋势。 4)第11步图作为真实答案(标签) A_target = A110 y_ij = 1 if 节点i和j在第110步相连 else 0 每个节点对 (i, j) 的标签就是第11步的真相; 如果在第11步有边 → 正样本; 没边 → 负样本。 5)平衡样本(1:1) 因为稀疏图中没连边的太多: 原来是 9,237 个正样本 vs 70,563 个负样本; 现在我们随机保留同样数量的负样本; 所以训练时正负样本平衡:9,237 : 9,237。 ✅ 这样模型不会再“全猜没边”。 6)训练 MLP 来做预测 MLP(X) → 输出每个节点对在第110步连边的概率 输入:每个节点对的 640 维特征; 输出:一个 [0,1] 概率; Loss:二分类交叉熵(BCELoss); 优化器:Adam。 🧠 白话解释: MLP 在学“什么样的历史关系轨迹会导致下一步产生连接”。 7)用真实 A110 对照预测结果 模型预测完后: 它给每对节点一个连边概率; 我们用阈值 0.5 分成「有边/无边」; 然后与真实的 $A_{110}$ 比较,得到: 指标 含义 AUC=0.8279 模型能区分哪些节点会连边、哪些不会(非常好) ACC=0.7223 有约 72% 的节点对被正确分类(相对平衡后的准确率) (1)静态图版本 你只有一张图,比如社交网络的当前关系: DeepWalk 学出 embedding; 然后用 MLP 或逻辑回归,预测那些“目前没边但 embedding 很接近”的节点对; 这些就是「潜在朋友」→ 即未来可能建立连接的边。 📘 所以静态链路预测其实是: 用当前结构的 embedding 相似度,预测将来是否可能连边。 (2)动态图版本 你有多帧图,比如第100~109步(连续的10个时间片): 每一步都用 DeepWalk 得到 embedding; 然后把每个节点对的“10帧特征”拼起来; 喂给 MLP 预测第110步是否连边。 📘 动态版本其实是: 把「节点关系的历史轨迹」作为输入, 预测下一个时间步的关系变化。 DeepWalk 的本质: 是一个 图嵌入算法(Graph Embedding Method), 输入图结构,输出节点的向量表示(embedding)。 也就是说: 每次运行 DeepWalk,相当于重新学习节点的 embedding; embedding 本身就是最终结果,不需要“恢复模型状态”去推理; 它不具备像神经网络那样“泛化到新数据”的功能。 所以: ✅ DeepWalk 的输出 = checkpoint ✅ DeepWalk 的 embedding = 可直接保存 / 复用的结果 ❌ 不需要保存训练中间的模型权重
论文
zy123
9月20日
0
2
0
2025-09-20
移动模型
移动模型 RWP(Random Waypoint,随机路标) 空间与时间: 在一个正方形活动区域 $[0,R]\times[0,R]$ 内,离散为 steps 个时间步。 节点运动规则: 初始位置:每个节点在区域内均匀随机选一个起点。 选目标点:从区域内均匀随机再选一个目标点(下一路标)。 速度:对该段路程,从区间 $[v_{\min}, v_{\max}]$ 均匀采样一个速度(以“每步移动的距离”计)。 运动轨迹:用直线匀速插值从当前点走到目标点,按需要的步数填充每个时间步的坐标。 停留:到达目标后,停留 pause_steps ~ U[pause_min, pause_max](整数步)。 循环:停留结束后再选一个新的随机目标点,重复 3–5。 输出轨迹: 把每个时间步所有节点的 $(x,y)$ 位置拼成矩阵 $Y\in\mathbb{R}^{\text{steps}\times 2N}$。 邻接生成(通讯图): 对每个时间步,任意两节点距离 $\le$ 通讯半径 comm_radius 则记为一条无向边(1),否则为 0,得到一组对称的 0/1 邻接矩阵序列。 要点:RWP 的目标点在区域内+“可停留”,因此轨迹呈 跳点—直线—驻留的节奏。 RW(Random Walk,随机游走) 空间与时间: 活动区域仍是边长 $R$ 的正方形(或你实现里也支持圆形采样作为初始点)。离散 steps。 节点运动规则: 初始位置:在活动区域内随机取一个点作为起点。 目标点:每次从一个随机边界点或区域内随机点中挑一个当目标(你的实现是 5 种可能:四条边上的均匀点或区域内随机点)。 速度:每段从 $[v_{\min}, v_{\max}]$ 均匀采样一个速度。 运动轨迹:按直线匀速插值走向目标。 无停留:到达目标立即选择下一目标继续走(不驻留)。 循环:重复 2–4。 邻接生成: 与 RWP 相同,以 comm_radius 做阈值逐步形成 0/1 邻接矩阵。 要点:RW 版本不设停留,且目标点常在边界,轨迹更“连续流动”,在边界附近来回穿梭的概率更高。 RD(Random Direction,随机方向) 空间与时间: 同样是正方形区域与离散时间。 节点运动规则: 初始位置:从边界上均匀随机选一个起点(四条边等概率)。 目标点:每段都从边界再均匀随机选一个新的边界点当目标(边界→边界)。 速度:每段速度 $[v_{\min}, v_{\max}]$ 均匀采样。 运动轨迹:直线匀速插值到目标。 停留:到达目标后停留 pause_steps ~ U[pause_min, pause_max] 步。 循环:继续从目标(边界点)出发,选下一个边界点为新目标。 邻接生成: 同上,按 comm_radius 阈值逐步构造邻接矩阵序列。 要点:RD 强化了边界—边界往返与停留,节点会频繁在边缘聚集、驻留,再切换到另一边。 Gaussian Markov Mobility(高斯-马尔科夫移动模型) 空间与时间: 在矩形区域 $[x_{\min}, x_{\max}] \times [y_{\min}, y_{\max}]$ 内,离散为多个时间步。 节点运动规则: 初始状态:每个节点随机生成位置 $(x,y)$,速度 $v \sim U(0.5, v_{\max})$,方向 $\theta \sim U(0,2\pi)$。 速度更新: $v_t = \alpha v_{t-1} + (1-\alpha)\mu_v + \sqrt{1-\alpha^2},\varepsilon_v,$ 其中 $\mu_v$ 是全局平均速度,$\varepsilon_v \sim \mathcal{N}(0,\sigma_v^2)$。 方向更新: $\theta_t = \alpha \theta_{t-1} + (1-\alpha)\mu_\theta + \sqrt{1-\alpha^2},\varepsilon_\theta,$ 其中 $\mu_\theta$ 是平均方向,$\varepsilon_\theta \sim \mathcal{N}(0,\sigma_\theta^2)$。 位置更新: $x_t = x_{t-1} + v_t \cos\theta_t, \quad y_t = y_{t-1} + v_t \sin\theta_t$ 边界处理:若节点越界,则进行反射,即位置镜像回区域内,同时方向在对应维度取反。 循环:重复步骤 2–5,生成连续轨迹。 邻接生成: 同前,设定通信半径 comm_radius,每个时间步任意两节点距离 ≤ 半径则连边,得到动态邻接矩阵序列。 要点: 参数 $\alpha$ 决定轨迹的平滑度/惯性: $\alpha \to 1$:路径接近直线,有明显惯性; $\alpha \to 0$:路径接近随机游走,更“抖动”。 和 RWP / RW / RD 不同,这里没有“目标点”概念,节点轨迹完全由马尔科夫更新的速度与方向决定,生成的运动更自然连续。 维度 RWP(随机路标) RW(随机游走,你实现:边界/内点混合目标、无停留) RD(随机方向,你实现:边界→边界+停留) GMM(高斯-马尔科夫) 空间密度 中心更密集(运动段偏向中心),若有停留:总体=中心偏移 + 均匀停留的混合 经典“各向同性反射随机游走”→近似均匀;但你的实现中目标多在边界,会带来轻微“边界增密” 边界显著增密(目标与停留都在边界,停留时间把概率质量“挂”在边缘) 近似均匀(无目标点偏好、速度/方向马尔科夫更新 + 反射),边界处可能有很弱的反射效应 速度(时间加权) 若每段速度 ~ U[v_min, v_max]:时间加权后的稳态速度分布偏向慢速(慢速段逗留时间更长 → 采样更容易采到),称“速度衰减/偏置” 同 RWP 的现象(段速均匀抽样 + 时间加权 → 偏慢) 同 RWP;另外停留会拉高“0 速度”的占比 受 α 与噪声控制,接近截断的高斯/稳态马尔科夫分布;无“路标段速”偏置 运动连续性 “跳点—直线—停留”—再跳点,方向变化较大 无停留、持续移动,方向由目标决定(混合边界/内点),变化连贯 “边界—直线—边界—停留”,方向常大幅改变;停留让轨迹呈块状 最平滑(速度/方向自相关),拐弯更自然 节点度/连边分布(给定 comm_radius) 中心密度更高 → 中心平均度更大,边缘更稀疏;有停留则在路标点附近形成“团” 近似均匀(你的实现可能边界稍高);总体度分布较均衡 边界平均度更高(节点停在边上形成热点),内部相对稀疏 近似均匀;由于轨迹平滑,同伴保持时间更长,度变化更缓 链路时长(LET)/SNR波动 停留时链路更稳定;运动段因频繁“折返”方向,LET 方差较大 持续移动且无停留→链路更易“断续”,LET 略短、波动更频繁 停留导致边界链路长时存在,离开边界后链路更快变化,两极分化 速度/方向相关性高 → 链路更平稳、LET 较长;SNR 梯度/方差更小 相遇/再相遇(contact / inter-contact) 中心高密 → 相遇更频繁;停留会带来重入热点 近似均匀;若边界目标占比高 → 边界再相遇概率升高 边界热点相遇/再相遇概率高;内部穿越时短暂接触 平滑惯性 → 更连续的相遇时段、再相遇概率↑(沿相近方向“并走”的时间更长) 链路预测效果: RWP:有停留 → 形成稳定链路,便于预测。中心偏置 → 形成热点区域,链路模式较明显。 RW:持续移动,没有停留 → 链路变化更快,能训练出短时预测能力。效果稍差 RD:节点停留在边界时,链路超稳定 → 预测很容易。 GMM:轨迹平滑,链路断开/形成有更明显的惯性。LET 分布更长,预测任务难度适中(比 RW 稳定,比 RWP 更连续)。最贴近“真实连续移动”的模型。
论文
zy123
9月20日
0
10
0
2025-09-08
K8S
Kubernetes (K8S) Kubernetes 是一个开源的容器编排平台,用于自动化部署、扩缩容(Pod 数量多了/少了自动调整)和自愈(坏掉的 Pod 会被自动重建) 基本架构 一个 Kubernetes 集群 (Cluster) = 控制平面 + 工作节点 的组合。要使用K8S,要先搭建集群,deployment.yaml 和 service.yaml 要提交到 K8S 集群,由它调度和运行。 控制平面 (Control Plane) 负责管理整个集群,不直接跑应用。 组件 作用 比喻 API Server 接收命令(kubectl)、提供统一接口 前台服务员 etcd 存储集群所有状态(配置、Pod 列表等) 账本/数据库 Scheduler 决定 Pod 跑在哪个 Node 上 领班 Controller Manager 保证实际状态符合预期(补 Pod、重建失败的 Pod) 经理 工作节点 (Worker Nodes) 实际跑应用容器。 组件 作用 Kubelet 负责跟 API Server 沟通,并启动/管理容器 容器运行时 运行容器(Docker、containerd) Kube-Proxy 管理网络规则,实现 Service 的负载均衡 graph TD A[控制平面] --> B[Node 1] A --> C[Node 2] A --> D[Node 3] B --> E[Pod] B --> F[Pod] C --> G[Pod] D --> H[Pod] K8S 核心概念 Pod 最小运行单元,一个 Pod 里可以有 1 个或多个容器。 共享网络和存储空间 Deployment 管 Pod 的「副本数」和「版本」。 支持滚动更新、回滚 Service 提供稳定的网络入口(因为 Pod IP 会变)。 负载均衡到一组 Pod。 ConfigMap & Secret ConfigMap:存储配置信息(非敏感)。 Secret:存储敏感信息(密码、Token),会加密。 基本使用方式 Deployment(定义 Pod 模板 + 副本数) apiVersion: apps/v1 kind: Deployment metadata: name: my-app spec: replicas: 3 # 要 3 个 Pod selector: matchLabels: app: my-app template: # Pod 模板 metadata: labels: app: my-app #给 Pod 打标签,Service 用 selector 找到这些 Pod 做负载均衡 spec: containers: - name: my-app #Pod名 image: my-registry/my-app:v1 # ← 指向 CI 推送后的镜像(仓库/名称:标签) ports: - containerPort: 8080 #容器对外提供服务的端口 Pod名可能是:my-app-6f7c9d7c5d-abcde,它里面的容器名:my-app 映射关系: kind: Deployment → 创建一个「Pod 管理器」 replicas: 3 → 保证始终有 3 个 Pod template → Pod 的样子(运行哪个镜像、开哪个端口) Service(提供统一访问入口) apiVersion: v1 kind: Service metadata: name: my-service spec: selector: app: my-app # 找到所有带 app=my-app 标签的 Pod ports: - port: 80 # Service 入口端口 targetPort: 8080 # Pod 里容器的端口 type: LoadBalancer # 暴露给外部访问 映射关系: selector → 绑定到 Deployment 创建的 Pod,根据 Pod 的标签(my-app) ports → 用户访问 80 端口,会转发到 Pod 的 8080 type: LoadBalancer → 提供一个外部 IP 供用户访问 典型工作流程 sequenceDiagram 开发者->>Git: 提交代码 Git->>CI/CD: 触发构建 CI/CD->>镜像仓库: 构建Docker镜像 CI/CD->>K8S: kubectl apply K8S->>K8S: 创建/更新Pod K8S->>K8S: 健康检查 K8S->>用户: 服务可用 sequenceDiagram 开发者->>API Server: kubectl apply -f xxx.yaml API Server->>etcd: 写入期望状态 API Server->>Scheduler: 请求调度 Scheduler->>Node: 分配 Pod 到合适的节点 Node->>Kubelet: 启动容器 Controller Manager->>Cluster: 监控状态并修复 Service->>用户: 提供统一访问入口 👉 过程总结: 提交 YAML → API Server 接收并存到 etcd。 Scheduler 决定 Pod 去哪个 Node。 Node 上的 Kubelet 把容器启动。 Controller Manager 盯着数量,缺了就补。 Service 统一出口,用户不用关心 Pod IP。 常用操作 前提是1:集群必须已经搭好(minikube/kind/k3s/云厂商的 K8S)。 2:kubectl 已经配置好 kubeconfig 3:镜像能拉取到 如果是公有镜像(比如 Docker Hub),直接写就行。 如果是私有仓库,需要配 imagePullSecrets。 # 部署应用 kubectl apply -f deployment.yaml kubectl apply -f service.yaml # 查看集群资源 kubectl get pods -o wide kubectl get deployments kubectl get services # 扩缩容 kubectl scale deployment/my-app --replicas=5 # 滚动更新 kubectl set image deployment/my-app my-app=my-registry/my-app:v2 # 回滚 kubectl rollout undo deployment/my-app
杂项
zy123
9月8日
0
2
0
2025-09-06
CICD
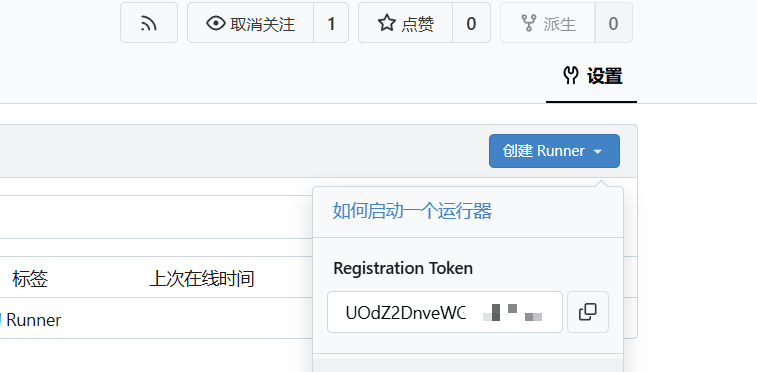
CI/CD 自动部署项目 使用Gitea Actions 1)启用Gitea Actions: 编辑你的Gitea服务器配置文件 app.ini(通常位于 /etc/gitea/或 Gitea 安装目录),添加: [actions] ENABLED = true 然后重启Gitea服务。 2)在部署服务器上安装Runner: # 1. 下载并安装 act_runner (需要sudo) sudo wget https://gitea.com/gitea/act_runner/releases/download/v0.2.10/act_runner-0.2.10-linux-amd64 -O /usr/local/bin/act_runner sudo chmod +x /usr/local/bin/act_runner # 2. 为Runner创建专用工作目录(推荐使用绝对路径) sudo mkdir -p /opt/gitea-runner sudo chown $USER:$USER /opt/gitea-runner # 将目录所有权给当前用户 cd /opt/gitea-runner # 3. 注册Runner(重要:必须添加labels标签) act_runner register --no-interactive \ --instance https://你的gitea域名.com \ --token <你的令牌> \ --name my-runner \ --labels self-hosted,linux # 这个标签必须与工作流文件中的runs-on匹配 # 4. 启动Runner(后台运行) nohup act_runner daemon > runner.log 2>&1 & # 5. 查看运行状态和日志 tail -f runner.log ps aux | grep act_runner 3)令牌获取: 如果你想给整个实例用 → 站点管理员设置 → Actions → Runners。 如果只想给某个仓库用 → 进入该仓库 → Settings → Actions → Runners。 点击 New Runner,系统会生成一个 TOKEN。 例如:abcdef1234567890 还是设置整个实例好!! 4)将act_runner注册为服务自启动 sudo vim /etc/systemd/system/act_runner.service 写入以下内容: [Unit] Description=Gitea Actions Runner After=network.target [Service] ExecStart=/usr/local/bin/act_runner daemon WorkingDirectory=/opt/gitea-runner User=zy123 Restart=always RestartSec=5 [Install] WantedBy=multi-user.target ExecStart 指向你安装的 act_runner 路径(你已经放在 /usr/local/bin/ 了)。 WorkingDirectory 可以写你打算存放 Runner 缓存的目录(比如 /home/zy123/act_runner,你已经在这里 register 过了)。 User=zy123 保证 Runner 以你当前用户运行,而不是 root。 重新加载 systemd 配置: sudo systemctl daemon-reexec 启动并开机自启: sudo systemctl enable --now act_runner 查看运行状态: systemctl status act_runner 5)在后端仓库根目录下,新建目录和文件: .gitea/workflows/deploy.yml 写入以下内容: name: Deploy Backend on: push: branches: [ "master" ] # master 分支推送时触发 jobs: build-and-deploy: runs-on: self-hosted steps: - name: Checkout code uses: actions/checkout@v3 - name: Create application-local.yml run: | mkdir -p src/main/resources/ cat << 'EOF' > src/main/resources/application-local.yml ${{ secrets.APPLICATION_LOCAL_YML }} EOF - name: Build and restart smile-picture run: | cd docs/tags/picture-v1.0 docker compose -f docker-compose-app-v1.0.yml build smile-picture-backend docker compose -f docker-compose-app-v1.0.yml up -d smile-picture-backend - name: Cleanup dangling images run: docker image prune -f 特别注意,application-local没有用git管理,把它存在了Actions的密钥中: 然后deploy.yml中可以把里面的内容复制过去。 6)工作原理 1.Runner 接收任务 当你 push 到 main 分支时: Gitea 会触发 workflow(.gitea/workflows/deploy.yml)。 服务器上的 act_runner 会接收到这个任务,并开始执行 jobs.build-and-deploy。 2.actions/checkout@v3 这一行的作用是:它会把你刚刚 push 的最新代码 完整克隆 到 Runner 的工作目录。 /home/<你的用户>/actions-runner/_work/<repo名>/<repo名>/ 所以,这时候你的项目在 Runner 的临时目录里已经是最新代码了,不需要 git pull。 3.后续 cd docs/tag/group-buy-v3.0 都是在 这个临时目录 里执行的。 相当于你在服务器上的临时副本中: 用 docker compose build 构建镜像 用 docker compose up -d 启动/更新容器 4.Runner 每次执行 workflow 时,工作目录都会 重新 checkout 最新代码。 默认不会自动清理旧目录,但可以在 workflow 里加 actions/checkout 的参数来控制,比如 clean: true。. 7)git push之后
杂项
zy123
9月6日
0
4
0
1
2
...
12
下一页